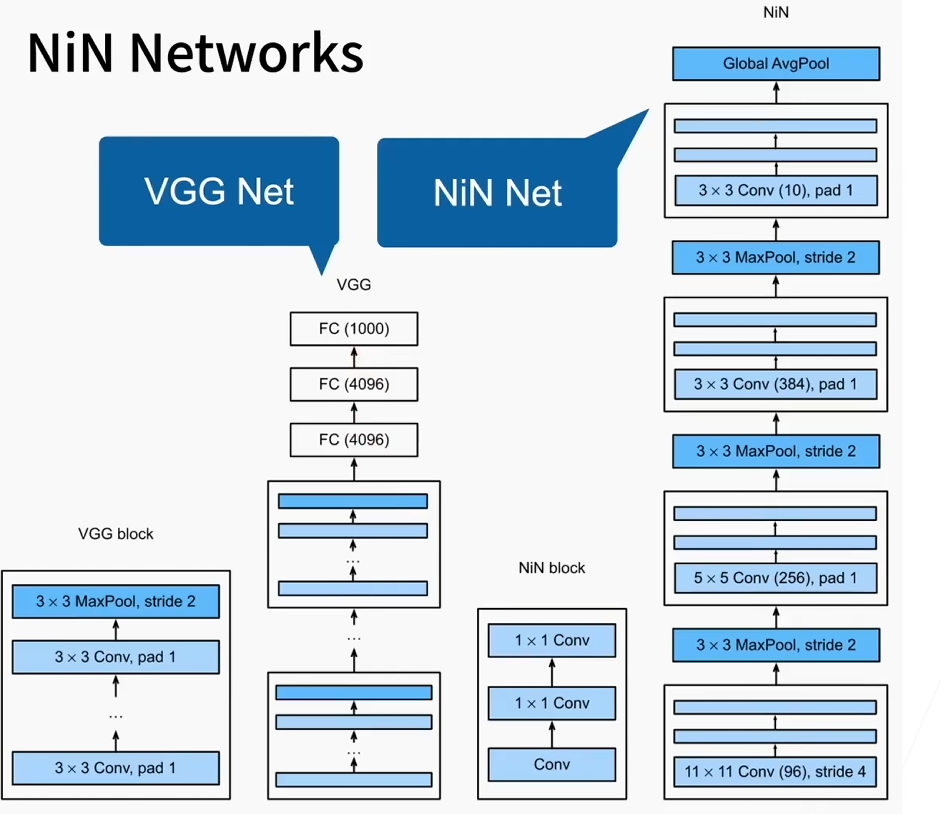
基于架构图的 VGG Net 与 NiN Net 深度分析
这张图清晰对比了VGG 网络 和NiN 网络的核心架构、基础模块设计,直观展现了两种经典 CNN 的设计思路差异,核心围绕「卷积模块设计」「分类头架构」「核心创新点」三个维度展开,以下是完整分析:
一、整体架构核心差异
表格
| 维度 | VGG Net | NiN Net |
|---|---|---|
| 核心设计思路 | 深度优先,通过堆叠统一的 3×3 卷积块构建深度网络,追求极致的特征提取能力 | 非线性优先,通过「卷积 + 1×1 卷积」的 mlpconv 模块增强局部非线性表达,同时简化分类头,轻量化网络 |
| 整体结构 | 「堆叠 VGG 卷积块 + 3 层全连接层」的经典结构,最终输出 1000 类分类结果 | 「堆叠 NiN 卷积块 + 全局平均池化」的全卷积结构,无全连接层,最终输出分类结果 |
| 参数量与效率 | 全连接层占总参数量 90% 以上,网络笨重,推理速度慢,易过拟合 | 无全连接层,参数量仅为 VGG 的几分之一,网络轻量,推理效率高,过拟合风险更低 |
二、基础模块设计对比:VGG Block vs NiN Block
1. VGG Block(VGG 核心基础单元)
图中左侧 VGG Block 的结构为:
plaintext
重复堆叠 3×3 Conv, pad=1 → 最终接 3×3 MaxPool, stride=2- 核心设计逻辑:用多个小尺寸 3×3 卷积核堆叠,替代大尺寸卷积核。2 个 3×3 卷积的感受野等价于 1 个 5×5 卷积,3 个 3×3 卷积等价于 1 个 7×7 卷积,在保证相同感受野的前提下,大幅减少参数量,同时增加网络深度和非线性表达能力。
- 设计特点:模块内卷积层通道数完全一致,结构高度规整,通过池化层完成空间降维,通道数随网络深度逐步翻倍。
2. NiN Block(NiN 核心创新单元)
图中下方 NiN Block 的结构为:
plaintext
基础Conv → 1×1 Conv → 1×1 Conv- 核心设计逻辑:提出 mlpconv(多层感知机卷积)结构,用 1×1 卷积替代传统卷积后的全连接层,在局部感受野内完成多层非线性变换,实现跨通道的特征融合,大幅增强特征的表达能力。
- 设计特点:1×1 卷积是核心创新,既可以完成通道维度的升维 / 降维,又能在不改变空间尺寸的前提下,引入更多非线性激活,这一设计直接影响了后续 GoogLeNet、ResNet 等经典网络的架构设计。
三、分类头设计的本质差异
1. VGG 的全连接层分类头
VGG 在卷积块后接了 3 层全连接层:FC(4096) → FC(4096) → FC(1000)
- 核心问题:
- 参数量爆炸:以 VGG16 为例,第一个全连接层的参数量约为 1 亿,占总参数量的 90% 以上,是网络笨重的核心原因;
- 破坏空间结构:全连接层将 2D 特征图展平为 1D 向量,完全丢失了特征的空间位置信息;
- 易过拟合:大量的全连接层参数极易在小数据集上过拟合,需要配合大量的正则化手段。
2. NiN 的全局平均池化分类头
NiN 完全舍弃了全连接层,直接用Global AvgPool(全局平均池化)作为分类头:
- 核心设计:将最后一个 NiN Block 的输出通道数设置为类别数(图中为 10 类),每个通道对应一个类别,对每个通道的特征图做全局平均池化,直接输出该类别的预测结果。
- 核心优势:
- 零额外参数:全局平均池化无需要学习的参数,彻底解决了全连接层的参数量爆炸问题;
- 保留空间结构:全程保持卷积的 2D 空间结构,更符合 CNN 的平移不变性特性;
- 正则化效果:全局平均池化强制特征图与类别一一对应,降低了过拟合的风险,提升了模型的泛化能力。
四、NiN 的核心创新与行业影响
- 1×1 卷积的普及:NiN 是首个将 1×1 卷积作为核心组件的网络,这一设计后续成为 CNN 的标准操作,广泛用于通道降维、特征融合、增加非线性,是 GoogLeNet 的 Inception 模块、ResNet 的残差模块的核心组成部分。
- 全卷积网络的先河:NiN 首次用全局平均池化替代全连接层,实现了全卷积结构,不仅大幅轻量化了网络,还让网络可以适配任意尺寸的输入图像,摆脱了全连接层对输入尺寸的限制。
- 局部非线性表达的新思路:mlpconv 的设计打破了 "卷积 + 激活" 的传统范式,在局部感受野内引入多层非线性变换,为后续的注意力机制、动态卷积等设计提供了思路参考。
五、两种网络的适用场景与局限性
VGG Net
- 适用场景:对精度要求极高、算力充足的分类任务,以及需要强特征提取能力的迁移学习任务(如图像检索、目标检测的 backbone)。
- 局限性:网络笨重,推理速度慢,部署成本高,全连接层的设计导致过拟合风险高,不适合端侧部署。
NiN Net
- 适用场景:对推理速度、模型大小要求高的场景,如端侧设备、实时分类任务,以及作为轻量化 backbone 用于简单的视觉任务。
- 局限性:网络深度不足,复杂场景下的特征提取能力弱于 VGG;全局平均池化对精细空间信息的利用不足,在细粒度分类任务上的精度上限低于 VGG。
什么是端侧部署
端侧部署 :把训练好的 AI 模型(比如 VGG、NiN 这类神经网络),部署在终端本地设备上运行推理预测,而不是把图片、数据上传到远端云端服务器去计算。
简单区分两种部署方式:
云端部署(云侧) 用户拍照 / 上传图片 → 数据传到远程服务器(机房高性能 GPU 电脑)→ 服务器跑模型计算识别结果 → 再把结果传回手机。 代表场景:大部分网页识图、云端 AI 服务、大型云平台 API 调用。
端侧部署(本地端) AI 模型直接预装在你的设备里,所有识别、计算就在本机硬件上完成,不需要联网上传数据到远程服务器。
为什么 VGG 不适合端侧部署?
参数量太大,占用存储空间高 VGG16 总参数约 1.3 亿,其中末尾三层全连接层就占了 90% 参数,模型文件动辄几百 MB。 手机、嵌入式设备存储空间有限,很难放下超大模型;就算放下,加载速度也极慢。
算力不足,推理速度很慢 端侧设备大多只有 CPU、低端 NPU,没有云端的高性能 GPU。 VGG 大量卷积 + 巨型全连接层计算量极高,一张图片可能要几秒甚至十几秒才能识别,达不到实时使用要求(比如人脸识别需要毫秒级出结果)。
功耗高、发热严重 复杂计算会让手机、嵌入式芯片高负载运行,设备快速发热、耗电快,无法长时间稳定工作。
端侧部署的核心优势(也是为什么优先用轻量化网络 NiN、MobileNet 等)
- 隐私安全:数据不上传云端,照片、人脸等敏感信息只在本地处理,不会泄露;
- 低延迟实时性:不用网络传输,本地毫秒级出结果,人脸识别、实时视频检测必须端侧;
- 断网可用:没有 Wi‑Fi、流量也能正常使用 AI 功能;
- 节约成本:不需要租用云端服务器算力,大批量智能硬件场景可以大幅降低运营费用。
举几个生活里典型的端侧 AI 例子
- 手机相册本地人脸分组、照片场景分类,不用联网就能识别;
- 门禁、小区摄像头人脸识别开门,断网也能正常工作;
- 相机实时美颜、物体识别、文档拍照矫正;
- 智能手表心率异常本地检测、车载自动驾驶感知小模型
端侧部署 VS 云端部署 优缺点对比表
| 对比维度 | 端侧部署(本地部署) | 云端部署(服务器部署) |
|---|---|---|
| 运行位置 | 模型在用户本地终端设备(手机、摄像头、树莓派、车载硬件等)本地运算 | 模型部署在远端机房的 GPU 服务器,数据通过网络上传到服务器运算 |
| 网络依赖 | ✅ 可离线运行,断网也能正常推理 | ❌ 必须依赖稳定网络,无网无法使用 |
| 数据隐私 | 原始图片、人脸等敏感数据只在本地处理,不上传,隐私安全性极高 | 原始数据需要上传云端服务器,存在数据泄露、被采集的风险 |
| 推理延迟 | ✅ 低延迟,本地毫秒级出结果,无网络传输耗时 | ❌ 存在网络传输耗时,高峰期容易卡顿、响应慢 |
| 硬件算力 | 受限于终端弱算力(手机 CPU/NPU、嵌入式低功耗芯片),只能跑轻量化小模型 | 拥有高性能 GPU 集群,可运行 VGG、大模型等超大网络,算力上限高 |
| 部署成本 | 一次性硬件适配成本,后期几乎无服务器使用费;设备越多,边际成本越低 | 需要长期租赁服务器、带宽,用户量越大,云服务计费越高 |
| 模型更新 | 需要推送固件 / APP 版本升级才能更新模型,迭代麻烦 | 后台直接更新服务器模型,用户无感升级,迭代便捷 |
| 功耗与发热 | 大模型会导致设备高负载、发热、耗电快,因此一般只用轻量化网络 | 算力压力在云端服务器,终端仅负责上传接收数据,设备功耗很低 |
优缺点总结
端侧部署
✅ 优点:
- 隐私安全、可离线使用、实时低延迟;
- 大批量硬件场景长期运营成本更低;
- 不会因为网络波动导致服务不可用。
❌ 缺点:
- 终端算力有限,无法运行 VGG 这类大参数量模型;
- 模型迭代、版本更新流程繁琐;
- 对模型压缩、轻量化优化技术要求高。
云端部署
✅ 优点:
- 算力充足,可部署高精度大模型,算法迭代简单快捷;
- 终端硬件压力小,普通低配设备也能使用 AI 能力;
- 集中式运维,方便统一管理、监控服务状态。
❌ 缺点:
- 依赖网络,存在网络延迟、掉线、带宽限流问题;
- 敏感数据上传存在隐私泄露风险;
- 海量用户场景下,服务器、带宽开销会持续增加。
适用场景推荐
适合端侧部署
人脸识别门禁、手机本地相册识别、车载感知、无人机实时检测、离线 AI 工具、智能家居本地识别。
适合云端部署
在线 AI 绘图、云端大语言模型、全网图片检索、大数据批量分析、高精度医疗影像识别。