1.什么是闭包,闭包的使用场景有哪些
闭包是指有权访问另一个函数作用域中变量的函数 。简单理解,当一个内层函数引用了其外层函数作用域中的变量或参数,且内层函数在其外层函数执行结束后依然能被访问和调用时,就形成了闭包。比如在 JavaScript 中,创建闭包常见方式是在一个函数内部创建另一个函数,且内部函数使用了外部函数的变量 。
人话:
想象你有一个盒子工厂(外部函数),工厂里有一些工具和材料(外部函数的变量) 。工厂里有个工人(内部函数),他熟悉这些工具和材料的使用方法。
当工厂完成一批盒子制造任务后,正常情况下,工厂里的工具和材料会被收拾起来。但如果把这个工人派出去(外部函数返回内部函数),他因为熟悉在工厂里的工具和材料,即使离开了工厂(外部函数执行完),他依然能使用这些工具和材料(访问外部函数的变量)去完成一些工作。这个被派出去的工人和他能使用的工厂资源的组合,就类似闭包。
内部函数引用了外部函数的变量,且外部函数返回内部函数,这时形成的函数组合就是闭包
闭包的使用场景
封装:在 JavaScript 等语言中,利用闭包可创建私有变量和函数,实现信息隐藏和封装。例如,通过闭包将某些变量和函数封装在内部,只对外暴露特定的接口来访问和操作内部数据,避免全局变量污染,提高代码的安全性和可维护性。
函数式编程:用于创建高阶函数(函数可以作为参数传递或作为返回值返回 )、延迟执行函数、柯里化等功能。比如柯里化通过闭包将多个参数的函数转化为一系列单参数函数,增强函数的灵活性和复用性。
定时器和事件处理:在处理定时器和事件时,闭包能保存局部状态。例如在定时器回调函数中,利用闭包保存每次迭代的变量值,确保在定时器触发时能获取到正确的值;在事件处理函数中,可保存相关的状态信息,方便后续逻辑处理。
模块模式:可将相关的函数和数据封装在一起形成模块。在模块内部通过闭包管理私有状态和行为,只向外暴露必要的接口,实现模块化编程,提高代码的组织性和可维护性。
回调函数(异步编程):在异步编程中,闭包常与回调函数配合,捕获周围作用域的状态,并在回调触发时使用这些状态。比如在 Ajax 请求的回调中,通过闭包保存请求相关的上下文信息,确保回调能正确处理响应 。
循环中的异步操作:在 JavaScript 循环中进行异步操作时,变量提升可能导致问题,使用闭包能确保在异步操作完成时获取到正确的循环变量值,避免因变量共享造成的逻辑错误。
函数节流与防抖:函数节流控制函数在一定时间内只执行一次,防抖是在一定时间内多次触发只执行最后一次。通过闭包可以保存计时状态等信息,实现节流和防抖功能,常用于优化窗口 resize、scroll 等频繁触发事件的处理,提高性能 。
缓存计算结果:利用闭包缓存函数的计算结果,避免重复计算。例如在计算复杂或耗时的函数结果时,将结果缓存起来,下次相同输入时直接返回缓存值,提升程序性能 。
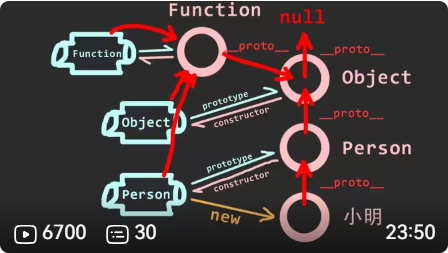
2.原型链
-
什么是原型、原型链
- 每个对象都有
__proto__,指向它的原型对象 - 原型对象也有自己的原型,直到
null,这条链就是原型链
- 每个对象都有
-
prototype和__proto__的区别prototype:函数独有,是构造函数的原型__proto__:对象独有,指向该对象的原型
-
constructor 是什么
- 原型对象里的
constructor指向构造函数本身
- 原型对象里的
-
new 一个对象发生了什么
- 创建空对象
- 绑定原型(
obj.__proto__ = Fn.prototype) - 执行构造函数(this 指向新对象)
- 返回对象
-
instanceOf 原理
- 沿着对象的
__proto__找,看是否等于构造函数的prototype
- 沿着对象的
-
如何判断对象自身属性 / 原型属性
hasOwnProperty():只查自身in:自身 + 原型链上都算
-
继承的实现(必考)
- 原型链继承
- 构造函数继承
- 组合继承
- 寄生组合继承(最优)
- ES6
class extends本质还是原型链
-
Object 和 Function 的关系
Object.__proto__ === Function.prototypeFunction.__proto__ === Function.prototype- 所有对象最终都继承自
Object.prototype
3.VueRouter 面试高频问题
Q1:VueRouter 有哪几种路由模式?区别是什么?
答:
-
hash 模式(默认):
-
原理:基于 URL 的
#锚点,#后的内容不会发送到服务器,通过hashchange监听路由变化; -
特点:兼容性好(支持低版本浏览器),URL 带
#不够美观,无需后端配置。
-
-
history 模式:
-
原理:基于 HTML5 History API(
pushState/replaceState),URL 无#,通过popstate监听; -
特点:URL 更规范,需要后端配置(Nginx/Apache),否则刷新页面会 404(需配置所有路由指向 index.html)。
-
-
abstract 模式:非浏览器环境(如 Node/Weex)的兜底模式,基于内存模拟路由。
Q2:路由传参有几种方式?优缺点?
| 方式 | 用法 | 优点 | 缺点 |
|---|---|---|---|
| 动态路由参数 | /user/:id → $route.params.id |
语义化,URL 清晰 | 刷新页面参数不丢失,参数必须在路由配置中定义 |
| query 参数 | /user?id=1 → $route.query.id |
灵活,无需配置路由 | URL 带参数,刷新不丢失,参数暴露在地址栏 |
| params 隐式传参 | router.push({ name: 'user', params: { id: 1 } }) |
参数不暴露 | 刷新页面参数丢失,必须配合 name 跳转 |
| 路由元信息(meta) | 配置 meta: { requireAuth: true } |
用于全局路由守卫(如鉴权) | 仅存储静态 / 全局信息,不适合动态传参 |
Q3:路由守卫有哪些?执行顺序是什么?
答:
- 分类 :
- 全局守卫:
router.beforeEach(前置)、router.afterEach(后置)、router.beforeResolve(解析完成前); - 路由独享守卫:
beforeEnter(在路由配置中定义); - 组件内守卫:
beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave。
- 全局守卫:
- 执行顺序 (跳转新路由时):
beforeEach→beforeEnter→beforeRouteEnter→beforeResolve→afterEach→ 组件创建(beforeRouteEnter的回调获取组件实例)。 - 核心用途:登录鉴权、页面权限控制、页面离开前确认(如表单未保存)。
Q4:如何实现路由懒加载?为什么要做?
答:
- 目的:减少首屏加载体积,提升 FCP/TTI 性能(首屏只加载当前路由组件,其他路由按需加载)。
- 实现方式:
javascript
// Vue 2/3 通用
const User = () => import('./views/User.vue');
// 批量懒加载(webpack 魔法注释,打包拆分 chunk)
const User = () => import(/* webpackChunkName: "user-chunk" */ './views/User.vue');
const routes = [{ path: '/user', component: User }];Q5:VueRouter 如何实现嵌套路由?
答:
- 路由配置中通过
children定义子路由,父组件中必须添加<router-view />作为子路由的挂载点:
javascript
const routes = [
{
path: '/home',
component: Home,
children: [
{ path: 'page1', component: Page1 }, // 匹配 /home/page1
{ path: '', redirect: 'page1' } // 默认子路由
]
}
];4.Vuex 面试高频问题
Q1:Vuex 的核心模块有哪些?各自的作用?
答:
- State :存储全局状态(单一状态树),通过
this.$store.state或mapState访问; - Getter :基于 State 派生的计算属性(类似组件的
computed),支持传参、缓存,通过mapGetters访问; - Mutation :唯一修改 State 的方式(同步操作),通过
commit触发,必须是纯函数; - Action :处理异步逻辑(如请求接口),通过
dispatch触发,内部可 commit Mutation; - Module :拆分复杂状态(模块化),解决单一状态树体积过大问题,支持命名空间(
namespaced: true)。
Q2:Vuex 中 Mutation 和 Action 的区别?
答:
| 维度 | Mutation | Action |
|---|---|---|
| 操作类型 | 同步操作 | 异步操作(支持 Promise/async-await) |
| 触发方式 | store.commit('mutationName') |
store.dispatch('actionName') |
| 修改 State | 直接修改 | 间接通过 commit Mutation 修改 |
| 传参 | 第二个参数为 payload | 第二个参数为 payload,支持返回值 |
Q3:Vuex 模块化(Module)如何使用?命名空间的作用?
答:
- 模块化配置:
javascript
const userModule = {
namespaced: true, // 开启命名空间(核心)
state: () => ({ name: '小明' }),
mutations: { updateName(state, payload) { state.name = payload; } },
actions: { asyncUpdateName({ commit }, payload) { setTimeout(() => commit('updateName', payload), 1000); } }
};
const store = new Vuex.Store({
modules: { user: userModule }
});-
命名空间作用:
-
避免不同模块的 mutation/action/getter 名称冲突;
-
精准定位模块内的方法,如
store.dispatch('user/asyncUpdateName', '小红'); -
组件中通过
mapState('user', ['name'])映射模块内状态。
Q4:Vuex 数据持久化如何实现?
答:
- 核心思路:将 Vuex 的 State 同步到 localStorage/sessionStorage,页面刷新时从本地存储恢复。
- 实现方式 :
- 手动实现:监听
beforeunload保存 State,页面初始化时读取; - 插件实现(推荐):使用
vuex-persistedstate:
- 手动实现:监听
javascript
import createPersistedState from 'vuex-persistedstate';
const store = new Vuex.Store({
modules: { user: userModule },
plugins: [createPersistedState({
key: 'vuex-store', // 本地存储的 key
paths: ['user'] // 只持久化 user 模块,默认全部
})]
});Q5:Vue3 中 Vuex 被 Pinia 替代的原因?Pinia 对比 Vuex 的优势?
答:
- Pinia 优势 :
- 更简洁:无 mutations,直接在 action 中修改状态(支持同步 / 异步);
- 天生模块化:无需手动配置 namespaced,每个 store 就是独立模块;
- 更好的 TypeScript 支持:类型推导更完善,无需手动定义类型;
- 轻量化:体积更小,API 更简洁,无需嵌套模块;
- 兼容 Vue2/Vue3,支持 DevTools 调试。
Q6:Pinia常问
-
Pinia 响应式底层依靠什么? Vue3 的
reactive/ref;store 实例本质是一个 reactive 代理对象,所以直接修改属性能触发响应式更新。 -
Pinia 实现模块化的原理,怎么做到无命名空间冲突? 每个 store 通过唯一 id 独立创建,各自拥有独立 state、作用域; 不存在 Vuex 的 rootState、modules 嵌套,导入哪个 store 就只用哪个,天然隔离,不需要 namespaced:true。
-
Pinia 的 DevTools 调试原理? 内部订阅 state 和 actions 变更,把操作快照发送给 Vue DevTools; 支持时间旅行、回滚 state、追踪 action 调用,区分每个独立 store。
-
Pinia 数据持久化怎么做?两种方案 方案 1:原生 $subscribe 监听手动存 localStorage; 方案 2:插件 pinia-plugin-persistedstate(企业主流),一行配置自动持久化,支持 sessionStorage/cookie/ 加密。
javascript
// main.js
import piniaPluginPersistedstate from 'pinia-plugin-persistedstate'
const pinia = createPinia()
pinia.use(piniaPluginPersistedstate)
// store中开启
defineStore('user',{
state:()=>({}),
persist:true // 开启持久化
})- 组件中批量解构 store 丢失响应式怎么解决? 直接解构会脱离 reactive 代理,失去响应:
javascript
const store = useUserStore()
const { name } = store // 非响应式解决三种方案:
- 不解构,直接 store.name;
- 计算属性包裹。
- storeToRefs 工具函数(推荐):
javascript
import {storeToRefs} from 'pinia'
const { name } = storeToRefs(store)5.RTK(Redux Toolkit)面试高频问题
Q1:Redux Toolkit 是什么?解决了原生 Redux 的哪些痛点?
答:
- RTK 定义 :Redux 官方推荐的工具集,封装了
redux、redux-thunk、immer等核心库,简化 Redux 开发。 - 解决原生 Redux 痛点 :
- 原生 Redux 样板代码过多(actionType/actionCreator/reducer 分开写);
- 需手动配置中间件(如 thunk 处理异步);
- 不可直接修改 state(需手动浅拷贝,RTK 内置 immer 支持 "可变写法修改不可变数据");
- 需手动合并 reducer,RTK 提供
combineSlices简化。
Q2:RTK 的核心 API 有哪些?各自作用?
答:
- createSlice:核心 API,封装 actionType、actionCreator、reducer,支持 immer :
javascript
import { createSlice } from '@reduxjs/toolkit';
const counterSlice = createSlice({
name: 'counter',
initialState: { value: 0 },
reducers: {
increment: (state) => { state.value += 1; }, // 直接修改(immer 处理不可变)
decrement: (state) => { state.value -= 1; }
}
});
export const { increment, decrement } = counterSlice.actions;
export default counterSlice.reducer;- configureStore :替代
createStore,自动配置中间件(thunk)、devTools、合并 reducer:
javascript
import { configureStore } from '@reduxjs/toolkit';
import counterReducer from './counterSlice';
export const store = configureStore({
reducer: { counter: counterReducer }
});- createAsyncThunk:处理异步 action(如接口请求):
javascript
const fetchUser = createAsyncThunk('user/fetchUser', async (userId) => {
const res = await axios.get(`/api/user/${userId}`);
return res.data;
});
// 在 slice 中处理异步状态(pending/fulfilled/rejected)
extraReducers: (builder) => {
builder
.addCase(fetchUser.pending, (state) => { state.loading = true; })
.addCase(fetchUser.fulfilled, (state, action) => { state.loading = false; state.data = action.payload; });
}Q3:RTK 中如何处理异步逻辑?
答:
- 核心用
createAsyncThunk定义异步 action,返回 Promise; - 在
createSlice的extraReducers中监听异步 action 的三个状态:pending:请求中(可设置 loading 为 true);fulfilled:请求成功(处理返回数据);rejected:请求失败(处理错误);
- 组件中通过
dispatch(fetchUser(1))触发异步 action。
Q4:RTK Query(RTKQ)是什么?解决了什么问题?
答:
- RTKQ 定义:RTK 内置的数据请求层,替代 axios + 手动管理请求状态(loading/error/data);
- 核心优势 :
- 自动缓存请求数据,避免重复请求;
- 自动管理请求状态(loading/error/success);
- 支持数据失效、轮询、乐观更新;
- 减少样板代码(无需手动写 action/reducer 处理请求)。
Q5:RTK 中 immer 的作用?为什么可以 "直接修改 state"?
答:
- immer 作用:基于 "代理" 实现不可变数据的 "可变写法",简化状态更新逻辑;
- 原理 :RTK 的 reducer 中,immer 会将 state 包装为 Proxy 对象,看似 "直接修改 state",实际 immer 会在底层生成新的不可变对象,既保留了 Redux 不可变的核心原则,又简化了代码(无需手动
...state拷贝)。
6.浏览器工作原理
一、浏览器渲染过程
Q1:浏览器从输入 URL 到页面展示的完整流程?
答:
- URL 解析与网络请求 :
- 解析 URL 协议 / 域名 / 端口,若为域名则通过 DNS 解析成 IP 地址;
- 建立 TCP 连接(三次握手),发送 HTTP 请求;
- 服务器响应请求,返回 HTML/CSS/JS 等资源,TCP 四次挥手断开连接。
- 解析与构建阶段 :
- HTML 解析:生成 DOM 树(Document Object Model);
- CSS 解析:生成 CSSOM 树(CSS Object Model);
- 合并 DOM + CSSOM 生成渲染树(Render Tree) (只包含可见节点,排除
display: none元素)。
- 渲染与绘制阶段 :
- 布局(Layout/Reflow):计算渲染树节点的位置、大小,生成布局树;
- 绘制(Paint):将布局树节点绘制到屏幕(像素填充,如颜色、边框、背景);
- 合成(Composite):将绘制后的图层合成为最终页面(GPU 加速,避免重绘 / 重排)。
Q2:重排(Reflow)和重绘(Repaint)的区别?如何减少重排重绘?
答:
- 区别:
| 维度 | 重排(Reflow/Layout) | 重绘(Repaint) |
|---|---|---|
| 触发原因 | 元素几何属性变化(宽高 / 位置 / 尺寸)、DOM 增删、窗口大小变化 | 元素样式变化但不影响几何属性(颜色 / 背景 / 阴影) |
| 性能开销 | 大(需重新计算布局) | 小(仅重新绘制像素) |
| 关联关系 | 重排必然触发重绘 | 重绘不一定触发重排 |
- 优化手段:
- 批量修改 DOM(如用文档碎片
DocumentFragment、离线 DOM); - 避免频繁读取布局属性(如
offsetTop/clientWidth,浏览器会缓存,频繁读会强制重排); - 将元素设为图层(
will-change: transform/transform: translateZ(0)),图层重排不影响其他元素; - 避免使用
table布局(table 重排成本远高于普通元素)。
Q3:为什么 JS 会阻塞 DOM 解析?如何解决?
答:
- 原因 :JS 可修改 DOM/CSSOM(如
document.write改写 HTML),浏览器为避免解析冲突,会暂停 DOM 解析,先执行 JS 代码,执行完成后再继续解析。 - 解决方式 :
- JS 标签加
defer:异步加载 JS,DOM 解析完成后执行(按加载顺序执行); - JS 标签加
async:异步加载 JS,加载完成后立即执行(不保证顺序); - 将 JS 放在
</body>底部,等待 DOM 解析完成后执行; - 使用动态导入
import()懒加载非首屏 JS。
- JS 标签加
Q4:CSS 会阻塞 DOM 解析吗?会阻塞页面渲染吗?
答:
- CSS 不阻塞 DOM 解析(DOM 解析和 CSSOM 构建并行);
- CSS 阻塞页面渲染(渲染树依赖 DOM + CSSOM,CSSOM 未构建完成时,渲染树无法生成,页面会空白);
- 额外:CSS 会阻塞 JS 执行(JS 可能读取 / 修改 CSSOM,因此浏览器会等待 CSSOM 构建完成后再执行 JS)。
二、浏览器缓存原理
Q1:浏览器缓存分为哪几类?各自的特点和优先级?
答:按优先级从高到低:
- Memory Cache(内存缓存) :
- 特点:缓存在内存中,读取最快,页面关闭后失效;
- 缓存内容:JS/CSS/ 图片等资源(已解析的)。
- Disk Cache(磁盘缓存 / HTTP 缓存) :
- 核心分类:
- 强缓存:通过
Expires(HTTP1.0)/Cache-Control(HTTP1.1,优先级更高)控制,如Cache-Control: max-age=3600,缓存期内直接用本地资源,不发请求; - 协商缓存:强缓存失效后触发,通过
Last-Modified``/If-Modified-Since或ETag``/If-None-Match与服务器协商,资源未修改则返回 304,使用本地缓存;Last-Modified:响应头,服务器返回,最后一次修改的时间戳If-Modified-Since:请求头,浏览器发送,浏览器第二次请求同一资源时,从本地缓存中取出之前保存的Last-Modified时间ETag:响应头,服务器返回,服务端对资源的唯一标识If-None-Match:请求头,浏览器发送,浏览器第二次请求同一资源时,从本地取出之前保存的ETag
- 强缓存:通过
- 特点:缓存在硬盘中,页面关闭后仍存在,容量更大。
- 核心分类:
- Service Worker Cache :
- 特点:独立于主线程的缓存,可自定义缓存策略,支持离线缓存(PWA 核心)。
Q2:强缓存和协商缓存的区别?如何设置?
答:
| 维度 | 强缓存 | 协商缓存 |
|---|---|---|
| 请求发送 | 不发送请求,直接用本地缓存 | 发送请求,服务器判断是否用缓存 |
| 状态码 | 无(200 from disk/memory cache) | 304(未修改)/200(已修改) |
| 控制字段 | Cache-Control/Expires |
Last-Modified/ETag |
| 优先级 | 更高(优先触发) | 更低(强缓存失效后触发) |
设置示例(服务器响应头):
javascript
# 强缓存(1小时)
Cache-Control: max-age=3600
# 协商缓存
ETag: "abc123"
Last-Modified: Wed, 06 Mar 2026 10:00:00 GMT刷新对缓存的影响
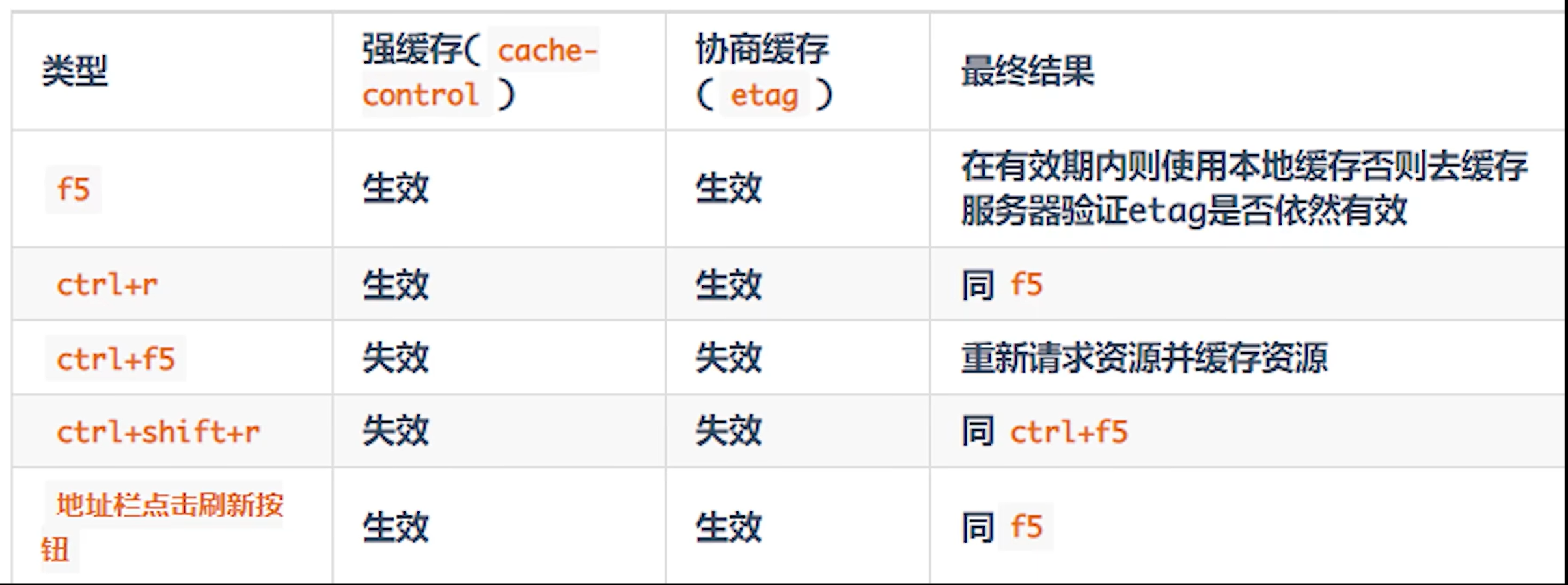
Q3:为什么需要 ETag?比 Last-Modified 有什么优势?
答:
- Last-Modified 缺陷:
- 精度只能到秒,文件若 1 秒内多次修改,无法识别;
- 服务器时间与客户端时间不一致时,判断失效;
- 文件内容未变,但修改时间变了(如重新保存),会误判为资源更新。
- ETag 优势:
- 基于文件内容生成唯一标识(如哈希值),内容不变则 ETag 不变,判断更精准;
- 不受时间影响,兼容性更好。
Q4:如何设置缓存策略更合理?
答:
- 首屏核心资源(如 HTML):禁用强缓存(
Cache-Control: no-cache),开启协商缓存(避免用户看到旧页面); - 静态资源(JS/CSS/ 图片):设置长时强缓存(
max-age=31536000)+ 文件名加哈希(如app.abc123.js),更新时改哈希即可触发重新请求; - 接口数据:根据时效性设置(如非实时数据用协商缓存,实时数据禁用缓存)。
三、事件循环(Event Loop)
Q1:浏览器事件循环的执行机制?宏任务(Macrotask)和微任务(Microtask)的区别?
答:
- 核心机制:
- ① 执行「执行栈」中的所有同步代码(从上到下、阻塞执行),直到执行栈为空;
- ② 执行「微任务队列」中的所有微任务(逐个执行,直到微任务队列清空);
- ③ 执行UI 渲染(更新 DOM、绘制页面);
- ④ 从「宏任务队列」中取出一个宏任务执行(仅一个),执行过程中产生的同步代码 / 微任务 / 新宏任务,会按规则进入对应队列;
- ⑤ 重复步骤①-④,直至所有任务队列清空。
- 宏任务 vs 微任务:
| 维度 | 宏任务(Macrotask) | 微任务(Microtask) |
|---|---|---|
| 核心定义 | 异步任务的 "大单元",执行间隔较长,可能触发渲染 | 异步任务的 "小单元",执行间隔极短,优先于渲染 |
| 包含类型 | script 整体代码(执行单元)、setTimeout/setInterval、AJAX(XHR/fetch)、DOM 事件(click/load)、setImmediate(非标准) | Promise.then/catch/finally、async/await(本质是 Promise)、MutationObserver、queueMicrotask () |
| 执行时机 | 微任务队列清空 + UI 渲染后,每次仅执行一个 | 同步代码执行完后,立即执行所有微任务(队列清空) |
| 优先级 | 低(微任务之后执行) | 高(宏任务内同步代码执行完后优先执行) |
| 与渲染的关系 | 执行完一个宏任务后,先清微任务、再渲染 | 微任务执行完后触发渲染,微任务内的 DOM 修改会同步渲染 |
Q2:手写代码题:说出执行顺序
javascript
console.log('1');
setTimeout(() => {
console.log('2');
Promise.resolve().then(() => console.log('3'));
}, 0);
Promise.resolve().then(() => console.log('4'));
async function fn() {
console.log('5');
await Promise.resolve();
console.log('6');
}
fn();
console.log('7');答案 :1 → 5 → 7 → 4 → 6 → 2 → 3解析:
- 同步代码:
console.log('1')→fn()执行(打印 5)→console.log('7'); - 微任务队列:
Promise.then(4)、await后的console.log('6')(await 后是微任务); - 执行所有微任务:打印 4 → 6;
- 宏任务队列:
setTimeout回调(打印 2),执行后触发微任务console.log('3'); - 执行微任务:打印 3。
Q3:async/await 的执行机制?和 Promise 的关系?
答:
- async/await 是 Promise 的语法糖,底层基于微任务:
async函数执行时,先同步执行到await处;await后的表达式执行(如Promise.resolve()),返回 Promise;await后的代码(如console.log('6'))被包装成微任务,加入微任务队列;- 同步代码执行完后,再执行该微任务。
Q4:Node 事件循环和浏览器事件循环的区别?
答:
- 核心区别:
- 任务队列分类不同:Node 事件循环分 6 个阶段(timers、pending callbacks、idle/prepare、poll、check、close callbacks),浏览器只有宏 / 微任务;
- 微任务执行时机不同:Node 11 前,每个阶段执行完后执行微任务;Node 11+ 与浏览器一致(宏任务后执行所有微任务);
- 宏任务优先级不同:Node 中
process.nextTick(微任务)优先级高于 Promise.then,浏览器中微任务优先级一致。
总结
- 渲染过程:URL → 网络 → DOM/CSSOM → 渲染树 → 布局 → 绘制 → 合成;重排 / 重绘的区别与优化是核心;
- 缓存原理 :强缓存(
Cache-Control)> 协商缓存(ETag),静态资源用 "长时强缓存 + 哈希",HTML 用协商缓存; - 事件循环:同步 → 宏任务(一个)→ 微任务(所有)→ 渲染,async/await 是 Promise 语法糖,微任务优先级高于宏任务。
7.性能优化
一、首屏加载优化
1. 怎么优化首屏加载速度?
- 路由 / 组件 懒加载
- 静态资源 压缩、合并、分包
- 图片优化:WebP、压缩、懒加载、雪碧图
- HTTP 缓存:强缓存 + 协商缓存
- CDN 加速静态资源
- 减少第三方包体积,tree-shaking
- 服务端优化:SSR/SSG、接口合并、减少请求
2. 什么是懒加载?怎么实现?
- 图片懒加载:
loading="lazy"/ IntersectionObserver - 路由懒加载:
() => import('./xxx') - 作用:减少首屏资源体积,提升 FCP、LCP
二、网络 / HTTP 优化
3. 浏览器缓存怎么优化?
- 强缓存 :
Cache-Control: max-age - 协商缓存 :
ETag / If-None-Match - 静态资源:长缓存 + 文件名哈希
- HTML:一般用协商缓存
4. 如何减少 HTTP 请求?
- 合并接口、合并小图片
- 雪碧图、内联小图片(base64)
三、渲染优化
5. 重排(reflow)重绘(repaint)是什么?怎么优化?
- 重排:改位置 / 大小,开销大
- 重绘:改颜色 / 样式,开销小
- 优化:
- 批量修改 DOM
- 离线 DOM(DocumentFragment)
- 使用
transform / opacity开启 GPU 加速 - 避免频繁读取布局属性
6. 如何避免卡顿、掉帧?
- 减少长任务(>50ms 会卡)
- 复杂计算放到 Web Worker
- 防抖节流(
debounce / throttle) - 合理使用
requestAnimationFrame
四、React / Vue 框架优化
7. React 怎么优化渲染?
React.memo缓存组件useMemo缓存计算结果useCallback缓存函数- 列表加唯一
key - 避免在 render 里创建新对象 / 函数
8. Vue 怎么优化?
v-once只渲染一次v-show替代频繁切换的v-if- 路由懒加载
- computed 缓存计算
- 大数据列表用虚拟滚动(只渲染当前视口内的列表项,而非全部数据)
五、图片 / 资源优化
9. 图片怎么优化?
- 使用 WebP/AVIF
- 图片压缩
- 图片懒加载
- 根据屏幕大小加载对应尺寸
- 小图用 base64 或雪碧图
六、性能指标
10. 核心性能指标有哪些?
- FCP 首次内容绘制
- LCP 最大内容绘制(核心)
- CLS 布局偏移
- INP 交互响应速度
- FPS 流畅度
七、你可以直接背的 "万能回答"
面试官问:你做过哪些性能优化?
直接答:
我主要从首屏加载、网络缓存、渲染优化、框架优化、图片优化五个方面做。
- 首屏用懒加载、代码分割、压缩打包,把 FCP 从 2.1s 优化到 0.9s;
- 网络用强缓存 + 协商缓存 + CDN,减少请求与耗时;
- 渲染避免频繁重排重绘,用
useMemo/useCallback减少不必要渲染; - 图片用 WebP、懒加载、压缩;
- 最终页面 FPS 稳定 55+,交互更流畅。
8.Git 协作流程
一、基础协作规范
Q1:Git 常用的协作分支模型有哪些?各自的适用场景?
答:
-
Git Flow(经典分支模型)
- 核心分支:
master/main:生产环境分支(稳定);develop:开发主分支(日常开发);feature/*:功能分支(从 develop 拉取,完成后合并回 develop);release/*:发布分支(从 develop 拉取,测试完成后合并到 master + develop);hotfix/*:紧急修复分支(从 master 拉取,修复后合并到 master + develop)。
- 适用场景:大型团队、版本迭代周期长、对稳定性要求高的项目(如企业级应用)。
- 核心分支:
-
GitHub Flow(简化分支模型)
- 核心规则:只有
main分支,所有功能开发从main拉取feature/*分支,完成后通过 PR/MR 合并回main,合并前必须通过代码评审和测试。 - 适用场景:小团队、敏捷开发、持续部署的项目(如前端小应用、ToC 产品)。
- 核心规则:只有
-
GitLab Flow(折中方案)
- 核心:以
main为核心,按环境划分分支(如pre/test/prod),通过 MR 逐级合并,兼顾规范与灵活性。 - 适用场景:中型团队、多环境部署的项目。
- 核心:以
Q2:日常开发中,你遵循的 Git 协作规范是什么?
答:
- 分支命名规范 :
- 功能分支:
feature/xxx-需求名称(如feature/user-login); - 修复分支:
bugfix/xxx-问题描述(如bugfix/order-pay-fail); - 紧急修复:
hotfix/xxx-紧急问题(如hotfix/home-crash)。
- 功能分支:
- 提交信息规范 :
- 格式:
type(scope): subject(如feat(user): 新增用户登录功能); - type 分类:
feat(新功能)、fix(修复)、docs(文档)、style(格式)、refactor(重构)、test(测试)、chore(杂项)。
- 格式:
- 协作流程 :
- 拉取最新主分支代码 → 新建功能分支 → 开发并频繁小提交 → 提 PR/MR → 代码评审 → 解决冲突 → 合并分支 → 删除本地 / 远程功能分支。
二、分支操作与冲突解决
Q3:多人协作时,如何处理 Git 冲突?
答:
- 预防冲突 :
- 频繁拉取主分支代码(
git pull origin develop),减少本地代码与远程的差异; - 按模块划分开发任务,避免多人同时修改同一文件。
- 频繁拉取主分支代码(
- 解决冲突(本地分支) :
- 步骤 1:拉取远程最新代码:
git pull origin develop; - 步骤 2:若出现冲突,Git 会标记冲突文件,打开文件找到
<<<<<<< HEAD(本地代码)、=======(远程代码)、>>>>>>> develop(冲突分界符); - 步骤 3:手动合并代码(保留正确逻辑,删除冲突分界符);
- 步骤 4:标记冲突已解决:
git add 冲突文件; - 步骤 5:提交解决后的代码:
git commit -m "fix: 解决与develop分支的合并冲突"。
- 步骤 1:拉取远程最新代码:
- 解决冲突(PR/MR 阶段) :
- 方式 1:本地拉取目标分支,合并后推送到功能分支,PR 会自动更新;
- 方式 2:在 GitLab/GitHub 界面直接编辑冲突文件,完成合并。
Q4:Git 中 merge 和 rebase 的区别?你在什么场景下使用?
答:
| 维度 | merge(合并) | rebase(变基) |
|---|---|---|
| 提交历史 | 保留原有提交记录,生成新的合并提交(历史呈 "分叉状") | 改写提交历史,将当前分支的提交 "移到" 目标分支最新提交之后(历史呈 "线性") |
| 冲突处理 | 只需要解决一次合并冲突 | 可能需要多次解决冲突(每一个提交都可能冲突) |
| 适用场景 | 公共分支(如 develop/main)合并 | 本地功能分支同步远程主分支代码(保持历史整洁) |
使用原则:
- 公共分支(如 develop)用
merge,避免改写公共历史; - 本地功能分支用
rebase同步远程主分支(如git rebase origin develop),让提交历史更清晰; - 禁止对已推送到远程的公共分支执行
rebase(会导致他人代码冲突)。
Q5:如何撤销已提交的代码?
答:
- 撤销未推送到远程的提交 :
- 撤销最后一次提交(保留代码修改):
git reset --soft HEAD~1; - 撤销最后一次提交(删除代码修改):
git reset --hard HEAD~1。
- 撤销最后一次提交(保留代码修改):
- 撤销已推送到远程的提交 :
- 方式 1(推荐):新建提交回滚:
git revert HEAD(生成反向提交,保留历史); - 方式 2(慎用):强制推送覆盖:
git reset --hard HEAD~1 && git push -f origin 分支名(会改写远程历史,仅限个人分支)。
- 方式 1(推荐):新建提交回滚:
- 撤销已添加到暂存区的文件 :
git reset HEAD 文件名。
三、进阶协作问题
Q6:如何处理大型版本的发布与回滚?
答:
- 版本发布 :
- 从 develop 拉取 release 分支(如
release/v1.2.0); - 在 release 分支做测试、修复小 bug(不新增功能);
- 测试通过后,将 release 分支合并到 main/develop,并打标签:
git tag -a v1.2.0 -m "发布v1.2.0版本"; - 推送标签到远程:
git push origin v1.2.0。
- 从 develop 拉取 release 分支(如
- 版本回滚 :
- 场景 1:发布后发现严重 bug,需回滚到上一版本;
- 步骤 1:找到上一版本的标签 / 提交哈希:
git log/git tag; - 步骤 2:创建回滚分支:
git checkout -b hotfix/rollback-v1.1.0 v1.1.0; - 步骤 3:将回滚分支合并到 main 分支,重新发布。
Q7:Git 子模块(submodule)的使用场景?如何操作?
答:
- 使用场景:项目中依赖独立的 Git 仓库(如公共组件库、工具库),需要单独维护版本。
- 核心操作 :
- 添加子模块:
git submodule add 仓库地址 目录名; - 拉取项目时同步子模块:
git clone --recurse-submodules 项目地址; - 更新子模块:
git submodule update --remote。
- 添加子模块:
Q8:如何避免多人协作时,误推敏感信息(如密钥)到远程?
答:
- 事前预防 :
- 在
.gitignore文件中添加敏感文件(如.env、config.js、私钥文件); - 使用环境变量或配置中心管理密钥,不硬编码到代码中。
- 在
- 事后处理 :
- 若已提交,使用
git filter-branch或 BFG Repo-Cleaner 工具删除历史中的敏感信息; - 立即更换泄露的密钥(如 API 密钥、数据库密码);
- 更新
.gitignore,避免再次提交。
- 若已提交,使用
9.Sass/Less 预编译工具
一、基础核心问题
Q1:Sass 和 Less 的区别?
答:
| 维度 | Sass(Scss) | Less |
|---|---|---|
| 语法风格 | 支持两种语法:缩进式(Sass)+ 花括号式(Scss,更接近 CSS) | 仅花括号式,完全兼容原生 CSS |
| 变量定义 | $变量名: 值(如 $primary: #0088ff) |
@变量名: 值(如 @primary: #0088ff) |
| 编译环境 | 基于 Ruby/Node.js(Dart Sass),需编译工具 | 可通过 JS 实时编译(浏览器端),也可预编译 |
| 嵌套规则 | 支持,且支持父选择器 & 进阶用法(如 &:hover) |
支持基础嵌套,& 用法与 Sass 一致 |
| 运算规则 | 单位运算更严格(如 10px + 5 会报错,需统一单位) |
单位运算更宽松(如 10px + 5 自动转为 15px) |
| 继承 / 混合 | @extend(继承选择器)+ @mixin/@include(混合器,支持参数) |
&:extend()(继承)+ .mixin() { } + @import(混合),参数支持较弱 |
| 条件 / 循环语句 | 支持 @if/@else、@for/@each/@while 等逻辑语句 |
仅支持简单条件(when),无原生循环(需借助递归) |
| 社区生态 | 更成熟,第三方库多(如 Compass、Bourbon) | 轻量,生态较简单 |
| 适用场景 | 大型项目、复杂样式逻辑(如组件库) | 中小型项目、快速开发 |
Q2:为什么使用 CSS 预编译工具(Sass/Less)?解决了原生 CSS 的哪些痛点?
答:
- 原生 CSS 痛点 :
- 无变量,重复值需多次修改(如主题色);
- 无嵌套,多层选择器代码冗余(如
.box .title .text); - 无复用机制,相同样式需复制粘贴;
- 无逻辑能力,无法根据条件生成样式。
- 预编译工具优势 :
- 变量化:统一管理主题色、尺寸等,一键修改;
- 嵌套化:简化层级选择器,代码更清晰;
- 复用化:通过混合(Mixin)/ 继承(Extend)复用样式,减少冗余;
- 逻辑化:支持条件、循环,动态生成样式(如生成多尺寸按钮);
- 模块化:通过
@import拆分样式文件,便于维护。
二、核心特性与实战应用
Q3:Sass 中 @mixin 和 @extend 的区别?各自的适用场景?
答:
| 维度 | @mixin(混合器) | @extend(继承) |
|---|---|---|
| 本质 | 定义可复用的样式片段,支持参数 | 继承已有选择器的样式,无参数 |
| 编译结果 | 样式会被复制到使用处(可能冗余) | 生成组合选择器(如 .btn, .btn-primary {}),代码更精简 |
| 灵活性 | 高(支持参数、默认值、逻辑) | 低(仅纯样式继承) |
| 适用场景 | 带参数的可变样式(如不同尺寸 / 颜色的按钮、圆角) | 纯静态样式复用(如基础样式、通用布局) |
示例:
css
// @mixin(带参数,适合可变样式)
@mixin btn($size: 14px, $color: #fff) {
font-size: $size;
color: $color;
padding: 8px 16px;
}
.btn-primary {
@include btn(16px, #0088ff); // 编译后样式直接复制到此处
}
// @extend(纯样式继承,适合静态样式)
.base-btn {
border: none;
border-radius: 4px;
}
.btn-secondary {
@extend .base-btn; // 编译后生成 .base-btn, .btn-secondary {}
background: #f5f5f5;
}Q4:如何在项目中配置 Sass/Less?
答:
1. Vue 项目配置 Sass(最常用)
- 步骤 1:安装依赖:
bash
npm install sass sass-loader --save-dev # Vue3 用 sass,Vue2 用 node-sass- 步骤 2:在
vue.config.js配置全局变量(可选):
bash
module.exports = {
css: {
loaderOptions: {
sass: {
additionalData: `@import "@/styles/variables.scss";` // 全局引入变量文件
}
}
}
};- 步骤 3:组件中使用:
html
<style lang="scss" scoped>
.box {
color: $primary; // 直接使用全局变量
}
</style>2. React 项目配置 Less
- 步骤 1:安装依赖:
bash
npm install less less-loader --save-dev- 步骤 2:修改
webpack.config.js(或 craco 配置):
bash
module.exports = {
module: {
rules: [
{
test: /\.less$/,
use: ['style-loader', 'css-loader', 'less-loader']
}
]
}
};Q5:Sass/Less 中的模块化如何实现?如何避免样式污染?
答:
-
文件拆分(模块化) :
- 按功能拆分样式文件:
variables.scss(变量)、mixins.scss(混合器)、reset.scss(重置样式)、components/button.scss(组件样式); - 通过
@import整合:main.scss中引入所有子模块,统一编译。
- 按功能拆分样式文件:
-
避免样式污染 :
- Vue 中使用
scoped属性:<style scoped>,通过添加唯一属性选择器隔离样式; - React 中使用 CSS Modules:样式文件命名为
xxx.module.less,组件中导入并使用:
javascriptimport styles from './App.module.less'; <div className={styles.box}>...</div>- 命名空间:为组件样式添加唯一前缀(如
.btn-component-xxx)。
- Vue 中使用
三、进阶深挖问题
Q6:Sass 的函数(Function)如何使用?举例说明?
答:
Sass 支持自定义函数,用于动态计算样式值(如颜色转换、尺寸计算),核心场景是主题适配、响应式尺寸计算。
css
// 自定义函数:计算响应式字体大小
@function rem($px) {
@return $px / 16 * 1rem; // 基于 16px 基准转换为 rem
}
// 自定义函数:加深颜色
@function darken-color($color, $percent) {
@return darken($color, $percent); // 调用 Sass 内置颜色函数
}
// 使用
.box {
font-size: rem(14); // 编译为 0.875rem
background: darken-color($primary, 10%); // 主色加深 10%
}Q7:PostCSS 和 Sass/Less 的区别?如何配合使用?
答:
- 核心区别:
| 维度 | Sass/Less | PostCSS |
|---|---|---|
| 定位 | 预编译工具(扩展 CSS 语法) | 后处理工具(转换已编译的 CSS) |
| 执行时机 | 编译阶段(CSS 生成前) | 编译后(CSS 生成后) |
| 核心功能 | 变量、嵌套、混合、逻辑 | 自动补全前缀(autoprefixer)、px 转 rem、样式 lint、压缩 |
- 配合使用流程:
- Sass/Less 编译为原生 CSS;
- PostCSS 处理编译后的 CSS(如 autoprefixer 补全
-webkit-前缀、px-to-viewport 转换单位); - 最终输出优化后的 CSS。
Q8:现在 CSS 原生支持变量、嵌套了,还需要用 Sass/Less 吗?
答:需要,核心原因:
- 兼容性 :CSS 原生变量(
--var)在低版本浏览器(如 IE)不支持,预编译工具编译后为原生 CSS,兼容性更好; - 功能丰富度 :CSS 原生仅支持基础变量、嵌套,无
@mixin、条件 / 循环、颜色函数等高级功能; - 工程化:预编译工具支持模块化拆分、全局变量注入,更适配大型项目的样式管理;
- 生态整合:可与 PostCSS、CSS Modules 无缝配合,形成完整的样式工程化体系。
10.TypeScript
1. TypeScript 是什么?和 JavaScript 的核心区别是什么?
答 :TypeScript 是 JavaScript 的超集,扩展了 JS 的语法,增加了静态类型系统,最终会编译为纯 JS 运行。核心区别:
- JS 是弱类型、动态类型语言(类型在运行时确定,易出现类型错误);
- TS 是强类型、静态类型语言(类型在编译期确定,提前发现错误);
- TS 支持接口、泛型、类型守卫等高级特性,JS 无原生支持。
2. 为什么使用 TypeScript?它能解决 JS 的哪些痛点?
答:核心解决 JS 弱类型导致的三大痛点:
- 类型安全:编译期校验类型,避免线上因类型错误(如传参错、访问不存在的属性)导致的 bug;
- 可维护性:类型定义即 "活文档",新人接手 / 代码重构时,通过类型就能理解数据结构,减少注释成本;
- 开发效率:编辑器基于类型推导提供精准补全、语法提示,降低拼写 / 逻辑错误。尤其适合中大型项目、团队协作场景。
3. TS 的基本类型有哪些?和 JS 类型的区别?
答:
- 基础类型:
string/number/boolean/null/undefined/symbol/bigint/Object(和 JS 一致); - TS 扩展类型:
any(任意值)、unknown(未知类型)、void(无返回值)、never(永不存在的值)、tuple(元组)、enum(枚举); - 核心区别:TS 增加了类型约束 ,比如
tuple限定数组长度和类型([string, number]),enum定义命名常量(enum Status { Success = 1 })。
4. interface 和 type 的区别?项目中如何选择?
答:
| 维度 | interface(接口) | type(类型别名) |
|---|---|---|
| 扩展性 | 支持多次声明自动合并(如扩展第三方库类型) | 不支持合并,一旦定义无法修改 |
| 适用场景 | 定义对象 / 类的结构(如组件 Props、API 接口) | 定义联合类型、交叉类型、基本类型别名 |
| 类实现 | 类可 implements 接口 |
类无法 implements 复杂 type(如联合类型) |
- 定义对象结构(如 Props、接口返回值)→ 用
interface(支持扩展); - 定义联合 / 交叉类型(如
type ID = string | number)→ 用type; - 简单场景两者均可,优先保持项目内统一。
5. 如何避免 any 类型的滥用?
答 :any 会失去 TS 类型校验的意义,核心替代方案:
- 精准类型 :已知结构用
interface/type定义,未知结构用unknown(更安全,使用前必须类型校验); - 类型缩小 :通过类型守卫(
typeof/instanceof/in)缩小类型范围,避免any; - 工程化约束 :
tsconfig.json开启noImplicitAny: true,强制推导类型,无法推导时报错; - 类型断言 :临时用
as断言(如data as User),但避免过度使用。
6. 泛型(Generic)的作用?举例说明使用场景?
答:泛型是 "类型参数化",让函数 / 接口 / 类支持多种类型,同时保持类型安全,核心场景:
- 通用工具函数:
TypeScript
// 支持任意类型数组反转,输入输出类型一致
function reverse<T>(arr: T[]): T[] {
return arr.reverse();
}
reverse(['a', 'b']); // 返回 string[],自动推导类型2.组件 Props 复用:
TypeScript
// 分页列表通用类型,适配不同数据类型
interface Pagination<T> {
list: T[];
pageSize: number;
}
type UserPagination = Pagination<User>; // 用户列表分页3.工具类型封装 :如 TS 内置的 Partial<T>/Required<T> 都是基于泛型实现。
7. 什么是类型守卫?常见实现方式?
答:类型守卫是运行时判断类型,缩小类型范围的手段,常见方式:
typeof:判断基本类型(typeof x === 'string');instanceof:判断类实例(x instanceof Array);in:判断对象属性('name' in x);- 自定义类型守卫:
TypeScript
function isUser(x: unknown): x is User {
return typeof x === 'object' && x !== null && 'name' in x;
}8. 如何处理异步请求的类型(如 API 接口)?
答:核心是定义接口规范,结合泛型约束返回值:
TypeScript
// 通用接口返回类型
interface ApiResponse<T> {
code: number;
data: T;
msg: string;
}
// 具体接口类型
interface User { id: number; name: string; }
// 异步函数类型标注
async function fetchUser(id: number): Promise<ApiResponse<User>> {
const res = await fetch(`/api/user/${id}`);
return res.json(); // TS 校验返回值是否符合类型
}9. React/Vue 中如何用 TS 实现组件类型安全?
答:以 React 为例(核心):
TypeScript
// 定义 Props 接口,明确类型约束
interface ButtonProps {
type: 'primary' | 'secondary'; // 限定枚举值
onClick: (e: React.MouseEvent<HTMLButtonElement>) => void;
children: React.ReactNode;
}
// 泛型组件标注 Props
const Button: React.FC<ButtonProps> = ({ type, onClick, children }) => {
return <button onClick={onClick}>{children}</button>;
};以 Vue3 为例:
TypeScript
<script setup lang="ts">
import { defineProps, defineEmits } from 'vue';
// Props 类型约束
interface Props { msg: string; count?: number; }
const props = defineProps<Props>();
// 事件类型约束
const emit = defineEmits<{ (e: 'change', value: number): void }>();
</script>10. unknown 和 any 的区别?为什么说 unknown 更安全?
答:
any:完全关闭类型校验,可任意访问属性、调用方法,无任何提示;unknown:类型安全的any,不能直接访问属性 / 调用方法,必须先通过类型守卫缩小类型范围;示例:
TypeScript
let a: any = 'hello';
a.foo(); // 无报错,运行时可能崩溃
let u: unknown = 'hello';
u.foo(); // 编译报错,必须先校验类型
if (typeof u === 'string') {
u.length; // 校验后可安全访问
}11. tsconfig.json 中核心配置项有哪些?
答:核心配置(影响类型校验和编译):
target:编译后的 JS 版本(如ES6);module:模块系统(如ESNext);strict:开启严格模式(包含noImplicitAny/strictNullChecks等);
TypeScript
// src/types/jquery.d.ts
declare module 'jquery' {
interface JQuery {
myPlugin(): JQuery; // 扩展 jQuery 方法
}
export default $;
}13. TS 中如何处理循环依赖?
答:核心方案:
- 类型导入 :用
import type导入仅用于类型的模块,避免运行时依赖;
TypeScript
import type { User } from './user'; // 仅导入类型,不生成运行时代码- 延迟导入 :运行时通过动态导入(
import())解决; - 提取公共类型 :将循环依赖的类型抽离到独立文件(如
types/common.d.ts)。
14. 如何实现 TS 类型的复用和模块化?
答:
- 抽离公共类型 :将通用类型(如 API 接口、工具类型)放在
src/types目录下,如types/api.d.ts、types/utils.d.ts; - 全局类型声明 :在
tsconfig.json中配置typeRoots,自动识别@types和自定义声明文件; - 工具类型封装:基于泛型封装通用工具类型(如分页、请求返回类型),跨模块复用。
15. TS 编译报错但运行正常,常见原因?
答:
- 原因 1:类型定义和实际值不匹配(如 API 返回值和定义的接口不一致);
- 原因 2:开启
strictNullChecks,但代码中未处理null/undefined; - 原因 3:第三方库无类型声明,用
any临时规避但类型校验不通过; - 解决:补充类型定义、开启非严格模式(临时)、用类型断言(
as)临时兼容。
总结
- 核心考点 :
interface/type区别、泛型、类型守卫、unknownvsany、严格模式配置是高频必问; - 答题技巧:结合项目场景回答(如 "在 XX 项目中,我用泛型封装了分页组件的类型,减少了重复代码");
- 避坑点 :避免滥用
any、忽略strictNullChecks、不写类型声明文件。
11.异步并发竞态治理
基础概念题
Q1:什么是接口竞态?举一个业务场景说明。 答:短时间并发多个异步接口,网络响应快慢不可控,请求发出顺序和响应返回顺序不一致,旧接口数据晚到达,覆盖最新页面数据,造成渲染错乱。 业务场景:商户首页多模块并行请求,慢接口后返回覆盖已有页面内容,出现数据闪烁、空白。
Q2:并发接口竞态会造成哪些线上问题? 答:1. 页面数据错乱、闪烁、空白,展示过期数据;2. 重复无效请求,增加后端服务器压力;3. 数据状态冲突引发前端渲染报错;4. 用户看到不一致数据,业务逻辑出错。
场景实操题
Q3:商户首页多模块独立请求并发产生时序错乱,你是怎么解决的? 答:基于 Promise + 请求状态锁封装全局请求调度工具,核心能力:
- 重复请求拦截:相同接口未完成时,阻止二次发起,取消重复请求;
- 请求状态锁管理:给每个接口维护 pending 状态标记;
- 竞态消除机制:区分请求批次,丢弃过期请求的返回结果;
- 统一调度所有页面接口,从根源解决时序错乱; 落地效果:线上数据报错率接近 0,后端无效请求减少 35%。
Q4:如何区分并丢弃过期的接口响应,解决时序覆盖问题? 答:两种主流方案,项目使用请求标记锁方案:
- 请求唯一批次标记:每次发起请求生成唯一 token / 序号,存储在当前页面作用域;接口返回时对比标记,标记不匹配则直接丢弃该次响应,不赋值页面;
- Axios CancelToken:切换页面 / 重复请求时取消上一次请求,不再接收回调;
- 状态锁 Map:全局 Map 存储接口 key 和 pending 状态,未完成的旧请求直接忽略回调执行。
Q5:什么是请求锁?你封装的全局调度工具里状态锁原理是什么? 答:请求状态锁本质是全局 Map 缓存,key 为接口唯一标识(url + 参数),value 存储请求 Promise、状态、批次标记;
- 发起请求前先查 Map,存在 pending 锁则拦截重复请求;
- 请求完成 / 失败后清除锁;
- 通过锁记录当前有效请求,旧请求响应到达时识别过期,不更新视图。
方案对比题
Q6:解决接口竞态有哪些常见方案,各自优缺点? 答:
- 串行请求(await 顺序执行):简单,但页面加载速度慢,首页体验差;
- Axios CancelToken 取消上一次请求:适合搜索、Tab 切换,无法处理多模块并行独立接口;
- 请求批次标记丢弃过期响应(项目方案):不阻塞并发加载,保留并行渲染速度,完美适配首页多模块场景;
- 防抖节流:仅适用于频繁触发类操作(搜索输入),不适用页面初始化批量请求。
Q7:为什么不使用串行 await 处理首页多模块接口? 答:串行会等第一个接口完成才请求下一个,拉长页面白屏加载时间,性能差;商户首页模块无依赖关系,应当并行请求提升加载速度,只需要治理竞态,不需要串行阻塞。
工具封装原理拔高题
Q8:简单说下你封装的全局请求调度工具核心实现思路? 答:
- 全局创建 pendingMap 作为状态锁容器;
- 封装基于 Axios 的统一 request 方法,入参携带接口唯一 key;(key 相同 = 同一查询,直接复用已有 pending Promise,不重复发接口)
- 发起前判断 Map 是否存在 pending 请求,存在则调用旧 CancelToken 取消请求,再复用 / 新建请求;(切换筛选、参数变更时,新旧 key 不一致,旧请求还在 pending,这里判断的是否为正在跑的请求,直接取消全部正在跑的旧请求,防止慢接口覆盖页面,解决竞态)
- 生成当前请求唯一批次标识,绑定 Promise 回调;
- 创建 Axios CancelToken 存入 Map,发起网络请求;
- 请求成功 / 失败后,清除 Map 中对应锁;
- 回调内部校验批次标识,过期请求直接 return,不赋值 state;
- 统一挂载 Axios 请求拦截、响应拦截、错误拦截,全局生效。
Q9:重复请求拦截逻辑怎么实现? 答:以 url + 请求参数序列化字符串作为唯一 key 存入 Map;调用接口时先校验 key 是否存在且处于 pending;若存在直接复用已有 Promise,不发起新 HTTP;请求结束删除 Map 内 key,释放锁。
Q10:多个页面同时调用同一个接口,请求锁会不会互相干扰?怎么处理? 答:会存在跨页面锁冲突;优化方案:给锁增加页面路由标识,Map 键改为「路由 + 接口 key」,不同页面的同接口互相不阻塞,仅同一页面内拦截重复请求。
性能与业务价值题
Q11:这套请求调度工具上线后带来哪些收益? 答:1. 彻底消除接口时序错乱导致的页面空白、数据闪烁,线上数据相关报错率接近 0;2. 拦截大量重复无效请求,后端请求量降低 35%,减轻服务器压力;3. 统一管理所有接口请求逻辑,复用拦截、锁、过期处理,减少重复业务代码。
拓展深挖题
Q12:Promise 本身能不能解决竞态?为什么? 答:不能。Promise 仅代表异步操作容器,无法控制网络返回顺序,多个 Promise 并行执行时,回调执行顺序完全由网络耗时决定,依旧会出现先请求后响应的竞态问题,必须额外增加批次 / 锁机制过滤过期回调。
Q13:Axios 中如何结合 CancelToken 与请求锁做双重优化? 答:在状态锁 Map 中同时存储 CancelToken 的 source 实例;发起同接口新请求时,取出上一次 source 调用 source.cancel () 终止旧网络请求;同时在响应回调中通过批次标记兜底过滤残留回调;双重保障:前端直接中断传输减少无效响应,标记兜底防止取消失败后的旧数据渲染,彻底杜绝竞态
补充配套概念面试题(Axios 专属,面试官大概率追问)
Q14:Axios 中 CancelToken 是什么?source.cancel () 作用是什么? 答:
- CancelToken 是 Axios 内置的请求取消机制,用于手动中断正在进行的网络请求,替代浏览器原生 AbortController(Axios v0.22 前标准方案);
- 调用 source.cancel (' 提示文案 ') 会立刻终止当前接口,进入 Axios 响应错误拦截,抛出 Cancel 异常,不会执行正常成功回调。
Q15:Axios 新版也支持 AbortController,为什么项目选用 CancelToken? 答:项目内部 Axios 版本偏低,未全面兼容 signal 绑定;CancelToken 兼容性更好,可直接存入请求锁 Map 统一管理,对老项目改造成本更低;新版本可混合使用 signal 与 CancelToken 双重取消
12.首屏加载全链路优化(多级资源预加载 + 接口内存缓存+懒加载 + 渐进式低清渲染)
基础业务题
Q1:你们首页首屏白屏久、海报资源大,做了哪些整体优化? 答:搭建三级缓存 + 多级资源预加载,搭配图片懒加载 + 渐进式渲染整套方案:
- 三级缓存:接口内存缓存、静态图片缓存、路由 keep-alive 页面缓存,减少 40% 重复网络请求;
- 多级预加载:按优先级预拉取首屏关键 JS、接口、海报资源,空闲时预加载次要资源;
- 图片优化:视口外图片懒加载,大图先用低清模糊图占位,高清图异步替换; 最终 FCP 从 2.37s 降至 1.32s,首屏速度提升 44%。
Q2:什么是三级缓存策略,分别怎么实现、解决什么问题? 答:分为接口内存缓存、静态图片缓存、路由页面缓存:
- 接口内存缓存:全局 Map 存储接口返回数据 + 过期时间,重复查询直接读内存,减少后端请求;
- 静态图片缓存:浏览器强缓存 + 内存缓存,加载过的海报图二次打开无需重新下载;
- 路由缓存:keep-alive 缓存页面组件实例,再次进入页面不重新请求基础数据、不重建 DOM; 三者配合,从接口、图片、页面三个维度避免重复资源加载。
多级资源预加载专项
Q3:多级资源预加载是怎么分级的,各级分别处理哪些资源? 答:分三档优先级:
- 最高优先级:首屏核心 JS、CSS、商户基础信息、顶部横幅接口,页面初始化立即并行预请求;
- 中优先级:首屏可视区内海报、封面图,通过 link preload 预加载;
- 低优先级:底部模块、弹窗、二级页面资源,使用 requestIdleCallback 在浏览器空闲时段加载,不抢占首屏带宽。
Q4:link preload 作用是什么?和懒加载冲突吗? 答:preload 是提前强制加载关键资源,用于首屏可视区大图、核心脚本;懒加载用于视口外图片;两者不冲突,可视区内预加载,可视区外懒加载,搭配使用。
Q5:requestIdleCallback 有什么用,为什么用它预加载次要资源? 答:该 API 在浏览器主线程空闲时才执行任务,不会抢占渲染、JS 执行主线程;次要资源放到空闲时加载,不会延长白屏、阻塞首屏渲染。
图片优化专项(高频)
Q6:图片懒加载怎么实现,为什么能优化首屏? 答:使用 IntersectionObserver 监听图片 DOM 进入可视区域后再请求图片;首屏只加载视口内少量图片,减少首屏并发请求数,降低网络阻塞,缩短加载时间。
Q7:渐进式低清渲染方案是什么,解决什么用户体验问题? 答:每张高清海报配套极小模糊缩略图;页面先展示低清占位图,同时异步请求高清大图,大图加载完成后平滑替换;避免大图加载期间大片空白,缓解用户等待焦虑,提升感知速度。
Q8:除了懒加载 + 渐进图,图片还有哪些配套优化手段? 答:1. 图片格式转换 WebP/AVIF,压缩体积;2. 图片尺寸适配,不同设备加载对应分辨率图;3. CDN 图片压缩;4. 静态图片开启强缓存 Cache-Control。
缓存机制深挖
Q9:接口内存缓存用 Map 实现有什么优缺点,怎么避免内存泄漏? 答:优点:读写速度远快于 localStorage,无序列化损耗,实时释放; 缺点:页面刷新缓存全部丢失,长时间页面停留会堆积数据; 处理泄漏:1. 页面路由离开时清空当前页面相关缓存;2. 设置缓存过期时间,定时清理过期数据;3. 切换商户 / 用户时全量清空缓存池。
Q10:内存缓存和 localStorage 缓存怎么取舍,为什么首屏接口优先用内存缓存? 答:localStorage 存在 JSON 序列化 / 反序列化性能损耗,容量有限;内存 Map 读写无转换开销,速度更快,适合首屏高频访问的临时接口数据;持久化数据才用本地存储,首屏临时数据只用内存缓存。
Q11:keep-alive 页面路由缓存有什么坑,怎么处理? 答:坑 1:页面缓存后接口不刷新,数据老旧;解决:路由进入钩子判断场景,主动清除对应接口缓存重新请求; 坑 2:缓存 DOM 过多占用内存;解决:设置 max 最大缓存页面数量,超出自动销毁; 坑 3:组件生命周期错乱;搭配 onActivated/onDeactivated 做缓存刷新与资源释放。
性能指标 & 收益题
Q12:FCP 是什么指标,优化前后数据怎么体现优化效果? 答:FCP 首次内容绘制,代表页面第一次渲染出可见内容的时间,是衡量白屏核心指标;优化前 2.37s,优化后 1.32s,速度提升 44%,直观说明白屏时间大幅缩短。
Q13:整套优化上线后带来哪些业务收益? 答:1. FCP 大幅降低,白屏等待变短,用户流失减少;2. 三级缓存减少 40% 重复网络请求,减轻后端与 CDN 带宽压力;3. 渐进式图片解决海报空白问题,用户体验显著提升。
拓展深挖拔高题
Q14:预加载会不会抢占首屏带宽,反而拖慢加载?怎么规避? 答:会,不分优先级全部预加载会造成请求并发拥堵; 规避方案:分级控制,核心资源立即预加载,次要资源利用浏览器空闲时段加载,不与首屏关键资源抢占网络。
Q15:如果用户网络很差,多级预加载策略需要降级吗?怎么处理? 答:需要降级;通过 navigator.connection 监测网络类型,弱网下关闭低优先级资源预加载,只预加载核心接口与首屏最小图片,优先保证页面基础渲染。
Q16:首屏资源还可以搭配哪些优化手段,和你这套方案配合? 答:1. 代码分割路由懒加载,减小首屏 JS 体积;2. 压缩打包、Tree-Shaking 剔除无用代码;3. 组件异步拆分;4. 骨架屏配合渐进图片,进一步优化感知体验;5. 静态资源 CDN 加速。
13.Vue 大文件分片上传 + 断点续传组件
一、基础概念类(必问,入门打底)
1. 为什么大文件不能直接整文件上传,要分片?
答:
- 浏览器请求有超时限制,超大文件一次性上传极易超时失败;
- 网络中断、刷新页面会导致全部重传,流量损耗大;
- 服务器单请求接收大文件内存占用高,容易 OOM;
- 分片可并行上传,提升上传速度;支持断点续传,只重传失败分片。
2. Blob、File、ArrayBuffer 三者关系,你怎么切割文件?
答:
- File 继承自 Blob,是本地文件特殊 Blob;
- 文件切割核心:
file.slice(start, end)返回 Blob 分片; 流程:计算分片大小(如 5MB)→ 循环计算每片起止下标 → slice 切割生成单个分片 Blob。
3. MD5 文件指纹作用是什么?为什么不用文件名做唯一标识?
答: MD5 用途:
- 全局唯一文件指纹,区分不同文件,实现断点续传匹配;
- 分片前后校验:前端分片 MD5 + 后端校验分片完整性,防止传输损坏;
- 秒传:后端存在相同 MD5 文件,直接返回上传完成,无需传分片。 不用文件名:同名不同内容文件、用户重命名、大小写、后缀修改都会冲突。
4. 断点续传核心逻辑是什么?
答:
- 上传前计算完整文件 MD5;
- 请求后端接口,携带 fileMd5 查询已上传分片列表;
- 前端对比本地全部分片下标,过滤掉已上传分片,仅上传缺失分片;
- 上传过程用 localStorage/indexDB 缓存上传进度、分片状态,刷新页面不丢失进度。
二、核心实现原理类(面试重点深挖)
1. 大文件计算 MD5 会卡顿页面,你怎么优化?
答: 原生同步读取文件计算 MD5 会阻塞主线程,页面卡死,优化方案:
- WebWorker:文件切片后在 worker 中异步计算 MD5,不阻塞 UI;
- 分块增量计算:不用一次性读取整个文件,分段读取逐步生成 md5;
- 限制 worker 数量,避免多文件上传创建大量线程;
- 降级:极小文件直接主线程计算,大文件走 worker。
2. 分片并行上传如何实现?怎么控制并发数量?为什么要限制并发?
答: 实现:使用 Promise 队列 + Promise.allSettled,多请求同时发分片; 并发控制:手写并发调度器,设置最大并发数(如 3/5),避免一次性发起几十条请求; 限制并发原因:
- 浏览器同源请求有最大连接限制(Chrome 同域 6 个),超量请求排队阻塞;
- 大量并发占用带宽,单分片上传速度下降,甚至丢包;
- 防止服务器短时间接收海量请求压垮接口。
3. 单个分片上传失败,自动重试机制怎么设计?
答:
- 每个分片维护状态:pending/success/fail;
- 分片请求捕获异常 / 后端返回失败状态码,标记失败;
- 重试策略:单分片最大重试次数(3 次),间隔递增重试(1s、2s、4s 指数退避);
- 重试耗尽仍失败:暂停上传,提示用户手动重试整个任务;
- 区分错误类型:4xx 客户端错误不重试,5xx / 网络中断触发重试。
4. 分片全部上传完成后,后端合并文件流程,前端需要做什么?
答: 前端操作:
- 所有分片上传成功后,调用合并接口;
- 参数携带文件 MD5、总分片数、文件名、文件大小; 后端逻辑:
- 根据 md5 找到对应分片文件夹;
- 按分片下标顺序读取所有分片二进制流,合并为完整文件;
- 校验合并后文件总大小、整体 MD5,校验失败返回前端重新上传缺失分片;
- 清理临时分片文件,返回完整文件访问地址。
5. 你用什么存储上传进度、分片状态?localStorage 和 IndexedDB 怎么选?
答:
- localStorage:容量小(5M),仅存简单 md5、进度、分片下标列表,适合小缓存;刷新页面读取恢复续传;
- IndexedDB:异步大容量存储,适合超大文件、多任务同时上传场景,存储完整分片状态、文件信息; 业务选择:单文件简单上传用 localStorage;多文件批量上传组件用 IndexedDB。
三、Vue 组件封装 & 工程化复用问题(贴合你的场景:全局公共组件)
1. 你如何封装成全局公共组件,全项目页面复用?有几种调用方式?
答: 两种封装方案同时实现:
- 组件式调用:全局注册
UploadBigFile,页面 template 直接标签使用,支持插槽自定义上传区域、进度展示; - 函数式调用(挂载 Vue 原型 / 单独 utils):
this.$uploadBigFile({ file, success }),弹窗上传,无需写 DOM; 工程化:
- 单独文件夹维护组件、上传工具类、api 请求、worker 文件;
- 抽离纯逻辑工具类
uploadChunk.js,解耦 DOM,方便其他 JS 文件复用; - props 提供配置项:分片大小、并发数、重试次数、接口地址、是否开启秒传;
- 事件抛出:onProgress、onSuccess、onError、onCancel,页面自定义业务逻辑。
2. 组件如何解耦?DOM 视图、上传核心逻辑、请求 API 分层?
分层结构(面试官爱问架构分层):
- 视图层:Vue 组件,只负责渲染上传按钮、进度条、错误提示,不处理上传逻辑;
- 核心工具层(纯 JS):分片切割、MD5 计算、并发调度、断点校验、重试逻辑;无 Vue 依赖,可单独导入;
- API 请求层:统一封装 axios 分片请求、查询分片、合并接口,统一处理请求头、token、错误拦截;
- WebWorker 层:单独 md5.worker.js,单独文件不污染主线程。
3. props 设计有哪些关键配置?如何做到页面灵活自定义?
核心 props: chunkSize 分片大小、maxConcurrent 最大并发、retryTimes 单分片重试次数、api 接口地址、autoRetry 自动重试、enableMd5 秒传开关、accept 文件类型、limit 多文件数量; 自定义能力:上传区域插槽、进度自定义插槽、错误提示插槽;支持 v-model 双向绑定上传列表。
4. 多文件同时上传怎么处理?组件如何管理多个上传任务?
答: 内部维护任务队列 Map,key 为文件 md5,value 为单个文件上传实例; 每个文件独立拥有:分片列表、进度、并发调度器、重试计数; 支持单独取消单个文件、清空全部、暂停 / 继续单个任务; 全局统一控制最大总并发,防止多文件叠加请求超限。
四、网络、性能优化面试题
1. 分片上传请求头、参数怎么设计?后端接收哪些参数?
前端每片请求携带: 文件 md5、chunkIndex 分片序号、chunkSize 分片大小、fileTotalSize、blob 分片二进制(FormData 传递); 查询分片接口:仅传 fileMd5; 合并接口:fileMd5、totalChunks、filename。
2. FormData 上传二进制分片,有什么优化点?
- 不用每次创建新 FormData,复用实例;
- 取消上传时调用
xhr.abort()中断请求,释放网络资源; - axios 配置取消令牌,支持批量取消所有分片请求;
- 避免携带多余参数,减少请求体体积。
3. 如何精准计算实时上传进度?
答:
- 记录每个分片大小,维护已上传总字节数;
- 累加所有成功分片字节 + 当前上传分片已传输字节;
- 进度 = 已上传总字节 / 文件总大小 * 100; 注意:不能按分片数量简单百分比,分片最后一片大小不统一,会进度失真。
4. 网络弱网场景怎么兼容?
- 分片重试指数退避,不频繁轰炸接口;
- 离线监听:navigator.onLine,断网自动暂停,联网后恢复续传;
- 超时配置:单个分片单独设置 timeout,避免单个慢分片阻塞整个任务;
- 缓存分片状态,刷新页面可恢复。
五、异常、边界故障场景(区分初级 / 高级候选人)
1. 上传中途关闭页面、刷新、浏览器崩溃,如何恢复断点?
答: 每成功上传一个分片,立刻持久化存储该分片下标(localStorage/IndexedDB); 再次选择同一文件时,先读取本地缓存 md5,请求后端校验已上传分片,合并本地缓存与后端数据,过滤已上传分片,直接续传。
2. MD5 计算失败、文件损坏怎么处理?
- Worker 异常捕获,提示文件读取失败;
- 文件读取中断(本地文件删除 / 损坏)直接终止任务,抛出错误;
- 提供重新选择文件按钮重置任务。
3. 后端合并文件校验 MD5 不一致,前端怎么处理?
答:
- 后端返回校验失败,告知缺失 / 损坏分片下标;
- 前端自动筛选对应分片,重新发起上传;
- 多次校验失败提示用户网络异常,建议重新上传。
4. 用户中途取消上传,需要做哪些清理工作?
- 通过 axios 的 AbortController 批量中断所有分片请求,区分手动取消不触发重试;
- 清空并发调度队列,停止分发新的分片请求;
- 终止 MD5 计算 WebWorker,清空内存里的分片、进度、任务实例;
- 删除 IndexedDB/localStorage 中该文件 md5 对应的断点缓存;
- 可选调用后端接口删除服务器临时分片;
- 重置 UI 进度,抛出取消回调,完成业务层面清理。
补充代码示意(AbortController 标准用法)
javascript
// 每个分片创建控制器
const controller = new AbortController()
this.abortList.push(controller)
axios.post('/upload/chunk', formData, {
signal: controller.signal
})
// 取消时统一中断
cancelUpload() {
this.abortList.forEach(controller => controller.abort())
this.abortList = []
// 后续执行队列清空、缓存删除、worker终止...
}六、拓展、进阶深挖(3 年 + 开发必问)
1. 除了 Blob 分片,还有没有其他大文件上传方案?优缺点对比
- 分片上传(当前方案):兼容性好、断点续传、可控,主流方案;
- WebSocket 流式上传:实时流传输,不适合大文件断点恢复;
- 流媒体 MediaSource:多用于视频,普通文件不适用;
- 第三方 OSS 直传(阿里云 / 腾讯云):前端直传 OSS,减轻业务服务器压力,分片逻辑由 OSS 提供。
2. 如果对接 OSS 对象存储,分片上传逻辑要怎么改动?
- 前端先向后端获取 OSS 上传凭证;
- 调用 OSS 原生分片上传接口,OSS 自身支持断点、分片合并;
- 不再需要业务服务器存储临时分片,节省服务器资源;
- MD5 校验逻辑保留,用于秒传和文件校验。
3. 如何实现上传限速?
在并发调度器中增加上传间隔控制,限制同一时间传输字节总量;通过延迟下一个分片请求降低整体上传速度,提供限速开关给用户。
4. 讲一下整体组件完整执行流程(高频流程口述题)
- 用户选择本地 File 文件;
- 初始化上传任务,创建 WebWorker 异步计算文件 MD5;
- MD5 生成完成,请求后端查询该 md5 已上传分片;
- 对比本地所有分片下标,过滤出未上传分片;
- 启动并发调度器,并行上传剩余分片,失败分片自动重试;
- 实时计算、更新上传进度;
- 所有分片上传成功,调用后端合并接口;
- 后端合并并校验文件完整性,返回文件地址;
- 触发 success 事件,清除本地临时缓存,上传完成;
- 中途断网 / 刷新:下次打开自动读取缓存,重复步骤 3 实现续传。
5. 项目中踩过什么坑?怎么解决(面试官最爱听实战坑)
- 同步计算 MD5 页面卡死 → 改用 WebWorker 增量计算;
- 并行请求过多浏览器阻塞 → 实现并发调度限制最大请求数;
- 刷新页面进度丢失 → IndexedDB 持久化分片状态;
- 最后一片分片大小不一致,进度计算错误 → 按字节而非分片数量算进度;
- 取消上传后请求还在后台发送 → axios 取消令牌 abort 中断 xhr;
- 多文件上传任务状态互相污染 → 使用 Map 隔离每个文件独立任务实例;
- 弱网下分片无限重试 → 增加最大重试次数 + 指数退避策略。
14.JSON 规则引擎(表单校验 + 动态表格)
一、基础背景类(开场必问)
1. 项目里为什么要做这套可配置 JSON 规则引擎?之前痛点是什么?
答:
- 页面泛滥:大量商户活动、运营表单、后台列表页面,每个页面单独写表单校验、表格列渲染、搜索条件、弹窗字段,重复代码极多;
- 硬编码维护成本高:新增 / 修改字段规则、表格列,必须改 Vue 模板 + JS 校验逻辑,多人开发容易出现格式不统一、校验遗漏;
- 复用性差:相同输入框(手机号、金额、身份证)、相同表格列(状态、操作按钮)每个页面重复复制粘贴;
- 迭代慢:新增商户活动页面,需要从零写模板、校验、表格渲染,重复工作量大;
- 规则散落在各个业务组件,没有统一标准,新人上手成本高。
所以抽离一套基于 JSON 配置的规则引擎,把渲染模板、校验规则、字段属性和页面业务代码完全解耦,统一配置驱动页面。
2. 你说组件复用提升 60%,开发效率提升 80%,这个数据怎么衡量出来的?
答:
- 复用率统计:改造前每个页面独立编写表单 / 表格组件,公共逻辑无法复用;改造后通用输入组件、校验规则、表格列全部抽入规则引擎,多页面共用一套配置,重复代码减少约 60%;
- 开发效率对比:
- 改造前:新增商户活动页,写模板、校验、表格、搜索平均 4~6 小时;
- 改造后:仅编写 JSON 配置,少量业务逻辑,平均 0.8~1 小时完成; 整体开发耗时降低 80%;
- 量化依据:对比同类型 3 个新旧活动页面代码行数,业务模板代码减少 80% 以上,公共通用逻辑统一维护。
3. 这套规则引擎主要支撑哪两块能力?
答:两大核心模块
- 动态表单模块:JSON 配置渲染表单组件、联动逻辑、校验规则、显隐、禁用、默认值;
- 动态表格模块:JSON 配置表格列、格式化、状态标签、操作按钮、排序、筛选、自定义插槽; 共用一套规则解析器、统一校验器、公共渲染组件。
二、架构 & 分层设计(核心重点,面试官深挖)
4. 整套规则引擎分层架构怎么设计的?如何实现业务解耦?
四层分层,完全解耦模板、规则、业务逻辑:
- 配置层(纯 JSON) 页面只导出一份配置对象,包含表单字段配置、表格列配置、校验规则、联动条件,无 DOM、无硬编码;
- 规则解析层(纯 JS 工具,独立 utils) 通用解析器:解析 JSON 配置,处理联动、显隐、格式化、分支条件; 统一校验引擎:解析 rules 数组,执行正则、非空、数字、自定义函数校验;
- 通用基础渲染组件层(全局公共组件)
- DynamicForm 动态表单组件
- DynamicTable 动态表格组件 只接收解析后的配置数据,负责渲染,不写任何业务相关逻辑;
- 业务页面层(Vue 页面) 只引入 JSON 配置、处理接口请求、特殊业务回调;模板一行代码渲染表单 / 表格,不再写循环、校验、列定义。
解耦关键点:页面不关心组件怎么渲染、怎么校验,只提供配置,所有通用能力下沉公共层。
5. JSON 配置长什么样?举一段表单 + 表格简单示例结构
动态表单配置示例
javascript
export const formConfig = {
labelWidth: "120px",
fields: [
{
field: "merchantName",
label: "商户名称",
type: "input",
placeholder: "请输入商户名称",
// 内置校验规则
rules: [{ required: true, message: "商户名称不能为空" }],
// 联动显隐规则
show: (formData) => formData.type === 1
},
{
field: "phone",
label: "联系电话",
type: "input",
rules: [{ pattern: /^1[3-9]\d{9}$/, message: "手机号格式错误" }]
},
{
field: "amount",
label: "活动金额",
type: "number",
rules: [{ min: 0, max: 999999, message: "金额范围0~999999" }]
}
]
}动态表格配置示例
javascript
export const tableConfig = {
border: true,
columns: [
{ label: "商户ID", prop: "id" },
{ label: "活动状态", prop: "status", type: "tag", tagMap: { 0: "未开始", 1: "进行中", 2: "已结束" } },
{ label: "操作", type: "action", btns: [
{ label: "编辑", click: "handleEdit" },
{ label: "删除", danger: true, click: "handleDelete" }
]}
]
}6. 校验规则引擎是怎么实现的?支持哪些校验类型?
- 内置基础规则:required、min/max 长度、数字区间、正则 pattern、邮箱、手机号、身份证;
- 联动条件校验:支持
when条件,满足条件才触发对应校验; - 自定义校验:支持传入 validator 自定义函数,处理复杂业务规则(如活动起止时间对比);
- 统一校验流程:
- 接收表单数据 + 字段 rules 配置;
- 循环遍历字段,逐条执行校验规则;
- 收集所有错误信息,统一返回,供 DynamicForm 渲染提示;
- 与 UI 解耦:校验逻辑抽离独立工具函数,表单组件只负责展示错误文案。
7. JSON 配置如何实现字段联动、显隐、禁用、只读?
两种实现方案结合:
- 简单静态联动:配置
show: boolean、disabled: boolean; - 动态联动:配置传函数
show(formData)=>boolean,解析器实时传入完整表单数据,根据其他字段值动态控制当前字段显示 / 禁用; 页面输入值变化时触发解析器重新计算所有字段状态,驱动组件刷新。
8. 动态表格如何处理复杂场景:状态标签、格式化、操作按钮、自定义插槽?
- 内置类型映射:type=tag/text/number,配置 tagMap 自动渲染不同颜色标签;
- formatter 格式化函数:配置
formatter(row)=>string,处理时间、金额、百分比; - 操作按钮配置:统一 btns 数组,支持权限控制、弹窗、跳转、回调事件;
- 插槽兼容兜底:配置 slotName,页面可自定义插槽覆盖默认渲染,兼顾简单配置和复杂自定义需求。
三、工程化复用 & 落地问题(贴合你简历提升效率的点)
9. 怎么封装成全局公共组件,全项目页面一键复用?
- 全局注册
DynamicForm、DynamicTable,main.js 统一挂载; - 配置文件单独抽离
xxx.config.js,和业务页面分离存放,便于统一维护; - 提供统一工具函数
validateForm(formData, config),非 Vue 页面也能单独调用校验规则。 - 页面使用极简模板,无需循环、不用重复写 el-input/el-table-column:
javascript
<!-- 表单 -->
<DynamicForm :config="formConfig" v-model="formData" @submit="onSubmit"/>
<!-- 表格 -->
<DynamicTable :config="tableConfig" :data="tableList"/>10. 新增商户活动页面开发流程简化成什么样?怎么做到效率提升 80%?
改造前流程: 写 template 循环表单→逐个写校验规则→写表格列→写格式化函数→写状态标签→写操作按钮→处理显隐联动,大量模板代码;
改造后流程:
- 新建
activity.config.js,编写 JSON 表单、表格配置; - Vue 页面引入配置,一行标签渲染表单和表格;
- 仅编写接口请求、提交、删除等少量业务回调; 无需编写重复 DOM 和通用校验逻辑,90% 通用能力由规则引擎承载,极大缩短开发时间。
11. 多页面共用相同字段(手机号、金额、状态列)如何复用配置?
抽离公共配置片段,导出公共常量:
javascript
// src/config/common.js 全局公共规则
export const phoneField = {
field: "phone", label: "手机号", type: "input", rules: [...]
}
export const statusColumn = {
label: "状态", prop: "status", type: "tag", tagMap: {...}
}业务页面配置直接导入扩展,无需重复定义:
javascript
import { phoneField, statusColumn } from "@/config/common"
fields: [phoneField, ...其他字段]
columns: [statusColumn, ...其他列]四、性能、边界、兼容深挖(区分初级 / 中级)
12. 如果表单字段几十上百个,JSON 解析、联动判断会不会卡顿?怎么优化?
优化方案:
- 缓存解析结果:相同配置只解析一次,缓存字段计算后的状态;
- 节流处理联动更新:表单输入频繁变更时,用节流控制解析执行频率;
- 按需渲染:复杂长表单做虚拟滚动,只渲染可视区域字段;
- 轻量化解析器:解析工具只做纯数据处理,不产生 DOM 操作,无额外渲染开销;
- 区分静态 / 动态字段:无联动的静态字段提前预解析,减少运行时计算。
13. 复杂业务场景 JSON 配置不好表达怎么办?如何平衡「配置化」和「自定义代码」?
不能强制所有场景都用 JSON,采用配置优先,插槽 / 回调兜底策略:
- 简单通用场景:全部 JSON 配置驱动,快速开发;
- 复杂定制场景(复杂弹窗、特殊交互、复杂渲染):提供插槽、自定义 render 函数、自定义回调;
- 设计原则:80% 常规页面走配置快速开发,20% 复杂页面保留自定义扩展能力,不牺牲业务灵活性。
14. 校验大量字段时,会不会出现校验阻塞页面?
- 基础同步校验逻辑极轻量,不会阻塞;
- 存在异步校验(如商户名称重复请求后端校验):规则支持 async 自定义 validator,异步校验加 loading 状态,不阻塞主线程;
- 批量提交时统一收集校验结果,错峰展示错误提示。
15. 配置化后出现问题,如何快速定位是配置错误还是组件 bug?
- 配置解析器增加日志输出,打印字段解析、校验失败信息;
- 开发环境增加配置校验工具,校验 JSON 字段格式、必填参数是否缺失;
- 分层排查:先看配置是否正确→再看解析器输出数据→最后看公共组件渲染逻辑;
- 提供调试工具函数,页面打印解析后的完整字段状态。
五、踩坑 & 优化实战题(面试官最爱)
16. 开发这套规则引擎过程中踩过哪些坑?怎么解决?
- 坑 1:联动函数中修改表单数据造成死循环 解决:联动只读取 formData,不直接修改;修改值单独通过组件提供 setFieldValue 方法;
- 坑 2:大量页面重复导入公共配置,冗余代码多 解决:统一封装公共配置导出文件,全局引入;
- 坑 3:JSON 无法处理复杂异步校验、复杂渲染 解决:支持自定义 validator、render 插槽、页面回调函数作为扩展;
- 坑 4:配置层级太深,多人维护格式不统一 解决:编写 TS 类型定义 / JS 注释规范,统一配置模板,增加开发环境配置格式校验;
- 坑 5:表格格式化、标签逻辑散落在各个页面 解决:全部下沉到表格规则引擎,统一配置 tagMap/formatter。
17. 有没有用 TypeScript 约束这套 JSON 配置?怎么做类型提示?
加分回答: 定义表单字段、表格列、校验规则 TS 接口,给配置提供完整类型提示,约束必填参数、type 枚举值,从编译阶段规避配置写错字段名、属性不存在的问题,降低线上 bug。
六、拓展进阶问题(3 年 + 深度提问)
18. 这套规则引擎能不能扩展到低代码平台?如何改造?
可以,改造方向:
- 提供可视化配置面板,拖拽生成 JSON 配置;
- 配置持久化到后端,接口下发配置,页面动态拉取渲染;
- 增加组件物料库、条件分支、循环容器等高级配置; 当前实现是前端静态 JSON 配置,是轻量化低代码雏形。
19. 如果后端需要动态下发表单配置(不同商户不同表单),你的引擎需要改动哪里?
仅改动两层:
- 配置层:不再本地导入 JSON,改为接口请求后端获取配置;
- 解析层无需改动,解析器只接收标准配置对象,不关心来源; DynamicForm/DynamicTable 组件完全不用修改,无缝兼容远程配置。
20. 和 Element Plus 自带表单校验、表格渲染相比,你的规则引擎优势在哪?
- 统一规范:全项目表单、表格一套标准,不会出现每个人写法不一致;
- 代码极简:不用写大量循环模板,页面代码量大幅减少;
- 开箱即用:内置手机号、金额、状态标签等通用业务规则,无需重复封装;
- 可复用:公共字段、表格列统一抽离,一处修改全页面生效;
- 解耦业务:页面只关心业务数据,剥离渲染与校验细节。
15.万级设备长列表虚拟列表优化
一、背景痛点类(开场必问)
1. 项目之前万级设备列表卡顿的根本原因是什么?
答:
- DOM 数量爆炸:一次性渲染上万条设备行,DOM 节点上千个,浏览器构建 DOM 树、布局树、渲染树开销极大;
- 滚动高频触发重排重绘:scroll 事件持续高频执行,每次滚动全量刷新列表;
- 内存占用高:每条设备包含状态标签、操作按钮、图标,大量 DOM 常驻内存,GC 频繁触发造成掉帧;
- 滚动时视图全部参与计算,页面 FPS 暴跌到 30 以内,滑动卡顿、滚动延迟,极端场景出现空白白屏。
2. 为什么不用分页 / 懒加载,非要做虚拟列表?两者区别?
答:
- 业务场景:设备列表需要快速上下自由滚动检索,分页需要切换页码、等待请求,用户体验差;懒加载滚动到底再加载,往上滚动还要重新请求,无法实现一次性全量本地数据流畅滑动;
- 分页:分割数据、减少单次 DOM,但滚动体验割裂;
- 虚拟列表:前端一次性加载全部万级数据,只渲染可视区域少量 DOM,滚动全程无接口等待,顺滑浏览全部数据,适配设备批量检索场景。
3. 简历里 FPS 从 30 提升到 70+,这个指标怎么观测、怎么验证优化效果?
答: 观测工具:Chrome Performance 面板、FPS meter、开发者工具渲染面板;
- 优化前:滚动时频繁红色长任务,主线程阻塞,FPS 稳定 20~30;
- 优化后:长任务消失,仅几十条固定 DOM 持续复用,滚动稳定 70 帧以上,接近显示器刷新率;
- 辅助指标:DOM 节点数量由上万降至 10~30 个可视 DOM,内存占用降低 60%+,无滚动白屏、滚动延迟消失。
二、虚拟列表核心原理(面试重中之重)
4. 虚拟列表核心实现原理是什么?
核心思想:只渲染视口内可见数据,复用固定数量 DOM,通过占位容器模拟总高度实现滚动条
- 外层滚动容器固定高度,生成一个空白占位 div,高度 = 总条数 × 单行高度,撑起完整滚动条;
- 容器内部只渲染可视区域 + 上下缓冲条数的真实 DOM 行(一般 20~30 条);
- 监听 scroll 滚动偏移,实时计算当前可视数据区间,替换 DOM 内列表内容;
- DOM 节点全程复用,不会新增 / 销毁大量节点,从根源减少渲染开销。
5. 单行高度分两种:固定高度 / 动态不定高度,分别怎么实现?你的设备列表用哪种?
- 固定高度(设备列表场景首选) 每条设备行高度统一,计算简单:总高度 = itemSize * total;根据 scrollTop 直接算出起始索引,性能极高,无额外计算损耗,我们项目设备行布局统一,采用固定高度方案。
- 动态不定高度 每条高度不一致,需要缓存每条真实高度、缓存每个条目 offsetTop,滚动二分查找可视区间;计算开销更大,适合图文混合不规则列表。
6. 缓冲区域是什么?为什么要设置上下缓冲条数?如何解决滚动白屏?
- 缓冲:可视区域上方、下方多渲染几条数据(比如各 5 条);
- 作用:快速大幅度滚动时,滚动计算有延迟,缓冲 DOM 提前渲染好,不会出现中间空白白屏;
- 无缓冲问题:快速滑动时计算还没完成,可视区 DOM 没更新,出现大片空白;
- 项目配置:上下各缓冲 5 条,彻底解决高速滚动白屏问题。
7. 虚拟列表三大核心计算逻辑,口述完整流程
- 基础参数:容器可视高度、单行高度、缓冲条数、滚动偏移 scrollTop;
- 计算起始索引 startIndex = Math.floor (scrollTop /itemSize) - 缓冲条数;
- 计算结束索引 endIndex = startIndex + 可视条数 + 上下缓冲条数;
- 计算偏移位移:用一个 transform: translate3d 垂直偏移真实 DOM 列表,模拟滚动位置,不修改 top(避免重排);
- 截取 startIndex, endIndex 区间数据渲染到复用 DOM 中。
8. 为什么用 translate3d 而不是 top/margin-top 做位移?
top/margin-top 会触发浏览器重排(回流),每次滚动重新计算布局,性能差; translate3d 开启 GPU 硬件加速,只触发复合层重绘,不影响页面布局,滚动性能大幅提升。
三、防抖、滚动性能优化配套方案
9. scroll 事件为什么要加防抖?防抖怎么配合虚拟列表使用?区分防抖 / 节流
- scroll 事件每秒触发几十上百次,不节流会频繁执行索引计算、数据切片、DOM 更新,主线程堵塞掉帧;
- 方案:使用节流 throttle(不是防抖)控制滚动计算频率,固定 50ms 执行一次滚动逻辑; 补充区分:
- 节流:滚动过程持续执行,控制频率,适合 scroll 拖拽;
- 防抖:停止滚动后延迟执行,适合滚动结束后统计、导出;
- 项目组合:滚动过程节流更新可视列表,滚动停止防抖执行统计、高亮定位等次要逻辑。
10. 除虚拟列表 + 节流防抖外,还做了哪些配套渲染优化?
- DOM 复用:固定 DOM 池,只替换内部文本、状态,不频繁创建销毁 div;
- 避免行内复杂渲染:设备状态标签、按钮使用 CSS 简单样式,移除滚动时动画;
- 图片懒加载:列表内设备图标使用懒加载,不在视口不请求图片;
- 避免滚动时读取 DOM 布局属性(offsetTop/clientHeight),全部缓存数值;
- 使用 requestAnimationFrame 在下一帧执行 DOM 更新,同步浏览器渲染周期;
- 列表容器开启 css will-change: transform,提前分配 GPU 资源。
四、工程化封装与业务落地(贴合 Vue 项目场景)
11. 在 Vue 中如何封装通用虚拟列表组件,全项目复用?组件设计关键 props
封装独立公共组件 VirtualList,解耦设备业务,其他长列表页面直接复用; 核心 props:
- data:完整万级设备数组;
- item-size:单行固定高度;
- height:外层滚动容器高度;
- buffer:上下缓冲条数;
- item-render:渲染每条行的插槽 / 渲染函数; 对外事件:滚动、选中行、数据切换回调; 页面使用示例:
javascript
<VirtualList
:data="deviceList"
:item-size="64"
:height="700"
:buffer="5"
>
<template #default="{ item }">
<!-- 单条设备UI:设备编号、在线状态、操作按钮 -->
</template>
</VirtualList>12. 万级设备数据一次性传入组件,会不会造成初始化卡顿?怎么处理?
优化手段:
- 数据分片赋值:接口返回万条数据,使用 requestIdleCallback 分批写入列表,不阻塞主线程;
- 初始只计算基础总高度,不循环遍历全部数据,初始化计算开销恒定;
- 不遍历全部数据做预处理,仅截取可视区间数据渲染。
13. 设备列表存在搜索、筛选、状态过滤,虚拟列表如何适配?
过滤逻辑在父页面处理,过滤后生成新数组传给 VirtualList; 组件内部监听 data 变化,重新计算总占位高度、重新计算可视索引,无需修改虚拟列表底层逻辑; 过滤后数据量变化也不会卡顿,因为始终只渲染可视区 DOM。
五、性能、边界问题 & 踩坑实战(高频深挖)
14. 快速滚动时出现数据错乱、重复行是什么原因?怎么修复?
原因:滚动节流延迟,上一次 DOM 更新未完成又执行下一次渲染,数据覆盖错乱; 解决:
- 每次更新前清除上一帧渲染任务;
- 使用唯一 key 绑定每条渲染行,Vue 精准 diff,避免复用 DOM 渲染错乱;
- 控制渲染逻辑单线程串行执行,避免并发计算。
15. 虚拟列表滚动定位(跳转到指定设备行)怎么实现?
根据目标索引计算偏移距离 scrollTop = index * itemSize,赋值给滚动容器 scrollTop,容器自动滚动到对应位置;搭配防抖,定位完成后高亮对应设备条目。
16. 大量设备行绑定点击、操作按钮事件,会不会造成性能损耗?怎么优化?
不每条 DOM 单独绑定事件,使用事件委托:外层虚拟列表容器统一监听点击,通过事件 target 区分当前点击设备条目,减少上千个事件监听,节省内存。
17. 虚拟列表有什么缺点?哪些场景不适合用?
缺点:
- 固定高度模式下,单行高度变更需要重新计算,维护成本增加;
- 复杂嵌套表格、多层树结构虚拟列表实现难度高; 不适用场景:
- 数据只有几十条,没必要增加虚拟列表复杂度;
- 每条高度差异极大且无法缓存的不规则图文列表。
18. 项目开发过程中踩过哪些典型坑?如何解决?
- 坑 1:无缓冲高速滚动出现大片白屏 解决:增加上下缓冲条数,提升渲染提前量;
- 坑 2:滚动使用 top 定位,持续重排导致 FPS 低 解决:替换为 transform3d GPU 加速;
- 坑 3:scroll 不加节流,主线程持续阻塞,帧率暴跌 解决:滚动计算逻辑加节流控制执行频率;
- 坑 4:Vue 渲染行不设置唯一 key,筛选后 DOM 复用错乱 解决:用设备唯一 ID 作为 key;
- 坑 5:初始化一次性遍历万条数据做处理,页面加载卡顿 解决:延后、分片处理数据,初始化只做高度计算。
六、进阶拓展问题(3 年 + 资深面试官提问)
19. 市面上虚拟列表方案对比:手写原生虚拟列表 /vue-virtual-scroller/el-virtual-list,你为什么选择自己封装?
- 第三方库体积大,内置很多不需要的不定高度、树列表逻辑,业务仅需固定高度设备列表,轻量化自研体积更小;
- 业务定制化需求:设备状态高亮、批量操作、滚动定位、设备筛选联动,第三方库扩展成本高;
- 自主可控,可针对性优化设备场景,搭配防抖、事件委托、设备特殊渲染逻辑深度适配,性能调优更灵活。
20. 如果是十万、百万级超大设备数据,当前方案如何升级?
- 前端内存压力大,结合虚拟列表 + 后端分片查询(无限滚动 + 虚拟混合方案);
- 缓存已请求分片数据,滚动到区间再请求对应设备数据,降低前端内存占用;
- 使用 WebWorker 预处理设备数据,避免主线程阻塞。
21. 如何监控虚拟列表性能,线上发现滚动卡顿怎么排查?
- 埋点:统计页面平均 FPS、长任务耗时、滚动延迟时长;
- 线上排查:
- 查看是否意外渲染大量 DOM(缓冲配置过大);
- 检查滚动回调内是否存在大量同步循环、DOM 读写;
- 排查是否有滚动动画、复杂 CSS 滤镜占用 GPU 资源。
七、口述完整优化流程(必背,面试官常让梳理方案)
- 现状:万级设备一次性渲染上万 DOM,scroll 高频触发重排,FPS 低、滚动卡顿、高速滑动白屏;
- 核心方案:自研固定高度虚拟列表组件,仅渲染可视区 + 缓冲 DOM,用占位 div 撑起滚动条,transform3d 做位移;
- 性能配套:scroll 滚动逻辑加节流,滚动结束防抖处理附加逻辑,事件委托减少监听、图片懒加载、GPU 加速;
- 业务适配:支持设备筛选、搜索、滚动定位、批量操作,封装为全局组件复用;
- 优化结果:DOM 数量缩减至 30 个以内,滚动 FPS 从 30 提升至 70+,万级列表上下滑动无卡顿、无空白白屏。
16.设备检索防抖 + 请求竞态优化(Vue3 Hook 封装)
一、背景痛点类(必开场提问)
1. 实时检索场景原始存在两个核心问题分别是什么?现象是什么?
答:
- 频繁重复请求(性能问题) 用户快速连续输入文字,每敲一个字符就发一次接口,短时间批量并发 axios 请求,浪费带宽、增加后端压力,输入过程页面频繁加载闪烁。
- 请求竞态:后发先至(数据错乱核心) 网络不稳定时,晚发起的请求先返回、早发起的请求后返回,旧接口结果覆盖最新检索条件的列表,设备页面数据来回闪烁、展示错误设备数据。
2. 简单说下什么是请求竞态(后发先至),举你项目里的实例?
用户输入 12:
- 输入 1 → 发起请求 A(耗时 1500ms)
- 立刻输入 2 → 发起请求 B(耗时 300ms) B 先返回,页面渲染 B 的设备列表;过一会 A 请求返回,直接覆盖页面,列表变回只搜 "1" 的旧数据,出现错乱闪烁,这就是竞态。
3. 为什么简单加 setTimeout 防抖无法彻底解决竞态?
单纯防抖只能减少请求次数,不能中断正在路上的旧请求: 即便间隔 500ms 发请求,若上一轮请求还在 pending,网络慢依旧会出现旧响应覆盖新数据,只能降低概率,无法根治数据错乱。
二、防抖原理与实现设计问题
4. 检索防抖的实现逻辑是什么?为什么选用节流不行?
- 防抖逻辑:输入停止后延迟 N 毫秒再发起请求;中途持续输入则清空定时器,重置倒计时。
- 场景区分:
- 防抖:适合输入框实时搜索(等用户输完再查);
- 节流:适合滚动、拖拽,固定频率持续执行; 实时检索核心需求是减少无效中间输入请求,因此用防抖。
5. 防抖延时一般设置多少毫秒?依据是什么?
项目统一设置 300~500ms;
- 太短:还是会大量发请求,失去防抖意义;
- 太长:用户输入完等待过久,交互卡顿; 300--500ms 是兼顾性能与用户体验的通用标准。
三、竞态解决方案核心:AbortController 高频深挖
6. AbortController 解决竞态的完整思路是什么?
- 每次发起新检索请求前,调用上一次请求的
controller.abort()终止未完成的旧 axios 请求; - 每次请求创建全新 AbortController 实例,挂载到当前接口;
- 被中断的请求会抛出
canceled错误,在响应拦截过滤,不执行列表赋值逻辑; - 保证永远只有最新一次检索请求能正常返回并渲染数据,彻底杜绝旧数据覆盖。
7. axios 如何绑定 AbortController?中断后会出现报错,怎么处理不污染业务错误提示?
javascript
const controller = new AbortController()
axios.get('/api/device/search', {
params: searchParams,
signal: controller.signal
})错误处理区分类型:
err.name === 'CanceledError':手动中断的请求,直接 return,不弹出错误提示、不更新列表;- 其他 5xx/4xx 网络错误,正常走业务报错逻辑。
8. 如果不使用 AbortController,还有哪些兜底方案?优缺点?
- 用标记位 flag(isLatestSearch):每次新请求置为 true,旧请求回调判断 flag=false 则不赋值; 缺点:请求依然在后台完成,占用网络带宽,大量无效请求堆积;
- 请求队列清空:记录所有 pending 请求,循环丢弃回调; 缺点:无法终止浏览器真实网络请求,仅前端拦截赋值,治标不治本。 最优方案一定是 AbortController 直接中断网络请求。
四、Vue3 Hook 工程化封装相关重点面试题
9. 为什么选择封装 Vue3 hook(useSearchDevice)而不是组件内硬写 / 全局混入?
- 复用性:多页面(设备列表、商户设备、监控设备)实时检索直接引入 hook,无需重复复制防抖、中断、清理逻辑;
- 逻辑解耦:检索防抖、请求管理、生命周期清理逻辑与 UI 模板完全分离;
- 无副作用:hook 作用域独立,不会像 mixin 存在命名冲突、变量覆盖问题;
- 统一管控:延时、请求中断、自动销毁逻辑统一维护,一处优化全页面生效。
10. 你的 hook 内部维护了哪些核心变量?
- timer:防抖定时器 ID,用于清空延时;
- abortController:保存当前请求控制器实例,用于中断旧请求;
- loading:检索加载状态;
- tableData:设备检索结果列表;
- searchParams:多字段检索条件。
11. 组件卸载时需要做哪些自动清理?为什么必须清理?
hook 内部监听onUnmounted执行双重清理,防止内存泄漏、页面销毁后回调执行报错:
- 清除防抖定时器 clearTimeout (timer),避免组件销毁后定时器还发请求;
- 判断 abortController 存在,执行 abort () 中断当前正在 pending 的检索请求; 不清理的后果:
- 页面关闭后定时器触发,发起无效请求;
- 接口返回后操作已卸载组件的响应式变量,Vue 抛出内存泄漏警告;
- 弹窗 / 路由切换后旧请求回来,污染新页面列表数据。
12. hook 如何支持多字段联合模糊检索?
hook 接收统一检索条件对象(设备名称、编号、在线状态、时间区间),每次输入任意字段变更触发防抖函数,统一把完整参数传给后端接口,无需单独处理单个输入框。
五、边界、异常与性能优化问题
13. 用户快速连续删除、粘贴大量文字,这套逻辑会不会失效?
不会: 每次输入变更都会清空上一次防抖计时器,重新计时;同时立刻中断上一轮未完成请求,保证只执行最新一次检索。
14. 同时存在输入检索 + 分页切换,如何避免两者互相产生竞态?
- 分页改变时,同样执行 abort 中断所有检索请求;
- 统一复用同一套 AbortController 实例,无论输入还是分页,新操作直接杀死旧网络请求;
- hook 对外暴露统一 search 方法,检索、分页共用一套请求管控逻辑。
15. 输入空值、全空格场景怎么优化减少无效请求?
在防抖执行的回调内增加前置校验: 过滤纯空、空白字符,直接清空列表并 return,不发起网络请求,节省接口调用。
16. 网络超时和请求中断怎么区分处理?
- 中断(CanceledError):静默丢弃,无提示;
- 超时 / 404/500:弹出业务错误提示,清空 loading,保留上一次有效列表数据。
六、完整执行流程口述题(面试官高频要求梳理流程)
- 用户输入设备检索字段,触发 v-model 更新;
- hook 触发防抖逻辑:清除原有定时器,重置 300ms 倒计时;
- 倒计时结束,执行检索函数: ① 判断存在上一次 abort 实例,调用 abort () 中断旧请求; ② 创建新 AbortController 保存到变量; ③ 携带完整多字段参数发起 axios 请求,绑定 signal;
- 请求成功:赋值设备列表,清除 loading;
- 请求被中断:捕获 CanceledError,不执行任何列表更新;
- 组件切换路由 / 关闭弹窗触发 onUnmounted:清除定时器、中断活跃请求,释放资源。
七、实战踩坑题(加分项,体现真实项目经验)
17. 开发过程踩过哪些坑,如何解决?
- 坑 1:只做防抖没中断请求,弱网依旧数据闪烁 解决:引入 AbortController 每次新请求终止旧请求;
- 坑 2:组件销毁未清理定时器,控制台大量 Vue 内存泄漏警告 解决:onUnmounted 统一清除 timer、中断请求;
- 坑 3:中断错误统一走业务报错弹窗,频繁输入弹出大量提示 解决:单独判断 CanceledError,跳过错误提示逻辑;
- 坑 4:多次快速输入,controller 重复覆盖导致无法中断上上个请求 解决:每次发起请求前先中断当前保存的 controller,再新建实例;
- 坑 5:hook 多组件共用,控制器变量互相污染 解决:hook 内部变量均为局部作用域,每个组件实例独立一套 timer、controller。
18. 和单纯在页面写防抖函数相比,hook 封装带来哪些工程化收益?
- 统一标准:延时、请求中断、销毁清理逻辑全局统一,不会每个人写法不一致;
- 减少重复代码:新页面实时检索只需引入一行 hook,不用重复写定时器、AbortController;
- 易于迭代:后续要修改防抖时长、增加请求拦截逻辑,仅修改 hook 一处;
- 逻辑内聚:检索相关状态、加载、清理全部收拢,可读性、维护性大幅提升。
八、拓展进阶深挖(3 年 + 中级 / 高级提问)
19. 如果同时开启多个 tab 页签检索设备,AbortController 会互相干扰吗?
不会,Vue3 hook 每一个组件实例拥有独立作用域,timer、abortController 都是局部变量,tab 之间完全隔离,互不影响。
20. 低版本浏览器不支持 AbortController 如何降级兼容?
降级方案组合:
- 存在 AbortController 则使用原生中断;
- 不存在时启用
isLatest标记位兜底,旧请求回调判断标记不赋值列表; - 同时保留防抖减少请求数量,双重保障避免数据错乱。
21. 如何拓展 hook 支持手动点击查询按钮、重置检索条件?
hook 对外暴露方法:
handleSearch():立即执行检索(跳过防抖延时);resetSearch():清空检索条件、中断当前请求、重置列表; 页面按钮可直接调用,一套逻辑同时支持实时输入检索 + 手动查询。
17.WebWorker 数万级设备数据运算(主线程阻塞优化)
一、背景痛点基础题(开场必问)
1. 为什么数万条设备筛选、统计会卡死页面?底层原理是什么?
答: JS 是单线程模型,主线程同时负责三件事:JS 逻辑执行、DOM 渲染、用户交互(点击 / 滚动输入)。 批量循环过滤、字段格式化、求和 / 分组统计属于密集同步计算,执行时独占主线程,浏览器无法渲染页面、响应鼠标操作,表现为页面卡死、滚动卡顿、按钮点不动。
2. 为什么不用 setTimeout /requestIdleCallback 拆分循环,非要用 WebWorker?两种方案优缺点?
- setTimeout 分片循环:只是把计算切成多段穿插执行,依旧跑在主线程,大量数据依然会出现轻微卡顿,只能缓解不能根治;且拆分逻辑代码繁琐,大量循环分片不好维护。
- requestIdleCallback 利用浏览器空闲时间运算:优先级极低,数据量大时计算完成速度极慢,无法满足批量统计实时出结果的业务需求。
- WebWorker:开辟独立后台线程,运算完全脱离主线程,UI 交互完全不受影响,海量数据筛选、分组统计性能最优,适合纯数据密集型运算场景。
3. 你的业务里 WebWorker 具体承载了哪些设备数据 heavy 运算?
三类耗时逻辑全部移入 worker:
- 批量筛选:多条件组合过滤设备数组(状态、在线、区域、设备类型多字段匹配);
- 数据格式化:统一时间格式化、状态码转中文标签、数值单位换算、空值清洗;
- 聚合统计:设备总数、在线离线数量分组、各类设备数量求和、平均值计算。
二、WebWorker 核心原理 & 通信深挖(面试核心)
4. WebWorker 工作机制是什么?主线程和子线程怎么通信?
- 主线程 new Worker ('xxx.worker.js') 创建独立线程;
- 两者完全隔离,不能互相访问 DOM、window、document、Vue 实例,无共享内存;
- 通信唯一方式:
postMessage()传递数据,通过message事件监听返回结果; - 数据传递采用结构化克隆算法,复制一份数据副本,不是引用传递。
5. postMessage 传上万条设备完整数组会不会性能损耗大?怎么优化大数据传输?
问题:数万条对象完整拷贝会有序列化开销,数据超大时传输慢。 优化方案分两种:
- 常规场景(万级设备):直接传递,业务可接受;精简传输字段,过滤无用冗余属性,减小数据体积;
- 超大十万级数据:使用
Transferable二进制转移(如 ArrayBuffer),所有权转移不复制内存,零拷贝; 本项目设备数据为普通 JSON 对象,无二进制,采用精简字段方案优化传输速度。
6. Worker 线程不能操作 DOM,那筛选完的数据怎么渲染页面列表?
流程:
- 主线程把原始设备数组、筛选条件传给 worker;
- worker 独立完成过滤、格式化、统计;
- 通过 postMessage 把处理后的结果数组 + 统计指标发回主线程;
- 主线程拿到纯数据,赋值给列表响应式变量,再由 Vue 渲染 DOM。 所有 DOM 渲染、UI 交互始终留在主线程,worker 只做纯数据运算。
7. WebWorker 常用生命周期事件有哪些,分别作用?
- message:接收对方发送的数据(核心通信事件);
- error:worker 内部计算报错,主线程捕获异常,避免整个页面崩溃;
- messageerror:传输数据序列化失败(传递循环引用对象会触发);
- terminate ():主线程手动销毁 worker,释放线程资源;
- self.close ():worker 内部自行关闭线程。
三、工程化封装(Vue3 项目落地高频问题)
8. Vue 项目中如何封装 WebWorker,避免重复创建线程?怎么处理打包路径问题?
- 封装通用数据处理 worker 文件
dataCalc.worker.js,统一承载筛选 / 格式化 / 统计逻辑; - 封装 useDataCalc 组合式 hook 管理 worker 实例:
- 组件初次加载创建一次 worker,复用线程,不重复 new Worker;
- 组件卸载自动 terminate 销毁,防止线程常驻内存泄漏;
- Vite/Webpack 打包适配:
- Vite:使用
new Worker(new URL('./xxx.worker.js', import.meta.url))解析路径; - Webpack:配置 worker-loader,区分工作线程文件; 不处理路径会出现 404,找不到 worker 脚本文件。
- Vite:使用
9. 多组件同时使用批量筛选,会创建多个 Worker 线程吗?如何控制线程数量?
- 基础方案:每个 hook 实例独立 worker,简单但大量页面会创建多线程,浏览器有线程上限(一般 8 个左右);
- 优化方案(项目采用):单例全局 worker,所有页面共用同一个后台线程,通过消息唯一标识区分不同组件的计算任务; 主线程发送消息携带
taskId,worker 返回结果带回 taskId,对应分发到对应组件,控制线程数量,避免浏览器线程耗尽。
10. hook 内部完整执行流程(口述必背)
- 用户切换筛选条件,触发筛选方法;
- 主线程判断 worker 是否存在,不存在则初始化创建;
- 发送 postMessage,携带:原始设备列表、筛选参数、taskId;
- 子线程接收数据,离线执行过滤、格式化、统计;
- 运算完成,将结果、统计指标、taskId 传回主线程;
- hook 监听 message 事件,匹配 taskId,更新页面列表与统计面板;
- 组件卸载调用 terminate () 销毁 worker,释放资源。
四、边界异常、性能优化实战题(区分初级 / 中级)
11. 往 postMessage 传递包含循环引用的设备对象会报错,怎么处理?
结构化克隆算法不支持循环引用,触发 messageerror:
- 预处理传参前深拷贝并清除循环引用字段;
- 只传递业务需要的纯基础数据字段,剔除互相引用的嵌套对象;
- 监听 messageerror 事件捕获异常,给用户提示数据解析失败。
12. 连续快速切换筛选条件,worker 多个计算任务并发返回,出现列表数据错乱怎么解决?
解决方案:
- 每次发起新运算时,记录最新 taskId;
- worker 返回结果时,对比当前最新 taskId,旧任务结果直接丢弃,不更新页面;
- 进阶:取消未完成旧任务(简易 worker 任务队列标记,放弃过期计算)。
13. 组件切换路由 / 弹窗关闭,不销毁 Worker 会有什么问题?
- 后台线程持续占用浏览器资源,多页面叠加造成线程堆积;
- worker 返回 message 时,组件已卸载,操作不存在的响应式变量,控制台 Vue 内存泄漏警告;
- 闲置线程持续占用内存,页面越多越卡顿。 处理:onUnmounted 钩子执行 worker.terminate () 彻底关闭线程。
14. Worker 内部运算报错如何捕获,不影响主线程整体功能?
主线程绑定 worker.onerror 监听错误:
- 捕获计算异常,打印错误日志;
- 清空 loading 状态,给用户友好提示「数据统计失败」;
- 不阻塞页面其他操作、滚动、点击。
15. 什么场景不适合使用 WebWorker?
- 数据量很小(几百条以内):创建线程、数据拷贝通信有额外开销,得不偿失;
- 需要 DOM 操作、window/BOM API 的逻辑(worker 无法访问);
- 频繁极小块即时运算,通信成本高于计算收益。
五、进阶深挖(3 年 + 高级面试提问)
16. WebWorker 共享线程方案 SharedWorker 和普通 Worker 区别,为什么项目不用?
- Worker:单页面私有线程,页面销毁线程销毁;
- SharedWorker:同域名多页面、多 tab 共享一个线程; 本项目设备筛选多为单页面独立运算,无需跨 tab 共享;SharedWorker 兼容性略差、调试复杂,因此选用普通 Worker。
17. 十万级超大设备数组传输,如何用 Transferable 优化传输性能?
如果后端返回二进制 / 数组缓冲区数据,传递时加第二个参数转移内存:
javascript
worker.postMessage(buffer, [buffer])所有权转移,不复制内存,大幅降低大数据传输耗时; 本项目是普通 JSON 设备对象无 ArrayBuffer,未采用该方案。
18. WebWorker 里能不能引入工具函数(日期格式化、过滤工具类)?
可以,worker 内部通过 importScripts () 引入公共工具脚本,把格式化、过滤通用方法抽离公共 js,主线程不用重复传递工具逻辑,简化 worker 代码。
19. 对比主流方案:分片循环 / WebWorker / 后端分页统计,各自适用场景?
- 分片循环:千条以内轻量计算,简单低成本;
- WebWorker:前端已有完整数万条数据,需实时多条件筛选、本地统计;
- 后端分页统计:数据百万级以上,前端无法一次性承载全量数据,每次筛选请求后端计算。
六、实战踩坑(面试官最爱加分项)
20. 开发中踩过哪些典型坑,怎么解决?
- 坑 1:Vue 打包后 Worker 文件 404 找不到 解决:Vite 使用 import.meta.url 构建 Worker 路径;
- 坑 2:传递超大数组页面短暂卡顿(序列化复制开销) 解决:精简传输字段,剔除无用属性,减少克隆体积;
- 坑 3:组件销毁未 terminate,后台线程残留内存泄漏 解决:onUnmounted 强制销毁 worker;
- 坑 4:多次快速切换筛选,旧任务结果覆盖最新列表 解决:taskId 标记,丢弃过期任务返回数据;
- 坑 5:worker 内部报错无捕获,页面无任何提示 解决:主线程绑定 onerror 捕获并提示用户;
- 坑 6:在 worker 中调用 window/document 直接报错 解决:把所有 DOM、Vue 相关逻辑留在主线程,worker 只做纯数据处理。
七、完整优化总结口述(面试收尾梳理方案)
原有问题:数万设备批量筛选、格式化、统计同步运算阻塞 JS 主线程,页面滚动、点击卡死; 解决方案:抽离纯数据密集逻辑到独立 WebWorker 线程,通过 postMessage 实现线程间数据通信;封装 Vue3 hook 统一管理 worker 实例、消息分发、自动销毁;通过 taskId 解决多任务返回数据错乱问题,组件卸载释放线程资源; 收益:海量数据运算完全不占用主线程,页面交互全程流畅无延迟,无卡死、无阻塞。
18.SSE 流式 AI 对话面试全套题
一、基础背景 & 选型类(开场必问)
1. 为什么 AI 流式对话不用轮询、WebSocket,选择 SSE?三者对比
(1)轮询(短轮询 / 长轮询)缺点
- 短轮询:定时发请求,空闲时大量无效 HTTP 请求,浪费带宽、后端压力大;消息延迟高,做不到实时打字效果;
- 长轮询:后端 hold 住连接,消息返回后立刻断开,下一条消息需要重新建连,频繁握手,AI 逐字输出场景延迟波动大,打字割裂。
(2)WebSocket 缺点
双向通信,但 AI 对话仅后端单向推流,不需要前端上行实时推送;
- 协议升级握手复杂,部分企业防火墙、反向代理不兼容 ws 协议;
- 需额外处理断线重连、心跳、二进制 / 文本解析,开发成本更高;
- 后端要维护 ws 连接池,资源开销高于 SSE。
(3)SSE 优势(贴合 AI 流式场景)
- 基于原生 HTTP/HTTPS,无需协议升级,nginx、网关兼容友好;
- 天然服务端单向推送,完美匹配 AI 逐段返回文本场景;
- 浏览器原生
EventSourceAPI,开箱即用,内置断线自动重连、消息 ID、重试间隔配置; - 轻量,头部开销小,后端实现简单,只需要设置固定响应头持续输出数据流;
- 自带事件、id 机制,支持断点续推,断连恢复不丢失对话内容。
2. SSE 底层核心原理、必备响应头是什么?
SSE 本质:一次 HTTP GET 请求,后端不关闭响应流,持续向 response 输出文本流,浏览器持续解析。 后端必须返回响应头:
javascript
Content-Type: text/event-stream
Cache-Control: no-cache
Connection: keep-alive数据格式固定规范:data: xxx\n\n,单条消息以双换行符结尾。 支持额外字段:
event: 自定义事件名:区分普通文本、结束、报错事件;id: 消息序号:断线重连携带 Last-Event-ID,后端断点续传;retry: 3000:设置断线自动重连毫秒间隔。
3. 你的 AI 对话业务中,后端是如何分片推送文本?
- AI 大模型流式生成 token,后端按字符 / 短句分片;
- 每生成一段文本,封装
data: 片段内容\n\n实时写入响应流; - 全部生成完毕后推送特殊结束标记
event: done; - 异常场景推送
event: error附带错误信息; 全程不关闭 HTTP 连接,持续分片输出。
二、前端实现核心问题(EventSource、打字机渲染)
4. 浏览器 EventSource 基础用法,怎么分段解析实现打字机实时效果?
- 创建 EventSource 实例建立 SSE 通道,监听 message 事件;
- 每次接收
data字段增量文本,追加到对话气泡末尾,不替换原有内容; - 拿到片段立刻更新响应式变量,Vue 自动渲染,视觉上逐字弹出打字机效果;
- 监听自定义 done 事件:标记流式输出完成,关闭加载状态;
- 监听 error 事件:捕获网络、服务端异常,做重连 / 报错提示。
极简示例:
javascript
const source = new EventSource('/api/ai/chat-stream', {
method: 'GET',
headers: { Authorization: token }
})
source.onmessage = (e) => {
const chunk = e.data
// 增量拼接文本,实时渲染
answerText.value += chunk
}
source.addEventListener('done', () => {
source.close() // 输出完毕主动关闭连接
loading.value = false
})5. EventSource 默认仅支持 GET 请求,业务需要携带 token、POST 传提问参数怎么解决?
两种落地方案(项目用方案 1):
- 请求头携带 token:部分浏览器 EventSource 构造函数支持 headers;不兼容则把 token 放在 url 参数里(短期对话安全可接受);
- 后端改造接口:前端 POST 提交对话提问参数到缓存,返回唯一会话 id;再用 EventSource GET 携带会话 id 建立 SSE 长连接,后端根据 id 读取提问并流式返回。
6. 流式渲染如何优化,避免频繁更新 DOM 卡顿?
- 增量拼接字符串,不频繁拆分重组 DOM,仅单次追加文本;
- 对话容器开启
white-space: pre-wrap,后端直接换行无需前端处理; - 大量长文本滚动自动置底使用节流,避免 onmessage 高频触发滚动逻辑;
- 不使用 v-if 频繁销毁重建气泡,用缓存容器持续追加内容;
- 超大文本分段渲染时禁用滚动动画,降低重绘开销。
7. 流式输出中途切换页面、关闭弹窗,如何销毁 SSE 连接,防止内存泄漏?
Vue3 组合式方案:
- 将 EventSource 实例存为 ref 变量;
onUnmounted生命周期执行source.close()主动断开长连接;- 移除所有 message、error、done 事件监听,防止组件销毁后回调执行报错;
- 清空对话文本、loading 状态,中断未完成推送。
三、断线重连、断点续推异常处理(高频深挖)
8. SSE 断网、网关超时断开,如何实现恢复后不丢失对话内容?
依靠 SSE 原生 Last-Event-ID 机制:
- 后端每条推送携带
id: 数字序号,代表当前分片下标; - 浏览器自动记录 id,重连请求头部携带
Last-Event-ID; - 后端读取该 ID,从对应分片继续推送剩余 AI 文本,无需重新生成整段回答;
- 前端缓存已接收完整文本,重连后只拼接后续增量片段,不会重复渲染、文字错乱。
9. 区分几种 SSE 异常,分别怎么处理?
- 临时网络波动(断网):EventSource 内置 retry 自动重连,无需手动封装;搭配 loading 防抖,避免频繁闪烁报错;
- 服务端报错(event: error):关闭连接,弹出提示,停止接收消息;
- 会话过期、token 失效:监听 error 状态码 401,清除登录态跳转登录页;
- AI 生成超时、限流:后端推送特殊错误 data,前端终止流式输出,提示用户重试。
10. 如何控制重连频率,避免短时间大量重试打满后端接口?
- 后端推送
retry: 5000指定 5 秒重试间隔,覆盖浏览器默认策略; - 前端增加最大重连次数(如 5 次),超过次数永久关闭连接,提示用户网络异常;
- 主动关闭的连接(用户切换页面、对话结束)禁止自动重连。
四、工程化封装(Vue3 Hook 封装)
11. 如何封装通用 useSSE AI 流式对话 Hook,多页面复用?
Hook 内部封装完整能力:
- 内部维护 EventSource 实例、对话文本、loading、重连计数;
- 对外暴露方法:
startStream(question)开启流式对话、closeStream()手动关闭; - 抛出回调钩子:onChunk(每段文本回调)、onFinish(输出完成)、onError(异常);
- onUnmounted 自动 close 销毁连接,统一管理清理逻辑;
- 内置 token 处理、断点 id 缓存、重连次数限制,业务页面仅调用一行代码即可实现流式打字对话。
12. 多轮连续对话场景,SSE 如何隔离不同会话流?
- 每一轮对话生成唯一 sessionId,拼接在 SSE 请求 url;
- 同一页面多气泡并行流式输出,多个独立 EventSource 实例隔离消息;
- 每条消息携带分片 id 与 sessionId,防止多轮对话文本互相串位。
五、SSE vs WebSocket 拓展深挖(高级面试官必问)
13. 什么场景不适合 SSE,必须改用 WebSocket?
- 需要前端双向实时发送(聊天室、协同编辑、实时键鼠操作);
- 低版本 IE 完全不支持 EventSource,且无法做兼容垫片;
- 高并发高频双向通信,需要减少 HTTP 头部冗余; AI 单向流式输出属于纯后端推送,SSE 更轻量更合适。
14. SSE 有什么原生局限?
- 标准 EventSource 仅支持 GET 请求;
- 单条浏览器同源 SSE 连接数有限(Chrome 最多 6 个),多标签多对话会排队阻塞;
- 无法传输二进制数据,只能纯文本;
- 依赖 HTTP 长连接,部分运营商网关会 30s~2min 强制切断空闲连接,必须依靠重连补偿。
六、实战踩坑(加分项,体现项目落地经验)
15. 开发过程遇到的典型问题与解决方案
- 坑 1:nginx 缓冲区缓存数据流,前端收不到实时分片,打字卡顿 解决:nginx 配置关闭缓冲
proxy_buffering off;,禁止聚合响应流,后端文本立即推送到前端。 - 坑 2:页面销毁未调用 close,后台持续推送、控制台内存泄漏警告 解决:hook onUnmounted 强制关闭 EventSource,清空监听。
- 坑 3:断连重连重复接收全部文本,内容叠加错乱 解决:使用 Last-Event-ID 断点续推,前端缓存已有文本,只追加新分片。
- 坑 4:token 放在 header 部分浏览器不兼容,鉴权失败 解决:降级方案 token 拼接 URL 参数,或先 POST 传参拿 sessionId。
- 坑 5:大段文本 onmessage 频繁触发,滚动一直抖动 解决:滚动置底逻辑加节流控制执行频率。
- 坑 6:后端忘记双换行 \n\n 分隔消息,前端一次性接收整段无流式效果 解决:规范后端 data 分隔格式,单条消息结尾必须
\n\n。
七、完整业务流程口述(面试梳理方案)
- 用户输入 AI 提问点击发送,前端携带对话参数请求后端;
- 后端缓存提问内容,返回会话标识;
- 前端创建 EventSource 建立 SSE GET 长连接,携带会话 id 与鉴权 token;
- 后端持续生成 AI 文本分片,按 SSE 规范实时写入响应流推送;
- 前端监听 message 事件,增量拼接文本,实时渲染打字机对话气泡;
- 全部内容推送完成,后端下发 done 事件,前端关闭加载状态;
- 断网自动根据 Last-Event-ID 断点续传;页面卸载主动 close 关闭长连接释放资源; 对比轮询方案,无无效请求、毫秒级分片推送,流式交互延迟大幅降低。
18.Promise 并发池(异步流量管控)
一、背景与选型基础题(开场必问)
1. 批量查询地图点位、AI 翻译直接用 Promise.all 有什么致命问题?
答:
Promise.all会一次性同时发起所有请求,批量场景几十条接口瞬间并发,触发后端限流(429 Too Many Requests),大量请求失败;- 浏览器同源连接数有限(Chrome 同域最大 6 条),超出后请求阻塞排队,页面加载变慢;
- 没有失败重试、任务排队机制,某个接口报错直接全部中断批量任务,容错性差;
- 无法动态控制并发流量,多页面同时批量操作会叠加请求,加剧服务端压力。
2. 为什么不用分批循环 + setTimeout 延时,非要手写通用并发池?两种方案对比
- 简单分批(每批 5 个,sleep 后下一批)缺点:
- 固定批次死板,一批全部执行完才走下一批,资源利用率低;
- 封装性差,每个批量业务都要重复写循环延时,无法全局复用;
- 某一批里有请求提前完成,空闲连接不会复用,浪费带宽。
- 并发池优势:
- 动态调度:有空闲槽位立刻执行下一个排队任务,最大化利用并发上限;
- 纯工具化抽离,全项目批量接口统一调用;
- 支持等待全部完成、获取所有结果、单独捕获失败,扩展性强。
3. 业务里哪些场景在用这个并发池?
- 地图批量点位批量详情查询;
- 批量 AI 文本翻译接口调用;
- 设备批量导出前批量拉取详情;
- 批量上传分片也可复用这套调度逻辑。
二、并发池核心原理与手写实现(面试重中之重,大概率让现场写简易版)
4. Promise 并发池底层设计思路是什么?三大核心变量
核心逻辑:固定最大并发槽位,维护任务等待队列,每完成一个任务就从队列取出新任务填充空位。 内部维护 3 个变量:
maxConcurrent:最大并发阈值(如 5);runningCount:当前正在执行的请求数量;taskQueue:等待执行的异步任务队列(存放返回 Promise 的函数)。
完整执行流程:
- 批量传入所有任务函数,循环推入等待队列;
- 触发调度函数:若运行数 < 最大并发,取出队首任务执行;
- 任务执行完毕,
runningCount--,递归再次执行调度,拉取队列剩余任务; - 全部队列清空且无运行任务,resolve 返回所有任务结果。
5. 为什么队列里存「返回 Promise 的函数」,不直接存 Promise 实例?
Promise 创建即立刻执行,若直接存 Promise,所有接口会瞬间全部发起,失去限流意义; 存包装函数:只有调度取出、手动执行函数时,才会发起接口请求,实现延迟调度、排队执行。
6. 并发池如何收集所有任务返回结果?成功 / 失败分别怎么处理?
两种模式对外提供:
- 类似
Promise.all:任意任务报错直接整体 reject,适合强依赖、缺一不可的批量场景; - 类似
Promise.allSettled:收集每一条任务成功 / 失败状态、返回数据,全部执行完统一返回,地图点位、AI 翻译批量场景用此模式,单条失败不阻断整体批量流程。
7. 简易并发池核心代码口述(面试手写精简版)
javascript
class PromisePool {
constructor(max) {
this.max = max
this.running = 0
this.queue = []
this.results = []
}
add(task) {
return new Promise(resolve => {
this.queue.push({ task, resolve })
this.run()
})
}
run() {
if(this.running >= this.max || !this.queue.length) return
this.running++
const { task, resolve } = this.queue.shift()
task().then(res=>{
this.results.push({ status:'fulfilled', data:res })
}).catch(err=>{
this.results.push({ status:'rejected', err })
}).finally(()=>{
this.running--
this.run()
// 队列空且无运行任务,统一返回结果
if(this.running === 0 && !this.queue.length) resolve(this.results)
})
}
}
// 使用
const pool = new PromisePool(5)
tasks.forEach(fn => pool.add(fn))三、业务落地、工程化封装问题
8. 如何封装成全局通用工具,项目任意页面批量接口直接复用?
- 单独抽离
src/utils/promisePool.js工具类,无 Vue 依赖,JS / 组件均可调用; - 封装快捷函数
batchRequest(tasks, maxConcurrent),内部实例化并发池; - 统一参数:任务数组、最大并发数、是否中断整体(all/allSettled 模式);
- 地图、AI 翻译页面直接导入调用,无需重复实现调度逻辑。
9. 批量地图点位请求,如何配置合理的 maxConcurrent?依据是什么?
常规配置 5~8:
- 低于浏览器同源 6 连接上限,不会造成浏览器请求排队;
- 兼顾速度,同时不会瞬间压满后端接口触发限流; 可根据后端限流阈值动态调整,封装支持动态传入并发数。
10. 并发池搭配请求拦截器,双重防护限流怎么做?
两层限流保障:
- 上层并发池:前端控制同时活跃请求数量,从源头减少并发;
- axios 响应拦截捕获 429 限流报错,给用户提示 "操作过快,请稍后重试"; 双重机制彻底杜绝大批量接口同时触发限流。
四、边界场景、异常处理高频提问
11. 批量任务中有接口 429 限流失败,并发池怎么处理?能否加自动重试?
扩展并发池支持单任务重试策略:
- 单个任务捕获 429 错误,达到重试次数前重新推入队列尾部等待执行;
- 重试耗尽标记该任务失败,不阻塞其他点位 / 翻译任务;
- 指数退避间隔重试,避免短时间重复轰炸接口。
12. 用户中途切换页面、关闭弹窗,正在排队 / 运行的批量任务如何取消?
给并发池增加终止方法 clear():
- 清空等待任务队列,不再调度新请求;
- 配合 axios AbortController,存储所有请求控制器,终止正在运行的接口;
- Vue 页面 onUnmounted 调用终止方法,防止页面销毁后请求回调修改已卸载组件数据,消除内存泄漏。
13. 多个页面同时使用并发池,会互相干扰流量管控吗?
不会: 每个页面调用都会新建独立 PromisePool 实例,running 计数、任务队列完全隔离; 如果需要全局总流量管控(限制整个项目所有页面总并发),可封装单例全局并发池统一调度。
14. 任务队列堆积大量任务,会不会造成内存占用过高?
- 批量执行完成后自动清空队列、结果数组;
- 页面卸载强制清空队列、中断请求,释放引用;
- 超大批量(上千点位)拆分分片送入并发池,避免一次性存入超长队列。
五、性能优化与拓展进阶问题(3 年 + 深度提问)
15. 并发池相比第三方异步库(p-limit),自己手写的优势是什么?
- 轻量化,无第三方依赖,减少打包体积;
- 业务定制扩展:内置限流重试、任务取消、allSettled 结果收集,贴合地图 / AI 翻译业务;
- 可控可改造,可灵活增加埋点、日志、全局流量监控;
- 方便面试讲解原理,完全掌握底层调度逻辑。
16. 如何实现动态调整并发上限?比如后端返回负载高时自动降低并发数
- 接口响应头携带服务端负载 / 限流提示;
- 并发池监听响应,检测到限流自动临时下调 maxConcurrent;
- 等待批量任务执行完毕后恢复默认并发阈值。
17. 并发池能和之前的 AbortController、SSE、WebWorker 方案结合使用吗?怎么结合?
完全可以组合使用:
- 批量 AI 翻译:并发池控制同时翻译请求数量,每个任务绑定 AbortController,页面销毁批量中断;
- 批量地图点位返回数万数据:并发池管控请求,拿到结果后丢入 WebWorker 做点位筛选、统计,不阻塞主线程。
六、实战踩坑(加分项,体现真实项目经验)
18. 开发并发池踩过哪些坑,如何解决?
- 坑 1:队列直接存 Promise,所有请求一次性并发,限流失效 解决:统一改为存放懒执行函数,调度时再调用发起请求;
- 坑 2:running 计数逻辑错误,并发数超限无限制,依然触发 429 解决:执行前 running++,finally 中 running--,严格计数;
- 坑 3:某个任务报错直接终止整个批量,点位数据全部丢失 解决:默认 allSettled 模式,单独记录每条任务成功失败;
- 坑 4:页面销毁未清空队列,后台持续执行请求,控制台内存泄漏 解决:增加 clear 终止方法,组件卸载调用中断请求、清空队列;
- 坑 5:递归 run 函数造成调用栈溢出(上万超长队列) 解决:用 setTimeout 异步执行 run,拆解递归调用栈。
七、完整业务流程口述(面试总结必背)
- 批量操作(地图点位 / AI 翻译)生成一批异步请求函数;
- 传入自定义 Promise 并发池,设置最大并发阈值控制流量;
- 内部维护运行计数器与等待队列,空闲槽位自动调度排队任务;
- 同一时间仅允许指定数量接口并行,其余排队等候;
- 所有任务执行完毕统一返回每条请求的成功 / 失败结果;
- 配合 axios 拦截捕获限流异常,支持页面卸载一键取消全部任务; 效果:不再一次性爆发数十并发请求,彻底解决后端 429 限流报错。
19.多模态交互全链路 AI 前端业务
一、项目整体 & 业务背景类(开场必问)
1. 什么是多模态交互?你这套系统包含哪几种模态,各自作用?
答: 多模态指文本、图像、音频多种媒介协同和 AI 交互,我独立实现四条核心链路:
- 图像模态:上传图片调用 AI 识别接口,完成文字提取、内容识别、场景标签生成;
- 音频模态:麦克风录音 + 浏览器 Web Speech / 流式 SSE 语音转文字,语音输入转 AI 提问文本;
- 文本模态:多语种互译、大模型流式对话、历史对话管理;
- 数据可视化模态:统计每次对话输入 / 输出 Token,折线、柱状图展示消耗趋势。 整体一套页面同时支持文字、语音、图片三种方式和 AI 对话,适配 PC、平板、移动端。
2. 为什么要把图片、语音、翻译、对话、统计整合一套全链路,分开做有什么问题?
- 重复鉴权、重复封装请求、重复 SSE / 上传逻辑,代码冗余;
- Token 消耗、对话记录分散存储,无法统一统计;
- 语音、图片识别结果无法直接联动翻译、AI 问答,交互割裂;
- 多端适配逻辑分散,统一封装一套自适应交互组件降低维护成本;
- 统一全局状态管理多模态临时缓存、上传队列、录音状态,避免多组件状态冲突。
3. 你独立完成全套逻辑,整体架构怎么分层解耦?
四层分层,模态能力完全解耦,可单独复用:
- 底层工具层:语音录制工具、图片 Blob 切割上传、MD5 文件校验、多语种翻译请求、Token 计算工具、SSE 流式工具;
- 公共 Hook 层
- useAudioRec:录音、暂停、停止、语音转文字;
- useImageAI:图片压缩、AI 识别、结果解析;
- useTranslate:多语种互译并发管控;
- useChatStream:SSE 流式对话;
- useTokenStat:Token 计算、本地持久化统计;
- 状态管理层(Pinia) 统一存储对话列表、临时图片识别结果、录音文本、全局语种、累计 Token 消耗;
- 视图层 多模态输入组合组件、对话气泡、Token 可视化图表、移动端自适应布局。
二、图像模态:AI 图片识别相关问题
4. 前端上传图片给 AI 识别做了哪些前置优化?
- 图片压缩:canvas 等比例压缩大尺寸原图,降低上传体积,减少接口耗时;
- 格式统一:webp/jpg 统一转换,过滤透明大图;
- 分片上传:大图走之前封装的 Blob 分片逻辑,支持断点续传;
- 图片校验:大小、格式、宽高校验,提前拦截无效图片;
- MD5 文件指纹:重复图片直接读取缓存识别结果,减少重复请求;
- 并发管控:多张图片批量识别使用 Promise 并发池,限制并行数量,防止 429 限流。
5. AI 图片识别返回结果如何联动其他模态功能?
- 识别出的文字一键填充到对话输入框;
- 选中文字直接调用多语种翻译;
- 图片 + 提取文本组合作为上下文发给大模型进行图文问答;
- 识别内容计入输入 Token,实时更新消耗统计图表。
三、音频模态:语音转文字核心问题
6. 前端语音转文字两种实现方案,项目用哪套,优缺点?
- 浏览器原生 Web Speech API 优点:不用后端,本地实时转写;缺点:兼容性差、语种少、无离线能力,移动端部分浏览器禁用;
- 前端录音上传二进制流 + 后端流式语音识别(SSE)(项目主方案) 流程:MediaRecorder 录制音频 Blob → 分片流式上传后端 → 后端实时转文字 SSE 分段推送; 优势:全浏览器兼容、支持多语种、长语音分段实时出字,搭配打字机流式效果。
7. 录音过程中需要处理哪些边界问题?
- 麦克风权限拦截:无权限弹窗引导授权;
- 静音检测:纯静音自动停止录音,提示无有效语音;
- 长音频分片上传,避免单次文件过大;
- 切换页面销毁录音实例,释放麦克风;
- 录音中断、网络断开自动缓存音频片段,支持重传;
- 录音状态全局统一管理:录制 / 暂停 / 转写中 / 完成,多组件不冲突。
8. 语音转文字结果如何联动翻译、AI 对话?
语音实时转写文本实时展示;转写完成可一键翻译、直接发送给大模型,语音输入完全替代手动打字。
四、多语种翻译模块面试题
9. 批量多语种翻译如何控制并发防止限流?
复用通用 Promise 并发池:批量文本翻译设置最大并发阈值,排队执行;捕获 429 限流错误支持单条重试,指数退避间隔。
10. 翻译如何和图文、语音模态打通?
- 手动输入文本、图片识别文字、语音转文字,任意内容均可一键翻译;
- AI 模型返回的回答支持一键切换目标语种;
- 记忆用户常用翻译语种,全局状态持久化缓存。
五、对话记录存储 & 上下文链路问题
11. 对话记录存在哪里?本地持久化方案怎么设计?
- 短期会话内存:Pinia 存储当前会话对话,快速渲染;
- 长期本地持久化:IndexedDB 存储完整历史对话、附带图片、语音文本、翻译记录;
- 每条对话携带唯一会话 ID、模态类型(文本 / 语音 / 图片)、时间、Token 消耗;
- 支持分页加载历史对话、按关键词检索、批量删除、清空记录;
- 登出 / 切换账号自动清空当前用户本地对话缓存,数据隔离。
12. 多模态上下文如何拼接传给大模型?
统一封装上下文组装工具: 自动区分输入类型:纯文本、图片 OCR 文本、语音转写文本、翻译结果,格式化统一 Prompt 结构,附带历史对话上下文,控制上下文长度避免 Token 超限,过长自动裁剪早期历史消息。
六、Token 消耗可视化统计(简历亮点高频深挖)
13. 前端如何精准计算输入、输出 Token?
两种方案结合:
- 前端轻量化分词工具粗算,实时展示实时消耗(可视化图表实时更新);
- AI 流式接口返回每条消息真实 token 数量(prompt_tokens/completion_tokens),用于精准统计; 两者结合:实时粗算展示,接口返回后修正真实数值。
14. Token 可视化做了哪些图表,如何适配多端?
- 指标卡片:当日总消耗、图片 / 语音 / 文本各模态占比;
- 折线图:近 7 天每日 Token 消耗趋势;
- 饼图:多模态消耗占比分布; 适配方案:使用自适应图表组件,屏幕宽度自动切换图表尺寸、隐藏冗余图例,移动端简化展示。
15. Token 数据持久化逻辑?
IndexedDB 按用户维度存储每日消耗记录,页面初始化读取历史数据渲染图表;支持清除统计数据、导出消耗记录。
七、SSE 流式对话全链路联动
16. 多模态输入(图 / 语音 / 文字)统一走 SSE 流式输出,如何统一封装?
统一封装 useChatStream Hook,接收统一入参结构: {type: 'text/audio/image', content: '', translateLang?: ''} 内部统一拼接 prompt、建立 SSE 长连接、增量渲染打字机效果、实时统计 token、自动保存对话记录;输入来源不影响底层流式逻辑,实现一套代码承载三类模态提问。
八、多端自适应交互相关问题
17. PC、平板、移动端分别做了哪些适配差异处理?
- 布局:PC 左右分栏(输入区 + 对话列表);移动端上下堆叠,底部固定输入框;
- 输入交互:PC 支持快捷键发送、粘贴图片;移动端优先语音输入,隐藏复杂侧边统计;
- 性能适配:移动端限制并发池最大请求数、压缩图片倍率更高;
- 组件兼容:移动端录音适配移动端浏览器 MediaRecorder 兼容问题;
- 图表自适应:小屏简化可视化,折叠统计面板。
18. 如何实现一套组件多端复用,不用写两套页面?
- CSS 媒体查询 + 动态类名控制布局;
- useMediaQuery Hook 监听屏幕宽度,区分 pc/tablet/mobile 三种设备标识;
- 模态输入组件、对话气泡、图表全部做自适应兼容,根据设备标识切换交互逻辑;
- 冗余复杂功能移动端按需懒加载,减少移动端首屏资源体积。
九、工程化、异常、性能综合问题
19. 整套多模态系统做了哪些性能优化?
- 图片压缩、分片上传、MD5 缓存识别结果;
- 批量翻译、批量识图使用 Promise 并发池限流;
- 数万条历史对话使用虚拟列表渲染,滚动无卡顿;
- WebWorker 单独计算 Token、批量解析历史对话,不阻塞主线程;
- SSE 长连接自动销毁、录音 MediaRecorder 页面卸载释放资源;
- IndexedDB 异步存储对话,不占用主线程;
- 多模态组件按需懒加载,首屏加快。
20. 全链路统一异常处理体系是怎么设计的?
分模态统一捕获异常并友好提示:
- 图片模态:格式错误、上传失败、AI 识别超时、限流 429;
- 语音模态:麦克风无权限、录制失败、转写接口报错;
- 翻译 / 对话:token 过期、模型限流、上下文过长报错; 统一错误拦截:axios 拦截 + SSE error 监听 + 录音 / 图片工具内部错误捕获; 区分静默失败(自动重试)和用户提示类错误,不阻塞整体交互。
21. 组件卸载时全链路资源清理需要做哪些操作?
- SSE 调用 close 关闭长连接;
- 终止 MediaRecorder 录音,释放麦克风;
- 并发池清空排队任务、AbortController 中断所有上传 / 翻译请求;
- WebWorker terminate 销毁线程;
- 清除临时图片 Blob 缓存、内存对话临时数据; 避免内存泄漏、后台持续请求、麦克风常驻占用。
十、实战踩坑加分题
22. 开发多模态全链路踩过哪些典型问题,怎么解决?
- 坑 1:语音、图片、翻译同时并发大量请求触发限流 解决:统一使用 Promise 并发池管控并行数量;
- 坑 2:移动端录音 MediaRecorder 兼容性差,部分浏览器无音频流 解决:降级为上传文件后端转写,兼容兜底;
- 坑 3:大量历史对话页面滚动卡顿 解决:虚拟列表渲染对话记录;
- 坑 4:多模态输入上下文拼接过长,模型报错超限 解决:前端工具自动裁剪早期历史消息,控制上下文长度;
- 坑 5:切换页面麦克风不释放,手机录音一直占用 解决:onUnmounted 强制停止录制销毁实例;
- 坑 6:Token 前端粗算和后端真实数值偏差大,图表数据不准 解决:接口返回真实 token 覆盖前端估算值,保证统计图表准确。
十一、进阶拓展深挖(3 年 + 高级提问)
23. 如果后续增加视频多模态识别,现有架构需要改动哪里?
现有分层架构完全可扩展,改动极小:
- 底层工具新增视频录制、视频分片上传、帧截图工具;
- 新增 useVideoAI Hook 处理视频识别;
- 状态层新增 video 模态类型;
- 对话组装、Token 统计、历史存储逻辑无需大幅改动,模态类型做分支判断即可。
24. 本地 IndexedDB 存储大量对话会不会出现页面加载缓慢?
不会:
- 历史对话采用分页懒加载,不一次性读取全部记录;
- 查询对话、统计 Token 消耗放入 WebWorker 异步计算;
- 提供删除、归档功能,避免存储数据无限膨胀。
25. 多用户切换场景,多模态数据如何隔离不串数据?
IndexedDB 存储增加 userId 主键;Pinia 状态切换用户时清空当前会话、销毁所有长连接、停止录音、清空临时缓存,读取对应用户历史记录。
十二、完整业务流程口述(面试总结)
用户可通过文字、录音语音、上传图片三种模态输入;
- 图片自动压缩分片 AI 识别,语音录制流式转文字;
- 识别 / 转写文本支持一键多语种翻译,并发池管控批量翻译流量;
- 统一组装多模态上下文,通过 SSE 建立长连接实现 AI 流式对话打字机效果;
- 实时计算 Token 消耗,存入 IndexedDB 持久化;
- 读取历史消耗数据渲染可视化图表,展示各模态使用占比;
- 所有对话记录本地持久存储,虚拟列表渲染历史会话;
- 整套组件适配 PC / 平板 / 移动端自适应布局; 配套完整资源销毁、异常捕获、并发限流、主线程优化方案,独立完成整套前端逻辑开发。
20.React 作业列表精准渲染优化(memo + useMemo + useCallback)
- 父组件轮询接口更新
list状态,父组件自身触发重渲染; - 子组件未做缓存时,父一更新全部重渲染;即便用了
memo,函数、对象引用每次变化,浅对比判定 props 改变,依然全部重渲染; - 列表几十上百条 Item,每条内部有格式化、标签、按钮,大量重复渲染阻塞主线程,滚动帧率下跌。
- 父渲染时,每行行内会生成全新函数 / 对象:
javascript
{list.map(item => (
<ListItem
key={item.id}
item={item}
// 每次父渲染都是新函数引用
onEdit={() => handleEdit(item)}
// 每次生成新对象
statusInfo={formatStatus(item)}
/>
))}2. 什么叫「粗粒度渲染」?你说的「精准细粒度优化」核心思路是什么?
- 粗粒度:父状态一变,整个列表所有行统一渲染,不区分哪些行数据真正变更;
- 细粒度优化目标:只重渲染数据发生变化的 Item,不变 Item 完全跳过渲染;
- 实现三板斧组合:
memo:子组件做 props 浅层对比;useCallback:稳定事件函数引用,不每次生成新函数;useMemo:缓存派生计算值、派生对象 / 数组,固定引用地址。
3. 只给子组件包 memo,不配合 useCallback /useMemo 能优化吗?为什么?
不能,几乎无优化效果。 memo 仅对比 props 的引用地址:
- 父每次渲染,行内箭头函数、格式化后的对象都是全新引用;
- 哪怕 item 数据完全没变,props 引用变了,memo 依旧判定组件需要重渲染; 必须搭配 useCallback、useMemo 稳定 props 引用,memo 才能拦截无效渲染。
二、三大 API 核心原理深挖(面试重点,常现场写代码)
4. useCallback 作用、项目中缓存哪些回调,依赖数组注意事项
- 作用:缓存函数实例,依赖不变时函数引用永远不变,传给子组件不会触发重渲染;
- 列表中缓存的回调:编辑、删除、查看详情、批量勾选、状态变更、分页切换;
- 依赖坑点:
- 所有函数内部使用的 state、props、外部变量必须写进依赖数组,否则闭包捕获旧值;
- 依赖频繁变化时,useCallback 会失效(每次生成新函数);
- 示例:
javascript
const handleEdit = useCallback((id) => {
setCurrentId(id)
}, [])5.useMemo 在作业列表两种核心使用场景,分别解决什么问题
场景 1:缓存复杂派生计算 每条作业需要计算逾期状态、进度百分比、格式化时间、状态标签文本,循环大量同步计算占用主线程;用 useMemo 缓存结果,仅 item 变更才重新计算。
场景 2:缓存数组 / 对象引用
- 缓存经过筛选、格式化后的完整列表数组,避免父渲染生成全新数组;
- 缓存单行传递给子组件的派生对象,固定引用地址,配合 memo 减少渲染。
6. memo、useCallback、useMemo 三者完整协作流程,口述一遍
- 列表 Item 子组件用
memo(ListItem)包裹,开启 props 浅对比; - 父组件所有行点击事件用
useCallback缓存,函数引用永久稳定; - 每一行派生数据(状态、进度、格式化信息)用
useMemo缓存,对象引用不变; - 父轮询刷新:未变更行的 item、事件、派生对象引用全部不变;
- memo 对比 props 无变化,直接跳过该 Item 的 render、不生成 DOM;
- 只有数据真正变更的行,才会重新计算、重新渲染,实现精准局部刷新。
7. useMemo、useCallback 有性能开销,什么场景不建议滥用?
- 简单基础运算(三元判断、简单字符串拼接):缓存开销 > 计算开销;
- 组件数据极少更新、列表只有十几条以内:优化收益极低,徒增依赖维护成本;
- 依赖频繁变动的场景:每次都会重新生成缓存值,完全失去缓存意义。
三、业务落地 & 代码规范问题
8. map 循环内部不能直接写 useMemo /useCallback,你怎么处理单行数据缓存?
Hook 不能写在循环、条件内部,两种方案:
- 抽离单行逻辑到自定义 Hook,封装
useWorkItemInfo(item),内部使用 useMemo; - 将单行格式化、计算逻辑下沉到 Item 子组件内部,在子组件中使用 useMemo 缓存自身计算; 推荐方案 2:业务分离,父组件只传原始 item,派生计算下沉子组件,父逻辑更简洁。
9. 列表轮询高频更新,如何减少父组件无意义重渲染?
配套优化:
- 接口返回数据做浅对比,数据完全一致时不 setState,不触发父重渲染;
- 分页、筛选、搜索状态拆分,避免一处更新带动全列表刷新;
- 列表数据用 useMemo 缓存加工后的数组,避免衍生状态频繁变化。
10. memo 只是浅对比,如果 props 是深层嵌套对象怎么办?
两种方案:
- 规范传参:拆分 props,把深层对象拆成独立基础类型参数(id、status、progress);
- 自定义 memo 对比函数,第二层做浅层对比:
javascript
memo(ListItem, (prev, next) => {
return prev.item.id === next.item.id && prev.item.status === next.item.status
})缺点:自定义对比函数会增加渲染耗时,优先拆分简单类型 props。
四、性能指标、FPS 优化相关问题
11. FPS 从 55 提升到 70+,这个数据怎么观测、优化前后区别是什么?
观测工具:Chrome Performance、FPS Meter、Rendering 面板;
- 优化前:轮询刷新时大量红色长任务,海量子组件执行 render、虚拟 DOM 对比、重绘,主线程阻塞,滚动稳定 50~55 帧,快速滑动明显卡顿;
- 优化后:90% 不变 Item 跳过渲染,render、diff 耗时大幅下降,无长时间阻塞任务,滚动稳定 70 帧以上,滑动顺滑无掉帧;
- 辅助指标:DOM 重绘次数减少 60%+,主线程长任务几乎消失。
12. 除了三件套缓存,还搭配了哪些列表渲染辅助优化?
- 列表 Item 稳定 key(用唯一业务 id,不用数组下标),减少 diff 开销;
- 滚动容器开启
will-change: transform,GPU 加速; - 复杂超长作业列表叠加虚拟列表,只渲染可视区域 DOM;
- 滚动事件加节流,避免滚动时频繁执行计算;
- 子组件内部复杂计算全部使用 useMemo 缓存;
- 图片懒加载,滚动区域外不加载图片资源。
五、边界场景、踩坑实战(加分高频提问)
13. 开发时踩过哪些缓存失效的坑,如何解决?
坑 1:useCallback 依赖数组缺失,闭包捕获旧变量,点击事件数据错乱 解决:用 eslint-plugin-react-hooks 自动校验依赖,补齐依赖项;
坑 2:行内直接生成对象传递给子组件,useMemo 写在循环外无法缓存单行数据 解决:计算逻辑下沉子组件内部缓存,不把派生对象放在父 map 里;
坑 3:memo 配合复杂嵌套对象 props,浅对比失效,子组件依旧重复渲染 解决:拆分 props 为基础类型,或自定义对比函数;
坑 4:滥用 useMemo 包裹简单计算,代码冗余且无性能提升 解决:仅对循环大量复杂计算、高频刷新场景使用缓存;
坑 5:轮询接口每次返回全新数组引用,父无差别重渲染所有 Item 解决:对比新旧列表,无变更时不更新 state,阻断父渲染触发。
14. 分页切换、筛选搜索时,缓存会不会失效?怎么保证性能?
分页 / 筛选会生成全新列表数据,此时本就需要全部重新渲染,缓存不会造成负面影响; 优化:筛选逻辑用 useMemo 缓存筛选后的列表,避免每次渲染重复过滤数组。
六、进阶深挖(3 年 + 高级面试)
15. React 18 自动批处理更新,对你这个列表优化有影响吗?
无负面影响,反而收益更高:
- 轮询、批量操作多个 setState 会自动批处理,只触发一次父重渲染;
- 并发渲染模式下,无效子组件渲染会占用可中断的渲染时间,缓存减少渲染任务,降低并发阻塞风险。
16. useMemo 能缓存 JSX 节点吗?什么场景适合?
可以缓存整行 JSX,减少虚拟 DOM 创建开销:
javascript
const renderItem = useMemo(() => (
<ListItem item={item} onEdit={handleEdit} />
), [item, handleEdit])适合列表单行结构复杂、高频刷新场景;缺点:代码可读性下降,优先下沉子组件缓存。
17. React.memo、useMemo、useCallback 底层原理简单说下?
- memo:组件记忆化,缓存上一次 vdom props,渲染前对比,相同则跳过 render;
- useCallback:内部维护缓存链表,根据依赖数组生成 key,key 不变复用函数;
- useMemo:和 useCallback 底层同一套缓存机制,区别是缓存函数返回值而非函数本身。
七、完整优化流程口述(面试总结背诵)
- 问题:作业列表轮询高频刷新,父组件重渲染生成全新函数、对象 props,所有 ListItem 全部执行渲染,主线程阻塞,滚动 FPS 偏低;
- 优化方案:
- 子组件使用
React.memo开启 props 浅对比; - 所有列表操作事件通过
useCallback缓存,稳定函数引用; - 作业状态、进度、格式化等复杂派生计算用
useMemo缓存; - 过滤、加工后的列表数组用 useMemo 缓存,减少重复遍历;
- 子组件使用
- 效果:仅数据变更的作业行重新渲染,绝大多数不变组件跳过 render 与 diff;主线程阻塞大幅减少,滚动 FPS 由 55 提升至 70+,海量列表滑动流畅。
21.纯前端离线 Excel 解析(SheetJS/xlsx)
一、业务背景 & 选型基础题(开场必问)
1. 为什么选择前端离线解析 Excel,不交给后端统一解析?各自优缺点
后端解析方案缺点
- 大 Excel 文件上传占用带宽,批量上万条数据接收、解析、校验占用服务器 CPU / 内存,易 OOM;
- 校验失败后需要整份文件重传,用户体验差,反复消耗流量;
- 并发批量导入场景,大量文件同时解析会压垮接口,频繁触发限流。
前端离线解析优势
- 浏览器本地解析,零文件上传,不占用带宽;
- 提前在校本地完成格式、字段、业务规则校验,不合格直接提示,无需等待接口响应;
- 后端只接收校验通过的干净 JSON 数组,省去解析、过滤、校验耗时,服务器压力大幅降低;
- 实时预览表格数据,用户可直接修改错误行再提交,交互更友好。
2. 项目为什么选用 sheetjs (xlsx),不用其他 Excel 库?
- 兼容性最强:支持 .xlsx/.xls/.csv,纯浏览器运行,无依赖;
- 体积轻量,提供多种构建版本(完整版 / 仅解析版),可按需引入减小打包体积;
- API 完善:读取二进制文件、行列遍历、单元格类型识别、自定义表头映射;
- 支持大数据分片读取,适配上万条学生信息表格;
- 社区成熟,无付费授权限制,后台管理系统导入通用方案。
3. 整体业务流程是什么(学生 Excel 导入完整链路)
- input 上传文件,获取 File 二进制对象;
- 使用 FileReader 读取文件为 ArrayBuffer;
- XLSX.read () 离线解析二进制,得到工作簿 workbook;
- 提取第一个工作表 sheet,转换为 JSON 数组;
- 自定义规则批量校验每一行学生数据(学号、手机号、身份证、空值、重复学号等);
- 区分成功行、错误行,展示错误位置 + 错误提示;
- 用户修正或剔除错误数据后,将干净数组传给后端保存; 全程解析、校验都在浏览器完成,仅最终合法数据请求接口。
二、XLSX 库底层核心实现问题(高频深挖)
4. 浏览器如何读取本地 Excel 二进制?FileReader 两种读取方式区别
readAsArrayBuffer(项目使用):读取为二进制缓冲区,适合 XLSX 解析,性能好,支持大文件;readAsBinaryString:旧方案,存在编码兼容问题,大数据易卡顿,废弃不用。 流程:File → FileReader → ArrayBuffer → XLSX.read (buffer)。
5. sheet_to_json 转换参数怎么配置?关键配置项作用
javascript
const jsonData = XLSX.utils.sheet_to_json(sheet, {
header: 1, // 1=数组格式(无自动映射表头),null=自动用第一行作为key
defval: "", // 空单元格默认填充空字符串,避免undefined报错
raw: false, // false:格式化日期/数字;true:返回原始单元格存储值
})业务场景使用 header: null,自动将 Excel 第一行表头作为对象 key,如 {学号:"2026001",姓名:"张三"},方便字段映射校验。
6. 上万条学生 Excel 一次性解析会不会阻塞主线程?如何优化?
原生 XLSX 同步读取大文件会阻塞 JS 主线程,页面卡死,两种优化方案结合使用:
- WebWorker 离线解析:把 ArrayBuffer 传入 worker,子线程完成 Excel 解析,完全不阻塞页面滚动、点击;
- 数据分片校验:解析完成后,分批次循环校验学生数据,搭配 requestIdleCallback,避免一次性循环上万条造成卡顿; 项目中文件解析放入 Worker,主线程只做渲染和提示。
7. 如何区分单元格数据类型(数字、日期、空单元格、文本)?
- 开启 raw: true 读取原始 cell 对象,识别 cell.t 类型:
s:字符串文本n:数字(学号、手机号会被自动转数字,产生丢失前导 0 坑)d:日期b:布尔值
- 业务坑点:Excel 里纯数字学号会自动识别为数字,开头 0 丢失,解决方案: 读取时配置单元格格式为文本,或读取后统一转字符串补全前导零。
三、自定义学生数据校验规则核心问题(简历重点)
8. 自定义了哪些学生信息校验规则?如何设计可配置校验规则
内置校验规则
- 非空校验:学号、姓名、班级、手机号必填;
- 格式正则:手机号、身份证、学号固定位数正则;
- 范围校验:年龄、年级数字区间;
- 唯一性校验:全表学号不可重复;
- 业务联动校验:入学日期不能晚于当前日期;
- 表头校验:必须包含指定表头(学号 / 姓名 / 班级),缺少直接拦截。
可配置规则引擎设计
抽离校验规则 JSON 配置,一行对应一个字段:
javascript
const rules = [
{ field: "studentId", label: "学号", required: true, pattern: /^\d{8}$/, unique: true },
{ field: "phone", label: "手机号", required: true, pattern: /^1[3-9]\d{9}$/ }
]通用校验工具循环遍历规则,批量校验每行数据,新增字段只需新增配置,不用改循环逻辑。
9. 校验后如何标记错误,展示给用户定位 Excel 问题?
每条错误存储信息:行号、字段名、错误提示; 页面渲染两栏:
- 校验通过列表:预览可直接提交;
- 错误数据列表:标红行号、错误字段提示,支持删除错误行、手动修改单元格内容; 行号和 Excel 实际行数对应(表头为第 1 行,数据从第 2 行开始),用户可快速打开原 Excel 修正。
10. 全表学号唯一性怎么校验,上万条数据性能如何?
- 解析完成后用 Map 存储已出现学号,循环每行判断是否重复;
- 上万条数据放入 WebWorker 执行去重校验,不阻塞主线程;
- 重复学号记录对应两行行号,统一展示重复提示。
四、工程化封装、大文件兼容问题
11. 如何封装通用 Excel 导入工具,多页面复用(学生 / 教师 / 批量设备通用)
抽离独立工具模块 src/utils/excelImport.js,对外暴露统一方法:
parseExcel(file, rules):接收文件 + 自定义校验规则,返回 {successList, errorList};- 内部封装 FileReader、Worker 解析、行列转换、通用校验逻辑;
- 管理系统所有导入页面直接引入,只传入对应校验规则,无需重复写解析代码。
12. 超大 Excel(5 万 + 学生数据)前端解析内存溢出怎么处理?
优化手段:
- WebWorker 解析,主线程不持有二进制大对象;
- 解析完成后分块存储,不一次性渲染全部表格;
- 不用一次性存储全量错误信息,滚动虚拟列表渲染预览数据;
- 解析完成及时销毁 ArrayBuffer、FileReader 实例释放内存。
13. 如何兼容不同 Excel 模板(表头顺序不一致、多余无关列)
- 基于表头字段名映射,不依赖列下标;
- 自动过滤 Excel 多余无关列,只保留配置规则中存在的字段;
- 缺失必填表头直接抛出错误,提示用户使用标准导入模板;
- 提供标准模板下载功能,统一用户上传文件格式。
五、边界坑点与异常处理(面试高频加分)
14. 开发中踩过哪些 Excel 解析经典坑,怎么解决?
-
坑 1:学号、工号纯数字,Excel 自动去除开头 0 解决:读取单元格原始文本,强制转为字符串,不足 8 位前置补零;
-
坑 2:日期读取为数字序列号(Excel 日期底层是数字) 解决:封装日期转换工具,识别 cell.t === 'd',转换为 YYYY-MM-DD 标准格式;
-
坑 3:大文件同步解析页面卡死 解决:解析逻辑移入 WebWorker 异步处理;
-
坑 4:空单元格读取为 undefined,校验报错 解决:sheet_to_json 配置 defval:"",统一为空字符串;
-
坑 5:xls 旧格式文件解析乱码 / 失败 解决:xlsx 库完整版本兼容 xls,统一读取二进制不分后缀;
-
坑 6:用户上传后缀伪装的非 Excel 文件 解决:双重校验:文件后缀 + 文件二进制魔数校验,拦截篡改后缀文件。
15. 文件读取、解析、校验三层异常分别怎么捕获?
- FileReader 读取异常:文件损坏、文件过大,提示文件损坏;
- XLSX 解析异常:非表格文件、加密 Excel,弹窗提示不支持加密文件;
- 业务校验异常:收集行错误,不阻断整体流程,区分可修复数据。
16. 加密 / 带密码 Excel 前端能解析吗?
SheetJS 标准版无法解析加密 xlsx,两种处理方案:
- 前端直接拦截,提示用户去除文件密码后重新上传;
- 加密文件走传统后端解析方案作为兜底降级。
六、前后端协同 & 性能拓展问题
17. 前端校验完成后传给后端的数据结构是什么?后端收益在哪?
前端输出纯净数组,字段统一格式化(学号字符串、标准日期、无空 undefined); 后端收益:
- 无需引入 Excel 解析依赖,不用处理二进制文件;
- 省去表头匹配、格式校验、去重逻辑,只做数据库批量新增;
- 接口请求体体积远小于原 Excel 文件,传输更快;
- 避免批量解析占用服务器内存,并发导入压力大幅下降。
18. 如果要求支持后端兜底解析,如何设计降级方案?
双层导入策略:
- 优先前端离线解析校验;
- 浏览器不支持 FileReader、文件加密、超大文件时,切换传统上传接口,由后端解析; 一套组件同时兼容两种模式,自动判断降级。
19. 除了导入,xlsx 库能否前端导出 Excel?和导入怎么复用工具
可以,XLSX.utils.json_to_sheet 反向将 JSON 数组生成工作表,导出 Blob 下载; 工具模块统一封装 importExcel /exportExcel 两个方法,共用表头映射、字段格式化逻辑,复用校验 / 转换工具函数。
七、完整业务流程口述(面试背诵总结)
用户上传学生信息 Excel 文件,前端通过 FileReader 读取二进制 ArrayBuffer,使用 WebWorker 离线调用 xlsx 库解析工作表;将表格转为标准 JSON 数组,通过可配置校验规则批量校验学号、手机号、空值、重复学号等业务规则;区分错误行与合法数据,页面展示错误位置供用户修改;校验无误后仅将干净 JSON 数组提交后端,全程解析、校验不依赖服务端,减少文件传输与服务器批量解析压力。