Claude Sonnet 5 上线:别再让 Claude Code 一律烧 Opus
6 月 30 日,Anthropic 发布 Claude Sonnet 5。
如果你平时用 Claude Code,这条消息不应该只理解成"又来了一个更强模型"。
它真正影响的是一个更具体的团队决策:以后 Claude Code 到底什么时候用 Sonnet,什么时候用 Opus,什么时候必须让人接管?
我的判断很直接:
不要全员默认 Opus。
也不要一听 Sonnet 5 便宜、上下文长,就把所有 Agent 任务都切过去。
更稳的做法,是给 Claude Code 建一张模型路由表:日常修 bug、补测试、解释模块,让 Sonnet 5 先跑;跨模块重构、权限逻辑、安全边界、生产事故,保留 Opus 或人工主导。
这篇不做"Sonnet 5 是否秒杀 Opus"的标题党。它更像一张团队迁移清单:如果你准备把 Claude Code 更深地放进开发流程,先把这 5 件事想明白。
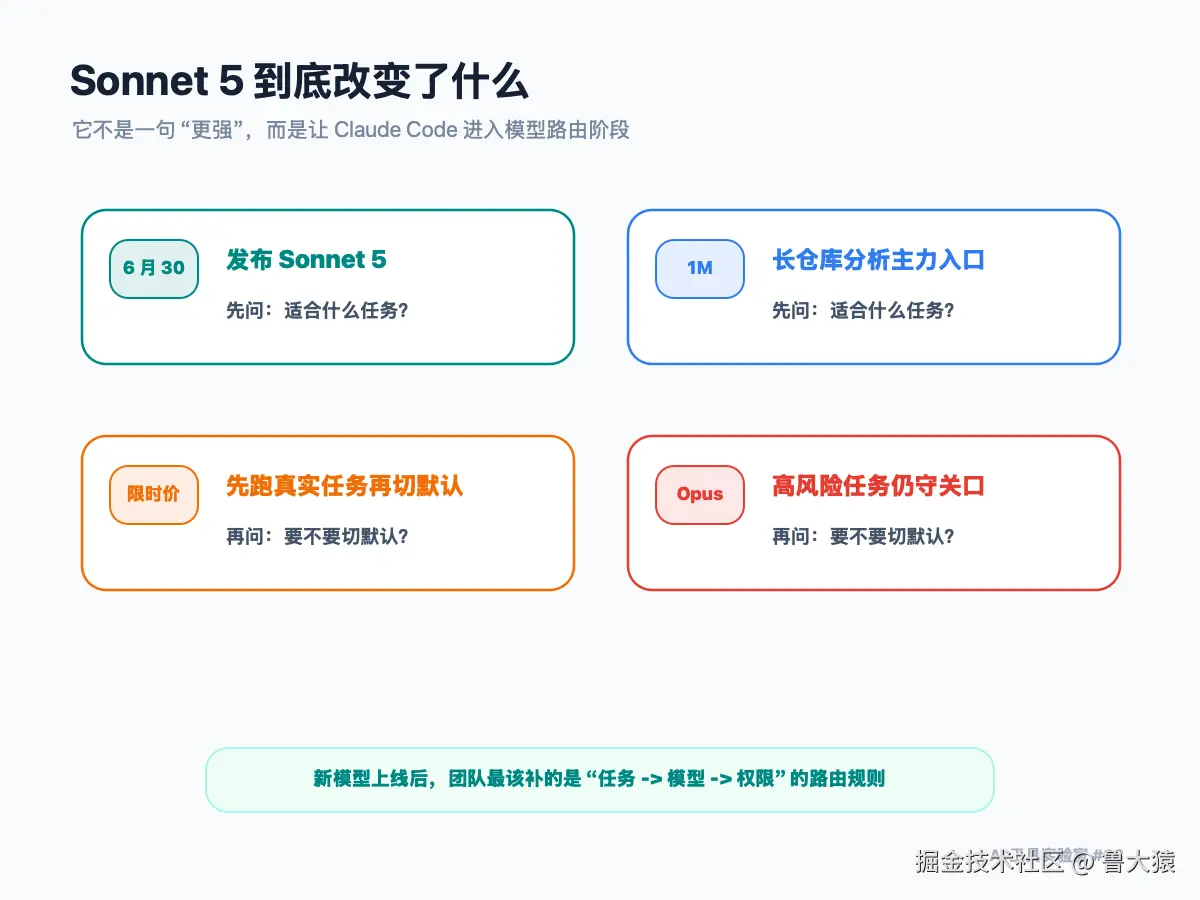
新模型上线,最先要改的是默认思路
官方文档里,Sonnet 5 的定位很清楚:这是面向多数开发任务的主力模型,支持 1M context,最大输出 128K token,并且在 8 月 31 日前有一段限时价格。
同一份模型文档里,Opus 4.8 仍然被放在复杂推理和 agentic coding 场景里。
这说明一个现实问题:
Claude Code 不是只能选"最强模型"。
它更像一个工具调度器。
一个任务只改 Controller 参数校验,让 Opus 全仓扫描,可能是浪费。
一个任务要动权限模型、数据迁移、异步任务、支付链路,让 Sonnet 直接大改,又可能是冒险。
以前很多团队的做法太粗:
预算紧,就全用便宜模型。
风险高,就全开最强模型。
但 AI 编程真正进入团队以后,这两个策略都会出问题。
前者容易把复杂任务交给不该独立做决定的模型。
后者会把大量日常任务变成高成本后台消耗。
Claude Code 应该有模型路由,不是模型信仰
我建议团队把 Claude Code 的任务先分成五类。
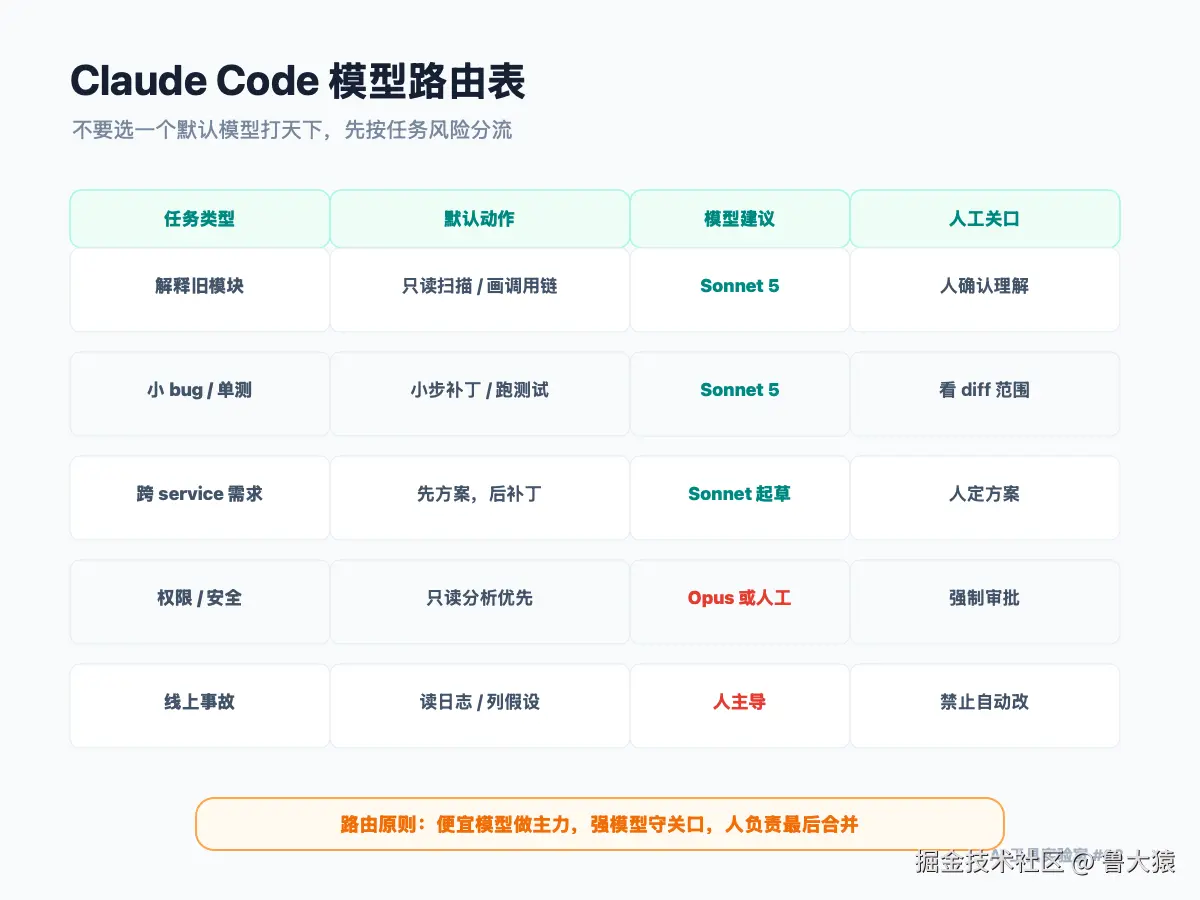
第一类,解释型任务。
比如读一个旧模块、梳理调用链、解释为什么某个接口会报错、整理测试入口。
这类任务优先给 Sonnet 5。它的价值是快速把上下文摊开,让人少花半天找入口。
第二类,小步修复。
比如参数校验、空指针、异常文案、单测补齐、小范围前端交互。
这类任务也可以先给 Sonnet 5,但要限制 diff 范围,要求输出测试证据。
第三类,跨文件改造。
比如新增接口、改领域对象、改缓存逻辑、改定时任务、改一段被多人复用的 service。
这里不能只看模型能力,要看 reviewer 成本。Sonnet 可以起草方案和小步补丁,但关键决策要让人确认。
第四类,高风险边界。
权限、密钥、生产配置、CI/CD、数据迁移、支付、审计、风控、安全策略。
这类任务不要交给"默认模型自动完成"。可以让 Opus 做方案推演,也可以让 Sonnet 做只读分析,但最终必须人工主导。
第五类,事故和线上问题。
这类任务最忌讳 Agent 自信地边猜边改。
模型可以帮你读日志、列假设、生成回滚检查单,但不要让它在没有边界的情况下直接改生产相关代码。
成本不能只看每百万 token 的价格
Sonnet 5 的价格优势会让很多团队心动。
但 AI 编程成本不是模型单价乘以 token 数这么简单。
真正要算的是三笔账:
生成成本。
返工成本。
Reviewer 成本。

如果一个任务 Sonnet 5 生成很快,但改动范围失控,reviewer 看半小时还不敢合并,它就不便宜。
如果一个任务 Opus 一次跑完,但输出了过度设计、无关重构、复杂测试环境要求,它也不一定划算。
团队真正应该记录的是:
这个任务花了多少轮对话?
改了多少文件?
人类 reviewer 花了多久?
测试有没有一次跑通?
有没有因为 AI 输出引入二次返工?
一周之后,你会发现模型路由不是拍脑袋决定的。
有些仓库、任务、语言栈确实适合 Sonnet 5 做主力。
有些核心模块即使用 Opus,也必须先让人拆任务和定验收。
升级前,先跑一周真实任务板
如果团队准备把 Claude Code 默认模型调整到 Sonnet 5,我建议不要开会争论。
直接拿一周真实任务跑一张测试板。
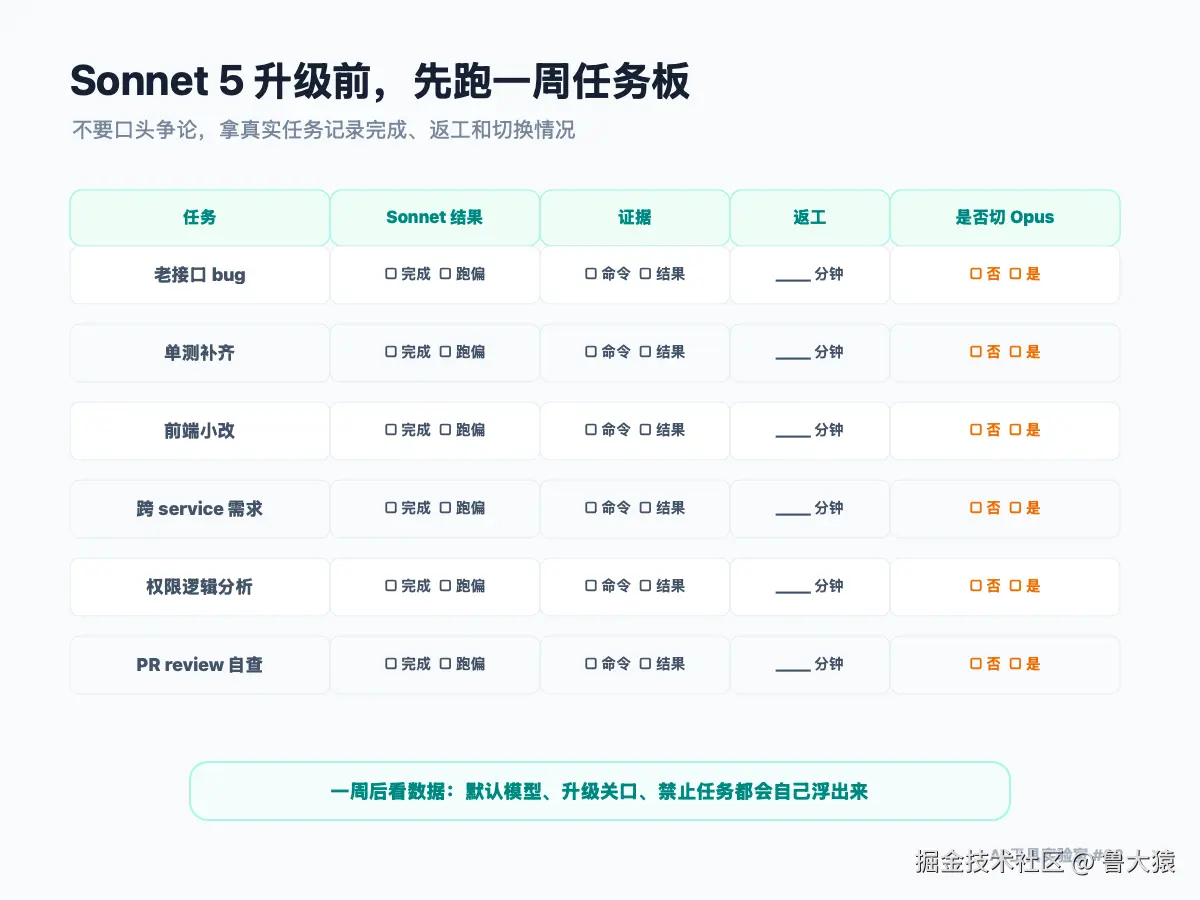
选 6 类任务:
一个老接口 bug。
一个单测补齐。
一个小型前端改动。
一个跨 service 的后端需求。
一个安全或权限相关分析。
一个 PR review 自查。
每个任务只记录 5 个结果:
是否完成。
改动是否收敛。
测试证据是否可用。
reviewer 返工多久。
是否需要切换到 Opus 或人工接管。
这张表跑完,比任何"模型很强"的评价都有用。
它会告诉你:Sonnet 5 在你们项目里能不能当默认工作马,Opus 应该保留在哪些关口,哪些任务根本不该让 Agent 自动改。
模型变强,不代表权限也要变大
很多团队升级模型时,只盯能力,不改权限。
这是最危险的地方。
模型越强,越应该收紧默认权限。
Claude Code 官方文档本来就支持模型配置、权限配置和允许模型列表。团队可以把这些东西当成工程控制面,而不是个人偏好。
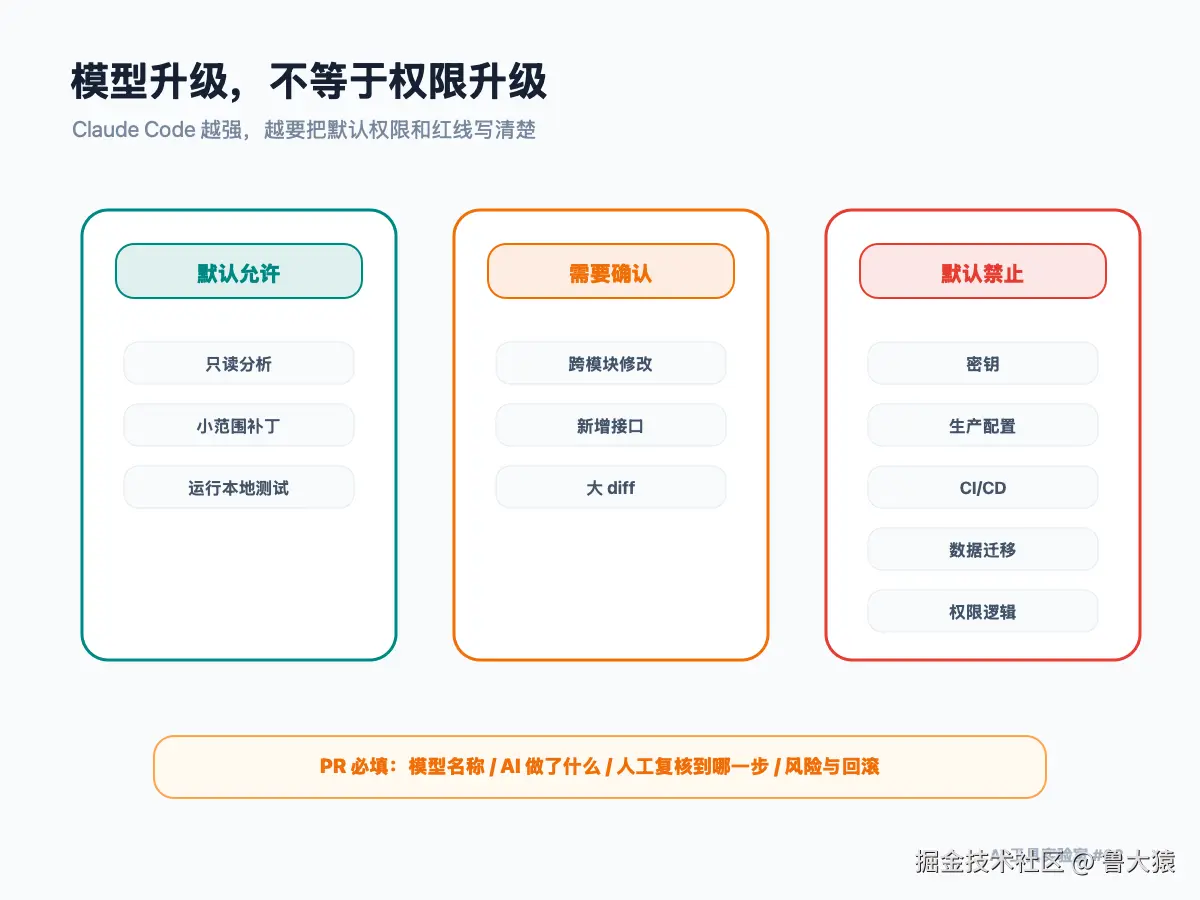
我的建议是:
Sonnet 5 默认只做低风险开发任务。
跨模块修改必须先出方案,再小步 patch。
Opus 用在复杂方案、架构推演、疑难问题复盘,不要默认拿来扫所有日常任务。
高风险目录和生产配置,默认禁止 AI 修改。
PR 里必须写清楚使用了哪个模型、做了哪部分、人工复核到哪一步。
这不是给 AI 降速。
这是让 AI 的速度能进团队流程。
没有路由,没有权限,没有证据,Claude Code 再强也只是个人玩具。
有了路由、权限和验收,它才可能变成团队基础设施。
最后的判断
Claude Sonnet 5 的重点,不是让程序员又多背一个模型名字。
它更像一次提醒:
AI 编程工具已经进入"模型调度"阶段。
以后团队不只要回答"用不用 Claude Code"。
还要回答:
什么任务用 Sonnet?
什么任务用 Opus?
什么任务只读分析?
什么任务必须人工接管?
什么任务不允许 AI 碰?
如果你现在还只会在设置里选一个默认模型,接下来很容易遇到两个问题:
要么为了省钱,把复杂任务交给便宜模型硬跑。
要么为了省心,把日常任务全交给贵模型硬烧。
这两种都不是成熟团队的用法。
成熟用法是:让模型按任务分工,让权限按风险分级,让 PR 按证据验收。
下一篇 AI 工具实验室,我更想做一个实际对比:同一个 Java 接口改造任务,让 Claude Code 的 Sonnet / Opus 路由、Codex、Cursor 各跑一遍,直接看谁的返工最少。