背景
在通过量化过后我们将模型转化为onnx格式,通常来说我们一般会将其先转化为onnx-fp32格式,然后在次基础上通过校准图像转化为onnx-int8格式。
转化好过后的fp32格式可能会含有两个文件,model.onnx和model.onnx.data

前者保存计算图、节点、张量引用、元信息,后者保存实际的大块权重数据,因此可以看出前者的内存大小远远小于data中的内存大小,而fp32整个内存大小则是这两个文件内存大小之和,其大约是int8格式的3-4倍,甚至更小。
其实按照量化的原理来说,fp32权重为4bytes,而int8为1bytes,其内存大小应该为严格的四倍关系。但是在量化时我们通过会根据量化形式不同采用不同的方法来确保量化的精度。
在QAT中通常插入伪量化节点,PTQ中通常插入QDQ节点,这些节点在转化后通过也会保留在权重信息中。同时一般为了保证精度的损失,通常会不量化最后网络的输出层即最后一层。这些都会增加int8的内存大小。
转化完成后,下面便是转化为其他模型格式或者直接运行onnx格式。
流程
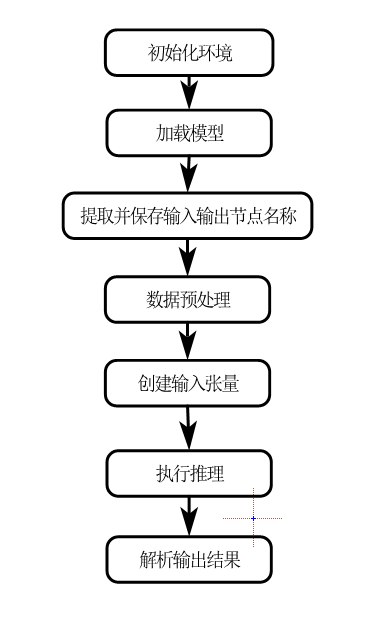
初始化环境->加载模型->提取并保持输入输出节点名称->数据预处理->创建输入张量以绑定已有内存->执行推理->解析输出结果,其中最大的不同就是解析输出结果,图像识别方面,seg和obb的处理方式不同,虽然都需要nms,但是seg还需要掩膜重建,而如果是TCN和transformer等则需要取最后一步输出等,但是前面都是一样的,主要是数据的预处理和输入张量形状要和训练时一样。
初始化环境
env_ = make_unique<Ort::Env>(ORT_LOGGING_LEVEL_WARNING, "YOLO_OBB_Inference");
session_options_ = make_unique<Ort::SessionOptions>();
// 单个算子最多并行线程数量设置
session_options_->SetIntraOpNumThreads(1);
// 不同算子最多并行调度线程设置
session_options_->SetInterOpNumThreads(1);
// 图优化
session_options_->SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);创建Ort::Env->配置Ort::SessionOption->加载onnx创建Ort::Session->线程设置->图优化
创建Ort::Env
env_ = make_unique<Ort::Env>(ORT_LOGGING_LEVEL_WARNING, "YOLO_OBB_Inference");创建一个 ONNX Runtime 的运行环境对象Ort::Env,其负责 ONNX Runtime 的全局环境,例如日志、线程池等。
第一个参数:
日志级别 含义 适合场景 ORT_LOGGING_LEVEL_VERBOSE 最详细日志,包含大量内部执行、优化、调试信息 深度排查问题 ORT_LOGGING_LEVEL_INFO 普通信息日志,比如初始化、加载、配置等 调试阶段 ORT_LOGGING_LEVEL_WARNING 只打印警告及以上信息 常用默认值 ORT_LOGGING_LEVEL_ERROR 只打印错误信息 部署时想减少日志 ORT_LOGGING_LEVEL_FATAL 只打印严重致命错误 极简日志,正式部署可用但不利于排查 第二个参数:日志名字
配置Ort::SessionOption并创建Ort::Session
session_options_ = make_unique<Ort::SessionOptions>();创建一个 ONNX Runtime 的 Session 配置对象,它本身不加载模型,只是用来配置后面创建
Ort::Session时的参数。如果后续需要使用CPU/GPU等加速也需要在这里面配置环境。
线程设置
session_options_->SetIntraOpNumThreads(1); session_options_->SetInterOpNumThreads(1);IntraOp表示单个算子内部并行。
InterOp表示不同算子并行计算。
小模型 / 嵌入式 / 低延迟:IntraOp = 1 或 2,InterOp = 1
大模型 / PC CPU:IntraOp = 物理核心数附近测试,InterOp = 1
多模型并发:每个 session 的 IntraOp 不要太大
图优化
session_options_->SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
参数 含义 适合场景 ORT_DISABLE_ALL关闭所有图优化 调试、对比原始图 ORT_ENABLE_BASIC基础优化 保守部署 ORT_ENABLE_EXTENDED基础优化 + 扩展融合优化 常用 ORT_ENABLE_LAYOUT进一步做 layout 相关优化 某些后端/模型可能收益更大 ORT_ENABLE_ALL开启所有可用优化 通常部署首选
加载模型
// 加载模型
filesystem::path model_path_fs(path);
session_ = make_unique<Ort::Session>(*env_, model_path_fs.c_str(), *session_options_);加载模型时,在linux系统下直接使用const sting来读取模型地址,然后通过c_str()转化为
提取并保存输入输出节点名称
// 提取并保存输入输出节点名称
input_names_str_.clear();
output_names_str_.clear();
input_node_names_.clear();
output_node_names_.clear();
size_t input_count = session_->GetInputCount();
size_t output_count = session_->GetOutputCount();
input_names_str_.reserve(input_count);
output_names_str_.reserve(output_count);
input_node_names_.reserve(input_count);
output_node_names_.reserve(output_count);
for (size_t i = 0; i < input_count; ++i) {
auto name_ptr = session_->GetInputNameAllocated(i, allocator_);
input_names_str_.emplace_back(name_ptr.get());
}
for (size_t i = 0; i < output_count; ++i) {
auto name_ptr = session_->GetOutputNameAllocated(i, allocator_);
output_names_str_.emplace_back(name_ptr.get());
}
for (const auto& name : input_names_str_) {
input_node_names_.push_back(name.c_str());
}
for (const auto& name : output_names_str_) {
output_node_names_.push_back(name.c_str());
}清空输入输出数据
当该函数需要别反复初始化时,通常需要使用clear将输入输出的节点名称清空,以免后续的错误调用。
提取模型输入输出个数并扩容输入输出容器
通过GetInputCount和GetOutputCount来统计输入输出的个数,再通过reserve将vector容器扩容以避免后续的参数过多时vector自动寻址扩容导致内存的零散和变更。
提取输入输出节点名称
通过上面得到的输入输出个数使用GetInputNameAllocated和GetInputNameAllocated提取出所有的输入输出,提取出来的输入输出名称都是临时的,只在该作用域下有效,随后通过成员函数get得到string类型的输入输出名称,并使用c_str转化为c风格的字符串。
数据预处理
数据预处理必须使用预训练时相同的数据预处理方法。
在使用yolo进行图像处理时,通常需要使用和yolo相同的预处理方法即首先进行等比例缩放,再在四周填充灰色像素至模型输入尺寸,然后对图像进行颜色通道、归一化、维度转化等处理。
在使用LPRNet进行OCR字符预测时,除了需要传入模型的位置、图像的长和宽,还需要传入四个点的坐标以实现将图像裁剪为所需目标取,再进行后续的预处理。
在使用TCN进行时间序列预测时,数据的预处理通常是序列整理、异常值处理、缺失值处理、归一化、滑动窗口、维度排列等。
创建输入张量
// 创建输入 Tensor,绑定已有内存
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info,
data_ptr, input_tensor_size, // 直接传 data_ptr
input_shape.data(), input_shape.size()
);创建储存在CPU中的张量
Ort::MemoryInfo描述的是一块 Tensor 内存的来源和类型。而后续的成员函数CreatCpu则是在Cpu中创建张量。其本身并不会拷贝数据,而是只创建一个张量放在指定的位置。第一个参数:内存池分配器
参数 含义 OrtArenaAllocator使用 ORT 的 arena 内存池分配器,会复用内存,减少频繁申请/释放 OrtDeviceAllocator使用设备自己的普通分配器,不走 arena 内存池 OrtReadOnlyAllocator只读内存分配器,通常和权重/常量相关,普通输入不用 第二个参数:CPU内存类型
参数 含义 OrtMemTypeDefault默认内存类型。CPU 推理时就是普通 CPU 内存 OrtMemTypeCPUInput非 CPU 后端使用的 CPU 输入内存,比如 GPU/NPU 推理时,输入先在 CPU 上 OrtMemTypeCPUOutput非 CPU 后端输出到 CPU 可访问内存
将数据传入张量
第一个参数:描述数据所需要储存的内存所在,通常是上文创建的张量
第二个参数:预处理后数据的首地址
第三个参数:元素个数(不是字节数)
第四个参数:输入张量的形状
第五个参数:输入张量的维度
输入数据张量形状
对于yolo和LPRNet模型来说,其都是用以处理图像数据,因此其输入数据张量形状为
vector<int64_t> input_shape = { 1, channels, input_height, input_width };对于TCN模型来说,其大多处理时间序列数据,因此其输入数据张量形状为
vector<int64_t> input_shape = { 1, feature_dim, sequence_length };
执行推理
// 执行推理
auto output_tensors = session_->Run(
Ort::RunOptions{ nullptr },
input_node_names_.data(), &input_tensor, 1,
output_node_names_.data(), output_node_names_.size()
);
参数个数 例子 含义 1Ort::RunOptions{nullptr}本次推理的运行选项,通常默认即可 2input_node_names_.data()输入节点名称数组 3&input_tensor输入 Tensor 数组 41输入 Tensor 数量 5output_node_names_.data()要获取的输出节点名称数组 6output_node_names_.size()输出节点数量
解析输出结果
解析输出结果的步骤会因为不同的模型而不同,这也是推理中最为不同的一步。
取出输出结果信息
// 解析输出结果
// 取出第i个输出张量的类型和形状信息
auto output_info = output_tensors[i].GetTensorTypeAndShapeInfo();
// 取得输出张量的形状
vector<int64_t> output_shape = output_info.GetShape();
// 取得输出张量的数据类型
ONNXTensorElementDataType dtype = type_info.GetElementType();
// 取得第i个输出张量的真实数据指针
float* output_data = output_tensors[i].GetTensorMutableData<float>();常见的模型中,yolo-seg和transformer等模型都是多输出模型,因此需要使用for循环来提取所有的输出信息,但是如果后续不适用某一部分的输出信息可以不提取,以减轻后处理的复杂度。
如果无法判断模型是否为多输出,可以将使用for循环将这些输出信息打印出来以直观判断。
在取得第i个输出张量得真实数据指针中,其取出得数据指针类型必须要和输出张量的数据类型相同。其中ONNXTensorElementDataType 的数据类型如下:
|---------------------------------------|---------|
| ONNXTensorElementDataType | c++类型 |
| ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT | float32 |
| ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT16 | float16 |
| ONNX_TENSOR_ELEMENT_DATA_TYPE_INT64 | int64 |
| ONNX_TENSOR_ELEMENT_DATA_TYPE_INT32 | int32 |
| ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT8 | int8 |
图像处理方面
图像处理方面通常都是使用yolo进行处理,目前较为常用的为目标检测、分类检测、旋转框检测和掩膜检测。这里主要说明旋转框检测和掩膜检测。
判断输出排列格式
无论是那种yolo模型首先都需要判断输出的排列格式。
if (output_shape[1] > output_shape[2]) {
num_anchors = static_cast<int>(output_shape[1]);
num_channels = static_cast<int>(output_shape[2]);
is_transposed = true;
}
else {
num_channels = static_cast<int>(output_shape[1]);
num_anchors = static_cast<int>(output_shape[2]);
}yolo-obb
旋转框检测通常输出一个候选框矩阵batch, C, N或batch, N, C,通常为batch, C, N,但是都需要先判断一下输出的排列格式,再进行后续的推理。其中C=4+类别数+1
第一个参数(batch):候选框
第二个参数(C):前四个表示候选框的cx,vy,w,h即中心点的x,y坐标和检测框的长、宽。中间为模型的类别分数,最后的候选框的角度。
第三个参数(N):模型原始输出的候选框数量。需要经过置信度过滤和nms才能得到最终的输出目标数量。
yolo-seg
yolo-seg通常有两个输出,output0:1, 4 + 类别数 + mask_dim, N和output1:1,mask_dim, mask_h, mask_w
output0:第一个参数:检测框
第二个参数:前四个表示检测框的cx,vy,w,h即中心点的x,y坐标和检测框的长、宽。中间为模型的类别分数,最后的mask_dim表示mask系数,即mask原型图的通道数,也是每个候选框携带的mask系数数量。计算mask_dim直接使用output1的第二个参数即可。
第三个参数:模型原始输出的候选框数量。需要经过置信度过滤和nms才能得到最终的输出目标数量。
output1:第一个参数:检测框
第二个参数:mask系数,通常都是32。
第三个参数:掩膜的高
第四个参数:掩膜的宽
获得取值函数
通过上面判断出的排列格式,构建一个函数用以后续的取值函数。
int num_classes = num_channels - 5; // yolo-obb
int num_classes = num_channels - 4 - 32; // yolo-seg
auto get_value = [&](int channel_idx, int anchor_idx) -> float {
if (is_transposed) {
return output_data[anchor_idx * num_channels + channel_idx];
}
else {
return output_data[channel_idx * num_anchors + anchor_idx];
}
};置信度阈值过滤
vector<OBBDetection> detections;
vector<SEGTempDetection> detections;
detections.reserve(num_anchors);
for (int i = 0; i < num_anchors; ++i) {
float max_conf = 0.0f;
int max_class_id = -1;
for (int c = 0; c < num_classes; ++c) {
float conf = get_value(4 + c, i);
if (conf > max_conf) {
max_conf = conf;
max_class_id = c;
}
}
if (max_conf >= conf_threshold) {
// 后续可能不同,需要根据自己的需求使用更改代码
OBBDetection det;
det.cx = get_value(0, i);
det.cy = get_value(1, i);
det.w = get_value(2, i);
det.h = get_value(3, i);
det.angle = get_value(4 + num_classes, i);
det.class_id = max_class_id;
det.confidence = max_conf;
detections.push_back(det);
}
}这里获取候选框的第几个参数需要结合上面的输出排列格式来判断。
这里得到的detections是所有种类,只要满足置信度的候选框。
非极大值抑制(nms)
其主要使用在目标检测中,当模型识别到一个物体时,会有一堆高度重叠的候选框,nms便是在这些高度重叠的候选框中,保留最可信的一个,同时去掉其余的候选框。
步骤
按confidence从高到底排列(sort)->取分数最高的框进行保留->计算它与其他框的IoU->判断IoU是否满足阈值
首先将解析好的候选框按从大到小的顺序排列。
然后定义一个是否过滤的容器,将所有候选框都定义为可以保留即不过滤的候选框,值为false,其大小与候选框大小相同。
第一个即置信度最高的候选框直接保留,无需其他验证。
遍历剩下的候选框,与当前的候选框计算IoU,并比较阈值。
若IoU大于阈值,则表示两框重叠太多,该候选框为相同种类不同物体,不修改容器值;若IoU小于等于阈值,则表示两框重叠较少,该候选框为相同种类相同物体,修改容器值为true。
在第一次遍历结束后,其主要修改的是候选框与置信度最高的候选框之间的IoU,还需要将剩下的候选框再次作比较,最后得出所有可能的候选框以输出。
// NMS
// 按置信度排列
sort(detections.begin(), detections.end(), [](const OBBDetection& a, const OBBDetection& b) {
return a.confidence > b.confidence;
});
vector<OBBDetection> nms_result;
vector<bool> is_suppressed(detections.size(), false);
for (size_t i = 0; i < detections.size(); ++i) {
// 取分数最高的框进行保留,其余分数在下面的代码中通过IoU可能会被值为true直接跳过
if (is_suppressed[i]) continue;
nms_result.push_back(detections[i]);
// 遍历除去第一个参数也就是最高分候选框
for (size_t j = i + 1; j < detections.size(); ++j) {
if (is_suppressed[j]) continue;
// 判断种类是否一致
if (detections[i].class_id == detections[j].class_id) {
// 通过旋转IoU与IoU阈值比较得出其是否为同一物体
// 如果后续有不满足阈值的,则表示候选框为相同种类不同物体
// 后续为满足阈值的,则表示候选框为相同种类相同物体
float iou = CalculateRotatedIoU(detections[i], detections[j]);
float iou = CalculateBoxIoU(detections[i], detections[j]);
if (iou > nms_iou_threshold) {
is_suppressed[j] = true;
}
}
}
}Rotated NMS
// 计算两个 OBB 的 Rotated IoU
float CalculateRotatedIoU(const OBBDetection& a, const OBBDetection& b) {
// 将弧度转换为角度
float angle_a_deg = a.angle * 180.0f / CV_PI;
float angle_b_deg = b.angle * 180.0f / CV_PI;
// 构建旋转矩形
cv::RotatedRect rect_a(cv::Point2f(a.cx, a.cy), cv::Size2f(a.w, a.h), angle_a_deg);
cv::RotatedRect rect_b(cv::Point2f(b.cx, b.cy), cv::Size2f(b.w, b.h), angle_b_deg);
// 计算多边形交集点
std::vector<cv::Point2f> intersecting_region;
int intersection_type = cv::rotatedRectangleIntersection(rect_a, rect_b, intersecting_region);
// 如果没有任何交集,IoU 为 0
if (intersection_type == cv::INTERSECT_NONE || intersecting_region.empty()) {
return 0.0f;
}
// 计算交集多边形的面积
float inter_area = cv::contourArea(intersecting_region);
// 计算各自的面积
float area_a = a.w * a.h;
float area_b = b.w * b.h;
// 计算 IoU = 交集 / 并集
float iou = inter_area / (area_a + area_b - inter_area);
return iou;
}yolo-obb在nms中最大的不同便是IoU的计算,为Rotated IoU。其步骤如上述代码所示。
Box NMS
float CalculateBoxIoU(const SEGTempDetection& a, const SEGTempDetection& b) {
float ax1 = a.cx - a.w * 0.5f;
float ay1 = a.cy - a.h * 0.5f;
float ax2 = a.cx + a.w * 0.5f;
float ay2 = a.cy + a.h * 0.5f;
float bx1 = b.cx - b.w * 0.5f;
float by1 = b.cy - b.h * 0.5f;
float bx2 = b.cx + b.w * 0.5f;
float by2 = b.cy + b.h * 0.5f;
float inter_x1 = std::max(ax1, bx1);
float inter_y1 = std::max(ay1, by1);
float inter_x2 = std::min(ax2, bx2);
float inter_y2 = std::min(ay2, by2);
float inter_w = std::max(0.0f, inter_x2 - inter_x1);
float inter_h = std::max(0.0f, inter_y2 - inter_y1);
float inter_area = inter_w * inter_h;
float area_a = std::max(0.0f, a.w) * std::max(0.0f, a.h);
float area_b = std::max(0.0f, b.w) * std::max(0.0f, b.h);
return inter_area / (area_a + area_b - inter_area + 1e-6f);
}为了节约算力,通常seg计算IoU不使用掩膜进行计算,直接使用Box NMS,该计算方法也是传统目标检测时使用的nms计算方法。只有一些特殊后处理或精细化算法,才会用 mask IoU。
后处理
后处理需要根据自己的需求改变解析出来的值,比如旋转角是传角度还是弧度,夹取物体时是否需要使用掩膜计算出不规则物体的质心而非中心点,以及一个坐标的还原等。
yolo-obb
cv::RotatedRect rRect(cv::Point2f(real_cx, real_cy), cv::Size2f(real_w, real_h), angle_deg);通常可以使用上述代码构建出旋转矩形以可视化。
yolo-seg--二值掩膜
由于上述nms直接使用Box NMS来输出的候选框,而如果需要还原预测物体的整体形状,则需要使用二值掩膜。
二值掩膜
二值掩膜是为了更为精确的描述目标的轮廓区域。通过yolo-seg预测出来的图像,其会生成一个掩膜矩阵,其每一个像素点都是0-1之间的某个概率,通过一个阈值,将其变化为二值结果,即一张0和1的mask图,用以表示那些像素属于目标,那些像素不属于目标。
再置信度过滤和nms后,保留下来的目标中,拿到对应目标的掩膜矩阵(相当于output1去掉最高维),然后再通过output0拿到对应目标的掩模系数(32×N),现在的N由于置信度过滤和nms,其值已经非常小,然后将两个取得的矩阵加权求和,并做归一化,最后resize回原图大小,同时取出其有效位置,并做阈值处理得出最后的二值掩膜矩阵。
cv::Mat BuildMaskBinary(
const std::vector<float>& mask_coeff,
Ort::Value& proto_tensor,
int input_width,
int input_height,
const cv::Rect& box,
float mask_threshold = 0.5f) {
// 创建二值掩膜矩阵
cv::Mat mask_binary = cv::Mat::zeros(input_height, input_width, CV_8UC1);
// 取出output1
auto proto_info = proto_tensor.GetTensorTypeAndShapeInfo();
std::vector<int64_t> proto_shape = proto_info.GetShape();
// output1不是4维或者掩膜系数为空
if (proto_shape.size() != 4 || mask_coeff.empty()) {
return mask_binary;
}
// 取得掩膜系数维度
int mask_dim = static_cast<int>(mask_coeff.size());
// 判断输出格式
bool is_chw = proto_shape[1] == mask_dim;
bool is_hwc = proto_shape[3] == mask_dim;
if (!is_chw && !is_hwc) {
return mask_binary;
}
// 取出掩膜高和宽并计算矩阵框面积
int mask_h = is_chw ? static_cast<int>(proto_shape[2]) : static_cast<int>(proto_shape[1]);
int mask_w = is_chw ? static_cast<int>(proto_shape[3]) : static_cast<int>(proto_shape[2]);
int mask_area = mask_h * mask_w;
// 取出掩膜系数的首地址
float* proto_data = proto_tensor.GetTensorMutableData<float>();
// 构建掩膜系数矩阵
cv::Mat mask_prob(mask_h, mask_w, CV_32FC1);
// 对每个像素位置,把32个基础掩膜值(掩膜宽×掩膜高)按32个掩膜系数加权求和
for (int y = 0; y < mask_h; ++y) {
// 取得矩阵第y行数据
float* row = mask_prob.ptr<float>(y);
for (int x = 0; x < mask_w; ++x) {
float value = 0.0f;
for (int k = 0; k < mask_dim; ++k) {
float proto_value = 0.0f;
// 第k个掩模通道的第y行第x列
if (is_chw) {
// [batch, height, weight]
proto_value = proto_data[k * mask_area + y * mask_w + x];
}
else {
// [height, weight, batch]
proto_value = proto_data[(y * mask_w + x) * mask_dim + k];
}
// 加权求和
value += mask_coeff[k] * proto_value;
}
// 第y行第x列数据归一化到[0, 1]
row[x] = sigmoid(value);
}
}
// resize回原图大小
cv::Mat mask_resized;
cv::resize(mask_prob, mask_resized, cv::Size(input_width, input_height), 0, 0, cv::INTER_LINEAR);
// 裁剪有效目标框
cv::Rect image_rect(0, 0, input_width, input_height);
cv::Rect valid_box = box & image_rect;
if (valid_box.width <= 0 || valid_box.height <= 0) {
return mask_binary;
}
// 仅获取目标区域掩膜得到概率图
cv::Mat roi_prob = mask_resized(valid_box);
cv::Mat roi_binary_float;
// 二值化并写入mask_binary
cv::threshold(roi_prob, roi_binary_float, mask_threshold, 255.0, cv::THRESH_BINARY);
roi_binary_float.convertTo(mask_binary(valid_box), CV_8UC1);
return mask_binary;
}上述代码仅针对于单张图像而言,如果有多张图像,需要加入不同图像的偏移
OCR字符识别--LPRNet
输出排列格式
LPRNet创建输出为三维矩阵1, 字符串类别数, 序列长度或1, 序列长度, 字符串别数
1:批次数量
字符串类别数:所有字符串类别数量,通常包含空白字符
序列长度:模型把车牌横向分成多少个识别位置
这个输出维度必须和模型的预训练中相同
if (output_shape.size() != 3) {
return "";
}
int dim1 = static_cast<int>(output_shape[1]);
int dim2 = static_cast<int>(output_shape[2]);
int num_classes = 0;
int sequence_length = 0;
bool class_first = false;
if (dim1 == static_cast<int>(charset.size())) {
num_classes = dim1;
sequence_length = dim2;
class_first = true;
}
else if (dim2 == static_cast<int>(charset.size())) {
num_classes = dim2;
sequence_length = dim1;
class_first = false;
}
else {
return "";
}准备字符表
模型输出的是字符编号,而非直接输出汉字或字母,因此需要定义一个字符表,而这个字符表的定义也必须和模型的预训练中相同。
这个字符表的长度也是上面输出排列格式中字符串类别数的长度,其中不一定含有空白字符,这需要根据你预训练时来更改。
// 准备字符表
vector<string> charset = {
"京","沪","津","渝","冀","晋","蒙","辽","吉","黑",
"苏","浙","皖","闽","赣","鲁","豫","鄂","湘","粤",
"桂","琼","川","贵","云","藏","陕","甘","青","宁","新",
"0","1","2","3","4","5","6","7","8","9",
"A","B","C","D","E","F","G","H","J","K","L","M",
"N","P","Q","R","S","T","U","V","W","X","Y","Z",
"0","-"
};找出空白字符编码
LPRNet通常使用类似连接时序分类的解码方式,所以字符表里通常会有一个空白字符。空白字符不是车牌内容,只是模型用来表示该位置没有明确字符。
// 找出空白字符编码
int blank_index = static_cast<int>(charset.size()) - 1;如上述字符表中,最后一个元素"-"便是空白字符。
CTC解码
每个序列取最大分数字符
LPRNet预测是将整个车牌分成"序列长度"的长度,每个"序列长度"都对应了"字符串类别数"个值,每个"字符串类别数"都是一个概率,因此需要在每个"序列长度"位置都选取分数最高的以一个字符串。
去掉连续重复字符&&去掉空白字符
去掉空白字符是max_class_id != blank_index,去掉连续重复字符是max_class_id != last_class_id
如果没有很好的理解这个原理,可能会觉得如果车牌为连续数字888这种,如果直接去掉连续字符会导致类似于这样的连续重复字符无法输出,甚至直接导致车牌位数的缺失。
但其实last_class_id是根据max_class_id来改变的,而每个字符之间一定存在一个空白字符,类似于上面的888车牌,其实真实模型的输出应该为88空白88空白8...,因此并不会出现上述车牌位数缺失的问题。
按字符表转成字符串
时间序列预测--TCN
TCN主要做取的事情是分类、回归预测、序列预测,其基本都是通过TCN神经网络来拟合一段数据以预测后续数据,因此其后处理通常都十分简单。这里我主要讲解器序列预测的输出格式。
输出排列格式
TCN创建输出为三维序列张量batch, feature_dim, sequence_length
batch:数据批次
feature_dim:预测特征数量
sequence_length:连续时间点
获取输出数据元素总数
// 获取输出元素总数
size_t output_size = 1;
for (auto dim : output_shape) {
output_size *= static_cast<size_t>(dim);
}获取输出数据
// 获取输出数据
vector<float> result(output_size);
for (size_t i = 0; i < output_size; ++i) {
result[i] = output_data[i];
}总结
虽然各个模型之间的后处理不同,但是其总体的环境设置、推理等都是一样。
而相同模型的不同格式则恰好相反,其后处理基本不变,但是其模型的环境、推理则不一样。
同时不同模型格式还需要注意在量化模型时,是否将nms等这些算法直接嵌入进模型了,如果嵌入则后续无需使用nms来进行后处理。同时不同格式的模型输出格式也可能不同,这也是我上面在讲解输出排列格式是使用了两个情况的原因。
因此模型不同也好,格式不同也好,都需要以实际输出内容为主,需要根据不同的嵌入式设备、模型导出格式等来进行调整。