大家好,最近在优化我们系统的定时任务模块时,跟 Linux 时间轮算法杠上了。
说真的,很多人学 Linux 网络编程的时候,会把 epoll、Reactor、协程吹得天花乱坠。可真到了线上,最容易把服务拖死的,往往是"时间"。
是的,就是如何高效管理海量定时任务!
我第一次真正理解 Linux 时间轮算法的时候,有种"卧槽原来还能这样"的感觉。
它不像红黑树那么优雅,也不像跳表那么性感。
但它特别像一个在机房待了十年的老运维:
不讲武德,只讲效率。
今天这篇文章,我想用一个干了很多年后端、被线上事故毒打过无数次的老程序员视角,聊聊 Linux 时间轮算法到底是怎么回事。
看完你会明白:为什么Linux内核选它,为什么Netty在用它,以及------最重要的一点------什么时候千万别用它。
一、为啥要搞时间轮?
定时器的本质很简单,就是告诉系统,"xx毫秒后,帮我干个活"。
很多新人第一次写定时任务的时候,会这么写:
while (true) {
sleep(1);
check_timeout_tasks();
}甚至现在不少业务系统还这样。
功能当然能跑。
可问题是------任务一多,系统立刻开始抽风。
举个最经典的场景。
假设你有 100 万个连接。
每个连接都需要:
- 60 秒心跳检测
- 超时关闭
- 延迟重试
你怎么办?
很多人第一反应是:
"那我存个时间戳呗。"
于是代码开始长这样:
struct Connection {
int fd;
long expire;
};
std::vector<Connection> conns;然后每秒扫描一次。
for (auto &conn : conns) {
if (conn.expire < now) {
close(conn.fd);
}
}看着是不是还挺合理的?
问题来了。
100 万连接。
你每秒扫一遍。
意味着什么?
意味着 每个时钟中断去遍历百万个节点,CPU直接原地升天。
就比如你开了一个邮局,所有信件都堆在一个大篮子里。来了新信,你得从头翻一遍,找到它该排的位置插进去。来十万封信,你就得翻十万遍------这不是在解决问题,这是在培养耐心。
内核大佬们可没时间这么捣腾。大佬George Varghese和Tony Lauck在SOSP上发表了一篇论文,提出了一个现在来看仍然惊艳的思路------时间轮算法。
核心特别简单:别再用有序链表的思路去折腾了,咱们换个角度,把定时器当成钟表盘上的刻度来管理,时间复杂度是 O(1),也就是说,无论有多少个定时器,添加、删除、触发操作的效率都几乎不变。这不就是我们想要的么?
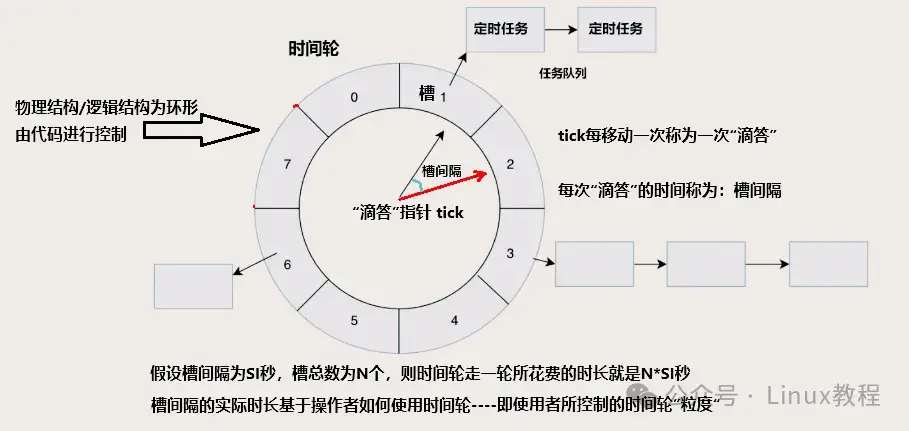
二、时间轮原理
时间轮算法的核心思想,就像钟表里的齿轮转动。Linux 内核用多级时间轮(也叫分层时间轮)来实现,它由多个层级组成,每个层级都是一个时间轮,就像多个齿轮嵌套在一起。最外层齿轮转一圈,内层齿轮就转一格,依次类推。每个时间轮上有很多槽位,每个槽位挂着一堆定时器。
很多文章一上来就讲:
- tick
- slot
- round
- cascade
- hierarchy
看得人头皮发麻,其实核心逻辑并不复杂。
假设现在有一个钟表。
0 1 2 3 4 5 6 7 8 9每秒走一格。
现在有几个任务:
|--------|--------|
| 任务 | 延迟 |
| A | 2 秒 |
| B | 5 秒 |
| C | 12 秒 |
那么:
- A 放 2
- B 放 5
- C 放 2
等等。
C 为什么也放 2?
因为时间轮只有 10 格。
12 % 10 = 2。
那怎么区分 A 和 C?
答案是:
圈数。
也叫 round。
A:
2 秒后触发
round = 0C:
12 秒后触发
round = 1时间轮每转一圈。
round--。
当 round == 0 时。
任务真正执行。
是不是一下就通了?
2.1 单层时间轮
理解时间轮,最好从单层开始。
假设你有一个大小为8的数组,每个位置叫一个"槽位"(bucket)。我们让一个时针每隔1秒走一格。当前指针指向槽i时,就把槽i里挂的所有定时任务统统触发掉。走完一圈8秒,再从头开始------是不是特别像一根秒针在表盘上打转?
#define WHEEL_SIZE 256
#define WHEEL_MASK (WHEEL_SIZE - 1)
struct timer_node {
void (*callback)(void *arg);
void *arg;
unsigned long expires; // 绝对过期时间(单位:tick)
struct list_head entry;
};
struct timer_wheel {
struct list_head slots[WHEEL_SIZE];
unsigned long current_slot;
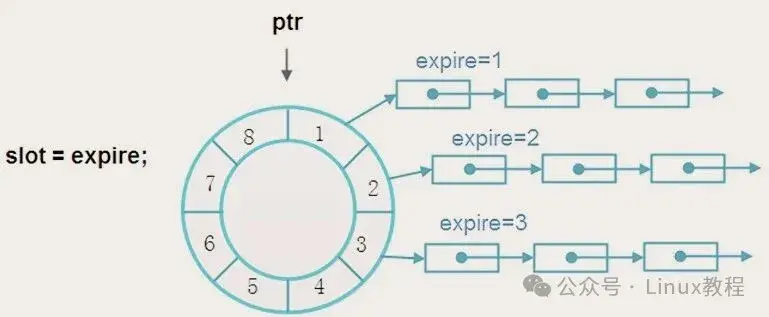
};插入任务时,计算它应该落在哪个槽位:slot_index = (expires - now) & WHEEL_MASK。如果expires - now正好等于1个tick,丢到邻位;等于WHEEL_SIZE,还丢在当前位置,但需要带一圈round计数,否则以为马上过期就乱套了。至于round计数怎么带,后面的多级轮子再展开。
插入O(1),删除O(1),这是什么概念?哈希表的定时器版本!
但天下没有免费的午餐------单层时间轮的覆盖范围极其有限。假设每个tick=10ms、256个槽,整圈合计也就2.56秒,超过这个时间范围的定时器就没法直接存了。解决办法要么硬拖多圈(带round),但这样过期检测就不是O(1)了;要么扩容------你试试把WHEEL_SIZE开到65536,直接把整个二级缓存的局部性打没了。
所以啊,单层时间轮特别适合短期、密集、高精度要求不高的场景。像网络重传超时(比如TCP的RTO)、用户态心跳检修,这些落在100ms~10s区间的任务非常香但如果你的业务动不动就要延迟一小时执行任务,用单层时间轮就是给自己找麻烦------要么数组巨大内存吃不消,要么多圈后性能直线下降。
2.2 多级时间轮
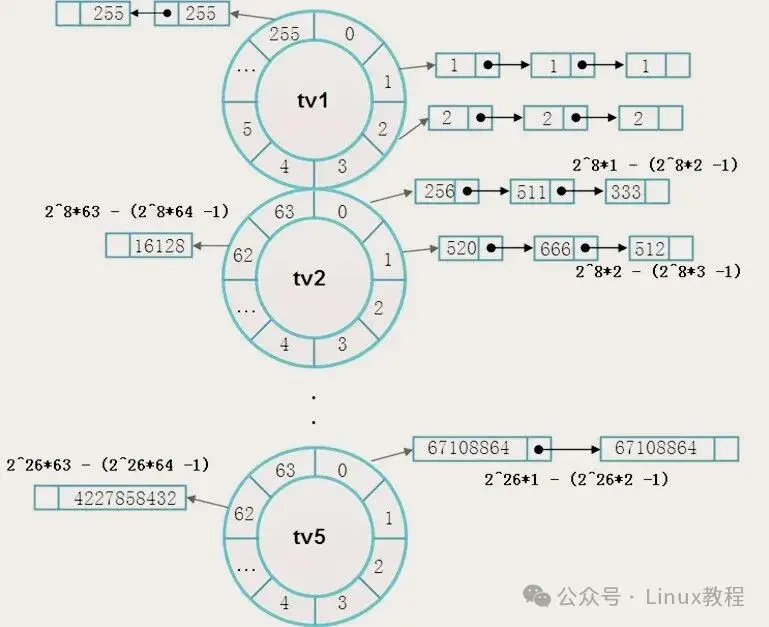
Linux这帮大牛当然不会满足于单层的限制。他们搞了一个优雅的五级结构来解决这个矛盾------TV1管近期,TV2到TV5一级级往上覆盖,越往上时间跨度越大牺牲的分辨率也越大。任务超出当前级容量就溢出到上级,上级到期的任务再级联回本级。
#define TVR_BITS 8 // 第一级 2^8 = 256
#define TVN_BITS 6 // 第二~五级 2^6 = 64
struct timer_vec_root {
struct list_head vec[TVR_SIZE]; // 第一级:0-255
};
struct timer_vec {
struct list_head vec[TVN_SIZE]; // 第二到五级:各64个槽位
};
struct tvec_base {
struct timer_vec_root tv1; // 近期定时器
struct timer_vec tv2; // 中期定时器
struct timer_vec tv3;
struct timer_vec tv4;
struct timer_vec tv5; // 最远期定时器
unsigned long timer_jiffies; // 当前时间指针
};怎么理解这个结构?假设HZ=1000(每个tick=1ms):
- TV1(256槽):覆盖0~255ms,精度1ms
- TV2(64槽×256ms):覆盖256ms~16.383秒
- TV3(64槽×16.384秒):覆盖约17分钟~18.6小时
- TV4和TV5逐级推更长时间范围
哪个更有趣?TV2一个槽位打包了TV1整张轮(256ms),TV3一个槽位打包了整个TV2和TV1!这种嵌套设计可以把长达数日的时间跨度压缩到几个不大的数组中,同时保留了O(1)的插入和到期检测性能。
当一个定时器的expires落在256ms~16.383秒之间,它就落到TV2的一个槽里,不需要动用TV3及以上的轮子。等时钟推进到它所在的那一组时,再级联回TV1。有点类似钟表的秒分时联动------秒针走完一圈,分针推一步,拉出下一分内的秒刻度。
级联机制(cascade) 是这套设计的灵魂之处:
static int cascade(struct tvec_base *base, struct timer_vec *tv, int index)
{
struct list_head *list = tv->vec + index;
struct timer_list *timer;
// 将该槽的所有定时器重新插入时间轮
list_for_each_entry_safe(timer, tmp, list, entry) {
__internal_add_timer(base, timer); // 重新计算层级
}
INIT_LIST_HEAD(list);
return index;
}每次时钟中断,timer_jiffies递增,TV1的当前槽被执行并清空。当timer_jiffies增长到TV1边界时,TV2相应槽被触发cascade,把里面的定时器按剩余时间重新塞回TV1对应的槽------这种懒处理的妙处在于,TV2整层都不需要高频扫描,只用时指针到达时一次性迁移。长时任务在绝大多数时间只待在高层数组里"睡大觉",连链表遍历的压力都没有。
我在调网络网关时曾经用单机hotplug压到10万个tcp timer,内核的timer轮几乎感觉不到压力,CPU在0.3%附近波动。要是改用有序链表的话,你说要挂多少。这,就是多级时间轮的威力。
但------敲黑板,这里必须提一嘴------低精度定时器的时间轮精度受HZ限制。HZ=100时,定时器精度只能到10ms,对毫秒级甚至微秒级精度需求完全无能为力。所以后面高精度定时器(hrtimer)子系统引入时,就把时间轮换成了红黑树(timerqueue),因为高精度定时器的到期时间是稀疏且随机分布的,时间轮在面对纳秒级精度需求时,要么需要一个巨大且大部分为空的时间轮(效率极低),要么精度崩坏。两种定时器场景不同,各司其职。
2.3 用户态的时间轮
说完了内核的多级轮子,咱们把目光拉回用户空间。
Java圈有Netty的HashedWheelTimer,C++这边呢?
很多网络库(比如muduo、evpp)自己也手撸过类似的东西。你有没有好奇过"Hashed"这个前缀啥意思?把定时器的deadline当key,用哈希法定位槽位------和内核那个线性推进jiffies的思路不太一样。说白了就是用空间换时间,加个hash的壳,让插入和删除都变成O(1)。
#include <atomic>
#include <chrono>
#include <condition_variable>
#include <functional>
#include <mutex>
#include <thread>
#include <vector>
#include <list>
#include <memory>
using TimerTask = std::function<void()>;
struct TimeoutEntry {
uint64_t deadline; // 绝对到期时间(ms)
TimerTask callback;
// 还可以加cancel标志,为了简单先不写
};
class HashedWheelTimer {
public:
explicit HashedWheelTimer(int ticksPerWheel = 512,
int tickDurationMs = 100)
: wheel_(ticksPerWheel),
tickDurationMs_(tickDurationMs),
currentTick_(0),
running_(true) {
worker_ = std::thread(&HashedWheelTimer::workerLoop, this);
}
~HashedWheelTimer() {
running_ = false;
cv_.notify_one();
if (worker_.joinable()) worker_.join();
}
// 添加一个延迟任务,delayMs单位毫秒
void addTimer(uint64_t delayMs, TimerTask task) {
uint64_t deadline = getCurrentTimeMs() + delayMs;
// 计算槽位:基于延迟的绝对时间
int slot = (deadline / tickDurationMs_) % wheel_.size();
std::lock_guard<std::mutex> lock(mutex_);
wheel_[slot].push_back({deadline, task});
}
private:
std::vector<std::list<TimeoutEntry>> wheel_;
const int tickDurationMs_; // 每个tick的毫秒数
std::atomic<uint64_t> currentTick_; // 当前已经走过的tick数
std::atomic<bool> running_;
std::thread worker_;
std::mutex mutex_;
std::condition_variable cv_;
uint64_t getCurrentTimeMs() {
auto now = std::chrono::steady_clock::now().time_since_epoch();
return std::chrono::duration_cast<std::chrono::milliseconds>(now).count();
}
void workerLoop() {
auto nextTickTime = std::chrono::steady_clock::now();
while (running_) {
// 1. 等待到下一个tick
{
std::unique_lock<std::mutex> lock(mutex_);
cv_.wait_until(lock, nextTickTime, [this] { return !running_; });
}
if (!running_) break;
// 2. 更新当前tick,并处理该槽位的所有任务
uint64_t tick = currentTick_.fetch_add(1);
int slot = tick % wheel_.size();
std::list<TimeoutEntry> bucket;
{
std::lock_guard<std::mutex> lock(mutex_);
bucket.swap(wheel_[slot]);
}
uint64_t now = getCurrentTimeMs();
for (auto& entry : bucket) {
// 严谨起见,这里可以判断 deadline <= now
if (entry.deadline <= now + tickDurationMs_) {
entry.callback();
} else {
// 理论上不应该发生,多圈任务我们没做级联,先忽略
// 后面会讲到多圈怎么办
}
}
// 3. 计算下一个tick的绝对时间
nextTickTime += std::chrono::milliseconds(tickDurationMs_);
}
}
};默认tickDurationMs_ = 100ms意味着所有定时器的精度最多误差±100ms。绝大多数网络场景其实无所谓------TCP超时重传差个几十毫秒,人根本感觉不到。但如果你拿这玩意儿去做量化交易里的价格推送延迟控制,我劝你善良。
worker是单线程驱动的。假设你某个槽位挂了上千个任务,一个tick里就要把这些回调全部执行完。如果某个回调里不小心写了同步DB查询或者RPC调用------恭喜你,整个时间轮卡死在这一槽。后续所有tick全部延迟,积压的任务越来越多,最后雪崩式崩溃。这不是bug,是算法边界,千万记住。
那有人说了:我把每个回调扔到线程池里异步执行行不行?
行,但注意定时器回调里如果访问共享数据,锁竞争又成了新的瓶颈。
而且异步执行会打乱任务完成的时序------本来希望A任务在B之前完成,线程池一调度全乱了。所以HashedWheelTimer这类设计天生就只适合轻量、短平快的回调,比如设置一个标志位、发一个消息到队列。凡是涉及I/O或复杂计算的,统统交给专门的工作线程去做,时间轮只负责"闹钟响铃"这个动作。
官方文档也好,各路大牛的博客也好,都反复强调这种timer是approximated(近似)的,别指望准时。你要是非要毫秒级精度,把tickDurationMs设成1ms,那新问题又来了:tick频率太高,worker线程大部分时间在空转遍历大量空槽位,CPU先吃不消了。典型的精度和吞吐量不可兼得。
C++社区有没有更优雅的实现?
有。比如asio::steady_timer配合io_context,每个定时器独立管理,但那是基于最小堆的,不适合超大规模并发。还有基于timerfd+epoll驱动的轮子------这个我们后面会专门讲。
说了这么多,核心就一句话:HashedWheelTimer适合高吞吐、低精度的批量超时管理,别拿它当高精度定时器用。
2.4 timerfd:用户态时间轮的终极方案
如果你在Linux用户空间手撸时间轮,最大的痛点是------谁来驱动这个轮子转?
以前很多人写Demo就这么写:
while (true) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
// 推进时间轮...
}看起来很自然对不对?
但如果服务跑在1000qps以上的生产环境里,sleep的精度和调度抖动会搞得你怀疑人生。我在排查第一次线上事故时才发现,std::this_thread::sleep_for底层依赖clock_nanosleep,它的实际唤醒时间受进程调度器的延迟影响,高负载下误差经常飙到几毫秒甚至几十毫秒。更致命的是,sleep线程哪怕什么都不干也在持续占用CPU做系统调用。这简直是"活着就已经给对方添麻烦了"的代码典范。
后来翻了大量资料,找到了最正统、最Linux式的方式:timerfd_create + epoll_wait。
timerfd机制把定时器到期变成了文件描述符上的可读事件,直接融入epoll事件循环,完全避免轮询。
核心用法:
int tfd = timerfd_create(CLOCK_MONOTONIC, TFD_NONBLOCK);
struct itimerspec new_value;
new_value.it_value.tv_sec = interval_sec;
new_value.it_value.tv_nsec = interval_nsec;
timerfd_settime(tfd, 0, &new_value, NULL);
int epfd = epoll_create1(0);
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = tfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, tfd, &ev);
while (true) {
int n = epoll_wait(epfd, events, MAX_EVENTS, -1);
// tfd可读------定时器已到期
uint64_t expirations;
read(tfd, &expirations, sizeof(uint64_t)); // 必须读!清空到期次数
tick(); // 驱动时间轮推进
}定时器到期时,内核在定时器fd的内核缓冲区写入一个8字节的整数值,表示到期的次数。epoll检测到EPOLLIN时,必须调用read读走这8字节,否则内核会认为你不想清空,下次不会重新触发。
我手改那个网关方案时换了timerfd+epoll驱动后,定时器的调度精度从±20ms提升到±2ms以内,GC毛刺也大幅减少。关键是不再有一个线程在那里傻乎乎地sleep了------定时事件完全被epoll复用,线程数量原地降级。
但这个方案有个细节大家容易翻车:CLOCK_MONOTONIC。你如果用了CLOCK_REALTIME,NTP校准时系统时间往后或往前突变,绝对时间模式(TFD_TIMER_ABSTIME) 下任务可能永久丢失或瞬间全部触发。别问我怎么知道的╮(╯▽╰)╭。
👉 【就业避坑】C++ 就业前景全解析:为什么劝退声不断,大厂核心岗仍刚需 C++?
👉 【大厂标准】Linux C/C++ 后端开发系统学习路线
👉 【音视频】音视频流媒体高级开发核心学习路径
👉 【Qt进阶】C++ Qt 桌面 & 嵌入式开发一条龙学习攻略
👉 【内核底层】Linux 内核硬核修炼指南
👉 【面试冲刺】C/C++ 高频八股面试题 1000 题(三)
👉 【项目实战】手撕线程池:C++ 程序员的能力试金石
三、手写一个简单的时间轮
懂了原理,咱们自己动手写一个简化版的时间轮。
假设:
- 60 个槽
- 每秒走一次
- 支持秒级定时任务
3.1 数据结构
#include <iostream>
#include <vector>
#include <list>
#include <functional>
using namespace std;
const int SLOT_NUM = 60;
struct TimerTask {
int rotation;
int slot;
function<void()> callback;
};
class TimeWheel {
private:
vector<list<TimerTask>> slots;
int current_slot;
public:
TimeWheel() {
slots.resize(SLOT_NUM);
current_slot = 0;
}
};其实核心就两个东西:
- 环形槽位
- 当前指针
简单得有点不像高性能算法。
3.2 添加任务
void add_timer(int timeout, function<void()> cb) {
int ticks = timeout;
int rotation = ticks / SLOT_NUM;
int ts = (current_slot + (ticks % SLOT_NUM)) % SLOT_NUM;
TimerTask task;
task.rotation = rotation;
task.slot = ts;
task.callback = cb;
slots[ts].push_back(task);
}重点看:
rotation = ticks / SLOT_NUM和:
slot = (current + offset) % SLOT_NUM整个时间轮精髓就在这儿。
说白了,就是:
- 算落哪个格子
- 算还要转几圈
3.3 时间推进
void tick() {
list<TimerTask> &lst = slots[current_slot];
for (auto it = lst.begin(); it != lst.end();) {
if (it->rotation > 0) {
it->rotation--;
++it;
} else {
it->callback();
it = lst.erase(it);
}
}
current_slot = (current_slot + 1) % SLOT_NUM;
}这个 tick,就是整个时间轮发动机。
每秒调用一次。
然后:
- 当前槽位任务 round--
- round 为 0 的执行
- 指针继续旋转
完事。
没有排序。
没有平衡树。
没有堆调整。
所以它非常快。
四、时间轮面试题
几道常考不衰的时间轮面试题:
第一题:为什么时间轮里每个槽都要用双向链表?
有的人愣半天,说"因为方便遍历"。双向链表的本事在于------它能以O(1)的代价从中间任意位置删除或取消节点。假设定时任务支持cancel()操作,没有双向指针的链表只能从头找到尾才能删除。单层桶里几百个任务一挂,删除一次就是O(n),这谁受得了。在多级时间轮里,跨级迁移和删除尤其需要双向链表的随机删除能力。
第二题:多级时间轮的级联机制如果某槽内有百万任务,会有什么问题?
这里通常没人想过。其实当某层的某个槽里有海量定时器时,触发cascade的那一次tick会一次性转移全部百万个任务到下一级,导致该次tick的CPU耗时飙高,后续所有调度都跟着延迟。这不是算法崩溃,而是延迟尖刺。解决方案:如果业务特征里确实可能聚集到百万个任务同时落在同一槽,可以考虑在高层级槽使用延迟队列加分批迁移的策略,而不是一次性全搬。
第三题:epoll_wait的timeout参数可以替代时间轮吗?
这是老有人偷懒的"骚操作"------epoll_wait(epfd, events, MAX_EVENTS, 100)直接当定时器用。但epoll的超时精度最差能到1ms级,且它的设计目标是等待I/O事件,不是管理大量并发定时器。你怎么给上万个连接设各自不同的超时?定时器链表里还得额外维护到期时间,对epoll_timeout来说是做不到的。所以时间轮的核心价值在于:管理大量独立超时源的O(1)能力,epoll_timeout做不到这一点。
第四题:Redis 为什么没直接用时间轮?
很多面试官会问,Redis有大量过期key,为什么不用时间轮?因为Redis场景不同。Redis key过期时间跨度太随机,而且数量巨大、时间分布离散、精度要求不高。于是Redis采用惰性删除加定期随机扫描。本质上,它在空间和CPU之间找了平衡。所以技术方案永远没有银弹,一定是场景驱动。别看到一个新技术就想everywhere。
第五题:为什么很多公司最后还是不用时间轮?
因为很多文章会让你误以为"时间轮天下无敌",其实并不是。时间轮有几个硬伤:精度有限 ------tick越大误差越大,tick越小CPU开销越大,这是天然的tradeoff。不适合超高精度场景 ,比如高频交易、实时控制、音视频同步,这些更偏向hrtimer。超长延迟管理复杂 ------虽然多层时间轮能解决,但实现复杂度会上升,而且cascade本身也有成本。调试困难,这点特别真实。线上timer出问题时,你会发现根本不知道它在哪层、哪一圈、什么时候触发,日志都不好打。
五、什么时候千万别用时间轮
时间轮,优雅,高效,但一定要锚定场景。
你拿它做双11秒杀的延迟库存释放集群没问题。拿它做证券交易中价位和波动率依赖的精准调度,一个100ms的偏差就能让策略模型直接失效。精度不够就是精度不够,算法再美也得选对场景。
Linux内核为什么时间轮和高精度定时器红黑树同时存在?因为它们服务的精度域不同------时间轮面向高吞吐、批量粗粒度的定时任务;hrtimer面向低延迟、纳秒级精度要求。你需要知道自己面对的是哪类问题。
这几年代码从多级轮子改到timerqueue,又改到基于timerfd的多级离散版本,我发现一个规律------写代码总是在"整洁的抽象"和"残酷的现实"之间反复摩擦。10ms的精度差别也许在代码里只是一行的差异,在业务上可能是一个重度游戏玩家的暴怒退游。所以,永远不要被算法的美迷惑了双眼,扎实用好tickDuration、慎用绝对时间模式,并且------务必把监控配起来。监控tick间隔偏离、pending timeout的数量、cascade耗时这些指标,别等到线上崩了再去补。
六、避坑点
坑 1:时间精度问题
系统时钟滴答的精度影响时间轮精度。如果滴答是 10 毫秒,那你设置的 5 毫秒定时器肯定不准。我们之前有个实时监控任务,要求 1 毫秒精度,结果发现系统滴答是 10 毫秒,只能手动修改内核配置,把 HZ 从 100 调到 1000,这才搞定。
坑 2:定时器过期处理
如果任务执行时间超过到期时间,比如定时器 A 应该在 10:00:00 触发,但执行到 10:00:05 才完成,那后面的定时器就全乱套了!我们当时的解决办法是:任务执行时,先检查当前时间是否已经过了下一个到期点,如果过了就重新入队,确保不会积压。
坑 3:高并发下的锁竞争
在多线程环境下,添加和删除定时器需要加锁。但锁太粗会导致性能暴跌。我们后来用了细粒度锁,给每个时间轮槽位加独立的锁,把性能提升了 5 倍!
坑 4:内存管理陷阱
大量创建和删除定时器会导致内存碎片。我们曾经遇到过系统运行几天后,内存碎片率飙升到 90%,最后改用内存池(比如 tcmalloc)才解决。