一、常见事故案例分析
有个订单服务,跑在 Kubernetes 里,Pod limit 给了 4Gi,JVM 参数写得看起来很稳:-Xms2g -Xmx2g。平时没事,大促流量上来 15 分钟后,Pod 开始反复 OOMKilled。
最容易误导人的地方在这里:Heap dump 显示堆只用了 60% 多,GC 日志也没有长时间 Full GC。研发第一反应是"堆没满,怎么会 OOM?" 但从 kubelet 和 Linux 的视角看,容器 RSS 已经贴着 4Gi limit 走了。
| 内存项 | 大致占用 | 为什么容易被忽略 |
|---|---|---|
| Java Heap | 约 1.8Gi | 大家都会盯它,但它不是全部 |
| Direct Buffer | 约 500Mi | Netty/WebClient/IO 密集服务常见 |
| Thread Stack | 600~800Mi | 线程数一多,每个线程都要栈空间 |
| Metaspace/CodeCache | 200~400Mi | 框架、代理、动态类都会吃 |
| JVM Native/GC/Internal | 200Mi+ | NMT 不开时很难直观看到 |

二、K8s 中的 Java 内存管理存在三层机制
裸机上调 JVM,很多人习惯从 Heap、GC、线程栈开始看;到了 Kubernetes,账本变成三层:JVM 自己的账、Linux cgroup 的账、Kubernetes 编排层的账。线上排查最怕只看其中一层。
| 视角 | 它关心什么 | 典型误判 |
|---|---|---|
| JVM | Heap、Metaspace、Direct、线程栈、GC | Heap 没满就以为没内存问题 |
| Linux/cgroup | memory.current、RSS、page cache、OOM killer | 看到 working set 高却不知道谁贡献的 |
| Kubernetes | requests、limits、QoS、重启、HPA、滚动发布 | 只改参数,不看发布时副本叠加 |

三、别把 -Xmx 设到 limit 的 80% 就完事
有些团队喜欢套公式:limit 4Gi,Xmx 设 3Gi;limit 8Gi,Xmx 设 6Gi。这个公式在简单 Spring MVC 服务上可能过得去,但到 Netty、WebClient、gRPC、消息消费、导出任务、RAG/Agent 调用这种服务上,很容易把堆外和线程栈挤没。
建议采用逆向计算方法:在容器限制的总内存中,需要先预留 Direct Memory、线程栈、Metaspace、CodeCache、GC/本地内存、日志缓冲区以及监控代理等组件所需的空间,最后剩余的部分才可用于设置 Xmx 参数值。
# 一个更保守的启动示例,不是银弹
JAVA_TOOL_OPTIONS="\
-Xms1800m -Xmx1800m \
-XX:MaxDirectMemorySize=512m \
-XX:MaxMetaspaceSize=256m \
-Xss512k \
-XX:+ExitOnOutOfMemoryError \
-XX:NativeMemoryTracking=summary"四、线程数量往往是隐藏的性能瓶颈
许多因 OOMKilled 终止的服务,其根源往往不是内存泄漏,而是线程数量失控。常见的线程来源包括:Tomcat 线程、业务线程池、定时任务、WebClient/Netty 事件循环、消息消费线程以及监控 SDK 线程。这些线程叠加起来,在业务高峰期达到数百个线程的情况并不少见。
如果 -Xss 还是默认 1Mi,700 个线程理论上就可能吃掉 700Mi 左右栈空间。它不会出现在 Heap 使用率里,但会出现在容器 RSS 里。
# 看 Java 进程线程数
ps -eLf | grep java | wc -l
# 看线程栈和阻塞点
jstack <pid> | less
# Linux 侧观察线程上下文切换
pidstat -t -p <pid> 1五、Direct Memory 需要设置独立边界
如果服务使用了 Netty、WebClient、gRPC、Elasticsearch client 或 Kafka client 等技术组件,基本上都会涉及 Direct Buffer 的使用。它的风险在于:虽然应用堆内存看似未满,GC 表现也正常,但堆外内存可能已耗尽容器资源限制。
建议采取两项关键措施:
- 务必显式配置 MaxDirectMemorySize 参数
- 将网络客户端的连接池设置、并发规模、响应体限制与超时机制进行联动优化
单纯调高 limit 参数只会延迟问题爆发,无法从根本上解决问题。
# 打开 NMT 后查看 native memory 摘要
jcmd <pid> VM.native_memory summary
# 看容器 cgroup 内存
cat /sys/fs/cgroup/memory.current # cgroup v2
cat /sys/fs/cgroup/memory/memory.usage_in_bytes # cgroup v1六、requests 和 limits 不是摆设
requests 控制资源分配和调度,limits 设置资源使用上限。Java 服务常见的配置误区包括:**requests 设置过低而 limits 过高,表面上节省资源,但在节点资源紧张时会导致容器间相互干扰;**或者 limits 设置过于严格,在滚动更新期间新旧 Pod 同时运行时会因内存峰值不足而被强制终止。
| 配置 | 建议 | 原因 |
|---|---|---|
| requests.memory | 接近稳定工作集,而不是随便写 512Mi | 调度器需要知道真实占用 |
| limits.memory | 给 Heap 之外留足余量 | OOM killer 看的是容器总内存 |
| Xmx | 通常低于 limit 的 50%~70% | 取决于堆外、线程和框架开销 |
| 滚动发布 | maxSurge/maxUnavailable 要看节点余量 | 发布期副本叠加会放大内存峰值 |
七、排查问题时应避免直接修改参数
合理的排查顺序应为:首先明确是容器 OOM 还是 JVM OOM,其次判断具体发生在 Heap、Direct Memory、线程栈、Metaspace 还是 Native 层面。若未经证实就盲目调整 Xmx 参数,很可能将偶发的 OOM 问题转化为频繁的 GC 抖动问题。
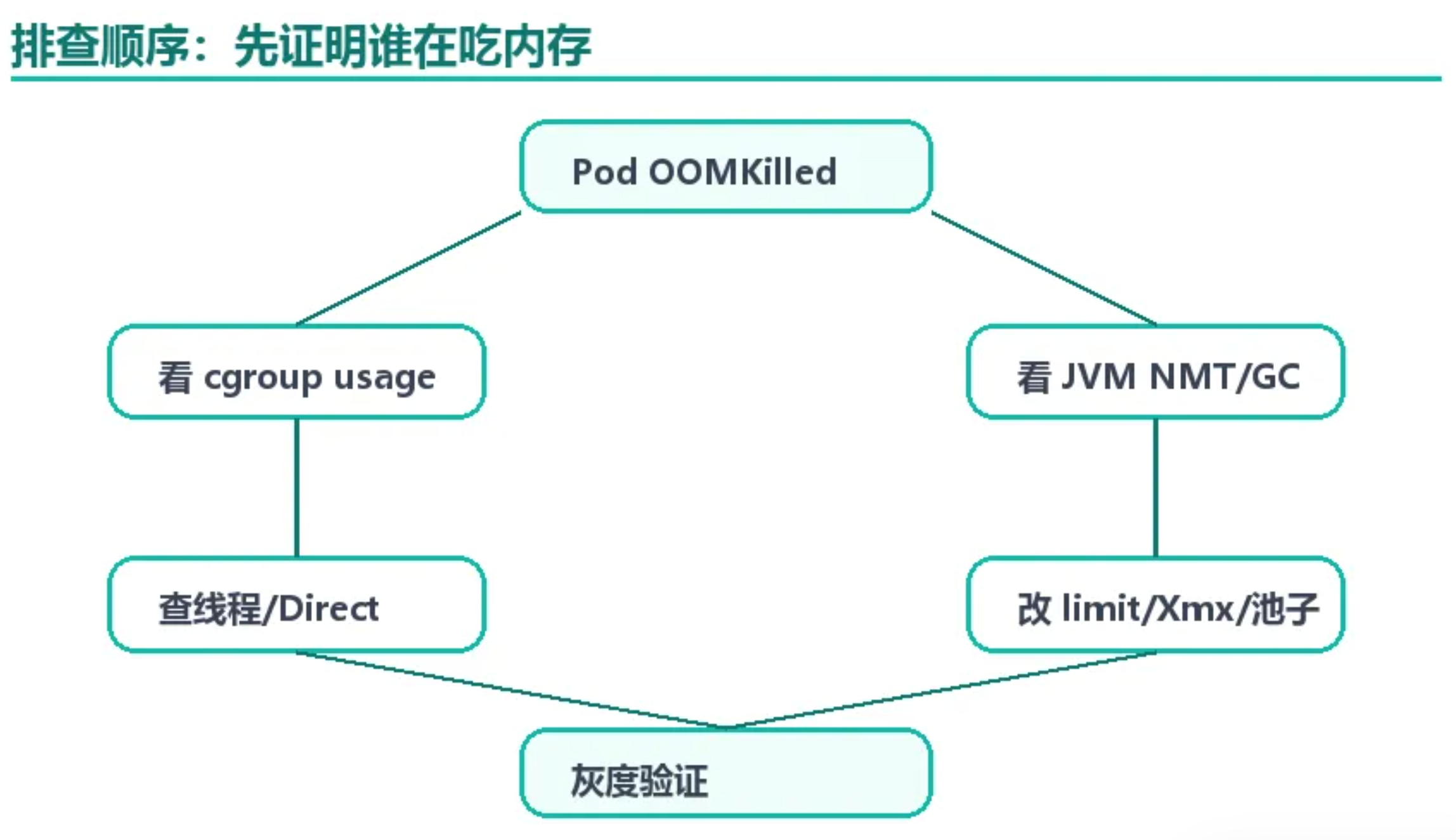
kubectl describe pod <pod> | egrep -i "oom|killed|reason|exit"
kubectl top pod <pod> --containers
# JVM 侧
jcmd <pid> VM.flags
jcmd <pid> GC.heap_info
jcmd <pid> VM.native_memory summary
# 容器侧
cat /sys/fs/cgroup/memory.current
cat /sys/fs/cgroup/memory.max八、一套切实可行的实施方案
为 Spring Boot 3 服务制定容器化基线时,建议采用以下方案:**合理设置内存限制,避免将 Xmx 配置得过于接近上限;****明确指定 Direct 和 Metaspace 的内存上限;****为所有线程池命名并设置合理的队列长度;****在灰度环境中启用 Native Memory Tracking (NMT) 功能;**为核心服务部署内存使用明细监控面板。
resources:
requests:
cpu: "1"
memory: "3Gi"
limits:
cpu: "2"
memory: "4Gi"
env:
- name: JAVA_TOOL_OPTIONS
value: >-
-Xms1800m -Xmx1800m
-XX:MaxDirectMemorySize=512m
-XX:MaxMetaspaceSize=256m
-Xss512k
-XX:+ExitOnOutOfMemoryError九、检查清单
| 检查项 | 命令/指标 | 判断 |
|---|---|---|
| Pod 是否 OOMKilled | kubectl describe pod | 先确认是不是容器层杀进程 |
| Heap 是否接近上限 | GC heap / actuator / jcmd | Heap 满才考虑堆参数和对象 |
| Direct 是否失控 | NMT / Netty metrics | IO 服务重点看 |
| 线程数是否异常 | ps -eLf / jstack / pidstat | 几百线程要算栈空间 |
| 发布期是否叠加 | rollout strategy / 节点余量 | 只看单 Pod 稳定不够 |
根因分类与解决方案矩阵
| OOM类型 | 特征 | 解决方案 |
| Java堆溢出 | java.lang.OutOfMemoryError: Java heap space | 1. 增大-Xmx 2. 分析内存泄漏代码 3. 优化数据缓存策略 |
| 元空间溢出 | java.lang.OutOfMemoryError: Metaspace | 1. 增加-XX:MaxMetaspaceSize 2. 检查类加载器泄漏 |
| 直接内存溢出 | java.lang.OutOfMemoryError: Direct buffer memory | 1. 调整-XX:MaxDirectMemorySize 2. 检查JNI/NIO代码 |
| 容器级OOM | OOMKilled(exit code 137) | 1. 提升容器内存限制 2. 优化JVM非堆内存使用 |
| 线程数超限 | java.lang.OutOfMemoryError: unable to create new native thread | 1. 减少线程池大小 2. 调整-Xss参数降低线程栈内存 |
|---|
小结
在容器环境下进行 JVM 调优,关键不在于记忆大量参数,而是要先理清内存账本。-Xmx 仅定义了堆内存边界,而 Kubernetes 的 OOMKilled 机制监控的是整个容器。必须将堆内存、直接内存、线程栈、元空间、原生开销、资源请求/限制以及滚动发布时的峰值负载等要素统一规划,才能为 Java 服务构建可靠稳定的运行基础。