万字长文解读claudeCpde/KiloCode 文件处理技术

ClaudeCode 结合 智谱 GLM Coding 完美使用教程: juejin.cn/post/759204...
1. 概述
本文档详细分析了 ClaudeCode/KiloCode 项目中文件处理的核心机制,包括大文件读取策略、多层保护机制、流式读取实现、Token 预算控制和配置化管理。
2. 核心配置项
2.1 文件读取自动截断阈值 (maxReadFileLine)
默认值: 500 行
当文件总行数超过此阈值时,自动截断只读取前 N 行。设置为 -1 或 0 时禁用行数限制;设置为 0 时仅显示代码定义,不读取文件内容。
重要说明 : 当 maxReadFileLine = -1 时:
read_file工具:仍受 Token 预算(60%)限制,文件会被截断- @file 提及文件:不受 Token 预算限制,会读取完整文件内容,可能导致"超出 token"错误
2.2 最大并发文件读取数 (maxConcurrentFileReads)
默认值: 5 个文件
限制 read_file 工具单次请求中最多可以读取的文件数量。
场景示例:
- 用户在会话中提及 6 个文件(如
@file1 @file2 ... @file6) - LLM 生成一个
read_file请求,包含 6 个文件路径 - 因为 6 > 5(默认限制),工具拒绝执行并返回错误
- LLM 需要分批发送请求(如先读 5 个,再读剩下 1 个)
目的: 防止单次请求读取过多文件导致内存溢出或 Token 超出限制。
2.3 Token 预算比例 (FILE_READ_BUDGET_PERCENT)
默认值: 60%(硬编码常量,无用户配置项)
可用上下文窗口的 60% 用于文件读取,剩余 40% 用于模型响应生成。
注意 : 这是一个硬编码的常量,定义在 src/core/tools/helpers/fileTokenBudget.ts 中,没有对应的用户配置项。
2.4 超大文件读取开关 (allowVeryLargeReads)
默认值: false
预留功能,当前在代码中无实际调用点。
3. 文件大小限制策略
3.1 通用文件 Token 限制(80% 限制)- 预留功能
常量 : SIZE_LIMIT_AS_CONTEXT_WINDOW_FRACTION = 0.8(80% 上下文窗口)
重要说明 : 这个 80% 限制是通过 blockFileReadWhenTooLarge() 函数实现的,但该函数当前未被调用,属于预留功能。
实际生效的限制:
- 行数限制 :
maxReadFileLine(默认 500 行) - Token 预算限制 :
FILE_READ_BUDGET_PERCENT(60%)
3.2 allowVeryLargeReads 开关说明 - 预留功能
默认值: false
作用 : 当启用时(allowVeryLargeReads = true),跳过 80% Token 限制检查。
当前状态 : 该配置项在 read_file 工具的执行流程中不被直接使用 。kilocode.ts 中定义的两个函数 summarizeSuccessfulMcpOutputWhenTooLong() 和 blockFileReadWhenTooLarge() 均未被调用。
重要说明:
- 80% 限制(
SIZE_LIMIT_AS_CONTEXT_WINDOW_FRACTION)和 60% Token 预算(FILE_READ_BUDGET_PERCENT)是独立的两层限制 - 即使启用
allowVeryLargeReads,跳过 80% 限制检查,read_file工具仍然使用 60% Token 预算限制 - 所以启用
allowVeryLargeReads后,文件读取仍然受 60% Token 预算限制
3.3 @file 提及文件的处理逻辑
当用户使用 @file 提及文件时,文件内容通过 getFileOrFolderContent 函数读取,该函数调用 extractTextFromFile 提取文本。
执行流程:
less
@file 提及 → getFileOrFolderContent() → extractTextFromFile()maxReadFileLine = -1 时的问题:
| 场景 | read_file 工具 | @file 提及文件 |
|---|---|---|
| maxReadFileLine = -1 | ✅ 受 Token 预算(60%)限制,文件会被截断 | ❌ 不受 Token 预算限制,读取完整文件 |
| 结果 | 安全,不会超出 token | 可能导致"超出 token"错误 |
原因分析:
read_file工具:有 Token 预算计算- @file 提及文件:只检查行数限制,没有 Token 预算检查
建议:
- 对于大文件,避免使用
maxReadFileLine = -1配置 - 使用 @file 提及大文件时,建议配合
line_range参数或使用read_file工具
3.4 详细代码分析
问题根源 :extractTextFromFile 函数在 src/integrations/misc/extract-text.ts 第 96-109 行的逻辑:
javascript
// 第 96-107 行:行数限制检查
if (maxReadFileLine !== undefined && maxReadFileLine !== -1 && maxReadFileLine !== 0) {
const totalLines = await countFileLines(filePath)
if (totalLines > maxReadFileLine) {
// 读取指定行数并返回截断提示
...
}
}
// 第 109 行:无限制时直接读取整个文件
return addLineNumbers(await fs.readFile(filePath, "utf8"))执行流程对比:
| 组件 | 调用位置 | maxReadFileLine = -1 时的行为 | Token 检测 |
|---|---|---|---|
read_file 工具 |
src/core/tools/ReadFileTool.ts:507-604 |
跳过行数限制 → 进入 Token 预算计算 → 调用 readFileWithTokenBudget |
✅ 有 |
extractTextFromFile |
src/integrations/misc/extract-text.ts:109 |
跳过行数限制 → 直接 fs.readFile() 读取完整文件 |
❌ 无 |
影响范围:
-
@file 提及文件 (
src/core/mentions/index.ts:303):scssconst content = await extractTextFromFile(absPath, maxReadFileLine)当
maxReadFileLine = -1时,会读取完整文件内容,可能导致 Token 超出。 -
@folder 提及文件夹 (
src/core/mentions/index.ts:335-357):javascript// absoluteFilePath 是具体文件的路径(文件夹路径 + 文件名) const absoluteFilePath = path.resolve(absPath, entry.name) // 使用 Promise.all 并行读取所有文件 const fileContents = (await Promise.all(fileContentPromises)).filter((content) => content)文件夹内的文件并行读取 ,每个文件都受
maxReadFileLine = -1影响,会读取完整内容。 -
二进制文件提取 (
src/core/tools/ReadFileTool.ts:420):scssconst content = await extractTextFromFile(fullPath) // 不传 maxReadFileLinePDF、DOCX 等文件不传
maxReadFileLine参数,会读取完整内容。
4. 流式读取实现
4.1 按行范围流式读取
使用 Node.js createReadStream 流式读取文件,达到目标行号后立即终止流,不读取剩余内容。内存占用仅与 chunk 大小相关,与文件大小无关。
4.2 行数统计
使用流式读取逐行统计文件总行数。
4.3 增量 Token 计数
流式读取过程中逐步计算 Token 数,可在达到 Token 预算时提前退出。
5. Token 预算控制
5.1 基于 Token 预算的读取
说明 : 这是在 Node.js 进程中读取文件到内存的过程,不是在 LLM 会话中。
缓冲区(lineBuffer) : 内存中的字符串数组,用于临时存储从文件读取的行。
核心算法:
-
逐行读取文件 :使用 Node.js
createReadStream流式读取 -
累积行缓冲 :每读一行放入
lineBuffer,默认累积 256 行 -
暂停读取:达到 256 行时暂停,计算这 256 行的 Token 数
-
检查预算:
- 如果未超出:将 256 行添加到结果,继续读取
- 如果超出:使用二分查找在这 256 行中找到合适的截断点,停止读取
-
返回结果:实际读取的内容、Token 数和完成状态
示例(预算 1000 Token,文件 10000 行):
markdown
第 1 批 256 行 → 300 Token → 累计 300 Token → 继续
第 2 批 256 行 → 300 Token → 累计 600 Token → 继续
第 3 批 256 行 → 300 Token → 累计 900 Token → 继续
第 4 批 256 行 → 300 Token → 累计 1200 Token → 超出!
└─> 二分查找:只保留前 80 行(约 100 Token)
└─> 最终返回:672 行,998 Token5.2 预算计算公式
scss
可用预算 = (上下文窗口 - 最大输出 Token - 已用 Token) × 60%5.3 Token 预算计算和流式读取顺序
执行顺序:
- 先计算 Token 预算:获取模型信息、已用 Token,计算可用预算
- 然后流式读取文件:使用预计算的预算值进行控制
关键点:
- Token 预算是预先计算的,不是边读边计算
- 流式读取时使用预计算的预算值进行控制
- 增量 Token 计数用于在读取过程中判断是否超出预算
6. ReadFileTool 完整流程
6.1 执行流程图
说明:
-
如果 LLM 返回了
line_range参数(如10-50),会优先使用行范围读取 -
代码定义结构:
10--50 | export function myFunction() { ... } 55--120 | class MyClass { ... }
6.2 多层保护机制
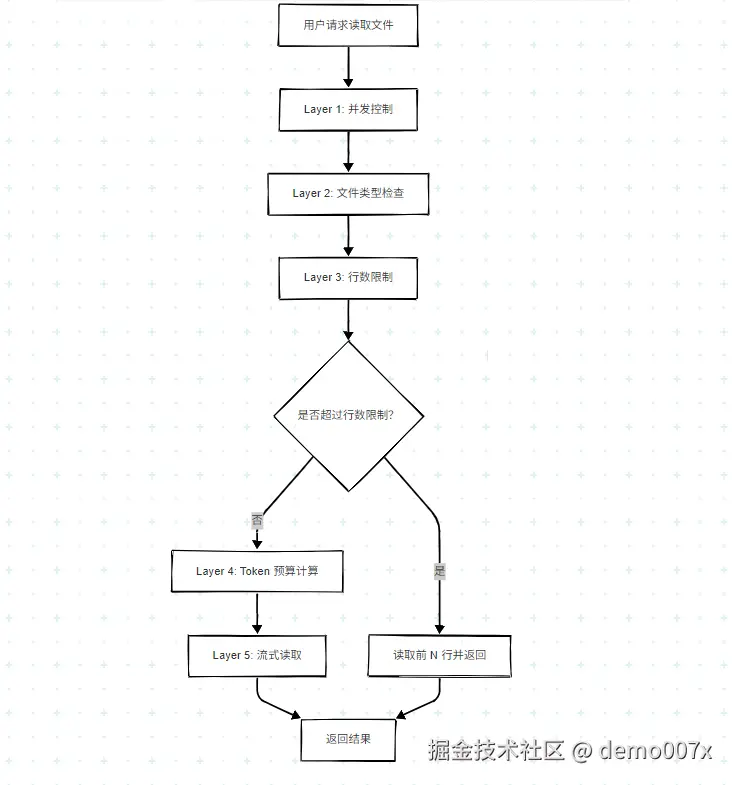
6.3 执行步骤说明
- 解析参数 :从 XML 或 JSON 中提取文件路径和行范围(
line_range) - 获取配置:获取 maxReadFileLine、maxConcurrentFileReads 等配置
- 文件验证:检查是否为目录、统计行数、检测二进制文件
- 行范围检查:如指定行范围,使用 readLines 读取指定行,直接返回
- 行数限制检查:如超过 maxReadFileLine,只读取前 N 行
- Token 预算计算:计算可用预算 = (上下文窗口 - 最大输出 Token - 已用 Token) × 60%
- 流式读取:使用 readFileWithTokenBudget 读取文件
- 返回结果:添加行号、截断提示,返回结果
重要 : 如果 LLM 返回了 line_range 参数(如 10-50),会优先使用行范围读取 ,直接返回指定行内容,不再执行后续的 maxReadFileLine 检查和 Token 预算检查。
6.4 文件验证详细说明
3.1 目录检查
使用 fs.stat() 获取文件状态,通过 stats.isDirectory() 判断是否为目录。如果是目录,返回错误提示建议使用 list_files 工具。
错误提示 : Cannot read 'xxx' because it is a directory. To view the contents of a directory, use the list_files tool instead.
3.2 二进制文件处理
使用 isbinaryfile 库检测文件是否为二进制文件。
分类处理:
- 图片文件 (
.png,.jpg,.jpeg,.gif,.webp,.svg,.bmp,.ico,.tiff,.tif,.avif): 验证大小和内存限制后返回 Data URL - PDF 文档 (
.pdf): 使用pdf-parse提取文本 - Word 文档 (
.docx): 使用mammoth提取文本 - Jupyter Notebook (
.ipynb): JSON 解析提取 cell 内容 - Excel 表格 (
.xlsx): 使用extractTextFromXLSX提取文本 - 其他二进制文件: 返回格式提示
7. LLM 多轮会话文件处理流程
7.1 概述
大文件读取的工具调用流程涉及 LLM 的 Function Call 机制和框架内部工具执行。
7.2 完整流程图
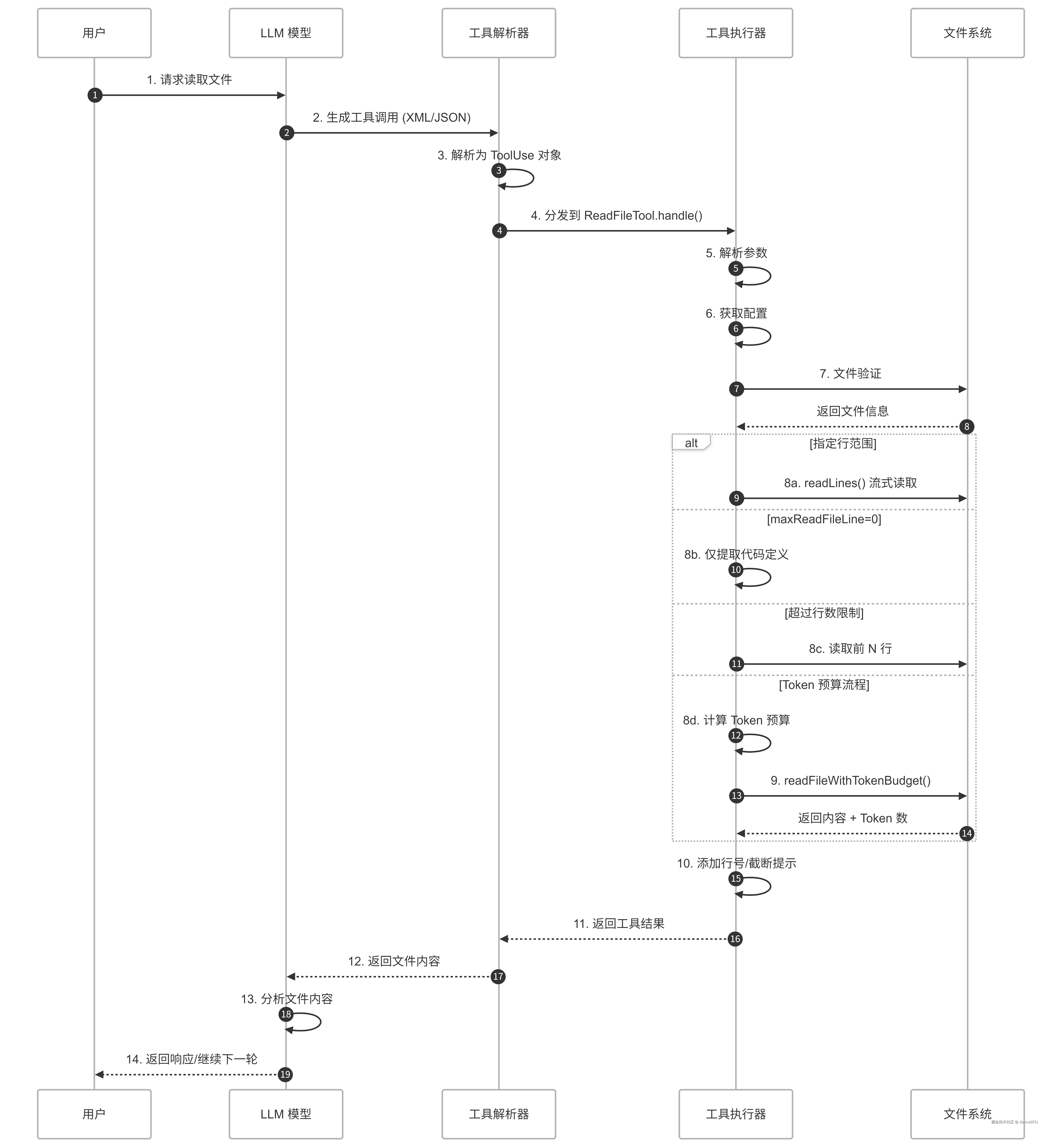
7.3 关键点总结
- 系统 Prompt 决定行为:Prompt 中明确说明了并发限制和行范围用法
- LLM 生成 Function Call:LLM 根据用户请求和上下文决定调用工具
- 工具执行由框架控制:框架负责分发工具调用
- ReadFileTool 独立执行:工具内部逻辑控制整个读取流程
- 配置决定行为:maxReadFileLine 决定截断,Token 预算决定最终读取量
7.4 系统 Prompt 与 LLM 工具执行逻辑
系统 Prompt 的作用
系统 Prompt 是 LLM 行为的决定性因素。在 Kilo Code 中,read_file 工具的描述通过系统 Prompt 传递给 LLM,明确说明了以下关键指令:
实现位置 : src/core/prompts/tools/read-file.ts
系统 Prompt 关键内容
arduino
// 工具描述
Description: Request to read the contents of one or more files.
The tool outputs line-numbered content (e.g. "1 | const x = 1")
for easy reference when creating diffs or discussing code.
// 并发限制指令
**IMPORTANT: You can read a maximum of ${maxConcurrentReads} files in a single request.**
If you need to read more files, use multiple sequential read_file requests.
// 行范围(line_range)使用指令
By specifying line ranges, you can efficiently read specific portions of large files
without loading the entire file into memory.
// 行范围参数说明
- line_range: (optional) One or more line range elements in format "start-end" (1-based, inclusive)
// 高效读取策略
IMPORTANT: You MUST use this Efficient Reading Strategy:
- You MUST read all related files and implementations together in a single operation
- You MUST obtain all necessary context before proceeding with changes
- You MUST use line ranges to read specific portions of large files
- You MUST combine adjacent line ranges (<10 lines apart)
- You MUST use multiple ranges for content separated by >10 lines
- You MUST include sufficient line context for planned modifications while keeping ranges minimalLLM 与工具的交互流程(单对话内单工具调用循环)
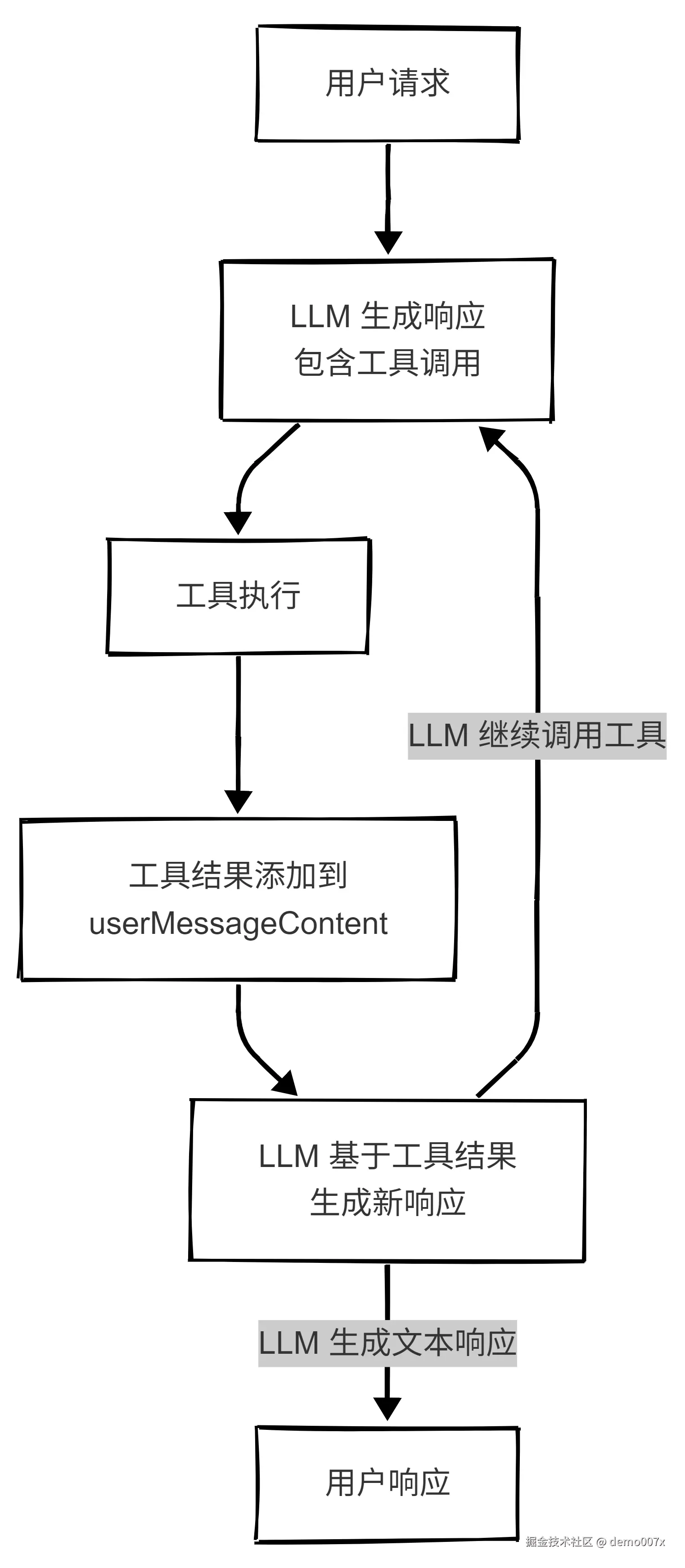
单对话内单工具调用说明:
根据 presentAssistantMessage.ts:535-686 的代码,每个 LLM 响应中只能使用一个工具:
kotlin
// 关键代码:didAlreadyUseTool 标志控制
if (cline.didAlreadyUseTool) {
// 忽略后续工具调用
const errorMessage = `Tool was not executed because a tool has already been used in this message.`
break
}
// 工具执行完成后设置标志
if (toolProtocol === TOOL_PROTOCOL.XML) {
cline.didAlreadyUseTool = true // XML 协议:单工具
} else if (toolProtocol === TOOL_PROTOCOL.NATIVE && !isMultipleNativeToolCallsEnabled) {
cline.didAlreadyUseTool = true // 原生协议:单工具(默认)
}关键特点:
- 单工具限制 :每个 LLM 响应中只能使用一个工具(
didAlreadyUseTool标志控制) - 循环执行:LLM 基于工具结果生成新响应,可以继续调用下一个工具
- 结果累积 :每个工具的执行结果都添加到
userMessageContent中 - 多轮交互:通过"LLM 调用 → 工具执行 → 结果返回 → LLM 再生成响应"的循环完成复杂任务
为什么采用单工具调用设计:
- LLM 响应质量:LLM 应该在使用下一个工具之前,先评估第一个工具的结果。确保 LLM 理解工具返回的内容,避免盲目连续调用工具。
- 错误隔离:每个工具的错误可以独立处理,便于调试和错误恢复。
- 用户确认:某些工具(如写文件、执行命令)需要用户确认后才能执行。
- 结果审查:用户可以在每个工具执行后查看结果,提供更好的可控性。
- Token 和上下文管理:单个工具执行完后,结果会添加到对话历史,LLM 基于累积的结果生成下一个响应,更好地管理上下文窗口使用。
- 批量操作补偿 :
read_file等工具支持批量操作(通过maxConcurrentFileReads配置,默认单次读取 5 个文件),弥补了单工具调用的限制。
7.5 Ask 模式和 Code 模式在文件处理上的区别
在 Kilo Code 中,Ask 模式 和Code 模式是两种不同的工作模式,它们在文件读取行为上有一些重要区别。
模式定义
- Ask 模式 (
ask): 专注于回答问题、提供建议,通常不涉及文件修改 - Code 模式 (
code): 专注于代码编写、修改和文件操作
文件读取行为对比
| 特性 | Ask 模式 | Code 模式 |
|---|---|---|
| 文件读取权限 | ✅ 支持 | ✅ 支持 |
| 文件修改权限 | ❌ 不支持 | ✅ 支持 |
| 默认读取行数限制 | 500 行 | 500 行 |
| 可使用工具 | 有限(只读工具) | 完整(包括写操作工具) |
可用工具对比
Ask 模式可用工具(只读):
read_file- 读取文件内容list_files- 列出目录内容search_files- 搜索文件内容codebase_search- 代码库语义搜索ask_followup_question- 询问用户attempt_completion- 完成任务
Code 模式额外可用工具(包括写操作):
write_to_file- 写入文件apply_diff- 应用代码差异edit_file- 编辑文件(使用 search/replace)fast_edit_file- 快速编辑文件(Morph Fast Apply)execute_command- 执行命令delete_file- 删除文件search_and_replace- 使用搜索和替换应用更改search_replace- 应用单个搜索和替换apply_patch- 应用 codex 格式的补丁browser_action- 使用浏览器use_mcp_tool- 使用 MCP 工具access_mcp_resource- 访问 MCP 资源generate_image- 生成图像update_todo_list- 更新待办列表run_slash_command- 运行斜杠命令
文件读取流程一致性
重要 :无论在 Ask 模式还是 Code 模式下,read_file 工具的核心读取逻辑是完全一致的:
- 都受
maxReadFileLine配置限制 - 都使用相同的 Token 预算计算(60% 剩余上下文)
- 都使用相同的流式读取和增量 Token 计数机制
8. 数据流架构
8.1 整体数据流
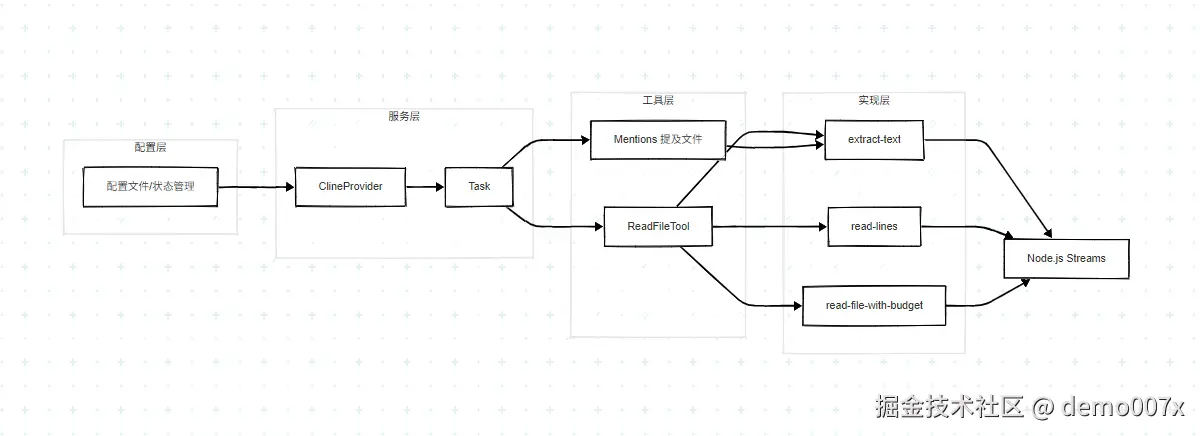
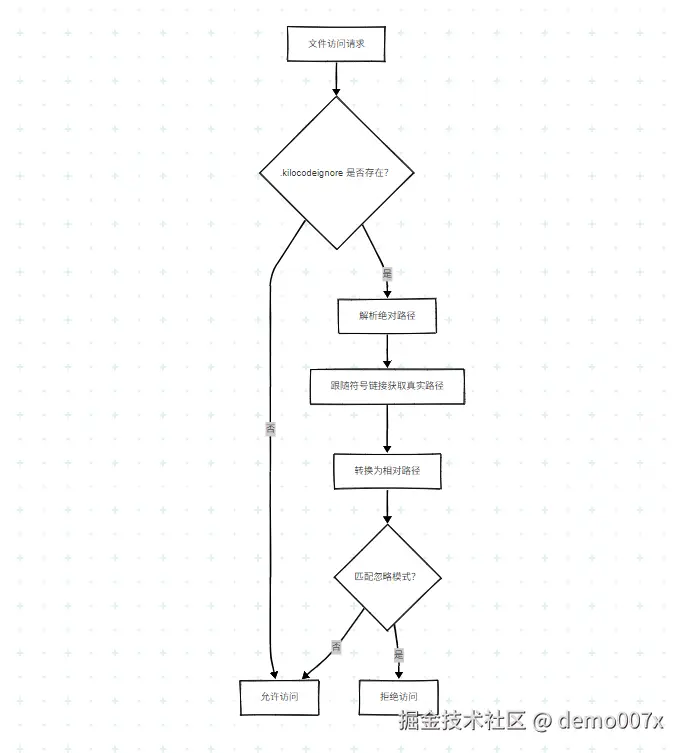
8.2 文件访问控制流程
9. 错误处理策略
| 错误类型 | 处理方式 |
|---|---|
| 目录 | 返回错误提示,建议使用 list_files 工具 |
| 二进制文件 | 支持的格式(PDF/DOCX/XLSX)提取文本,不支持的返回格式提示 |
| Token 预算不足 | 返回空内容并提示无可用预算 |
| 代码定义解析错误 | 不支持的语言静默处理,其他错误记录日志 |
10. 状态跟踪
10.1 文件结果状态
| 状态 | 说明 |
|---|---|
| pending | 初始状态 |
| blocked | 行范围错误或文件访问限制 |
| approved | 用户确认 |
| denied | 用户拒绝 |
| error | 读取过程出错 |
10.2 错误跟踪
- 连续错误计数
- 记录工具错误
- 当前 turn 失败标记
- 拒绝标记
11. 内存保护策略
- 流式读取: 使用 Node.js Streams 逐块读取,避免一次性加载整个文件
- 缓冲批处理: 累积固定行数(默认 256 行)后进行 Token 计数
- 提前终止: 达到 Token 预算时立即终止流
- 并发限制: 限制同时读取的文件数量(默认 5 个)
12. 配置项总结
| 配置项 | 默认值 | 说明 |
|---|---|---|
maxReadFileLine |
500 | 文件读取自动截断阈值(行数),✅ 生效中 |
allowVeryLargeReads |
false | 允许超大文件读取开关,⚠️ 预留功能 |
maxConcurrentFileReads |
5 | 单次请求最多读取文件数,✅ 生效中 |
注意:
allowVeryLargeReads和 80% 限制功能当前未被使用FILE_READ_BUDGET_PERCENT(60%)是硬编码常量,无用户配置项- 实际生效的用户配置项只有
maxReadFileLine和maxConcurrentFileReads
13. 最佳实践建议
13.1 配置建议
| 场景 | 推荐配置 | 说明 |
|---|---|---|
| 常规开发 | maxReadFileLine: 500 |
默认配置,平衡性能和实用性 |
| 大文件分析 | maxReadFileLine: -1 |
禁用行数限制,仍受 Token 预算(60%)限制 |
| 代码审查 | maxReadFileLine: 0 |
仅查看代码定义,不读取内容 |
| 批量文件读取 | maxConcurrentFileReads: 10+ |
增加并发数以提高效率 |
13.2 使用建议
- 优先使用行范围 : 对于大文件,使用
line_range参数精确读取需要的部分 - 批量读取: 相关多个文件一起读取,减少往返次数
- 定义导航 : 使用
maxReadFileLine: 0先查看代码定义,再定位具体位置 - Token 监控: 注意上下文使用情况,避免超出预算
13.3 性能优化
- 流式处理: 所有文件读取都使用流式,避免内存溢出
- 增量计数: Token 计数在读取过程中逐步进行,可提前退出
- 二分查找: 超出预算时使用二分查找找到最佳截断点
- 并发限制: 限制同时读取文件数,防止资源耗尽
14. 相关文件索引
| 文件 | 说明 |
|---|---|
src/core/tools/ReadFileTool.ts |
主要文件读取工具实现 |
src/core/tools/helpers/fileTokenBudget.ts |
Token 预算配置 |
src/core/tools/kilocode.ts |
超大文件读取开关逻辑 |
src/integrations/misc/read-file-with-budget.ts |
基于 Token 预算的流式读取 |
src/integrations/misc/read-lines.ts |
按行范围流式读取 |
src/integrations/misc/line-counter.ts |
行数和 Token 计数 |
src/integrations/misc/extract-text.ts |
文本提取(支持行数限制) |
src/core/webview/ClineProvider.ts |
状态管理和配置 |
src/core/ignore/RooIgnoreController.ts |
文件访问控制 |
src/core/mentions/index.ts |
@file 提及文件处理 |
15. 版本历史
- v5.x : 引入
allowVeryLargeReads配置项(当前未使用) - v5.x : 引入
maxReadFileLine配置项(默认 500 行) - v5.x: 实现基于 Token 预算的流式读取
- 早期版本: 基础流式读取实现
16. 会话历史压缩和截断处理逻辑
16.1 核心概念
消息标签机制:
isSummary: 标记消息是否为摘要condenseId: 摘要的唯一 IDcondenseParent: 指向生成此摘要的原始消息组truncationParent: 指向截断操作的 IDisTruncationMarker: 标记是否为截断标记
有效历史记录 (getEffectiveApiHistory()):
- 通过过滤带有
condenseParent或truncationParent标签的消息 - 只返回实际发送给 API 的消息
- 被压缩/截断的消息仍保留在历史中,但不发送给 API
16.2 滑动窗口截断 (truncateConversation())
流程:
- 过滤出当前可见的消息(未被标记为隐藏)
- 计算需要隐藏的消息数量(保留第一个可见消息)
- 为要隐藏的消息添加
truncationParent标签 - 在隐藏和保留消息之间插入截断标记
- 返回带标签的消息数组
截断标记:
yaml
{
role: "user",
content: `[Sliding window truncation: ${messagesToRemove} messages hidden to reduce context]`,
ts: firstKeptTs - 1,
isTruncationMarker: true,
truncationId,
}16.3 会话摘要压缩 (summarizeConversation())
消息范围确定 (getMessagesSinceLastSummary()):
- 查找最后一个
isSummary=true的消息 - 返回该摘要之后的所有消息(包括摘要)
- 如果没有摘要,返回所有消息
压缩流程:
- 保留最后 N 条消息(默认保留最近的对话)
- 对早期消息调用 LLM 生成摘要
- 创建摘要消息(带
isSummary和condenseId标签) - 为被压缩的消息添加
condenseParent标签
16.4 上下文管理 (manageContext())
触发条件:
csharp
const contextPercent = (100 * prevContextTokens) / contextWindow
if (contextPercent >= effectiveThreshold || prevContextTokens > allowedTokens) {
// 触发压缩
}处理流程:
- 优先尝试智能压缩(调用
summarizeConversation()) - 如果压缩失败或禁用,回退到滑动窗口截断
- 返回处理后的消息数组
16.5 数据流向
scss
完整历史 (apiConversationHistory)
↓
getEffectiveApiHistory() - 过滤被压缩/截断的消息
↓
发送给 API 的有效消息关键点:
- 原始历史始终保留完整数据
- 通过标签控制哪些消息发送给 API
- 支持回滚/删除操作后恢复被压缩的消息
本文档基于 ClaudeCode / KiloCode 项目源代码分析生成,最后更新时间:2026-03-05