RAG 实战:从零搭建语义搜索系统,彻底告别关键词匹配的尴尬
当用户问"马铃薯怎么做"时,如何让他搜到"酸辣土豆丝的做法"?传统
LIKE '%土豆%'只能望洋兴叹,而 RAG(检索增强生成)结合向量嵌入(Embedding),能精准捕捉语义,让搜索真正"懂你"。
一、RAG 是什么?为什么它让搜索脱胎换骨
RAG 全称 Retrieval-Augmented Generation,即检索增强生成。它由三个核心环节构成:
- Retrieval(检索):从知识库中快速找到与问题最相关的文档片段。
- Augment(增强):将检索到的内容作为上下文,与原始问题拼接成更丰富的提示词。
- Generate(生成):交给大语言模型(LLM)生成最终答案,既保证准确性,又避免"胡言乱语"。
传统搜索(如数据库 LIKE 或 Elasticsearch 分词匹配)依赖字面重合 ,例如搜索"马铃薯"搜不到"土豆",因为二者字符不同。但语义上它们完全等价。RAG 通过向量化将文本映射到高维语义空间,相似含义的文本距离更近,从而解决"词不达意"的难题。
二、自然语言搜索的痛点与向量化方案
假设我们有一个 posts.json 文件,记录了许多文章标题和分类:
json
[
{"title": "酸辣土豆丝的家常做法", "category": "美食"},
{"title": "马铃薯种植技术指南", "category": "农业"},
{"title": "Vue 3 响应式原理详解", "category": "前端"}
]用户提问:"马铃薯怎么做?"
- 传统做法 :用正则或
LIKE '%马铃薯%'只能命中"马铃薯种植技术指南",但"酸辣土豆丝"却漏掉了------因为"土豆"≠"马铃薯"。 - 语义搜索 :将问题和所有文档都转为 Embedding(向量),计算余弦相似度,发现"马铃薯"与"土豆"在语义空间距离极近,从而返回"酸辣土豆丝"作为首位结果。
这就是嵌入(Embedding)的魔力------它将文字变换为富含语义的数字向量,让计算机能"理解"词语背后的含义。
三、生成 Embedding:从文本到向量的魔法
我们使用阿里云 DashScope 提供的 text-embedding-v4 模型(兼容 OpenAI SDK)。以下是一个最简单的调用示例(index.mjs):
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DASHSCOPE_API_KEY,
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1'
});
const response = await client.embeddings.create({
model: 'text-embedding-v4',
input: '张三同学大三哦'
});
console.log(response.data[0].embedding); // 输出一个浮点数数组(向量)- 环境变量 :通过
dotenv加载 API Key,安全隔离敏感信息。 - 客户端:使用 OpenAI 兼容接口,方便切换不同提供商。
- 输出 :
embedding是一个长度固定的向量(如 1536 维),它是对输入文本的语义压缩表示。
💡 思考:为什么向量维数固定?因为模型需要统一输出维度,以便进行相似度计算。不同文本的向量长度一致,才能做点积或余弦运算。
四、批量处理:为整个知识库生成向量并持久化
生产环境中,我们不能每次搜索都重新计算所有文档的向量(成本高、延迟大)。正确做法是离线预计算 ,将向量与原始数据一同存储。creat-embedding.mjs 做了这件事:
javascript
// posts.json 向量化
// - node 内置 fs 模块读取文件
// - JSON.parse() 每一项调用 embedding 接口,加到数组
// - 写入新文件,长期存储
import fs from 'fs/promises'; // 支持 Promise 的 fs 模块
import { client } from './app.service.mjs';
const inputFilePath = './data/posts.json';
const outputFilePath = './data/posts-embedding.json';
const data = await fs.readFile(inputFilePath, 'utf-8');
const posts = JSON.parse(data);
// 控制请求频率,避免触发限流
const sleep = (ms) => new Promise(resolve => setTimeout(resolve, ms));
const postsWithEmbedding = [];
for (const { title, category } of posts) {
console.log(title, category, 'embedding');
const response = await client.embeddings.create({
model: 'text-embedding-v4',
// 将标题和分类拼接,提供更完整的上下文,提升向量质量
input: `标题:${title},分类:${category}`
});
postsWithEmbedding.push({
title,
category,
embedding: response.data[0].embedding
});
await sleep(200); // 间隔 200ms,避免 API 限流
}
await fs.writeFile(
outputFilePath,
JSON.stringify(postsWithEmbedding, null, 2)
);要点解析:
fs/promises:Node 原生支持异步读写,避免回调地狱,使代码更清晰。- 循环 + 延迟 :因为 API 有 QPS 限制,我们手动
sleep(200)控制速率,这是工程上必要的自我保护。 - 输入构造 :将
标题和分类拼接,让 Embedding 模型更清楚文本的领域,从而得到更准确的向量表示。 - 持久化 :写入
posts-embedding.json,后续搜索直接读取,无需重复调用 API。
五、语义搜索核心:余弦相似度与命令行交互
有了所有文档的向量,搜索时只需将用户问题也转为向量,然后计算它与每个文档向量的余弦相似度 ,取 Top K 返回。semantic-search.mjs 完整实现了这一流程:
javascript
// RAG 实现语义搜索
import fs from 'fs/promises';
import { client } from './app.service.mjs';
import readline from 'readline'; // 读取用户输入
const inputFilePath = './data/posts-embedding.json';
const data = await fs.readFile(inputFilePath, 'utf-8');
const posts = JSON.parse(data);
// 余弦相似度计算函数
const cosineSimilarity = (v1, v2) => {
// 点积:对应元素相乘后累加
const dotProduct = v1.reduce((acc, curr, i) => acc + curr * v2[i], 0);
// 向量模长(L2范数)
const lengthV1 = Math.sqrt(v1.reduce((acc, curr) => acc + curr * curr, 0));
const lengthV2 = Math.sqrt(v2.reduce((acc, curr) => acc + curr * curr, 0));
// 余弦值 = 点积 / (模长乘积)
return dotProduct / (lengthV1 * lengthV2);
};
// 创建命令行交互界面
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
// 处理用户输入
const handleInput = async (answer) => {
console.log(`您的问题:${answer}`);
// 1. 将问题向量化
const response = await client.embeddings.create({
model: "text-embedding-v4",
input: answer
});
const { embedding } = response.data[0];
// 2. 计算与所有文档的相似度,降序取前3
const result = posts
.map(item => ({
...item,
similarity: cosineSimilarity(embedding, item.embedding)
}))
.sort((a, b) => b.similarity - a.similarity) // 从高到低
.slice(0, 3)
.map((item, index) => `${index + 1}. ${item.title} (${item.category})`)
.join('\n');
console.log(`\n搜索结果:\n${result}`);
// 递归等待下一次输入(模拟持续对话)
rl.question('请输入你要搜索的内容:', handleInput);
};
// 启动对话
rl.question('请输入你要搜索的内容:', handleInput);代码逐层剖析:
- 余弦相似度 :衡量两个向量在方向上的接近程度,范围
[-1, 1],越接近 1 表示越相似。它是语义搜索中最常用的度量,因为 Embedding 向量的模长受文本长度影响,而余弦只关注方向,能有效消除长度干扰。 map+sort+slice:函数式编程风格,清晰表达"计算相似度 → 排序 → 取前三"的流水线。- 递归交互 :
handleInput内部再次调用rl.question,实现连续问答,用户可多次搜索而无需重启程序。 - 实时向量化:每次用户输入都调用 Embedding API,这是在线推理的成本。如果追求更低延迟,可缓存常见问题向量。
六、从检索到生成:RAG 的完整闭环
以上我们实现了 Retrieval 部分。那么如何"增强"和"生成"呢?
拿到相似度最高的几个文档片段后,我们可以将它们拼接成一段上下文,再交给 LLM(如 Qwen、GPT)生成最终回复。例如:
javascript
const context = result.map(item => item.title).join(';');
const prompt = `基于以下信息回答问题:\n${context}\n问题:${answer}`;
const completion = await client.chat.completions.create({
model: 'qwen-max',
messages: [{ role: 'user', content: prompt }]
});
console.log(completion.choices[0].message.content);这样,当用户问"马铃薯怎么做"时,检索到的"酸辣土豆丝"会作为上下文注入,LLM 就能生成一份详细的菜谱------这就是 RAG 的完整威力。
七、流程图:语义搜索全链路
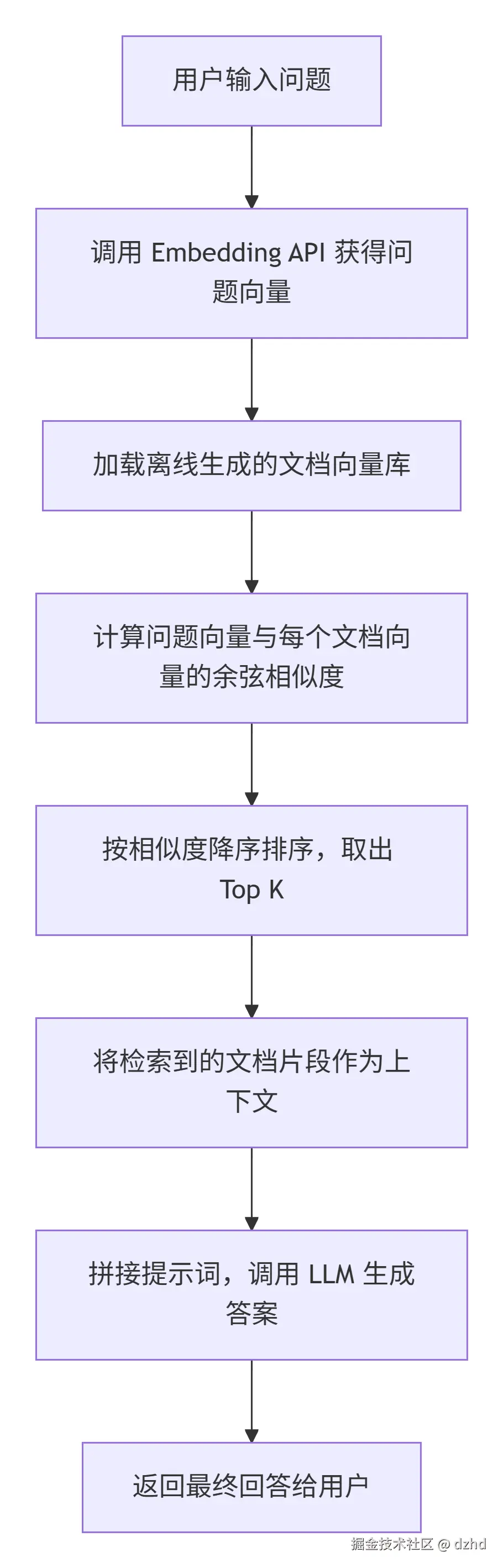
而离线向量化流程如下:
八、深度思考:工程化落地的关键细节
- Embedding 模型选择 :
text-embedding-v4是阿里云最新版,支持多语言,维度 1536,在 MTEB 基准上表现优异。实际选型需权衡精度、维度、推理速度。 - 向量存储:当文档量超过十万级,内存计算余弦相似度不再可行,应引入向量数据库(如 Milvus、Pinecone、Qdrant),它们基于 ANN(近似最近邻)算法,实现毫秒级检索。
- 增量更新:知识库动态变化时,需设计增量 Embedding 机制,避免全量重建。
- 缓存策略:对于高频问题(如"什么是 Vue"),可缓存其向量和搜索结果,大幅降低 API 调用成本。
- 错误处理与重试:网络波动或限流时,代码应加入指数退避重试,提升鲁棒性。
九、总结
通过这篇实战文章,我们从零实现了基于 RAG 的语义搜索系统:
- 理解了 Embedding 如何将文本映射到语义空间,跨越"同义词鸿沟"。
- 实践了 Node.js + 阿里云 DashScope 的向量生成与批量处理。
- 编写了 余弦相似度计算 和 命令行交互 的完整搜索逻辑。
- 展望了 检索 + 增强 + 生成 的全链路实现。
RAG 不仅让搜索更智能,还为 LLM 提供了"外挂知识库",成为企业级 AI 应用的核心范式。掌握这套技术栈,你将能构建出真正理解用户意图的下一代搜索系统。
📌 所有源码已在文中完整呈现,你可以直接复制运行(记得配置
DASHSCOPE_API_KEY)。如有疑问,欢迎在评论区交流探讨!
本文为掘金首发,转载需注明出处。