第一次调 LLM API 时,我有点恍惚。
我以为会收到一个像 ChatGPT 那样"正在输入"的鲜活响应,结果服务器只是冷冰冰地丢回一个 JSON:
json
{
"choices": [{
"message": {
"role": "assistant",
"content": "2 + 2 = 4."
}
}],
"usage": { "prompt_tokens": 17, "completion_tokens": 7 }
}然后就没有然后了。没有会话状态,没有上下文记忆,没有"思考中"的动画。LLM 根本不在乎这是你的第几轮提问------它只看你这次发过去的文本。
后来我才发现,Agent 的"强大"并不来自模型本身,而是来自一个我们手动维护的循环:把 LLM 的回复塞回上下文,把工具的返回值再塞给 LLM,一遍又一遍。没有魔法,只有循环。
这篇文章把这条路走完。从一次最普通的 LLM API 调用,到流式响应,再到 Tool Calling、Agent Loop,最后拼出一个能读文件、修 bug、跑命令的 Mini Coding Agent。中途我会重点讲一个我最初忽略的工程问题:怎么让工具对 LLM 更友好。
这是"从 LLM API 到 Agent 工程"专栏的第一篇。读完它,你能理解单个 Agent 为什么能跑通;但这个专栏真正想回答的,是 Agent 怎么在真实代码仓库里稳定、可靠、可验证地完成任务。
1. LLM API 的本质:无状态函数
1.1 text in → text out
调用 LLM API 本质上就是一次 HTTP 请求。你发一个 JSON 请求体,服务器返回一个 JSON 响应。它和我们调用的任何其他远程函数没有区别。
请求方法:POST /chat/completions,Content-Type: application/json。
请求体:
json
{
"model": "deepseek-v4-flash",
"messages": [
{ "role": "system", "content": "你是一个简洁的助手。" },
{ "role": "user", "content": "2 + 2 等于多少?" }
]
}返回也是 JSON:
json
{
"choices": [{
"message": { "role": "assistant", "content": "2 + 2 = 4。" }
}]
}模型不会记住你上一秒问过什么。你问"我叫什么名字?",它只能回答:你没有告诉我。这不是它在装傻,而是它真的不知道。
1.2 无状态:LLM 最重要的设计约束
服务器不保存你的会话,第 100 次调用和第 1 次调用对模型来说没有任何区别------它只看你这次发了什么文本。这导致多轮对话必须手动拼历史,想让模型记得前文,每一轮都要把完整 messages 重新发过去。
这里同时还有一些工程约束:
- 对话越长越贵。每次都要把历史重发一遍,输入 token 只增不减,成本随轮次上升。
- 上下文有上限。模型单次能处理的 token 数量是有限的,我们常说的 128K、200K、1M 就是这个上限。一旦超出,请求会直接报错或被截断。使用的上下文越长,模型对中间信息的利用能力还会越差。
这些约束叠加在一起,麻烦就来了。服务器不存状态,你只能靠不断堆 messages 维系记忆;messages 越堆越长,迟早撞上下文上限。这个矛盾是整个 Agent 上下文工程的起点。
模型不是失忆了,它根本就没有记忆。记忆是我们用 messages 人工堆出来的。
1.3 多轮对话的真相:messages 是记忆
如果你想让模型在第二轮还记得你叫葡萄边,做法是把第一轮的内容也塞进 messages 数组。下面这个例子演示了一次真正的多轮对话 :每一轮都把前一轮的回复 push 进 messages,再发起下一轮请求。
ts
import { builtinModels } from "@earendil-works/pi-ai";
import type { Context } from "@earendil-works/pi-ai";
const models = builtinModels();
const model = models.getModel("deepseek", "deepseek-v4-flash");
const context: Context = {
systemPrompt: "你是一个简洁的助手。",
messages: [],
};
// 第一轮:自我介绍
context.messages.push({
role: "user",
content: "我叫葡萄边。",
timestamp: Date.now(),
});
const reply1 = await models.completeSimple(model, context);
console.log(reply1.content); // 你好,葡萄边。
// 关键:把模型回复 push 回上下文,否则下一轮模型看不到
context.messages.push({
role: "assistant",
content: reply1.content,
timestamp: Date.now(),
});
// 第二轮:测试模型是否记得
context.messages.push({
role: "user",
content: "我叫什么名字?",
timestamp: Date.now(),
});
const reply2 = await models.completeSimple(model, context);
console.log(reply2.content); // 你叫葡萄边。
// 第二轮回复也 push 回上下文
context.messages.push({
role: "assistant",
content: reply2.content,
timestamp: Date.now(),
});这个例子刻意没有预拼历史。它展示了"记忆"是怎么在代码里长出来的:每一轮调用结束后,你手动把 assistant 的回复 push 进 messages,下一轮的请求里才会有它。messages.push({ role: "assistant", content: ... }) 这行是灵魂。不 push,模型就失忆;push 了,它才能看到完整历史。
这就是后面 Agent 循环的雏形。

1.4 流式输出与"文字接龙":token 是 LLM 的基本单位
ChatGPT 的回复一个字一个字冒出来,不是前端动画,而是模型真的在边想边吐。
LLM 生成文本的本质叫自回归(autoregressive):每次只预测下一个 token,然后把预测结果拼回输入,再预测下一个。循环往复,直到结束。
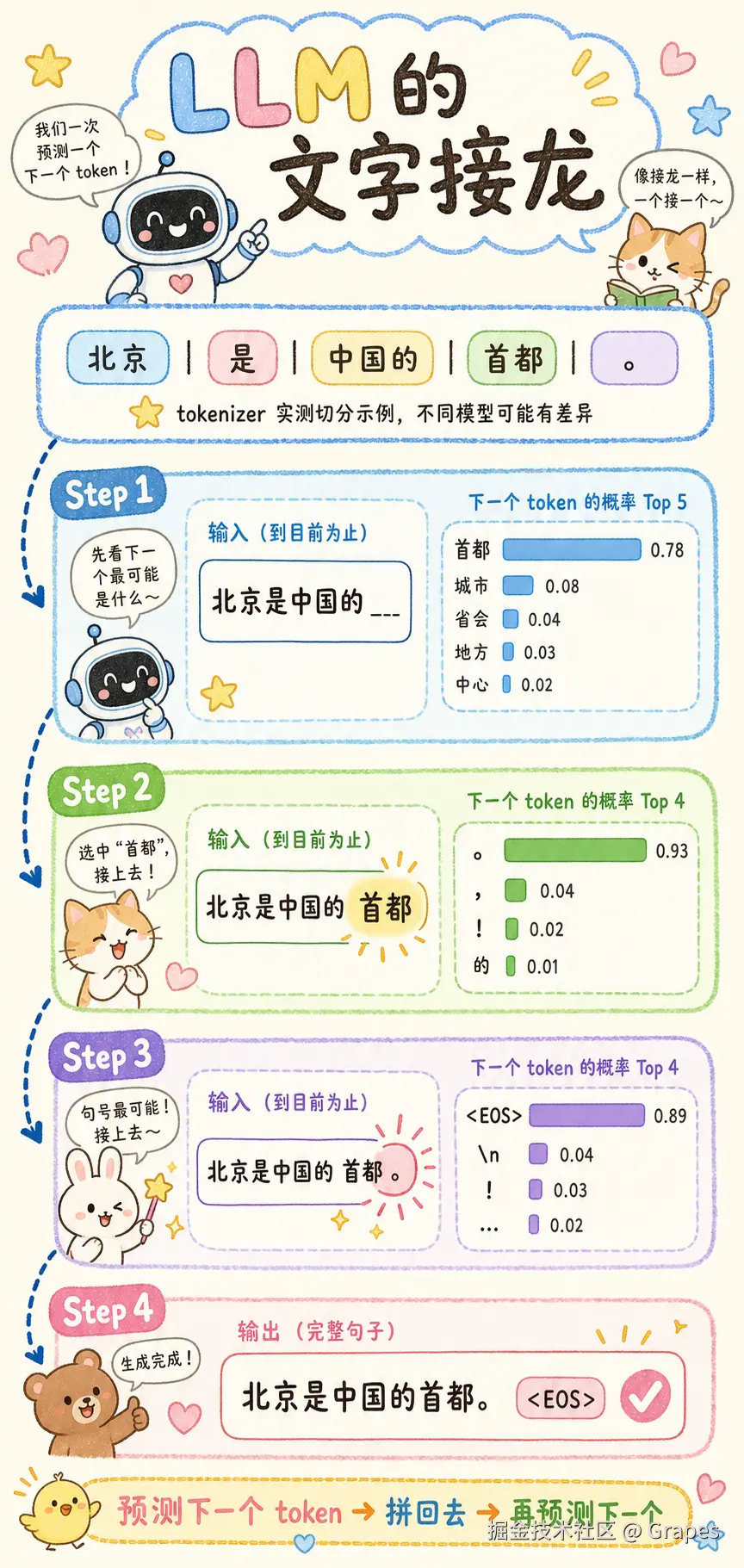 基于 tokenizer 实测切分:北京 | 是 | 中国的 | 首都 | 。,不同模型可能有差异。
基于 tokenizer 实测切分:北京 | 是 | 中国的 | 首都 | 。,不同模型可能有差异。
模型并没有什么"理解"的顿悟时刻。它只是在每个位置都问:给定前面所有文本,下一个最可能出现的 token 是什么?比如在"北京是中国的"后面,下一个 token 很可能是"首都";再把"首都"拼回输入,下一个 token 就可能是"。";就这样一直推到模型吐出结束符。单个动作简单到有点无聊,重复几千次之后,却能冒出一段看起来"理解了"的文本。
流式 API 把这个接龙过程直接暴露给了你。每次只吐一个 token,所以你看到的就是"打字"效果。底层用的是 SSE(Server-Sent Events),下一节会简单讲。
1.5 pi 的 Context:把无状态调用写成代码
写到这里,我们需要一个具体的代码框架来落地这些概念。我用的是 pi,一个由 earendil-works 开源的 TypeScript 工具集,很适合用来学习和小型工程化的 Agent 系统。
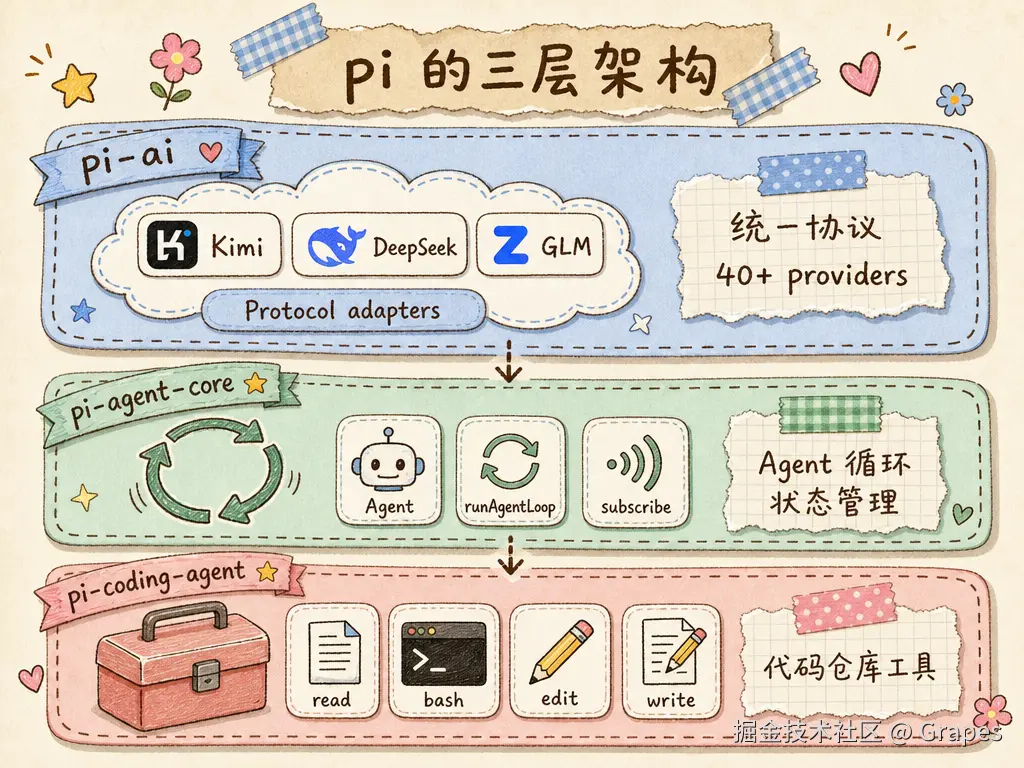
pi 的分层很清晰:
pi-ai:统一 LLM 协议。把 OpenAI、Anthropic 等协议差异封装掉,同时接入 Kimi、DeepSeek、GLM 等 40 多个 provider。对外暴露complete()、stream()和Context/Tool类型。pi-agent-core:Agent 循环的抽象。提供Agent类、AgentTool类型和事件系统。pi-coding-agent:面向真实工程的工具系统,比如代码搜索、测试运行、Git 工作流等。这是专栏后续的内容。
分层清晰的好处是:想只调 LLM 可以只拿 pi-ai;想自己写一个 Agent 循环可以拿 pi-agent-core;想直接开箱做一个终端 Coding Agent 可以拿 pi-coding-agent。不会被绑在全套产品上。对于想理解 Agent 运行原理而不是只调封装接口的开发者,这种结构很合适。
我们先用 pi-ai 的 Context 类型来理解一次 API 调用:
ts
import type { Context } from "@earendil-works/pi-ai";
export interface Context {
systemPrompt?: string; // 系统角色设定
messages: Message[]; // 用户/助手/工具结果的完整历史
tools?: Tool[]; // 当前可用的工具
}Context 就是无状态函数在代码里的体现。每一次 models.completeSimple(model, context),都是一次全新的 HTTP 调用;模型不会保留任何状态,所以你必须通过 messages 把历史喂进去。
接下来,我们就用 pi 的 API,把上面这些概念一步步变成能运行的代码。
2. SSE:流式响应的管道
ChatGPT 的"打字"效果来自流式 API。它不是一次性返回完整文本,而是把生成过程中的每个 token 逐个推送给客户端。底层协议是 SSE(Server-Sent Events)。
2.1 为什么 LLM 流式 API 不用标准 EventSource
浏览器原生的 EventSource 只能发 GET 请求,不能带自定义 Header,也不能在请求体里塞 messages。LLM API 需要 POST + 自定义 Header(比如 Authorization),所以通常需要手写 SSE 解析器。
2.2 一个最小 SSE 解析器
SSE 协议很简单。服务器通过长连接发送这样的文本块:
text
data: {"choices":[{"delta":{"content":"你"}}]}
data: {"choices":[{"delta":{"content":"好"}}]}
data: [DONE]在 LLM API 中,常见的规则是这样的:
- 每条消息以
data:开头 - 消息之间用两个换行符分隔
- 结束时可能收到
data: [DONE]
用 TypeScript 实现一个最小解析器:
ts
async function* parseSSE(
response: Response,
signal?: AbortSignal,
): AsyncGenerator<string> {
const reader = response.body!.getReader();
const decoder = new TextDecoder("utf-8", { stream: true });
let buffer = "";
while (true) {
if (signal?.aborted) throw new Error("aborted");
const { value, done } = await reader.read();
if (done) break;
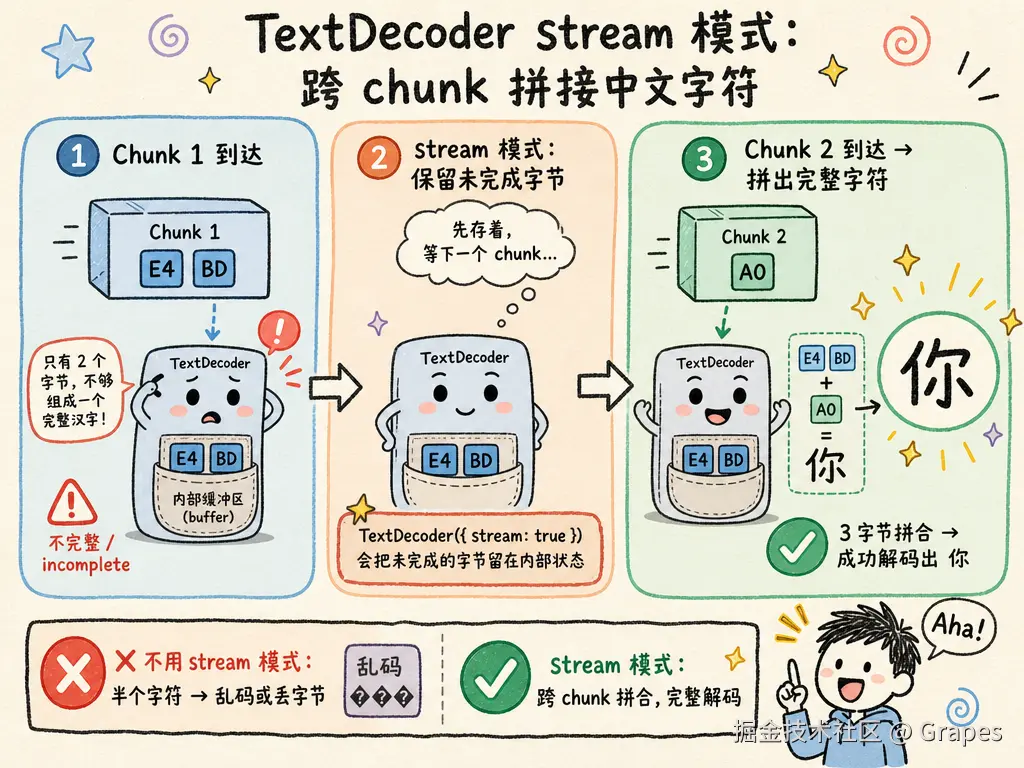
// stream: true 是关键。它允许中文字符跨多个 chunk 拼合。
// 例如 "你" 的 UTF-8 编码是 3 字节,如果两个 chunk 只到了前 2 字节,
// 普通 decode 会报错;stream 模式会保留未完成的字节,等下一个 chunk 补全。
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split("\n");
buffer = lines.pop() ?? "";
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
if (!line.startsWith("data:")) continue;
const data = line.slice(5).trim();
if (data === "[DONE]") return;
try {
const json = JSON.parse(data);
const delta = json.choices?.[0]?.delta?.content ?? "";
if (delta) yield delta;
} catch {
// 忽略不完整的 JSON
}
}
}
}这个函数把 SSE 流转换成一连串文本片段。把这些片段拼起来,就是模型的完整回复。
TextDecoder({ stream: true }) 对中文等多字节字符尤其重要。一个汉字在 UTF-8 中通常占 3 个字节。如果网络刚好把一个汉字拆到两个 chunk 里,普通解码会乱码或丢字节;stream 模式会把未完成的字节留在内部状态,等下一个 chunk 到达后再拼出完整字符。画张图更直观:
写这个最小解析器,不是为了生产环境重复造轮子,而是为了理解 stream() 事件从哪来。当你看到 text_delta 事件时,你知道它背后是一个 ReadableStream、一个 TextDecoder、一段缓冲区、以及对 [DONE] 的识别。理解了这一点,后面看 pi-ai 的 stream() 或 streamSimple() 的封装就不会觉得它"自动魔法"了。
2.3 用 pi 的 stream():看封装背后是什么
手写解析器是为了理解原理,真实项目里,pi-ai 把 SSE 流封装成了一组事件:
ts
import { builtinModels } from "@earendil-works/pi-ai/providers/all";
import type { Context } from "@earendil-works/pi-ai";
const models = builtinModels();
const model = models.getModel("deepseek", "deepseek-v4-flash");
const context: Context = {
systemPrompt: "你是一个简洁的助手。",
messages: [{ role: "user", content: "用一句话介绍你自己。", timestamp: Date.now() }],
};
const s = models.stream(model, context);
for await (const event of s) {
if (event.type === "text_delta") {
process.stdout.write(event.delta);
}
}
const finalMessage = await s.result();
context.messages.push(finalMessage);text_delta 这个事件,背后就是上一节手写的那段 SSE 解析------ReadableStream、TextDecoder、缓冲区、[DONE] 识别,全在里面。pi 把它们包成了一组事件类型:start 标记开始,text_start / text_delta / text_end 处理文本片段,toolcall_start / toolcall_delta / toolcall_end 处理工具调用,最后 done 收尾。
for await 循环结束后,s.result() 会拿到完整的 AssistantMessage------就是模型这一轮的最终回复。和 1.3 节一样,关键动作还是把它 push 回 context.messages,下一轮才能看到。
写 Agent 时,这些中间事件恰恰是你要的:你想在每个 token 到达时更新 UI,或者在 toolcall_start 时显示"工具执行中"。
3. Tool Calling:让 LLM 从"说话"到"办事"
如果 LLM 只能输出文本,那它永远是个聊天机器人。Tool Calling 让它第一次能够"行动"------调用你提供的工具。
3.1 Tool Calling 的本质
LLM 并不执行工具。它只决定:
- 要不要调用工具
- 调用哪个工具
- 传什么参数
真正的执行还是你的代码。也就是说,Tool Calling 是 LLM 向外部世界"发指令"的协议。
在 pi 里,工具定义用 TypeBox。TypeBox 是一个能在运行时生成 JSON Schema、同时提供 TypeScript 静态类型的库。这意味着你的工具参数既有类型检查,又能被 LLM API 直接消费。
ts
import { Type, type Static } from "typebox";
import type { Tool } from "@earendil-works/pi-ai";
const readSchema = Type.Object({
path: Type.String({
description: "Path to the file to read (relative or absolute)",
}),
offset: Type.Optional(Type.Number({
description: "Line number to start reading from (1-indexed)",
})),
limit: Type.Optional(Type.Number({
description: "Maximum number of lines to read",
})),
});
type ReadInput = Static<typeof readSchema>;
const readTool: Tool<typeof readSchema> = {
name: "read",
description: "Read the contents of a file. Output is truncated to 2000 lines or 50KB.",
parameters: readSchema,
};description 不是给人类看的注释,而是给 LLM 看的"使用说明"。LLM 会根据它判断:这个工具能帮我完成当前任务吗?
description 的写法直接影响模型会不会误用工具。好的 description 通常回答三个问题:它做什么、什么时候用、边界在哪里 。对比两个 read 的 description:
ts
// 差的写法:模型不知道截断和输出格式
const badRead = {
name: "read",
description: "Read file",
};
// 好的写法:模型知道何时用、输出会怎样
const goodRead = {
name: "read",
description: "Read the contents of a text file. Output is truncated to 2000 lines or 50KB. If you need more, call read again with offset.",
};差的 description 会让模型在"是否调用 read"和"怎么读"上猜测。好的 description 告诉模型:
- What:读取文本文件内容
- When:需要查看文件内容时调用
- Boundaries:输出会被截断到 2000 行或 50KB,想继续读可以带 offset
参数里的 description 同样重要。它们不是注释,而是 LLM 填参数时的提示。offset 写成 Line number to start reading from (1-indexed),模型就知道从 1 开始数而不是 0。
parameters 既是一个 JSON Schema(LLM API 需要),也是一个 TypeScript 类型(你的代码需要)。这就是 TypeBox 的价值:一次定义,两端受益。
3.2 调用流程
一次 Tool Calling 的完整往返是:
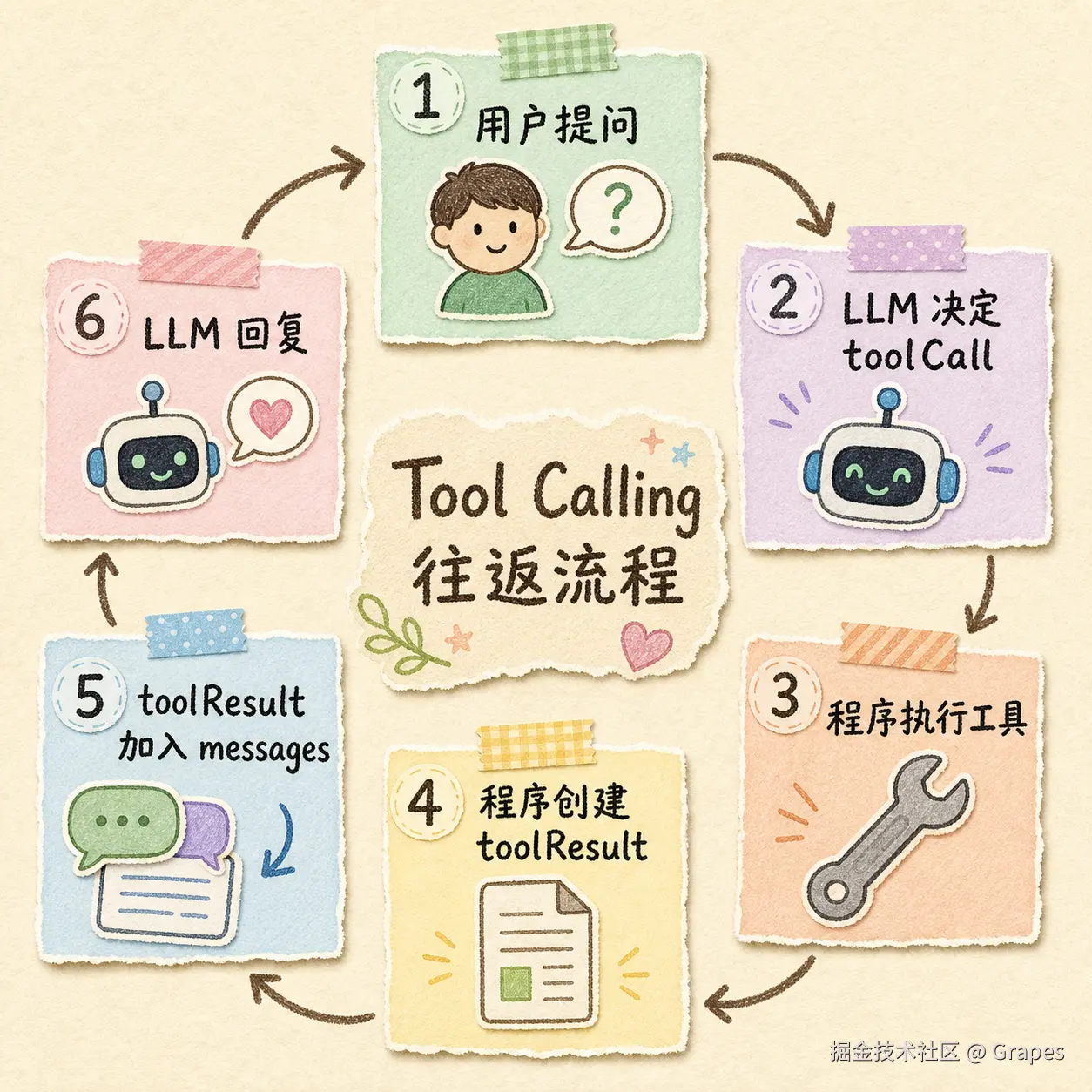
- 用户输入:读取 README.md
- LLM 返回
toolCall:决定调用read,参数{ path: "README.md" } - 程序执行
read - 程序把结果包装成
toolResult消息 - 程序把
toolResult塞回messages - LLM 再次生成,这次基于文件内容给出回复
注意第5步。和 1.3 节一样,关键又是 messages.push(...):把工具执行结果塞回上下文,让 LLM 在下一轮"看到"这个结果。
3.3 手写第一个 while 循环
Tool Calling 的核心可以写成一个简单的 while 循环:
ts
import { builtinModels } from "@earendil-works/pi-ai";
const models = builtinModels();
const model = models.getModel("deepseek", "deepseek-v4-flash");
async function runAgent(context, tools) {
while (true) {
const reply = await models.completeSimple(model, context);
if (reply.stopReason === "stop") {
// 普通文本回复,结束循环
console.log(reply.content);
break;
}
if (reply.stopReason === "toolUse") {
// 调用工具,把结果塞回上下文
const toolCall = reply.content.find(c => c.type === "toolCall");
const tool = tools.find(t => t.name === toolCall.name);
const result = await tool.execute(toolCall.arguments);
context.messages.push({
role: "toolResult",
toolCallId: toolCall.id,
toolName: toolCall.name,
content: result,
});
// 继续循环,让 LLM 基于结果继续生成
}
}
}这就是 Agent 的雏形:一个 while 循环,把 LLM 和工具串起来。循环没有终止条件的话,Agent 会自己决定什么时候退出(stopReason === "stop")。
能跑了,但离"能维护"还远。下一节看看它卡在哪。
4. 从 while 到 Agent:循环的产品化
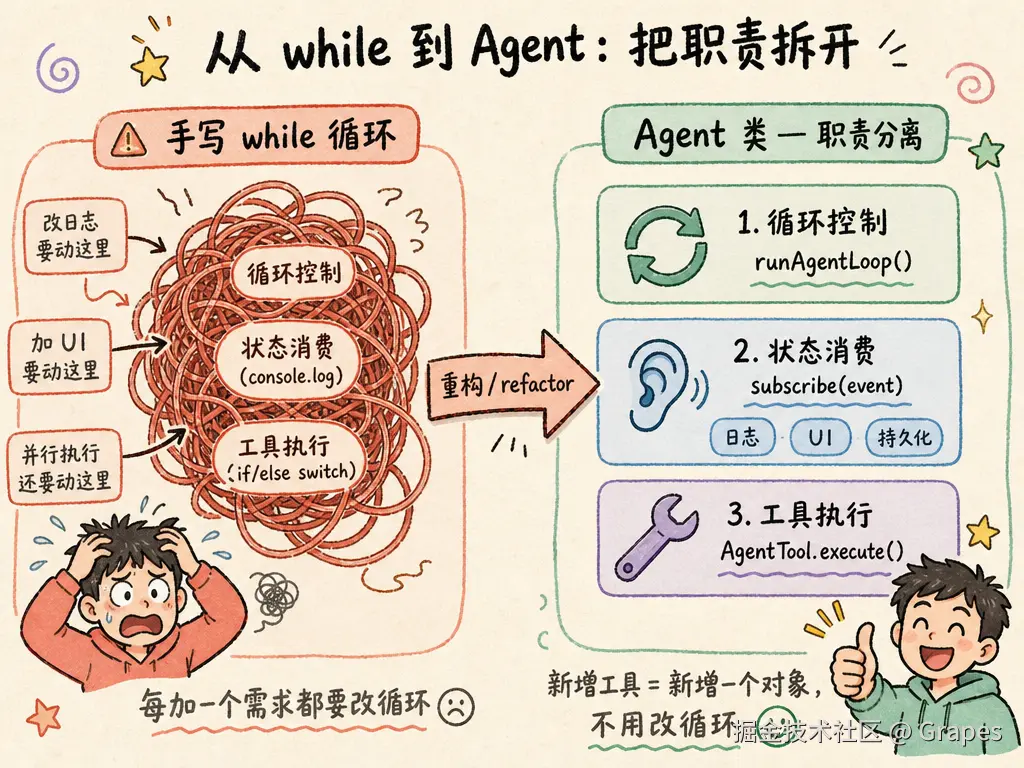
4.1 手写循环的耦合问题
那个 30 行的 while 循环同时做了三件事:
- 循环控制:什么时候调 LLM,什么时候结束
- 状态消费:怎么展示进度、怎么更新 UI、怎么记录日志
- 工具执行:根据名字找到工具,执行它,包装结果
这三个职责会迅速纠缠:
- 你想把日志打到文件,而不是
console.log------改循环 - 你想把状态同步到 WebSocket,让前端显示"工具执行中"------改循环
- 你想持久化 messages 到数据库------改循环
- 你想支持多个工具并行执行------改循环
- 你想让用户中途取消运行------改循环
循环里的职责越堆越多,每加一个需求,都要在原来的逻辑上动刀。
4.2 产品级 Agent 的解法:把职责拆开
pi 用 pi-agent-core 把上面那团毛线拆开。核心思路是:把循环控制 留给 runAgentLoop(),把状态消费 改为事件订阅,把工具执行 改成独立的 AgentTool 对象。Agent 类再把生命周期、消息队列、外部订阅串起来。
事件订阅在代码里长这样:
ts
import { Agent } from "@earendil-works/pi-agent-core";
const agent = new Agent({ model, tools, systemPrompt: "..." });
agent.subscribe((event) => {
if (event.type === "tool_execution_start") {
console.log(`🔧 ${event.toolName}(${JSON.stringify(event.args)})`);
}
if (event.type === "tool_execution_end") {
console.log(event.isError ? "❌" : "✅", event.result);
}
});
await agent.prompt("读取 README.md");subscribe 不关心循环怎么跑。它只消费循环抛出来的事件。这样你可以同时挂多个消费者:一个打日志,一个更新 UI,一个写入数据库,互不干扰。
4.3 工具也从 switch 里拆出来
手写循环里的工具执行通常长这样:
ts
if (toolCall.name === "read") {
result = await readFile(args);
} else if (toolCall.name === "edit") {
result = await editFile(args);
}在 pi 里,每个工具都是一个独立的 AgentTool 对象:
ts
import type { AgentTool } from "@earendil-works/pi-agent-core";
import { Type, type Static } from "typebox";
const weatherSchema = Type.Object({
city: Type.String({
description: "City name in English, e.g. Beijing",
}),
});
type WeatherInput = Static<typeof weatherSchema>;
const weatherTool: AgentTool<typeof weatherSchema, { temperature: number }> = {
name: "weather",
label: "Get weather",
description: "Get the current weather for a given city. Use this when the user asks about weather.",
parameters: weatherSchema,
execute: async (_toolCallId, params) => {
const response = await fetch(
`https://api.example.com/weather?city=${encodeURIComponent(params.city)}`,
);
const data = await response.json();
return {
content: [{ type: "text", text: `${params.city} 当前气温 ${data.temperature}°C` }],
details: { temperature: data.temperature },
};
},
};每个工具自己负责:叫什么、需要哪些参数、怎么执行。Agent 类只需要遍历 tools 数组,找到匹配的 name,调用 execute()。新增工具就是新增一个对象,不用改循环。label 是给 UI 显示用的,details 是给日志/审计用的,content 才是给 LLM 看的。
4.4 小结
回头看,从 while 到 Agent 类,本质是把循环控制、状态消费、工具执行三件事彻底分开。分开之后,加日志、换 UI、持久化消息、并行工具、中途取消------这些需求各自落在自己的位置上,不用再来回改循环。
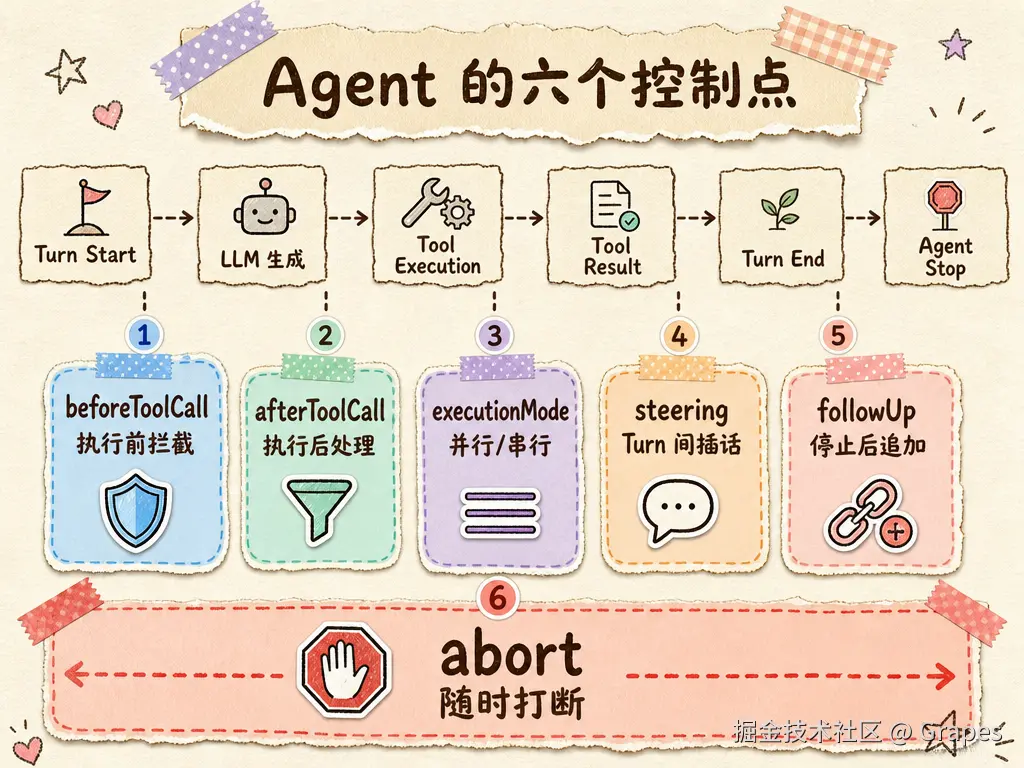
5. Agent 的六个控制点
当 Agent 真正跑起来之后,你会发现光有一个循环还不够。你需要在关键环节插入自己的逻辑:拦截危险操作、修改工具结果、并行执行多个工具、在回合之间插入新指令,或者在 Agent 本应停止时追加任务,甚至让用户随时打断。pi 提供了六个控制点。
5.1 beforeToolCall:执行前的拦截
在工具真正执行前,可以检查权限、记录日志、甚至拒绝执行。
ts
beforeToolCall: async ({ toolCall }) => {
if (toolCall.name === "bash" && toolCall.args.command.includes("rm -rf /")) {
return { block: true, reason: "危险命令被拒绝" };
}
return { block: false };
}这是产品化的第一道安全门。没有它,Agent 调用 bash 就像直接给服务器开 shell,风险极高。
5.2 afterToolCall:执行后的后处理
工具执行完后,可以修改结果、补充上下文、或者决定要不要让 LLM 继续。
比如 read 返回的文本太大,你可以在 afterToolCall 里再做一层压缩,或者把敏感信息脱敏后再交给 LLM。
5.3 executionMode:并行与串行
LLM 一次可以返回多个 toolCall。如果它们之间没有依赖关系,就可以并行执行,节省时间。
ts
executionMode: "parallel" // 或 "sequential"parallel:多个工具同时跑,适合独立查询sequential:按顺序跑,前一个结果可能影响后一个
这个选择直接影响 Agent 的延迟和正确性,是工程上必须显式决定的事情。
5.4 steering:Turn 之间插话
Agent 的每次循环叫一个 Turn 。steering 允许你在 Turn 结束后、下一次 LLM 调用前,向消息队列中插入一条"系统插话"。
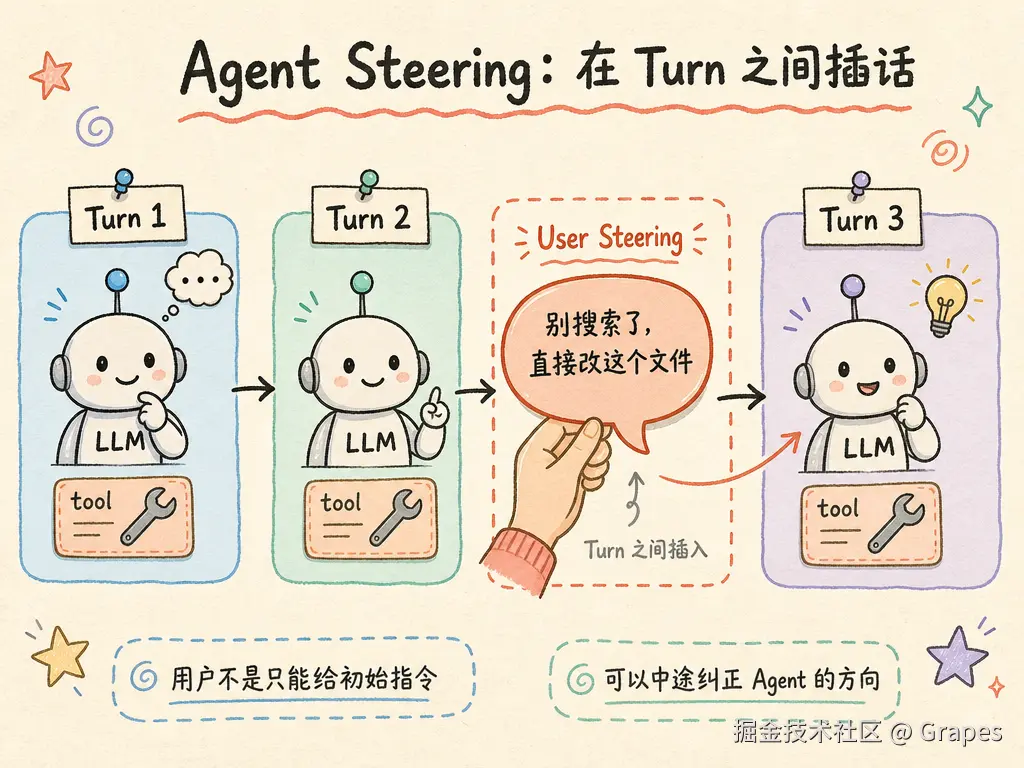
应用场景:用户看到 Agent 走了弯路,可以在中间说"别搜索了,直接改这个文件"。这条插话会被塞进 messages,影响下一轮的生成。
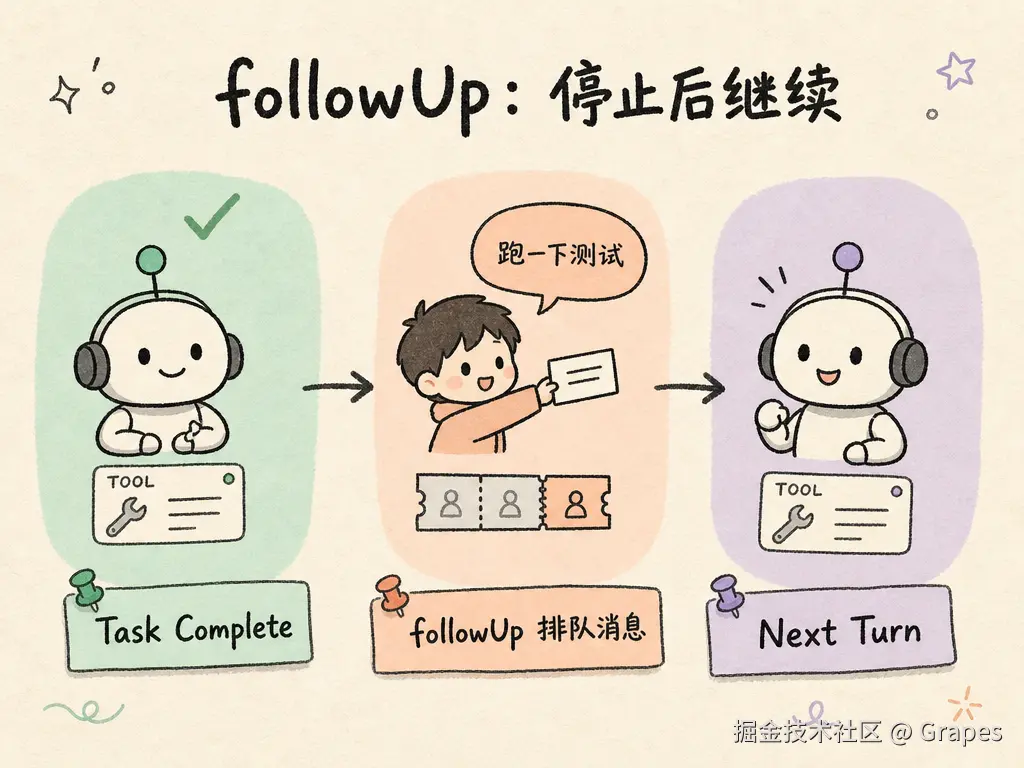
5.5 followUp:停止后继续
Agent 正常完成任务后会停下来。但有时候你并不想它停,而是想追加一个相关任务。
followUp 是用户提前排好的消息队列。比如用户在 Agent 跑的时候输入了下一条指令,这条指令不会立刻打断当前任务,而是排队等着------等 Agent 完成当前任务准备停下来时,这条排队的消息会被投递进去,让 Agent 进入下一轮。
它和 steering 的区别在于时机:steering 是在 Turn 之间插话,Agent 还在跑;followUp 是在 Agent 即将停下来时追加,让它继续。一个管纠偏,一个管续跑。
5.6 abort:用户打断 Agent
前面提到的 AbortSignal 不是装饰。它贯穿整个 Agent 生命周期:LLM 请求、工具执行、状态转换,任何一个时刻都可以被触发。
比如用户按下 Ctrl+C,或者 UI 上点击停止按钮:
ts
const controller = new AbortController();
agent.prompt("修复 bug", { signal: controller.signal }).catch(err => {
if (err.name === "AbortError") {
console.log("用户已取消");
}
});
// 用户点击停止
controller.abort();pi 的 agent-loop.ts 在流式响应阶段就监听了 AbortSignal。一旦用户触发 abort,流式请求会立刻停止。
那条生成了一半的 assistant 消息不会被丢弃。流式响应一开始,partial message 就已经存在于 messages 里了;abort 发生时,它被原地标记成最终形态------stopReason 变成 "aborted",带上 errorMessage,已生成的文本保留不动。然后循环直接结束。
我在本地用 DeepSeek API 跑了一下:让模型写一首秋天的长诗,在它写到一半时触发 abort。保留在上下文里的消息长这样:
json
{
"role": "assistant",
"content": [
{ "type": "text", "text": "## 《秋的咏叹调》\n\n西风开始梳理梧桐的" }
],
"stopReason": "aborted",
"errorMessage": "Request was aborted"
}诗写到"梧桐的"就断了,但已生成的内容完整保留。如果丢弃半残消息,用户 abort 后想继续对话(比如用 followUp 追问),LLM 会看到一条凭空消失的记录------上一秒还在写诗,下一秒 messages 里什么都没有,它的行为会变得不可预测。保留半残消息,LLM 就能看到"我之前写了一半被打断了",自然地续写或切换话题。
已经发出的 tool 调用不会被继续执行。AbortSignal 会贯穿 LLM 请求、工具执行、文件读写和 bash 进程,一路把相关资源干净地释放掉。
5.7 小结
这六个控制点覆盖了 Agent 执行过程中最关键的干预位置:
| 控制点 | 位置 | 作用 |
|---|---|---|
| beforeToolCall | 工具执行前 | 权限、拦截、审计 |
| afterToolCall | 工具执行后 | 后处理、脱敏、补充 |
| executionMode | 工具调用策略 | 并行或串行 |
| steering | Turn 之间 | 中途插话、纠偏 |
| followUp | Agent 停止后 | 追加任务、链式执行 |
| abort | 任意时刻 | 用户中断、资源释放 |
6. Mini Coding Agent:让工具对 LLM 更友好
前面我们讲了 LLM API、SSE、Tool Calling、Agent Loop 和控制点。现在把这些拼起来,做一个能读文件、修 bug、跑命令的 Mini Coding Agent。
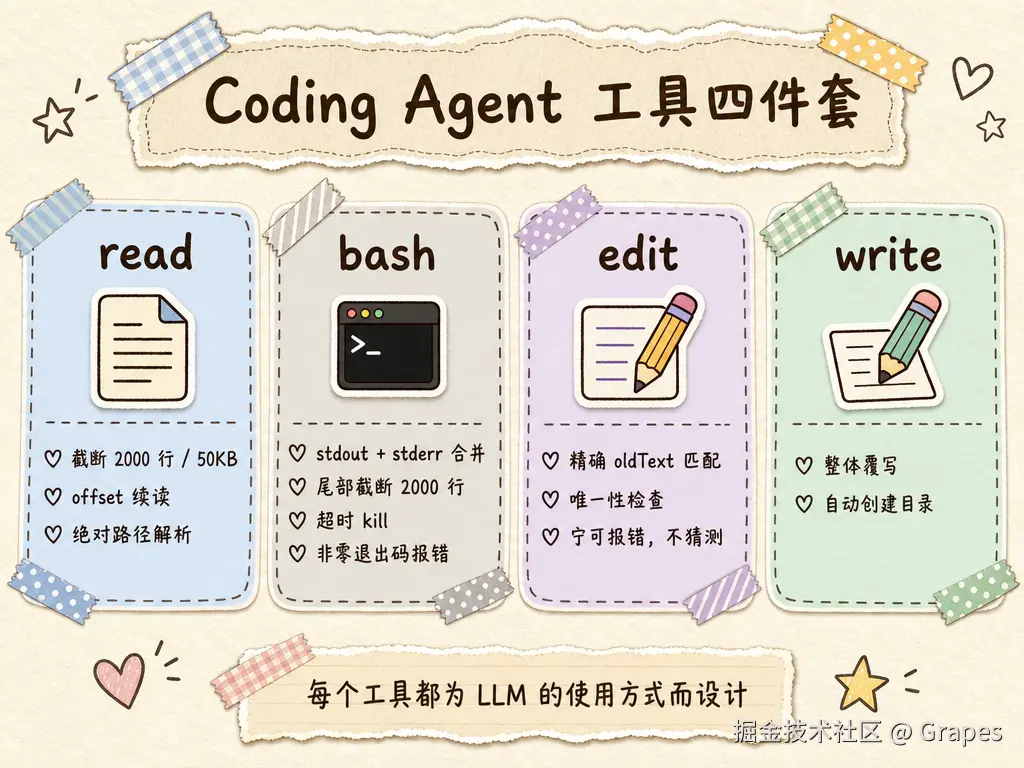
这个 Agent 用了哪些工具其实不稀奇------read、write、edit、bash,四件套。我想讲的是另一件事:为什么这些工具的接口长这样。后面会看到,工具接口的设计对稳定性的影响,比模型本身大得多。
6.1 四件套工具
Coding Agent 最常用的四个工具:
read:读取文件write:写入文件edit:精确修改文件bash:执行命令
它们看起来简单,但每一个接口都经过了仔细设计------不是为了让人类用着顺手,而是为了贴合 LLM 的能力边界。
说实话,在读 pi 的源码之前,我从来没想过这几个工具能这么复杂。一个 read 不就是读文件,一个 bash 不就是跑命令吗?但真钻进去看,每个都藏着工程问题:文件太大怎么截断才不撑爆上下文、中文字符怎么算字节数、失败时怎么给 LLM 一条退路。决定 Agent 稳不稳的,是这些工具接口有没有被认真打磨过。
6.2 read:让 LLM 能处理大文件
人类读代码时习惯直接 cat 整个文件。但 LLM 的上下文有限,一个几百 KB 的文件直接塞进去会爆上下文。read 的设计是:
ts
const readSchema = Type.Object({
path: Type.String({
description: "Path to the file to read (relative or absolute)",
}),
offset: Type.Optional(Type.Number({
description: "Line number to start reading from (1-indexed)",
})),
limit: Type.Optional(Type.Number({
description: "Maximum number of lines to read",
})),
});关键设计:
- 截断:输出限制在 2000 行或 50KB,哪个先达到就按哪个截断
- 按真实字节统计 :50KB 不是用字符串
.length算的,而是用Buffer.byteLength统计 UTF-8 字节数。这有个容易踩的坑------下面专门讲 - 可继续提示 :截断时返回
Use offset=... to continue - 绝对路径解析:所有相对路径基于 cwd 解析,避免 LLM 在路径上犯错
为什么 50KB 要用 Buffer 而不是字符串 .length 来统计?这要从 JavaScript 字符串的底层说起。
JavaScript 的字符串在内存里是 UTF-16 编码的。.length 统计的是 UTF-16 码元(code unit)的数量,不是字节数,也不是"字符数"。大多数情况下一个字符占 1 个码元,所以 .length 看起来像在数字符。但一旦遇到多字节字符,这个直觉就错了:
arduino
"hello".length // 5 → UTF-8 实际 5 字节
"你好".length // 2 → UTF-8 实际 6 字节(每字 3 字节)
"😀👋".length // 4 → UTF-8 实际 8 字节(每个 emoji 4 字节)英文一个字符 1 字节,中文一个字符 3 字节,emoji 一个字符 4 字节。但 .length 把它们都当成长度 1 或 2。如果用 .length 来判断 50KB 限制,中文文件会被严重低估------一个 13000 字的中文文件,.length 看起来才 13K,实际 UTF-8 已经 38KB 了。反过来,如果用 .slice(0, N) 按字符数截断,你以为截了 6 个"单位",实际 UTF-8 可能已经 10 字节以上。
pi 的做法是先读成 Buffer(原始字节),再用 Buffer.byteLength(content, "utf-8") 算出真实字节数。这样不管是中文、英文还是 emoji,统计的都是它在网络上传输、在磁盘上存储时的真实大小,50KB 的限制才有意义。
ts
// 来自 pi 的源码片段
const buffer = await ops.readFile(absolutePath);
const textContent = buffer.toString("utf-8");
// ... 应用 offset/limit ...
const truncation = truncateHead(selectedContent);truncateHead 是"保留头部"的截断:文件内容按行切分,从头开始保留,直到达到行数或字节上限。如果第一行就超过 50KB,它会直接告诉模型用 bash 命令读取:[Line 1 is 60KB, exceeds 50KB limit. Use bash: sed -n '1p' file | head -c 51200]。
这种错误信息不是给人类看的,而是给 LLM 看的。它让 LLM 知道:当前工具走不通,但可以用另一个工具继续。这就是"可操作的错误信息"。
6.3 bash:让 LLM 拿到可执行的结果
bash 和 read 正好相反:文件读取是从头开始,所以保留头部;bash 输出通常是日志或命令结果,关键信息在末尾。所以 bash 用 truncateTail:保留最后 2000 行或 50KB。 这个设计很巧妙,因为命令失败时,错误信息通常出现在最后。如果一个测试命令跑了 10 万行输出,最后几行是报错摘要,保留尾部能让 LLM 直接看到关键信息。
ts
const bashSchema = Type.Object({
command: Type.String({
description: "Bash command to execute",
}),
timeout: Type.Optional(Type.Number({
description: "Timeout in seconds (optional, no default timeout)",
})),
});关键设计:
- 合并 stdout + stderr:LLM 只需要知道命令输出,不需要区分管道
- 超时 kill:可选 timeout,防止命令卡死
- 尾部截断:保留最后 2000 行或 50KB
- 非零退出码报错:LLM 能立刻知道命令失败了
- 截断时保存完整输出到临时文件:如果输出超过限制,会提示 LLM 完整输出路径
6.4 edit:宁可报错,也不猜测
人类编辑代码可以用"替换第 5 行"这种模糊描述,但 LLM 没有行号视觉。edit 要求提供精确的 oldText:
ts
const replaceEditSchema = Type.Object({
oldText: Type.String({
description: "Exact text for one targeted replacement. It must be unique in the original file.",
}),
newText: Type.String({
description: "Replacement text for this targeted edit.",
}),
});
const editSchema = Type.Object({
path: Type.String({
description: "Path to the file to edit (relative or absolute)",
}),
edits: Type.Array(replaceEditSchema),
});pi 的实现会先尝试精确匹配,再尝试模糊匹配。但无论如何,它都会检查:
oldText必须存在oldText在文件中必须唯一- 多个
edits之间不能重叠
宁可在 LLM 调用失败时返回清晰错误,也不让它猜测着改。猜测会破坏代码,而错误信息可以被 LLM 自己读到,然后重新调用。
6.5 统一返回结构:content 给 LLM,details 给系统
每个工具都返回同样的结构:
ts
interface AgentToolResult<T> {
content: (TextContent | ImageContent)[]; // 给 LLM 看的自然语言结果
details: T; // 给 UI/日志/审计用的结构化数据
}这个设计把"LLM 可读性"和"系统可观测性"分开。content 用自然语言描述结果,让 LLM 理解;details 保留原始状态,给日志、UI、错误分析使用。
6.6 完整可运行的 Mini Coding Agent
下面是一份完整的代码。你在本地新建一个目录,初始化项目,安装依赖,配置 API key,然后运行 tsx main.ts 即可。
ts
// main.ts
import { Agent } from "@earendil-works/pi-agent-core";
import { builtinModels } from "@earendil-works/pi-ai";
import { createReadTool, createEditTool, createBashTool } from "@earendil-works/pi-coding-agent";
import { existsSync, writeFileSync } from "node:fs";
// 1. 创建测试文件
const buggyCode = `function add(a: number, b: number): number {
return a - b; // 应该是 a + b
}
console.log(add(2, 3));
`;
if (!existsSync("buggy.ts")) {
writeFileSync("buggy.ts", buggyCode, "utf-8");
}
// 2. 配置模型(需要设置对应的环境变量,如 DEEPSEEK_API_KEY)
const models = builtinModels();
const model = models.getModel("deepseek", "deepseek-v4-flash");
// 3. 创建工具
const cwd = process.cwd();
const tools = [
createReadTool(cwd),
createEditTool(cwd),
createBashTool(cwd),
];
// 4. 创建 Agent
const agent = new Agent({
model,
tools,
systemPrompt: `你是一个严谨的 Coding Agent。每次只执行必要工具,任务完成后用中文说明结果。`,
beforeToolCall: async ({ toolCall }) => {
// 只靠字符串和正则表达式匹配,其实是远远不够的,因为很容易就能被绕过
if (toolCall.name === "bash" && /rm\s+-rf\s*\//.test(String(toolCall.args.command))) {
return { block: true, reason: "危险命令被拒绝" };
}
return { block: false };
},
});
// 5. 订阅事件,观察运行过程
agent.subscribe((event) => {
if (event.type === "tool_execution_start") {
console.log(`🔧 ${event.toolName}(${JSON.stringify(event.args)})`);
}
if (event.type === "tool_execution_end") {
console.log(event.isError ? "❌" : "✅", event.result);
}
});
// 6. 启动任务
async function main() {
await agent.prompt(
"读取 buggy.ts,找出 bug 并修复,然后运行 npx tsc --noEmit 验证。"
);
const messages = agent.state.messages;
const last = messages[messages.length - 1];
console.log("\n最终结果:");
console.log(last.content);
}
main().catch(console.error);
bash
# 初始化项目
mkdir mini-coding-agent && cd mini-coding-agent
npm init -y
npm install typescript tsx @earendil-works/pi-ai @earendil-works/pi-agent-core @earendil-works/pi-coding-agent
npx tsc --init
# 设置 API key(以 deepseek 为例)
export DEEPSEEK_API_KEY="your-api-key"
# 运行
npx tsx main.ts实际运行后,终端输出(简化版输出):
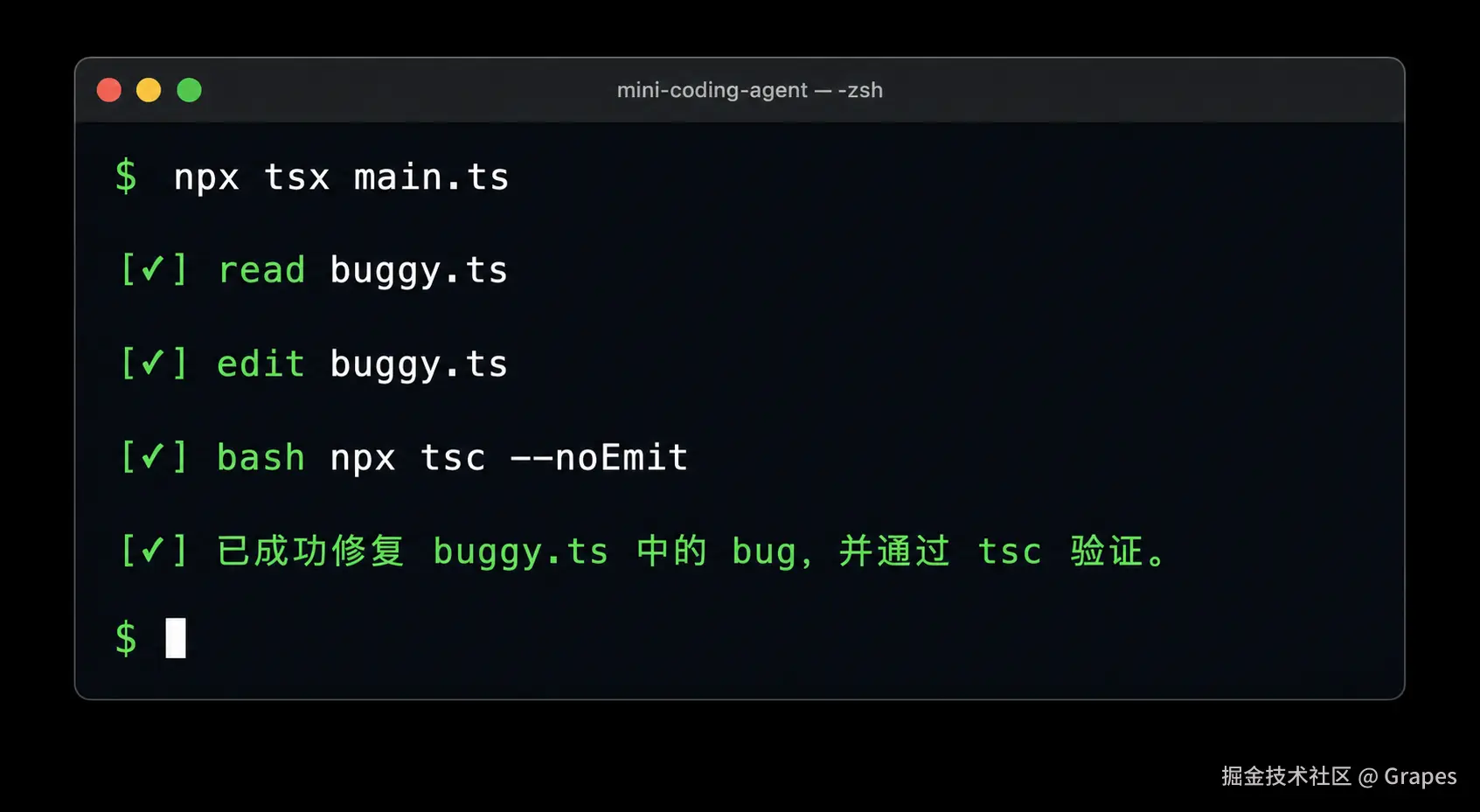
回头看,每个工具接口都在解决一个具体问题:read 防爆上下文,bash 保留错误尾部,edit 拒绝模糊匹配。LLM 不是人类,"命令执行失败"这种含糊的输出它根本看不懂,只能猜。
6.7 小结
Mini Coding Agent 就是四件套工具加一个循环。模型负责决策,工具负责执行,决定它稳不稳的,是工具接口有没有被认真打磨过。
pi 体现的工程理念是:Harness 不是给人类工具裹一层壳扔给 LLM,而是照着 LLM 的能力边界重新设计工具接口。
7. 这是专栏的第一篇
这篇文章把一个 Agent 从 LLM API 到能调工具、能完成任务的最小循环走通了。但"能跑通"和"能在真实代码仓库里稳定完成任务"之间,还隔着一整个工程领域。
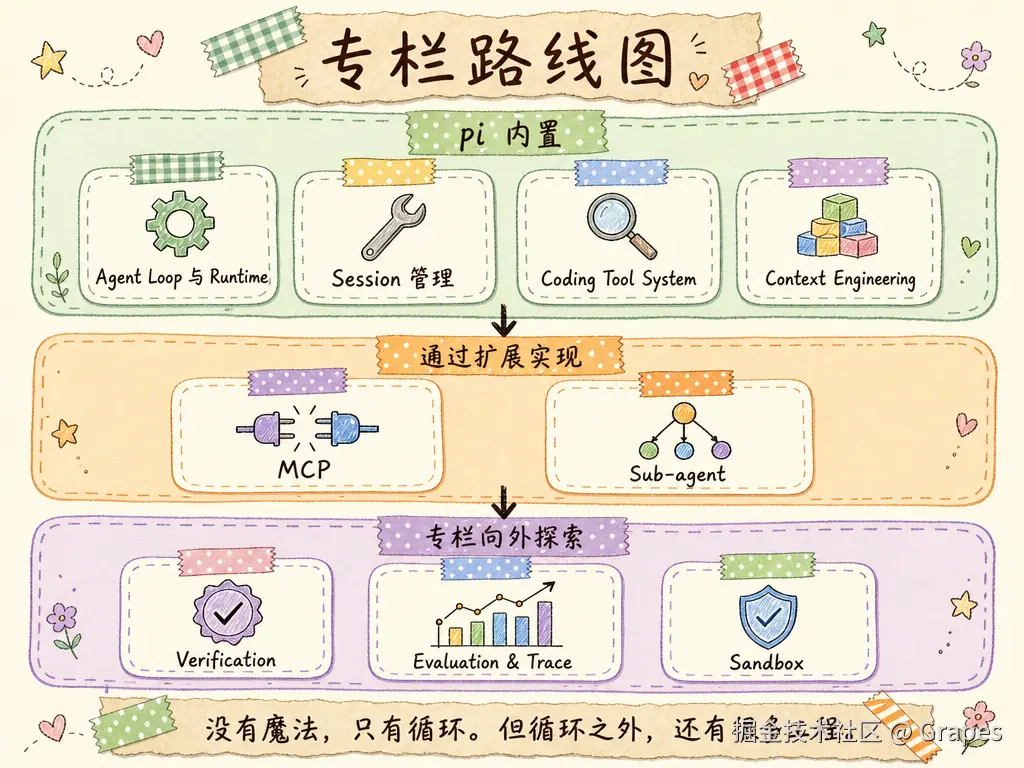
后续专栏会沿着 pi-coding-agent 的实现,把这些方向一个一个拆开:Agent Loop、Session、Coding Tool System、Context Engineering、MCP、SubAgent、Verification、Evaluation & Trace、Sandbox...
这些不全是 pi 的内置功能。pi 的核心很小------四个工具加一个循环,其余靠一套灵活的扩展机制:MCP 和子代理通过扩展接入,沙箱隔离依赖外部方案,验证、评测和会话分支则需要自己搭。这也是这个专栏有意思的地方:我们不只是读 pi 的源码,还会探索那些 pi 没有覆盖的工程问题。
没有魔法,只有循环。但循环之外,还有很多工程。