我主导的一个全栈项目(Java 后端 + Vue 小程序 + 运营后台,多模块多仓库),3 个人两个月交付了 512 个功能点。
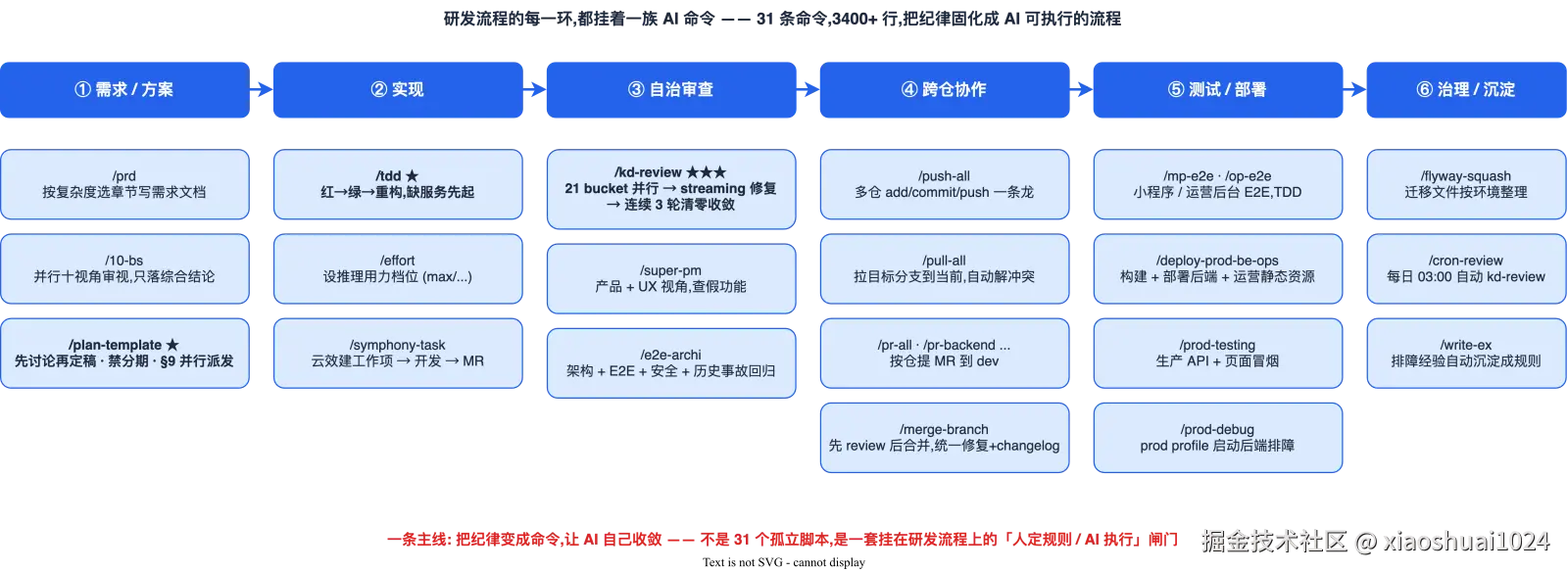
这个数字不是堆人堆出来的,也不是靠加班。关键在于:我把研发流程里每一步该守的纪律,都固化成了 AI 可执行的命令。最终沉淀了 31 条命令、3400 多行,挂在研发流程的每个环节上。
背后是两条工程主线,我先把它们说清楚,后面每一节都是它们的展开:
- harness 自治:人只定规则,把执行全权交给 AI。人不在审查的每一轮里,只看最终报告。harness(线束/约束)的意思是------命令不是"让 AI 做事",是"给 AI 套上纪律边界,让它在边界内自治"。
- loop engineering:把审查、修复、验证都做成自动循环,直到收敛(零问题)才退出。能循环的就不让人介入,把"等同事有空"这类串行等待彻底消掉。
这是 「一切皆可脚本化」那篇的延续------那篇讲「为什么该脚本化」,这篇讲「具体沉淀了什么、怎么用命令的形态落地」。
一、命令不是脚本,是「流程契约」
先澄清一个概念。很多人把 AI 命令理解成「一段能跑的脚本」,这是低估了它。
我项目里这 31 条命令,本质是流程契约 :每条命令规定了一个研发环节里「AI 该怎么做、必须守什么纪律、什么时候停」。脚本只负责执行,命令还要负责约束 AI 的行为边界。
举几个对比:
- 脚本:「跑一下测试」→ AI 跑了,失败也不知道怎么处理。
- 命令 :
/tdd→ 锁定红绿重构、缺服务先探测再启动、跑通后必须汇报证据。AI 的行为被约束在 TDD 纪律内。
这个区别决定了命令体系能不能撑住 512 个功能的交付量。光会跑脚本,AI 跑偏了你拉不回来;有了契约,AI 在每个环节的行为都可预期。
二、需求与方案:把「想清楚」沉淀成模板
研发的第一个关口是方案。这块最容易翻车的是「需求没想透就开写」,写到一半发现方向错了。
我在这环节挂了三条命令:
/prd:按功能复杂度选章节组合写需求文档,含产品价值、成功指标、用户画像、优先级。/10-bs:并行十视角审视同一命题(业务闭环、技术边界、多租户、安全、性能......),只把综合结论落盘到方案文件,过程不污染正文。/plan-template(旗舰):全栈方案模板,是这套命令里最重的一条。
/plan-template 有几个设计点值得单独说,因为它直接决定了能不能一次做对。
先讨论再定稿。第一轮禁止直接输出完整方案,只产出讨论稿------范围、待确认问题、风险、不做项清单。每个待确认问题必须带 AI 的推荐和理由,用户可以直接回「按推荐」采纳。
用户确认后才进入定稿。这一步挡掉了大量「AI 替用户拍脑袋定稿」的浪费。
禁止分期交付同一方案。一份方案定稿的本期功能,必须在单次实现周期内全部完成并过门禁。正文里出现「第一期/第二期」直接判违规。
要分期就拆成多份独立 plan,每份各自一次做完。这条逼着 AI 不偷懒------不能用「下期再补」逃避当前范围。
§9 实现任务派发。定稿时并行派发 backend / frontend / operation 三个子 agent,各自用 codegraph 搜代码库,产出文件映射、API 契约、DDL、组件接口。
最后主 agent 合并去重、做一致性校验。这把「写完方案还要人工补文件清单」的活也自动化了。
三、实现:/tdd 锁死测试纪律
实现环节的核心矛盾不是「会不会写代码」,是「AI 会不会偷工」。AI 写代码很快,但也很容易写出「编译过了就宣称完成」的东西。
/tdd 这条命令,就是用来锁死测试纪律的。
它的规则很硬:实现前必须有可失败的测试,禁止先堆实现再补假绿断言。测试跑不通时,按项目规范排查------首个失败即停,修当前红再重跑。
依赖服务(本机 MySQL、Redis、8080 上的 Spring Boot)必须先探测再启动,禁止以「服务没起」为由跳过门禁。启动失败要读日志排障,不能把失败归咎于「环境不行」就结束会话。
这跟 测试纪律篇讲的是同一件事:纪律不靠人盯,靠命令固化成 AI 必须遵守的流程。
AI 想提前收工?命令里写得清清楚楚------本期范围内验证命令没全跑通,不算完成。
/effort 是配套的小命令,设定本会话的推理用力档位(最高档 max)。复杂逻辑用 max 档,简单改字用低档,省 token 也省时间。
四、审查:loop engineering 的典型实现
这是整套命令体系的旗舰,也是 512 个功能能交付的关键,更是 loop engineering 落地最彻底的一环。
传统的代码审查是人审,或者 AI 审一次给个报告就走。我的做法是 /kd-review------全自动审查循环,直到零问题收敛。
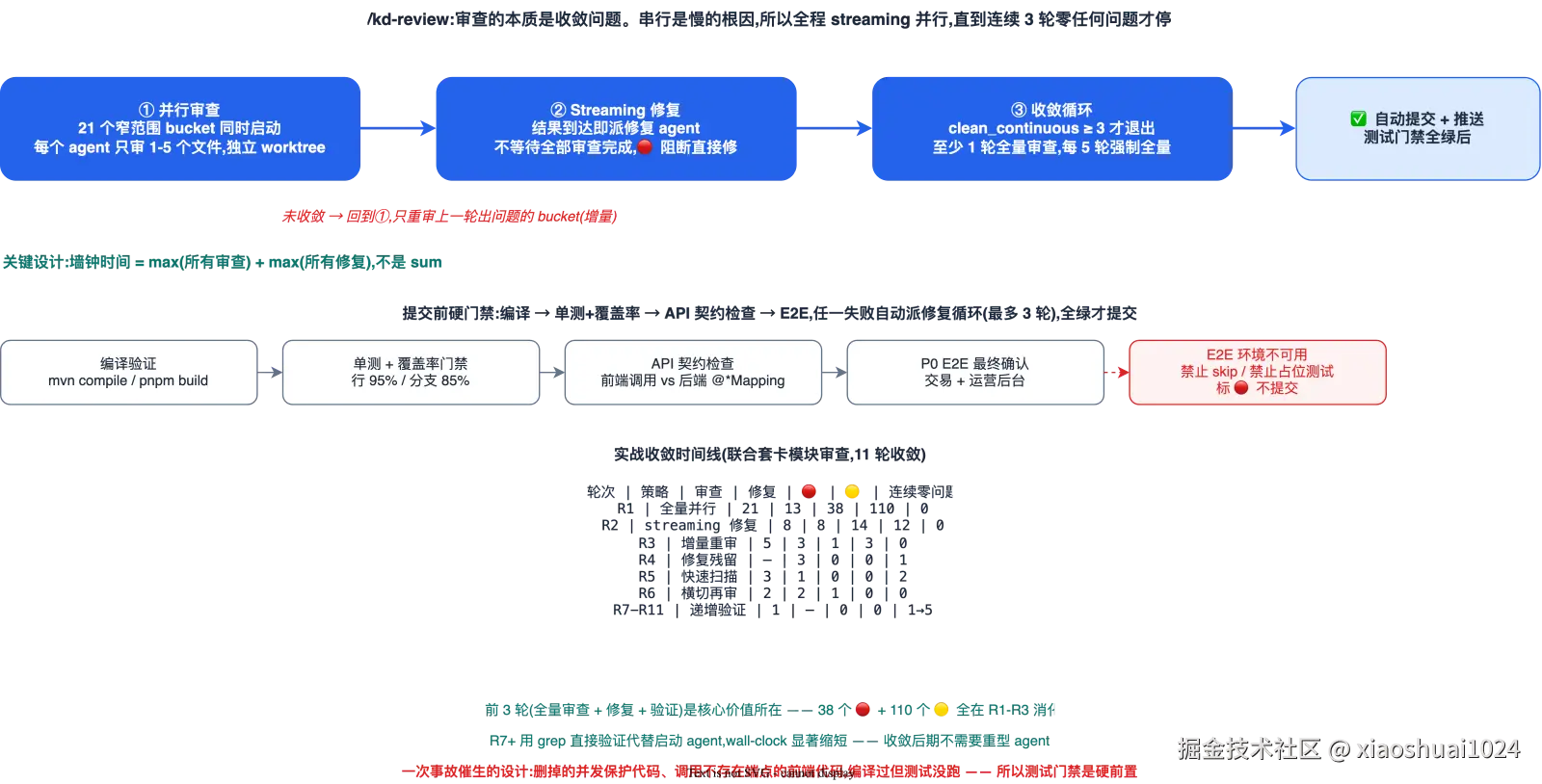
核心思路:审查的本质是收敛问题,串行是慢的根因。所以全程 streaming 并行------这同时是 loop engineering 的两个发力点:循环(收敛)+ 并行(提速)。
第一阶段,并行审查。把变更拆成约 21 个窄范围 bucket------后端按服务拆、前端按页面拆、横切按关注点拆。每个 agent 只审 1-5 个文件,各自在独立 worktree 里,全部同时启动。
第二阶段,streaming 修复。关键优化是不等全部审查完成。每个审查 agent 一返回结果,立刻派修复 agent,🔴 阻断问题直接修,不询问、不等确认。
墙钟时间约等于 max(所有审查) + max(所有修复),不是相加。这是 streaming 模式相对串行的核心收益。
第三阶段,收敛循环。连续 3 轮零任何问题(🔴🟡🔵 全清)才退出。每轮用增量审查------只重审上一轮出过问题的 bucket,连续两轮零问题的文件直接跳过。
每 5 轮强制全量一次,防止增量产生盲区。
提交前还有四道硬门禁:编译 → 单测+覆盖率(行 95%/分支 85%)→ API 契约检查 → P0 E2E。契约检查这一层专门拦「前端调用了后端不存在的端点」------逐仓审查时发现不了,必须做跨仓 diff。
任一失败自动派修复循环,最多 3 轮,全绿才提交。
这套门禁是被事故催生的。历史上 kd-review 只做编译验证就自动提交,结果删掉的并发保护代码、调用了后端不存在端点的前端代码,都编译过了但测试没跑。
编译通过 ≠ 测试通过------所以测试门禁变成硬前置。
E2E 环境不可用时,命令的态度也很硬:禁止自动跳过、禁止写 expect(true).toBe(true) 占位测试。直接标 🔴 不提交,等环境恢复。这条挡住了「假装通过」这条最隐蔽的偷工路径。
审查族还有两条专项命令各有分工。/super-pm 站产品 + UX 视角,查假功能------弹窗代替逻辑、占位入口、假数据、骨架页冒充,逐一排查。
/e2e-archi 站架构 + 安全视角,查事务边界、租户隔离、性能容量。它最特别的一项是历史事故回归检查------已经踩过的坑,逐条变成检查项,防止再次引入。
五、跨仓协作:多仓库全靠命令兜底
这个项目是「主仓 + frontend + backend + operation-backend」多仓库结构,跨仓协作是日常痛点。
这块的命令最朴素,但最省时间:
/push-all:对有改动的子模块和主仓,依次 add、commit、push 一条龙。默认按暂存路径自动生成 conventional commit 说明。/pull-all:拉目标分支(默认 dev)代码到当前分支,自动处理冲突。/pr-all和按仓拆分的/pr-backend、/pr-frontend等:先同步再按仓提 MR 到 dev。按仓拆是为了让审查粒度更合理。/merge-branch:交互式多仓合并助手。fetch → 预检 → e2e-archi review → merge + 解冲突 → 统一修复 + 全量测试 → changelog,一条命令走完。
这些命令单独看都不复杂,但组合起来把多仓库协作的机械操作全自动化了。没有它们,3 个人管 4 个仓库光是 git 操作就要吃掉大量时间。
六、测试与部署:E2E 是硬门禁
测试和部署环节,挂的是验证族命令。
/mp-e2e和/op-e2e:小程序端和运营后台端的 E2E,都带 TDD 和环境预检。失败时先收集再分析,不盲改。/deploy-prod-be-ops:构建并部署后端 JAR 和运营后台静态资源到生产服务器。/prod-testing:生产快速验证------API 冒烟 + 运营后台页面冒烟。部署完必跑。/prod-debug:调试生产环境,后端以 prod profile 启动排障,前端切到生产域名,重启全部服务。
E2E 在这套体系里是硬门禁,不是可选项。前面 /kd-review 的收敛条件里,E2E 失败一样阻断提交。
这跟 AI 转型篇讲的判断一致:AI 能把测试和验证全自动化,前提是你得把「E2E 不可跳过」这条纪律固化进命令。
七、DB 与运维:把事故沉淀成命令
最后一块是治理族,这套命令最有「长期价值」的部分。
/flyway-squash:Flyway 迁移文件整理。先判断环境------本地开发库可自动 squash,共享库手工操作,生产只输出指导不执行。不同的库有不同的安全边界,命令把这套判断固化了。/cron-review:在当前会话启动后台定时审查,每天 03:00 自动跑 kd-review(数据安全 + 全量质量)。夜间让 AI 巡检,第二天看报告。/write-ex:排障经验自动沉淀。排障后把经验归类追加到对应规则文件并写入个人记忆,全程自动。这是「事故即规范」的落地机制------踩过的坑自动变成下次 AI 会读的规则。
/write-ex 是整套体系里最容易被忽视、但复利最大的一条。AI 排障依赖经验,而经验不沉淀就会丢失。让每次排障的结论自动写进规则文件,等于让整个命令体系在持续自我进化。
八、回到两条主线:harness 自治与 loop engineering
把 31 条命令的共性提炼出来,归根到底就是开头那两条主线------它们不是抽象口号,是每条命令的设计依据。
harness 自治:人定边界,AI 在边界内全权执行
「把纪律变成命令」就是 harness 的字面含义------给 AI 套上线束。每条命令不是「让 AI 做某事」,是「让 AI 在做某事时必须守某些规则」,然后把执行权完整交出去。
/tdd 守测试纪律,/kd-review 守审查纪律,/plan-template 守方案纪律。规则是稳定的,执行交给 AI------人不盯每一轮,只看最终报告。这套机制让 3 个人能管 4 个仓库而不失控,靠的就是 harness 把人的介入面压到最小。
loop engineering:能循环的就循环到收敛
「让 AI 自己收敛」的工程化形态就是 loop。能并行的全并行,能自动修复的自动修,能循环的就循环到收敛------把「等同事有空」「等环境恢复」这类串行等待彻底消掉。
/kd-review 的 streaming 设计就是典型:21 个 bucket 并行审查、并行修复、连续 3 轮零问题才退出。不是为了炫技,是因为审查串行真的慢,而 loop 能把墙钟时间从「相加」压成「取最大」。
分层闸门:harness 的最后一道兜底
编译 → 单测 → 契约 → E2E,每层独立判定,任一失败阻断。闸门之间不互相兜底,各管各的------这是 harness 自治能被信任的前提:AI 自治执行的边界,由确定性闸门兜住,而不是寄望于一个万能检查。
没有分层闸门,loop engineering 会变成「无效循环」------问题反复出现却拦不住。闸门把每一类问题钉死在专门的拦截层上,loop 才能真正收敛。
九、命令体系是新的护城河
回到开头那个数字。512 个功能、3 个人、两个月,听起来像奇迹,其实是 harness 自治 + loop engineering 这套机制的必然产物。
人定规则,AI 自治执行;能循环的循环到收敛。规则沉淀进命令文件,每次执行都按同一套纪律走,不靠人盯。新人(或新 AI 会话)进来,读一遍命令就知道该怎么干------这比口口相传的「团队规范」稳定得多,规范靠人记,命令靠文件固化。
我的判断是:研发的护城河,已经从「我会做什么」挪到了「我沉淀了什么命令体系」。前者 AI 正在接管,后者才是把小团队产能拉满的关键。
遇到任何重复操作、任何依赖纪律的环节,我的第一反应不是「我来盯」,而是「这能不能做成 harness + loop」------给它套上纪律边界让它自治,给它一个收敛条件让它循环。
一年下来,身边攒的已经不是散装脚本,而是一套挂在研发流程上的、AI 自治执行 + 自动收敛的流程契约。
这才是「AI 研发实战」的终局形态------不是会用 AI 写代码,而是用 harness 自治和 loop engineering 重建整个研发流程的执行层。