Android 老铁们,只要做客户端,基本都绕不开和后端联调。
一个客户端问题来了,后端说"客户端传参不对",客户端说"接口返回就是这样"。这个时候最有说服力的不是猜,也不是吵,而是马上把当时的请求、返回、状态流转、错误栈翻出来。
所以我专门针对这个场景写了一个 Android 本地日志库:StatLog。
它的核心目标很简单:快。日志库不应该成为业务链路里的性能负担,尤其是金融、支付、交易、风控这类 App,日志既要能持续开,又要能在出问题时快速查,还要能配合 AI 帮我们把日志读明白。
这篇文章不展开接入方式,完整接入代码和参数都放在项目 README 里。这里主要聊 StatLog 的性能、架构,以及 AI LogChat 是怎么围绕本地日志做分析的。
为什么要重新写一个日志库
普通日志方案在小日志量下都没什么问题,但一旦进入高频业务场景,就会遇到几个很实际的问题:
- 写日志不能卡 UI 线程,也不能拖慢交易、支付、风控这类核心链路。
- 日志文件大了以后,不能每次查看都把整个文件读进内存。
- 排查问题时,经常需要倒序看最近日志、按时间查、按级别查、按关键词查、精确统计数量。
- 日志上传不能影响当前正在写入的活跃文件。
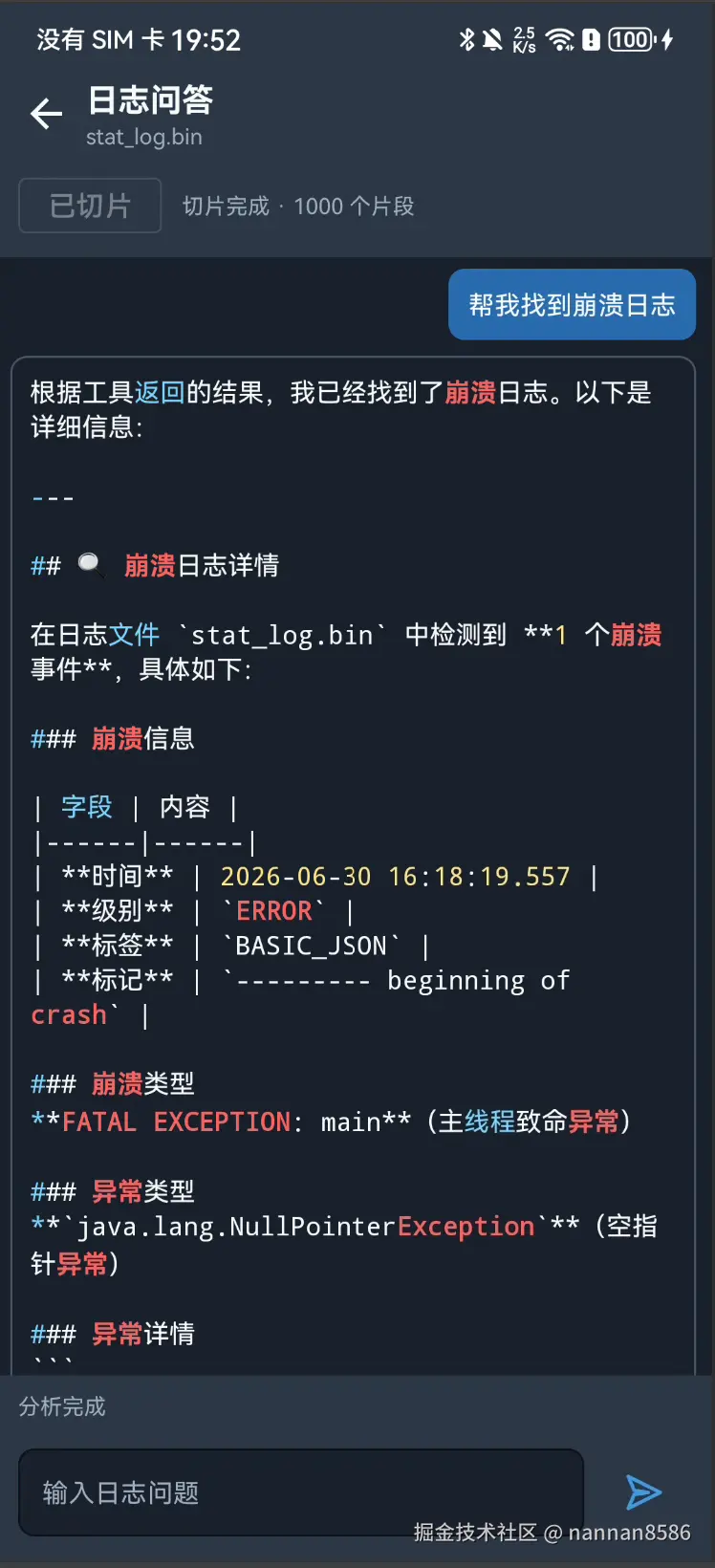
- 用户问"最后一次 login 接口返回的 JSON 是什么"这种问题时,最好能直接让 AI 基于真实日志回答。
StatLog 就是围绕这几个目标设计的:高吞吐写入、快速本地查询、可靠上传、再加一层 AI 排障能力。
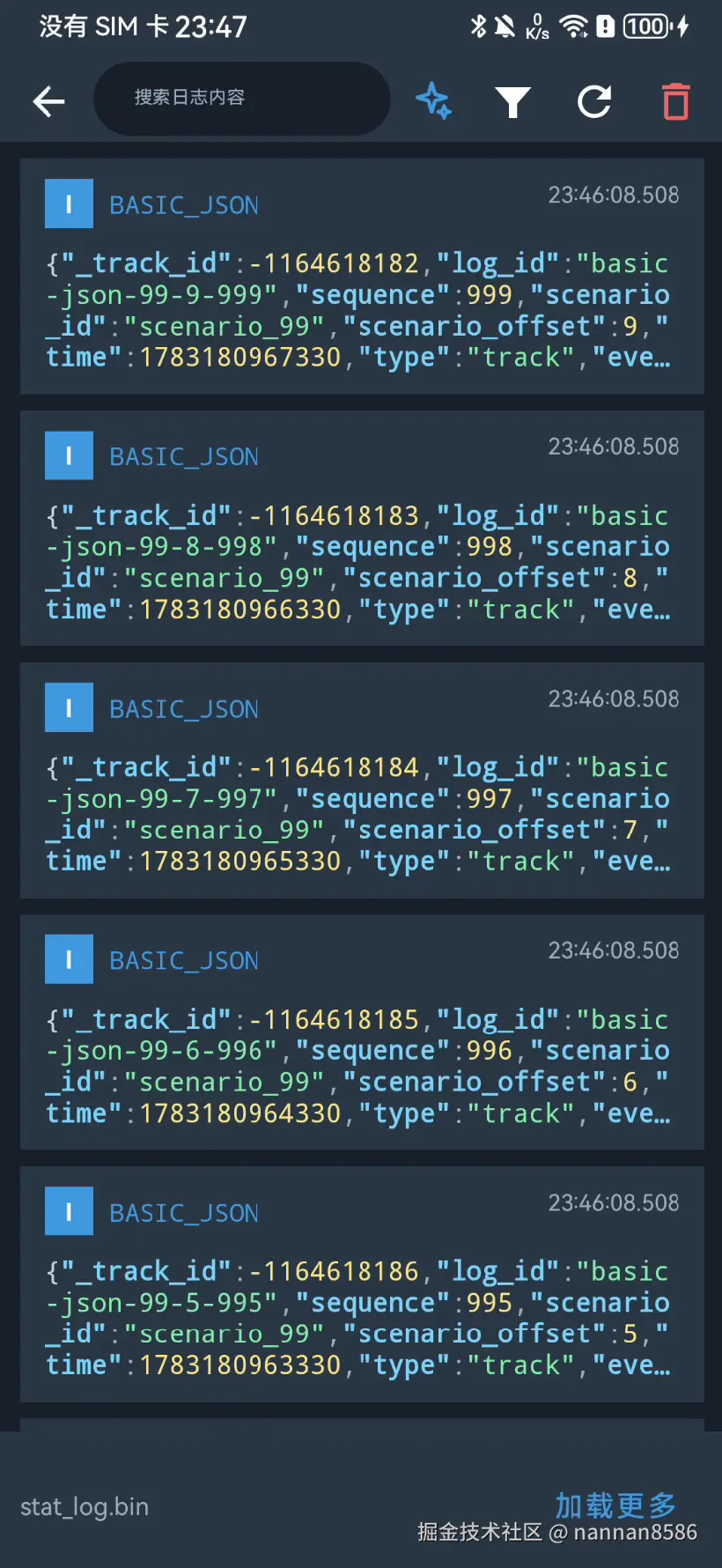
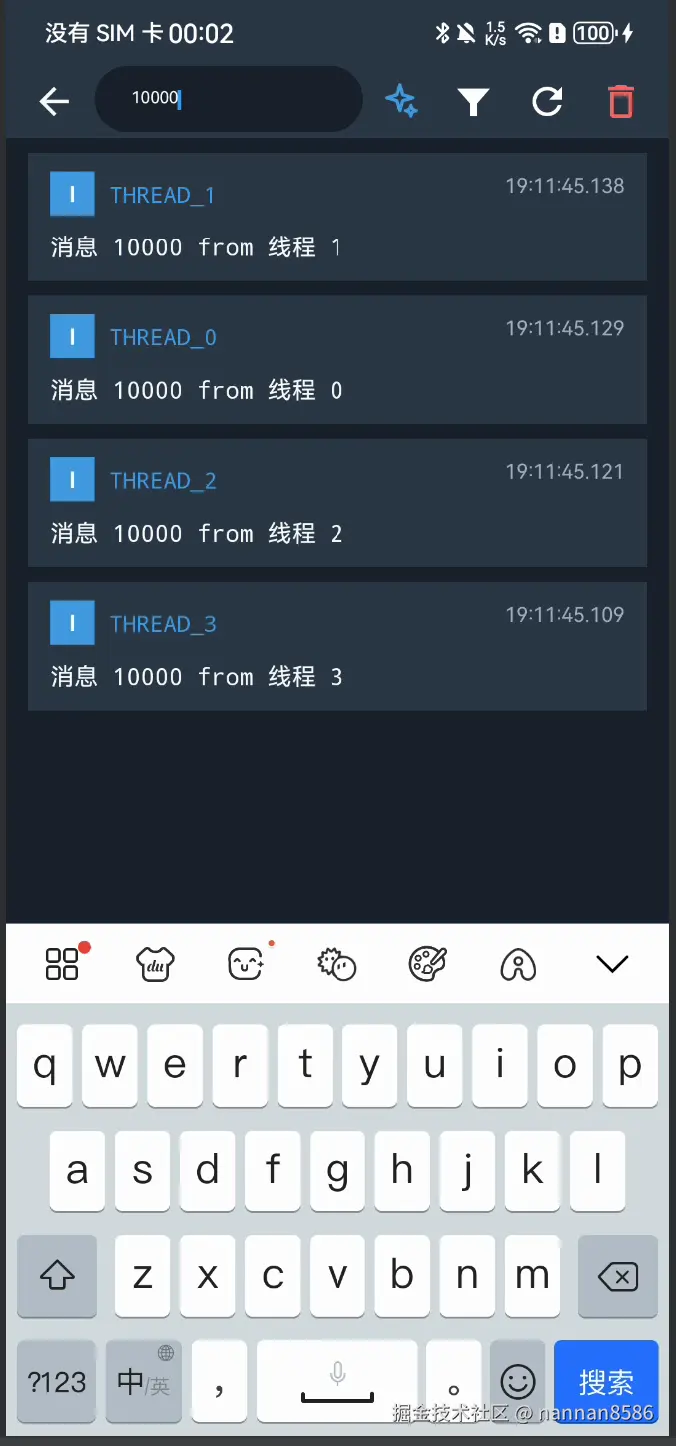
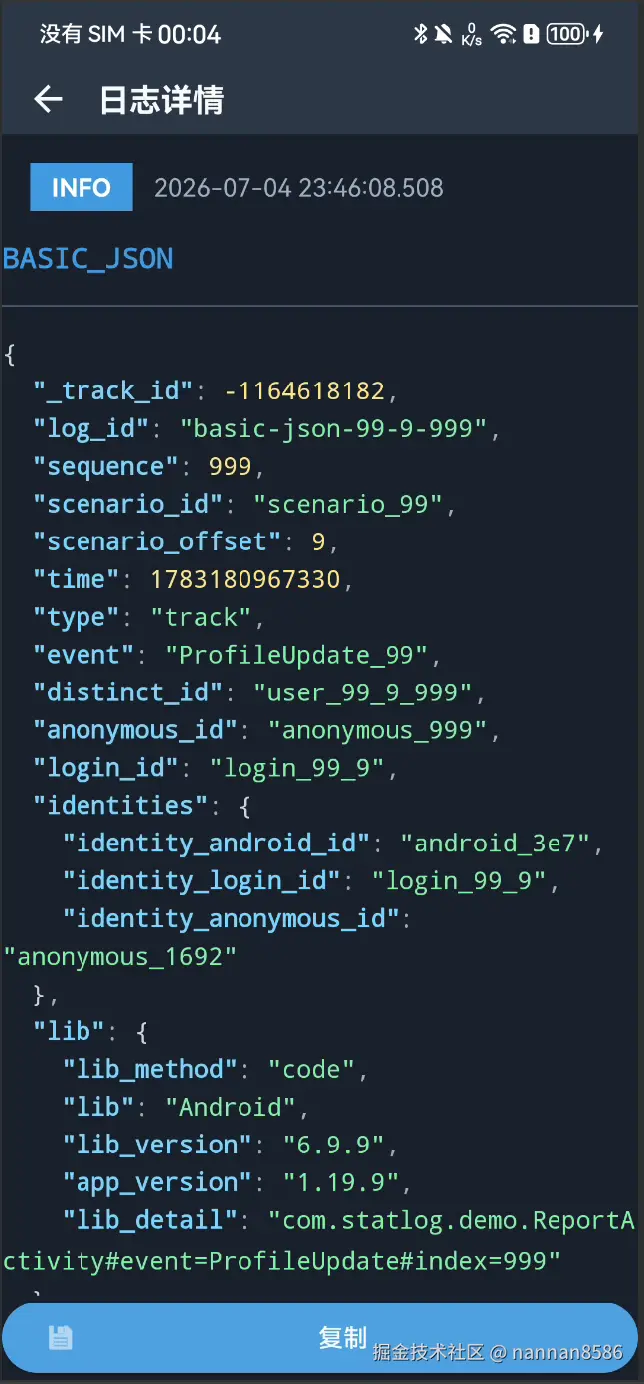
页面截图
 |
 |
|---|---|
 |
 |
|---|---|
AI 使用:我使用的是deepseek的接口,很便宜
 |
 |
|---|---|
性能展示
先看结果。下面这些数据来自项目里的性能控制台和本地压力测试记录,不是通用 benchmark,真实线上表现还要看机型、存储状态、日志长度、索引开关、上传策略等因素。
| 场景 | 测试结果 |
|---|---|
| 基础写入 | 20,000 条,136 ms,约 147k 条/秒 |
| 多线程写入 | 4 线程,20,000 条,100 ms,约 200k 条/秒 |
| 内容校验 | 200,000 条,737 ms,丢失 0 条 |
| 完整压力测试 | 400,000 条,10 线程混合场景,约 1 秒级 |
| 1GB 大文件验证 | 5,360,000 条写入后完整读回,数量匹配 |
| 1GB 读取内存 | 流式读取,记录中读取后内存仅增长约 132 KB |
我最关注的是 40 万条日志这个场景。因为这已经不是"随便打几条 log"的量级了,而是比较接近高频业务、压测、异常追踪时会遇到的日志密度。
在这种场景下,日志库必须把业务线程上的事情做得足够轻,真正重的活放到后台去做。
为什么它写得快
StatLog 的写入链路大概是这样的:
text
业务代码
-> QuantumLogger.log()
-> logChannel
-> processorLoop(s)
-> LogInterceptorChain
-> serializeBatch()
-> batchChannel
-> writerLoop
-> LogWriter
-> .bin
-> LogIndexWriter
-> .qidx / .qmeta这里面几个点比较关键。
第一,业务线程只负责把日志提交进队列,尽量不在业务线程做序列化、写文件、维护索引这些重操作。
第二,后台是批量处理的。日志会先进入 logChannel,由多个 processor 收集、过滤、序列化,再统一交给 writer 写入。批量写入比一条一条写文件稳定得多。
第三,底层写入优先使用 DoubleBufferMmapWriter。MMAP 适合高吞吐连续写,双缓冲可以减少写入阻塞。如果 MMAP 不可用或者出现异常,还会降级到普通文件写入。
第四,热路径做了对象池复用,减少高频日志下的对象分配和 GC 压力。
第五,紧急日志单独处理。比如 crash、支付失败、风控命中这种关键日志,可以走 urgent 路径,绕过普通队列,直接 write + flush + index flush,保证关键证据尽量落盘。
日志架构图
这里插入日志核心架构图:
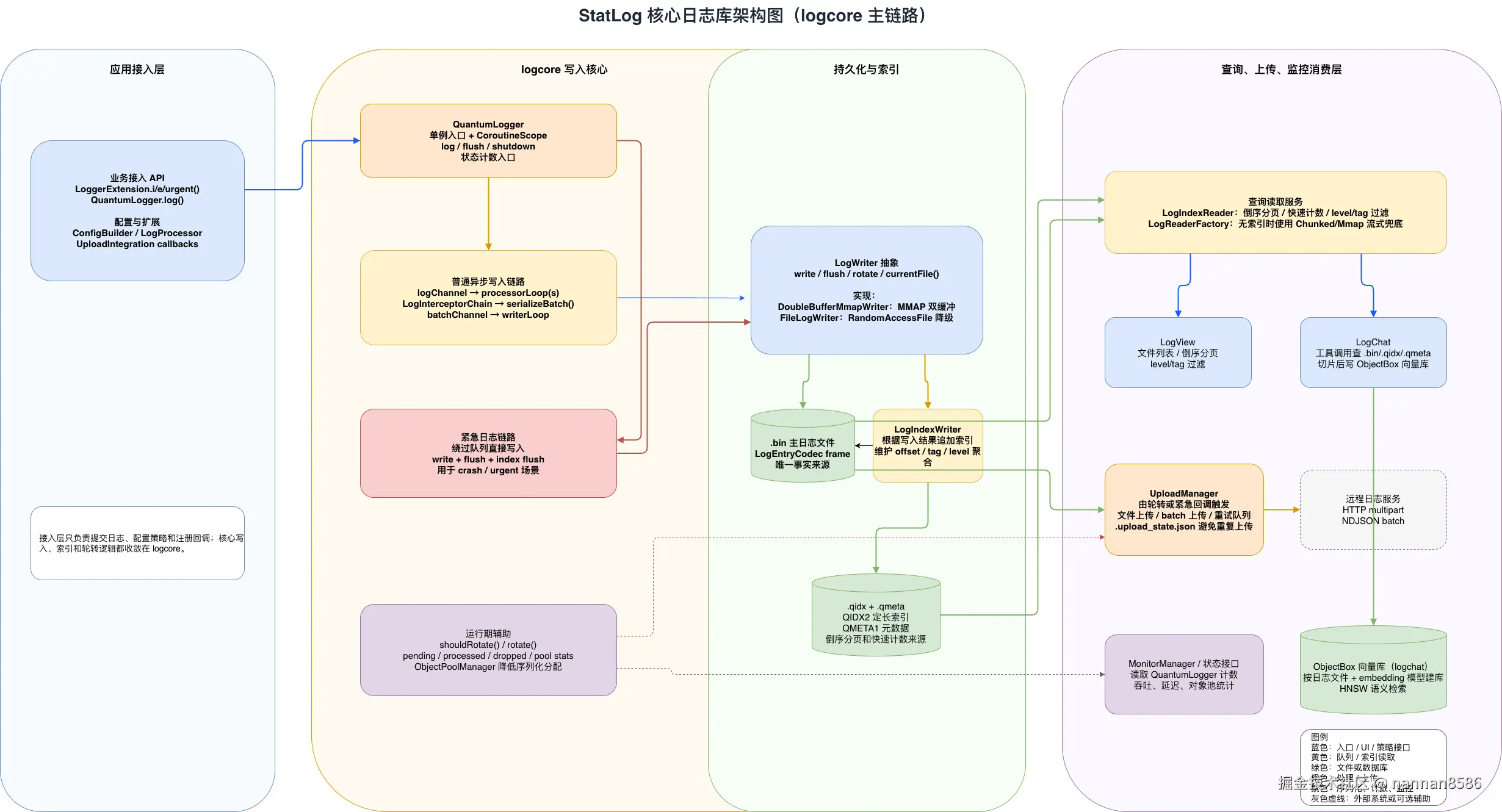
整个项目不是一个单文件 logger,而是拆成了几个模块:
| 模块 | 作用 |
|---|---|
logcore |
核心写入引擎,负责异步管线、二进制编码、MMAP/File 写入、轮转和索引 |
logview |
日志查看页面,支持文件列表、倒序分页、过滤和详情 |
upload |
上传模块,支持轮转后上传、批量上传、重试、网络策略和上传状态 |
monitor |
性能监控模块,记录吞吐、延迟、队列、批次、丢弃和内存指标 |
logchat |
AI 日志问答模块,负责工具调用、向量检索、证据清洗和最终回答 |
sentence_embeddings |
本地 embedding 模型运行时,给 logchat 做日志切片向量化 |
这样的拆分好处是比较清晰:写入、查看、上传、监控、AI 分析互相独立,不需要的模块可以不接。
文件模型
StatLog 的主日志文件是 .bin,它是唯一事实来源。
围绕 .bin,还会有几类辅助文件:
| 文件 | 作用 |
|---|---|
.bin |
主日志文件,保存真实日志内容 |
.qidx |
定长索引,保存 offset、length、timestamp、priority、tagId、urgent 等信息 |
.qmeta |
聚合元数据,保存总数、tag 字典、level 计数、tag + level 组合计数 |
.upload_state.json |
上传状态,配合 .uploaded 位图避免重复上传 |
| ObjectBox 向量库 | logchat 使用,一个日志文件加一个 embedding 模型对应一个向量库目录 |
这里最重要的是 .qidx 和 .qmeta。
如果只靠 .bin,查最近日志就要倒序扫描,统计数量也要重新遍历。文件小还行,文件大了体验会很差。
有了 .qidx 以后,日志查看页面可以根据 offset 和 length 快速定位具体日志内容;有了 .qmeta 以后,总数、level 分布、tag 分布这类统计可以直接读元数据,不需要每次全文件扫描。
所以它不只是"写得快",查看和统计也要快。
上传为什么要和轮转结合
日志上传最怕影响当前写入。
StatLog 推荐默认使用"文件轮转后上传":当前活跃文件继续写,已经轮转出去的旧文件再进入上传流程。这样上传失败、网络波动、服务端慢,都不会直接压到当前写日志的路径上。
如果业务需要更高实时性,也可以按条数做 batch 上传;如果想完全自己控制,也可以只登记状态,业务手动触发上传。
这块设计的核心原则还是一样:日志系统服务业务,但不能反过来拖业务后腿。
AI LogChat 架构图
这里插入 AI LogChat 架构图:
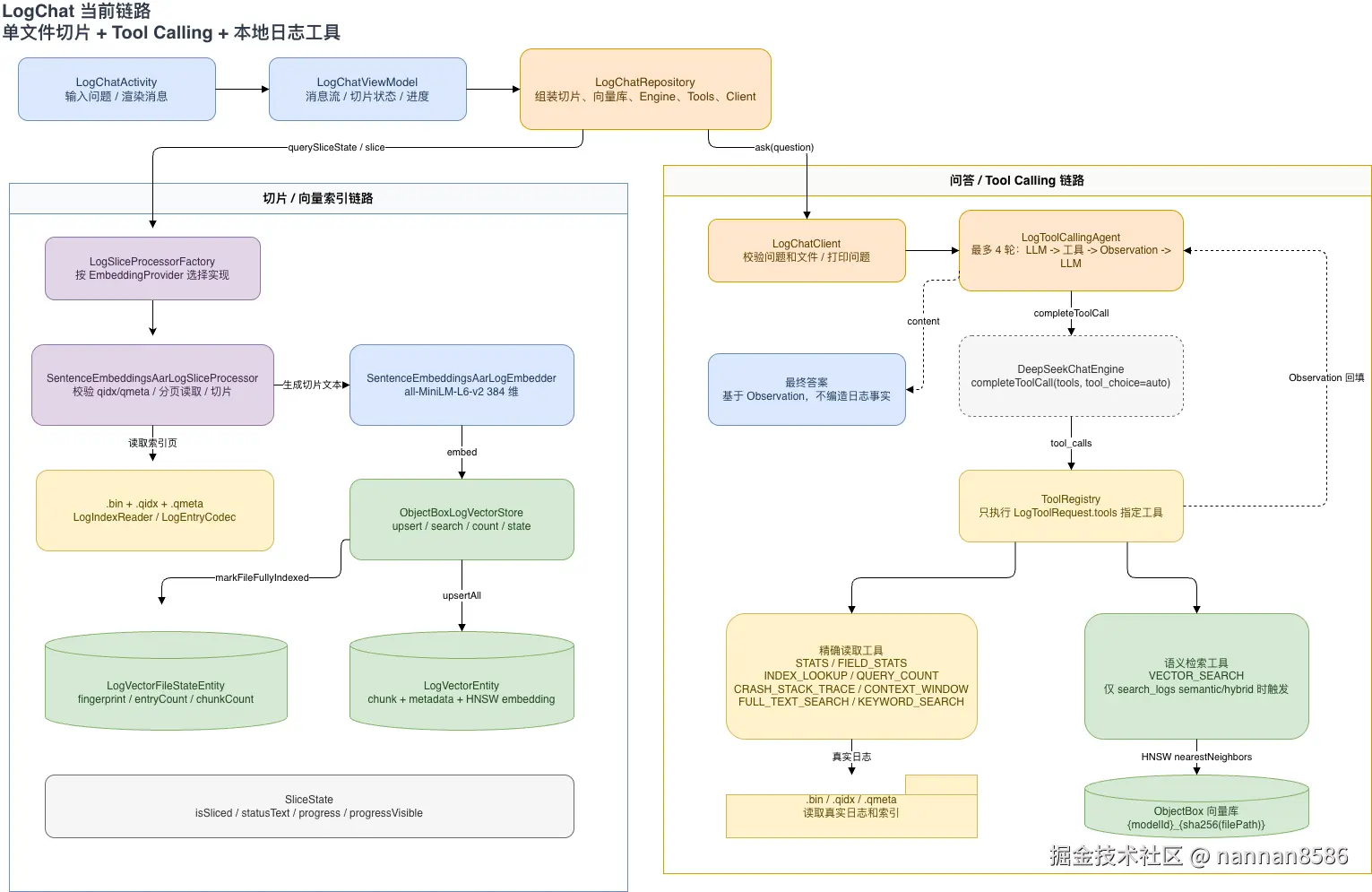 AI 这部分我一开始也走过弯路。
AI 这部分我一开始也走过弯路。
最开始很容易想到:把用户问题向量化,然后去向量库里查相似日志,再丢给大模型回答。
但真实排查日志时,这个方案不够。
因为很多问题不是纯语义相似:
- "一共多少条日志"需要精确计数。
- "下午 3 点到 4 点有哪些 ERROR"需要时间范围和级别过滤。
- "崩溃日志前后各一条"需要先定位崩溃,再拿上下文窗口。
- "最后一次 login 接口返回的 JSON 是什么"需要最新匹配和内容理解。
- "这个 traceId 的完整链路是什么"需要围绕 ID 拉整条链路。
所以现在的 LogChat 走的是 Agent + Tool Calling + 本地工具 + RAG 的闭环:
text
用户问题
-> LogChatClient
-> LogToolCallingAgent
-> 远程大模型 Tool Calling
-> ToolRegistry 执行本地工具
-> 读取 .bin/.qidx/.qmeta/ObjectBox
-> EvidenceCleaner 清洗证据
-> EvidenceReranker 重排证据
-> 大模型基于证据生成最终回答这里大模型不是直接"猜答案",也不是直接操作数据库。它负责理解用户想问什么,并通过 Tool Calling 选择合适的语义工具;真正读日志、查索引、查向量库的动作都在本地执行。
本地工具执行完以后,再把工具结果作为证据交给大模型,让它基于真实日志输出最终答案。
为什么不是把全部日志发给大模型
原因很简单:不安全,也不现实。
日志里可能有设备信息、接口数据、业务字段甚至敏感内容。完整日志文件动不动几十 MB、几百 MB,也不适合直接塞进大模型上下文。
更合理的方式是:
- 本地先通过索引、关键词、时间范围、traceId、JSON 字段、向量库等工具召回候选日志。
- 对候选日志做清洗,去掉重复、噪声和无关上下文。
- 再做重排,把更可能回答问题的证据放前面。
- 最后只把必要证据给大模型。
这样既节省 token,也能减少大模型胡说的概率。
目前 AI LogChat 能做什么
当前本地工具大概覆盖这些方向:
- 索引健康检查
- 总数和精确条件计数
- level 查询
- 时间范围查询
- 关键词和全文搜索
- 最新匹配日志查询
- 上下文窗口查询
- 时间线整理
- crash stack trace 提取
- traceId / sessionId 链路查询
- JSON 字段过滤和字段统计
- ObjectBox HNSW 语义向量检索
比如你可以问:
- "最近一条 crash 是什么?"
- "下午 3 点到 4 点有哪些 ERROR?"
- "最后一次 login 接口返回的 JSON 是什么?"
- "包含 upload failed 的日志有多少条?"
- "把崩溃日志前后各一条列出来。"
这些问题背后用到的查询方式都不一样,所以我没有把它做成一个固定 when 判断,而是尽量让大模型通过 Tool Calling 输出语义计划,本地再执行真实工具。
适合什么场景
我觉得 StatLog 比较适合这几类 App:
- 金融、支付、交易、风控等高频关键链路 App。
- 需要线上问题快速定位的业务 App。
- 需要本地大日志查看和过滤的工具型 App。
- 需要日志上传、重试和状态管理的 App。
- 想把 AI 引入日志排障,但又不想把完整日志直接发给大模型的场景。
如果只是 Demo 项目,或者一天只打几十条日志,那普通日志方案就够了。
但如果你的 App 里日志真的很多,而且日志就是排查问题的核心证据,那日志库本身就值得认真设计。
总结
StatLog 做这件事的核心思路其实就三点:
第一,写入要快。业务线程只做轻量提交,后台批量处理,底层用 MMAP 和降级文件写入兜底。
第二,查询要快。.bin 保存事实,.qidx/.qmeta 提供快速索引和统计能力,大文件读取走流式扫描。
第三,AI 要基于证据。大模型负责理解问题和生成答案,本地工具负责查真实日志,中间再做证据清洗和重排。
这样日志库就不只是"打 log",而是从写入、查看、上传、监控到 AI 排障的一整套链路。
完整接入方式、参数说明和架构图我都放在 README 里了,本文就不重复贴代码了。
源码:github:github.com/nannan111/s...
欢迎找我交流或者定制