用 AI 编码助手写了大半年代码,有两个问题我一直在跟它们搏斗。
第一个,AI 在「要构建什么」还没想清楚的时候就开始写代码。你跟它讨论需求,聊了三轮,它突然来一句「我来帮你实现吧」,然后一顿输出,写完一看,方向跑偏了。代码能跑,但不是你想要的。删了重来,token 已经烧掉了。
第二个,规划倒是写了,但实现的时候还是漂移。代码和 spec 各走各的路,到最后 review 的时候才发现对不上。
为了解决这两个问题,我分别找到了两个框架。
OpenSpec,GitHub 5.7 万星,Fission AI 开源的 spec-driven 规划引擎。规划能力极强,proposal 到 specs 到 design 到 tasks,每一步都有 schema 验证,delta spec 做增量变更,支持 25+ 个 AI 编码平台。说实话,在「让 AI 想清楚再动手」这件事上,目前没看到比它更成熟的方案。
Superpowers,GitHub 24 万星,obra 做的执行纪律框架。TDD 铁律、Review Gate、Subagent-Driven Development、系统性调试,四层质量门禁层层设卡。在「逼着 AI 按规矩做」这件事上,它是绝对的行业标杆。
两个框架都很强,我两个都在用。但用了一段时间之后,一个新的痛点浮出水面------
我得手动判断现在该用哪个框架。
需求模糊的时候用 OpenSpec 探索,规划写完了要切到 Superpowers 执行,中间还得手动管理状态转换、手动归档、手动检查 spec 有没有漂移。两个框架各自没有对接,粘合剂是我自己脑子里的流程。
太累了。
所以我写了 spec-superflow,一个把两者焊在一起的插件。核心思路说出来其实不复杂------用一张「执行契约」把规划和执行连起来,然后让状态机自动驱动流转。
今天拆开来聊聊这个设计思路。
OpenSpec,5.7 万星的规划标杆
先聊 OpenSpec。这是 Fission AI 开源的 AI-native 规划引擎,MIT 协议,目前 v1.4.1,GitHub 5.7 万星。
它要解决的问题很直接------AI 编码助手在需求只存在于聊天记录的时候,行为是不可预测的。你今天跟 AI 说「加个暗色模式」,它记住了。明天你改了主意说「先别做暗色模式,把性能优化搞一下」,它可能还记得昨天那个暗色模式的上下文,写着写着又跑回去了。
OpenSpec 的解法是加一层轻量协议,在写代码之前先把变更该做什么记下来。不是写那种 50 页的 PRD,而是一个结构化的 spec,用 SHALL 和 MUST 这种确定性词汇描述需求,配上 Given/When/Then 的场景。
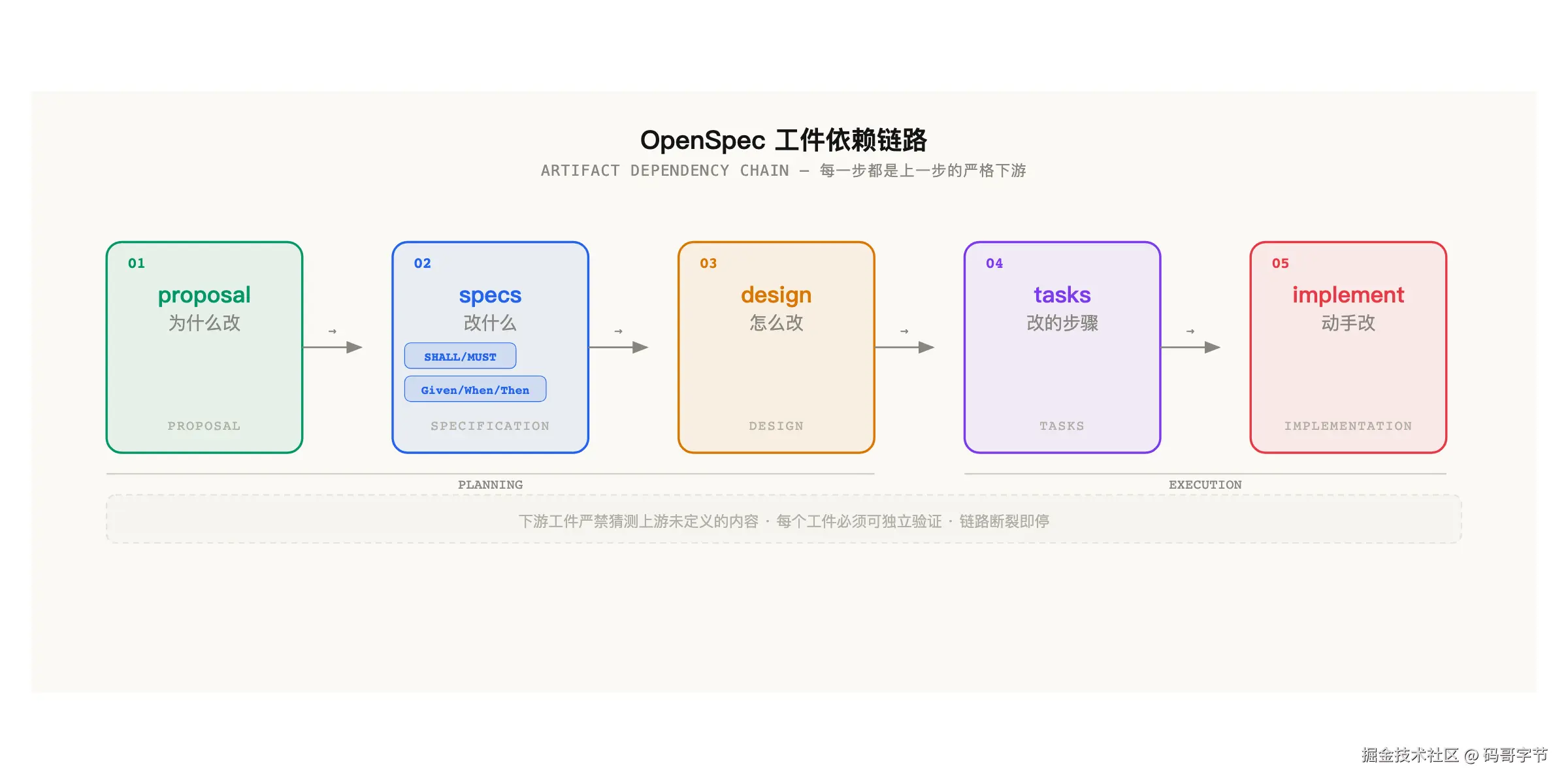
它有一套非常漂亮的工件依赖图。proposal 定义变更意图,specs 描述具体需求,design 给出技术方案,tasks 拆分成可执行步骤,最后才是 implement。每个工件都有 schema 定义,靠一个 YAML 引擎做拓扑排序,前置工件没就绪,后续的自然等着。依赖关系是「使能」而不是「卡死」------你随时可以回去修改前面的工件,这在「流动不僵化」这个设计理念下非常实用。
几个核心命令,/opsx:explore 探索需求,/opsx:propose 生成 proposal,/opsx:apply 往下游推进,/opsx:sync 同步 delta spec 到主 spec,/opsx:archive 归档已完成的变更。支持 25+ 个 AI 编码平台,Claude Code、Cursor、Codex、Gemini CLI 全覆盖。
有个设计我特别欣赏------delta spec。棕地项目最怕改一处要重写整份 spec。OpenSpec 用 ADDED/MODIFIED/REMOVED 三个标记描述增量变更,不动已有 spec,只描述差异。这让它在存量代码场景下极其好用。
不过,OpenSpec 的定位是「规划引擎」,它把规划做到了极致,但从规划到落地这段路,它有意不碰。它的设计哲学是「做好一件事」------把需求定义清楚,然后交给执行层。这不是缺陷,是边界。
只是这个边界意味着,用户需要自己去找一个靠谱的执行层框架来对接。
Superpowers,24 万星的执行圣经
再说 Superpowers。这是 obra(Prime Radiant)做的一套软件开发方法论,打包成可组合的 AI agent skills,目前 v6.0.3,GitHub 24 万星。
24 万星什么概念?这是 AI 编码工具生态里星标最高的框架之一。它不是某个特定功能做得好,而是整个「AI 该怎么写代码」的方法论被社区认可了。
如果说 OpenSpec 是个冷静的参谋,Superpowers 就是个铁血教官。它的核心不是「帮你想清楚」,而是「逼着你按规矩来」。
每个 skill 都是强制性的。它甚至有一张「Red Flags」表,列出了 AI 可能用来跳过流程的借口------「这个改动太小了不需要测试」「用户赶时间先跳过 review」------然后逐条告诉你为什么这些借口不成立。我第一次看到这张表的时候笑了,因为它列的每条借口我都见过,AI 确实就是这么偷懒的。
TDD 在这里是铁律,没有失败测试就不准写生产代码。不是建议,是强制。AI 要是违反了这条,规则要求它把写的代码全部删掉,从 failing test 重新开始。这个设计太狠了,但也太对了。AI 最难拒绝的就是「我先写个大概能跑的版本再补测试」这种诱惑,Superpowers 直接把这扇门焊死了。
Review Gate 层层设卡------spec 写完先自审,每个任务完成后审查,整个分支完成后审查,交付前最终验证。四层 gate,任何一层没通过都不能往下走。
SDD(Subagent-Driven Development)更是杀手级能力。每个任务分发给一个独立的子代理去执行,上下文隔离,文件交接。子代理不会被其他任务的上下文污染,完成后还有双裁决审查------既查 spec 合规性,又查代码质量。v6.0 的评测数据显示,这套机制让 token 消耗砍了约 50%,速度翻了一倍。
不过,Superpowers 的定位是「执行纪律」,它在规划层提供的是 brainstorming------更像设计讨论,不是正式的 spec。没有 SHALL/MUST 这种确定性需求描述,没有 delta spec 增量管理,没有 spec 之间的拓扑依赖。同样,这不是缺陷,是边界------它专注于把「做」这件事做到极致。
只是,规划层需要一个更正式的引擎来补位。
spec-superflow,让两个框架自动协作
现在该说 spec-superflow 了。这是我自己开源的 Claude Code 插件,v0.2.0,MIT 协议。
你可能想,两个框架同时装上不就行了?
问题在于,粘合剂得你自己做。OpenSpec 的 explore 和 Superpowers 的 brainstorming 都在做需求梳理,同时用哪个?OpenSpec 的 propose 和 Superpowers 的 writing-plans 都在做计划生成,听谁的?规划完了谁触发执行?执行到一半发现 spec 要改谁来回滚?归档的时候谁来同步 delta spec?
全靠手动判断,手动切换,手动归档。用了一段时间我就烦了------这哪是提效,这是给自己加了个「流程管理员」的活。
所以我决定把两者焊死,让状态机自动驱动流转。做法是三步------去重叠、留异同、加独创。
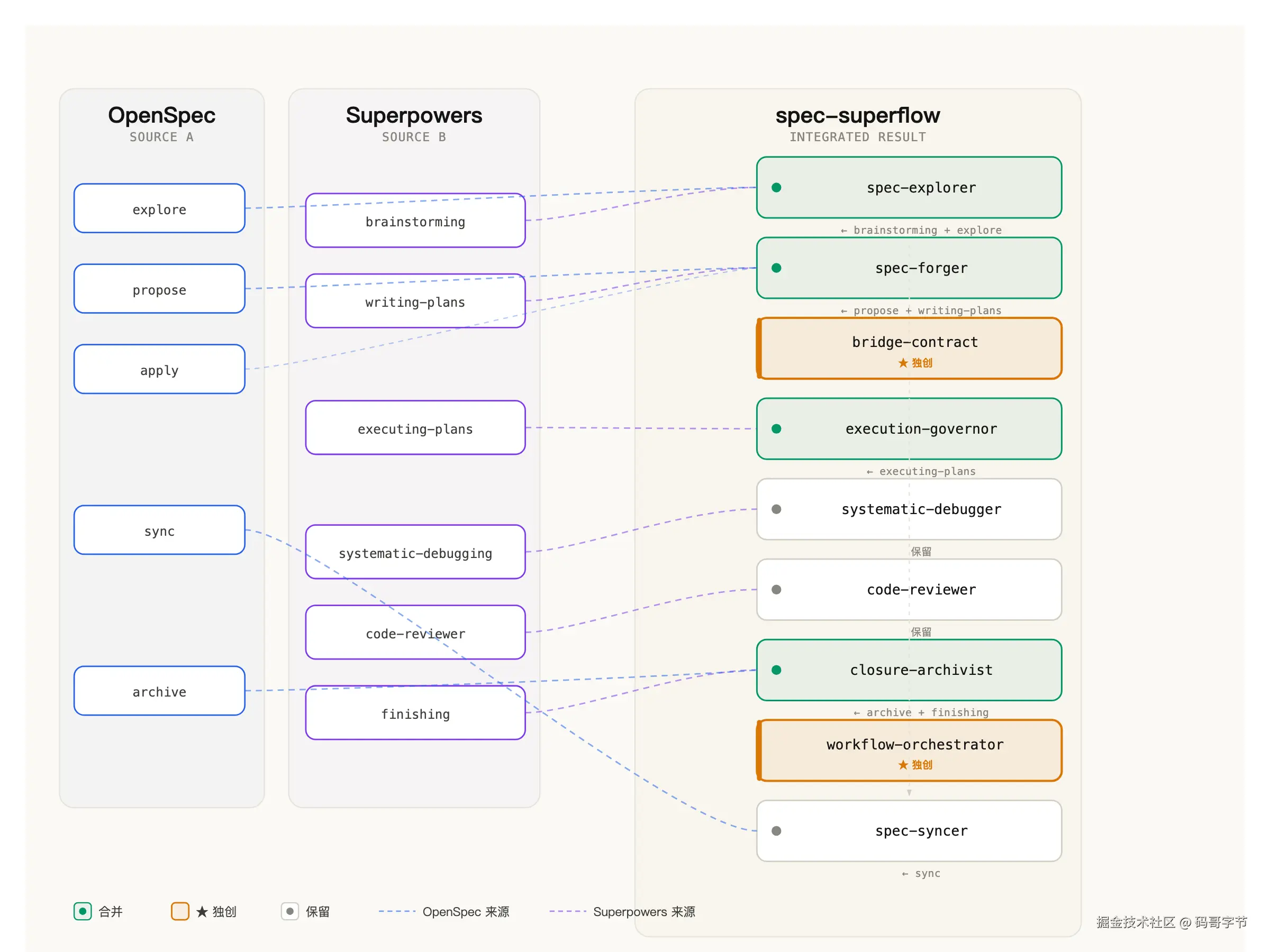
去重叠,把功能重复的合并掉,brainstorming 融入 spec-explorer,因为探索需求本身就是头脑风暴的落地形态;writing-plans 融入 spec-forger,规格锻造的过程就是写计划的过程;executing-plans 并入 execution-governor,执行和治理本来就不该分开;archive 和 finishing 并入 closure-archivist,收尾归档一气呵成。
留异同,两边各自独有的东西全部保留。systematic-debugger 是 Superpowers 的精华之一,专门处理 bug 的,OpenSpec 没有对应物,保留。spec-syncer 是 OpenSpec 的 delta spec 同步机制,Superpowers 没有,保留。code-reviewer 同理。
加独创,这是最关键的部分。新增了三个组件,bridge-contract(解析引擎,自动从规划工件提取执行契约)、workflow-orchestrator(内容级状态检测,不只是看文件存不存在)、还有一个覆盖全流程的七状态机。
这三个新增组件里面,bridge-contract 是核心创新。单独拆出来说。
执行契约,让规划变成可验证的东西
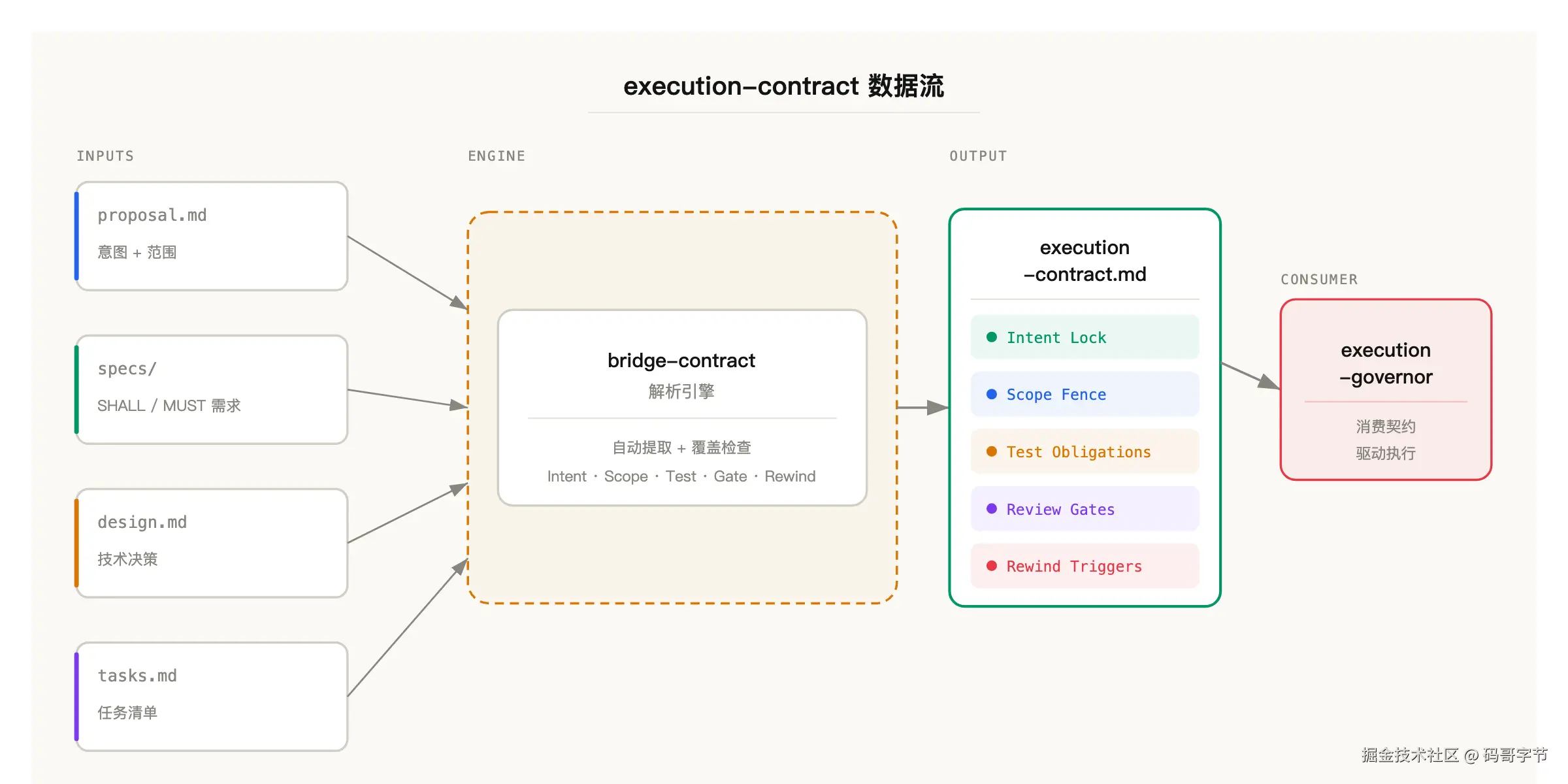
bridge-contract 是整个 spec-superflow 的设计重心。它生成的 execution-contract.md 不是第五个规划文档,而是一份可验证的执行契约。
为什么需要这个东西?
因为我发现前面说的那两个失败模式,根源在于规划和执行之间缺少一个「锚点」。OpenSpec 的 spec 是参考材料,AI 执行的时候可能看也可能不看。Superpowers 的 skill 是行为准则,但它不知道具体该验证什么。execution-contract 就是那个锚点,它从 OpenSpec 的四个规划工件(proposal、specs、design、tasks)里自动提取关键约束,形成一份执行必须对标的契约。
提取什么?六样东西。
Intent Lock,锁定变更意图,防止执行过程中目标漂移。Scope Fence,圈定变更范围,明确什么该改什么不该改。Non-Goals,列出明确不做的东西,这个很重要,AI 最容易「顺手」做 spec 之外的事情。Test Obligations,测试义务,哪些场景必须有测试覆盖。Review Gates,审查节点,执行到哪一步需要暂停等人 review。Rewind Triggers,回滚触发条件,出现什么情况必须停下来重新评估。
然后做覆盖检查,每个 spec 里的 SHALL 和 MUST 需求,都必须在契约中有对应的条目。如果某条需求在契约里找不到映射,说明规划层和执行层之间有缝隙,要么补契约,要么回头补规划。
契约生成后,唯一的人工门禁就是用户审批。审批通过了,execution-governor 才能启动执行。这个设计是有意的,机器可以生成规划,机器可以执行代码,但「确认这个规划值得执行」这个判断,必须是人来做。
来看一段实际的 contract 片段。假设我们在做一个「给用户管理模块加分页」的变更,
markdown
## Intent Lock
实现用户管理列表的分页查询功能,支持按创建时间排序。
## Scope Fence
### In Scope
- `src/modules/user/user.controller.ts` --- 新增分页参数解析
- `src/modules/user/user.service.ts` --- 分页查询逻辑
- `src/modules/user/dto/user-list.dto.ts` --- 新增分页 DTO
### Out of Scope
- 用户详情接口不动
- 不做前端分页组件
## Non-Goals
- 不引入 Elasticsearch
- 不做全文搜索
- 不优化现有的 N+1 查询(留给下个变更)
## Test Obligations
- [ ] 默认分页参数(page=1, size=20)单元测试
- [ ] 非法分页参数(page=0, size=-1)边界测试
- [ ] 空结果集返回格式测试
## Review Gates
- Gate 1: DTO 和 Service 层完成后,review 分页逻辑
- Gate 2: Controller 层完成后,review 参数绑定
## Rewind Triggers
- 如果分页查询导致已有接口响应时间 > 500ms,暂停评估是否需要加索引
- 如果发现需要改动 user.entity.ts,暂停------可能超出 scope这就是契约的样子。不长,但每一条都对应着执行时的检查点。AI 在写代码的时候,execution-governor 会拿着这份契约逐条比对。Scope Fence 之外的文件?不许碰。Non-Goals 里提到的事情?不准顺手做。Rewind Trigger 触发了?暂停,等人来决定。
bash
# Claude Code 安装
/plugin marketplace add MageByte-Zero/spec-superflow
/plugin install spec-superflow@spec-superflow
# 启动工作流
使用 workflow-orchestrator 开始七状态机,一条路走到黑的流程
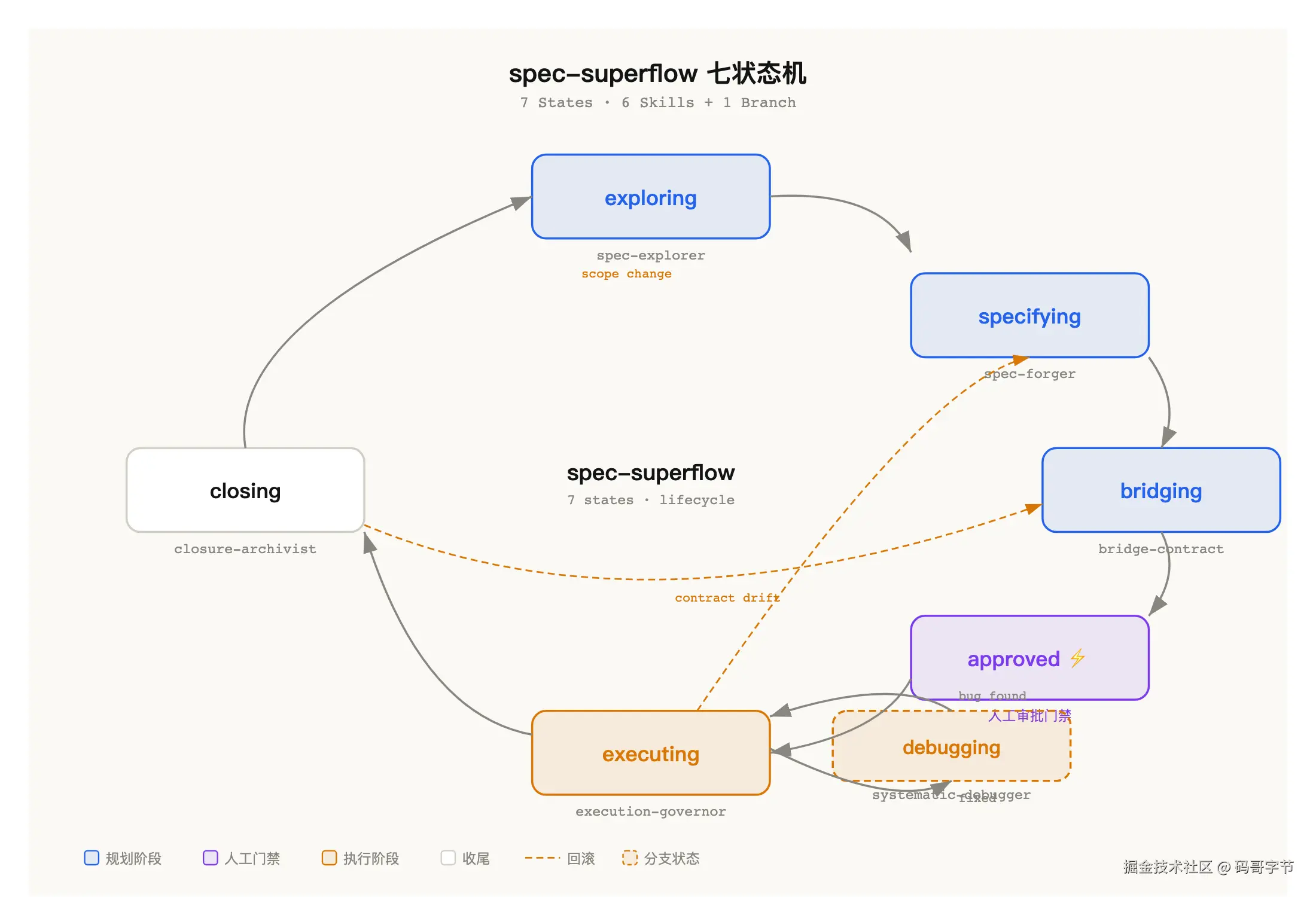
spec-superflow 的完整工作流用七个状态描述,exploring → specifying → bridging → approved → executing → debugging → closing。
每个状态对应一到两个 skill。exploring 阶段用 spec-explorer 梳理需求,specifying 阶段用 spec-forger 生成规划工件,bridging 阶段用 bridge-contract 生成执行契约,approved 是人工审批的暂停点,executing 阶段用 execution-governor 管控实施,debugging 阶段交给 systematic-debugger 处理异常,closing 阶段由 closure-archivist 完成归档。
workflow-orchestrator 是入口。你说「开始」或者「继续」,它检测当前状态,决定下一步该调用哪个 skill。这里有个设计细节值得说说,它不是简单地检查某个文件存不存在来判断状态,而是读文件内容,分析里面写了什么。比如它不会只看「design.md 存在吗」,而是看「design.md 里面的内容是否覆盖了 specs 里提到的所有关键技术决策」。
这个内容级检测的设计是因为我踩过坑。早期版本用文件存在性检查,结果 AI 生成了一个空的 design.md 占位,状态机就以为规划完成了,直接往下走。后来改成内容级检测,才把这类问题堵住。
整套插件零外部依赖。纯 TypeScript 接口定义,正则做工件解析,没有 npm 包。我不想为了一个流程编排工具给用户的项目塞一堆 node_modules。
什么时候该用,什么时候别用
说了这么多,得说说边界。
两个真实跑通的例子。一个是 add-dark-mode,在一个已有的 Next.js 项目上加暗色模式支持。从 exploring 开始,走完七个状态,bridge-contract 锁定了主题切换的 scope,明确不改已有的 API 层,execution-governor 逐 task 推进,code-reviewer 在 gate 检查。整个过程 spec 漂移率很低,因为契约把边界画得很清楚。
另一个是 refactor-auth-boundary,把一个单体里的认证逻辑抽成独立模块。这种棕地重构特别适合 delta spec 的方式,不动原有 spec,只描述「认证边界从 A 移到 B」这个变更。rewind trigger 在重构中途触发了一次(发现需要改数据库 schema),暂停后人工评估,调整 scope 后继续。
适合用的场景,大型功能开发,多人协作需要统一规格,长期维护的项目需要可追溯的变更历史,需要严格 TDD 和 Review Gate 的团队流程,棕地项目需要精确的增量描述。
不适合用的场景,快速原型验证,小于 100 行的小改动,纯探索性的开发,单纯的 bug 修复,个人实验项目。
经验法则,如果你不需要写 proposal 和 design doc 就能把事情想清楚,那 spec-superflow 对你来说太重了。它的价值在于给「想不清楚就容易出错」的中大型变更提供护栏,不是给所有开发场景加一层仪式。
FAQ
spec-superflow 支持哪些平台? 目前 v0.2.0 支持 7 个平台,包括 Claude Code、Cursor、Copilot 等。核心逻辑是纯 Markdown 工件,理论上任何支持文件读写的 AI 编码工具都能适配。
OpenSpec 和 Superpowers 各自都很强,为什么还要融合? 它们确实很强,各自在自己擅长的领域做到了极致。问题在于它们各有偏重------OpenSpec 偏规划,Superpowers 偏执行,两者之间没有自动对接机制。如果你只用其中一个,完全没问题。但如果你想同时享受「规划清晰」和「执行严谨」两个好处,就得手动管理状态切换和工件同步。spec-superflow 解决的就是这个手动粘合的痛点------bridge-contract 自动把规划转成可验证契约,状态机自动驱动流转,你不再需要充当两个框架之间的「人肉胶水」。
TDD 铁律怎么执行? execution-governor 在推进每个 task 之前,会检查对应的测试文件是否存在、测试是否通过。如果没有失败测试作为起点,它拒绝生成生产代码。这个行为写死在 skill 里,AI 没法绕过。
token 开销会不会很大? 会。七个状态、九个 skill、多层 review gate,完整的流程跑下来 token 消耗确实不低。所以回到那个经验法则,小改动别用。spec-superflow 的 ROI 在中大型变更上才能体现出来。
最后
OpenSpec 和 Superpowers,一个 5.7 万星,一个 24 万星,能走到今天这个位置,靠的是各自在自己领域做到极致。我对这两个框架的作者都充满敬意------它们的设计思路给了我很多启发。
spec-superflow 做的事情,说白了就是当个「连接器」。OpenSpec 把规划做得漂亮,Superpowers 把执行做得严谨,但两者之间缺一条自动化的桥梁。bridge-contract 就是这条桥梁,七状态机就是自动化的引擎。
融合之后是什么感觉?你不再需要手动判断「现在该用哪个框架」了。告诉 workflow-orchestrator「开始」,它会自动走完探索、规划、契约生成、审批、执行、调试、归档的全流程。规划阶段用 OpenSpec 的能力,执行阶段用 Superpowers 的能力,中间衔接全部自动。
说句实话,融合之后的工作流,比单独用任何一个框架都要完整。这就是 1+1 > 2 的效果------不是两个框架的简单叠加,而是在它们之间创造了一个新的层。
项目目前 v0.2.0,刚起步。GitHub 上搜 spec-superflow 就能找到,MIT 协议,零依赖。欢迎试用,欢迎提 issue,更欢迎 PR。

我正在写一系列 AI 编码工作流的实战文章,下篇打算拆解 bridge-contract 的实现细节,感兴趣可以关注一下。如果你身边有人正在为 AI 编码「想不清楚就做」的问题头疼,这篇可以直接甩给他。
