论文标题: UniFormer: Efficient and Unified Model-Centric Scaling for Industrial Recommendation
论文链接: arxiv.org/abs/2606.27058
论文作者: Bo Chen, Jinlong Jiao, Tijian Hu, Ruihao Zhang, Yanzhi Liu, Chenghou Jin, Qinglin Jia, Baixuan He, Hechang Pan, Yiwu Liu, Jian Liang, Chaoyi Ma, Ruiming Tang, Han Li, Kun Gai(快手 Kuaishou Technology)
发表: KDD '25,Toronto
一句话总结: 快手把工业推荐里长期各自为战的行为建模 / 特征交互 / 多任务学习,重构成一个统一的 Transformer 式 co-scaling 框架 ------ 用 Feature-space Interaction Module(FIM)+ Task-space Interaction Module(TIM) 两块标准化模块 + 多视角 FFN,实现特征空间与任务空间的联合缩放,在快手主站 5% 流量 A/B 上 App Stay Time 提升 +0.101%、Watch Time +1.113%,同时通过用户-物品解耦让在线推理 QPS 提升 48%。
1. 背景与动机
工业推荐排序模型一直被"三驾马车"切成互相独立的模块:
-
行为建模(Behavior Modeling):DIN / DIEN / SIM / TWIN / C-Former,从终身行为序列里抽用户兴趣。
-
特征交互(Feature Interaction):DeepFM / DCN / EENet / RankMixer,做高阶交叉。
-
任务建模(Task Modeling):MMoE / PLE / HoME / SMES,处理多任务 seesaw。
LLM 时代告诉我们"模型 scaling"能带来质变,工业界也开始试着把上面某一块做大。但作者指出,这些工作大多是 Component-centric Scaling(组件级缩放),即只把三块里的某一块加大参数:
-
Figure 1 (a)-©:LONGER 只 scale 序列,HHFT/RankMixer 只 scale 特征交互,SMES 只 scale 任务专家。
-
Figure 1 (d)-(e):OneTrans / HyFormer / MixFormer 迈出一小步,做了 Feature-space 内部的跨模块 co-scaling,但依然把任务建模晾在一边。
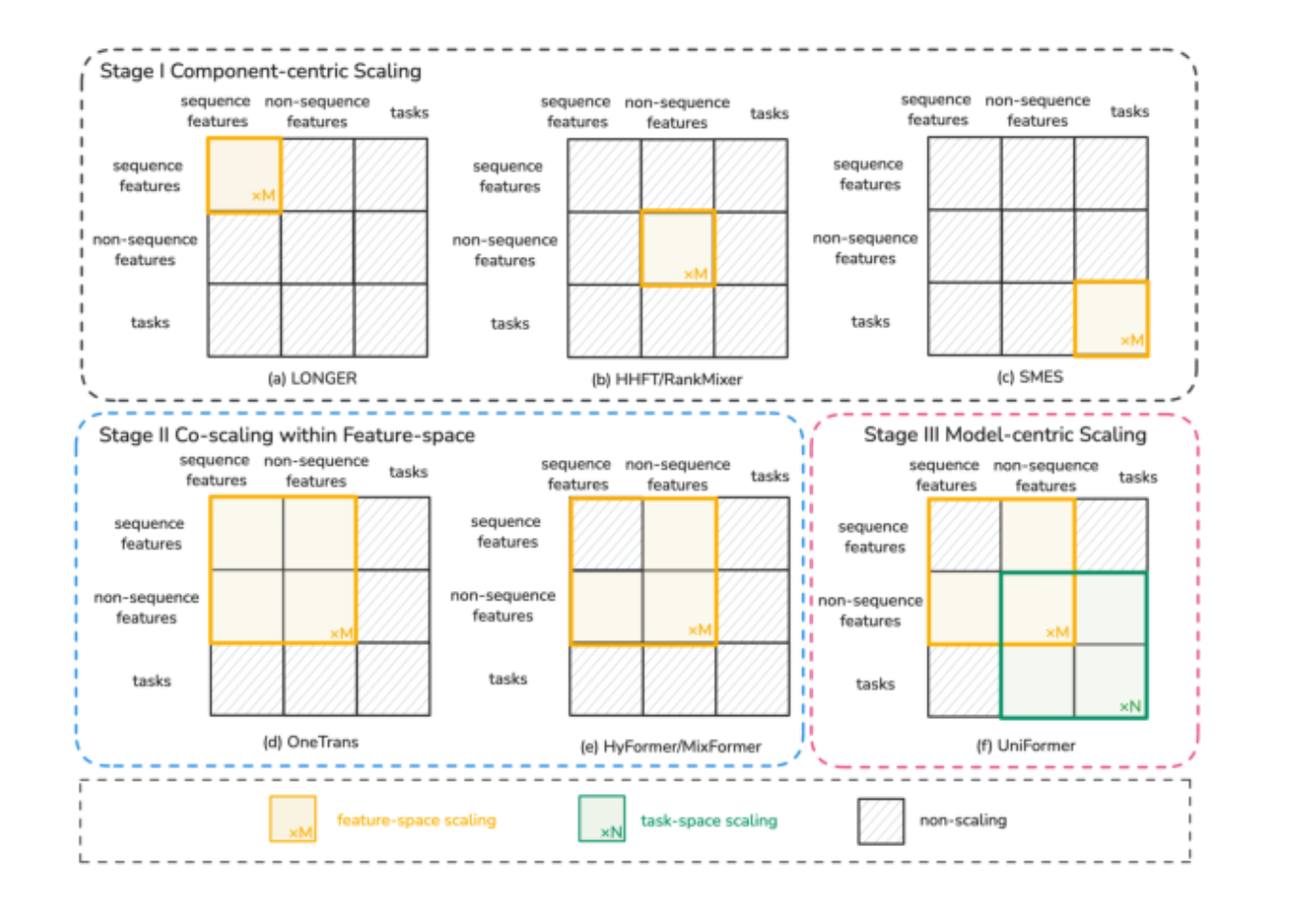
作者要做的是 Figure 1 (f) ------ Model-centric Scaling(模型级缩放):让"序列 + 非序列特征 + 任务"三个空间在同一个统一框架里被一起 scale。为了这件事,他们提出三条硬约束:
-
高训练 / 推理效率:候选一次数百到上千,工业延迟不允许硬堆参数。
-
异构行为 & 短长期兴趣兼顾:避免"偏好塌陷"(preference collapse)。
-
灵活可扩展的参数分配:不能所有参数都集中到单个模块里。
一句话理解:把推荐模型往 Transformer + FFN 这种标准算子上收敛,让"扩容"这件事像 LLM 一样,一个旋钮拧就能起效果。
2. 整体架构
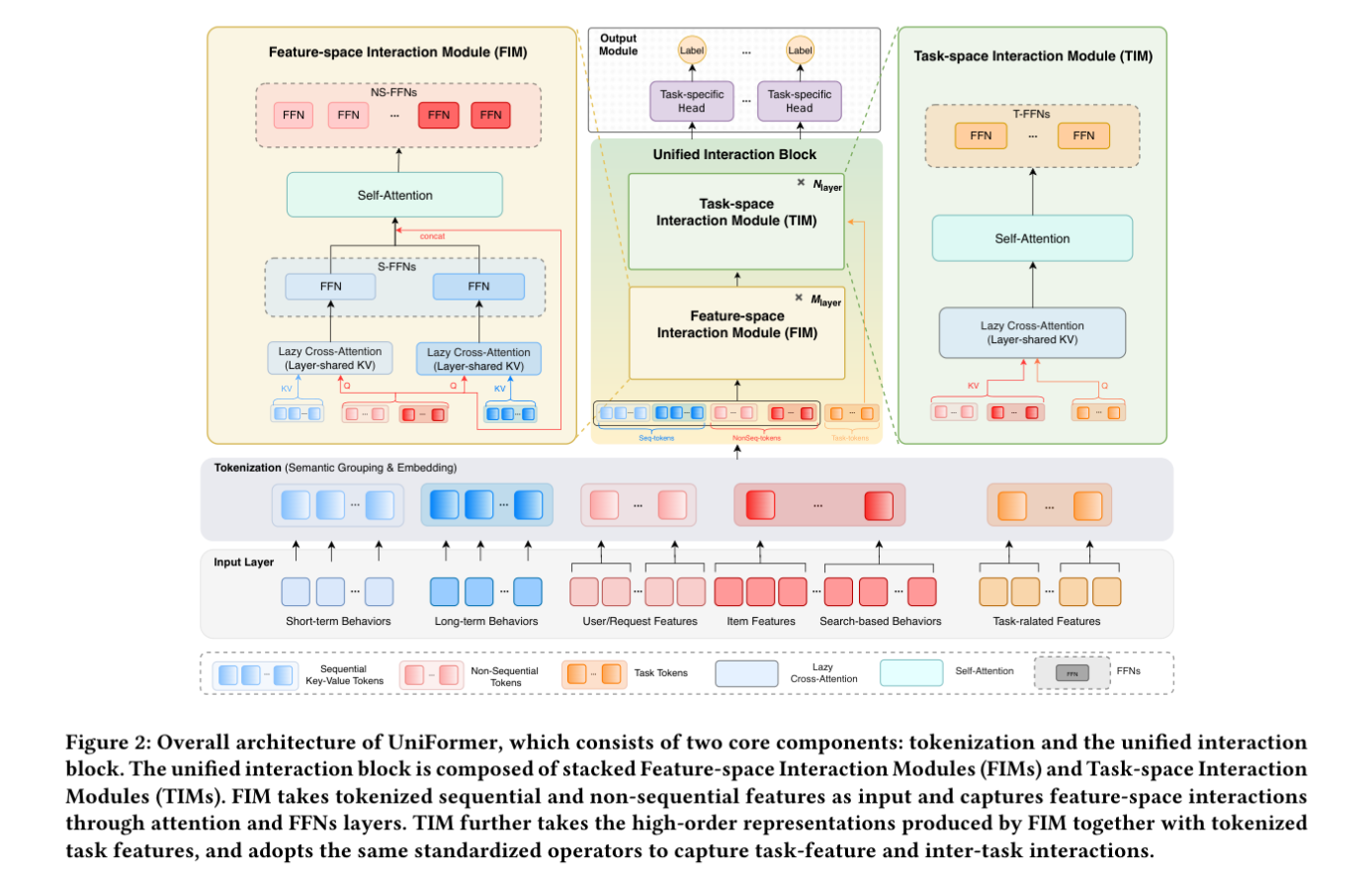
端到端数据流:
-
输入层:短期行为、长期压缩兴趣、用户/请求特征、Item 特征、Search-based 行为、任务特征。
-
Tokenization :按"是否依赖候选 item"分组,走 SwiGLU 投影,产出三类 Token ------ 序列 KV Token、非序列 Token(
N_NS ∈ R^{q×d_model})、任务 Token(N_T ∈ R^{t×d_model})。 -
Unified Interaction Block:
-
FIM(Feature-space Interaction Module)× M 层:Lazy Cross-Attention 从序列取信息 + Self-Attention 做高阶特征交互,两组 FFN(S-FFNs / NS-FFNs)分开建模序列与非序列。
-
TIM(Task-space Interaction Module)× N 层:Lazy Cross-Attention 让任务 Token 查询 FIM 输出,Self-Attention 做任务间关系,T-FFNs 做任务专属 FFN。
-
-
Output Module:每个任务一个 FFN Head + Sigmoid,多任务 BCE 加权求和。
关键工程决策 :所有 Cross-Attention 都走 "Lazy" 模式(
S_kv=1, L_kv=1),全部层共享一份 KV,同时省显存又省算力;Self-Attention 只在非序列 Token 之间做,避免整块特征空间上跑 O(seq²) 的自注意力。
3. 逐模块方案拆解
3.1 Tokenization:按"item 依赖性"做语义分组
3.1.1 Sequential Features(序列侧)
按对目标 item 的依赖性划分两类:
-
Item-independent :短期浏览序列、长期压缩兴趣(C-Former)。保留原始序列结构,逐元素拼接 side info:
e^short_i = [e^pid_i ‖ e^tag_i ‖ e^paid_i ‖ e^duration_i ‖ ...]。 -
Item-dependent :Search-based 序列(SIM)。做聚合而非保留原序,为的是让下游 Cross-Attention 的 KV 不依赖候选 item(后面 4.3 会讲这是在线加速的关键)。
序列 Token 走 SwiGLU 投影到统一空间 z_i ∈ R^{d_seq}:
d s e q = S k v ⋅ L k v ⋅ d m o d e l , d m o d e l = G k v ⋅ d h e a d d_{seq} = S_{kv} \cdot L_{kv} \cdot d_{model}, \qquad d_{model} = G_{kv} \cdot d_{head} dseq=Skv⋅Lkv⋅dmodel,dmodel=Gkv⋅dhead
变量说明:
-
S_kv:Key-Value 拆分系数。S_kv=1表示 K 和 V 共享,S_kv=2表示 K、V 分开。 -
L_kv:跨层共享的 KV 层数(默认L_kv=1,所有层共用一份 KV,这就是 "Lazy" 的核心)。 -
d_model:模型隐藏维度,d_head是单头维度,G_kv是注意力头数。
投影后转成 layer-specific KV 对 [C^0_i, C^1_i, ..., C^{S_kv·L_kv−1}_i],第 l 层做 RMSNorm:
k i ( l ) = R M S N o r m k , l ( C i S k v ⋅ l ) \mathbf{k}^{(l)}i = \mathrm{RMSNorm}{k,l}(\mathbf{C}^{S_{kv}\cdot l}_i) ki(l)=RMSNormk,l(CiSkv⋅l)
v i ( l ) = { k i ( l ) , if S k v = 1 (shared KV) R M S N o r m v , l ( C i S k v ⋅ l + 1 ) , if S k v = 2 (separated KV) \mathbf{v}^{(l)}i = \begin{cases} \mathbf{k}^{(l)}i, & \text{if } S{kv}=1 \text{ (shared KV)} \\ \mathrm{RMSNorm}{v,l}(\mathbf{C}^{S_{kv}\cdot l+1}i), & \text{if } S{kv}=2 \text{ (separated KV)} \end{cases} vi(l)={ki(l),RMSNormv,l(CiSkv⋅l+1),if Skv=1 (shared KV)if Skv=2 (separated KV)
短期序列产出 (K_short, V_short),长期序列产出 (K_long, V_long)。
对 SIM 类 item-dependent 行为,用 Target Attention Tokenizer 直接压成一个 token:
e s e a r c h = T A ( e t a r g e t , K s e a r c h , V s e a r c h ) \mathbf{e}{search} = \mathrm{TA}(\mathbf{e}{target}, \mathbf{K}{search}, \mathbf{V}{search}) esearch=TA(etarget,Ksearch,Vsearch)
变量说明:
-
e_target:目标候选 item 的 embedding,作为 attention 的 query。 -
(K_search, V_search):Search-based 序列的 KV 表征。 -
e_search:聚合后的单一 token,作为一个"item-independent-like feature"进入下游。
3.1.2 Non-sequential Features(非序列侧)
同样按依赖性分两组:
-
Item-independent features:user ID、user profile、上下文请求特征。
-
Item-dependent features:item ID、item 统计、user-item 交叉特征。
组内按语义再细分,得到 m 个 item-independent group + n 个 item-dependent group。每组 embedding concat 后过 SwiGLU 投影到统一空间:
- 输出:
N_NS ∈ R^{q × d_model},其中q = m + n。
为什么要"语义分组"而不是"全局 Token"? 一是把 user-request 侧和 item 侧分开,request-only 部分可以按请求算一次、512 个候选共享;二是不同语义组给下游 Cross-Attention 提供多视角 Query,有效缓解 "Attention Homogenization"(后面 Fig.5 会看到证据)。
3.1.3 Task Features
每个任务的 task-specific 特征(task ID、bias 特征)拼一起,SwiGLU 投影后得到 N_T ∈ R^{t × d_model},t 是任务数。
3.2 Feature-space Interaction Module(FIM)
FIM 做的是"特征空间里的高阶交互",两个子模块层层堆 M 层。
3.2.1 Sequential-oriented Interaction:多序列 Cross-Attention
作者刻意用 多序列并行 Cross-Attention 而不是把短/长序列 concat 起来共享一个 CA,目的是防止 preference collapse(只关注某一类行为)。
以短期序列为例,第 l 层:
H s h o r t f e a t , ( l ) = C A ( R M S N o r m ( Q c r o s s f e a t , ( l − 1 ) ) , K s h o r t ( l ) , V s h o r t ( l ) ) + Q c r o s s f e a t , ( l − 1 ) \mathbf{H}^{feat,(l)}{short} = \mathrm{CA}\Big(\mathrm{RMSNorm}(\mathbf{Q}^{feat,(l-1)}{cross}), \mathbf{K}^{(l)}{short}, \mathbf{V}^{(l)}{short}\Big) + \mathbf{Q}^{feat,(l-1)}_{cross} Hshortfeat,(l)=CA(RMSNorm(Qcrossfeat,(l−1)),Kshort(l),Vshort(l))+Qcrossfeat,(l−1)
变量说明:
-
Q^{feat,(l-1)}_{cross} ∈ R^{q × d_model}:上一层 FIM cross 分支的输出 query(第 0 层用N_NS)。 -
K^{(l)}_short, V^{(l)}_short:短期序列在第l层的 KV,默认S_kv=1, L_kv=1,即所有层共用一份(Lazy Design)。 -
H^{feat,(l)}_short ∈ R^{q × d_model}:短期序列在第l层的输出。
紧接一个短期专属 S-FFN + 残差:
H ~ s h o r t f e a t , ( l ) = F F N s h o r t f e a t , ( l ) ( H s h o r t f e a t , ( l ) ) + H s h o r t f e a t , ( l ) \tilde{\mathbf{H}}^{feat,(l)}{short} = \mathrm{FFN}^{feat,(l)}{short}\Big(\mathbf{H}^{feat,(l)}{short}\Big) + \mathbf{H}^{feat,(l)}{short} H~shortfeat,(l)=FFNshortfeat,(l)(Hshortfeat,(l))+Hshortfeat,(l)
长期序列同构,产出 H̃^{feat,(l)}_long。
两种融合策略:
-
Global adaptive fusion :学一个全局系数
α:H^{feat,(l)}_cross = α · H̃^{feat,(l)}_short + (1 − α) · H̃^{feat,(l)}_long,α ∈ [0,1]可学习。 -
Personalized adaptive fusion :按用户特征(活跃度、行为量等)学个体化
α_i,用来适配高活/冷启用户在长短期偏好上的差异。
3.2.2 Non-Sequential-oriented Interaction:Self-Attention + NS-FFN
Cross 分支的输出偏"序列味"重,作者用 Interaction Enhancement:把 cross 分支输出跟上一层 self 分支的 query 拼起来一起过 Self-Attention。
拼接:X^{feat,(l)} = [H^{feat,(l)}_cross ‖ Q^{feat,(l-1)}_self],其中 Q^{feat,(0)}_self = Q^{feat,(0)}_cross = N_NS。
Self-Attention + 残差:
H s e l f f e a t , ( l ) = S A ( R M S N o r m ( X f e a t , ( l ) ) ) + X f e a t , ( l ) \mathbf{H}^{feat,(l)}_{self} = \mathrm{SA}\Big(\mathrm{RMSNorm}(\mathbf{X}^{feat,(l)})\Big) + \mathbf{X}^{feat,(l)} Hselffeat,(l)=SA(RMSNorm(Xfeat,(l)))+Xfeat,(l)
变量说明: H^{feat,(l)}_self ∈ R^{2q × d_model}。因为拼了两路,token 数从 q 变成 2q。
然后对每个 slice h^{feat,(l)}_i, i ∈ {0,...,2q-1} 用一个"专属"NS-FFN:
f i f e a t , ( l ) = F F N i f e a t , ( l ) ( h i f e a t , ( l ) ) + h i f e a t , ( l ) \mathbf{f}^{feat,(l)}_i = \mathrm{FFN}^{feat,(l)}_i\Big(\mathbf{h}^{feat,(l)}_i\Big) + \mathbf{h}^{feat,(l)}_i fifeat,(l)=FFNifeat,(l)(hifeat,(l))+hifeat,(l)
得到 F^{feat,(l)} ∈ R^{2q × d_model}。
层间路由: 把 F^{feat,(l)} 按维度 split 成两条:
F f e a t , ( l ) = Q c r o s s f e a t , ( l + 1 ) : Q s e l f f e a t , ( l + 1 ) \mathbf{F}^{feat,(l)} = \big\\mathbf{Q}\^{feat,(l+1)}_{cross} : \\mathbf{Q}\^{feat,(l+1)}_{self}\\big Ffeat,(l)=Qcrossfeat,(l+1):Qselffeat,(l+1)
-
Q^{feat,(l+1)}_cross ∈ R^{2q·β^{(l)} × d_model}送到下一层 Cross-Attention。 -
Q^{feat,(l+1)}_self ∈ R^{2q(1−β^{(l)}) × d_model}送到下一层 Self-Attention。 -
默认
β^{(l)} = 0.5;也可以做金字塔式设计,一层一层减小β^{(l)}让 Cross 支路变轻,进一步加速。
3.3 Task-space Interaction Module(TIM)
FIM 出来的 F^{feat,(M)} 是充分交互过的高阶特征表征,TIM 负责把这些表征跟"任务"耦合。堆叠 N 层,同样两个子模块。
3.3.1 Feature-oriented Interaction:Task 查 Feature
第 l 层用 task query 去查 FIM 输出:
H c r o s s t a s k , ( l ) = C A ( R M S N o r m ( Q c r o s s t a s k , ( l − 1 ) ) , K f e a t ( l ) , V f e a t ( l ) ) + Q c r o s s t a s k , ( l − 1 ) \mathbf{H}^{task,(l)}{cross} = \mathrm{CA}\Big(\mathrm{RMSNorm}(\mathbf{Q}^{task,(l-1)}{cross}), \mathbf{K}^{(l)}{feat}, \mathbf{V}^{(l)}{feat}\Big) + \mathbf{Q}^{task,(l-1)}_{cross} Hcrosstask,(l)=CA(RMSNorm(Qcrosstask,(l−1)),Kfeat(l),Vfeat(l))+Qcrosstask,(l−1)
变量说明:
-
Q^{task,(l-1)}_cross ∈ R^{t × d_model}:任务 query,第 0 层为N_T。 -
(K^{(1)}_feat, V^{(1)}_feat) = F^{feat,(M)}:所有 TIM 层共享同一份 FIM 输出作 KV(Lazy 又一次上线)。 -
语义等价:这就是一个可学习的、跨任务的"加权池化" ------ 类似 MMoE 里 gate 从 shared expert 出结果的过程。
3.3.2 Task-oriented Interaction:任务间 Self-Attention + T-FFN
H s e l f t a s k , ( l ) = S A ( R M S N o r m ( H c r o s s t a s k , ( l ) ) ) + H c r o s s t a s k , ( l ) \mathbf{H}^{task,(l)}{self} = \mathrm{SA}\Big(\mathrm{RMSNorm}(\mathbf{H}^{task,(l)}{cross})\Big) + \mathbf{H}^{task,(l)}_{cross} Hselftask,(l)=SA(RMSNorm(Hcrosstask,(l)))+Hcrosstask,(l)
f i t a s k , ( l ) = F F N i t a s k , ( l ) ( h i t a s k , ( l ) ) + h i t a s k , ( l ) \mathbf{f}^{task,(l)}_i = \mathrm{FFN}^{task,(l)}_i\Big(\mathbf{h}^{task,(l)}_i\Big) + \mathbf{h}^{task,(l)}_i fitask,(l)=FFNitask,(l)(hitask,(l))+hitask,(l)
变量说明: h^{task,(l)}_i, i ∈ {0,...,t-1} 是 H^{task,(l)}_self 沿 task 轴切下来的 slice;每个任务用自己的 T-FFN。输出 F^{task,(l)} ∈ R^{t × d_model},直接作为下一层的 Q^{task,(l+1)}_cross。
3.3.3 Output Module
最后一层 F^{task,(N)} 逐任务过 Head + Sigmoid:
y ^ i = σ ( F F N i ( f i t a s k , ( N ) ) ) \hat{y}_i = \sigma\Big(\mathrm{FFN}_i(\mathbf{f}^{task,(N)}_i)\Big) y^i=σ(FFNi(fitask,(N)))
4. 训练目标
多任务加权 BCE:
L = ∑ i = 1 t λ i L i ( y i , y ^ i ) \mathcal{L} = \sum_{i=1}^{t} \lambda_i \mathcal{L}_i(y_i, \hat{y}_i) L=i=1∑tλiLi(yi,y^i)
变量说明:
-
y_i:第i个任务的 ground truth(如 Effective-view / Long-view / Like / Follow 的二分类标签)。 -
ŷ_i:模型预估。 -
L_i:任务专属损失,通常是 BCE。 -
λ_i:任务权重,工业实践中按任务重要性 / 数据量调。
5. 训练与部署优化
5.1 训练侧
User-level Common Compression。 同一次请求里 512/1024 个候选共享同一份用户行为序列,直接拼 batch 会把用户特征重复处理很多遍。作者对 user-side 特征做"去重"存储 + 索引映射,只算一次、多次复用。
设一个 batch 有 B 个样本 / U 个 unique user,k̄ = B/U,用户侧代价 C_com、样本侧代价 C_sample,理论 speedup:
B ( C c o m + C s a m p l e ) U ⋅ C c o m + B ⋅ C s a m p l e = C c o m + C s a m p l e C s a m p l e + C c o m / k ˉ \frac{B(C_{com}+C_{sample})}{U \cdot C_{com} + B \cdot C_{sample}} = \frac{C_{com}+C_{sample}}{C_{sample}+C_{com}/\bar{k}} U⋅Ccom+B⋅CsampleB(Ccom+Csample)=Csample+Ccom/kˉCcom+Csample
Variable-length FlashAttention。 用户行为序列天生不等长,传统 padded Cross-Attention 复杂度 O(B q L_max d),变长版本降到 O(q Σ_i L_i d),再叠 FlashAttention 的 IO-aware tiling,进一步省显存带宽。
BF16 混合精度。 显存 & 吞吐双收益,精度对推荐任务够用。
5.2 推理侧:User-Item 解耦
工业排序一次要给 I = 512 or 1024 个候选打分。UniFormer 的 Tokenization 已经把非序列特征切成 m 个 item-independent token + n 个 item-dependent token,而 item-dependent 行为(SIM)也在 3.1.1 里被聚合成 item-independent 表征,因此所有 Cross-Attention 的 KV 完全独立于候选 item。
-
Cross-Attention 和 FFN 天然按 token 独立,可以按"用户 token" / "item token"拆开算。
-
唯一麻烦的是 Self-Attention 会跨 token 交互,作者用 Attention Mask 强制屏蔽 "user query → item key" 的注意力方向,从而让 user 侧计算按请求算一次、512 个 item 共享。
在线实测:QPS +48%,GAUC 掉得可忽略。
6. 实验分析
6.1 离线主实验
数据集:快手单页短视频推荐场景,DAU 4 亿 +,日交互 500 亿 +,四个任务 Effective-view / Long-view / Like / Follow,指标 GAUC(0.05% 就算显著)。
结果(表格转自论文 Table 1):
| 模型 | Effective-view GAUC | Impr. | Long-view GAUC | Impr. | Like GAUC | Impr. | Follow GAUC | Impr. | #Params |
|---|---|---|---|---|---|---|---|---|---|
| SIM+DCN | 0.7418 | - | 0.7734 | - | 0.8486 | - | 0.8361 | - | 115.8M |
| SIM+HoME | 0.7424 | +0.08% | 0.7740 | +0.08% | 0.8494 | +0.09% | 0.8374 | +0.16% | 114.8M |
| SIM+RankMixer | 0.7443 | +0.34% | 0.7757 | +0.30% | 0.8507 | +0.25% | 0.8374 | +0.16% | 492.0M |
| HyFormer | 0.7447 | +0.39% | 0.7762 | +0.36% | 0.8512 | +0.31% | 0.8381 | +0.24% | 496.5M |
| MixFormer | 0.7450 | +0.43% | 0.7764 | +0.39% | 0.8514 | +0.33% | 0.8388 | +0.32% | 489.4M |
| UniFormer | 0.7457 | +0.53% | 0.7771 | +0.48% | 0.8531 | +0.53% | 0.8435 | +0.89% | 516.0M |
| UniFormer-Large | 0.7465 | +0.63% | 0.7779 | +0.58% | 0.8538 | +0.61% | 0.8448 | +1.04% | 995.3M |
关键观察:
-
Component-centric → Cross-module co-scaling → Model-centric,三阶段依次提升。 RankMixer 相比 DCN 涨 0.34%,MixFormer / HyFormer 再往上涨 0.050.10%,UniFormer 相比 MixFormer 又涨 0.050.57%。Follow 任务(互动型)涨得最猛,+0.89%~+1.04%,说明把任务空间纳入统一 scaling 对 Follow 这种稀疏正向反馈价值最大。
-
UniFormer-Large(995M)继续单调涨点,说明这套架构真的有 scaling law,而不是"到某个体积就饱和"。
6.2 消融实验
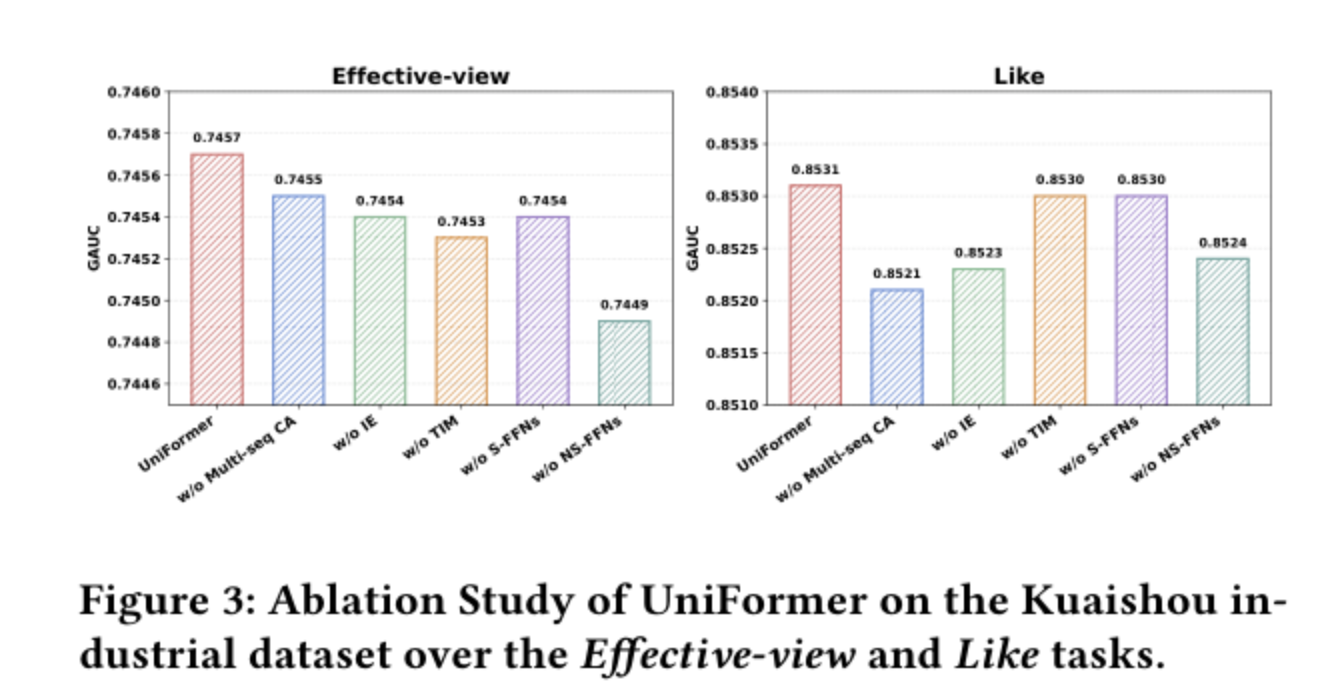
结论(红色 UniFormer 为满配基线):
-
w/o Multi-seq CA(换成共享 Cross-Attention 处理拼接后的长短期序列):Like 掉 0.10%,最严重的 drop,验证 preference collapse 的存在。
-
w/o IE (去掉 Interaction Enhancement,即
X^{feat,(l)} = H^{feat,(l)}_cross):Effective-view 掉 0.03%,说明拼上 self 分支的 query 确实提供了额外信息。 -
w/o TIM:Effective-view 掉 0.04%,Like 影响相对小 ------ 任务空间建模对 duration 类任务收益更明显。
-
w/o S-FFNs / w/o NS-FFNs (把多视角 FFN 退化成共享单个 FFN):下降幅度最大。NS-FFNs 单独换共享后 Effective-view 跌 0.08%、Like 跌 0.07%,说明"每个语义组一个专属 FFN"这件事是灵活参数分配的核心承重墙。
6.3 Scaling Law
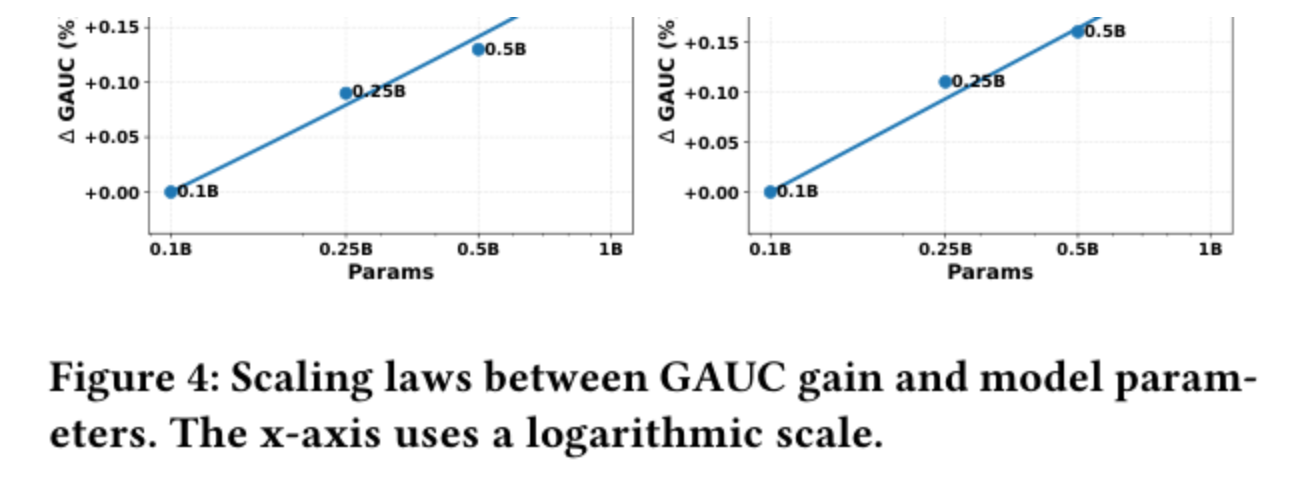
作者把多视角 FFN 的隐层维度从 0.1B 一路拉到 1B,GAUC 沿 log(Params) 近似线性增长,没出现传统 component-centric scaling 里常见的"diminishing returns"(快速饱和)。说明 model-centric 的均衡扩容方式确实把模型的容量利用率拉高了。
6.4 可视化分析
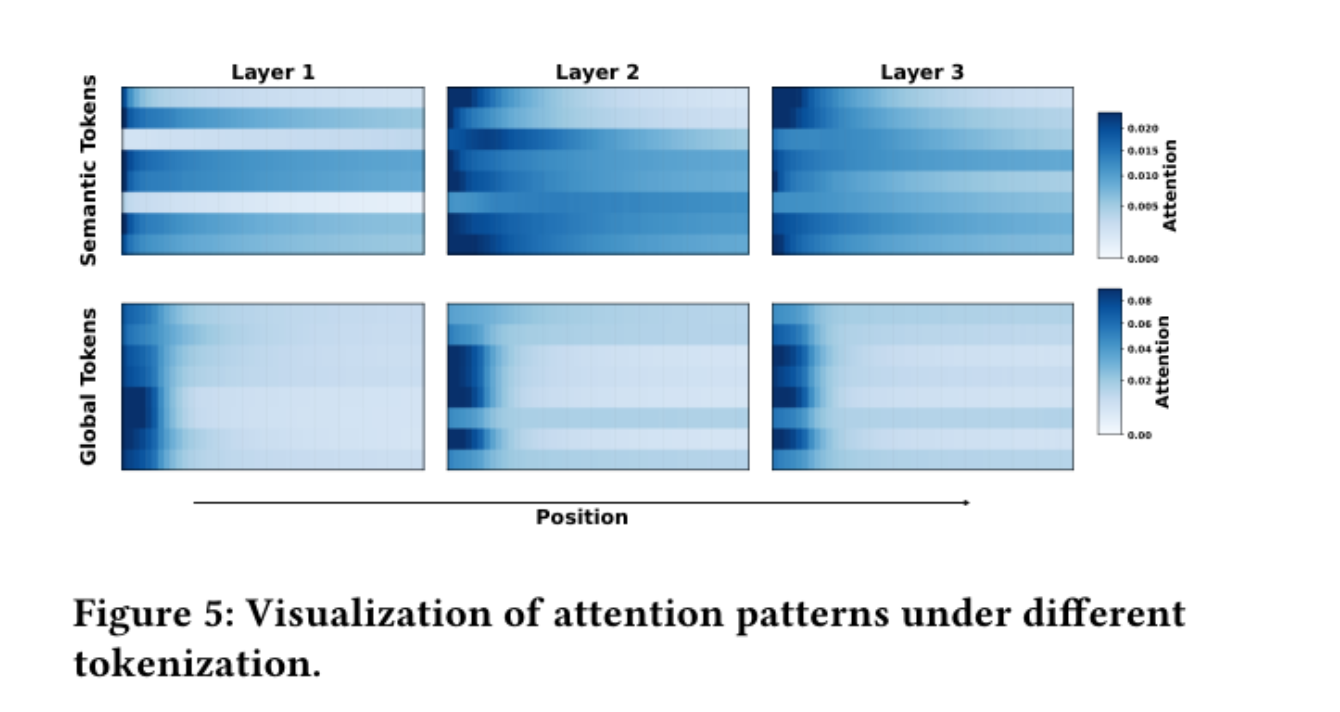
Figure 5: 语义 Token(上排)在 3 层 Cross-Attention 里注意力分布有明显的层间差异,模型在不同层关注不同的行为 pattern;Global Token(下排)三层几乎一样,attention 老盯着相同位置 ------ 这就是"Attention Homogenization"的证据,语义分组是解药。
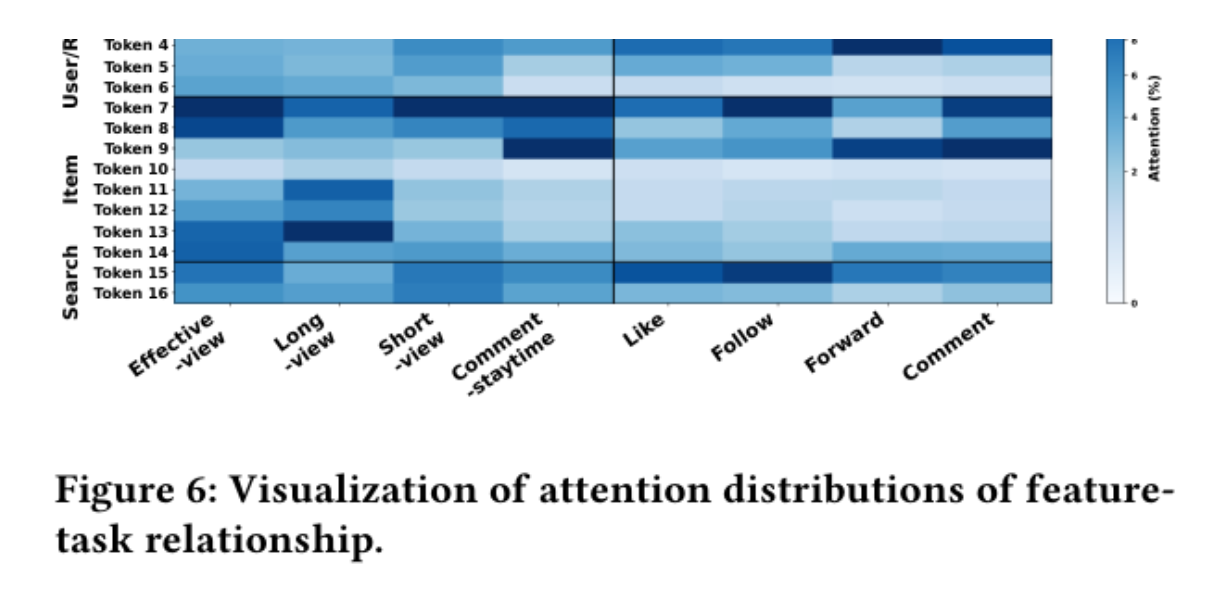
Figure 6: TIM 里不同任务对 16 个 Feature Token 的注意力权重热力图。
-
一些 Token(item 基础特征、search 行为)无论哪个任务都被高度关注 ------ 通用信息。
-
Item 统计特征(Token 11-14)在 Duration 类任务(Effective-view / Long-view / Short-view / Comment-staytime)上权重更高。
-
用户侧特征(Token 1-4)在 Interaction 类任务(Like / Follow / Forward / Comment)上权重更高。
-
高相关任务的 attention pattern 长得几乎一样:例如 Comment Staytime 和 Comment 的分布高度对齐 ------ 表明 TIM 用同一套注意力就把任务间关系隐式学出来了。
6.5 在线 A/B
快手主 APP + 极速版,5% 流量灌 7 天,主 APP 与极速版结果分别汇报:
| 类别 | 指标 | Kuaishou Lite | Kuaishou 主 APP |
|---|---|---|---|
| Engagement(时长) | App Stay Time | +0.260% | +0.101% |
| Watch Time | +1.113% | +0.729% | |
| Video View | +0.252% | +0.249% | |
| Interaction(互动) | Like | +1.089% | +0.155% |
| Comment | +1.818% | +1.488% | |
| Collect | +0.930% | +0.647% | |
| Forward | +1.274% | +0.157% |
推理侧:借助 User-Item 解耦,推理 QPS 相比未解耦版本 +48%,GAUC 掉得可忽略。
7. 优势与局限
7.1 优势
-
范式层面:第一次把"特征空间 + 任务空间"塞进同一个 Transformer 式 co-scaling 框架,把工业推荐里三块拼图彻底拧成一个可微调容量分配的整体。
-
架构层面:算子极度标准化(Attention + FFN + RMSNorm + SwiGLU),既方便向 LLM 那套训练/推理基建对齐,也让 scaling law 变得可预测。
-
效率层面:Lazy KV 共享 + 多序列 Cross-Attention + Attention Mask 让 user 侧计算按请求算一次,工业落地里省下的是真金白银 ------ +48% QPS 且效果几乎无损。
-
异构行为处理 :Multi-seq CA + 个体化融合系数
α_i,天然把高活/冷启用户区分开来,避免长短期兴趣被塌陷成一块。
7.2 局限
-
强依赖大规模日志数据:所有实验都在快手日 500 亿 + 交互样本量上跑,中小场景不一定能复现 model-centric scaling 的整齐 scaling law。
-
多视角 FFN 参数占比大:主要参数集中在 S-FFN / NS-FFN / T-FFN,虽然带来灵活分配,但也意味着"哪个空间给多少参数"依赖大量经验或搜索;论文没给参数分配的自动化方案。
-
任务 Token 数量偏小 :
t(任务数)通常只有 4~8,TIM 里的 Self-Attention 更多是象征性的,任务规模再涨(比如百个精细目标)时的行为没有验证。 -
序列长度上限:Cross-Attention 虽然靠 variable-length FlashAttention 做了优化,但依然是 O(qL) 复杂度;如果序列继续拉长到 10k+(相当于 LONGER / GEMs 级别),效率对比 sliding-window / 稀疏化路线的优势会削弱。
-
公开细节不足 :论文没披露 M / N(FIM / TIM 层数)、
q/t的具体设置,也没给 ablation 里的参数量对齐口径,复现难度偏高。