音视频「数据本质」的绝妙镜像
🎯 音视频底层世界终极对照表(Final Edition)
| 维度 (Dimension) | 音频世界 (Audio World) | 视频世界 (Video World) |
|---|---|---|
| 内核驱动子系统 | ALSA (/dev/snd/pcm*) 字符设备,应用层通过 mmap 或 read/write 拉取 DMA 数据。 |
V4L2 (/dev/video*) 字符设备,基于 videobuf2 (vb2) 框架管理缓冲区。 |
| 有损压缩格式 | AAC / MP3 / OPUS 利用心理声学模型去除人耳不敏感的频域冗余。 | H.264 / H.265 / AV1 利用运动估计与帧间预测去除时间与空间上的视觉冗余。 |
| 帧内编码格式 (修正:原"无损/帧内") | FLAC / ALAC 真正无损压缩,帧内独立解码,不依赖历史数据。 | MJPEG / ProRes / FFV1 (注:常规 MJPEG 有损,ProRes 近无损,FFV1 无损) 共同点是仅依赖当前帧内空间,无帧间参考链。 |
| 裸数据数学结构 | 一维时间序列 (1D Time Series) 只有时间轴 t。多声道数据在数组中交错排列(Interleaved),空间概念极弱。 |
二维/三维空间矩阵 (2D/3D Spatial Matrix) 明确的 Width × Height × Channel 空间拓扑。时间轴被解耦为离散的"帧序号"。 |
| 裸数据"硬通货" | PCM (脉冲编码调制) 采样点数值(如 s16le),直接反映声波振幅随时间的变化。 |
Raw Pixels (YUV/NV12/RGB) 像素分量值,直接反映光强与色度在平面上的空间分布。 |
| 典型吞吐量级 | ≈ 1.4 Mbps (CD 品质) 数据量极小,内存带宽毫无压力,L1/L2 Cache 轻松容纳。 | ≈ 1.5 Gbps (1080p@60fps) 恐怖的数据洪流,现代 SoC 内存带宽的"杀手级"消费者。 |
| 内核内存流转机制 | 环形缓冲区 (Ring Buffer) 依赖 snd_pcm_hardware 的 periods 轮转。中断频繁,CPU 主动参与 memcpy 搬运数据是常态。 |
队列式缓存池 (Buffer Queue) 依赖 vb2 与 dma-buf。 工业级强制零拷贝 (Zero-Copy):驱动层只传递文件描述符(fd)指针,严禁应用层做 CPU 内存拷贝(否则 ARM 直接跑崩)。 |
| 纯裸数据处理器 (基带/空间变换) | 音频 DSP 引擎库 (如 libsamplerate, speexdsp, LADSPA) 执行重采样、混音、EQ。纯 CPU 密集型,强时域/频域实时计算。 |
像素处理与滤镜库 (如 FFmpeg libswscale, libavfilter) 执行色彩空间转换 (CSC)、缩放、卷积滤波。 强依赖硬件加速器 (RGA/VPU/GPU),CPU 只做配置,不做像素级运算。 |
| 上层高阶框架 (业务路由 vs 算法应用) | PipeWire / PulseAudio 解决跨进程音频流的全局动态路由与策略控制(就像音频的"交换机")。 | OpenCV / RKNN / CUDA 在拿到像素矩阵后,执行不规则的计算机视觉算法与 AI 推理(物体检测、分类)。 |
| 核心实时性特征 | 延迟敏感型 (Latency-Sensitive) 追求内核 SCHED_FIFO 低延迟调度。绝不能断流 (Underrun),否则 DAC 饥饿,瞬间引发"咔哒"爆音。 |
吞吐/结构敏感型 (Throughput-Sensitive) 对几百毫秒延迟相对宽容。 强依赖 GOP 结构完整性:丢参考帧将引发画面劣化(花屏/卡顿),直至下一个关键帧 (I帧) 到来才能恢复。 |
| ✨ 时间基准物理意义 (新增封神维度) | 绝对物理时间轴 (Continuous) 采样率(如 48kHz)由晶振 PLL 锁相。PCM 时间戳必须严格线性递增,驱动按物理时钟吞吐数据。 | 离散逻辑时间轴 (Discrete) PTS/DTS 仅用于帧间排序与同步。允许轻微抖动 (Jitter),系统不关心物理时间的均匀流逝,只关心"这一帧该在哪个序号显示"。 |
GStreamer / PipeWire / V4L2 / ALSA 解决的是"怎么把这管道接通,把数据安全、准时地运过去"的问题;而 OpenCV 和 音频DSP 解决的是"数据运到了,我现在要在里面大刀阔斧改写字节,实现业务逻辑"的问题。 抓住了"纯粹音视频数据字节流"这个本质,无论是调音频驱动还是写视觉算法,底层逻辑全通了。
典型的音频栈
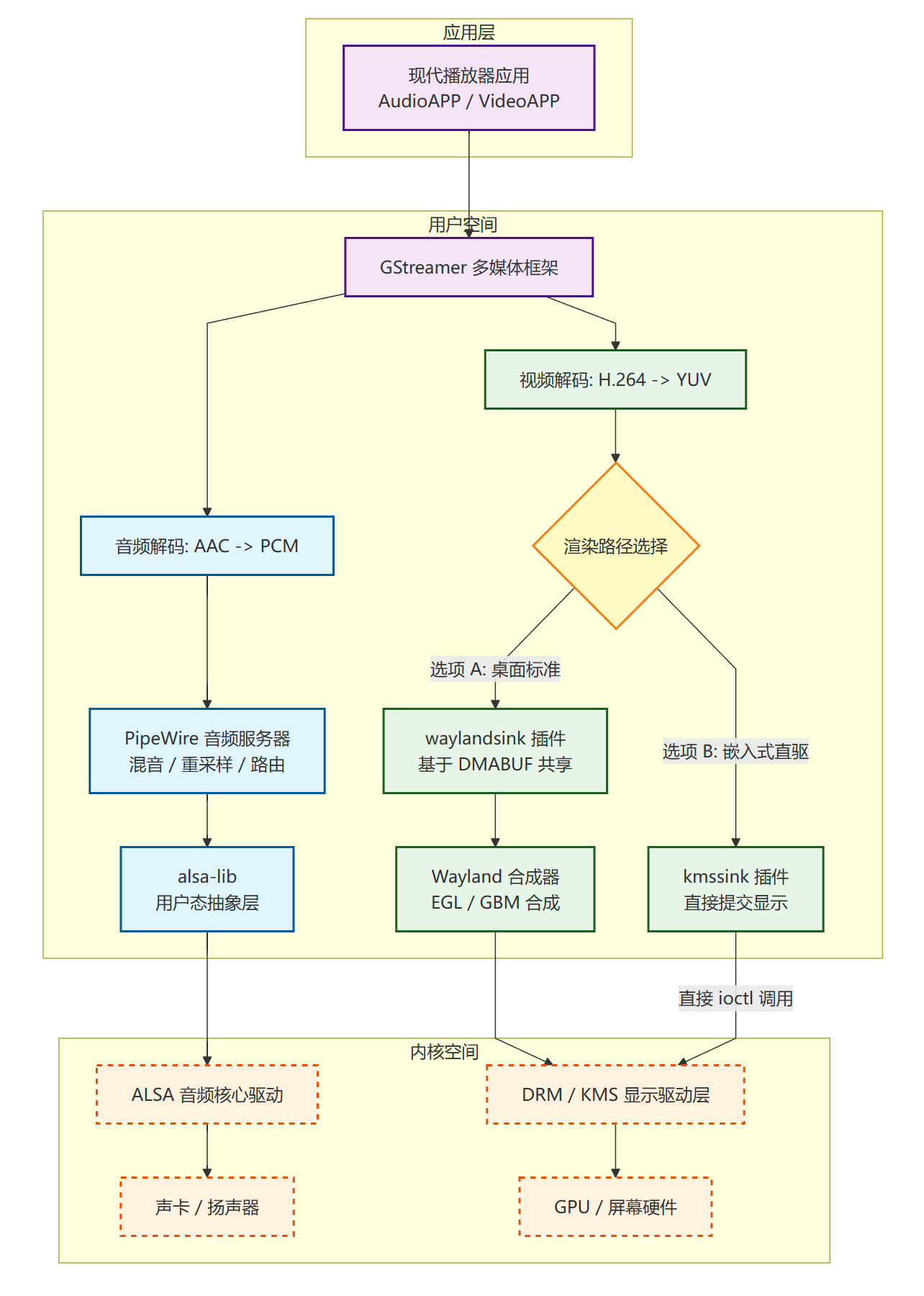
这张图精准体现了以下几个关键点:
-
音频路径(蓝色) :严格遵循现代 Linux 标准,
App → GStreamer → PipeWire → alsa-lib → ALSA 驱动,实现了应用层与硬件驱动的完全解耦。 -
视频路径(绿色) :明确画出了互斥的二选一关系,没有混淆。
-
选项 A(桌面) :通过
waylandsink交给 Wayland 合成器统一合成后再进 DRM。 -
选项 B(嵌入式) :通过
kmssink直接绕开显示服务器,通过ioctl直触 DRM 驱动。
-
-
层级分离:用虚线框清晰划分了"用户态"与"内核态",符合 Linux 系统分层设计的逻辑,用于技术方案讲解或文档撰写都非常专业。
-
GPU 与 视频子系统的补充:
GPU 的显示/渲染核心:只与 DRM 交互,绝不与 V4L2 交互。
GPU 的周边视频解码协处理器(VPU):只与 V4L2 交互(负责解码),绝不与 DRM 交互(不负责显示)。
两者唯一的交集:通过内核的 DMA-BUF 机制传递解码后的视频帧内存地址,让 DRM 驱动把这张"由 V4L2 解码出来的图片"拿去显示。