1、内存溢出
内存溢出指的是程序在申请内存时,没有足够的内存可供分配,导致无法满足程序的内存需求,常见的内存溢出情况包括堆内存溢出(Heap Overflow)和栈溢出(Stack Overflow):
- 堆内存溢出通常发生在程序申请的对象过多,堆内存无法满足这些对象的存储需求时。
- 栈溢出则通常发生在方法调用层次过深,导致栈空间耗尽。(例如递归没有正确设置退出条件)
2、内存泄漏
内存泄漏指的是程序在使用完内存后未能正确释放(回收)这些内存,导致程序长时间运行后占用的内存逐渐增加,最终耗尽系统的可用内存,内存泄漏通常是由于程序中存在未释放的无用对象或资源(如文件句柄、数据库连接等)引起的。
简单的说,就是正常情况下,某个对象不再被程序使用的同时,理应不存在GC Root的引用链上,在下一次GC时被回收,而造成内存泄漏的情况下,即使某个对象不再被程序使用,依旧存在于GC Root的引用链上,导致一直无法被回收,最终会导致内存溢出。
3、监控内存
监控内存的方式有很多种,这里介绍一种使用JDK 1.8自带的VisualVM工具(JDK 1.8之后需要自行下载):
位于JDK的bin目录下:

也可以通过IDEA集成VisualVM插件的方式:
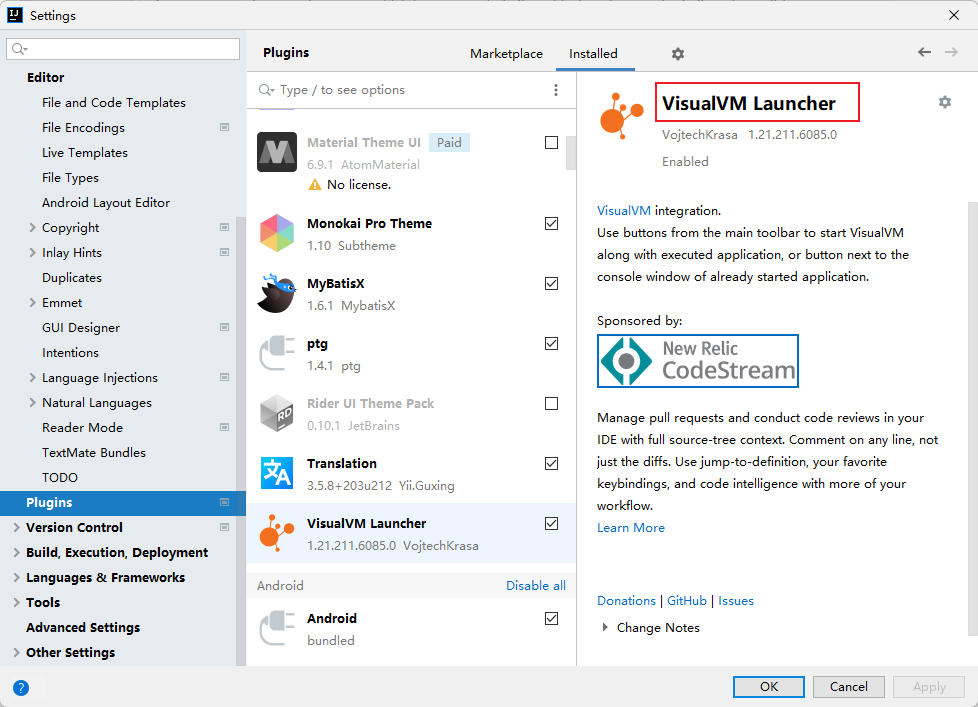
插件安装完毕后需要进行设置,路径为JDK下的bin目录中的文件。
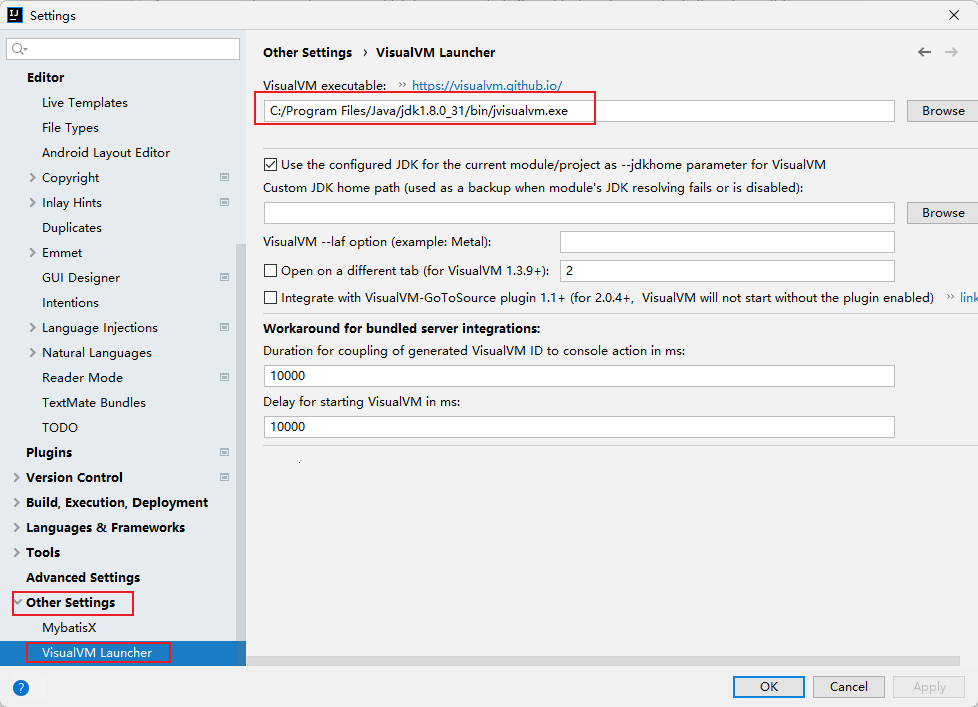
在启动程序时选择:
会自动弹出Visual界面,进行监控:
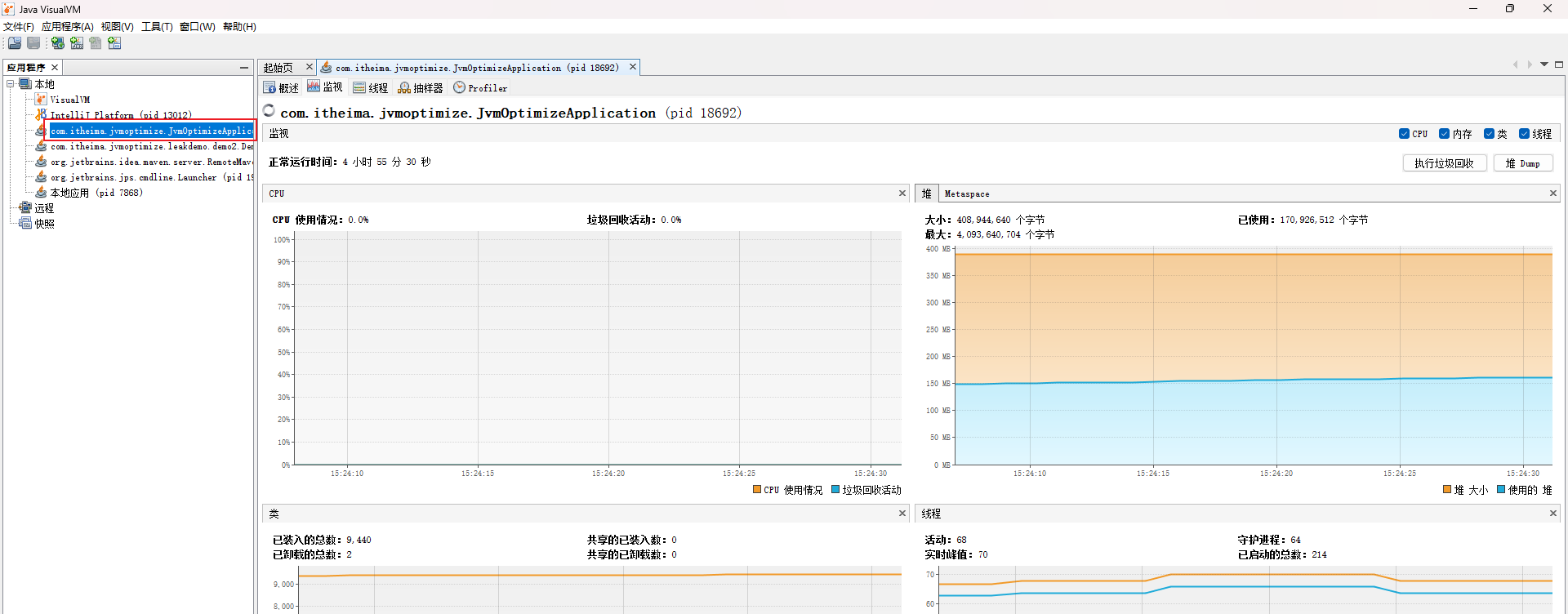
使用案例:
这里有一段程序:
public class Demo0 {
public static long count = 0;
public static void main(String[] args) throws InterruptedException {
while (true){
byte[] bytes = new byte[1024 * 1024 * 5];
}
}
}byte\[\]数组虽然是强引用,但是作用域只是在每次循环中,一旦循环结束,它们就会超出作用域而无法再被访问到,所以不会发生内存溢出,对应的内存图如下:
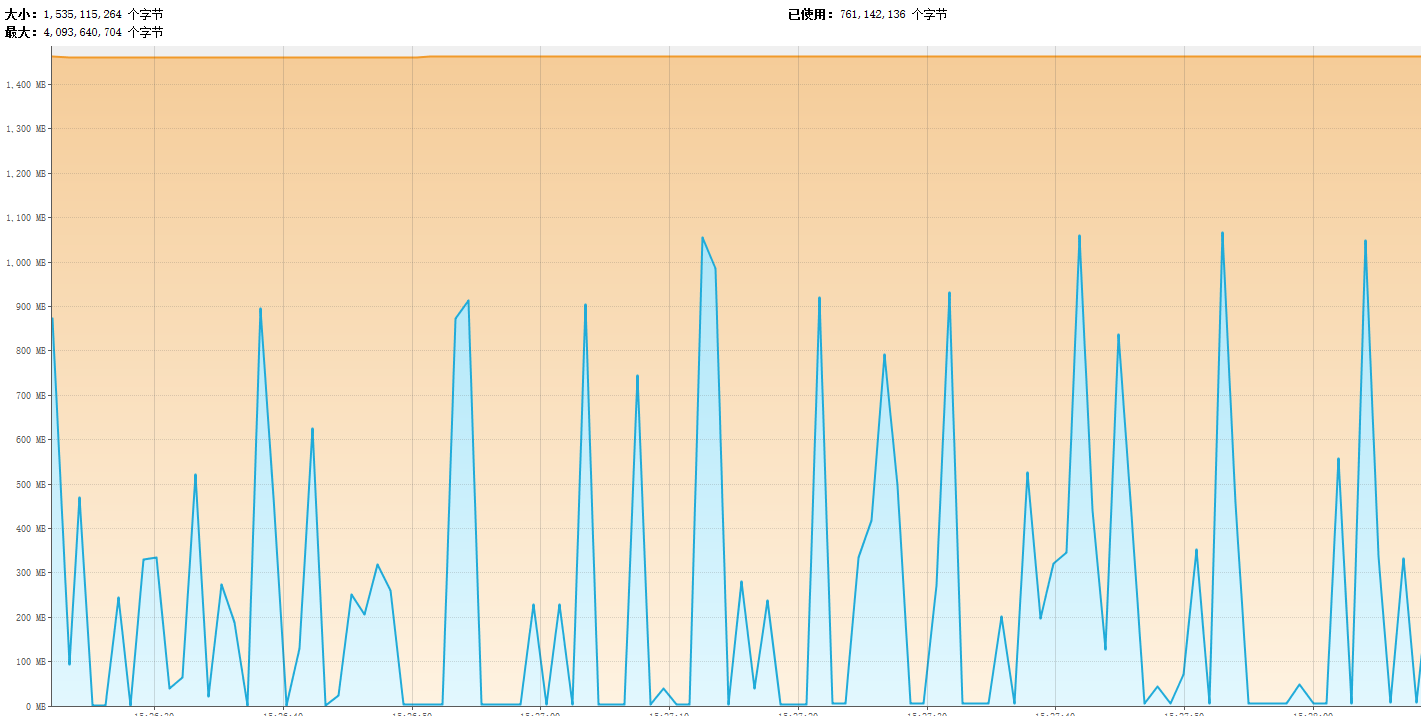
接下来改写一下这个程序:
public class Demo0 {
public static long count = 0;
public static void main(String[] args) throws InterruptedException {
List<byte[]> byteList = new ArrayList<>();
while (true){
byte[] bytes = new byte[1024 * 1024 * 5];
byteList.add(bytes);
}
}
}不同于上一个案例。在循环外创建了一个集合,每次都将循环中的bytes的引用放入集合中,最终集合无法被垃圾回收,导致内存溢出:
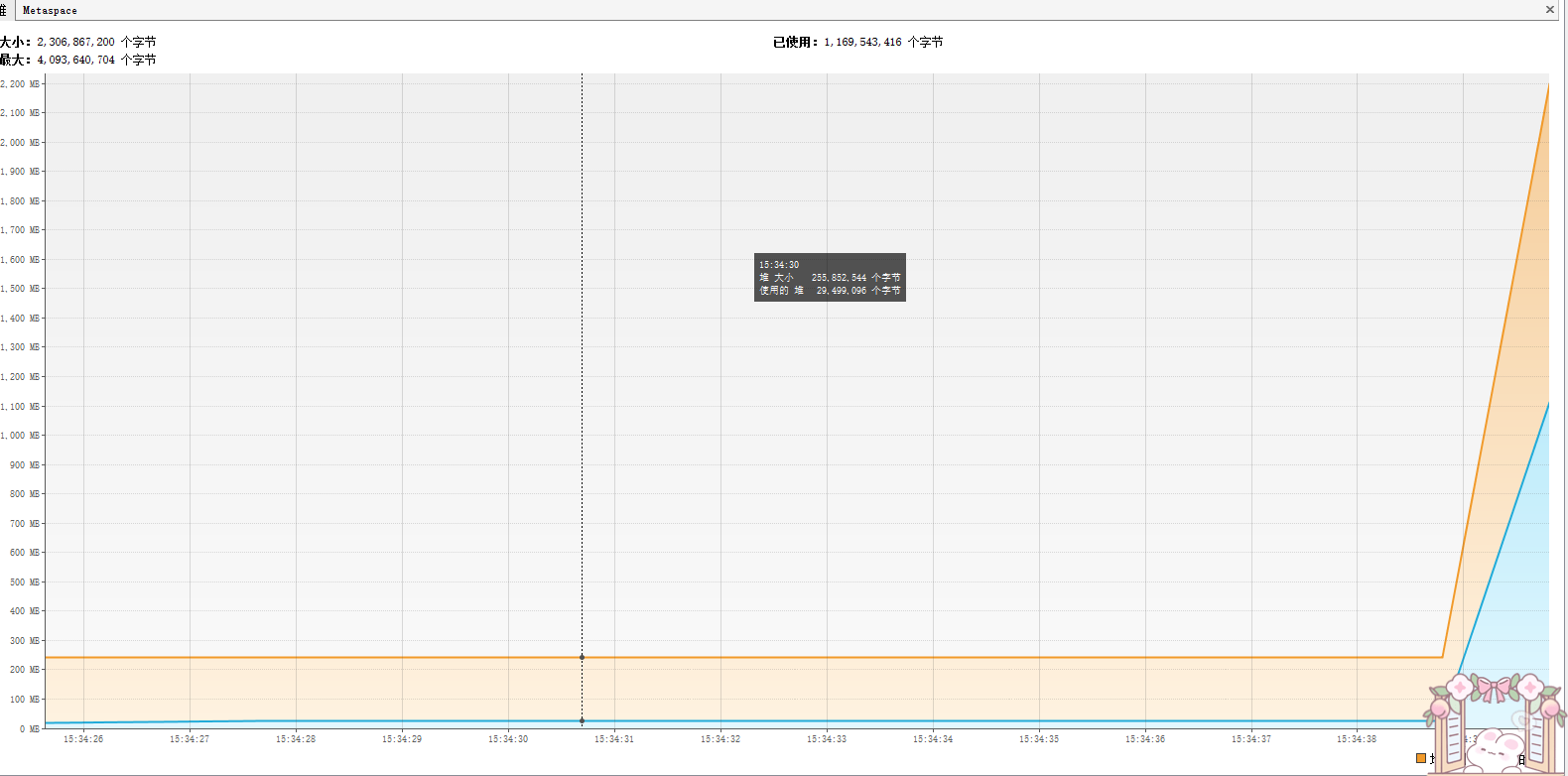
通过上面两种情况,可以发现,在正常情况下,内存曲线应该是在一个固定的范围内起伏的,而内存溢出的情况则是曲线持续增长,即使手动进行GC也无法回收大部分的对象。
4、内存溢出原因分析
在实际应用中,造成内存溢出的原因一般会有两种,第一种是因为代码中的不规范做法/bug,第二种则是因为某个接口同一时间的并发请求过多,而处理速度慢造成的。
代码中的内存溢出:
4.1、未正确重写hashCode()和equals()方法
我现在有一个Student类:
public class Student {
private String name;
private Integer id;
private byte[] bytes = new byte[1024 * 1024];
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
}在主类中通过一个静态HashMap在一个死循环中存放Student对象(关于静态问题后面会分析):
public class Demo2 {
public static long count = 0;
public static Map<Student,Long> map = new HashMap<>();
public static void main(String[] args) throws InterruptedException {
while (true){
if(count++ % 100 == 0){
Thread.sleep(10);
}
Student student = new Student();
student.setId(1);
student.setName("张三");
map.put(student,1L);
}
}
}结果是发生了内存溢出。
要了解为什么上面的做法会导致内存溢出,我们首先复习一下一个元素是如何放入HashMap的,当向 HashMap 中放入一个元素时,会经历以下过程:
- HashMap 会调用键的hashCode()方法来计算键的哈希值。哈希值是用来确定键值对在哈希表中存储位置的重要依据。
- HashMap 会根据计算得到的哈希值和哈希表的大小,确定键值对在哈希表中的存储位置。(通过取模运算记录桶下标)
- 如果存在hash冲突就会进行处理(链表+红黑树),HashMap 将键值对插入到确定的存储位置中,如果存在相同键(根据equals()方法判断),则会更新对应的值。
由此可见,hashCode()和equals()方法在上面的过程中至关重要。如果我们没有重写hashCode()和equals()方法,默认会使用Object类中的,我们可以点进去看一下:
Object中的hashCode() 方法使用的是本地方法,equals()方法使用的是==,比较的是地址值。
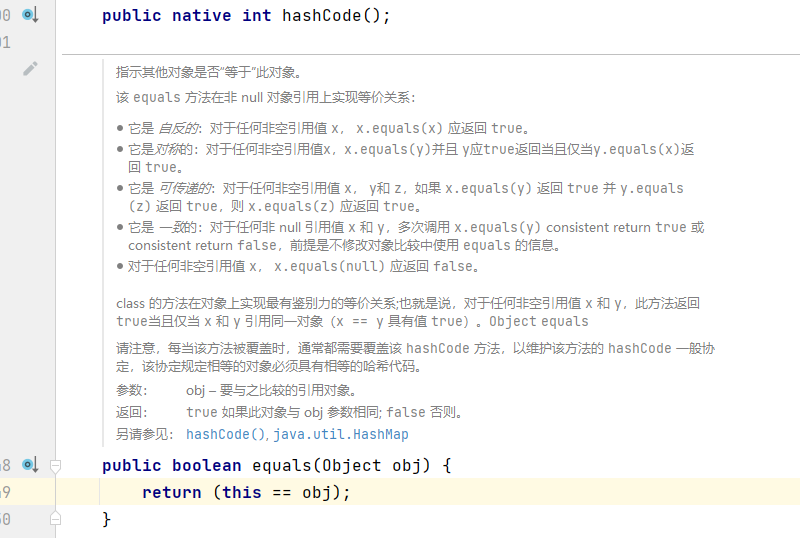
在上面的案例中,使用了Object中的hashCode() 和equals() 方法,可能会导致相同ID的对象,计算出的hash值却不一样,就会放在hashMap不同的槽位上。而equals() 方法比较的是地址值:
Student student = new Student();每一个创建出的对象的地址值都是不一样的,导致即使学生的id和name相同,也是不同的对象,导致hashMap中存在的无法被回收的对象持续增加,最终OOM
而我们想要的效果是,后一个相同的key覆盖前一个相同的key。就需要重写hashCode() 和equals() 方法:
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Student student = (Student) o;
return new EqualsBuilder().append(id, student.id).isEquals();
}
@Override
public int hashCode() {
return new HashCodeBuilder(17, 37).append(id).toHashCode();
}所以在定义Java Bean时,需要手动重写hashCode() 和equals() 方法 ,并且在定义HashMap时,不建议使用对象作为Key的类型,推荐使用String类型,提高查找效率。
4.2、内部类引用外部类
首先来简单复习一下什么是外部类和内部类:
-
OuterClass是一个外部类,外部类可以直接访问其内部定义的成员变量和方法,但无法直接访问内部类的成员。
-
InnerClass是一个内部类,内部类可以访问外部类的所有成员,包括私有成员,并且可以直接访问外部类的方法和字段。
public class OuterClass {
private int outerVar;public void outerMethod() { // 可以访问内部类 } // 内部类的定义 public class InnerClass { public void innerMethod() { // 可以访问外部类的成员变量和方法 outerVar = 10; outerMethod(); } }}
在创建内部类的实例时,需要用到外部类的实例 。
public static void main(String[] args) {
OuterClass outer = new OuterClass();
OuterClass.InnerClass inner = outer.new InnerClass(); // 创建内部类的实例需要使用外部类的实例
inner.innerMethod(); // 调用内部类的方法
}一个内部类引用外部类导致内存溢出的案例:
public class Outer {
private byte[] bytes = new byte[1024 * 1024]; //外部类持有数据
private String name = "测试";
class Inner {
private String name;
public Inner() {
this.name = Outer.this.name;
}
}
public static void main(String[] args) throws IOException, InterruptedException {
// System.in.read();
int count = 0;
//集合存放的是Outer外部类中Inner内部类的对象
ArrayList<Inner> inners = new ArrayList<>();
while (true) {
if (count++ % 100 == 0) {
Thread.sleep(10);
}
//创建内部类,需要用到外部类的实例
inners.add(new Outer().new Inner());
}
}
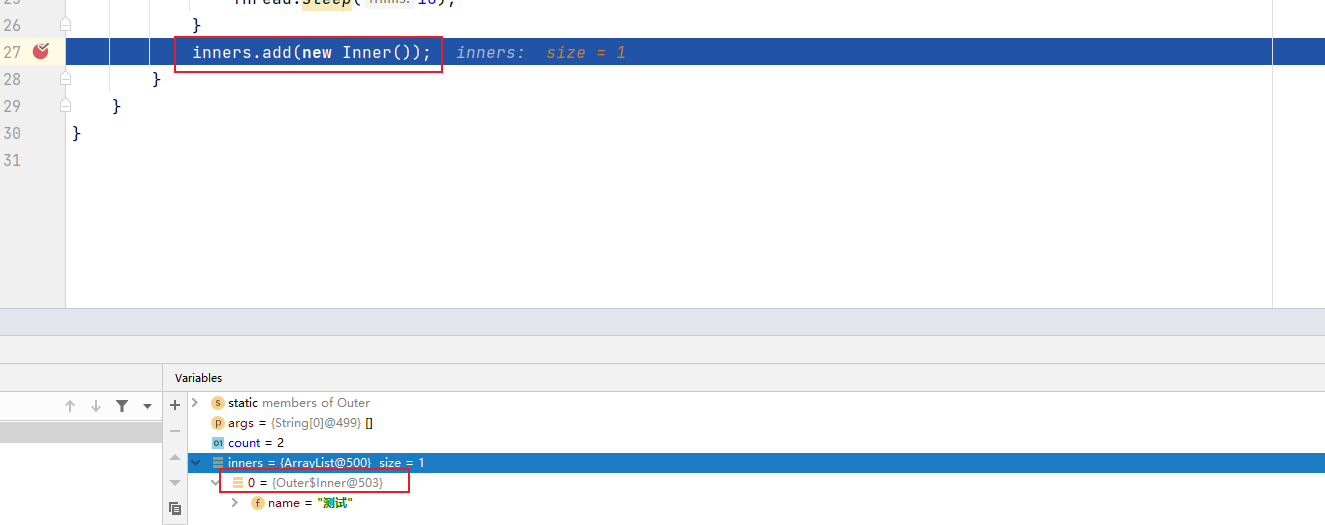
}我们在inners.add(new Outer().new Inner());这一行打一个断点:
内部类中持有了一个外部类的引用 ,导致外部类此时也在GC Root的引用链上,不会被回收。

如果需要解决这样的问题,我们可以使用静态内部类,再简单的复习一下一般内部类和静态内部类的区别:
-
静态内部类可以直接通过外部类访问 :静态内部类是独立的,不依赖于外部类的实例,因此可以直接通过外部类来访问。(解决内部类引用外部类内存溢出的关键)
-
静态内部类不能访问外部类的非静态成员:由于静态内部类是独立的,因此无法访问外部类的非静态成员变量和方法。
-
静态内部类可以直接创建实例:可以直接通过"外部类.内部类"的方式创建静态内部类的实例,而不需要先创建外部类的实例。
改造案例中的代码:
public class Outer {
private byte[] bytes = new byte[1024 * 1024]; //外部类持有数据
private static String name = "测试";
static class Inner {
private String name;
public Inner() {
this.name = Outer.name;
}
}
public static void main(String[] args) throws IOException, InterruptedException {
// System.in.read();
int count = 0;
ArrayList<Inner> inners = new ArrayList<>();
while (true) {
if (count++ % 100 == 0) {
Thread.sleep(10);
}
inners.add(new Inner());
}
}
}此时内部类完全独立,不再持有外部类的引用,所以外部类可以正常被回收。
4.3、ThreadLocal的不正确使用
如果是在手动创建线程的线程中使用ThreadLocal,一般不会造成内存溢出:
public class Demo5_1 {
public static ThreadLocal<Object> threadLocal = new ThreadLocal<>();
public static void main(String[] args) throws InterruptedException {
while (true) {
new Thread(() -> {
threadLocal.set(new byte[1024 * 1024 * 10]);
}).start();
Thread.sleep(10);
}
}
}每个线程对ThreadLocal中存储的对象都有独立的副本,线程一旦结束,其中的内存便会得到释放,即使不使用.remove()方法,如果每次存放入ThreadLocal的数据量不大,也不一定会发生内存溢出。
当使用线程池统一创建线程时,线程不一定是立刻被回收,如果没有使用.remove()方法 ,则大概率会造成内存溢出。
public class Demo5 {
public static ThreadLocal<Object> threadLocal = new ThreadLocal<>();
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(Integer.MAX_VALUE, Integer.MAX_VALUE,
0, TimeUnit.DAYS, new SynchronousQueue<>());
int count = 0;
while (true) {
System.out.println(++count);
threadPoolExecutor.execute(() -> {
threadLocal.set(new byte[1024 * 1024]);
});
Thread.sleep(10);
}
}
}解决方式也很简单,线程中的逻辑执行完成后,手动调用ThreadLocal的.remove()方法。
4.4、String的Intern()方法
Intern() 方法的作用是,将调用该方法的字符串放入字符串常量池中,在JDK 1.8中,字符串常量池位于堆中。
如果不同字符串的Intern() 方法被大量调用,达到堆内存上限后也会造成内存溢出的问题。(在实际开发中很少遇到,了解即可)
4.5、通过static字段修饰的容器保存对象
在前篇中提到,如果某个类的静态资源被引用,即使该类的实例全部不可达,该类也无法被回收。 并且static 字段属于类级别的,而不是属于某个实例,生命周期和类一样长,因此保存在其中的对象也会持续存在直到类被卸载。
当大量对象被保存在 static 字段所属的类中时,这些对象将随着类的加载而被创建并持续存在于堆内存中。如果这些对象没有被及时释放,就会导致堆内存不断被占用,最终导致内存溢出。
static 字段属于类级别的,所有实例共享同一个 static 字段,因此如果保存在其中的对象过多或者对象占用过多内存,就会对整个应用产生影响,容易导致内存资源的耗尽。
所以被static关键字修饰的变量,当不再使用时,需要手动将引用设置为null方便下次回收。
4.6、IO或数据库连接资源没有及时关闭
IO或数据库连接资源没有及时关闭,并不一定会100%导致内存泄漏,其原因与在手动创建线程中使用完ThreadLocal后没有手动调用.remove()方法类似。如果是在连接池中使用,或者短时间内连接数过多,依旧有可能会造成内存溢出。
推荐使用JDK 7 的新特性try..with...resources进行连接管理。
前提是被管理的连接需要实现AutoCloseable接口。
另一个可能导致内存溢出的原因,在于多线程并发访问时:
4.7、多线程并发访问
通常,用户在页面上点击按钮发送请求,服务器端会通过数据库进行处理,将查询的结果集读取到内存中并且返回给页面,然后就可以释放这部分内存。但是如果处理逻辑复杂,过程消耗时间较久,同时又有大量的请求,会导致数据全部积压在内存中,最终导致内存溢出。
例如下面这一段代码,模拟了数据量大,并且处理时间长的场景:
@GetMapping("/test")
public void test1() throws InterruptedException {
byte[] bytes = new byte[1024 * 1024 * 100];//100m
Thread.sleep(10 * 1000L);
}如果需要演示高并发的场景,可以通过压力测试工具实现,我这里使用Jmeter。
准备工作:将最大堆内存和初始堆内存设置成1g
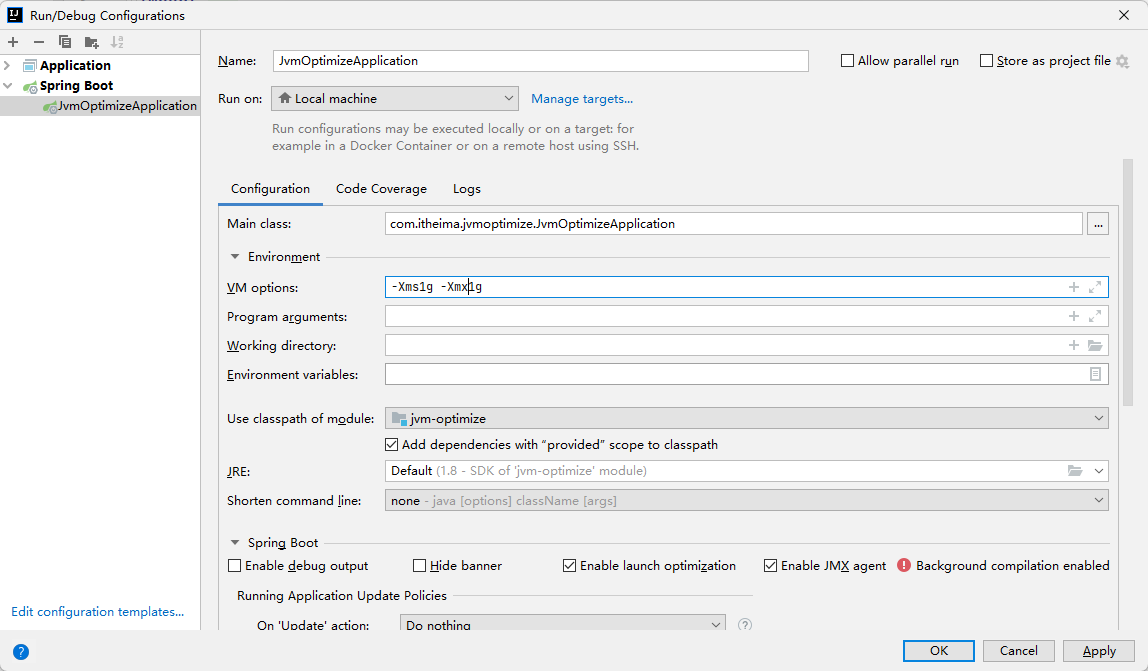
配置Jmeter
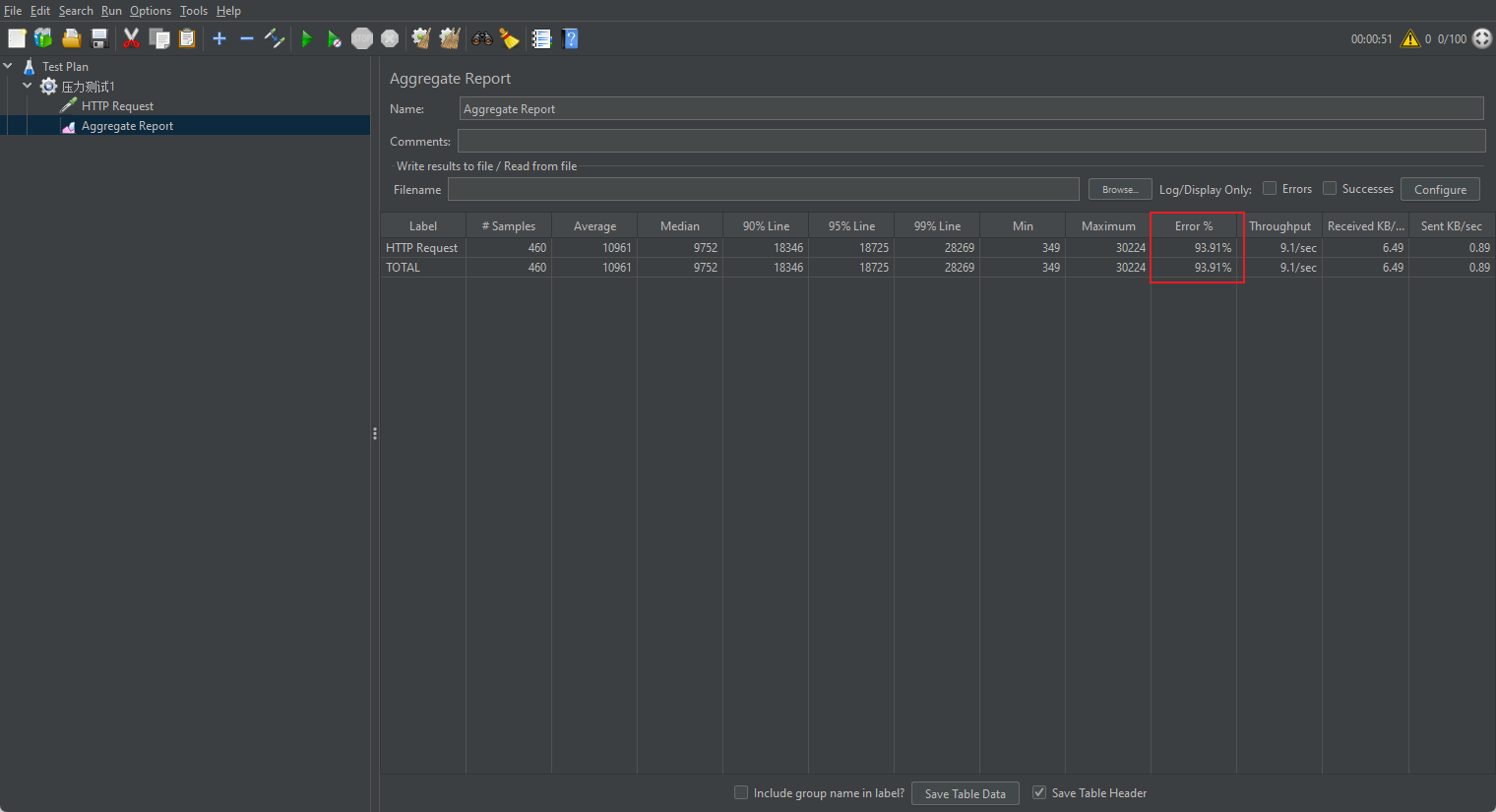
经过了100次/s的请求,发生了内存溢出:
再模拟一种使用静态关键字修饰的容器存放大量数据的情况:
/**
* 登录接口 传递名字和id,放入hashmap中
*/
@PostMapping("/login")
public void login(String name, Long id) {
userCache.put(id, new UserEntity(id, name));
}Jmeter配置
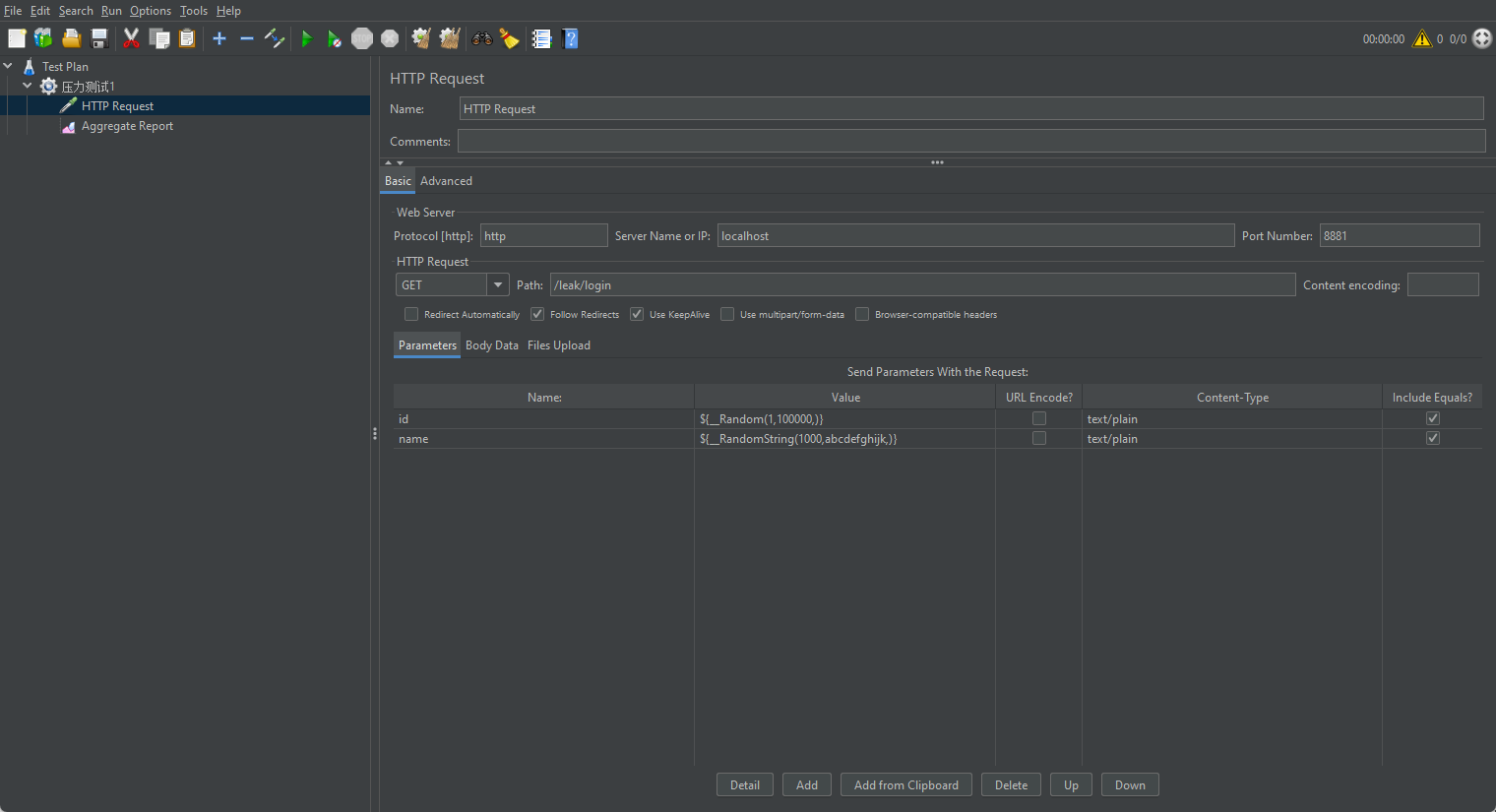
最终同样会造成内存溢出。