|---------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 | 英文名称: MemGPT: Towards LLMs as Operating Systems 中文名称: MemGPT:将LLMs打造成操作系统 链接: https://arxiv.org/abs/2310.08560 代码: https://github.com/cpacker/MemGPT 作者: Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, Joseph E. Gonzalez 机构: 加州大学伯克利分校 日期: 2023-10-12 引用次数: 37 |
1 摘要
- 目的:解决大型语言模型在处理长对话和文档分析等任务时受到有限上下文窗口限制的问题。
- 方法:提出了一种名为虚拟上下文管理的新技术,该技术受到了传统操作系统中分层内存系统的启发,通过在物理内存和硬盘之间进行分页,提供了扩展虚拟内存的假象。
- 结果:在文档分析和多次会话聊天这两个领域,证明了设计的有效性,MemGPT 能够分析远超过 LLM 上下文窗口的大型文档,并能创建能够记忆、反思并通过与用户的长期互动动态进化的对话代理。
2 读后感
作者提出了一种类似于管理计算机内存(内)和磁盘(外)的上下文管理方法 。这种方法的核心在于,能够在无人为干预 的情况下管理自己的上下文内存,解决了 LLM 每次只能思考一步和 token 限制的问题。
可以类比为把 Agent 看作一个记忆力有限的人,把常用的信息记在脑子里,不常用的信息则记在本上,需要时再从本上找。这里的关键技术在于,作者对于什么应该记在脑子里给出了明确的定义 。简单来说,就是近期的具体内容,远期内容的摘要,关键事实,个人偏好和其他重要信息,以及与当前对话相关的从笔记本上找到的内容 。此外,文中还给出了何时应该在笔记本上记录信息,以及何时应该从笔记本上查找信息的具体实现方式。
从用途的角度看,无论是在使用 LLM 聊天,阅读文献,还是编码时,都需要设计在主存储中应存储什么,以及何时应该在外部存储器中存储和查找信息。本文给出了很好的示例。
3 引言
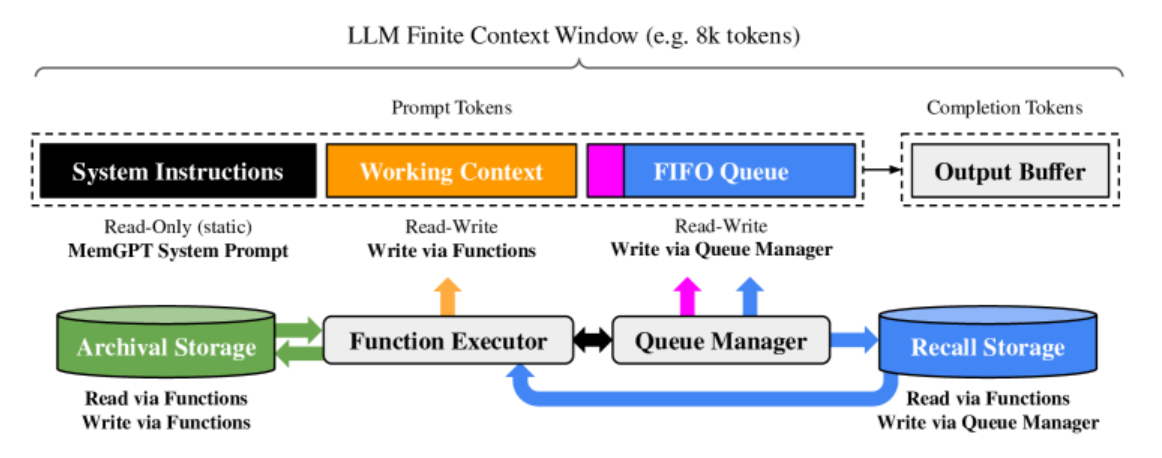
图 -3 中 LLM 可接收的上下文窗口 LLM Finite Context 是有限的,比如 8k;LLM 的输入 Prompt Tokens 由系统指令、工作上下文和先进先出的队列组成;LLM 的输出 Completion Tokens 通过函数执行程序 Function Executor 解释成函数调用。MemGPT 使用函数调用在主上下文和外部上下文之间移动数据。
4 方法
MemGPT 划分了两种主要存储类型:主上下文(类似于主内存/RAM)和外部上下文(类似于磁盘存储)。主上下文由大型语言模型(LLM)的提示标记组成,LLM 在推理过程中可以访问主上下文中的任何内容。外部上下文是指任何存储在 LLM 固定上下文窗口之外的信息。MemGPT 提供了一些功能调用,使 LLM 处理器能够在无需用户干预的情况下管理自己的内存。
4.1 主上下文(Prompt tokens)
MemGPT 的提示标记分为三部分:系统指令(只读,包含控制流程和使用的指令)、工作上下文(非结构化固定大小的文本块,只能通过 MemGPT 函数调用来写入,存储关键信息和用户偏好)、FIFO 队列(记录历史消息,系统警告,函数调用的输入和输出,递归摘要等)。
4.2 队列管理器
队列管理器接收新消息时,将其添加到 FIFO 队列并触发 LLM 进行回应。这些消息和回应都会被保存在一个叫做 Recall Storage 的数据库里。当需要检索这些消息时,队列管理器会将它们重新放回队列,以便 LLM 可以再次访问它们。
队列管理器还负责控制上下文溢出。当队列快满时,它将一个系统消息插入队列,警告 LLM 即将进行队列驱逐,并允许 LLM 将重要信息移动到其他地方(工作上下文或存档存储)。当仓库完全满了(刷新标记计数),管理员会清空一部分仓库(驱逐消息),使用现有的递归摘要和被驱逐的消息生成一个新的递归摘要。被驱逐的消息虽然不能立即查看,但可以在 Recall Storage 中长期保存,并通过 MemGPT 函数调用进行读取。
4.3 函数执行器(Completion tokens)
MemGPT 通过 LLM 处理器生成的函数调用来操作主上下文和外部上下文之间的数据移动。内存编辑和检索完全是自我导向的:MemGPT 会根据当前上下文自主更新和搜索自己的内存。通过指令来实现自主编辑和检索,这些指令指导 LLM 如何与 MemGPT 内存系统交互。指令包括两个主要组件:内存层次结构及其各自实用程序的详细说明,以及系统可以调用以访问或修改其内存的函数模式。
每个推理周期中,LLM 处理器将主上下文作为输入,并生成一个输出字符串。MemGPT 解析这个输出字符串以确保正确性,如果解析器验证了函数参数,那么就会执行该函数。然后,包括任何运行时错误在内的结果都会被 MemGPT 反馈给处理器。这个反馈循环使得系统能够从其行为中学习并相应地调整其行为。
4.4 控制流程和功能链
在 MemGPT 中,各种事件,如用户消息、系统消息、用户交互或定时事件,都能触发 LLM 进行推理。这些事件会被转换成可以添加到主上下文的纯文本消息。有些任务需要按顺序执行多个函数,比如浏览多页查询结果或整理多份文档的数据。MemGPT 能够连续执行多个函数调用,然后再将控制权返回给用户。
5 实验
5.1 用于聊天的 MemGPT
根据以下两个标准评估我们提出的系统 MemGPT:(1)MemGPT 是否利用其内存来提高对话一致性?它能否记住过去互动中的相关事实、偏好和事件以保持连贯性?(2)MemGPT 是否通过利用内存产生更引人入胜的对话?它是否自发地合并远程用户信息来个性化消息?
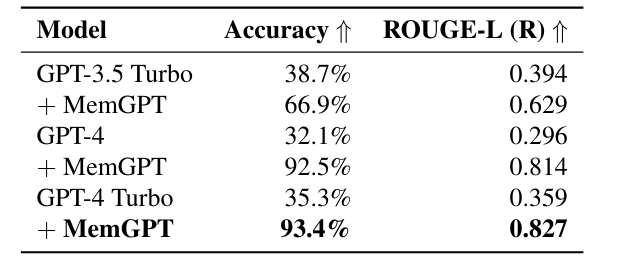
5.2 用于文档分析的 MemGPT
检索器根据 OpenAI 的 text-embedding-ada-002 嵌入上的相似性搜索(余弦距离)选择排名靠前的 𝐾 文档。我们使用 MemGPT 的默认存储设置,该设置使用 PostgreSQL 进行存档内存存储,并通过 pgvector 扩展启用矢量搜索。
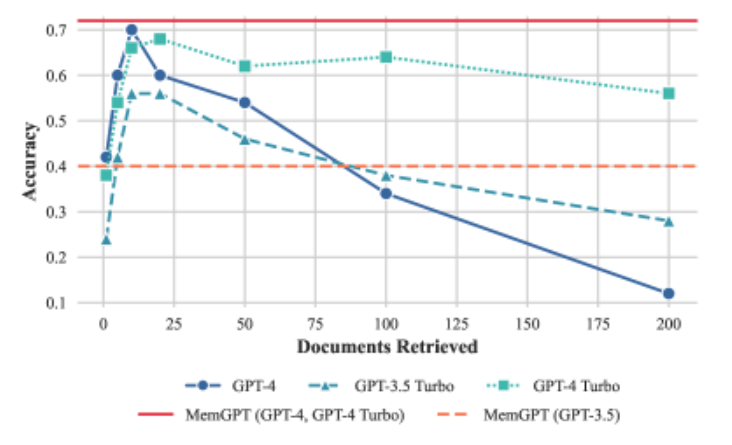
QA 任务执行情况。MemGPT 的性能不受上下文长度增加的影响。