语音识别(录音与语音播报)
简介
语音识别人工智能技术的应用领域非常广泛,常见的应用系统有:语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;语音控制系统,即用语音来控制设备的运行,相对于手动控制来说更加快捷、方便,可以用在诸如工业控制、语音拨号系统、智能家电、声控智能玩具等许多领域。
语音识别简单来说就是利用计算机语音信号自动转换为文本的一项技术,语音识别技术拆分下来,主要可分为"输入---编码---解码---输出"四个流程。在语音识别中,设备首先收集目标语音,然后对收集到的语音进行一系列处理,得到目标语音的特征信息。这些特征信息包括声学特征和语言特征。声学特征是指语音信号的频谱、功率谱、倒谱等,而语言特征则是指语音信号中的文本内容。接下来,系统会将这些特征信息与数据库中已存数据进行相似度搜索比对,评分高者即为识别结果。
语音识别的原理是将一段语音信号转换成相对应的文本信息,系统主要包含特征提取、声学模型、语言模型以及字典与解码四大部分。其中为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等预处理工作,把要分析的信号从原始信号中提取出来;之后,特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量;声学模型中再根据声学特征性计算每一个特征向量在声学特征上的得分;而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率;最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。
一般来说,语音识别的方法有三种:基于声道模型和语音知识的方法、模板匹配的方法以及利用人工神经网络的方法。
其中,基于声道模型和语音知识的方法是最早被提出来的,它是通过对语音信号进行分析,提取出与语音信号相关的特征参数,然后将这些特征参数与声学模型相结合,从而实现语音识别。传统方法主要分两个阶段:训练和识别,训练阶段主要是生成声学模型和语言模型给识别阶段用。传统方法主要有五大模块组成,分别是特征提取(得到每帧的特征向量),声学模型(用GMM从帧的特征向量得到状态,再用HMM从状态得到音素)、发音字典(从音素得到单词)、语言模型(从单词得到句子)、搜索解码(根据声学模型、发音字典和语言模型得到最佳文本输出。
模板匹配法是将待识别语音与已知的模板进行比较,从而找到最相似的模板,进而实现语音识别。模板匹配的方法是一种传统的语音识别方法,它是基于模板的匹配,即将语音信号与预先存储的模板进行比较,从而得到最佳匹配结果。模板匹配的方法主要分为两类:动态时间规整(DTW)和隐马尔可夫模型(HMM)。其中,DTW是一种基于时间对齐的方法,它可以将两个不同长度的语音信号进行对齐,然后计算它们之间的距离。HMM是一种基于状态转移的方法,它将语音信号建模为一个状态序列,并使用概率模型来描述状态之间的转移。
深度学习的方法是一种新兴的语音识别方法,利用人工神经网络的方法是通过训练神经网络来实现语音识别,它主要是基于神经网络的模型,如卷积神经网络(CNN)、循环神经网络(RNN)和长短时记忆网络(LSTM)等。这些模型可以自动地从原始语音信号中提取特征,并将其转换为高级表示,然后使用这些表示来进行分类或回归。深度学习的方法已经在语音识别领域取得了很大的成功,它们通常比传统方法更准确,并且可以处理更复杂的任务。
实验平台
机器硬件:OriginBot(导航版/视觉版)
扩展硬件:语音扩展版
主机:电脑(Windows >10/ Ubuntu>20.04)
实现
硬件检测、普通录音及播放
首先要确保安装tros和智能算法语音包
sudo apt update
sudo apt install tros-hobot-audio 首先检测硬件环境,将旭日X3派与音频转接板、麦克风阵列拾音板接好之后上电使用如下指令可以检查设备的接入情况,若成功接好,默认可以在I2C上读取到三个地址。如下图:
rmmod es8156
i2cdetect -r -y 0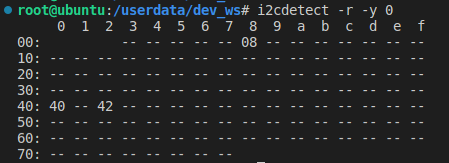
若没检测到,请重新检查设备的连接。然后从TogetherROS的安装路径中拷贝出运行示例需要的配置文件。并且确认麦克风阵列类型,麦克风阵列类型通过配置文件config/audio_config.json中的mic_type字段设置,默认值为0,表示环形麦克风阵列。如果使用线形麦克风阵列,需要修改该字段为1。然后加载音频驱动,设备启动之后只需要加载一次,如果显示modprobe: FATAL: Module snd_card=5 not found。请忽略。
cd /userdata/dev_ws/
# 配置TogetheROS环境
source /opt/tros/setup.bash
# 从tros.b的安装路径中拷贝出运行示例需要的配置文件。
cp -r /opt/tros/lib/hobot_audio/config/ .
# 加载音频驱动,设备启动之后只需要加载一次
bash config/audio.sh 加载驱动音频codec(编解码器)和x3音频框架驱动
sudo modprobe es7210
sudo modprobe es8156
sudo modprobe hobot-i2s-dma
sudo modprobe hobot-cpudai
sudo modprobe hobot-snd-7210 snd_card=5 检测是否加载成功
ls /dev/snd
然后就可以录音播放测试了
rm -rf *test.wav采集4通道麦克风的录音5秒钟:
sudo tinycap ./4chn_test.wav -D 0 -d 0 -c 4 -b 16 -r 48000 -p 512 -n 4 -t 5采集2通道麦克风的录音5秒钟:
sudo tinycap ./2chn_test.wav -D 0 -d 0 -c 2 -b 16 -r 48000 -p 512 -n 4 -t 5可以使用音箱或者3.5mm接口耳塞接入位号U4的插口中听效果,也可以从系统中拉出音频文件至电脑中播放
sudo tinyplay ./2chn_test.wav -D 0 -d 1