从零手搓大模型第三章教程:从零实现一个 GPT 模型
第三章的主题是 Implementing a GPT model from Scratch To Generate Text,也就是"从零实现一个 GPT 模型,并让它能生成文本"。
如果前几章的主线是:
第 1 章从零手搓大模型(一)文本如何变成 LLM 的输入:文本 -> token ID -> embedding
第 2 章从零手搓大模型(二)Attention 机制到底在算什么:embedding -> attention -> context vector
那么第 3 章就是:
text
把 embedding、multi-head attention、LayerNorm、FeedForward、残差连接拼成完整 GPT注意:这一章只是搭模型结构,并用随机权重跑通前向传播和文本生成。真正训练模型是在下一章。
1. 本章你要学会什么
学完这一章,你应该能说清楚:
- GPT 的整体结构由哪些模块组成。
- GPT-2 124M 配置里的参数是什么意思。
- token embedding 和 positional embedding 如何进入模型。
- LayerNorm 为什么能稳定训练。
- GELU 和 FeedForward 在 Transformer 里做什么。
- residual / shortcut connection 为什么重要。
- TransformerBlock 内部是怎么串起来的。
- GPTModel 如何把多个 TransformerBlock 堆叠起来。
- logits 是什么,为什么形状是
(batch, tokens, vocab_size)。 - 简单 greedy decoding 如何逐 token 生成文本。
第 3 章最关键的形状是:
text
输入 token IDs: (batch_size, num_tokens)
token embeddings: (batch_size, num_tokens, emb_dim)
Transformer 输出: (batch_size, num_tokens, emb_dim)
logits: (batch_size, num_tokens, vocab_size)2. GPT-2 124M 的配置
定义一个 GPT-2 小模型配置:
python
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}逐个解释:
vocab_size: 词表大小。GPT-2 tokenizer 有 50257 个 token。context_length: 上下文长度。模型一次最多能看 1024 个 token。emb_dim: embedding 维度。每个 token 会变成 768 维向量。n_heads: attention head 数量。这里是 12 个头。n_layers: Transformer block 层数。这里堆 12 层。drop_rate: dropout 比例,用于减少过拟合。qkv_bias: Q/K/V 线性层是否使用 bias。
这一组配置决定了模型的大小和结构。
3. 先搭一个 GPT 空壳
先定义一个 DummyGPTModel,也就是"占位版 GPT"。
它还没有真正的 TransformerBlock 和 LayerNorm,只是先把整体数据流搭起来。
python
import torch
import torch.nn as nn
class DummyGPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[DummyTransformerBlock(cfg) for _ in range(cfg["n_layers"])])# _ 的意思就是:我只是想重复创建这么多层,不关心当前是第几层。
self.final_norm = DummyLayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits你可以先只看 forward:
text
token IDs
-> token embedding
-> positional embedding
-> 两者相加
-> dropout
-> 多层 TransformerBlock
-> final LayerNorm
-> output head
-> logits这就是 GPT 的主干。
之所以有模型最多支持多长,是跟位置编码的训练有关
context_length = 可用位置 embedding 的数量 = 模型最大上下文长度
不过更广义地说,最大上下文长度还和这些因素有关:
causal mask 的大小(causal mask 是用在 QK 相乘之后得到的 attention scores 上的)
attention 计算量,约随序列长度平方增长
显存占用
训练时见过的长度分布
某些模型的位置编码方式,比如 RoPE、ALiBi,外推能力会不同
4. DummyTransformerBlock 和 DummyLayerNorm
占位模块长这样:
python
class DummyTransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
def forward(self, x):
return x
class DummyLayerNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-5):
super().__init__()
def forward(self, x):
return x它们什么都不做,只是原样返回输入。
为什么要先写空壳?
因为这样可以先确认 GPT 的输入输出形状是对的,再逐步替换成真正实现。
5. 准备一个小 batch
用 GPT-2 tokenizer 编码两句短文本:
python
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
batch = []
txt1 = "Every effort moves you"
txt2 = "Every day holds a"
batch.append(torch.tensor(tokenizer.encode(txt1)))
batch.append(torch.tensor(tokenizer.encode(txt2)))
batch = torch.stack(batch, dim=0)
print(batch)输出
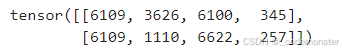
这里 batch 是 token ID:
text
batch.shape = (2, 4)含义:
text
2 条文本,每条文本 4 个 token送进 DummyGPTModel:
python
torch.manual_seed(123)
model = DummyGPTModel(GPT_CONFIG_124M)
logits = model(batch)
print("Output shape:", logits.shape)输出

输出形状是:
text
(2, 4, 50257)含义:
text
2 条文本
每条 4 个位置
每个位置都输出 50257 个 token 的分数这 50257 个分数就是 logits。
6. logits 是什么
logits 是模型输出的原始分数,还不是概率。
对于每个位置,模型都会给词表里的每个 token 打一个分数:
text
logits[batch_idx, token_pos, vocab_id]如果要变成概率,需要做 softmax:
python
probas = torch.softmax(logits, dim=-1)第 4 章训练时,会用 logits 和真实 target token 计算 cross entropy loss。
多维可以理解为一个二叉树,逐一往下分叉
7. LayerNorm 要解决什么问题
LayerNorm 的全名是 Layer Normalization。
它的作用是:把每个样本的特征归一化,让均值接近 0,方差接近 1。因为深层网络里,每一层的输出分布会不断变化。LayerNorm 的目的就是让每个 token 的特征值别太飘,训练更稳定。
先构造一个小网络输出:
python
torch.manual_seed(123)
batch_example = torch.randn(2, 5)
layer = nn.Sequential(nn.Linear(5, 6), nn.ReLU())
out = layer(batch_example)
print(out)输出
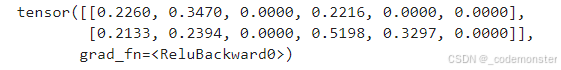
这里 out.shape 是:
text
(2, 6)表示 2 个样本,每个样本 6 个特征。
计算每个样本自己的均值和方差:
python
mean = out.mean(dim=-1, keepdim=True)
var = out.var(dim=-1, keepdim=True)
print("Mean:\n", mean)
print("Variance:\n", var)输出

这里 dim=-1 表示沿最后一个维度,也就是 feature 维度计算。
默认 keepdim=False,计算完方差的那一维会被压缩消失;
keepdim=True 保留原来的维度结构,被计算的那一维长度变为 1。
归一化:
python
out_norm = (out - mean) / torch.sqrt(var)
print("Normalized layer outputs:\n", out_norm)这一步之后,每一行的均值更接近 0,方差更接近 1。
8. 手写 LayerNorm
notebook 实现了一个 LayerNorm:
python
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift关键点:
eps: 防止除以 0。scale: 可训练缩放参数,初始为 1。shift: 可训练平移参数,初始为 0。
为什么归一化后还要 scale 和 shift?
因为模型可能需要恢复某些分布。LayerNorm 先把数据标准化,再让模型自己学习是否缩放和平移。
公式可以理解为:
text
normalized = (x - mean) / sqrt(var + eps)
output = scale * normalized + shiftGPT 中几乎每个 Transformer block 都会用 LayerNorm。
9. GELU 激活函数
Transformer 里的 FeedForward 通常不用 ReLU,而是用 GELU。
这里实现的是近似版 GELU:
python
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))你不需要死记公式。
直觉上:
text
ReLU: 小于 0 直接砍掉
GELU: 更平滑地控制信息通过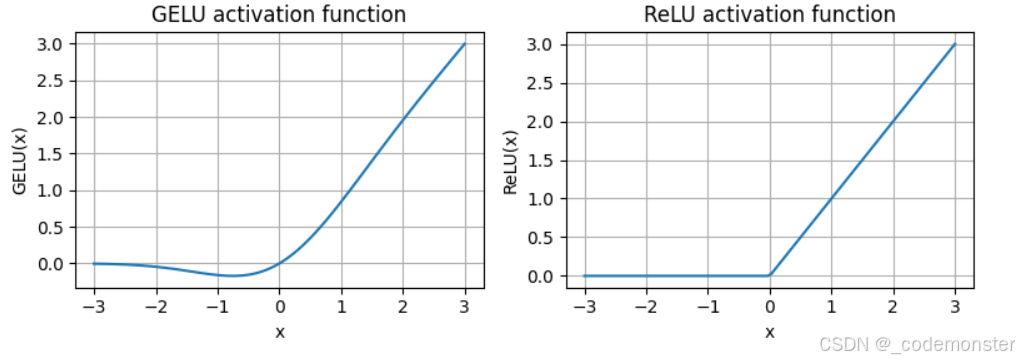
GELU 在很多 Transformer 模型里都很常见。为什么 Transformer 喜欢 GELU?
因为语言模型里的特征不是简单的"有用/没用"。很多信息可能是模糊的、弱相关的。GELU 不会像 ReLU 那样把所有负值直接清零,而是更平滑地保留一点信息,训练时梯度变化也更柔和。
10. FeedForward 模块
Transformer block 里除了 attention,还有一个 FeedForward 网络。
实现如下:
python
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)它做了两层线性变换:
text
emb_dim -> 4 * emb_dim -> emb_dim以 GPT-2 124M 为例:
text
768 -> 3072 -> 768为什么中间要放大 4 倍?
可以理解为给每个 token 一个更大的"思考空间",经过 GELU 非线性变换后,再压回原来的维度。
测试:
python
ffn = FeedForward(GPT_CONFIG_124M)
x = torch.rand(2, 3, 768)
out = ffn(x)
print(out.shape)输出仍然是:
text
(2, 3, 768)FeedForward 不改变整体形状。
11. 残差连接 shortcut / residual connection
子层不用从零生成完整表示,只需要学习"在原来的 x 上改一点什么"
shortcut 的本质是:保留原始输入 x,并把子层学到的变化量加到 x 上。
残差连接的形式很简单:
text
输出 = 子层输出 + 原始输入代码里通常像这样:
python
shortcut = x
x = some_layer(x)
x = x + shortcut它的作用是帮助深层网络训练,缓解梯度消失。
用一个小网络演示有无 shortcut 时梯度差异:
python
class ExampleDeepNeuralNetwork(nn.Module):
def __init__(self, layer_sizes, use_shortcut):
super().__init__()
self.use_shortcut = use_shortcut
self.layers = nn.ModuleList([
nn.Sequential(nn.Linear(layer_sizes[0], layer_sizes[1]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[1], layer_sizes[2]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[2], layer_sizes[3]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[3], layer_sizes[4]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[4], layer_sizes[5]), GELU())
])
def forward(self, x):
for layer in self.layers:
layer_output = layer(x)
if self.use_shortcut and x.shape == layer_output.shape:
x = x + layer_output
else:
x = layer_output
return x
def print_gradients(model, x):
# Forward pass
output = model(x)
target = torch.tensor([[0.]])
# Calculate loss based on how close the target
# and output are
loss = nn.MSELoss()
loss = loss(output, target)
# Backward pass to calculate the gradients
loss.backward()
for name, param in model.named_parameters():
if 'weight' in name:
# Print the mean absolute gradient of the weights
print(f"{name} has gradient mean of {param.grad.abs().mean().item()}")没有残差的情况
python
layer_sizes = [3, 3, 3, 3, 3, 1]
sample_input = torch.tensor([[1., 0., -1.]])
torch.manual_seed(123)
model_without_shortcut = ExampleDeepNeuralNetwork(
layer_sizes, use_shortcut=False
)
print_gradients(model_without_shortcut, sample_input)输出

有残差的情况
python
torch.manual_seed(123)
model_with_shortcut = ExampleDeepNeuralNetwork(
layer_sizes, use_shortcut=True
)
print_gradients(model_with_shortcut, sample_input)输出

只要输入输出形状一样,就可以相加。
这也是为什么 attention 和 FeedForward 都保持 emb_dim 不变:这样才能做残差连接。
12. TransformerBlock:GPT 的核心积木
现在把第 2 章的 MultiHeadAttention、本章的 LayerNorm、FeedForward 和残差连接组合起来。
从 previous_chapters.py 导入第 2 章的多头注意力:
python
from previous_chapters import MultiHeadAttention然后实现 TransformerBlock:
python
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
x = x + shortcut
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut
return x主流 Transformer / GPT 类大模型里,attention 子层通常输入维度和输出维度都等于模型隐藏维度,也就是 emb_dim / hidden_size / d_model。这个隐藏维度其实就是token的嵌入维度。隐藏维度 hidden_size / d_model / emb_dim = 每个 token 的向量维度
这个结构非常重要。
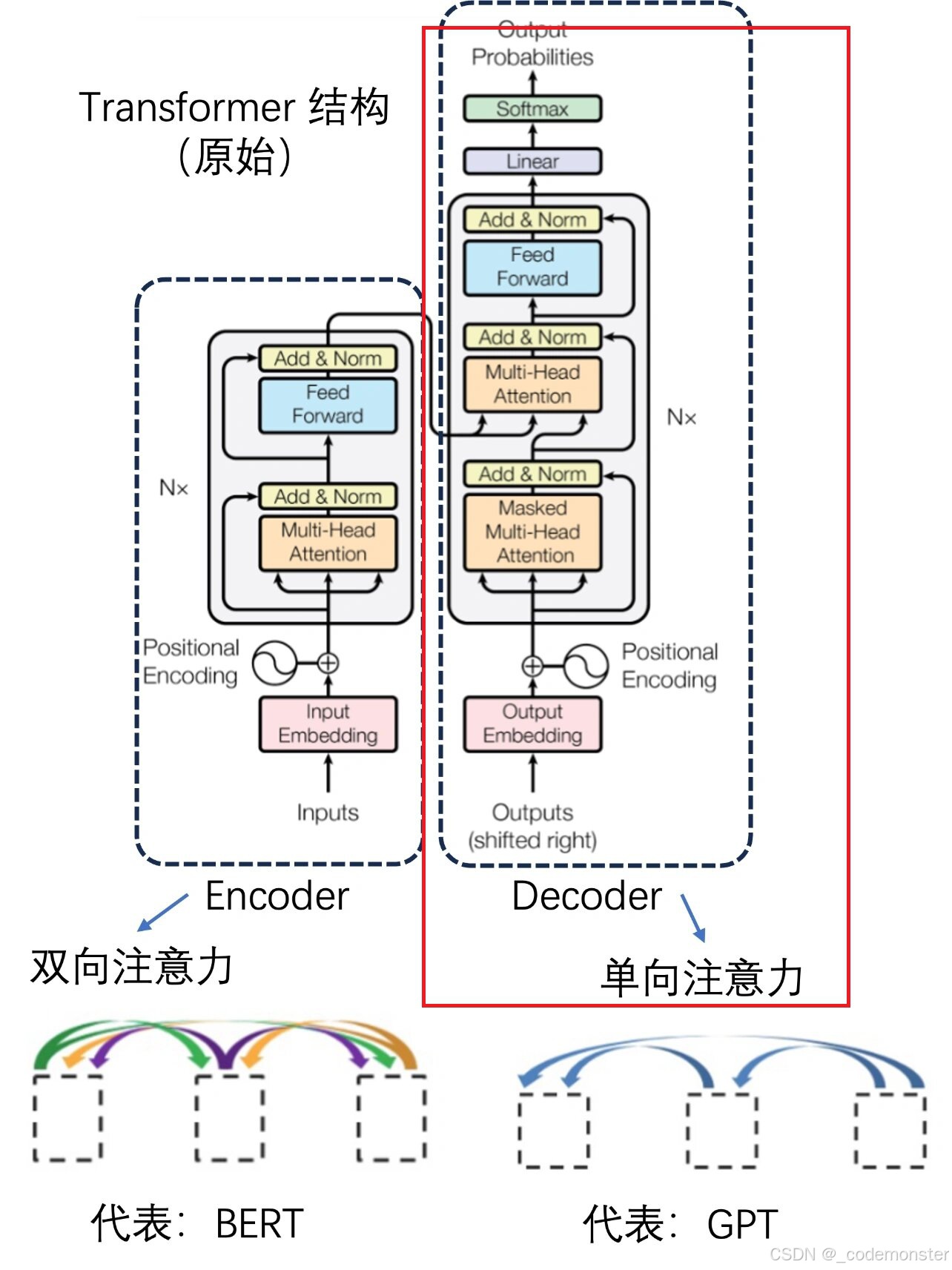
本章实现的GPT和原始Transformer结构的区别
GPT = 只保留 decoder 的 masked self-attention + feedforward 部分
去掉 encoder
也去掉 encoder-decoder cross attention
另外还有一个小差别:图里是经典 Transformer 的 Add & Norm,通常是先子层、再残差、再 Norm;而这本书第 4 章实现的是更常见于现代 GPT 的 Pre-LN:
LayerNorm -> Attention -> Add
LayerNorm -> FeedForward -> Add
可以画成:
text
x
-> LayerNorm
-> MultiHeadAttention
-> Dropout
-> + shortcut
-> LayerNorm
-> FeedForward
-> Dropout
-> + shortcut
-> output注意这里是 Pre-LayerNorm:
text
先 LayerNorm,再进入 attention / feedforward这种结构在现代 LLM 中很常见,训练更稳定。
13. TransformerBlock 不改变输入形状
测试:
python
torch.manual_seed(123)
x = torch.rand(2, 4, 768)
block = TransformerBlock(GPT_CONFIG_124M)
output = block(x)
print("Input shape:", x.shape)
print("Output shape:", output.shape)输入:
text
(2, 4, 768)输出:
text
(2, 4, 768)这很关键。
因为 GPT 会堆很多层 TransformerBlock:
text
第 1 层输入/输出都是 (batch, tokens, emb_dim)
第 2 层输入/输出也是 (batch, tokens, emb_dim)
...
第 12 层输入/输出还是 (batch, tokens, emb_dim)形状不变,才能一层接一层堆起来。
14. 实现真正的 GPTModel
现在替换掉前面的 Dummy 模块,得到完整 GPT:
python
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits和 DummyGPTModel 的流程一样,只是现在:
text
TransformerBlock 是真的
LayerNorm 是真的
FeedForward 是真的
MultiHeadAttention 是真的15. GPTModel 的 forward 逐行理解
输入 in_idx 是 token ID:
text
in_idx.shape = (batch_size, seq_len)例如:
text
(2, 4)第一步,token embedding:
python
tok_embeds = self.tok_emb(in_idx)形状:
text
(batch_size, seq_len, emb_dim)第二步,position embedding:
python
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))形状:
text
(seq_len, emb_dim)第三步,相加:
python
x = tok_embeds + pos_embedsPyTorch 会广播位置向量:
text
(batch_size, seq_len, emb_dim) + (seq_len, emb_dim)结果:
text
(batch_size, seq_len, emb_dim)第四步,经过 12 层 TransformerBlock:
python
x = self.trf_blocks(x)形状不变:
text
(batch_size, seq_len, emb_dim)第五步,最后归一化:
python
x = self.final_norm(x)第六步,输出到词表大小:
python
logits = self.out_head(x)形状变成:
text
(batch_size, seq_len, vocab_size)也就是:
text
每个位置都预测下一个 token 在整个词表上的分数。16. 实例化模型并查看输出
python
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)输出形状:
text
(2, 4, 50257)解释:
text
2 条文本
4 个 token 位置
每个位置预测 50257 个 token 的分数到这里,GPT 模型的前向传播已经跑通了。
但注意:模型权重还是随机初始化的,所以现在输出没有语言能力。
17. 参数量为什么不是刚好 124M
计算参数量:
python
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")输出

然后打印 token embedding 和输出层形状:
python
print("Token embedding layer shape:", model.tok_emb.weight.shape)
print("Output layer shape:", model.out_head.weight.shape)你会看到:
text
Token embedding: (50257, 768)
Output layer: (50257, 768)这两个矩阵形状一样。
原始 GPT-2 使用了 weight tying:
text
输入 token embedding 矩阵和输出层矩阵共享同一份参数这个 notebook 为了教学清晰,没有做 weight tying,所以参数量会比 124M 更多。
如果减去输出层参数:
python
total_params_gpt2 = total_params - sum(p.numel() for p in model.out_head.parameters())
print(f"Number of trainable parameters considering weight tying: {total_params_gpt2:,}")输出

就会更接近 GPT-2 124M。
18. 模型大小估算
假设每个参数是 float32,也就是 4 字节:
python
total_size_bytes = total_params * 4
total_size_mb = total_size_bytes / (1024 * 1024)
print(f"Total size of the model: {total_size_mb:.2f} MB")输出

B = Byte 字节
b = bit 位
KB:千字节(文件存储)
1 KB = 1024 B(字节)
1 B = 8 b(位)
联立:
1 KB = 1024 × 8 = 8192 b
这只是参数本身占用的空间。
真实训练时还会有:
- gradients
- optimizer states
- activations
- batch 数据
所以训练显存通常远大于模型参数文件大小。
19. 生成文本的基本思路
GPT 生成文本不是一次生成一整段,而是一次生成一个 token:
text
输入已有 token
-> 模型预测下一个 token
-> 把新 token 拼到输入后面
-> 再预测下一个 token
-> 循环这叫 autoregressive generation,自回归生成。
一个最简单的生成函数:
python
def generate_text_simple(model, idx, max_new_tokens, context_size):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
probas = torch.softmax(logits, dim=-1)
idx_next = torch.argmax(probas, dim=-1, keepdim=True)
idx = torch.cat((idx, idx_next), dim=1)
return idx这是 greedy decoding,也就是每一步都选概率最高的 token。
20. generate_text_simple 逐行理解
输入 idx 是当前已有 token IDs:
text
idx.shape = (batch_size, n_tokens)如果上下文超过模型支持长度,就只保留最后 context_size 个 token:
python
idx_cond = idx[:, -context_size:]送进模型:
python
logits = model(idx_cond)模型输出:
text
(batch_size, n_tokens, vocab_size)我们只需要最后一个位置的预测,因为它对应"下一个 token":
python
logits = logits[:, -1, :]形状变成:
text
(batch_size, vocab_size)转成概率:
python
probas = torch.softmax(logits, dim=-1)选概率最大的 token:
python
idx_next = torch.argmax(probas, dim=-1, keepdim=True)拼到原序列后面:
python
idx = torch.cat((idx, idx_next), dim=1)循环 max_new_tokens 次,就生成这么多个新 token。
21. 用随机初始化模型生成文本
准备输入:
python
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)输出
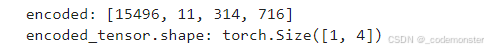
unsqueeze(0) 是添加 batch 维度:
text
(n_tokens,) -> (1, n_tokens)生成:
python
model.eval()
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))输出

解码:
python
decoded_text = tokenizer.decode(out.squeeze(0).tolist())
print(decoded_text)输出
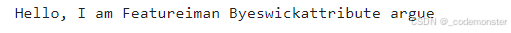
这里输出会很怪,因为模型还没训练。
第 3 章只是证明:
text
这个 GPT 架构可以接收 token IDs,输出 logits,并按 logits 逐步生成 token。第 4 章才会让它真正学习语言规律。
22. 本章完整流程回顾
第 3 章可以压缩成这条路线:
text
1. 定义 GPT_CONFIG_124M
决定词表大小、上下文长度、embedding 维度、层数、head 数等
2. 搭 DummyGPTModel
先确认 GPT 的整体输入输出流程
3. 实现 LayerNorm
稳定每层激活分布
4. 实现 GELU
Transformer 中常用的平滑激活函数
5. 实现 FeedForward
emb_dim -> 4*emb_dim -> emb_dim
6. 理解 shortcut connection
帮助深层网络训练,缓解梯度消失
7. 实现 TransformerBlock
LayerNorm + MultiHeadAttention + shortcut
LayerNorm + FeedForward + shortcut
8. 实现 GPTModel
token embedding + position embedding
堆叠 n_layers 个 TransformerBlock
final norm + output head
9. 输出 logits
shape = (batch, tokens, vocab_size)
10. 实现 greedy generation
每次选概率最高的下一个 token23. GPTModel 的结构总览
可以把本章实现的 GPT 看成:
text
token IDs
|
v
token embedding + positional embedding
|
v
dropout
|
v
TransformerBlock x 12
|
v
final LayerNorm
|
v
Linear output head
|
v
logits over vocabulary其中一个 TransformerBlock 是:
text
x
|
+---- shortcut ----------------+
| |
LayerNorm |
| |
MultiHeadAttention |
| |
Dropout |
| |
+---------- add <--------------+
|
+---- shortcut ----------------+
| |
LayerNorm |
| |
FeedForward |
| |
Dropout |
| |
+---------- add <--------------+
|
output24. 本章最容易混淆的点
logits 不是文本
logits 是模型对词表中每个 token 的原始分数。
要生成文本,需要:
text
logits -> 选择 token ID -> tokenizer.decode -> 文本TransformerBlock 不改变 shape
不管里面做了 attention 还是 FeedForward,输入输出都是:
text
(batch, tokens, emb_dim)这就是它能堆很多层的原因。
FeedForward 是逐 token 工作的
FeedForward 不混合不同 token 的信息。
token 之间的信息混合主要由 attention 完成。
FeedForward 更像是对每个 token 自己的表示做非线性变换。
residual connection 要求形状一样
如果要做:
python
x = x + shortcut两边 shape 必须一致。
所以 attention 和 FeedForward 都会输出 emb_dim。
这一章的模型还没有训练
能生成文本,不代表会说话。
第 3 章只是搭好结构,权重还是随机的。
第 4 章才会通过 next-token prediction 训练模型。
25. 建议
建议按这个顺序学:
- 先看
GPT_CONFIG_124M,理解每个配置项。 - 跑
DummyGPTModel,只关注输入输出 shape。 - 学
LayerNorm,理解dim=-1是沿特征维度归一化。 - 学
GELU和FeedForward,记住768 -> 3072 -> 768。 - 学 shortcut connection,理解为什么深层模型需要残差。
- 重点看
TransformerBlock,这是 GPT 的核心积木。 - 再看
GPTModel,理解 12 层 block 如何堆起来。 - 最后看
generate_text_simple,理解生成是一个 token 一个 token 接出来的。
本章最值得反复看的两个类:
text
TransformerBlock
GPTModel只要这两个类看懂,第 3 章就真正过关了。
26. 和后续章节的关系
第 3 章结束后,我们已经有了一个完整 GPT 架构:
text
输入 token IDs -> 输出 logits但是它还没训练,所以输出是随机的。
第 4 章会做:
text
准备训练数据
计算 loss
反向传播
更新参数
保存模型
生成更像样的文本也就是说:
text
第 3 章:造模型
第 4 章:训练模型你可以把第 3 章当成"把 GPT 的骨架搭起来"。后面所有训练、微调、指令跟随,都会建立在这个骨架上。