距离上次写博客已有很长的时间,我也已经近一年没学算法了。最近期末考突然捡起算法与数据结构,以往的痛苦又开始折磨我,使我意识到算法可视化的迫切需求。于是我建了一个这样的项目------一个能让我"看见"算法执行过程的平台。
学算法的新手大概都有这种感觉:看书上的代码,脑子里推演着循环和递归,脑海里理解的很模糊,实际实现一堆错。指针怎么跳的、数组怎么换的、队列怎么进的------这些过程光靠想象,总归是差了点什么。
所以我就想,能不能做一个东西,让算法真的能被看见?而且不是那种柱状图往上冒一下的"看见",是把算法映射到真实世界场景里------比如Dijkstra算法在城市街道上跑,排序算法在工厂流水线上走,并查集在一片社区里建连接。
于是就有了这个项目。
项目已经开源在GitHub上(地址见文末),完整代码、全部场景、所有算法模板都在里面。
项目概览
先放一张整体的效果:
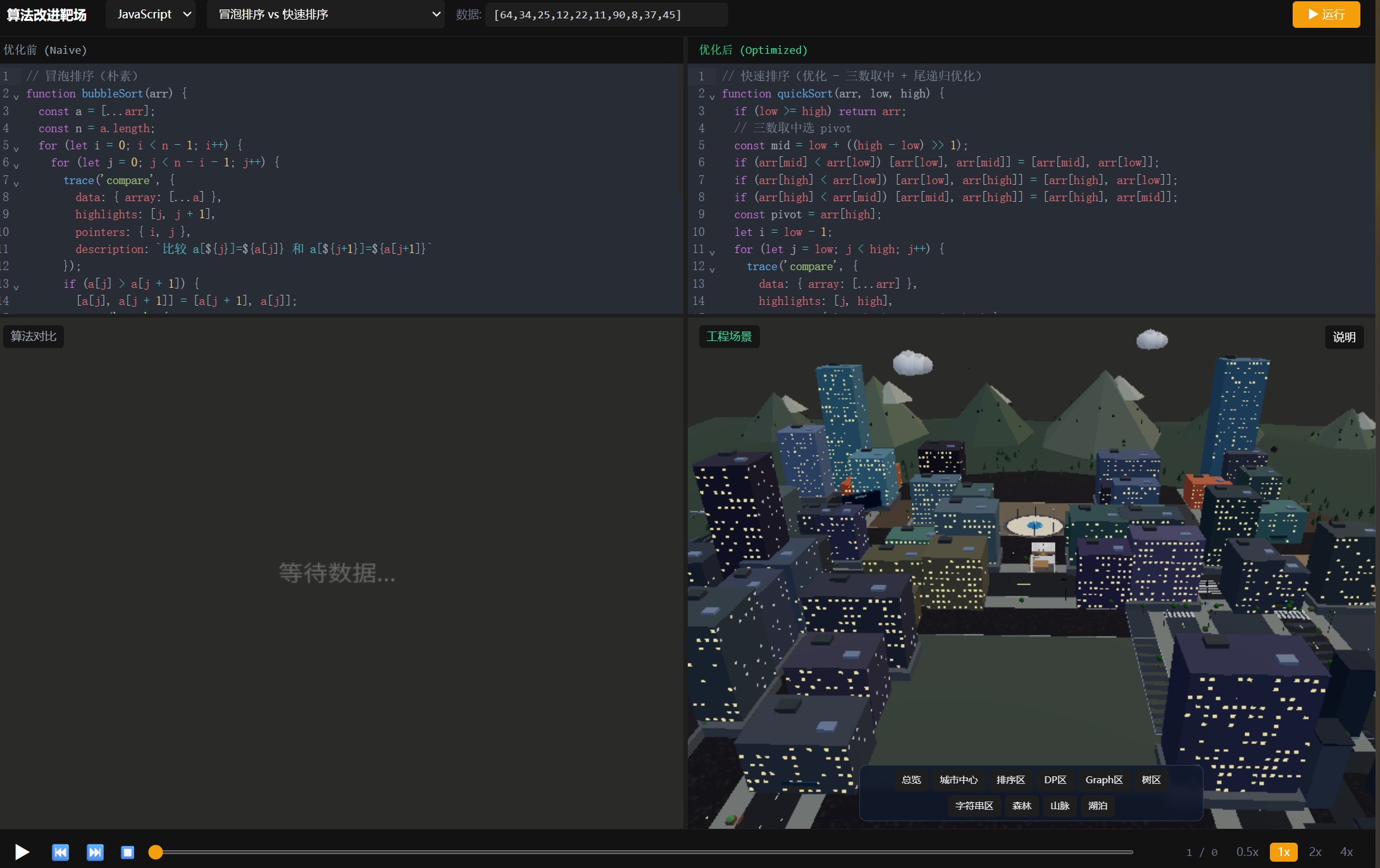
整个平台基于 React + Three.js + TypeScript 构建,支持 JavaScript 和 Python 双语言执行。核心功能一句话说就是:左侧跑朴素算法,右侧跑优化算法,两边的每一步都在3D场景里呈现出来,你可以逐帧播放对比 。例如左边是冒泡排序在笨拙地来回搬运,右边是快速排序在利落分治。这就是我想写的东西:算法的执行,不只是时间复杂度的改进,更是一种过程化的升维。
技术栈
项目依赖的核心库:
json
{
"react": "^18.3.1",
"three": "^0.169.0",
"@react-three/fiber": "^8.17.0",
"@react-three/drei": "^9.114.0",
"zustand": "^5.0.0",
"codemirror": "^6.0.1"
}- React 18 + Three.js (通过 @react-three/fiber) 构建3D场景
- Zustand 管理播放状态(步骤进退、速度控制)
- CodeMirror 6 作为代码编辑器,支持JS/Python语法高亮
- Web Worker 沙箱执行用户代码,不阻塞UI
- Tailwind CSS 做暗色主题UI
架构设计
整个项目分了几个核心层:
1. 执行引擎层
用户点击"运行"后,代码会被送到Web Worker里执行。执行过程中,代码里的 trace() 调用会把每一步的快照发回主线程:
typescript
// src/core/types.ts --- 核心类型定义
export interface TraceSnapshot {
label: string;
data: Record<string, unknown>;
highlights?: number[];
pointers?: Record<string, number>;
description?: string;
timestamp: number;
}
export interface AlgorithmTemplate {
id: string;
name: string;
category: string;
language: 'js' | 'python';
naiveCode: string; // 朴素实现
optimizedCode: string; // 优化实现
defaultData: unknown;
}执行引擎通过Web Worker做沙箱隔离:
typescript
// src/core/executor.ts --- 沙箱执行
export function executeCode(
code: string,
data: unknown,
timeoutMs: number = 5000
): Promise<{ success: boolean; traces: TraceSnapshot[]; error?: string }> {
return new Promise((resolve, reject) => {
const w = getWorker();
const requestId = `req_${++requestIdCounter}`;
// ... 通过 postMessage 通信
});
}这套架构支持JavaScript原生沙箱执行和Python(通过Pyodide在Worker中运行),未来要扩展C语言也不难,加个executor就行。
2. 场景映射层
每个算法类别都对应一个或多个3D场景。比如图算法映射到城市场景(街道=边,路口=节点),排序算法映射到工厂场景(传送带=数组)。系统会自动检测当前运行的数据结构类型,切换到对应的场景。
场景分为两类:
- 抽象场景:柱状图、节点连线图------清晰展示算法逻辑
- 工程场景:城市、工厂、森林、图书馆------沉浸式体验
这也是这个项目最耗时的部分------光城市场景就写了5000多行代码。
算法模板一览
目前内置了六大类40多种算法的朴素vs优化对比模板,每种都有JavaScript和Python双版本:
排序类
| 朴素 | 优化 | 改进点 |
|---|---|---|
| 冒泡排序 O(n²) | 快速排序(三数取中) O(n log n) | 分治+尾递归 |
| 选择排序 O(n²) | 堆排序 O(n log n) | 二叉堆 |
| 插入排序 O(n²) | 希尔排序 | 步长分组 |
| 归并排序(递归) | 归并排序(迭代) | 栈溢出规避 |
| 计数排序 | 基数排序(LSD) | 多关键字 |
图算法
| 朴素 | 优化 | 改进点 |
|---|---|---|
| Dijkstra 朴素 O(V²) | Dijkstra 优先队列 O(E log V) | 最小堆 |
| Prim 朴素 O(V²) | Prim 堆优化 O(E log V) | 最小堆 |
| QuickFind | 路径压缩+按秩合并 | 摊还α(n) |
字符串
| 朴素 | 优化 |
|---|---|
| 朴素匹配 O(nm) | KMP O(n+m) |
| 最长回文暴力 O(n³) | 中心扩展 O(n²) |
| 异位词排序 | 异位词哈希 |
| 无重复子串暴力 O(n²) | 滑动窗口 O(n) |
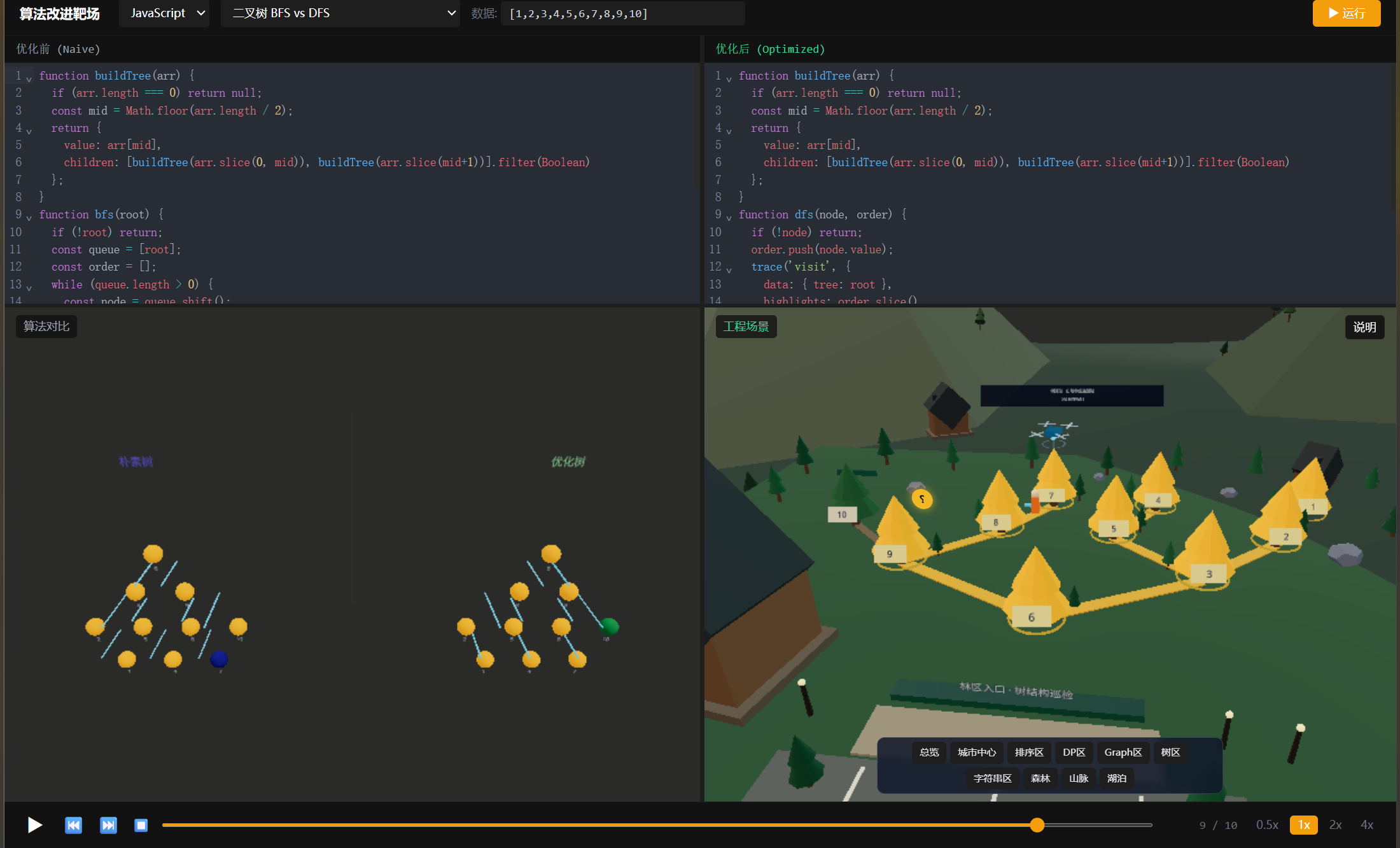
还有动态规划(0-1背包、LCS、编辑距离、Coin Change等)、树算法(BFS/DFS、验证BST、LCA、迭代遍历)、搜索算法(二分搜索、Two Sum哈希、旋转数组二分)------总共约40种对比模板。
关键算法代码
贴几个算法实现。
1. KMP字符串匹配
KMP的核心是那张LPS表(最长公共前后缀)。理解了LPS怎么构建,就理解了KMP。
javascript
// 朴素 → KMP 的优化版本
function kmpSearch(input) {
const text = typeof input === 'object' && input.text ? input.text : input;
const pattern = typeof input === 'object' && input.pattern ? input.pattern : '';
const n = text.length, m = pattern.length;
// 构建 LPS 表
const lps = new Array(m).fill(0);
let len = 0, i = 1;
while (i < m) {
if (pattern[i] === pattern[len]) {
len++; lps[i] = len; i++;
} else {
if (len !== 0) len = lps[len - 1];
else { lps[i] = 0; i++; }
}
}
trace('lps', {
data: { array: lps },
description: `LPS表: [${lps}]`
});
// KMP 搜索
let j = 0; i = 0;
while (i < n) {
if (pattern[j] === text[i]) { i++; j++; }
if (j === m) {
trace('found', {
data: { text, pattern },
highlights: [i - j],
description: `在位置 ${i-j} 找到匹配!`
});
j = lps[j - 1];
} else if (i < n && pattern[j] !== text[i]) {
if (j !== 0) {
j = lps[j - 1]; // 利用LPS跳过已匹配部分
trace('skip', {
data: { text, pattern },
highlights: [i],
description: `失配, j->${j}`
});
} else { i++; }
}
}
}LPS表的构建是整个KMP最巧妙的部分------它利用前缀的自相似性,避免了朴素匹配中"匹配到一半发现不对,从头再来"的悲剧。
2. Dijkstra + 优先队列
朴素Dijkstra每次都要线性扫描找最小dist节点,用堆优化后效率翻倍:
javascript
// 优先队列优化的 Dijkstra
function dijkstraPQ(graph, start) {
const { nodes, edges } = graph;
const n = nodes.length;
const dist = new Array(n).fill(Infinity);
dist[start] = 0;
const adj = Array.from({ length: n }, () => []);
for (const e of edges) adj[e.from].push({ to: e.to, w: e.weight });
// 用数组模拟最小堆(实际生产环境用二叉堆)
const pq = [[0, start]];
while (pq.length > 0) {
pq.sort((a, b) => a[0] - b[0]); // 按距离排序
const [d, u] = pq.shift();
if (d > dist[u]) continue; // 惰性删除
trace('visit', {
data: { ...graph },
highlights: [u],
description: `弹出 ${nodes[u].label}, dist=${d}`
});
for (const { to, w } of adj[u]) {
if (dist[u] + w < dist[to]) {
dist[to] = dist[u] + w;
pq.push([dist[to], to]);
trace('relax', {
data: { ...graph },
highlights: [u, to],
description: `更新 ${nodes[to].label}->${dist[to]}`
});
}
}
}
}在3D场景中,Dijkstra算法的执行过程是这样的:一辆货车从起点出发,每到一个路口(节点),所有相邻路口的路标会更新距离。货车总是沿着当前已知最短的路走------这就是"贪心"的具象化。
3. 并查集 路径压缩
从QuickFind到路径压缩,代码量没增加多少,性能却从O(n)降到了摊还α(n):
javascript
// 路径压缩 + 按秩合并
function ufPC(ops) {
const n = 8;
const parent = Array.from({ length: n }, (_, i) => i);
const rank = new Array(n).fill(0);
function find(x) {
if (parent[x] !== x) {
parent[x] = find(parent[x]); // 路径压缩
trace('compress', {
data: { array: parent },
highlights: [x],
description: `路径压缩: ${x}->${parent[x]}`
});
}
return parent[x];
}
function union(x, y) {
let rx = find(x), ry = find(y);
if (rx === ry) return;
if (rank[rx] < rank[ry]) [rx, ry] = [ry, rx];
parent[ry] = rx;
if (rank[rx] === rank[ry]) rank[rx]++;
trace('union', {
data: { array: parent },
highlights: [x, y],
description: `合并 ${x} 和 ${y}`
});
}
for (const [a, b] of ops) union(a, b);
}在城市场景中,并查集的每个集合对应一个社区。两个社区合并时,会有一座桥(或一条路)把两个区域连接起来。路径压缩的过程看起来像是"直接拉了一条捷径直通社区中心"------非常直观。
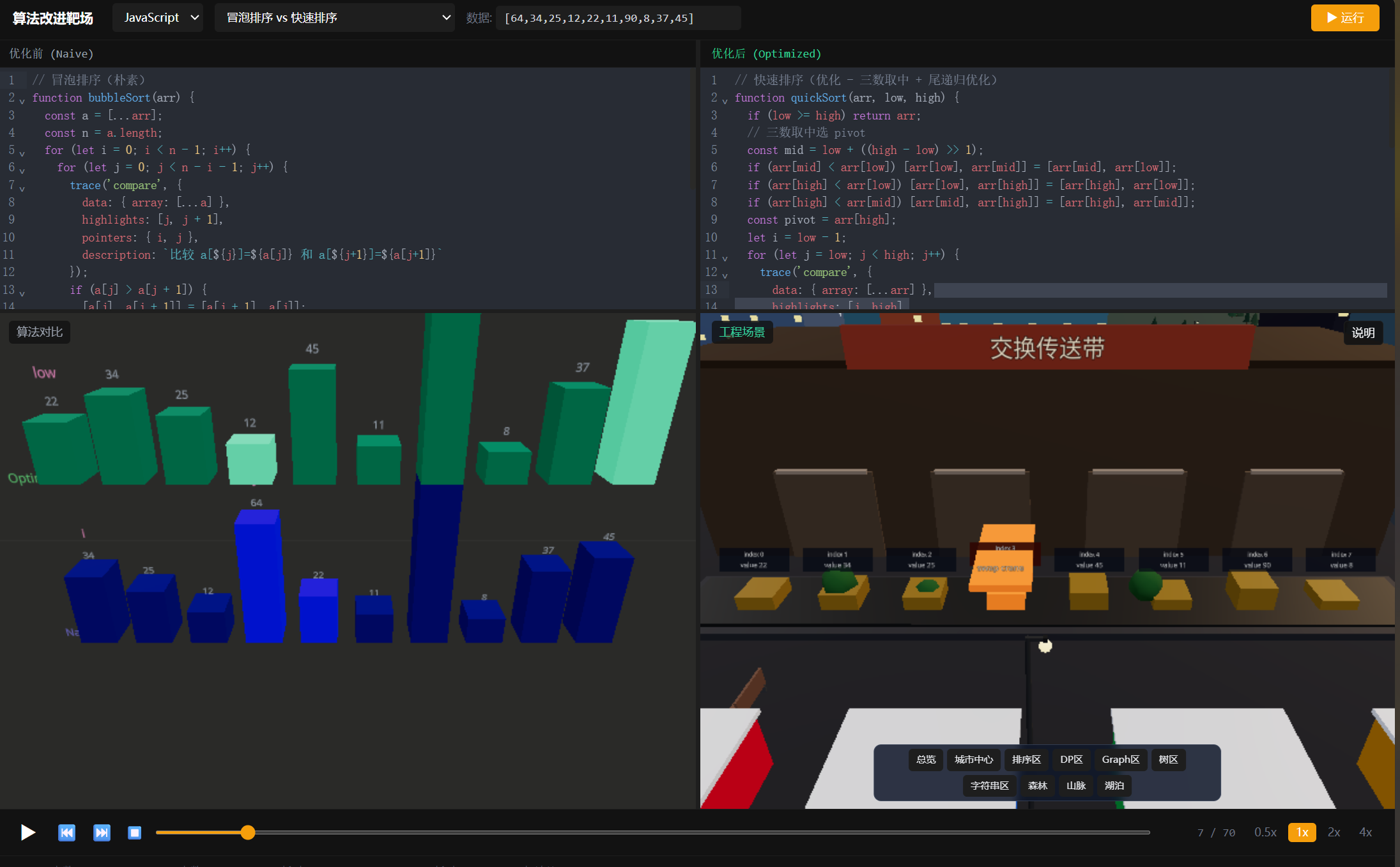
4. 快速排序 --- 三数取中
优化版的快排,用三数取中避免选到最差pivot:
javascript
function quickSort(arr, low, high) {
if (low >= high) return arr;
// 三数取中:arr[low]、arr[mid]、arr[high] 的中位数做 pivot
const mid = low + ((high - low) >> 1);
if (arr[mid] < arr[low]) [arr[low], arr[mid]] = [arr[mid], arr[low]];
if (arr[high] < arr[low]) [arr[low], arr[high]] = [arr[high], arr[low]];
if (arr[high] < arr[mid]) [arr[mid], arr[high]] = [arr[high], arr[mid]];
const pivot = arr[high];
let i = low - 1;
for (let j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
[arr[i], arr[j]] = [arr[j], arr[i]];
}
}
[arr[i + 1], arr[high]] = [arr[high], arr[i + 1]];
// 尾递归优化:优先处理较短的子数组
quickSort(arr, low, i); // 左半部分
quickSort(arr, i + 2, high); // 右半部分
}在工厂场景中,快排的pivot就像传送带上的分拣标准------所有小于pivot的往左送,大于pivot的往右送,然后左右两条传送带各自递归。冒泡排序则是两个工人来来回回地对比交换------你一眼就能看出哪个效率高。
3D城市场景
这部分是我花时间最多的。
整个城市由以下几个部分组成:
- 街道网格:构成了图的边
- 建筑物/路口:构成了图的节点
- Dijkstra园区:有专门的公园路径,算法运行时长椅上会出现路径标记
- Prim变电站:电网拓扑结构展示最小生成树的构建
- 并查集社区:一片住宅区,合并时"破墙通路"
- 排序分拣中心:传送带和货架构成数组
- 森林苗圃:树结构可视化,每个节点是一棵树
- 图书馆:字符串匹配的场景,书架上的书就是字符
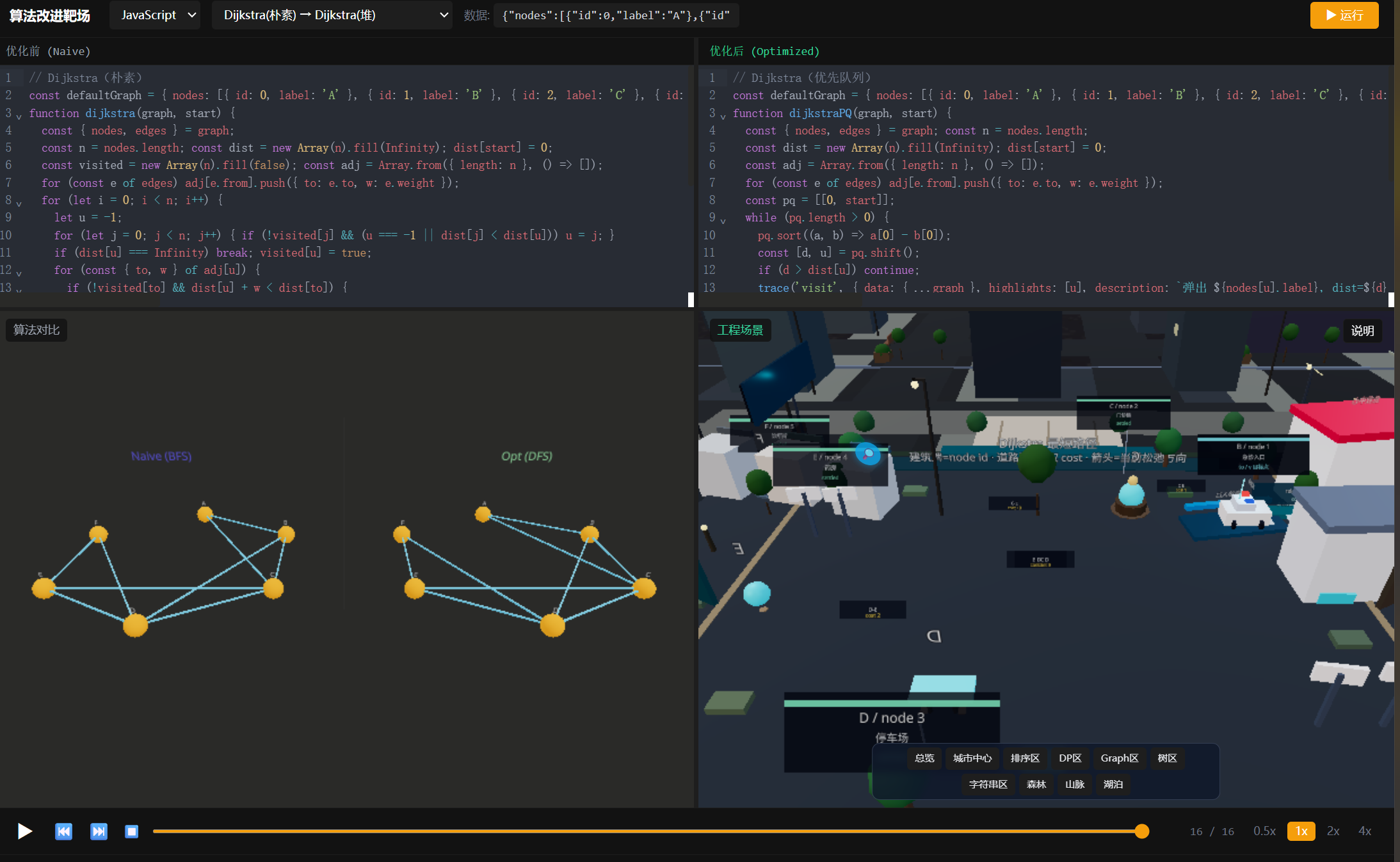
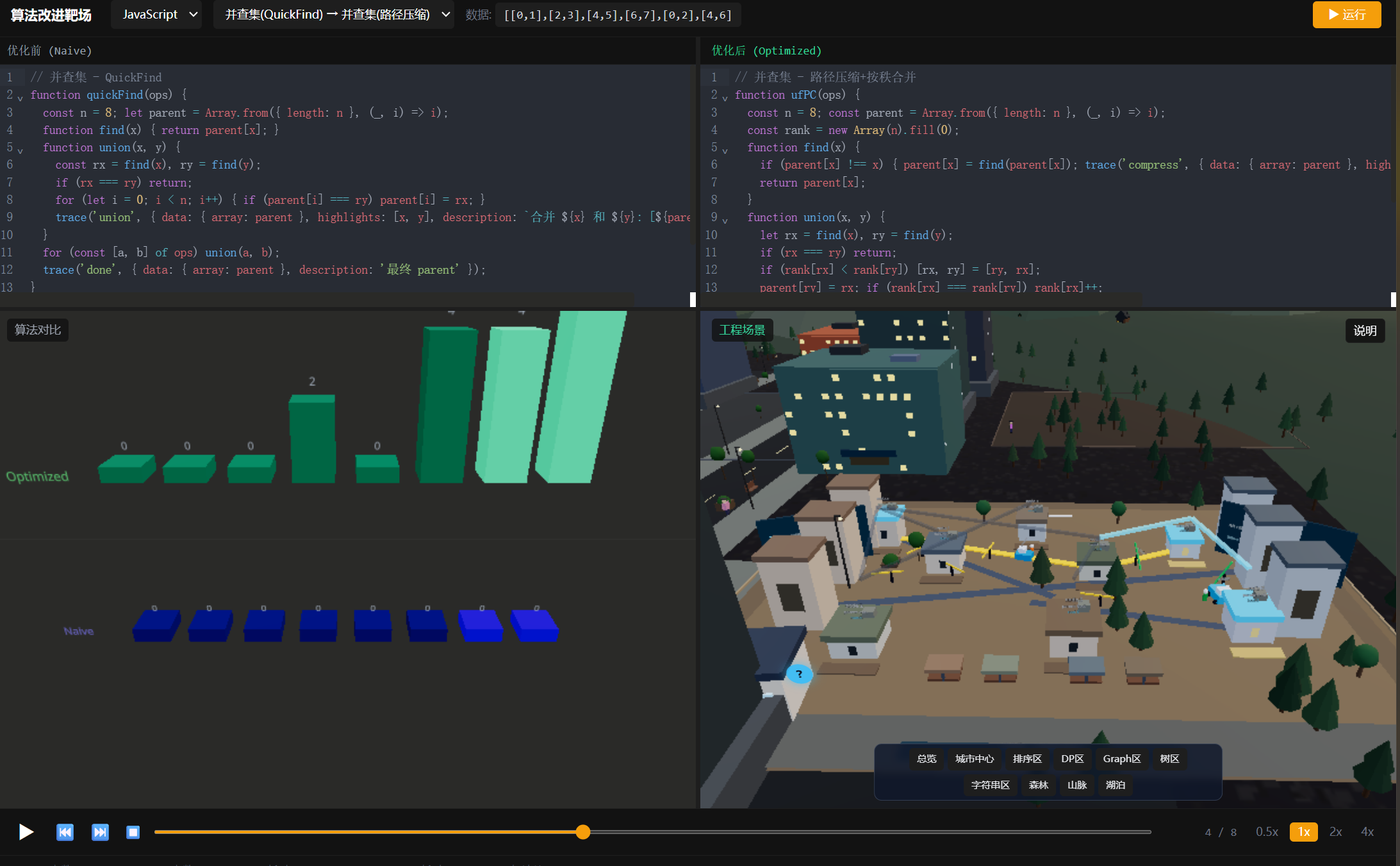
每个场景都配了完整的相机控制------可以用鼠标旋转、缩放、平移。算法运行时,相机会自动对准当前操作的元素。
底部工具栏
运行算法后,底部的控制面板支持:
- ▶️ 逐帧播放:一步步看算法的每一次比较和交换
- ⏸️ 自动播放:连续播放,速度可调(0.5x ~ 4x)
- ⏪ 回退:回到上一步
- 📊 统计面板:显示朴素vs优化的步骤数、执行时间、加速比

- 以及算法改进必备的时间执行耗时对比
开发感受
这个项目从一开始的"我就试试Three.js能不能做算法可视化",一步步变成了一个完整的平台。中间经历了无数次:
- 场景太卡 → 优化Draw Calls
- Python执行器跑不起来 → 换Pyodide
- 城市太空旷 → 加建筑、路灯、河流、桥
- 截图太丑 → 重写材质和光照
我每次启动项目看3D动画时都会感到震惊,并不是我写的算法有多好,而是意识到算法真正的的作用------并不是单纯为了刷题,而是应用于实际。你可以任意修改算法,然后现实就会为你改变。我想写的从来不是单纯的炫酷场景,而是让算法与现实碰撞出火花。
不管是在城市地铁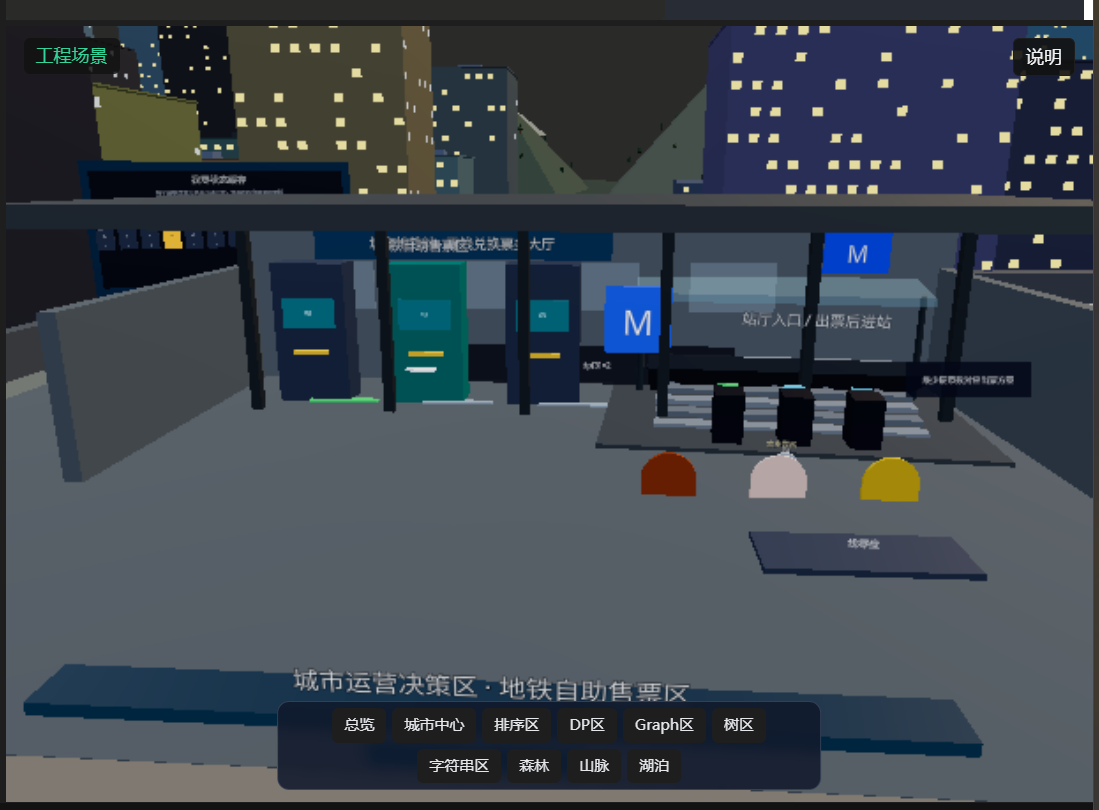
还是警察抓小偷
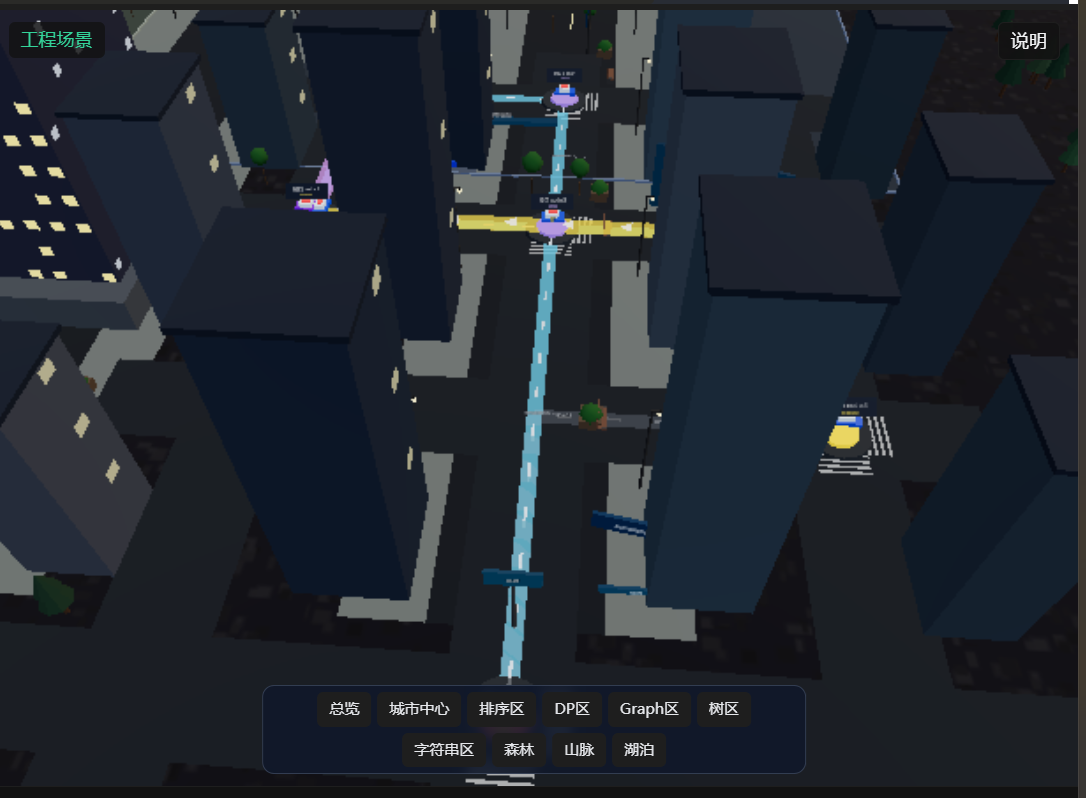
亦或者是叉车装货
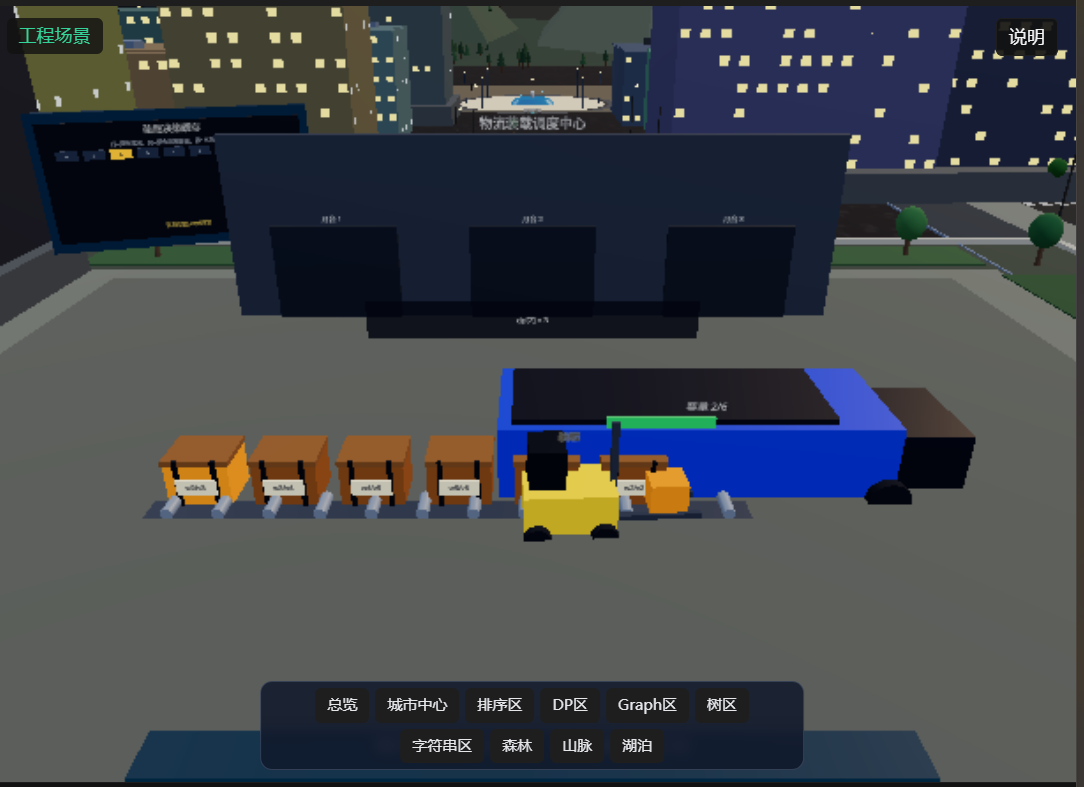
又或者是电网连接等等等等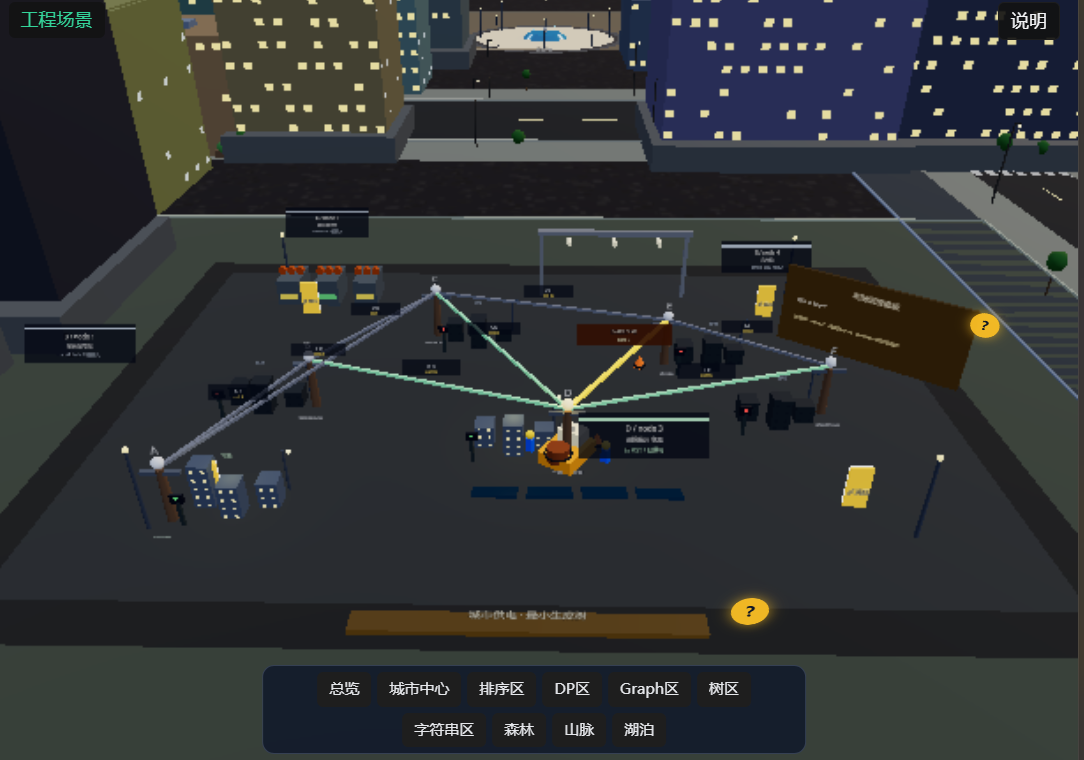
我想要构建的是一个思维改变世界的项目。
当然不得不承认我的城市建模还是有点粗糙,因此我开源出来希望大家能共同努力。
项目地址(GitHub) :https://github.com/gu860/dsa-improvement-range
最后
算法学习没有捷径,但有更好的方式。光看书上的O(n²)和O(n log n),你可能知道快排比冒泡快,但你不会真正感受到这种差距。当你在3D场景里看到冒泡排序的元素像蜗牛一样一格一格挪动,而快速排序像流水线一样干脆利落地分治时------那种体验是完全不一样的。