HAVING子句
1、寻找缺失的编号
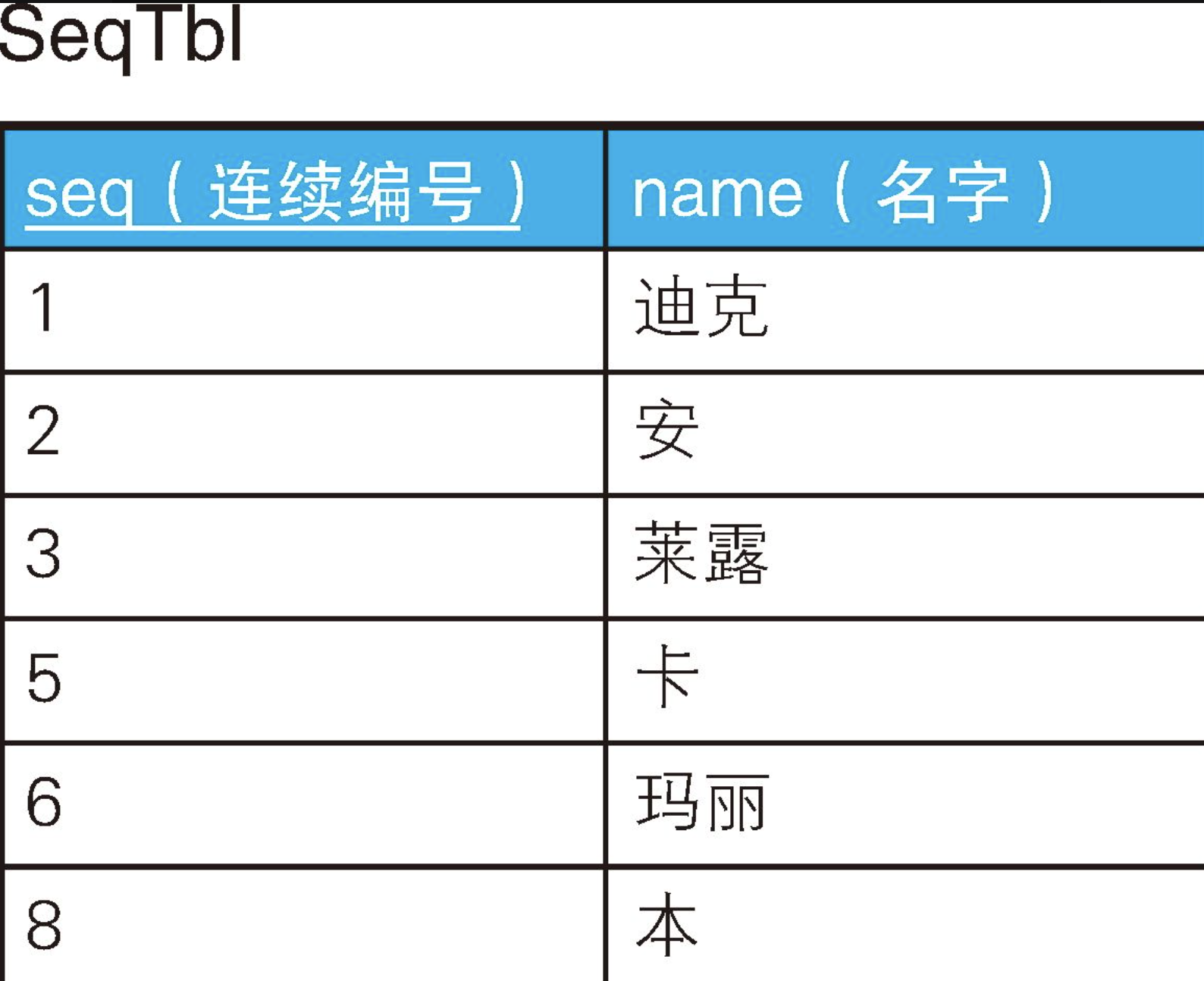
假设现有一张带有"连续编号"列的表SeqTbl。我们在使用自动分配的数值时经常会见到像这样的表。
sql
CREATE TABLE SeqTbl (
seq INTEGER PRIMARY KEY,
name VARCHAR(16) NOT NULL
);
INSERT INTO SeqTbl VALUES(1, '迪克');
INSERT INTO SeqTbl VALUES(2, '安');
INSERT INTO SeqTbl VALUES(3, '莱露');
INSERT INTO SeqTbl VALUES(5, '卡');
INSERT INTO SeqTbl VALUES(6, '玛丽');
INSERT INTO SeqTbl VALUES(8, '本');虽然编号那一列叫作连续编号,但实际上编号并不是连续的,缺少了4和7。我们要做的第一件事,就是查询这张表里是否存在数据缺失。如果像本例这样,数据只有几行,那么我们一下子就能找出来。但是,如果数据有100万行,应该就不会有人用肉眼去查询了吧。
如果这张表的数据存储在文件里,那么用面向过程语言查询时,步骤应该像下面这样。
- 对"连续编号"列按升序或者降序进行排序。
- 按照键的升序(或降序)进行循环,比较每一行和其下一行的seq列的值。
步骤很简单,但是也体现了面向过程语言和文件系统处理问题的特点:文件的记录是有顺序的,为了操作记录,编程语言需要对记录进行排序。
而表的记录是没有顺序的,而且SQL也没有排序的运算符。SQL会将多条记录作为一个集合来处理,因此如果将表整体看作一个集合,就可以像下面这样解决这个问题。
sql
-- 如果有查询结果,说明存在缺失的编号
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);
+----------------+
| gap |
+----------------+
| 存在缺失的编号 |
+----------------+如果这个查询结果有1行,说明存在缺失的编号;如果1行都没有,说明不存在缺失的编号。这是因为,如果用COUNT(*)统计出来的行数等于"连续编号"列的最大值,就说明编号从开始到最后是连续递增的,中间没有缺失。如果有缺失,COUNT(*)会小于MAX(seq),这样HAVING子句就变成真了。这个解法只需要3行代码,十分优雅。
如果用集合论的语言来描述,那么这个查询所做的事情就是检查自然数集合和SeqTbl集合之间是否存在一一映射(又称双射)。换句话说,就是像下图展示的那样,MAX(seq)计算的,是由"到seq最大值为止的没有缺失的连续编号(即自然数)"构成的集合的元素个数,而COUNT(*)计算的是SeqTbl这张表里实际的元素个数(即行数)。
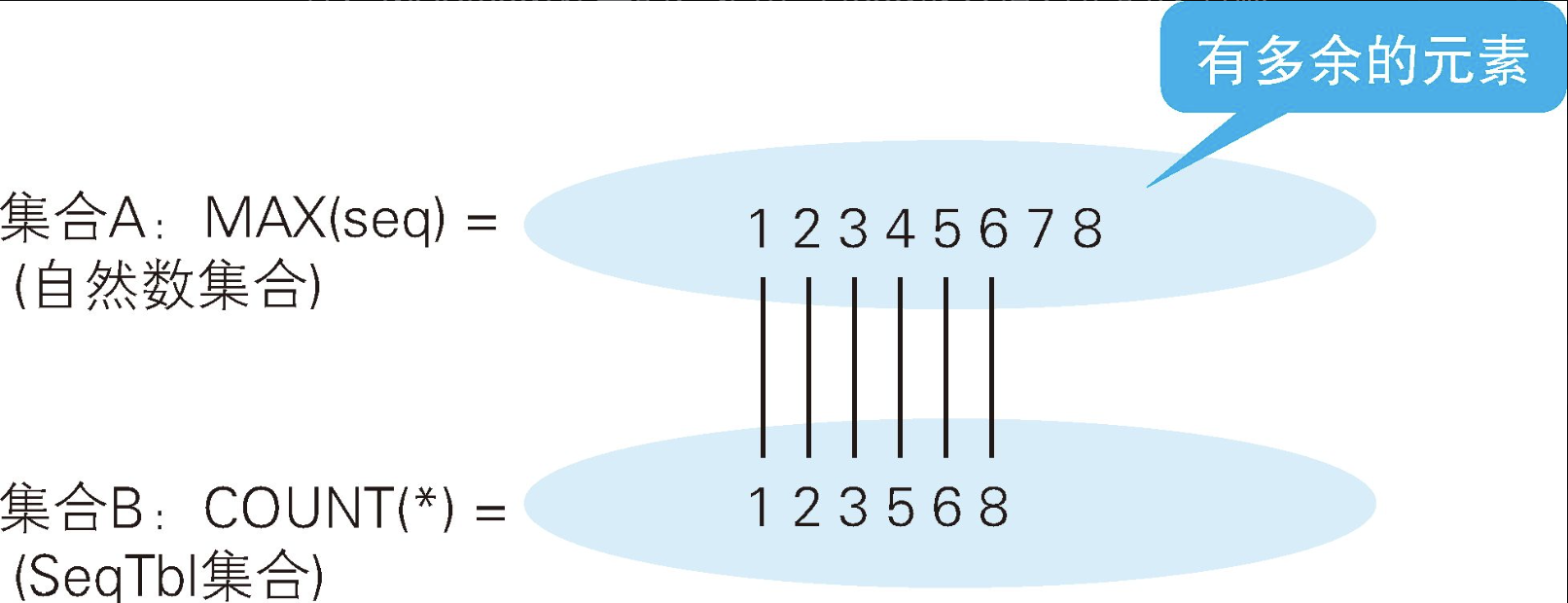
于是,如果像上图这样存在缺失的编号,那么集合A和集合B中的元素个数肯定是不一样的。
也许大家注意到了,上面的SQL语句里没有GROUP BY子句,此时整张表会被聚合为1行。在这种情况下,HAVING子句也是可以使用的。在以前的SQL标准里,HAVING子句必须和GROUP BY子句一起使用,所以到现在也有人会有这样的误解。但是,按照现在的SQL标准来说,HAVING子句是可以单独使用的。不过在这种情况下,就不能在SELECT子句里引用原来的表里的列了,要么就得像示例里一样使用常量,要么就得像SELECT COUNT(*)这样使用聚合函数。
sql
-- 查询缺失编号的最小值
SELECT min(seq + 1) AS gap
FROM SeqTbl
WHERE (seq+ 1) NOT IN (
SELECT seq FROM SeqTbl
);
+-----+
| gap |
+-----+
| 4 |
+-----+这里也是只有3行代码。使用NOT IN进行的子查询针对某一个编号,检查了比它大1的编号是否存在于表中。然后,"3,莱露""6,玛丽""8,本"这几行因为找不到紧接着的下一个编号,所以子查询的结果为真。如果没有缺失的编号,则查询到的结果是最大编号8的下一个编号9。前面已经说过了,表和文件不一样,记录是没有顺序的(表SeqTbl里的编号按升序显示只是为了方便查看)。因此,像这条语句一样进行行与行之间的比较时,其实是不进行排序的。
顺便说一下,如果表SeqTbl里包含NULL,那么这条SQL语句的查询结果就不正确了。
上面展示了通过SQL语句查询缺失编号的最基本的思路,然而这个查询还不够周全,并不能涵盖所有情况。例如,如果表SeqTbl里没有编号1,那么缺失编号的最小值应该是1,但是这两条SQL语句都不能得出正确的结果(请试着自己模拟分析一下,推测出可能的结果)。下面,我们就来学习一下查询缺失编号的更完备的做法。
2、寻找缺失的编号:升级版
我们对前面的问题放宽一下限制条件,思考一下不管数列的最小值是多少,都能用来判断该数列是否连续的SQL语句。对新的SQL语句来说,下页这4种情况中,(3)是连续的,而 (4)存在数据缺失。但是,对前面的SQL语句来说,这里 (3)的起始值不是1,所以是不连续的。
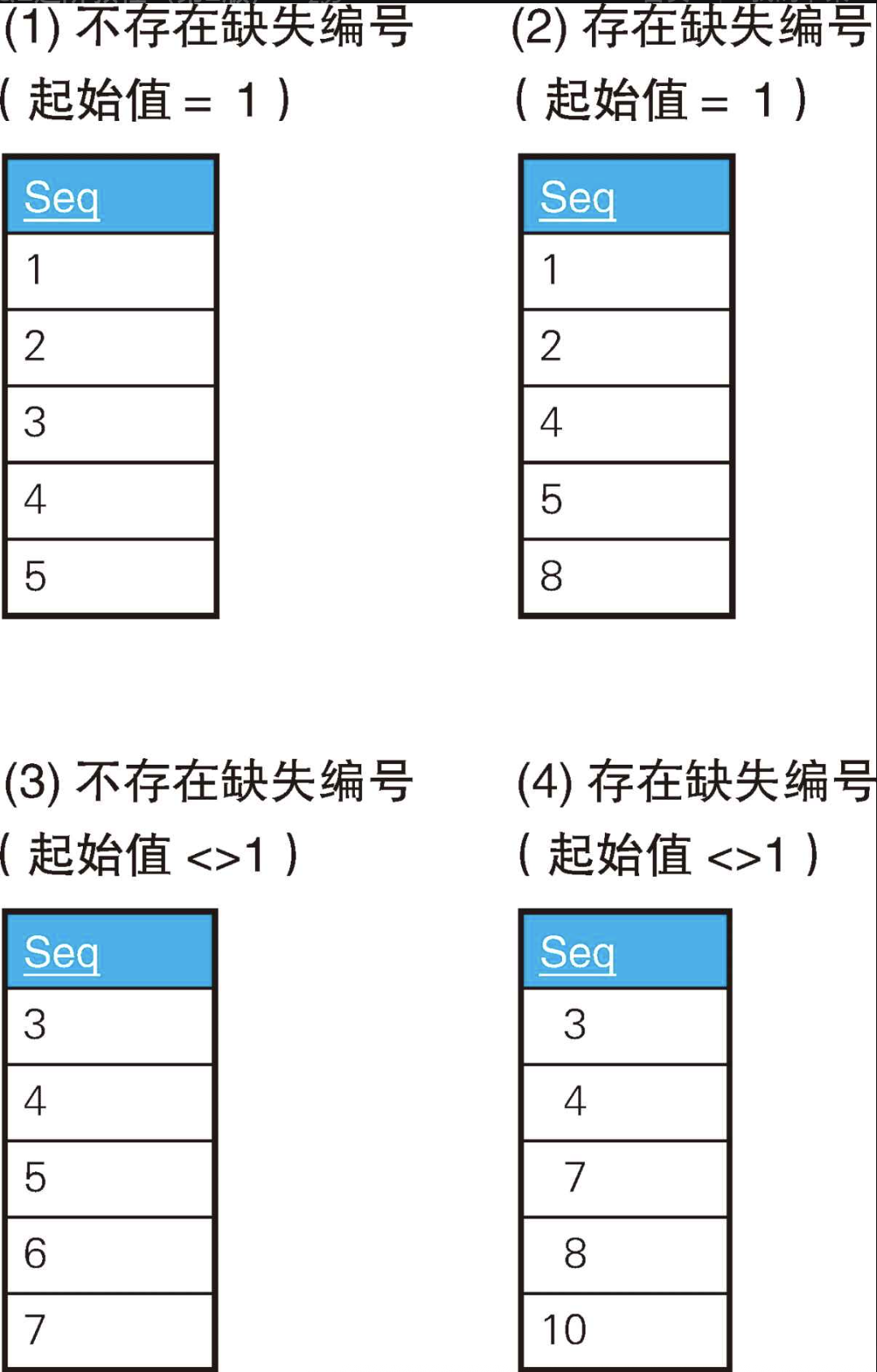
解决这个问题的基本思路和之前是一样的,即将表整体看作一个集合,使用COUNT()来获得其中的元素个数。上面4种情况的话,每张表都满足COUNT()=5。而且,如果数列的最小值和最大值之间没有缺失的编号,它们之间包含的元素的个数应该是"最大值-最小值+1"。因此,我们像下面这样写比较条件就可以了。
sql
-- 如果有查询结果,说明存在缺失的编号:只调查数列的连续性
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq)- MIN(seq)+ 1 ;
+----------------+
| gap |
+----------------+
| 存在缺失的编号 |
+----------------+这条SQL语句将情况 (1)和(3)看成是连续的。如果不论是否存在缺失的编号,都想要返回结果,那么只需要像下面这样把条件写到SELECT里就可以了。
sql
-- 不论是否存在缺失的编号, 都返回一行结果
SELECT CASE WHEN COUNT(*) = 0 THEN '表为空'
WHEN COUNT(*) <> MAX(seq)- MIN(seq)+ 1 THEN '存在缺失的编号'
ELSE '连续' END AS gap
FROM SeqTbl;
+----------------+
| gap |
+----------------+
| 存在缺失的编号 |
+----------------+这条SQL语句中稍微多做了一点处理,即将"表为空"当作异常情况处理,返回"表为空"的结果(即使是表为空的时候,前面那条使用了HAVING的SQL语句也会认为编号是连续的)。能够像这样表达详细的条件分支正是CASE表达式的魅力所在。
接下来,我们也顺便改进一下查找最小的缺失编号的SQL语句,去掉起始值必须是1的限制。对于之前的简单版的SQL语句来说,情况 (4)会把5当成最小的缺失编号来返回。因为表中并没有1和2,所以简单版的SQL语句根本不会去检查它们的下一个数是否存在。对于表中原本就不存在1的这类情况,我们可以追加一个条件分支让它返回1,即像下面这样来写SQL语句。
sql
-- 查找最小的缺失编号:当表中没有 1 时,返回 1
SELECT CASE WHEN COUNT(*)= 0 OR MIN(seq)> 1 -- 最小值不是 1 时→返回 1
THEN 1
ELSE (SELECT MIN(seq +1) -- 最小值是 1 时→返回最小的缺失编号
FROM SeqTbl S1
WHERE NOT EXISTS
(SELECT *
FROM SeqTbl S2
WHERE S2.seq = S1.seq + 1)) END
FROM SeqTbl;可以看到,简单版的SQL语句以标量子查询的方式整体地嵌入了CASE表达式的返回结果块里。考虑到表可能为空,所以这里加上了COUNT(*)= 0这个条件。而且相比简单版,NOT IN也改写成了NOT EXISTS,这样写是为了处理值为NULL的情况,以及略微优化一下性能。特别是如果在seq列上建立了索引,那么使用NOT EXISTS就能明显改善性能。这条SQL语句会返回下面这样的结果。
- 情况(1)⇨ 6 (没有缺失的编号,所以返回最大值5的下一个数)
- 情况(2)⇨ 3 (最小的缺失编号)
- 情况(3)⇨ 1 (因为表中没有1)
- 情况(4)⇨ 1 (因为表中没有1)
在面向过程语言中,条件分支是通过IF语句或者CASE语句等进行的。但是在SQL语言中,所有的条件分支都是通过"表达式(函数)"进行的。在这一点上,SQL语言跟函数式语言非常相似。
3、用HAVING子句进行子查询:求众数
sql
CREATE TABLE Graduates (
name VARCHAR(16) PRIMARY KEY,
income INTEGER NOT NULL
);
INSERT INTO Graduates VALUES('桑普森', 400000);
INSERT INTO Graduates VALUES('迈克', 30000);
INSERT INTO Graduates VALUES('怀特', 20000);
INSERT INTO Graduates VALUES('阿诺德', 20000);
INSERT INTO Graduates VALUES('史密斯', 20000);
INSERT INTO Graduates VALUES('劳伦斯', 15000);
INSERT INTO Graduates VALUES('哈德逊', 15000);
INSERT INTO Graduates VALUES('肯特', 10000);
INSERT INTO Graduates VALUES('贝克', 10000);
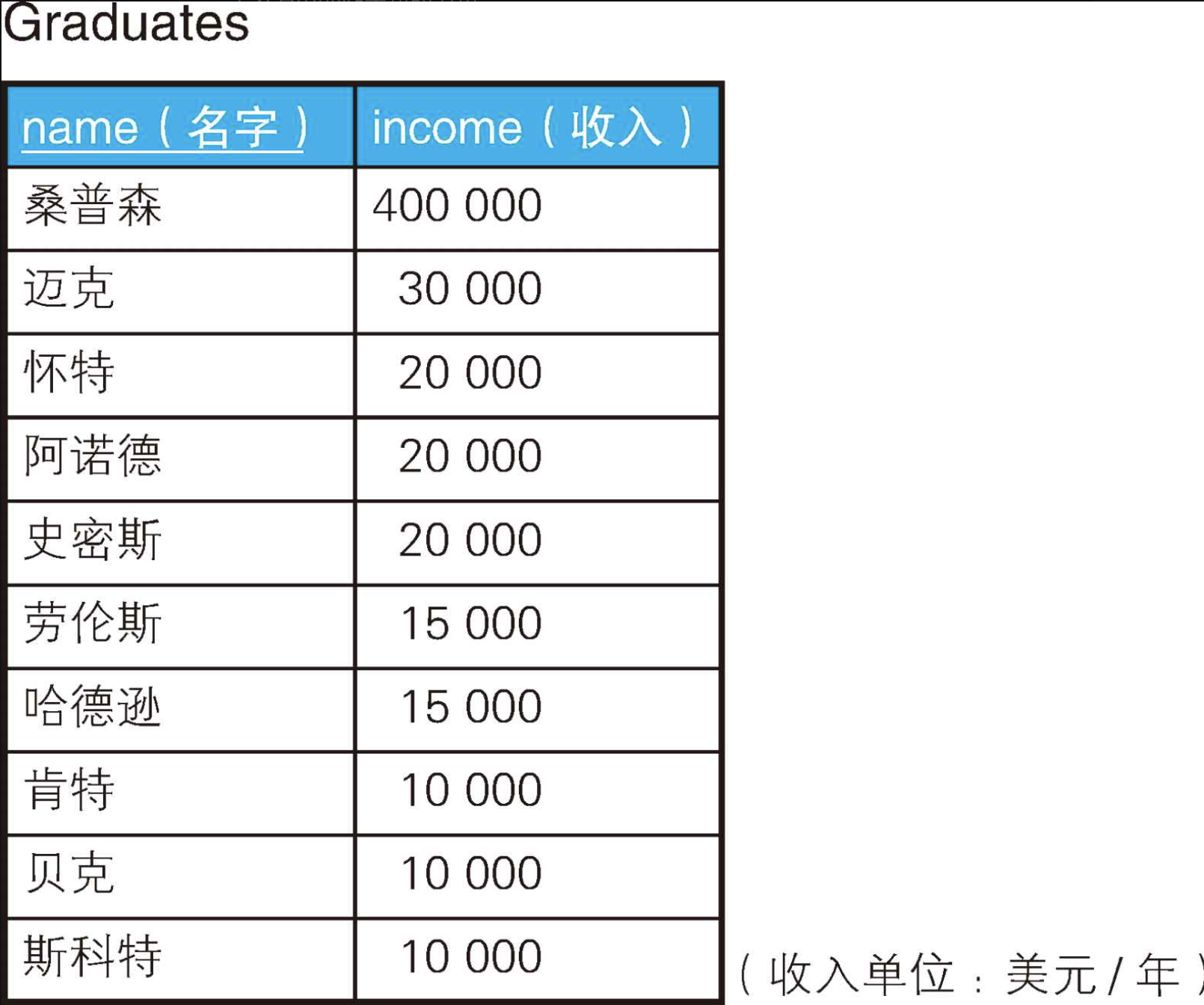
INSERT INTO Graduates VALUES('斯科特', 10000);从这个例子可以看出,简单地求平均值有一个缺点,那就是很容易受到离群值(outlier)的影响。这就是广为人知的错误统计方法------平均值缺陷。
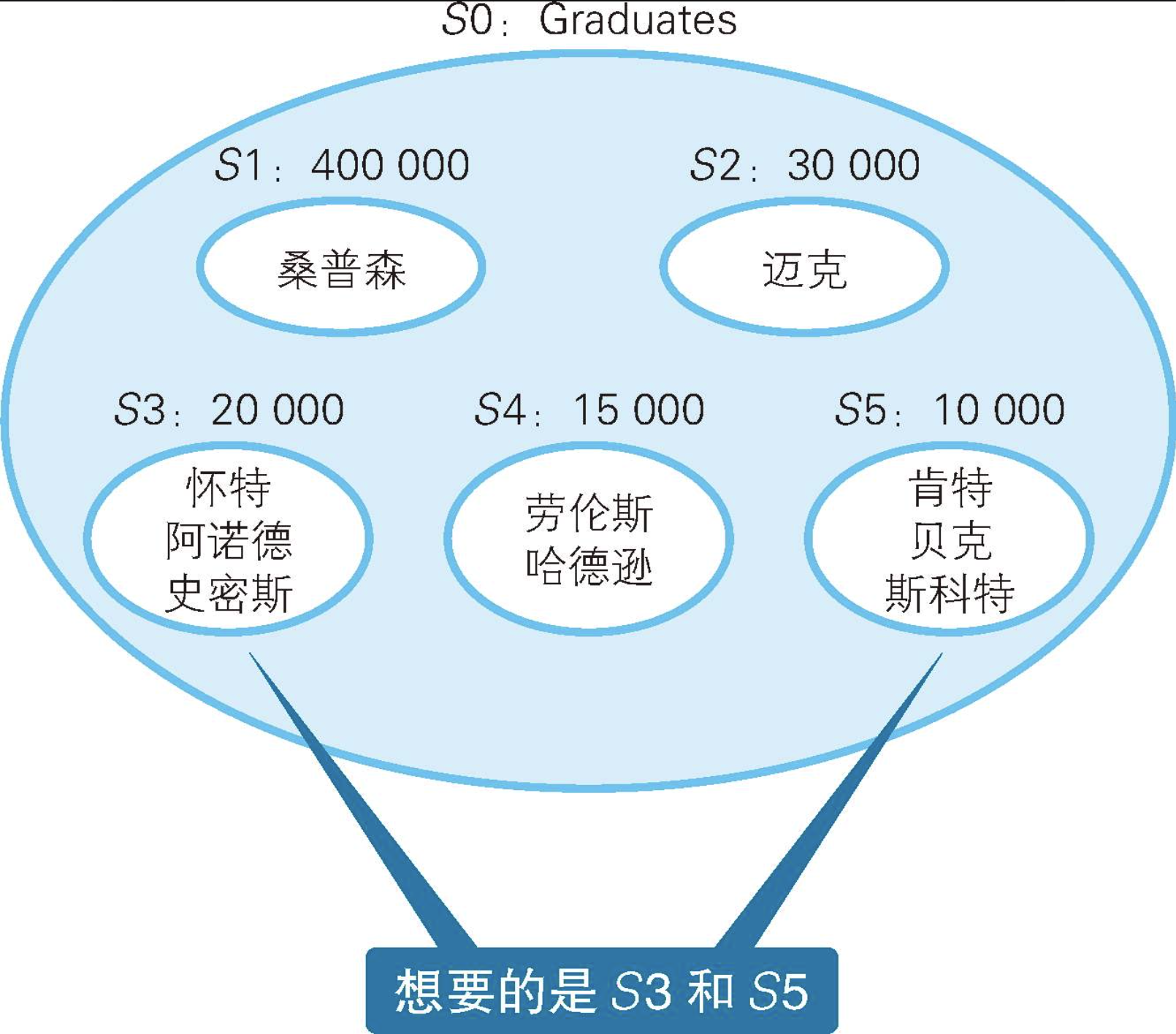
这种时候,就必须使用更能准确反映出群体趋势的指标------众数(mode)就是其中之一。它指的是在群体中出现次数最多的值,因此在日语中也被称为流行值。就上面的表Graduates来说,众数就是10000和20000这两个值。接下来,我们思考一下如何用SQL语句求众数。
有些DBMS已经提供了用来求众数的函数,但其实用标准SQL也很简单。思路是将收入相同的毕业生汇总到一个集合里,然后从汇总后的各个集合里找出元素个数最多的集合。像这样用SQL来操作集合,正如探囊取物一样简单。
sql
select income, count(income) as cnt
from Graduates
group by income
having count(*) >= all (
select count(*)
from Graduates
group by income
);
+--------+-----+
| income | cnt |
+--------+-----+
| 20000 | 3 |
| 10000 | 3 |
+--------+-----+GROUP BY子句的作用是将总集分割成若干个子集。因此,将收入(income)作为GROUP BY的列时,将得到5个子集,如图所示。
ALL谓词用于NULL或空集时会出现问题,可以用极值函数来代替它。这里要求的是元素数最多的集合,因此可以用MAX函数。
sql
select income, count(income) as cnt
from Graduates
group by income
having count(*) >= (
select max(cnt)
from (
select count(*) as cnt
from Graduates
group by income
) tmp
);如果表Graduates是存储在文件里的,需要用面向过程语言的方法来求众数,又该怎么做呢?恐怕要先按收入进行排序,然后一行一行地循环处理和中断控制,遇到某个收入值的人数超出前面一个收入值的人数时,将新的收入值赋给另一个变量并保存,以便后续使用。很显然,与这种做法相比,使用SQL既不需要循环,也不需要赋值。
4、查询不包含NULL的集合
COUNT函数的使用方法有COUNT(*)和COUNT(列名)两种,它们的区别有两个:
- 第一个是性能上的区别;
- 第二个是
COUNT(*)可以用于NULL,而COUNT(列名)与其他聚合函数一样,要先排除掉NULL的行再进行统计。第二个区别也可以这么理解:COUNT(*)查询的是所有行的数目,而COUNT(列名)查询的不一定是。
对一张全是NULL的表NullTbl执行SELECT子句,我们就能清楚地知道两者的区别了。
sql
CREATE TABLE NullTbl (col_1 INTEGER);
INSERT INTO NullTbl VALUES (NULL);
INSERT INTO NullTbl VALUES (NULL);
INSERT INTO NullTbl VALUES (NULL);
sql
-- 在对包含 NULL 的列使用时,COUNT(*)和 COUNT(列名)的查询结果是不同的
SELECT COUNT(*), COUNT(col_1)
FROM NullTbl;
+----------+--------------+
| COUNT(*) | COUNT(col_1) |
+----------+--------------+
| 3 | 0 |
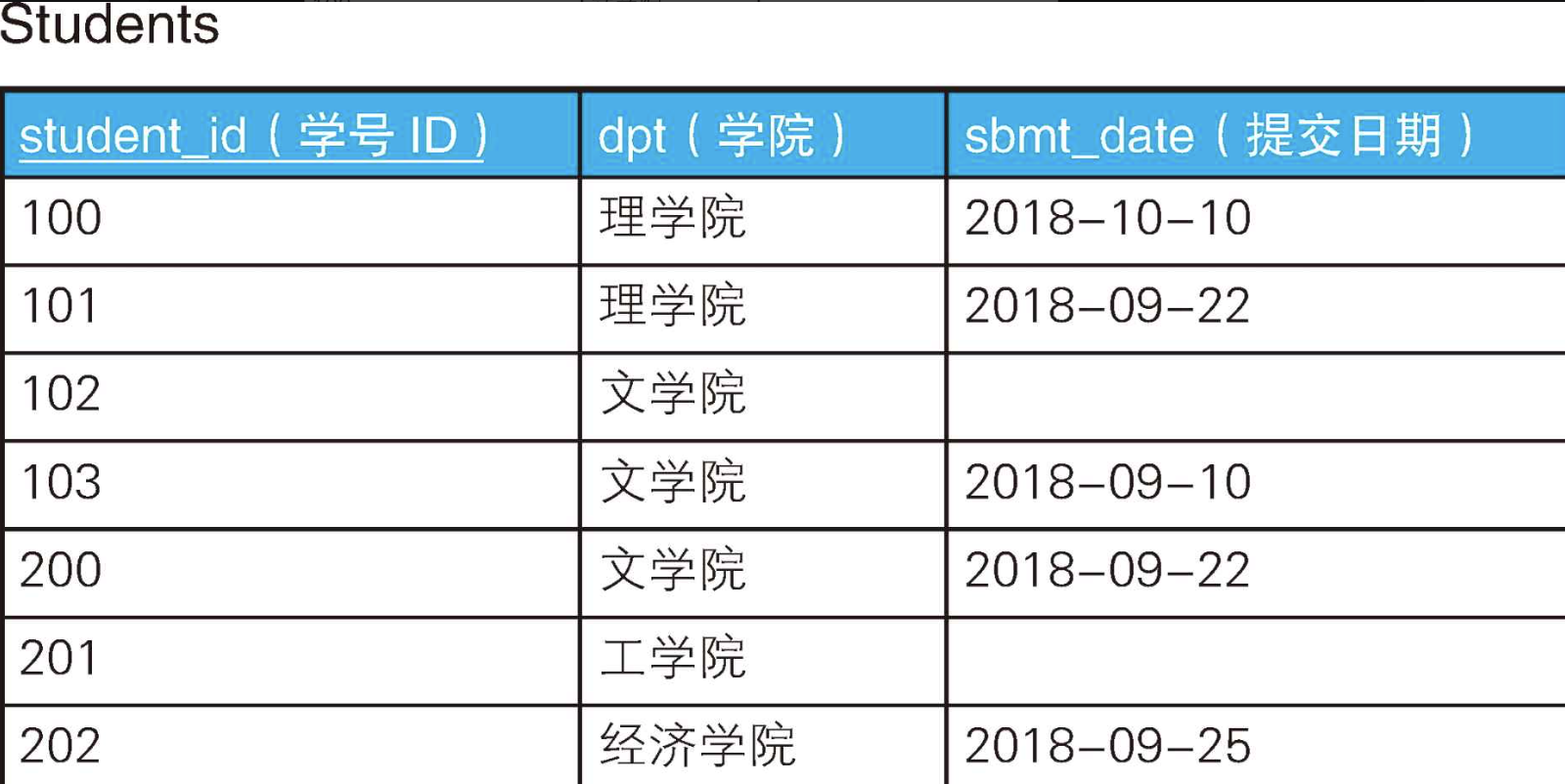
+----------+--------------+对于这两个区别,我们在编写SQL语句时当然要多加留意,但是如果能好好利用,它们也可以发挥令人意想不到的作用。例如,这里有一张存储了学生提交报告的日期的表Students。
sql
CREATE TABLE Students (
student_id INTEGER PRIMARY KEY,
dpt VARCHAR(16) NOT NULL,
sbmt_date DATE
);
INSERT INTO Students VALUES(100, '理学院', '2018-10-10');
INSERT INTO Students VALUES(101, '理学院', '2018-09-22');
INSERT INTO Students VALUES(102, '文学院', NULL);
INSERT INTO Students VALUES(103, '文学院', '2018-09-10');
INSERT INTO Students VALUES(200, '文学院', '2018-09-22');
INSERT INTO Students VALUES(201, '工学院', NULL);
INSERT INTO Students VALUES(202, '经济学院', '2018-09-25');学生提交报告后,"提交日期"列会被写入日期,而提交之前它们是NULL。现在,我们需要从这张表里找出哪些学院的学生全部都提交了报告(即理学院、经济学院)。如果只是用WHERE sbmt_date IS NOT NULL这样的条件查询,文学院也会被包含进来,结果就不正确了(因为文学院学号为102的学生还没有提交)。正确的做法是,以"学院"为GROUP BY的列生成图这样的子集。
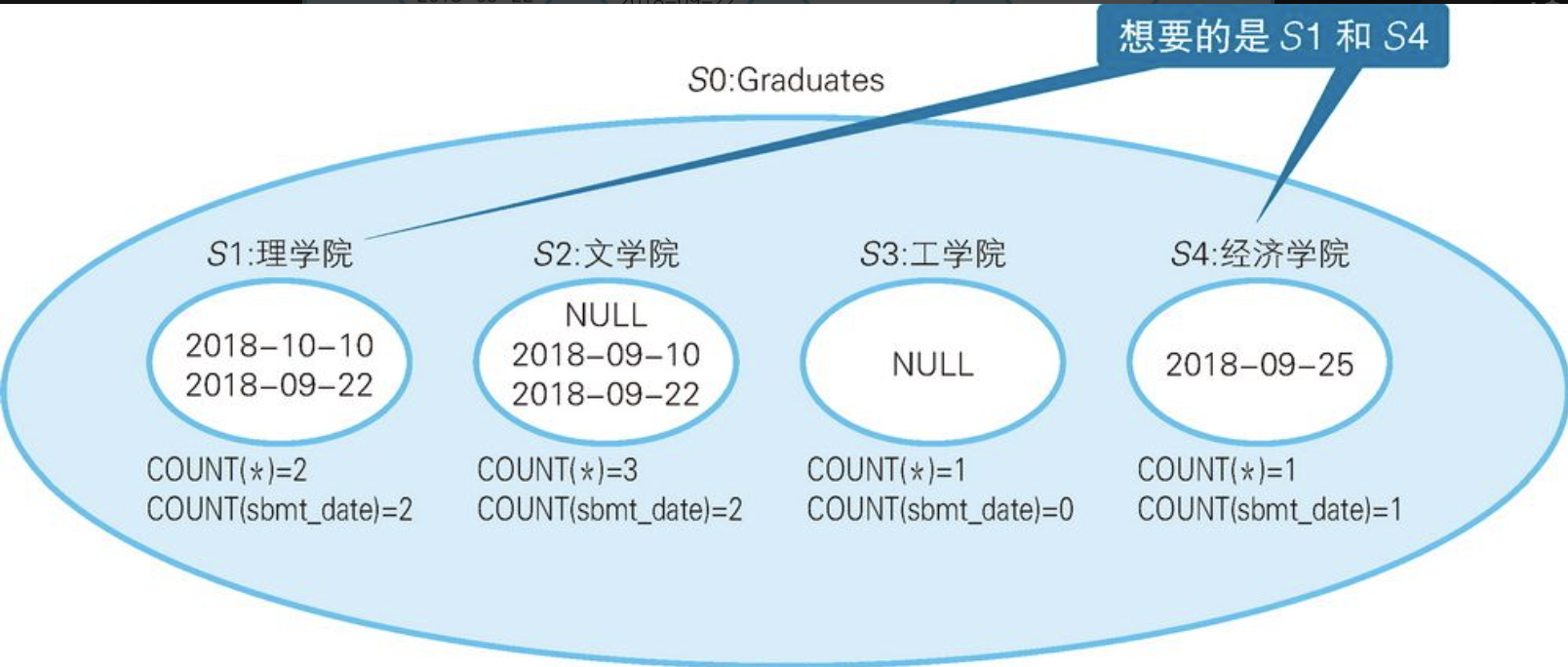
sql
-- 查询"提交日期"列内不包含 NULL 的学院(1):使用 COUNT 函数
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = COUNT(sbmt_date);
+----------+
| dpt |
+----------+
| 理学院 |
| 经济学院 |
+----------+当然,使用CASE表达式也可以实现同样的功能,而且更加通用。
sql
-- 查询"提交日期"列内不包含 NULL 的学院(2):使用 CASE 表达式
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*)= SUM(
CASE WHEN sbmt_date IS NOT NULL
THEN 1 ELSE 0 END
);可以看到,使用CASE表达式时,将"提交日期"不是NULL的行标记为1,将"提交日期"是NULL的行标记为0。在这里,CASE表达式的作用相当于进行判断的函数,用来判断各个元素(=行)是否属于满足了某种条件的集合。这样的函数我们称之为特征函数(characteristicfunction),或者从定义了集合的角度称之为定义函数。像这样,HAVING子句可以用作研究集合性质的工具,特别是在与聚合函数或CASE表达式一起使用时,它具有更强大的威力。
另外,大家可能已经注意到了,当使用HAVING子句分割集合来解决问题时,在纸上画圆的方法效果很好。面向过程语言中使用流程图(线和四边形)来辅助思考,而面向集合语言中则使用圆(维恩图)来辅助思考。
5、特征函数的应用
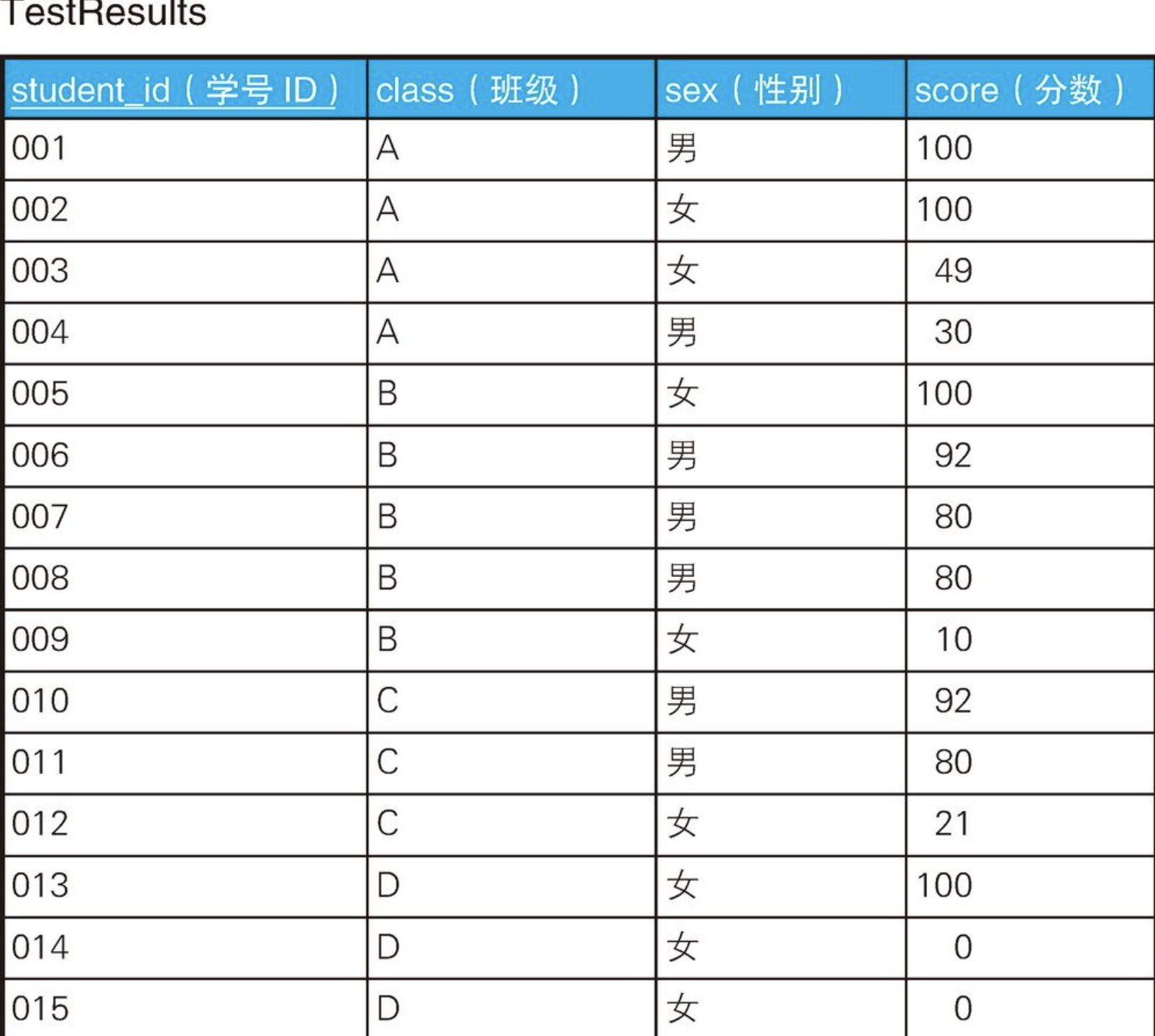
sql
CREATE TABLE TestResults (
student_id CHAR(12) NOT NULL PRIMARY KEY,
class CHAR(1) NOT NULL,
sex CHAR(1) NOT NULL,
score INTEGER NOT NULL
);
INSERT INTO TestResults VALUES('001', 'A', '男', 100);
INSERT INTO TestResults VALUES('002', 'A', '女', 100);
INSERT INTO TestResults VALUES('003', 'A', '女', 49);
INSERT INTO TestResults VALUES('004', 'A', '男', 30);
INSERT INTO TestResults VALUES('005', 'B', '女', 100);
INSERT INTO TestResults VALUES('006', 'B', '男', 92);
INSERT INTO TestResults VALUES('007', 'B', '男', 80);
INSERT INTO TestResults VALUES('008', 'B', '男', 80);
INSERT INTO TestResults VALUES('009', 'B', '女', 10);
INSERT INTO TestResults VALUES('010', 'C', '男', 92);
INSERT INTO TestResults VALUES('011', 'C', '男', 80);
INSERT INTO TestResults VALUES('012', 'C', '女', 21);
INSERT INTO TestResults VALUES('013', 'D', '女', 100);
INSERT INTO TestResults VALUES('014', 'D', '女', 0);
INSERT INTO TestResults VALUES('015', 'D', '女', 0);5.1、请查询出75%以上的学生分数都在80分以上的班级
班级里的总人数可以通过COUNT(*)查到,80分以上的学生人数可以通过特征函数来统计,因此答案如下所示。
sql
select a.class, count(a.score)
from TestResults a
where a.score >= 80
group by a.class
having count(a.score) / (
select count(score)
from TestResults b
where b.class = a.class
) >= 0.75;
-- 或
SELECT class
FROM TestResults
GROUP BY class
HAVING COUNT(*) * 0.75
<= SUM(CASE WHEN score >= 80
THEN 1
ELSE 0 END);
+-------+
| class |
+-------+
| B |
+-------+5.3、查询出分数在50分以上的男生的人数比分数在50分以上的女生的人数多的班级
两个条件都可以用特征函数来描述。
sql
select class
from TestResults
group by class
having sum(
case when score >= 50 and sex = '男' then 1
else 0 end
) > sum(
case when score >= 50 and sex = '女' then 1
else 0 end
);
+-------+
| class |
+-------+
| B |
| C |
+-------+5.4、请查询出女生平均分比男生平均分高的班级
按照和前两题一样的思路,像下面这样写的人应该不少吧。
sql
-- 比较男生和女生平均分的 SQL 语句(1):对空集求平均值使用 AVG 后返回 0
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(
CASE WHEN sex = '男' THEN score ELSE 0 END
) < AVG(
CASE WHEN sex = '女' THEN score ELSE 0 END
);
+-------+
| class |
+-------+
| A |
| D |
+-------+D班全是女生。在上面的解答中,用于判断男生的CASE表达式里的分支ELSE 0生效了,于是男生的平均分就成了0分。对于女生的平均分约为33.3的D班,条件0 <33.3也成立,所以D班也出现在查询结果里了。这种处理方法看起来好像也没什么问题。但是,如果学号013的学生分数刚好也是0分,结果会怎么样呢?这种情况下,女生的平均分会变为0分,所以D班不会被查询出来。
男生和女生的平均分都是0,但是两个0的意义完全不同。女生的平均分是正常计算出来的,而男生的平均分本来就无法计算,只是强行赋值为0而已。真正合理的处理方法是,保证对空集求平均的结果是"未定义",就像除以0的结果是未定义一样。
根据标准SQL的定义,对空集使用AVG函数时,结果会返回NULL下面,我们来看一下修改后的SQL语句。
sql
-- 比较男生和女生平均分的 SQL 语句(2):对空集求平均值后返回 NULL
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(
CASE WHEN sex = '男' THEN score ELSE NULL END
) < AVG(
CASE WHEN sex = '女' THEN score ELSE NULL END
);
+-------+
| class |
+-------+
| A |
+-------+这回,D班男生的平均分是NULL。因此不管女生的平均分多少,D班都会被排除在查询结果之外。这种处理方法和AVG函数的处理逻辑也是一致的。
关注集合的性质,反过来说其实就是忽略掉单个元素的特征。在解答上面几道例题时,我们考虑的也是班级整体具有的特点和趋势,至于个人得了多少分,并没有关注。这种在确保成员隐秘性的同时研究集体趋势的思维方式与统计学的方法论不谋而合。考虑到BI与SQL之间的相似之处,这种情况就一点都不奇怪了。
6、使用HAVING语句表达全称量化
首先,恭喜你被任命为了消防队(或地球保卫队也行)的总负责人。现在你收到了来自司令部的出勤指示。
你需要做的是查出现在可以出勤的队伍。可以出勤的条件就是队伍里所有队员都处于"待命"状态。你使用的是下面这张表。
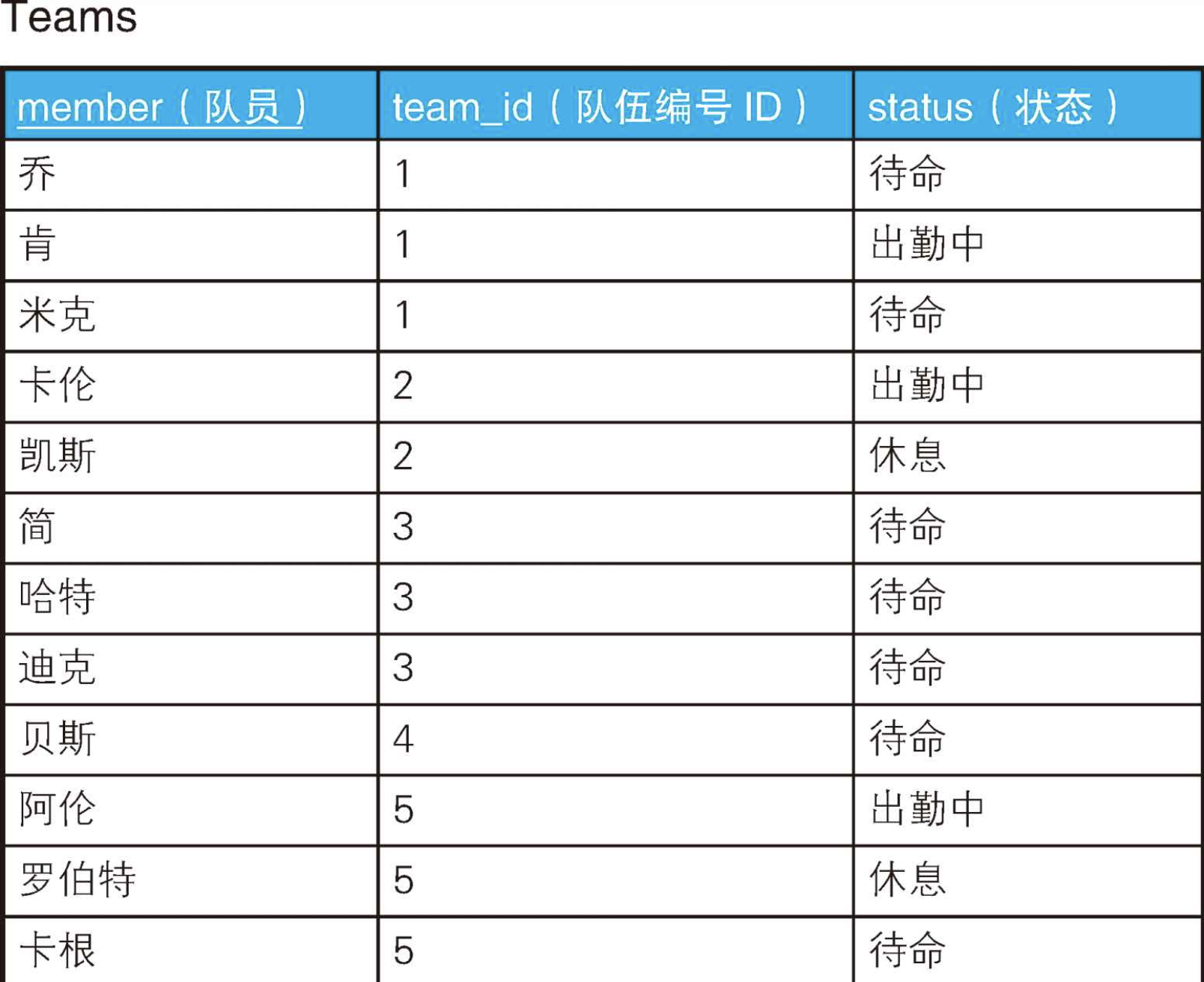
sql
CREATE TABLE Teams (
member CHAR(12) NOT NULL PRIMARY KEY,
team_id INTEGER NOT NULL,
status CHAR(8) NOT NULL
);
INSERT INTO Teams VALUES('乔', 1, '待命');
INSERT INTO Teams VALUES('肯', 1, '出勤中');
INSERT INTO Teams VALUES('米克', 1, '待命');
INSERT INTO Teams VALUES('卡伦', 2, '出勤中');
INSERT INTO Teams VALUES('凯斯', 2, '休息');
INSERT INTO Teams VALUES('简', 3, '待命');
INSERT INTO Teams VALUES('哈特', 3, '待命');
INSERT INTO Teams VALUES('迪克', 3, '待命');
INSERT INTO Teams VALUES('贝斯', 4, '待命');
INSERT INTO Teams VALUES('阿伦', 5, '出勤中');
INSERT INTO Teams VALUES('罗伯特', 5, '休息');
INSERT INTO Teams VALUES('卡根', 5, '待命');在这张示例表中,可以出勤的队伍是3队和4队。4队里虽然只有贝斯1人,但是确实也是全队都集齐了。我们来思考一下求可以出勤的队伍的SQL语句。
所有队员都处于待命状态这个条件是全称量化命题,所以可以用NOT EXISTS来表达。
sql
-- 用谓词表达全称量化命题
SELECT team_id, member
FROM Teams T1
WHERE NOT EXISTS (
SELECT *
FROM Teams T2
WHERE T1.team_id = T2.team_id
AND status <> '待命'
);
+---------+--------+
| team_id | member |
+---------+--------+
| 3 | 哈特 |
| 3 | 简 |
| 4 | 贝斯 |
| 3 | 迪克 |
+---------+--------+"所有队员都处于待命状态"="不存在不处于待命状态的队员"
这个查询的性能很好,而且结果中能体现出队员信息,这些是它好的地方。但是它使用了双重否定,所以理解起来不是很容易。如果使用HAVING子句,写起来就非常简单了,像下面这样。
sql
select team_id
from Teams
group by team_id
having count(*) = sum(
case when status = '待命' then 1
else 0 end
);
+---------+
| team_id |
+---------+
| 3 |
| 4 |
+---------+上面这条SQL语句是一个肯定句,理解起来更直观,而且代码很简洁。接下来,我们仔细看一下这条SQL语句具体做了些什么。第一步还是使用GROUP BY子句将Teams集合以队伍为单位划分成几个子集。
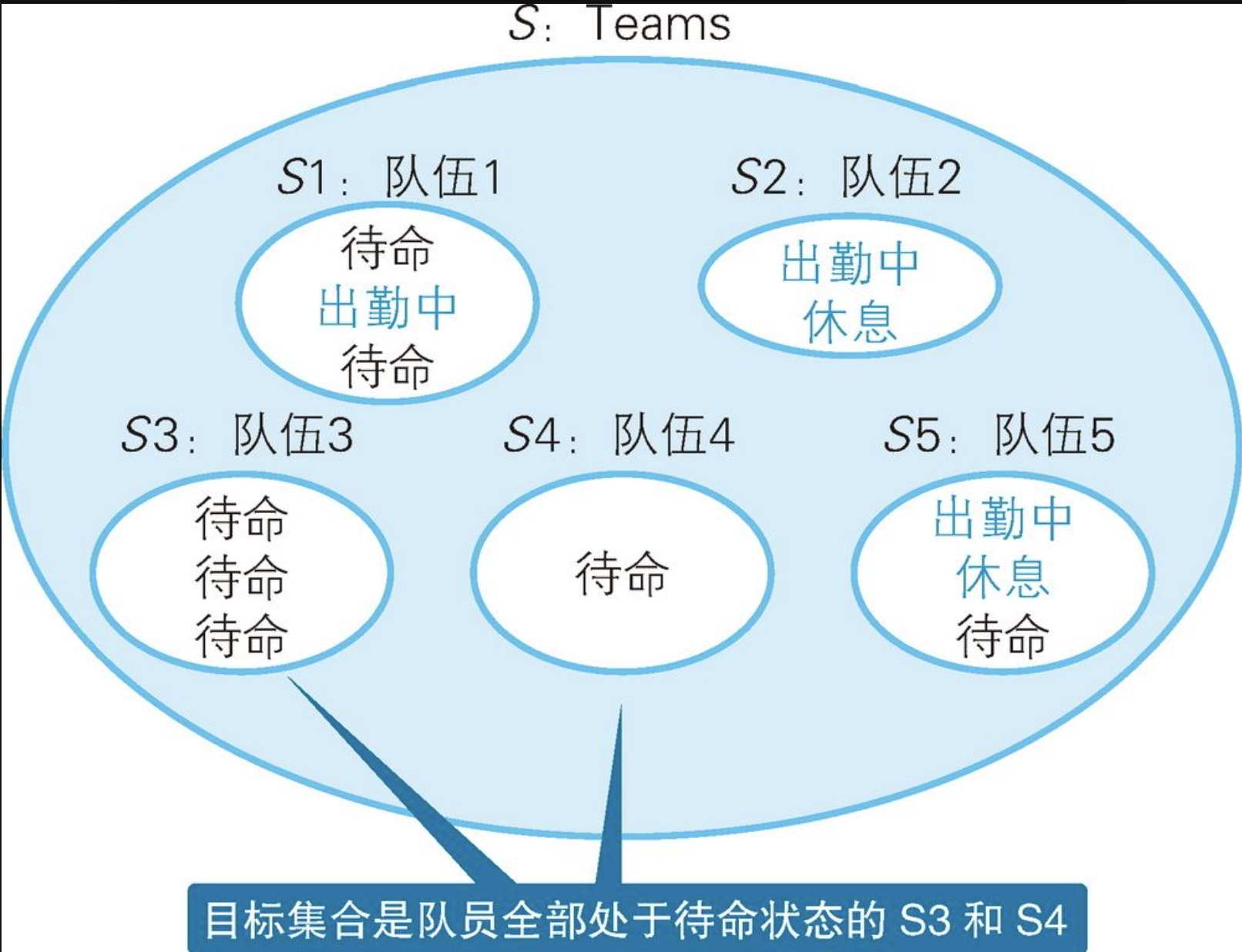
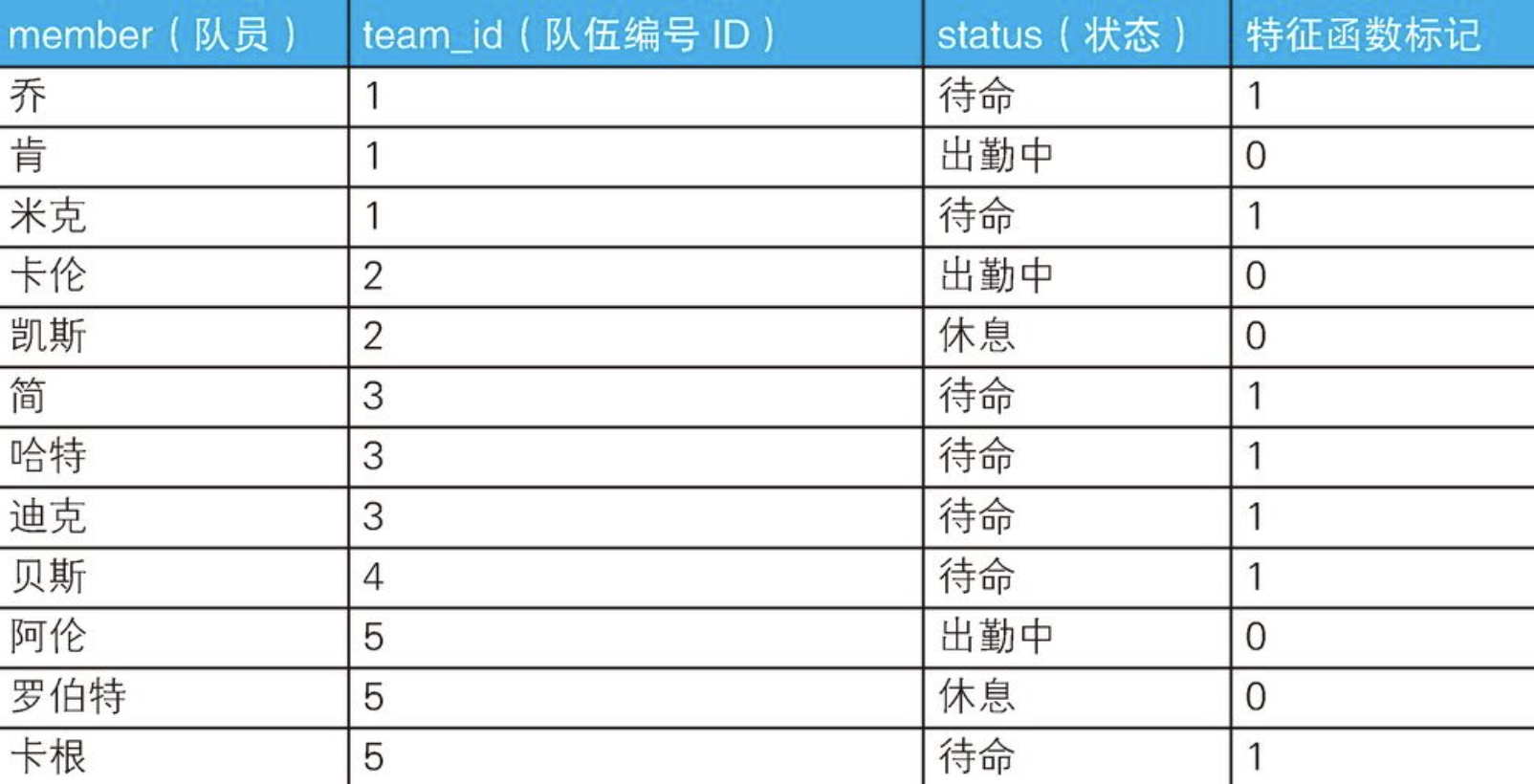
目标集合是S3和S4,那么只有这两个集合拥有而其他集合没有的特征是什么呢?答案是,处于"待命"状态的数据行数与集合中数据的总行数相等。这个条件可以用CASE表达式来表达:状态为"待命"的情况下返回1,其他情况下返回0。也许大家已经注意到了,这里使用的就是特征函数。如果像下表这样,根据是否满足条件分别为表里的每一行数据都加上标记1或0,是不是就更容易理解了?
顺便说一下,HAVING子句中的条件还可以像下页这样写。
sql
-- 用集合表达全称量化命题(2)
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING MAX(status)= '待命'
AND MIN(status)= '待命';
+---------+
| team_id |
+---------+
| 3 |
| 4 |
+---------+这条SQL语句的意思大家明白吗?在某个集合中,如果元素最大值和最小值相等,那么这个集合中肯定只有一种值。因为如果包含多种值,最大值和最小值肯定不会相等。极值函数可以使用参数字段的索引,所以这种写法性能更好(当然本例中只有3种值,建立索引也并没有太大的意义)。
当然,我们也可以把条件放在SELECT子句里,以列表形式显示出各个队伍是否所有队员都在待命,这样的结果更加一目了然。
sql
-- 列表显示各个队伍是否所有队员都在待命
SELECT team_id,
CASE WHEN MAX(status)= '待命' AND MIN(status)= '待命'
THEN '全员待命'
ELSE '队长!人手不够' END AS status
FROM Teams GROUP BY team_id;
+---------+----------------+
| team_id | status |
+---------+----------------+
| 1 | 队长!人手不够 |
| 2 | 队长!人手不够 |
| 5 | 队长!人手不够 |
| 3 | 全员待命 |
| 4 | 全员待命 |
+---------+----------------+7、单重集合与多重集合
关系数据库中的集合是允许数据重复的多重集合。与之相反,通常意义的集合论中的集合不允许数据重复,所以称之为"单重集合"。
允许循环插入和频繁读/写的表中有可能产生重复数据。在定义表时加入唯一性约束可以预防表中产生重复数据,但是有些情况下根据具体的业务需求,产生重复数据也是合理的。例如,有下面这样一张管理各个生产地的材料库存的表。
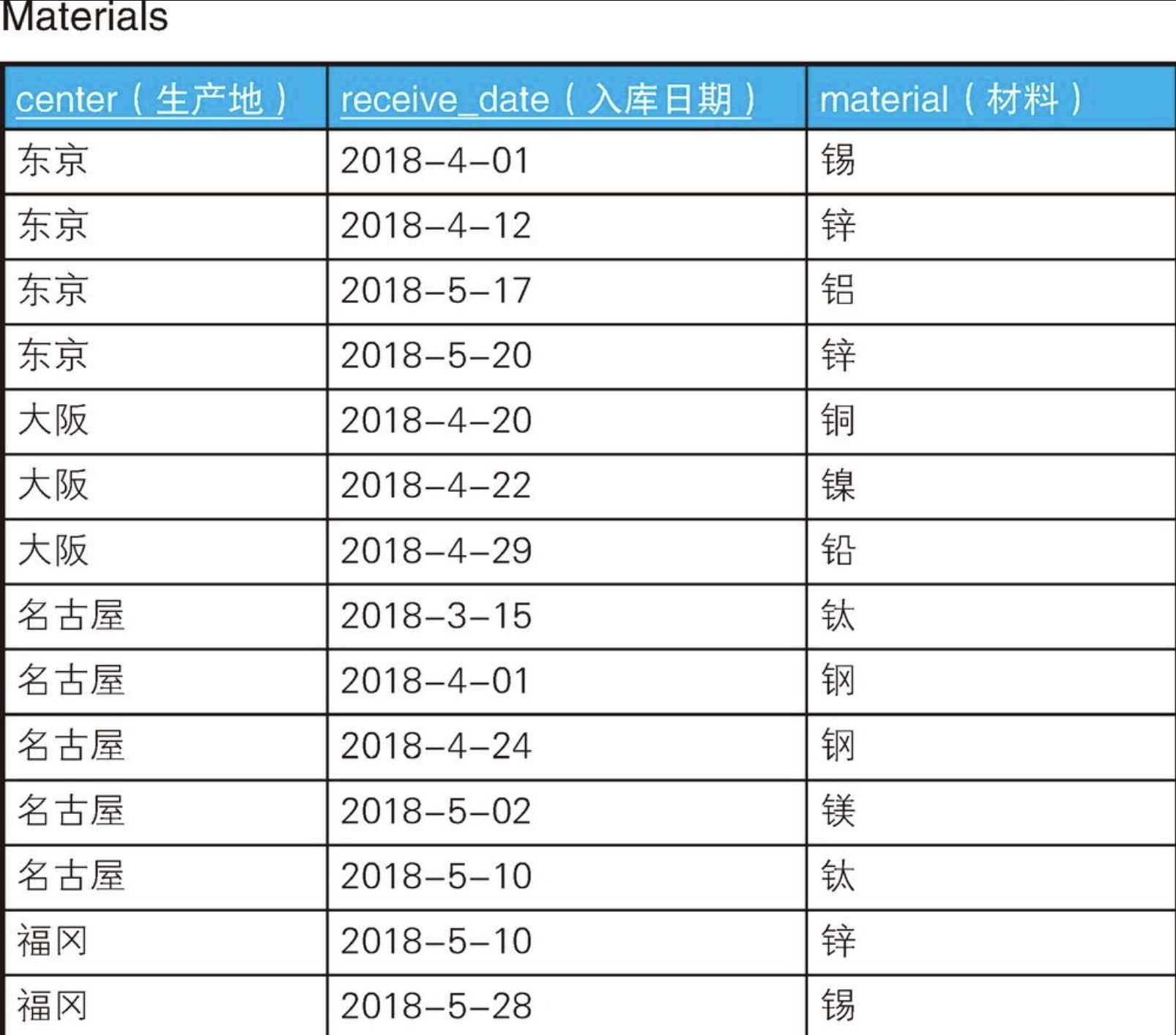
sql
CREATE TABLE Materials (
center CHAR(12) NOT NULL,
receive_date DATE NOT NULL,
material CHAR(12) NOT NULL,
PRIMARY KEY(center, receive_date)
);
INSERT INTO Materials VALUES('东京' ,'2018-4-01', '锡');
INSERT INTO Materials VALUES('东京' ,'2018-4-12', '锌');
INSERT INTO Materials VALUES('东京' ,'2018-5-17', '铝');
INSERT INTO Materials VALUES('东京' ,'2018-5-20', '锌');
INSERT INTO Materials VALUES('大阪' ,'2018-4-20', '铜');
INSERT INTO Materials VALUES('大阪' ,'2018-4-22', '镍');
INSERT INTO Materials VALUES('大阪' ,'2018-4-29', '铅');
INSERT INTO Materials VALUES('名古屋', '2018-3-15', '钛');
INSERT INTO Materials VALUES('名古屋', '2018-4-01', '钢');
INSERT INTO Materials VALUES('名古屋', '2018-4-24', '钢');
INSERT INTO Materials VALUES('名古屋', '2018-5-02', '镁');
INSERT INTO Materials VALUES('名古屋', '2018-5-10', '钛');
INSERT INTO Materials VALUES('福冈' ,'2018-5-10', '锌');
INSERT INTO Materials VALUES('福冈' ,'2018-5-28', '锡');各生产地每天都会入库一批材料,然后使用材料生产各种各样的产品。但是,有时材料不能按原定计划在一天内消耗完,会出现重复。这时,为了在各生产地之间调整重复的材料,我们需要调查出存在重复材料的生产地。
我们先来分析一下满足条件的生产地具有哪些特征。从表中可以看到,一个生产地对应着多条数据,因此"生产地"这一实体在表中是以集合的形式,而不是以元素的形式存在的。处理这种情况的基本方法就是如图所示,使用GROUP BY子句将集合划分为若干子集。
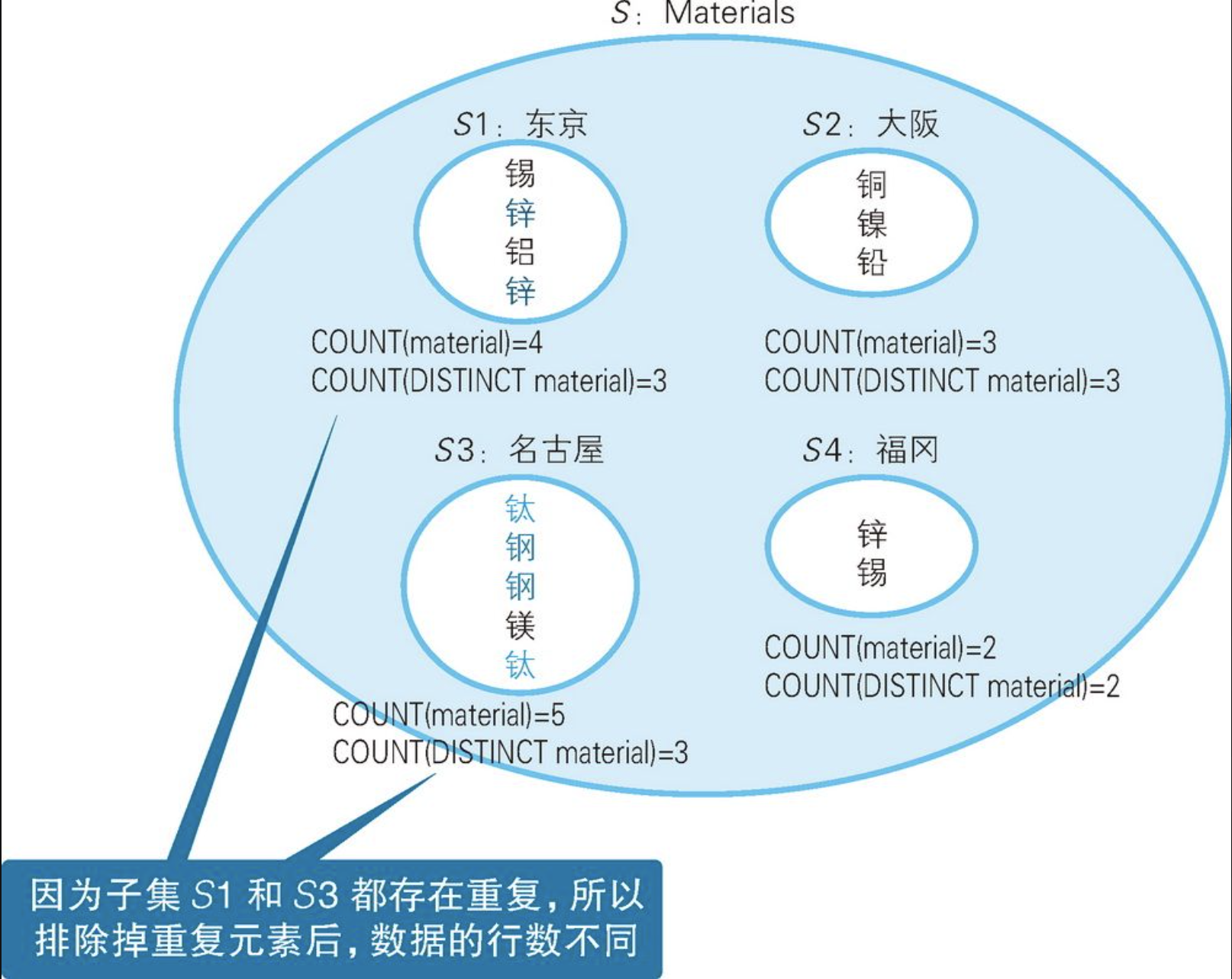
目标集合是锌重复的东京,以及钛和钢重复的名古屋。那么,这两个集合满足而其他集合不满足的条件是什么呢?
这个条件就是"排除掉重复元素后和排除掉重复元素前元素个数不相同"。这是因为,如果不存在重复的元素,不管是否加上DISTINCT可选项,COUNT的结果都是相同的。
sql
-- 选中材料存在重复的生产地
SELECT center
FROM Materials
GROUP BY center
HAVING COUNT(material) <> COUNT(DISTINCT material);
+--------+
| center |
+--------+
| 东京 |
| 名古屋 |
+--------+虽然我们无法通过这条SQL语句知道重复的材料具体是哪一种,但是通过在WHERE子句中加上具体的材料作为参数,可以查出某种材料存在重复的生产地。而且,和前面一样,我们可以把条件移到SELECT子句中,这样就能在结果中清晰地看到各个生产地是否存在重复材料了。
sql
SELECT center, CASE WHEN COUNT(material) <> COUNT(DISTINCT material)
THEN '存在重复'
ELSE '不存在重复'
END AS status
FROM Materials
GROUP BY center;
+--------+------------+
| center | status |
+--------+------------+
| 东京 | 存在重复 |
| 名古屋 | 存在重复 |
| 大阪 | 不存在重复 |
| 福冈 | 不存在重复 |
+--------+------------+对于使用GROUP BY将原来的表划分为子集的思路,大家已经非常习惯了吧。接下来,针对我们一直在使用的"子集",稍微补充一点理论方面的知识。
在数学中,通过GROUP BY生成的子集有一个对应的名字,叫作划分(partition)。它是集合论和群论中的重要概念,指的是将某个集合按照某种规则进行分割后得到的子集。这些子集相互之间没有重复的元素,而且它们的并集就是原来的集合。这样的分割操作被称为划分操作。
SQL中的GROUPBY,其实就是针对集合的划分操作的具体实现。
顺便说一下,这个问题也可以通过将HAVING改写成EXISTS的方式来解决。
sql
-- 存在重复的集合:使用 EXISTS
SELECT center, material
FROM Materials M1
WHERE EXISTS (
SELECT *
FROM Materials M2
WHERE M1.center = M2.center
AND M1.receive_date <> M2.receive_date
AND M1.material = M2.material
);
+--------+----------+
| center | material |
+--------+----------+
| 东京 | 锌 |
| 东京 | 锌 |
| 名古屋 | 钛 |
| 名古屋 | 钢 |
| 名古屋 | 钢 |
| 名古屋 | 钛 |
+--------+----------+用EXISTS改写后的SQL语句也能够查出具体是哪一种材料重复,而且使用EXISTS的性能也很好。相反地,如果想要查出不存在重复材料的生产地有哪些,只需要把EXISTS改写为NOT EXISTS就可以了。
8、用关系除法运算进行购物篮分析
接下来,我们假设有这样两张表:全国连锁折扣店的商品表Items,以及各个店铺的库存管理表ShopItems。这是关系模型中经常见到的表结构。
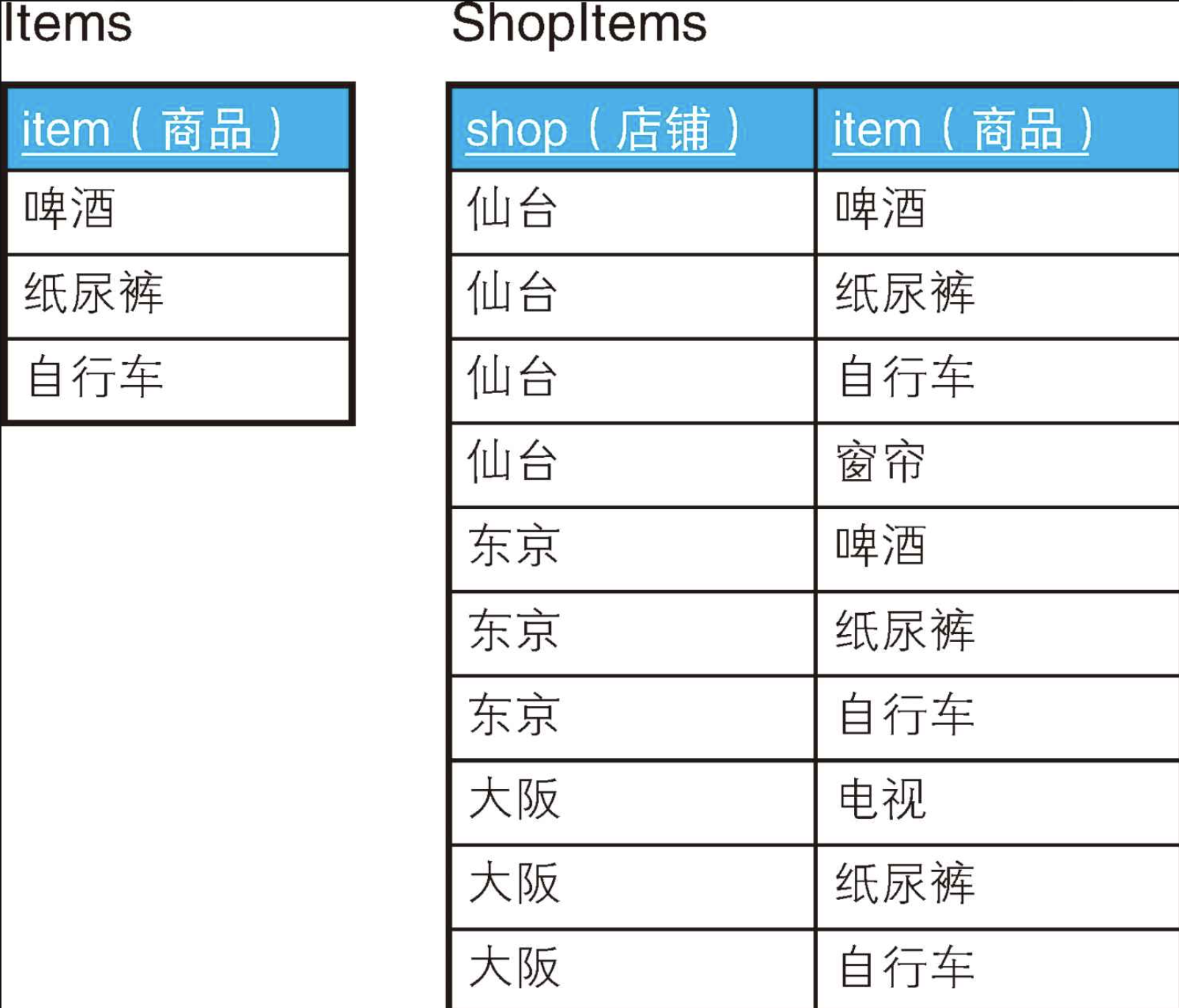
sql
CREATE TABLE Items (
item VARCHAR(16) PRIMARY KEY
);
CREATE TABLE ShopItems (
shop VARCHAR(16),
item VARCHAR(16),
PRIMARY KEY(shop, item)
);
INSERT INTO Items VALUES('啤酒');
INSERT INTO Items VALUES('纸尿裤');
INSERT INTO Items VALUES('自行车');
INSERT INTO ShopItems VALUES('仙台', '啤酒');
INSERT INTO ShopItems VALUES('仙台', '纸尿裤');
INSERT INTO ShopItems VALUES('仙台', '自行车');
INSERT INTO ShopItems VALUES('仙台', '窗帘');
INSERT INTO ShopItems VALUES('東京', '啤酒');
INSERT INTO ShopItems VALUES('東京', '纸尿裤');
INSERT INTO ShopItems VALUES('東京', '自行车');
INSERT INTO ShopItems VALUES('大阪', '电视');
INSERT INTO ShopItems VALUES('大阪', '纸尿裤');
INSERT INTO ShopItems VALUES('大阪', '自行车');这次我们要查询的是囊括了表Items中所有商品的店铺。也就是说,要查询的是仙台店和东京店。大阪店没有啤酒,所以不是我们的目标。
这个问题在实际工作中的原型是数据挖掘技术中的"购物篮分析",但是只要改变一下它的形式,就可以把它应用到很多业务场景。例如在医疗领域查询同时服用多种药物的患者,或者从员工技术资料库里查询UNIX和PostgreSQL两者都精通的程序员,等等。
遇到像表ShopItems这种一个实体(在这里是店铺)的信息分散在多行的情况时,仅仅在WHERE子句里通过OR或者IN指定条件是无法得到正确结果的。这是因为,在WHERE子句里指定的条件只对表里的某一行数据有效。
sql
-- 查询啤酒、纸尿裤和自行车同时在库的店铺:错误的 SQL 语句
SELECT DISTINCT shop
FROM ShopItems
WHERE item IN (SELECT item FROM Items);
+------+
| shop |
+------+
| 仙台 |
| 大阪 |
| 東京 |
+------+谓词IN的条件其实只是指定了"店内有啤酒或者纸尿裤或者自行车的店铺",所以店铺只要有这三种商品中的任何一种,就会出现在查询结果里。那么,我们该如何针对多行数据(或者说针对集合)设定查询条件呢?也许大家已经知道了,那就是用HAVING子句来解决这个问题。SQL语句可以像下面这样写。
sql
-- 查询啤酒、纸尿裤和自行车同时在库的店铺:正确的 SQL 语句
SELECT SI.shop
FROM ShopItems SI INNER JOIN Items I
ON SI.item = I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (
SELECT COUNT(item)
FROM Items
);
+------+
| shop |
+------+
| 仙台 |
| 東京 |
+------+HAVING子句的子查询 (SELECT COUNT(item)FROMItems)的返回值是常量3。因此,对商品表和店铺的库存管理表进行连接操作后,结果是3行的店铺会被选中;对没有啤酒的大阪店进行连接操作后的结果是2行,所以大阪店不会被选中;而仙台店因为(仙台,窗帘)的行在表 连接时会被排除掉,所以也会被选中;另外,东京店因为连接后结果是3行,所以当然也会被选中。
然而请注意,如果把HAVING子句改成HAVINGCOUNT(SI.item)=COUNT(I.item),结果就不对了。如果使用这个条件,仙台、东京、大阪这3个店铺都会被选中。这是因为,受到连接操作的影响,COUNT(I.item)的值和表Items原本的行数不一样了。下面的执行结果一目了然。
sql
-- COUNT(I.item)的值已经不一定是 3 了
SELECT SI.shop, COUNT(SI.item), COUNT(I.item)
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP BY SI.shop;
+------+----------------+---------------+
| shop | COUNT(SI.item) | COUNT(I.item) |
+------+----------------+---------------+
| 仙台 | 3 | 3 |
| 大阪 | 2 | 2 |
| 東京 | 3 | 3 |
+------+----------------+---------------+问题解决了。接下来,我们把条件变一下,看看如何排除掉仙台店(仙台店的仓库中存在"窗帘",但商品表里没有"窗帘"),让结果里只出现东京店。这类问题被称为"精确关系除法运算"(exact relational division),即只选择没有剩余商品的店铺 [与此相对,前一个问题被称为"带余除法运算"(division with a remainder)]。解决这个问题,我们需要使用外连接。
sql
-- 精确关系除法运算:使用外连接和 COUNT 函数
SELECT SI.shop
FROM ShopItems SI LEFT OUTER JOIN Items I
ON SI.item=I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item)FROM Items) -- 条件 1
AND COUNT(I.item) = (SELECT COUNT(item)FROM Items);
+------+
| shop |
+------+
| 東京 |
+------+以表ShopItems为主表进行外连接操作后,因为表Items里不存在窗帘和电视,所以连接后相应行的I.item列是NULL。然后,我们就可以使用之前用到的检查学生提交报告日期的COUNT函数的技巧了。条件1会排除掉COUNT(SI.item)= 4的仙台店,条件2会排除掉COUNT(I.item)= 2的大阪店(NULL不会被计数)。
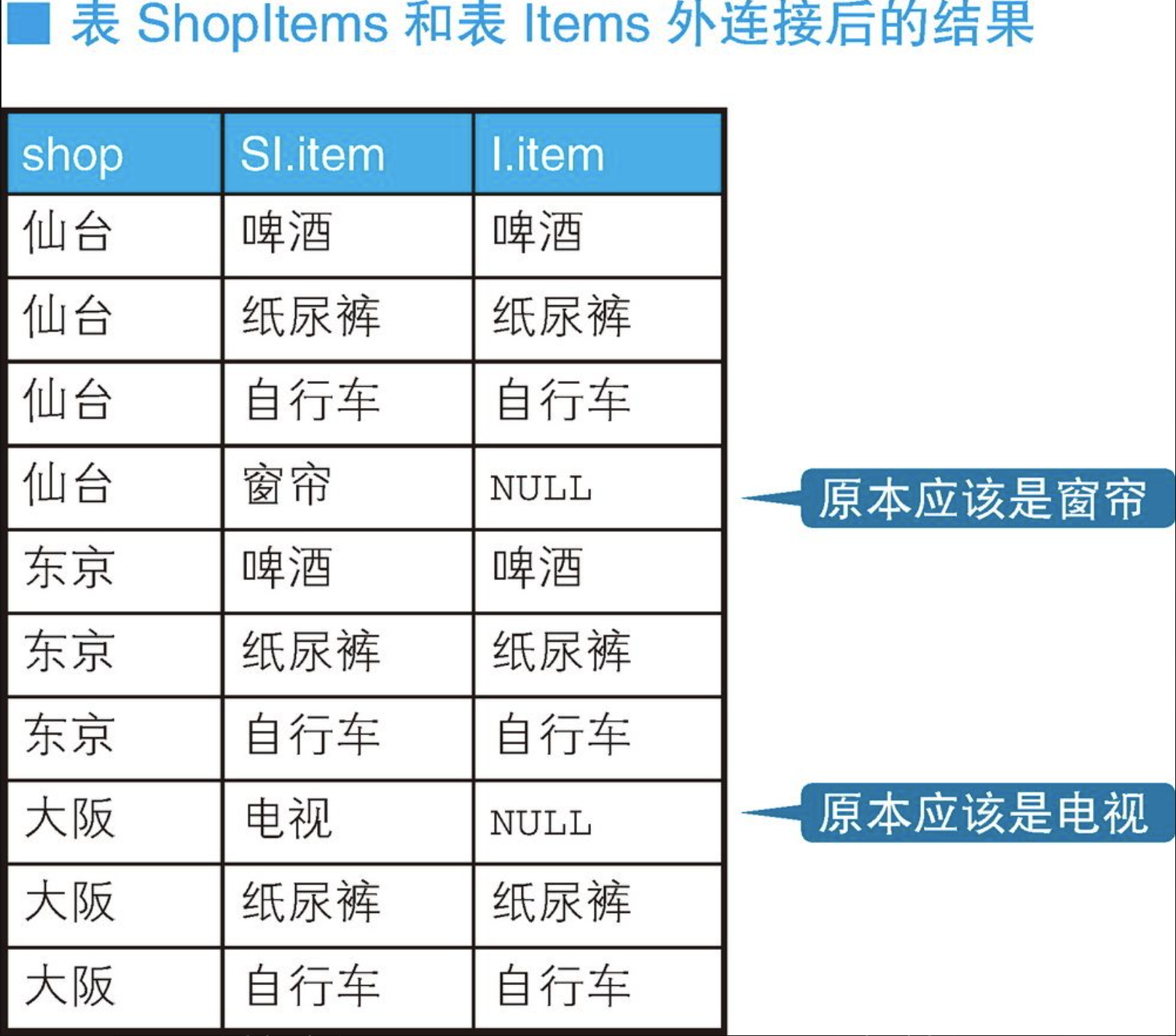
一般来说,涉及外连接时,商品表Items大多会作为主表进行外连接操作,而这里颠倒了一下主从关系,使用了表ShopItems作为主表,这一点比较有趣。
9、总结
用一句话来概括使用HAVING子句时的要点,就是要搞清楚将什么东西抽象成集合。前面我们看过的例题,其实都是把各种各样的实体当作集合来处理了,其中有像数列、班级、队伍这样本身就容易看作集合的实体,也有像店铺、生产地这样本身是原子性元素的实体,这些都被当作集合来处理了。
大家需要理解的是,在SQL中一件东西能否抽象成集合,和它在现实世界中的实际意义无关,只取决于它在表中的存在形式。根据需要,我们可以把实体抽象成集合,也可以把它抽象成集合中的元素。
如果实体对应的是表中的一行数据,那么该实体应该被看作集合中的元素,因此指定查询条件时应该使用WHERE子句。如果实体对应的是表中的多行数据,那么该实体应该被看作集合,因此指定查询条件时应该使用HAVING子句。
最后,我们整理一下在调查集合性质时经常用到的条件。这些条件可以在HAVING子句中使用,也可以通过SELECT子句写在CASE表达式里使用,需要的时候可以参考一下。
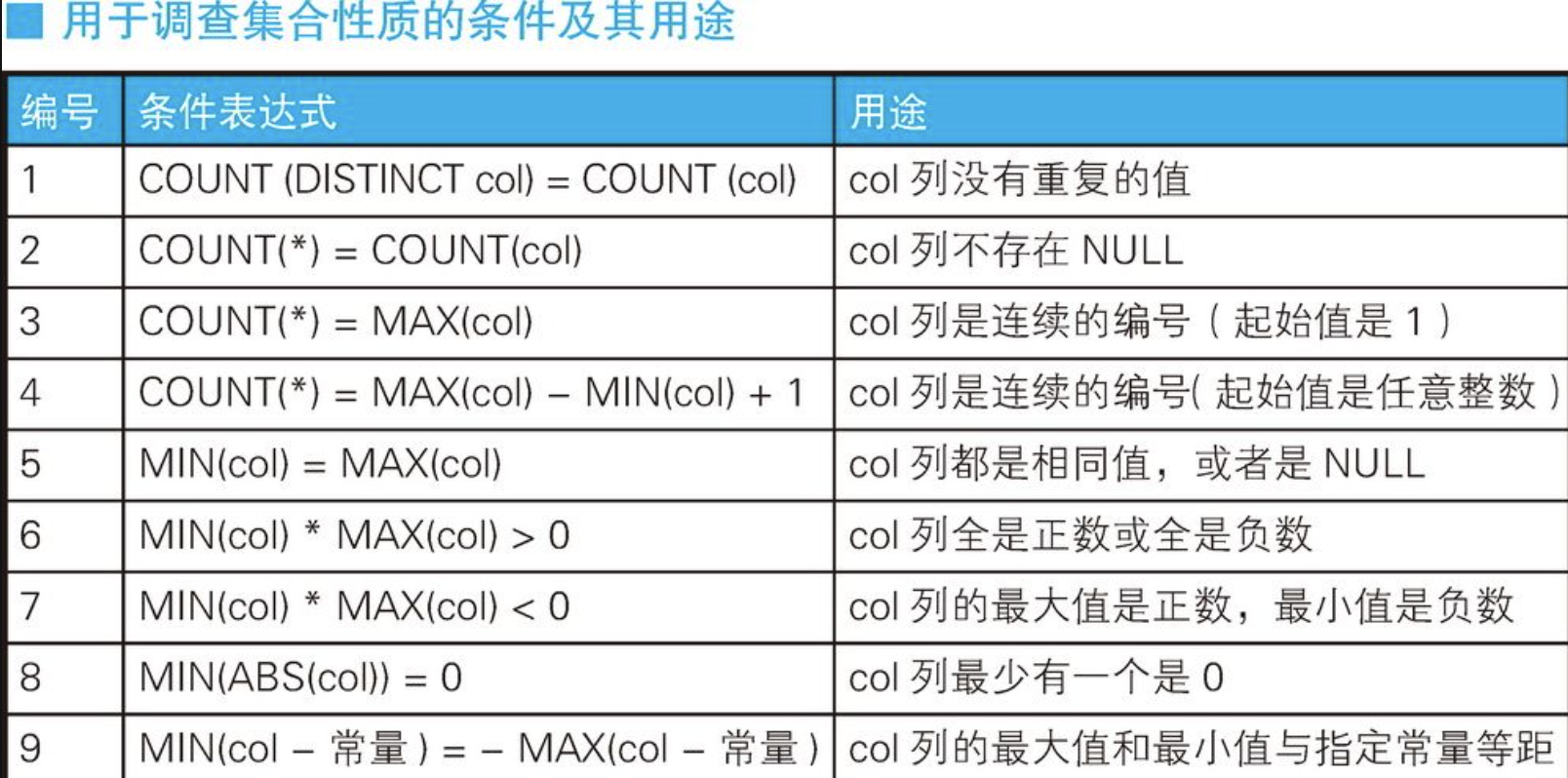
不仅限于这些简单的条件,如果使用CASE表达式来生成特征函数,那么无论多么复杂且通用的条件,我们都可以描述出来,在这里就不再详细解释了。很多人觉得HAVING子句像是影视剧里的配角一样,并没有太多的出场机会,仿佛是一种附属品,从而轻视了它。但是读过本节内容后,相信大家就能明白,HAVING子句其实是非常强大的,它是面向集合语言的一大利器。特别是与CASE表达式或自连接等其他技术结合使用,更能发挥它的威力。