自连接
自连接(self join)是使用SQL进行高级数据处理时常用的技术,但与通常的连接相比,其处理过程让人很难理解,原因在于人们经常不知道该如何解释针对同一张表的连接条件。
SQL的连接运算根据其特征的不同,有着不同的名称,如内连接、外连接和交叉连接等。一般来说,这些连接大都是以不同的表或视图为对象进行的,但针对相同的表或相同的视图的连接也并没有被禁止。针对相同的表进行的连接被称为"自连接"。一旦熟练掌握自连接技术,我们便能快速地解决很多问题。但是,其处理过程不太容易想象,以至于常常被人们敬而远之。
1、可重排列、排列、组合
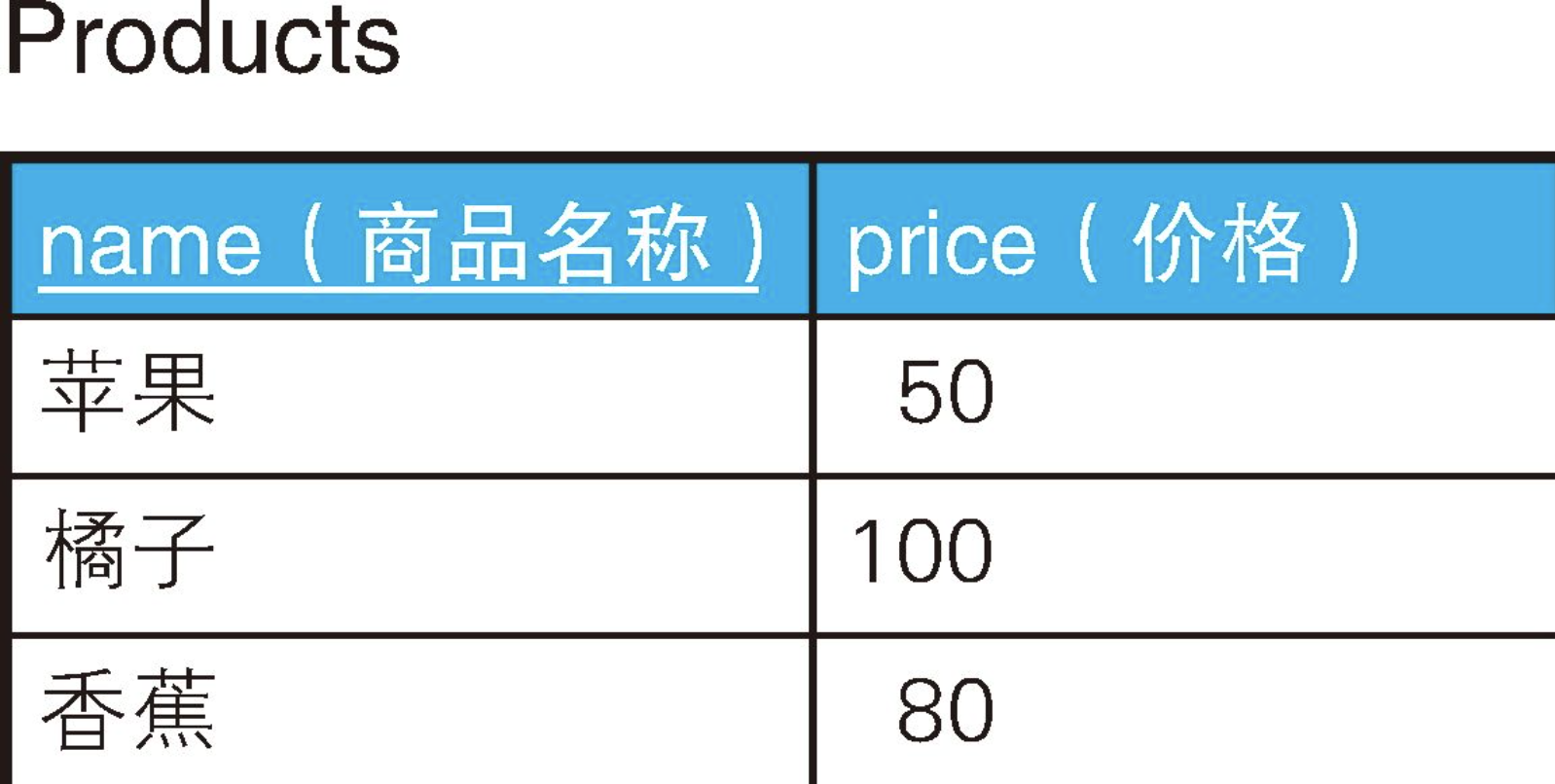
假设这里有一张存放了商品名称及价格的表,表里有"苹果、橘子、香蕉"这3条记录。在生成用于查询销售额的报表等的时候,我们有时会需要获取这些商品的组合。
sql
CREATE TABLE Products (
name VARCHAR(16) PRIMARY KEY,
price INTEGER NOT NULL
);
-- 可重排列、排列、组合
DELETE FROM Products;
INSERT INTO Products VALUES('苹果', 100);
INSERT INTO Products VALUES('橘子', 50);
INSERT INTO Products VALUES('香蕉', 80);这里所说的组合其实分为两种类型。
- 一种是有顺序的有序对(ordered pair)。有序对用尖括号括起来,如
<1, 2>; - 另一种是无顺序的无序对(unorderedpair)。无序对用花括号括起来,如
{1, 2}。
这是数学中常用的记法。在有序对里,如果元素顺序相反,那就是不同的对,因此 <1, 2>≠ <2, 1> ;而无序对与顺序无关,因此 {1, 2} = {2, 1}。用学校里学到的术语来说,这两类分别对应着"排列"和"组合"。
用SQL生成有序对非常简单。像下面这样通过交叉连接生成笛卡儿积(直积),就可以得到有序对。
sql
-- 用于获取可重排列的 SQL 语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1 CROSS JOIN Products P2;
+--------+--------+
| name_1 | name_2 |
+--------+--------+
| 香蕉 | 橘子 |
| 苹果 | 橘子 |
| 橘子 | 橘子 |
| 香蕉 | 苹果 |
| 苹果 | 苹果 |
| 橘子 | 苹果 |
| 香蕉 | 香蕉 |
| 苹果 | 香蕉 |
| 橘子 | 香蕉 |
+--------+--------+交叉连接的特征是没有连接条件,因为交叉连接是通过遍历两张表来列举出所有记录的组合的。
执行结果里每一行(记录)都是一个有序对。因为是可重排列,所以执行结果的行数为3 * 3 = 9。执行结果里出现了(苹果,苹果)这种由相同元素构成的对,而且(橘子,苹果)和(苹果,橘子)这种只是调换了元素顺序的对也被当作不同的对了。这是因为,该查询在生成结果集合时会区分顺序。
另外,交叉连接也可以写成下面这样。
sql
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2;不过,我们最好避免这种写法,因为可能会出现原本想执行有连接条件的内连接,却因为忘了写连接条件,所以最终按交叉连接执行的危险。交叉连接的消耗极高,一不小就会浪费服务器资源,导致处理延迟。
接下来,我们思考一下如何更改才能排除由相同元素构成的对。我们先去掉(苹果,苹果)这种由相同元素构成的对,为此需要像下面这样加上一个条件,然后进行连接运算。
sql
-- 用于获取排列的 SQL 语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1 INNER JOIN Products P2
ON P1.name <> P2.name;
+--------+--------+
| name_1 | name_2 |
+--------+--------+
| 香蕉 | 橘子 |
| 苹果 | 橘子 |
| 香蕉 | 苹果 |
| 橘子 | 苹果 |
| 苹果 | 香蕉 |
| 橘子 | 香蕉 |
+--------+--------+加上ON P1.name <> P2.name这个条件以后,就能排除由相同元素构成的对,执行结果的行数为排列 P 3 2 = 3 ! ( 3 − 2 ) ! = 6 P_3^2 = \frac{3!}{(3-2)!} = 6 P32=(3−2)!3!=6。理解这个连接的关键,在于想象一下这里存在下面这样的两张表。
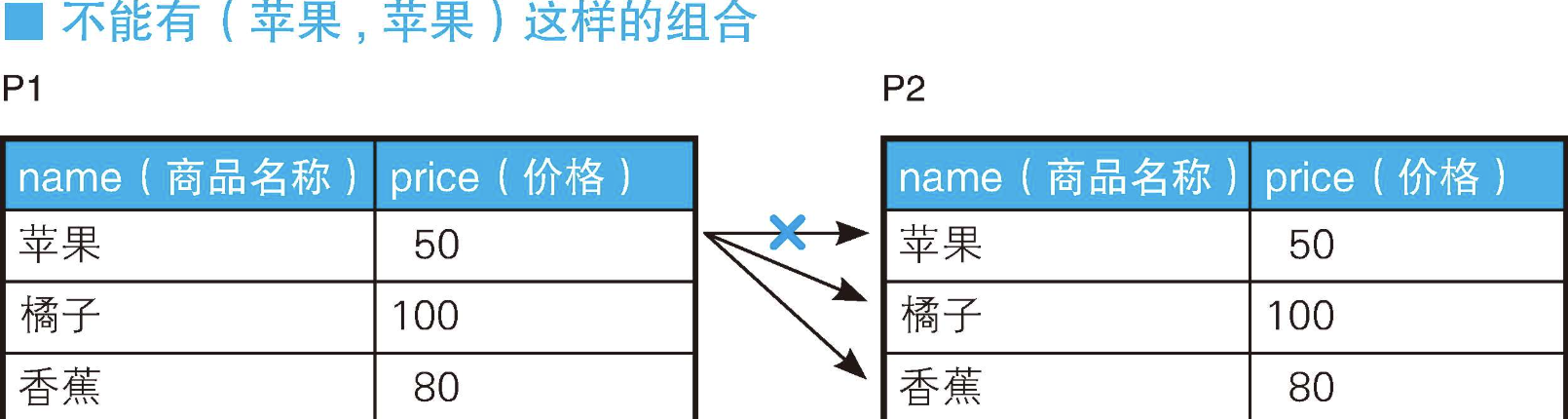
当然,无论是P1还是P2,实际上数据都来自同一张物理表Products。但是,在SQL里,只要被赋予了不同的名称,即便是相同的表也应该当作不同的表(集合)来对待。也就是说,P1和P2可以看成碰巧存储了相同数据的两个集合。这样的话,这个自连接的处理结果就成了下页这样。
- P1里的"苹果"行的连接对象为P2里的"橘子、香蕉"这两行
- P1里的"橘子"行的连接对象为P2里的"苹果、香蕉"这两行
- P1里的"香蕉"行的连接对象为P2里的"苹果、橘子"这两行
由此我们可以认为,相同的表的自连接和不同表间的普通连接并没有什么区别,自连接里的"自"这个前缀也没有太大的意义。
在旧式写法里还可以像下面这样写,但这种写法只要一步出错,就会变为前面提到的交叉连接,因此我们应该避免使用这种写法。
sql
-- 用于获取排列的 SQL 语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name <> P2.name;如果使用了这种写法,那么即使忘记写WHERE P1.name<> P2.name,DBMS也会将其解析成交叉连接并执行,而在采用INNER JOIN的情况下,如果忘记写ONP1.name <> P2.name,多数DBMS就会报错,所以是一种防呆法(fool-proof)的机制。
这次的处理结果依然是有序对。接下来我们进一步对(苹果,橘子)和(橘子,苹果)这种只是调换了元素顺序的 对进行去重。请看下面的SQL语句。
sql
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1 INNER JOIN Products P2
ON P1.name > P2.name;
+--------+--------+
| name_1 | name_2 |
+--------+--------+
| 苹果 | 橘子 |
| 香蕉 | 橘子 |
| 香蕉 | 苹果 |
+--------+--------+同样,请想象这里存在P1和P2两张表。在加上"不等于"这个条件后,这条SQL语句所做的是按字符顺序排列各商品,只与"字符顺序比自己靠前"的商品进行配对,执行结果的行数为组合 C 3 2 = 6 C_3^2 = 6 C32=6。到这里,我们终于得到了无序对。恐怕平时我们说到组合的时候,首先想到的就是这种类型的组合吧。
想要获取3个以上元素的组合时,像下面这样简单地扩展一下就可以了。这次的样本数据只有3行,所以结果应该只有1行,具体的SQL语句如下所示。
sql
-- 用于获取组合的 SQL 语句:扩展成 3 列
SELECT P1.name AS name_1,
P2.name AS name_2,
P3.name AS name_3
FROM Products P1 INNER JOIN Products P2
ON P1.name > P2.name
INNER JOIN Products P3
ON P2.name > P3.name;
+--------+--------+--------+
| name_1 | name_2 | name_3 |
+--------+--------+--------+
| 香蕉 | 苹果 | 橘子 |
+--------+--------+--------+如这道例题所示,使用等号"="以外的比较运算符,如"<"">""<>"进行的连接称为非等值连接。这里将非等值连接与自连接结合使用了,因此称为"非等值自连接"。虽然这个技术在实际工作中并不怎么常用,但在需要获取列的组合时,我们会用到它。
最后补充一点,">"和"<"等比较运算符不仅可以用于比较数值的大小,也可以用于比较字符串(比如按字典序进行比较)或者日期等。当然,这些比较运算符也可以用在日期等有序数据中。
2、删除重复行
在关系数据库的世界里,重复行和NULL一样,都不受欢迎。因此,人们想了很多办法来排除重复行。前面的例题用过一张商品表,现在我们假设在这张表里,"橘子"这种商品存在重复。可怕的是,这张表里连主键都没有(其实是根本没法设置主键)。我们现在就需要马上清理一下,去掉重复行。
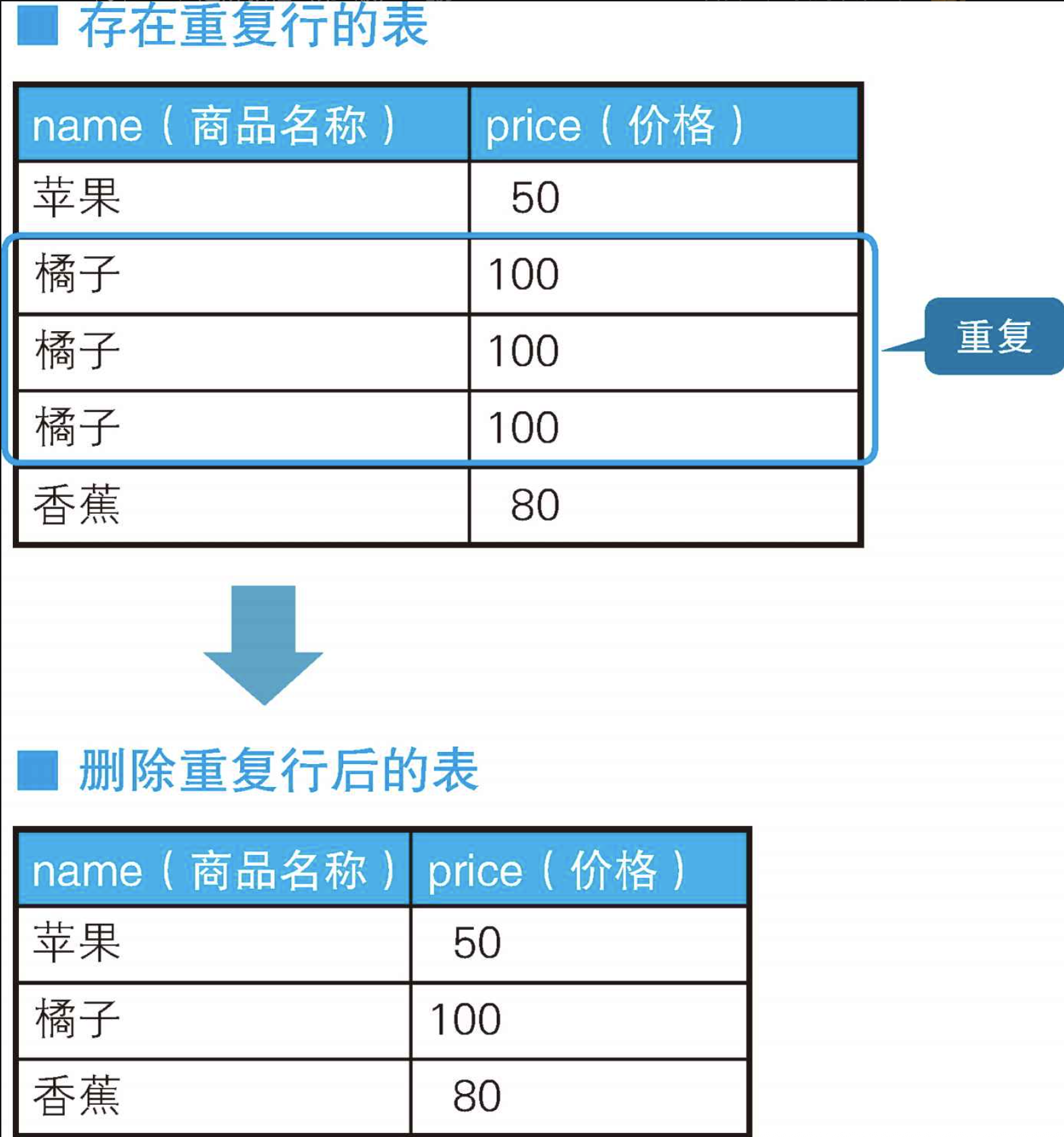
这回,我们来学习一下使用关联子查询删除重复行的方法。连接和关联子查询虽然是不同的运算,但是思路很像,而且很多时候它们的SQL语句在功能上是等价的,所以在这里我们一并了解一下。
sql
DROP TABLE Products;
CREATE TABLE Products (
name VARCHAR(16) NOT NULL,
price INTEGER NOT NULL
);
-- 重复的记录
INSERT INTO Products VALUES('苹果', 50);
INSERT INTO Products VALUES('橘子', 100);
INSERT INTO Products VALUES('橘子', 100);
INSERT INTO Products VALUES('橘子', 100);
INSERT INTO Products VALUES('香蕉', 80);
sql
DELETE FROM Products
WHERE (name, price) IN (
SELECT name, price
FROM (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY name, price
ORDER BY name
) AS rn
FROM Products
) t
WHERE rn > 1
);重复行有多少行都没有关系。通常,只要重复的列里不包含主键,就可以用主键来处理,但像这道例题一样所有的列都重复的情况,则需要使用由数据库独自实现的行ID。这里的行ID可以理解成拥有"任何表都可以使用的主键"这种特征的虚拟列。在下面的SQL语句里,我们使用的是Oracle数据库里的rowid。
sql
-- 用于删除重复行的 SQL 语句(1):使用极值函数
DELETE FROM Products P1
WHERE rowid < (
SELECT MAX(P2.rowid)
FROM Products P2
WHERE P1.name = P2. name
AND P1.price = P2.price
);这个关联子查询的处理乍看起来不是很好理解。顾名思义,关联子查询原本是用来查找两张表之间的关联性的,而这里只有一张表,却也跟"关联"(correlated)扯上了关系,想必大家都心存疑问吧。
之所以大家会有这种疑问,是因为没有从正确的层面来理解这条SQL语句。请像前面的例题里讲过的一样,将关联子查询理解成对两个拥有相同数据的集合进行的关联操作。
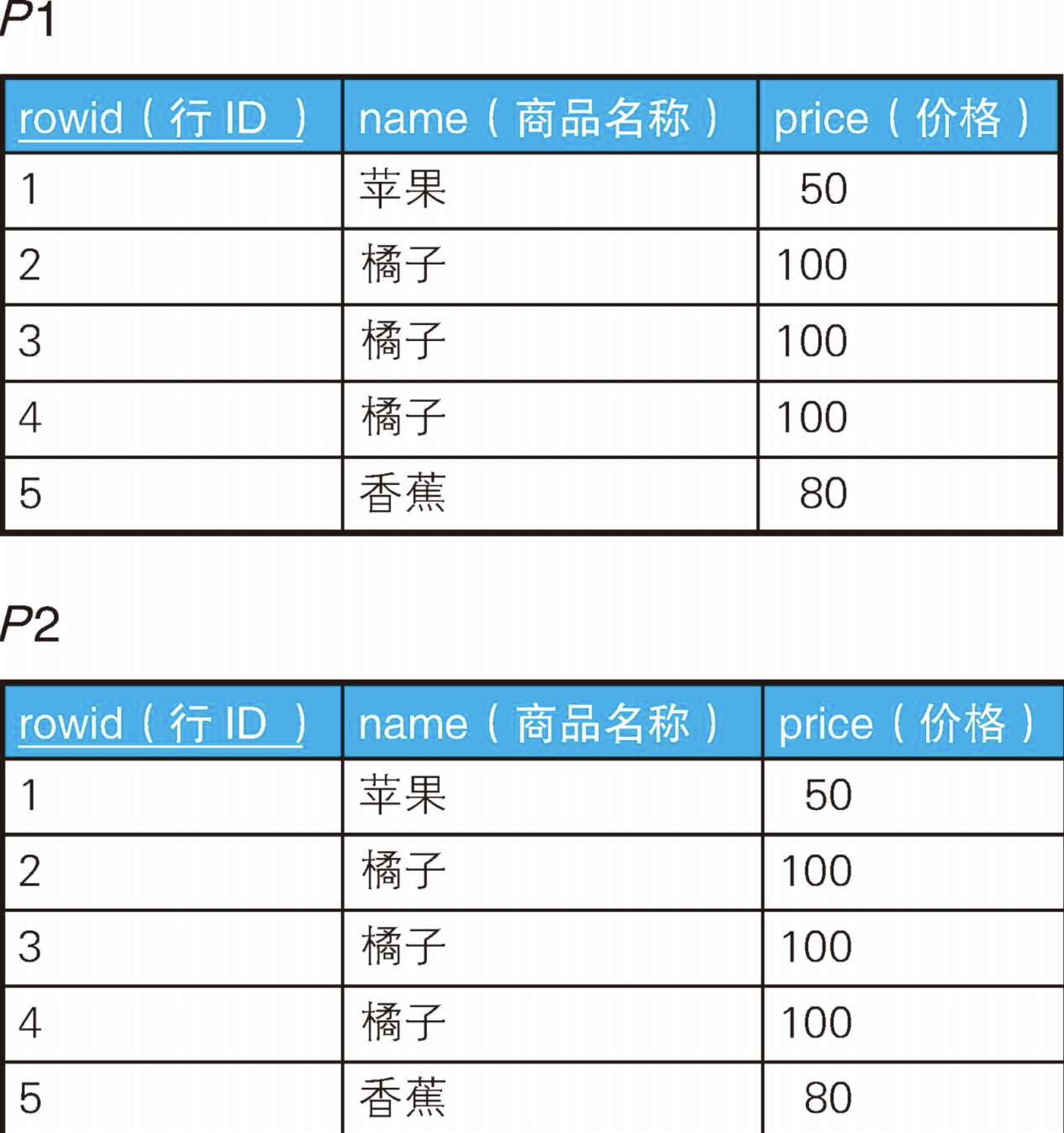
这里的重点也与前面的例题一样,对于在SQL语句里被赋予了不同名称的集合,我们应该将其看作完全不同的集合。尽管它们在物理层面上是同一张表(Products),但从逻辑层面上来讲,它们是不同的表(P1和P2)。
这个子查询会比较两个集合,然后返回商品名称和价格都相同的行里最大的rowid所在的行。于是,由于苹果和香蕉没有重复行,所以返回的行是"1:苹果""5:香蕉",而判断条件是不等号,所以该行不会被删除。而对于"橘子"这个商品,程序返回的行是"4:橘子",那么rowid比4小的两行------"2:橘子"和"3:橘子"就会被删除。
如果从物理表的层面来理解SQL语句,抽象度是非常低的。"表""视图"这样的名称只反映了不同的存储方法,而存储方法并不影响SQL语句的执行和结果,因此无须有什么顾虑(在不考虑性能的前提下)。无论是表,还是视图,本质上都是集合------集合是SQL唯一能处理的数据结构。
3、查找局部不一致的列
假设有下面这样一张住址表,主键是人名,同一家人的家庭ID是一样的。在寄送新年贺卡等时,肯定会有人制作这样一张表吧。

一般来说,同一家人应该住在同一个地方(如加藤家),但也有像福尔摩斯和华生这样不是一家人却住在一起的情况。接下来,我们看一下前田夫妇。这两个人并没有分居,只是夫人的住址写错了而已。前面说了,如果家庭ID一样,住址也必须一样,因此这里需要修改一下。那么,我们该如何找出像前田夫妇这样的"是同一家人,但住址不同的记录"呢?
实现办法有几种,不过如果用非等值自连接来实现,代码会非常简洁。
sql
-- 查找局部不一致的列
CREATE TABLE Addresses (
name VARCHAR(32),
family_id INTEGER,
address VARCHAR(32),
PRIMARY KEY(name, family_id)
);
INSERT INTO Addresses VALUES('前田义明', '100', '东京都港区虎之门3-2-29');
INSERT INTO Addresses VALUES('前田由美', '100', '东京都港区虎之门3-2-92');
INSERT INTO Addresses VALUES('加藤茶', '200', '东京都新宿区西新宿2-8-1');
INSERT INTO Addresses VALUES('加藤胜', '200', '东京都新宿区西新宿2-8-1');
INSERT INTO Addresses VALUES('福尔摩斯', '300', '贝克街221B');
INSERT INTO Addresses VALUES('华生', '400', '贝克街221B');
sql
-- 用于查找是同一家人但住址不同的记录的 SQL 语句
SELECT DISTINCT A1.name, A1.address
FROM Addresses A1 INNER JOIN Addresses A2
ON A1.family_id = A2.family_id
AND A1.address <> A2.address;
+----------+------------------------+
| name | address |
+----------+------------------------+
| 前田义明 | 东京都港区虎之门3-2-29 |
| 前田由美 | 东京都港区虎之门3-2-92 |
+----------+------------------------+这条SQL语句逐词翻译了"是同一家人,但住址不同"这个条件,相信大家都能看明白。可以看到,像这样把自连接和非等值连接结合起来确实非常好用。这条SQL语句不仅可以用于发现不规则的数据,而且修改后也可以用来查找商品,比如下面这道例题。
从下面这张商品表里找出价格相等的商品的组合。
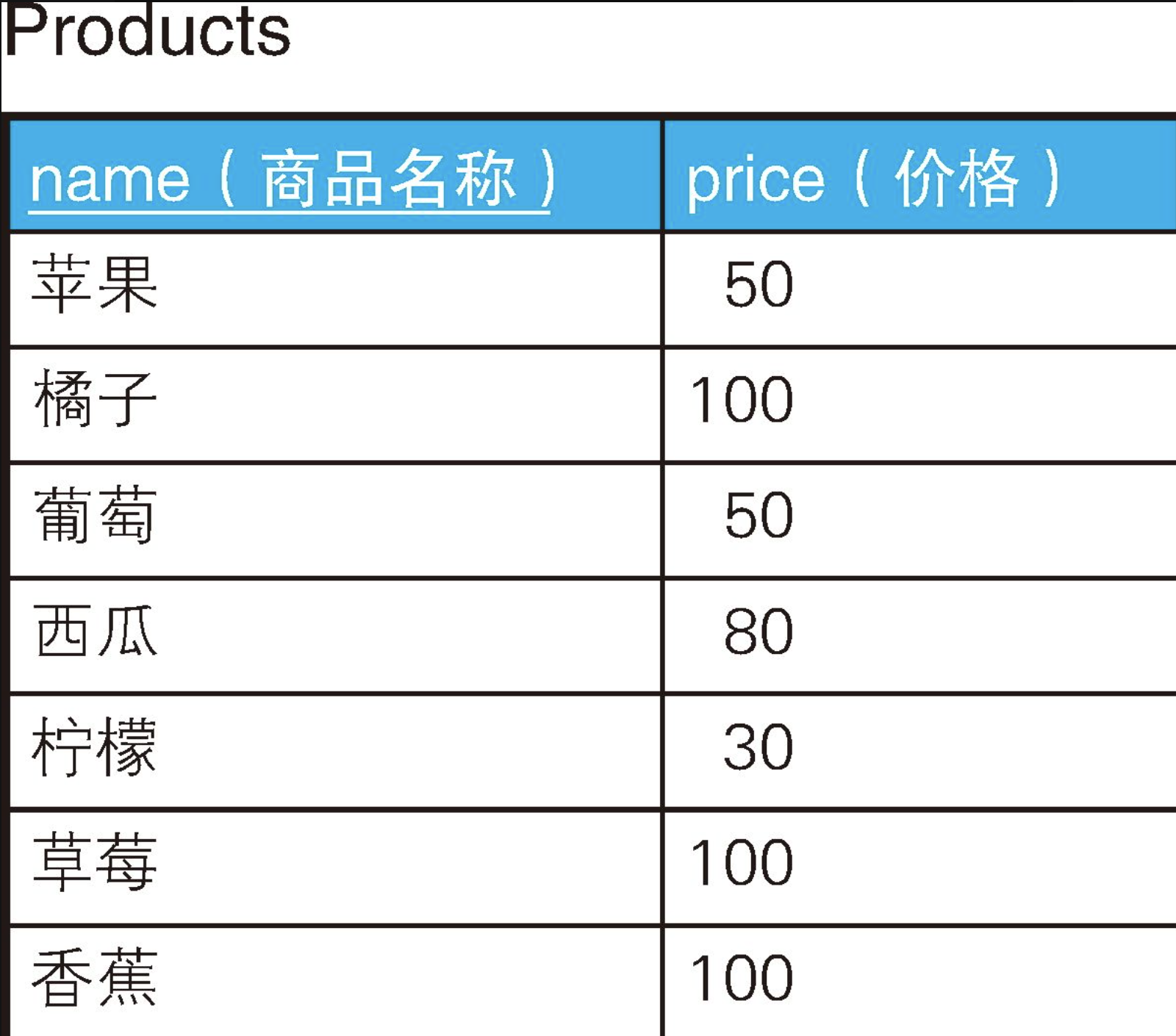
sql
DELETE FROM Products;
INSERT INTO Products VALUES('苹果', 50);
INSERT INTO Products VALUES('橘子', 100);
INSERT INTO Products VALUES('葡萄', 50);
INSERT INTO Products VALUES('西瓜', 80);
INSERT INTO Products VALUES('柠檬', 30);
INSERT INTO Products VALUES('草莓', 100);
INSERT INTO Products VALUES('香蕉', 100);和前面的住址表那道题的结构完全一样。家庭ID ⇨ 价格 住址 ⇨ 商品名称请像上面这样替换一下。然后,代码就会变成下面这样。
sql
-- 用于查找价格相等但商品名称不同的记录的 SQL 语句
SELECT DISTINCT P1.name, P1.price
FROM Products P1 INNER JOIN Products P2
ON P1.price = P2.price
AND P1.name <> P2.name
ORDER BY P1.price;
+------+-------+
| name | price |
+------+-------+
| 葡萄 | 50 |
| 苹果 | 50 |
| 香蕉 | 100 |
| 草莓 | 100 |
| 橘子 | 100 |
+------+-------+请注意,这里与住址表那道题不同的是,如果代码中不加上DISTINCT,结果里就会出现重复行。出现不同的关键,在于价格相同的记录的条数。就住址表的例题来说,不加DISTINCT就会出现重复行的前提是前田家有孩子。不过,这道例题使用的是连接查询,如果改用关联子查询,就不需要DISTINCT了。
4、总结
自连接是一门非常重要的技术:
- 自连接经常和非等值连接结合起来使用。
- 自连接和GROUP BY结合使用可以生成递归集合。
- 将自连接看作不同表之间的连接更容易理解。
- 用逻辑而非物理的方法来思考。
在使用数据库制作各种票据和统计表的工作中,我们经常需要按分数、人数或销售额等对数值进行排序。现在,我们要按照价格从高到低的顺序,对下面这张表里的商品进行排序。价格相同的商品位次也一样,在它们后一位的商品有两种排序方法,一种是跳过之后的位次,另一种是不跳过之后的位次。
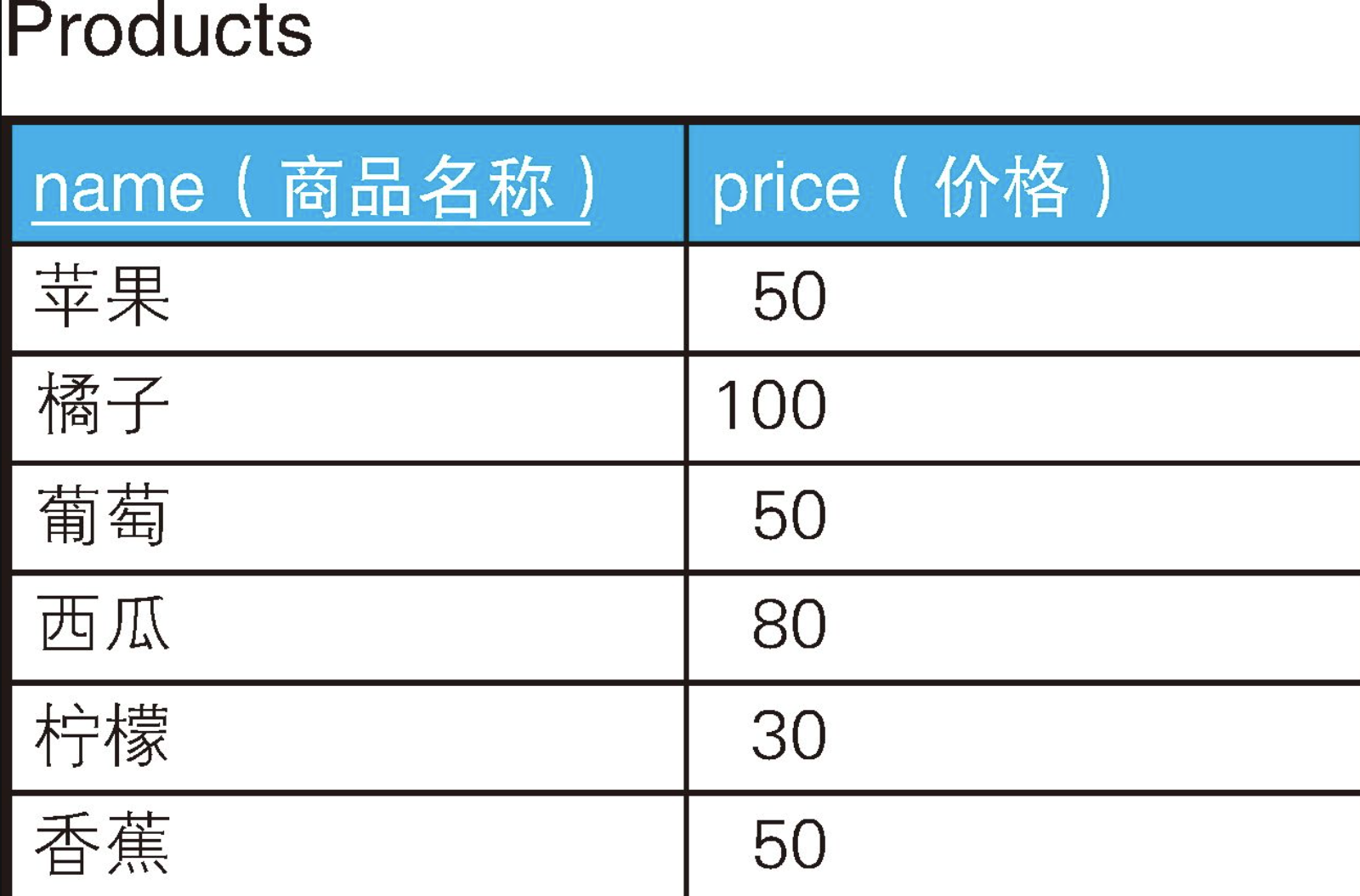
在现在的SQL中,如果使用窗口函数,可以像下面这样轻松实现。
sql
-- 排序:使用窗口函数
SELECT name, price,
RANK()OVER (ORDER BY price DESC)AS rank_1,
DENSE_RANK()OVER (ORDER BY price DESC)AS rank_2
FROM Products;
+------+-------+--------+--------+
| name | price | rank_1 | rank_2 |
+------+-------+--------+--------+
| 橘子 | 100 | 1 | 1 |
| 草莓 | 100 | 1 | 1 |
| 香蕉 | 100 | 1 | 1 |
| 西瓜 | 80 | 4 | 2 |
| 苹果 | 50 | 5 | 3 |
| 葡萄 | 50 | 5 | 3 |
| 柠檬 | 30 | 7 | 4 |
+------+-------+--------+--------+在出现相同位次后,rank_1跳过了之后的位次,rank_2没有跳过。代码很简洁,也很容易理解。
不过,在窗口函数还未出现时,使用SQL进行排序需要下一番功夫。下面是用非等值自连接写的代码。
sql
-- 排序从 1 开始。如果已出现相同位次,则跳过之后的位次
SELECT P1.name, P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
+------+-------+--------+
| name | price | rank_1 |
+------+-------+--------+
| 橘子 | 100 | 1 |
| 草莓 | 100 | 1 |
| 香蕉 | 100 | 1 |
| 西瓜 | 80 | 4 |
| 苹果 | 50 | 5 |
| 葡萄 | 50 | 5 |
| 柠檬 | 30 | 7 |
+------+-------+--------+这段代码的排序方法看起来很普通,但很容易扩展。例如,去掉标量子查询后边的 +1,就可以从0开始给商品排序,而且如果使用COUNT(DISTINCT P2.price),那么存在相同位次的记录时,就可以不跳过之后的位次,而是连续输出(相当于DENSE_RANK函数)。
这条SQL语句很好地体现了面向集合的思维方式。子查询所做的,是计算出价格比自己高的记录的条数,并将其作为自己的位次。为了便于理解,我们先思考从0开始,对去重之后的4个价格100、80、50、30进行排序的情况。
首先是价格最高的100,因为不存在比它更高的价格,所以COUNT函数返回0。接下来是价格第二高的80,比它高的价格只有一个100,所以COUNT函数返回1。同样,价格为50的时候返回2,价格为30的时候返回3。这样,就生成了下面的集合。
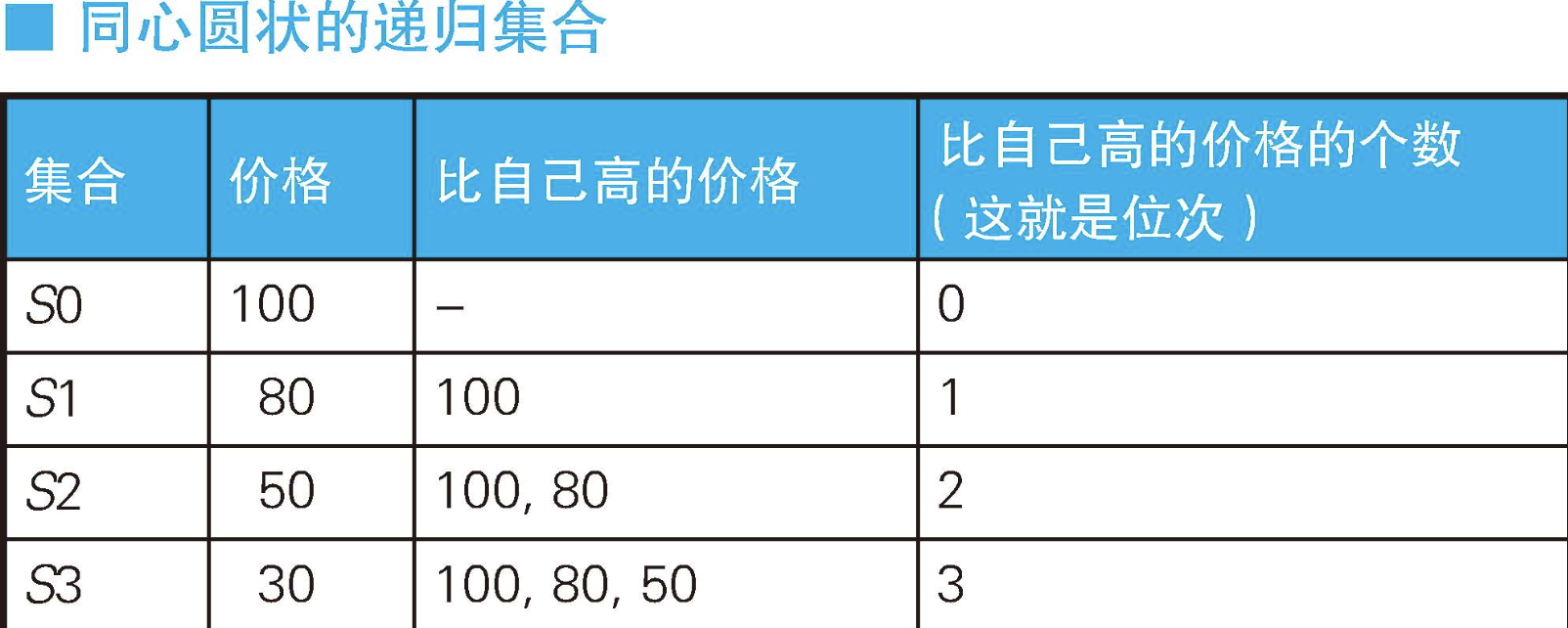
也就是说,这条SQL语句会生成下面这种同心圆状的递归集合,然后数这些集合的元素个数。
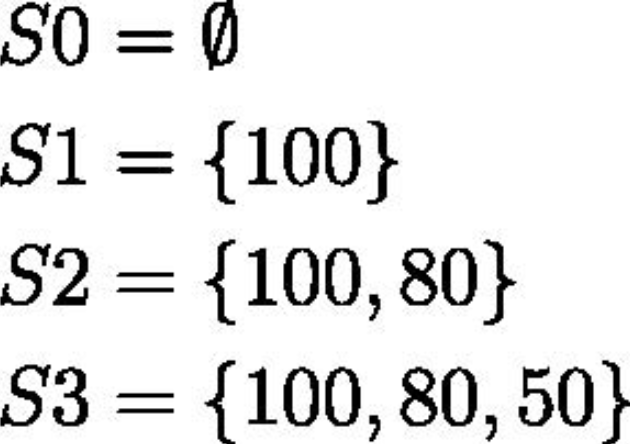
除关联子查询之外,该查询还可以按照自连接的写法来写。这种写法让我们更容易掌握执行情况。
sql
-- 排序:使用自连接
SELECT P1.name, MAX(P1.price) AS price,
COUNT(P2.name)+1 AS rank_1
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price GROUP BY P1.name;
+------+-------+--------+
| name | price | rank_1 |
+------+-------+--------+
| 苹果 | 50 | 5 |
| 橘子 | 100 | 1 |
| 葡萄 | 50 | 5 |
| 西瓜 | 80 | 4 |
| 柠檬 | 30 | 7 |
| 草莓 | 100 | 1 |
| 香蕉 | 100 | 1 |
+------+-------+--------+去掉这条SQL语句里的聚合并展开成下面这样,就可以更清楚地看出同心圆状的包含关系(为了看得更清楚,我们从表中去掉价格重复的行,只留下橘子、西瓜、葡萄和柠檬这4行)。
sql
-- 不聚合,查看集合的包含关系
SELECT P1.name, P2.name
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price;
+------+--------+
| name | name |
+------+--------+
| 苹果 | 香蕉 |
| 苹果 | 草莓 |
| 苹果 | 西瓜 |
| 苹果 | 橘子 |
| 橘子 | <null> |
| 葡萄 | 香蕉 |
| 葡萄 | 草莓 |
| 葡萄 | 西瓜 |
| 葡萄 | 橘子 |
| 西瓜 | 香蕉 |
| 西瓜 | 草莓 |
| 西瓜 | 橘子 |
| 柠檬 | 香蕉 |
| 柠檬 | 草莓 |
| 柠檬 | 西瓜 |
| 柠檬 | 葡萄 |
| 柠檬 | 橘子 |
| 柠檬 | 苹果 |
| 草莓 | <null> |
| 香蕉 | <null> |
+------+--------+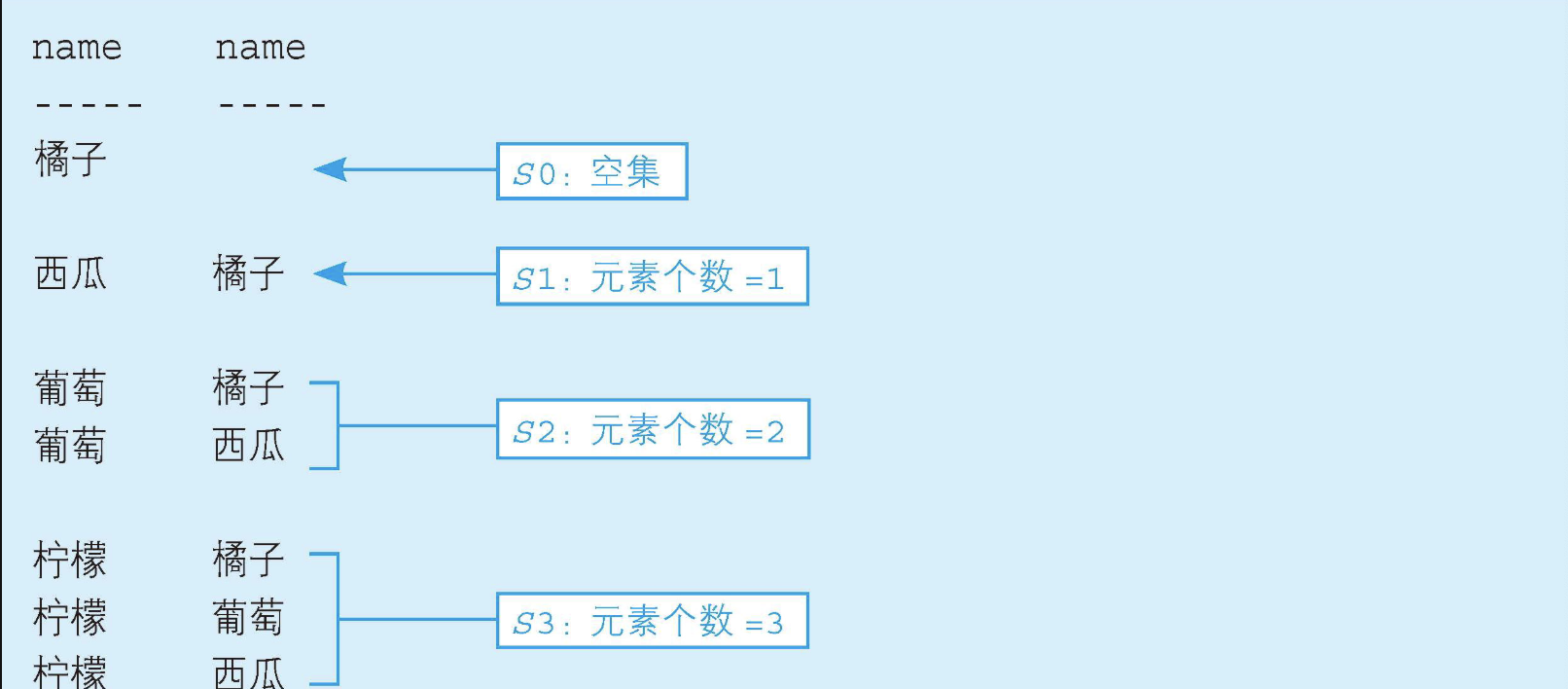
从执行结果可以看出,集合每增多1个,元素也增多1个,通过数集合里元素的个数就可以算出位次。