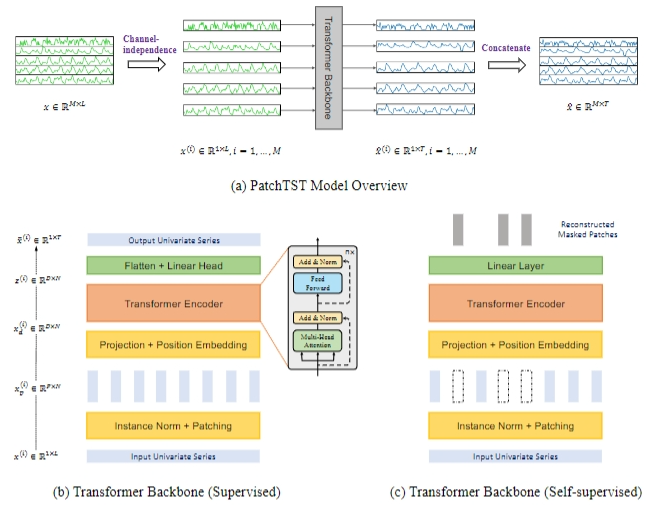
一、patchTST代码理解
1.1 series_decomp
moving_avg低频趋势提取器
这个模块不建模负责的关系,不引入参数,而是去噪,平滑,强化趋势,抑制高频波动,具体步骤如下:
- 输入x: Batch, Input length, Channel,
- 提取首帧x:, 0:1, : # shape: B, 1, C, 尾帧x:, -1:, : # shape: B, 1, C
- 首尾帧扩展padding的长度,k=self.kernel_size, pad = (k - 1) // 2;
- 然后把扩展后的帧进行拼接扩展后的首帧,x,扩展后的尾帧,这个过程就是边界复制,作用:1、防止卷积/平均时边界信息丢失;2、避免zero padding 带来的边缘突变;3、用首尾值延伸序列;
- 将x 由B, L, C 转换为 B, C, L, 然后每个通道上单独做窗口内的平均,不发生通道内的混合。
注意:首尾帧的长度是为了输入长度和输出长度一致!
series_decomp时序分解模块
python
moving_mean = self.moving_avg(x)
res = x - moving_mean
return res, moving_mean这个模块返回趋势项和波动项(高频),拆开是因为,模型希望趋势变化慢,希望波动项变化快。
1.2 PatchTST_backbone
RevIN层
RevIN层的核心作用,就是对每个样本独立计算统计量,然后每个样本、每个通道都进行高斯归一化,这样可以把不同时间序列拉到"同一统计分布",为什么要这样操作,因为时间序列有一个致命的问题,不同样本分布差异巨大,如果不处理,直接喂给transformer,模型就会学到,哪个序列值更大,而不是变化模式
- 输入是x: Batch, Input length,Channel,该模块分为两个模式,一个是norm归一化模式,一个是denorm反归一化模式;
- 如果是norm模式,对输入的B,L,C,每个batch,每个通道上计算时间维度的均值和方差,输出为mean → B, 1, C,std → B, 1, C,注意batch之间不共享;归一化是先减去均值,再除以方差,
- x_减均值 = xB,L,C - meanB, 1, C,
- x_norm = x_减均值B,L,C / stdB, 1, C
- affine_weight 和 affine_bias是可学习的权重,x_final = x_norm * affine_weight + affine_bias
- denorm模式,就是norm模式的反向操作。
Patch层
- 输入是x: Batch, Channel,Input length,进行右边补齐,变为x: Batch, Channel,Input length + stride
- z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride),对时间维度L,做滑动窗口切片,等价于用窗口size=path_len,步长=stride,在时间轴上滑动切片,输出B, C, patch_num, patch_len;
- 维度转换输出B, C, patch_len, patch_num
backbone层
- 数据维度转换,由B, C, patch_len, patch_num 转换为 B, C, patch_num, patch_len;
- 输入数据编码向量化,self.W_P = nn.Linear(patch_len, d_model) ,把每个path映射为d维的向量,输出为: B, C, patch_num, d_model;这里是把时间维度的数据,映射为tokens;
- 位置编码 ,位置编码前,需要将输入数据xB, C, patch_num, d_model转换为uB\*C, patch_num, d_model,位置编码最根本的就是学习这样一个位置编码矩阵Wpos∈RqlenXdmodelW_{pos} \in R^{q_{len} X d_{model}}Wpos∈RqlenXdmodel,其中,q_len:是path的数量,d_model:是Embedding的维度,唯一的区别是,W_pos是如何初始化的,以及是否参与训练,常见的方式有一下几种:例如:zero,特点只有一个维度,然后广播到d_model维度上,参数少
python
W_pos.shape = (q_len,1)
Uniform(-0.02,0.02)例如:zeros,(q_len,d_model),标准Learnable PE 论文常见的一种
python
patch1
[0.01 0.02 ...]
patch2
[-0.01 0.05 ...]
...关键是获得W_pos可学习的矩阵后,u = self.dropout(u + self.W_pos) 数据和位置编码矩阵直接相加,得到带有位置的数据
TSTEncoder编码
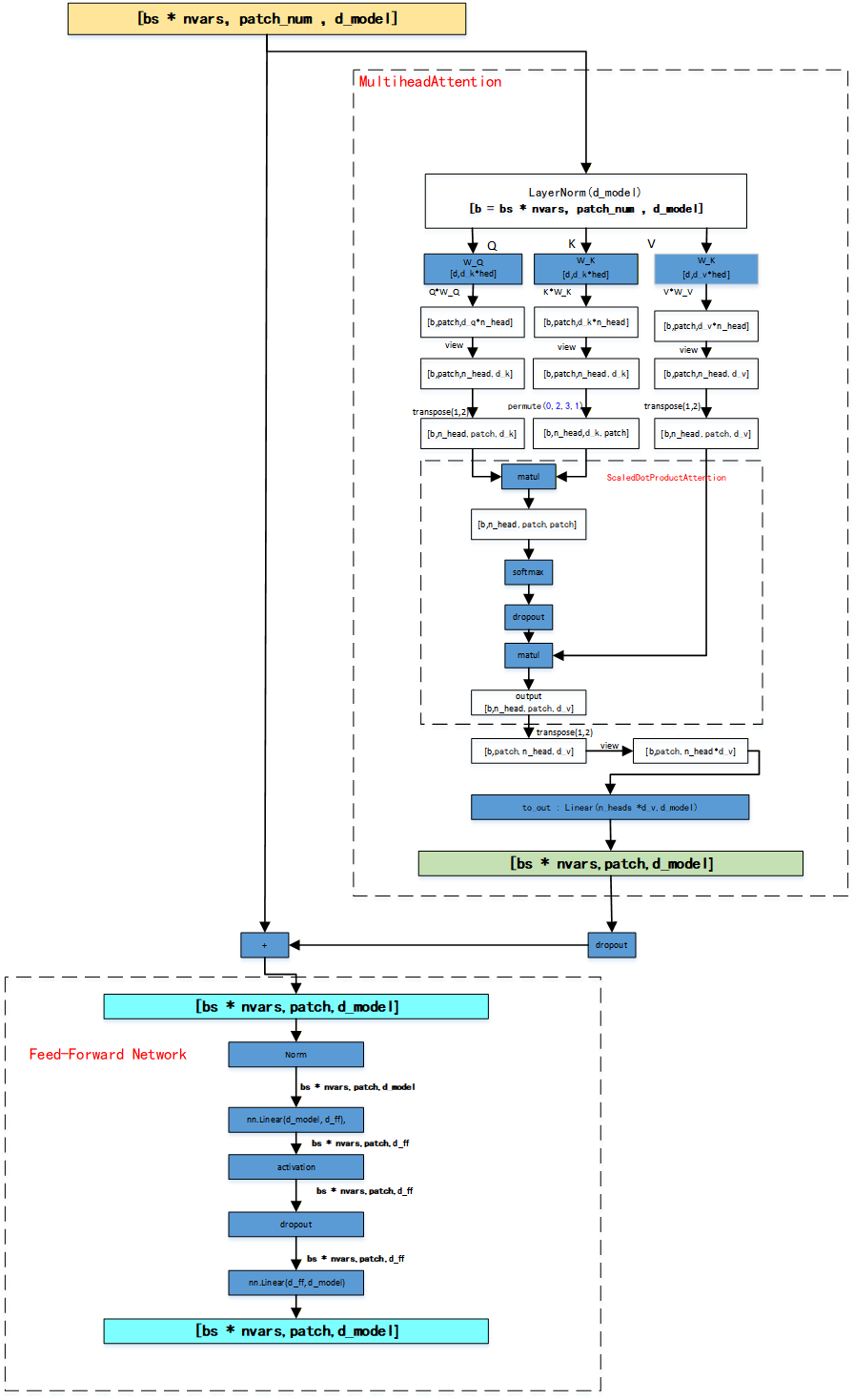
TSTEncoder编码 模块中可以有多个transformer ,每个transformer的输入和输出都是bs\*nars, patch, d_model,编码器结束后,输出尺寸变为:bs,nars, patch, d_model
Prediction Head
作用:把Transformer提取出的高维特征转换城最终需要预测的时间序列,其输入是bs,nars, patch, d_model
有两种方式,
方式1,每个元有独立的预测头:
python
for i in range(self.n_vars):
self.flattens.append(nn.Flatten(start_dim=-2))
self.linears.append(nn.Linear(nf, target_window))
self.dropouts.append(nn.Dropout(head_dropout))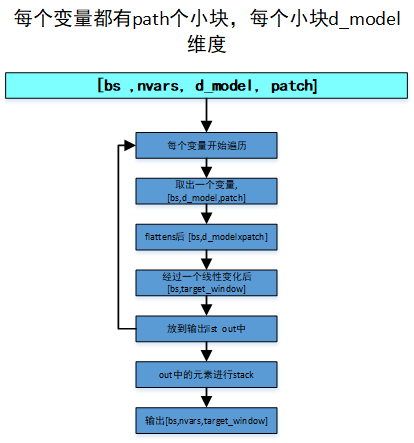
方式二:所有变量共享同一个预测头(论文默认)
python
self.flatten = nn.Flatten(start_dim=-2)
self.linear = nn.Linear(nf, target_window)
self.dropout = nn.Dropout(head_dropout)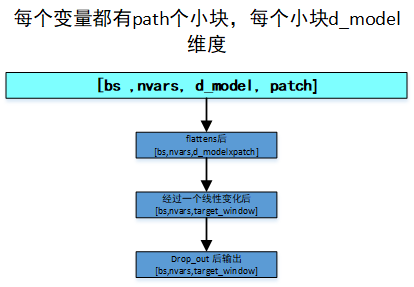
二、论文理解