窗口函数
窗口函数出现于20世纪90年代后半期,在21世纪初得到了Oracle、DB2和SQL Server等DBMS的支持。随着2017年MySQL也开始支持窗口函数,现在的主流DBMS中就都可以使用窗口函数了。如果熟练掌握了窗口函数,从某种意义上来说,我们就可以像使用面向过程语言那样操作数据。窗口函数能够大幅扩展SQL编程的可能性,是一个非常重要的工具。
1、概述
首先,初次见到窗口函数的人会觉得这个名字有些不可思议。大家可能会想象这个函数是使用了某种类似于"窗口"的东西,但看到语法示例时,却发现并没有哪句代码表明了"这是窗口",只看到那些使用了PARTITION BY子句或ORDER BY子句的查询示例。
我们来看一下窗口函数的典型用例------计算移动平均值的语法的示例。
sql
CREATE TABLE Products (
products_id CHAR(4) NOT NULL,
products_name VARCHAR(100) NOT NULL,
products_type VARCHAR(32) NOT NULL,
sale_price INTEGER ,
incoming_price INTEGER ,
registration_date DATE ,
PRIMARY KEY (products_id)
);
INSERT INTO Products VALUES ('0001', 'T恤衫' ,'衣服', 1000, 500, '2009-09-20');
INSERT INTO Products VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Products VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO Products VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO Products VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO Products VALUES ('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO Products VALUES ('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO Products VALUES ('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
sql
--匿名窗口
SELECT products_id, products_name, sale_price,
AVG (sale_price) OVER (ORDER BY products_id ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg
FROM Products;
+-------------+---------------+------------+------------+
| products_id | products_name | sale_price | moving_avg |
+-------------+---------------+------------+------------+
| 0001 | T恤衫 | 1000 | 1000.0000 |
| 0002 | 打孔器 | 500 | 750.0000 |
| 0003 | 运动T恤 | 4000 | 1833.3333 |
| 0004 | 菜刀 | 3000 | 2500.0000 |
| 0005 | 高压锅 | 6800 | 4600.0000 |
| 0006 | 叉子 | 500 | 3433.3333 |
| 0007 | 擦菜板 | 880 | 2726.6667 |
| 0008 | 圆珠笔 | 100 | 493.3333 |
+-------------+---------------+------------+------------+上面的代码按商品ID的升序来排列商品表,计算包含当前ID之前的两个商品的价格移动平均值。虽然出现了AVG、OVER、ROWS BETWEEN、CURRENT ROW等窗口函数的关键字,但我们看不到窗口本身的定义。
然而,这并不是说该查询并未使用窗口。实际上,该语法中也定义了窗口,只是操作是悄悄进行的,乍一看会让人以为没有窗口。
显式定义窗口的语法如下所示。
sql
SELECT products_id, products_name, sale_price,
AVG(sale_price) OVER W AS moving_avg
FROM Products
WINDOW W AS (ORDER BY products_id ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);这里显式定义了窗口,并对其应用了AVG函数。这里所说的窗口,就是针对通过FROM子句选择的记录集,使用ORDER BY排序和使用ROWS BETWEEN定义帧之后所形成的数据集。窗口会通过各种可选项对记录集进行数据加工,这就是它和记录集的不同之处。
通过比较这两种语法可以知道,我们常用的窗口函数的语法,是默认使用"匿名窗口"的简略版语法(这与匿名存储过程或匿名函数是一样的)。其优点是内容简练,而带名称的窗口的优点是窗口可以重复使用,能避免编辑错误。这与通过公用表表达式(CTE)重复使用视图,以及在存储过程中定义有名称的存储过程的效果是一样的。
sql
-- 有名称的窗口可以被重复使用
SELECT products_id, products_name, sale_price,
AVG(sale_price) OVER W AS moving_avg,
SUM(sale_price) OVER W AS moving_sum,
COUNT(sale_price)OVER W AS moving_count,
MAX(sale_price) OVER W AS moving_max
FROM Products
WINDOW W AS (ORDER BY products_id ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
+-------------+---------------+------------+------------+------------+--------------+------------+
| products_id | products_name | sale_price | moving_avg | moving_sum | moving_count | moving_max |
+-------------+---------------+------------+------------+------------+--------------+------------+
| 0001 | T恤衫 | 1000 | 1000.0000 | 1000 | 1 | 1000 |
| 0002 | 打孔器 | 500 | 750.0000 | 1500 | 2 | 1000 |
| 0003 | 运动T恤 | 4000 | 1833.3333 | 5500 | 3 | 4000 |
| 0004 | 菜刀 | 3000 | 2500.0000 | 7500 | 3 | 4000 |
| 0005 | 高压锅 | 6800 | 4600.0000 | 13800 | 3 | 6800 |
| 0006 | 叉子 | 500 | 3433.3333 | 10300 | 3 | 6800 |
| 0007 | 擦菜板 | 880 | 2726.6667 | 8180 | 3 | 6800 |
| 0008 | 圆珠笔 | 100 | 493.3333 | 1480 | 3 | 880 |
+-------------+---------------+------------+------------+------------+--------------+------------+匿名窗口和有名称的窗口各有优势,要根据具体情况进行选择,但有一点必须注意,即有的DBMS不支持有名称的窗口,一旦使用就会发生错误插图。人们通常认为有名称的窗口是"正式"的语法,但实际情况恰好相反,被普遍使用的是匿名窗口。
2、一张图看懂窗口函数
前面介绍了窗口函数的定义,下面我们来看一下窗口函数的功能(如下图):
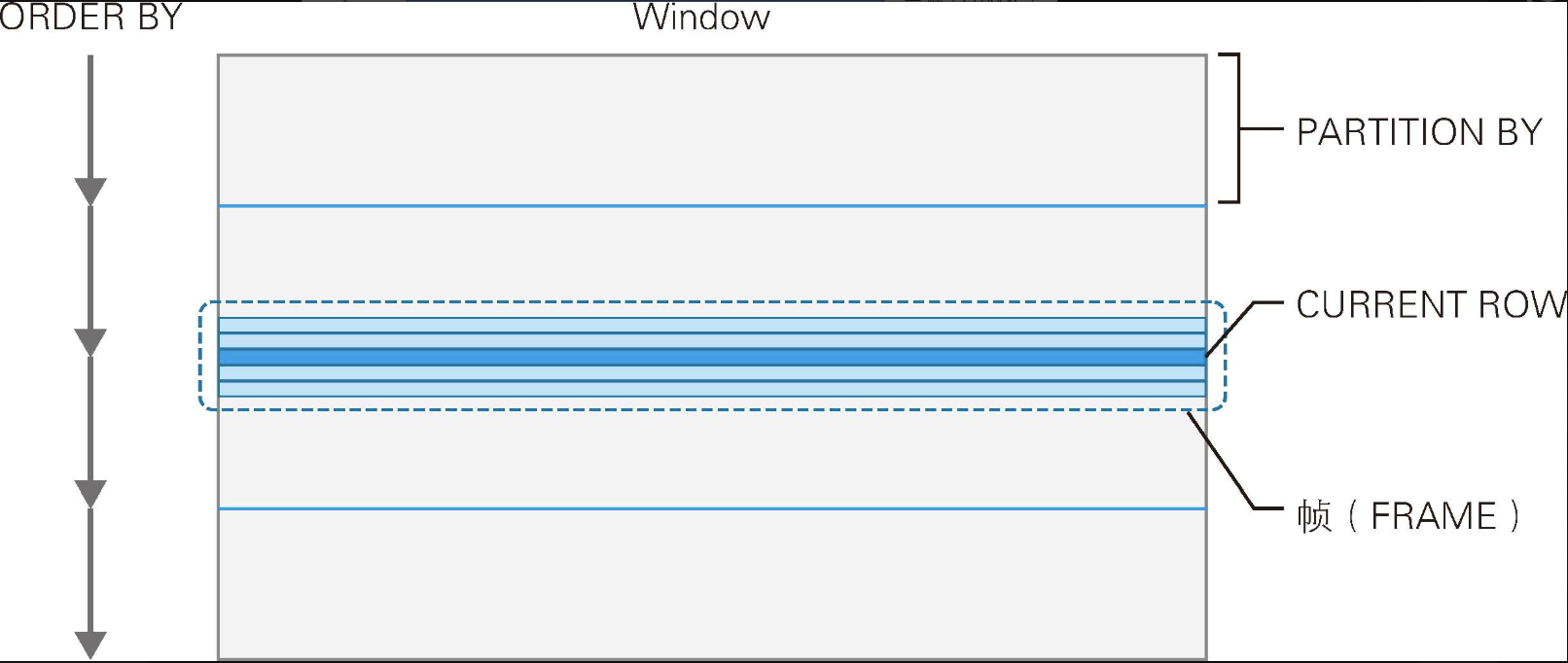
窗口函数让人难以理解的原因之一是1个窗口函数中包含多个操作,而如果像上图那样从整体来看,窗口函数实际上只包含下面3个功能:
- 使用PARTITION BY子句分割记录集合。
- 使用ORDER BY子句对记录排序。
- 使用帧子句定义以当前记录为中心的子集。
其中,第1个功能和第2个功能因为与现有的GROUP BY和ORDER BY的功能几乎一样,所以对于已经掌握SQL基本语法的人来说都很容易理解。
窗口函数真正特有的功能是上面列出的第3个功能。传统的SQL编程中并没有显式地使用"当前记录"的概念。另外,使用关系数据库构建过系统的人应该能立刻注意到,这个"当前记录"源自"游标"(cursor)的引入------关系数据库一直使用游标向面向过程语言传递数据(如下图)。
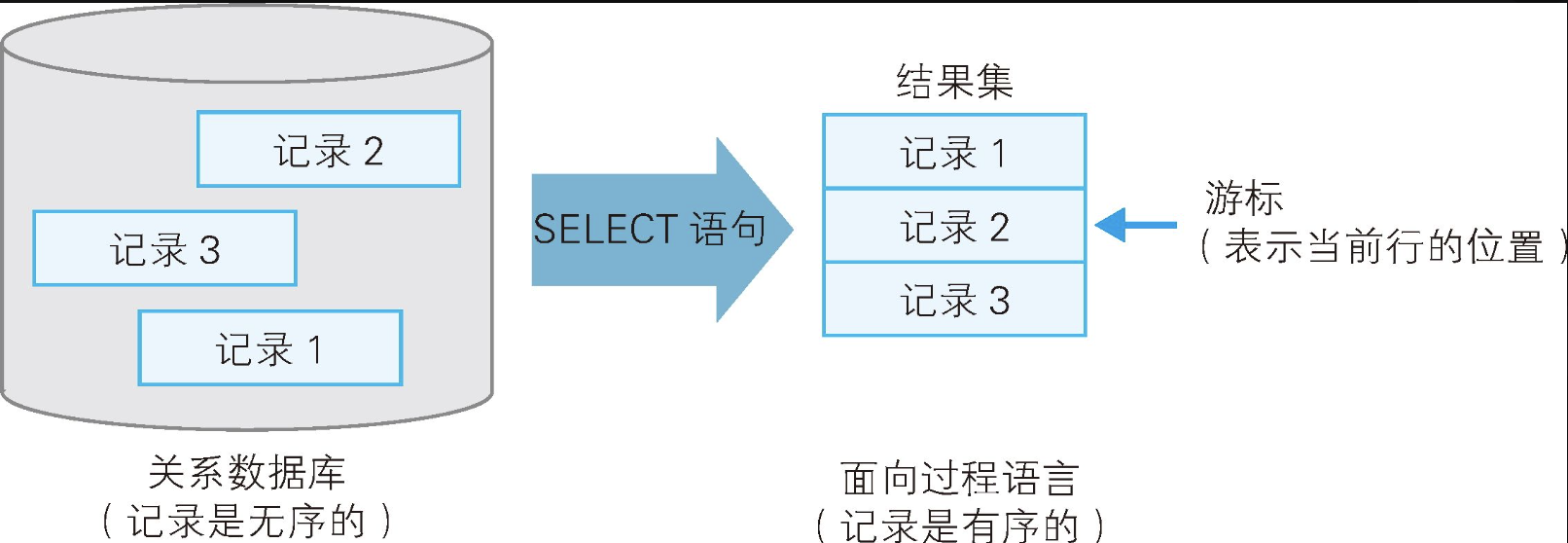
之所以需要游标,是因为关系数据库的表中的记录是无序的,操作的基本单位是记录的集合,也就是一次一集合(set at a time)的操作方式,而面向过程语言的记录是有序的,操作的基本单位是一行记录,也就是是一次一记录(record at a time)的操作方式,我们需要用游标来填补二者之间的差异。
在面向过程语言中,根据键对记录集合进行排序,通过for语句或while语句循环记录集合,一行一行地移动当前记录进行处理,这种操作方法至今都没有变过。即使在引入地址隐藏和面向对象后,也没有发生改变。在这一点上,窗口函数可以说是将面向过程语言的思想引入到了SQL中。
帧子句的作用是能通过SQL简单计算出移动平均值等以当前记录为基准计算的统计指标。除此之外,帧子句还有很广泛的用途。直观来讲,帧子句可以将其他行移至当前行。之前使用SQL进行行间比较很困难,现在则变得很自如。
3、求过去最临近的值
当比较时间序列中的数据时,SQL基本上是沿着时间序列,一行一行地向前追溯或向后推进。作为示例,我们来看一张记录了服务器各个时点的负载量的表LoadSample(这里选用了较为合适的数值作为负载量,大家不用关注其具体含义)。由于采样是不定期的,所以存储的日期并不连续,间隔随机。
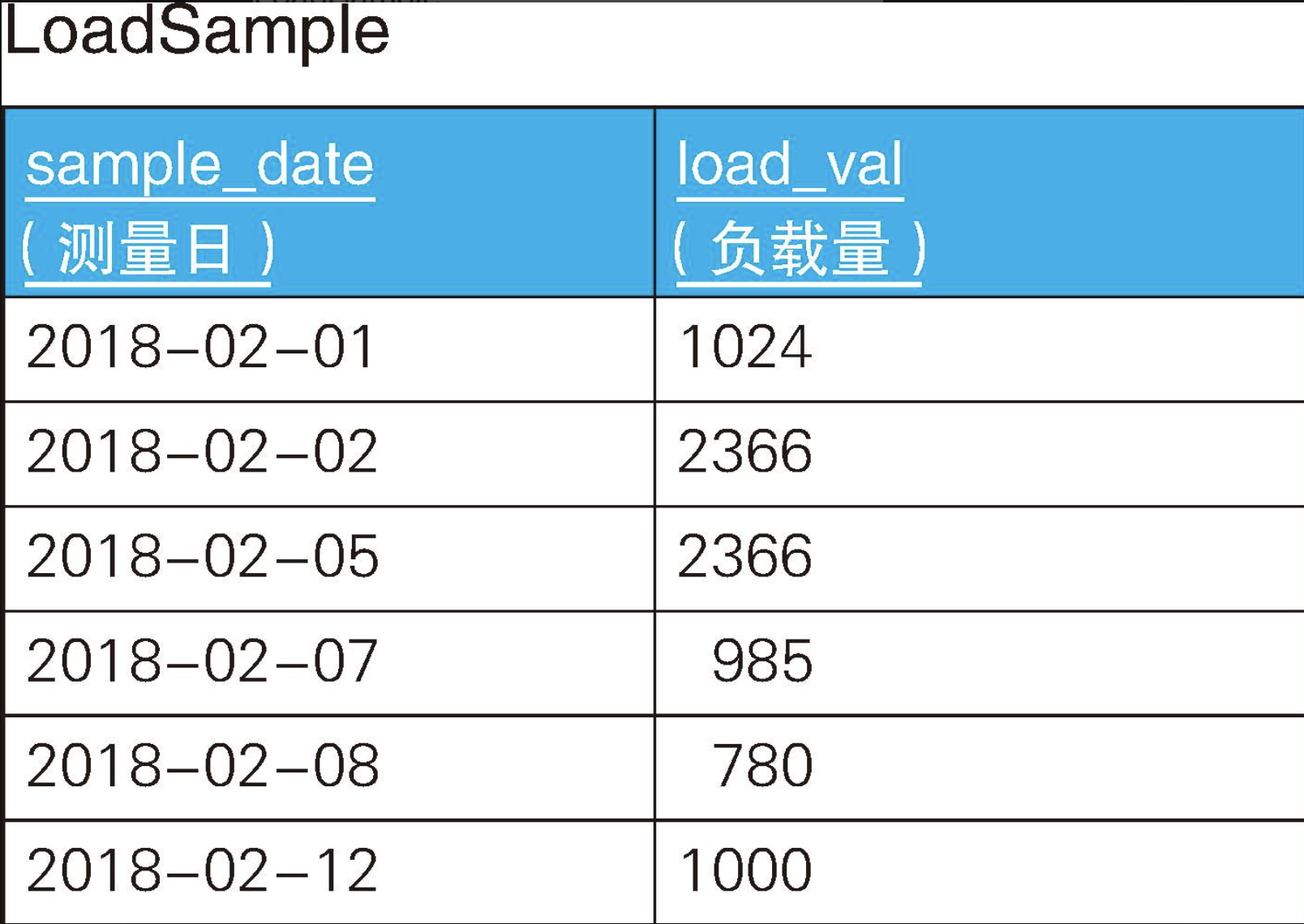
sql
CREATE TABLE LoadSample (
sample_date DATE PRIMARY KEY,
load_val INTEGER NOT NULL
);
INSERT INTO LoadSample VALUES('2018-02-01', 1024);
INSERT INTO LoadSample VALUES('2018-02-02', 2366);
INSERT INTO LoadSample VALUES('2018-02-05', 2366);
INSERT INTO LoadSample VALUES('2018-02-07', 985);
INSERT INTO LoadSample VALUES('2018-02-08', 780);
INSERT INTO LoadSample VALUES('2018-02-12', 1000);首先计算各行的"过去最临近的日期",也就是计算"上一行"的日期。
sql
-- 窗口里永远只包含前一行这一行数据
select
sample_date as cur_date,
min(sample_date) over (order by sample_date rows between 1 preceding and 1 preceding) as latest_date
from LoadSample;
+------------+-------------+
| cur_date | latest_date |
+------------+-------------+
| 2018-02-01 | <null> |
| 2018-02-02 | 2018-02-01 |
| 2018-02-05 | 2018-02-02 |
| 2018-02-07 | 2018-02-05 |
| 2018-02-08 | 2018-02-07 |
| 2018-02-12 | 2018-02-08 |
+------------+-------------+由于该表中并没有2月1日之前的数据,所以2月1日这行之前的日期是NULL。这一点应该不难理解。从2月2日起,每行日期的过去最临近的日期都存在于表中,它们保存在latest列中。该查询的重点是通过ROWS BETWEEN 1PRECEDING AND 1 PRECEDING将帧子句的范围限定在按sample_date排序后的上一行。一般来说,BETWEEN大多用来指定多行的范围,而这里用来将范围限定为一行,自然就不会发生错误。
可以说,这里的帧子句以游标位于"当前行"为前提,创建了范围是"上一行"的记录集合。
除日期之外,计算与日期相对应的负载量也很简单。当前记录的负载量可以直接用load列计算出来。在相同的窗口定义下仅将列修改为load列,就可以计算出上一行的负载量。
sql
SELECT sample_date AS cur_date,
load_val AS cur_load,
MIN(sample_date) OVER (ORDER BY sample_date ASC ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING) AS latest_date,
MIN(load_val) OVER (ORDER BY sample_date ASC ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING) AS latest_load
FROM LoadSample;
+------------+----------+-------------+-------------+
| cur_date | cur_load | latest_date | latest_load |
+------------+----------+-------------+-------------+
| 2018-02-01 | 1024 | <null> | <null> |
| 2018-02-02 | 2366 | 2018-02-01 | 1024 |
| 2018-02-05 | 2366 | 2018-02-02 | 2366 |
| 2018-02-07 | 985 | 2018-02-05 | 2366 |
| 2018-02-08 | 780 | 2018-02-07 | 985 |
| 2018-02-12 | 1000 | 2018-02-08 | 780 |
+------------+----------+-------------+-------------+这段代码中出现了两次相同的窗口定义。如果使用有名称的窗口语法,就可以像下面这样将窗口函数汇总为一个(结果是一样的)。
sql
SELECT sample_date AS cur_date,
load_val AS cur_load,
MIN(sample_date)OVER W AS latest_date,
MIN(load_val) OVER W AS latest_load
FROM LoadSample
WINDOW W AS (ORDER BY sample_date ASC ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING);除向前移动之外,帧还可以向"后"移动:这时要使用FOLLOWING关键字。例如,在过去最临近的值的查询中,将帧的范围向后移动一行。
sql
SELECT sample_date AS cur_date,
load_val AS cur_load,
MIN(sample_date)OVER W AS next_date,
MIN(load_val) OVER W AS next_load
FROM LoadSample
WINDOW W AS (ORDER BY sample_date ASC ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING);
+------------+----------+------------+-----------+
| cur_date | cur_load | next_date | next_load |
+------------+----------+------------+-----------+
| 2018-02-01 | 1024 | 2018-02-02 | 2366 |
| 2018-02-02 | 2366 | 2018-02-05 | 2366 |
| 2018-02-05 | 2366 | 2018-02-07 | 985 |
| 2018-02-07 | 985 | 2018-02-08 | 780 |
| 2018-02-08 | 780 | 2018-02-12 | 1000 |
| 2018-02-12 | 1000 | <null> | <null> |
+------------+----------+------------+-----------+这次在next_date和next_load列中显示将来最临近的日期的记录值。
另外,同时使用PRECEDING和FOLLOWING,将当前记录夹在中间,还可以设置范围为"前后各 n行"的帧。
**这里使用了MIN函数,请问它有什么含义呢?**如果是像示例这样将帧的范围限定为一行,那么MIN并没有什么特别的含义。即使使用的是MAX、AVG或SUM,结果也是一样的,因为这相当于对一行应用聚合函数。如果帧的范围是多行,就需要应用相应的聚合函数了。
sql
-- 执行结果与使用 MIN 函数时相同
SELECT sample_date AS cur_date,
load_val AS cur_load,
MAX(sample_date) OVER W AS latest_date,
MAX(load_val) OVER W AS latest_load
FROM LoadSample
WINDOW W AS (ORDER BY sample_date ASC ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING);
+------------+----------+-------------+-------------+
| cur_date | cur_load | latest_date | latest_load |
+------------+----------+-------------+-------------+
| 2018-02-01 | 1024 | <null> | <null> |
| 2018-02-02 | 2366 | 2018-02-01 | 1024 |
| 2018-02-05 | 2366 | 2018-02-02 | 2366 |
| 2018-02-07 | 985 | 2018-02-05 | 2366 |
| 2018-02-08 | 780 | 2018-02-07 | 985 |
| 2018-02-12 | 1000 | 2018-02-08 | 780 |
+------------+----------+-------------+-------------+**可以设置"一天前"或"两天前"这样基于列值(而不是行)的帧吗?**可以。这时要使用RANGE关键字来代替ROWS。
sql
SELECT sample_date AS cur_date,
load_val AS cur_load,
MIN(sample_date) OVER (ORDER BY sample_date ASC
RANGE BETWEEN interval '1' day PRECEDING
AND interval '1' day PRECEDING
) AS day1_before,
MIN(load_val) OVER (ORDER BY sample_date ASC
RANGE BETWEEN interval '1' day PRECEDING
AND interval '1' day PRECEDING
) AS load_day1_before
FROM LoadSample;
+------------+----------+-------------+------------------+
| cur_date | cur_load | day1_before | load_day1_before |
+------------+----------+-------------+------------------+
| 2018-02-01 | 1024 | <null> | <null> |
| 2018-02-02 | 2366 | 2018-02-01 | 1024 |
| 2018-02-05 | 2366 | <null> | <null> |
| 2018-02-07 | 985 | <null> | <null> |
| 2018-02-08 | 780 | 2018-02-07 | 985 |
| 2018-02-12 | 1000 | <null> | <null> |
+------------+----------+-------------+------------------+表LoadSample中的数据不是连续的,如果没有一天前的数据,day1_before列和load_day1_before列中就会显示NULL。这样看起来比较直观。
下面是帧子句中可以使用的选项,大家可以参考。
ROWS:按行设置移动单位RANGE:按列值设置移动单位。使用ORDER BY子句来指定基准列n PRECEDING:仅向前(行号较小的方向)移动n行。n为正整数n FOLLOWING:仅向后(行号较大的方向)移动n行。n为正整数UNBOUNDED PRECEDING:一直移动到最前面UNBOUNDED FOLLOWING:一直移动到最后面CURRENT ROW:当前行
4、行间比较的一般化
现在这样已经可以求出过去最临近的日期了,但在实际工作中,人们还可能希望将比较范围再扩大一些,比如将某个日期与其"过去最临近的日期"或"过去第二临近的日期"进行比较,甚至与"前面 n行的日期"进行比较。这就是行间比较的一般化。
为了满足该需求,我们首先要思考如何以某个日期为起点开始依次追溯之前的日期。假设我们先追溯前面三个临近的日期,那么结果会像下页这样呈阶梯形。之所以会呈现出这种形状,是因为当追溯的日期数据不存在时,数据为NULL。
sql
-- 设想的执行结果
cur_date latest_1 latest_2 latest_3
-------- -------- -------- --------
2018-02-01
2018-02-02 2018-02-01
2018-02-05 2018-02-02 2018-02-01
2018-02-07 2018-02-05 2018-02-02 2018-02-01
2018-02-08 2018-02-07 2018-02-05 2018-02-02
2018-02-12 2018-02-08 2018-02-07 2018-02-05求解的窗口函数如下所示。
sql
SELECT sample_date AS cur_date,
MIN(sample_date) OVER (ORDER BY sample_date ASC
ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING) AS latest_1,
MIN(sample_date) OVER (ORDER BY sample_date ASC
ROWS BETWEEN 2 PRECEDING AND 2 PRECEDING) AS latest_2,
MIN(sample_date) OVER (ORDER BY sample_date ASC
ROWS BETWEEN 3 PRECEDING AND 3 PRECEDING) AS latest_3
FROM LoadSample;这里只是将BETWEEN的指定行修改为"前一行""前两行""前三行"......实现起来非常简单。不管是前几行,我们都可以使用相同的方法进行扩展。在这种情况下,可能有人认为可以使用有名称的窗口来汇总定义,但是很遗憾,由于帧的定义不一样,这一点无法实现。
5、窗口函数的内部动作
前面介绍过,窗口函数拥有下面3个功能。
- 使用PARTITION BY子句分割记录集合。
- 使用ORDER BY子句对记录排序
- 使用帧子句定义以当前记录为中心的子集。
查看SQL语句内部动作的手段通常是查看"执行计划"(execution plan)。所谓执行计划,其实就是一份由数据库提供的计划书,以帮助我们确定DBMS在执行SQL语句时,以什么样的访问路径获取数据、执行什么样的计算是最高效的。可以说,它就像是一份用来判断登山路线的参考书。
虽然执行计划的格式会随DBMS的不同而发生改变,但只要是经过一定培训的人,应该就能看懂。因此,当SQL语句执行较慢时,我们就要输出并解析执行计划,查明原因并进行优化(SQL语句越复杂,执行计划就越复杂,解析也就越辛苦)。
sql
EXPLAIN SELECT
products_id,
products_name,
sale_price,
AVG (sale_price) OVER (ORDER BY products_id
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg
FROM Products \G;
***************************[ 1. row ]***************************
id | 1
select_type | SIMPLE
table | Products
partitions | <null>
type | ALL
possible_keys | <null>
key | <null>
key_len | <null>
ref | <null>
rows | 8
filtered | 100.0
Extra | Using filesort执行计划的含义都是扫描(读取)表Products的数据,并对读取的数据进行排序。PostgreSQL的执行计划中出现了SORT关键字,MySQL的执行计划中出现了Using filesort关键字,它们都表示排序。
6、窗口函数的本质是排序
之所以要在窗口函数中进行排序,是出于使用PARTITION BY子句进行分组和使用ORDER BY子句对记录排序时的需要。在关系数据库中,表的记录并不一定是物理排序的,因此一般来说,如果要基于键值对记录排序,就需要先对记录集合进行排序。
所谓"进行排序",就是执行使用for语句或while语句的循环。虽然我们无法根据执行计划确定使用的是什么排序算法,但不管是快速排序,还是归并排序,在面向过程语言中通常都是通过循环来实现的。实际上,如果大家不使用SQL而使用面向过程语言,对CSV或文本文件等适当形式的数据执行与窗口函数同样的计算,使用循环进行排序也可以解决问题。
不过,排序作为窗口函数的实现方法在性能方面是否最优,也存在不同的意见。在图1.2.1的边注所提到的论文中,实际的测试结果显示从原理上来说,某些情况下使用散列来计算PARTITION BY子句的性能会更好。
散列函数拥有这样的特性:若输入值不同,输出值基本上也不会一样(值不会重复)。该输出值称为散列值。下图展示了"30"→"cdae7jh02"的转换。成对的输入值和散列值称为散列表。使用散列表进行分组,就可以在不进行排序的情况下执行聚合操作(虽然输入值不转换为散列值也可以进行分组,但散列值的优点是无须在意列数或 数据类型,即可使用各种需要输入散列值的函数)。
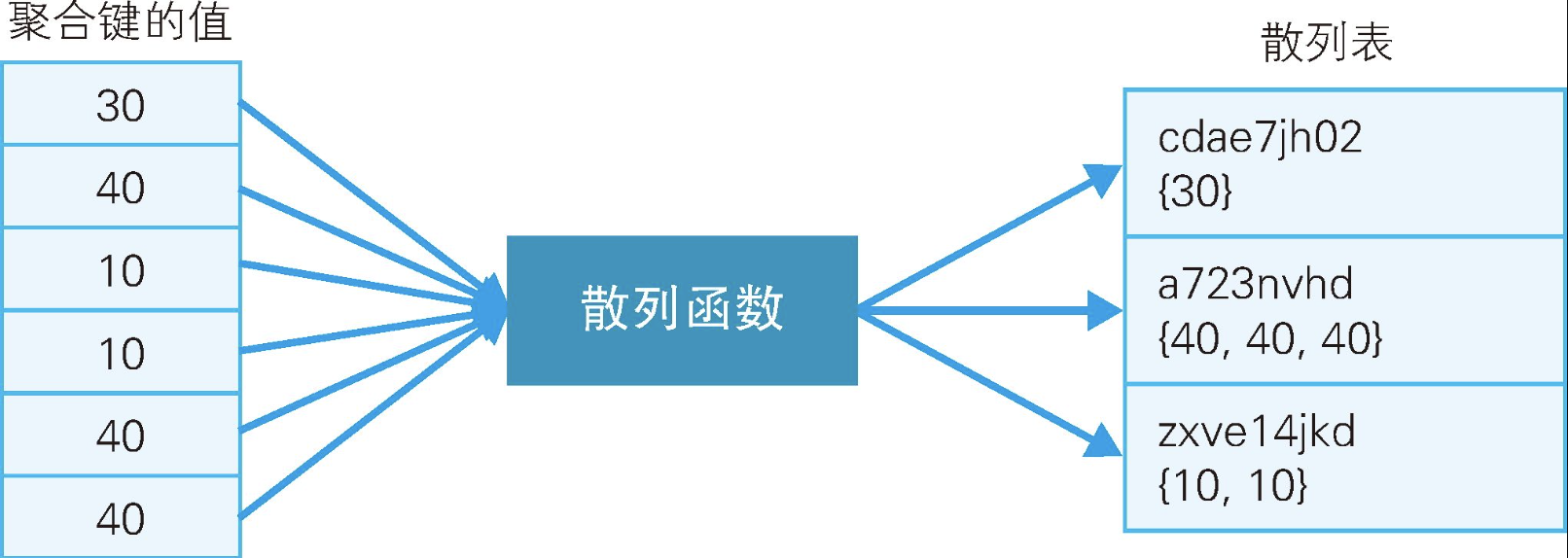
实际上,GROUP BY子句的功能与PARTITION BY子句的功能几乎是一样的。在Oracle或PostgreSQL中,GROUP BY子句除排序之外,还可以使用散列进行计算。不过,前述论文中也指出,散列要想发挥优势是有几个前提的,并不是说它在任何情况下都有优势。或许,窗口函数早晚有一天会像GROUP BY子句那样能使用散列进行计算。