前言
本文仅根据模型的预测过程,即从输入图像到输出结果(图像预处理、模型推理、后处理),来展现不同任务下的网络结构,OBB 任务暂不包含。
Backbone
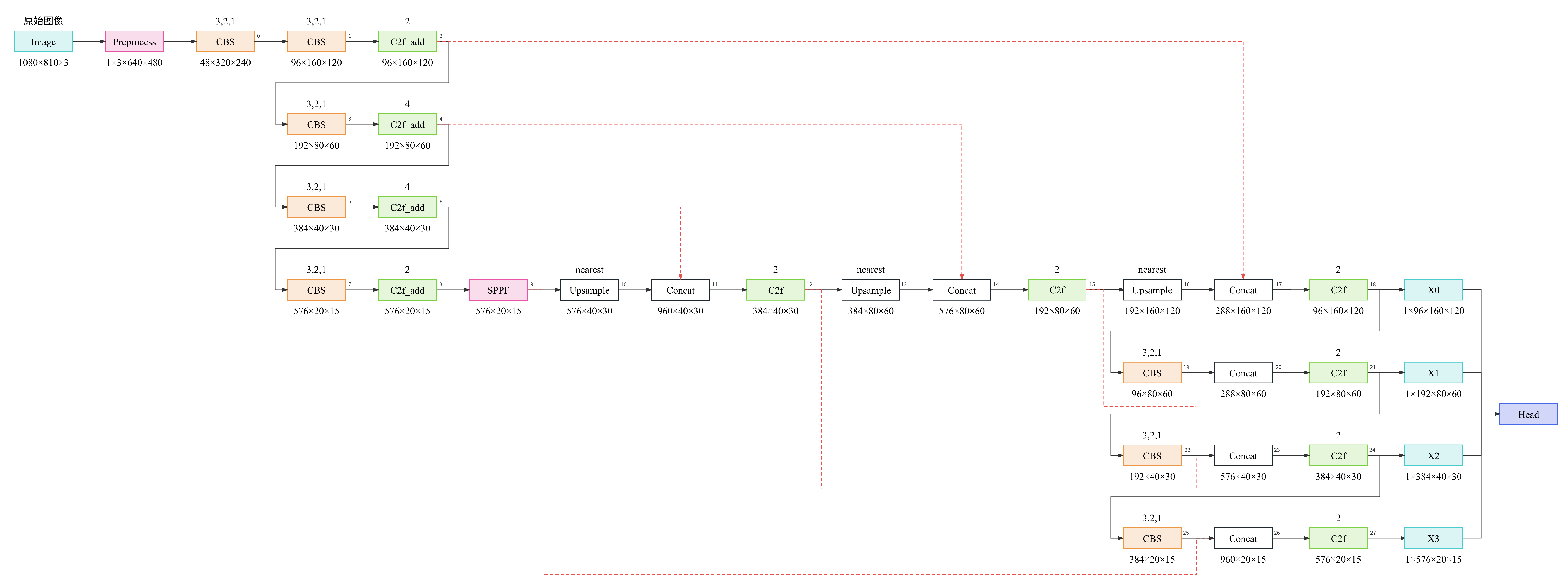
1. yolov8m

2. yolov8m-p2
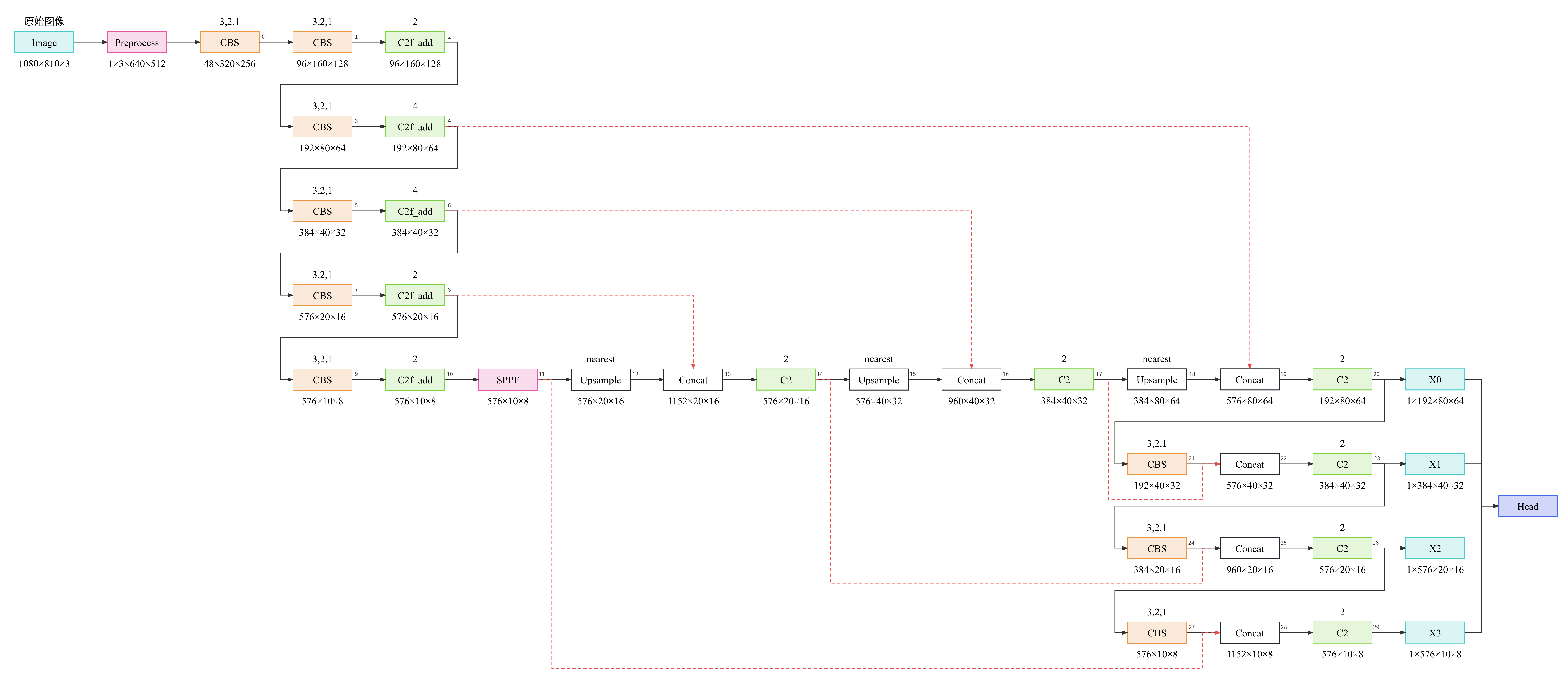
3. yolov8m-p6
4. 细节
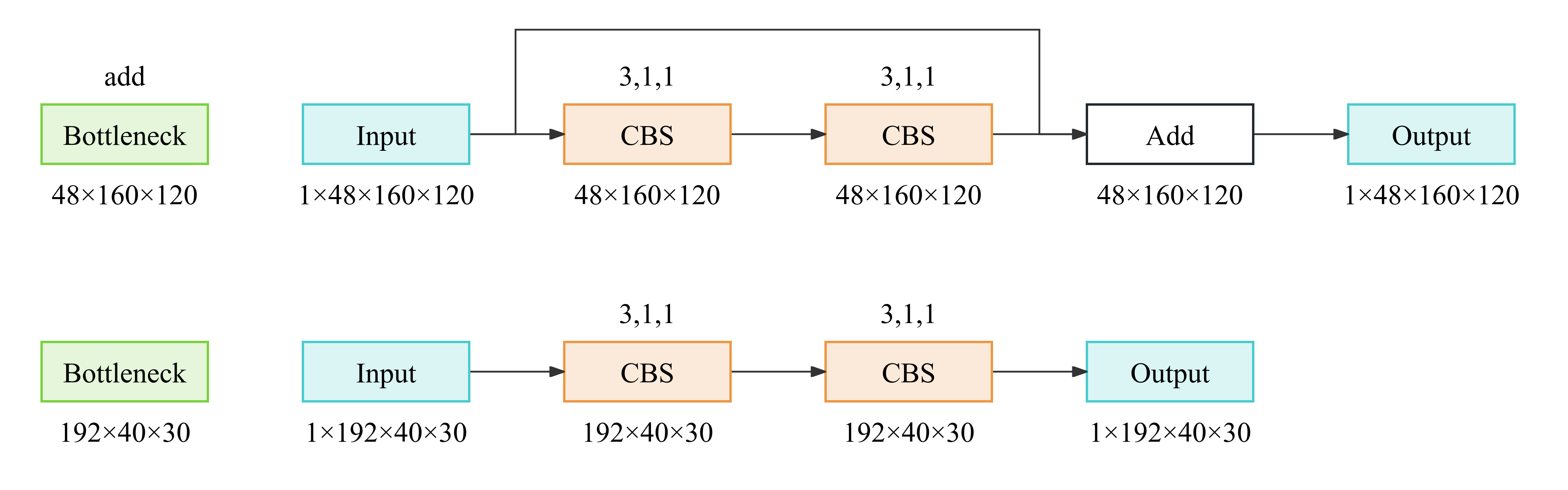
- 图中
CBS = Conv2d + BatchNorm2d + SiLU,上方为卷积参数对应size, stride, padding - 各模块细节至 [附录 - Block Modules](#附录 - Block Modules) 查看
yolov8m-p2通过增加一次上采样,与2-P2融合得到针对小目标的P2输出。yolov8m-p6通过增加一次下采样和一次上采样,与10-P6融合得到针对大目标的P6输出;因为多了一次下采样需要图像的分辨率能被64整除,所以图像预处理输出的分辨率有所不同。yolov8m-p6将SPPF之后的C2f模块替换为了C2模块。SPPF之前的C2f模块中的Bottleneck启用add,而其之后的C2f / C2中的Bottleneck未启用add
5. Image Preprocess

上图按 yolov8m-p6 绘制,LetterBox 环节先保持长宽比将图像较长边缩放至 640,再对四周做填充,使 h , w h,w h,w 都可被模型最大下采样倍率整除( p 6 → 2 6 = 64 \mathrm{p6}\to2^6=64 p6→26=64)
python
img = cv2.copyMakeBorder(
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)
)Head
1. Detect
Detect 部分尤为重要,Segment 和 Pose 都包含 Detect Head,依赖目标检测的结果。
实际上 Concat 后获得的 x 0 , x 1 , x 2 x_0, x_1, x_2 x0,x1,x2 就是训练阶段网络的输出,后续的步骤中不包含网络中需要训练的参数。
Detect head 通过两个分支 cv2 和 cv3 分别得到检测框和分类的输出。分类的输出较好理解,在后续步骤中通过 Sigmoid 直接得到对应 80 个类别的置信度。检测框的部分需要结合 DFL 理解。
python
class DFL(nn.Module):
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, _, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
box 中的 64 代表 4 个位置坐标,每个坐标是长度 16 的向量,经过 softmax 得到 16 个概率值;DFL 中卷积参数为固定值 0~15,卷积运算便是与这 16 个概率值做加权求和,最终得到坐标值,其范围也是 [0, 15]。
python
lt, rb = dfl(box).chunk(2, dim=1)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb Anchor:以 x 0 x_0 x0 为例,按其分辨率 80 × 60 80\times60 80×60 绘制一个网格,每个格子边长为 1 1 1,左上角为原点, x x x 轴向右, y y y 轴向下,每个格子的中心点坐标就是 Anchor 坐标,例如左上角坐标为 ( 0.5 , 0.5 ) (0.5,0.5) (0.5,0.5),右下角坐标为 ( 59.5 , 79.5 ) (59.5,79.5) (59.5,79.5)。
从代码中可以看出,DFL 得到的坐标为目标框左上角和右下角坐标与 Anchor 坐标的距离。
Postprocess - NMS
- 根据阈值
conf_thres=0.25筛选出置信度较高的 Anchor - 若数量较多,则选取置信度较高的
max_nms=30000项参与 NMS i = torchvision.ops.nms(boxes, scores, iou_thres)- 若数量较多,则选取
i中前max_det=300项作为最终检测结果
2. Segment
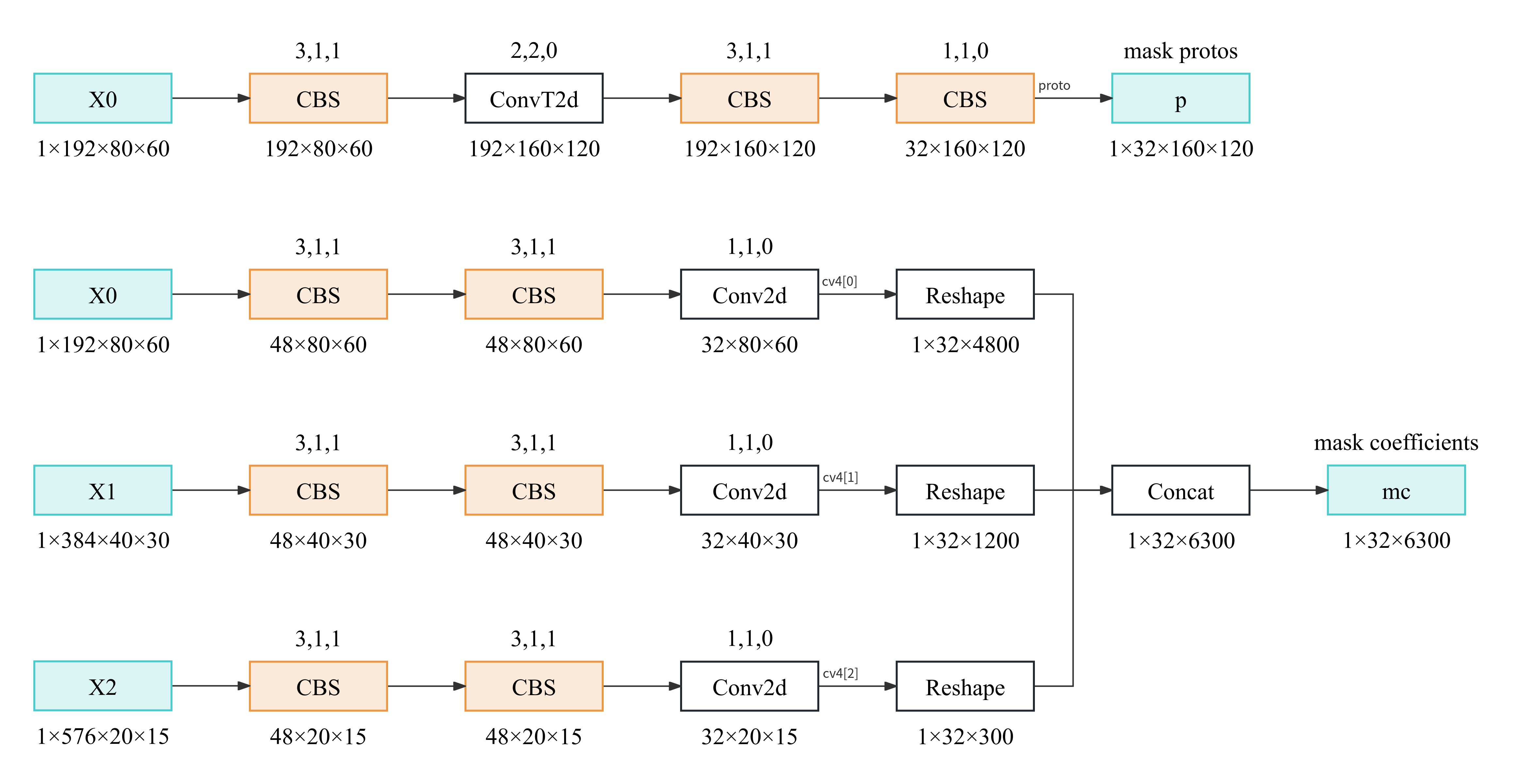
Segment 添加了一个类似 Detect 中 cv2 和 cv3 的分支 cv4 计算分割结果
mc 中 6300 代表 Anchor,32 代表 Mask。在 Detect 中每个 Anchor 对应了一个检测结果,mc 则是每个检测结果对应的分割结果 Mask,而 Mask 使用一个长度为 32 的向量表示。
p 用于将 mc 中的 Mask 解码成常规的 Mask(二值图),具体步骤如下:
mc @ p.view(32, -1).sigmoid().view(-1, 160, 120)
这里的mc大小为[n, 32],n为经过 NMS 等后处理后最终目标检测的数量,通过矩阵乘法、Sigmoid、Reshape 操作得到了 Maskcrop_mask(masks, downsampled_bboxes)
根据对应的检测结果,将检测框外的 Mask 数值置零F.interpolate(masks, image_shape, mode="bilinear", align_corners=False)
上采样至原图分辨率masks.gt_(0.5)
以 0.5 为阈值转为零一矩阵,即最终每个检测目标对应的 Mask
3. Pose

上图以 yolov8m-p6 作为 backbone, 51 = 17 × 3 51=17\times3 51=17×3 即 17 个关键点,每个点有 ( x , y , v i s i b l e ) (x,y,\mathrm{visible}) (x,y,visible) 3 个值,visible 代表该关键点是否可见,可视化时会根据阈值(默认 0.25)判断关键点是否可见。
python
y = kpts.clone()
if ndim == 3:
y[:, 2::3] = y[:, 2::3].sigmoid()
y[:, 0::ndim] = (y[:, 0::ndim] * 2.0 + (self.anchors[0] - 0.5)) * self.strides
y[:, 1::ndim] = (y[:, 1::ndim] * 2.0 + (self.anchors[1] - 0.5)) * self.strides 上述代码为图中 decode 过程。Anchor 坐标与 Detect 部分略有不同,anchors - 0.5 可以看作以网格左上角而非中心点作为 Anchor 坐标。 x , y x,y x,y 为距离 Anchor 坐标的一半(为何采用一半?)。
Classify
1. Backbone
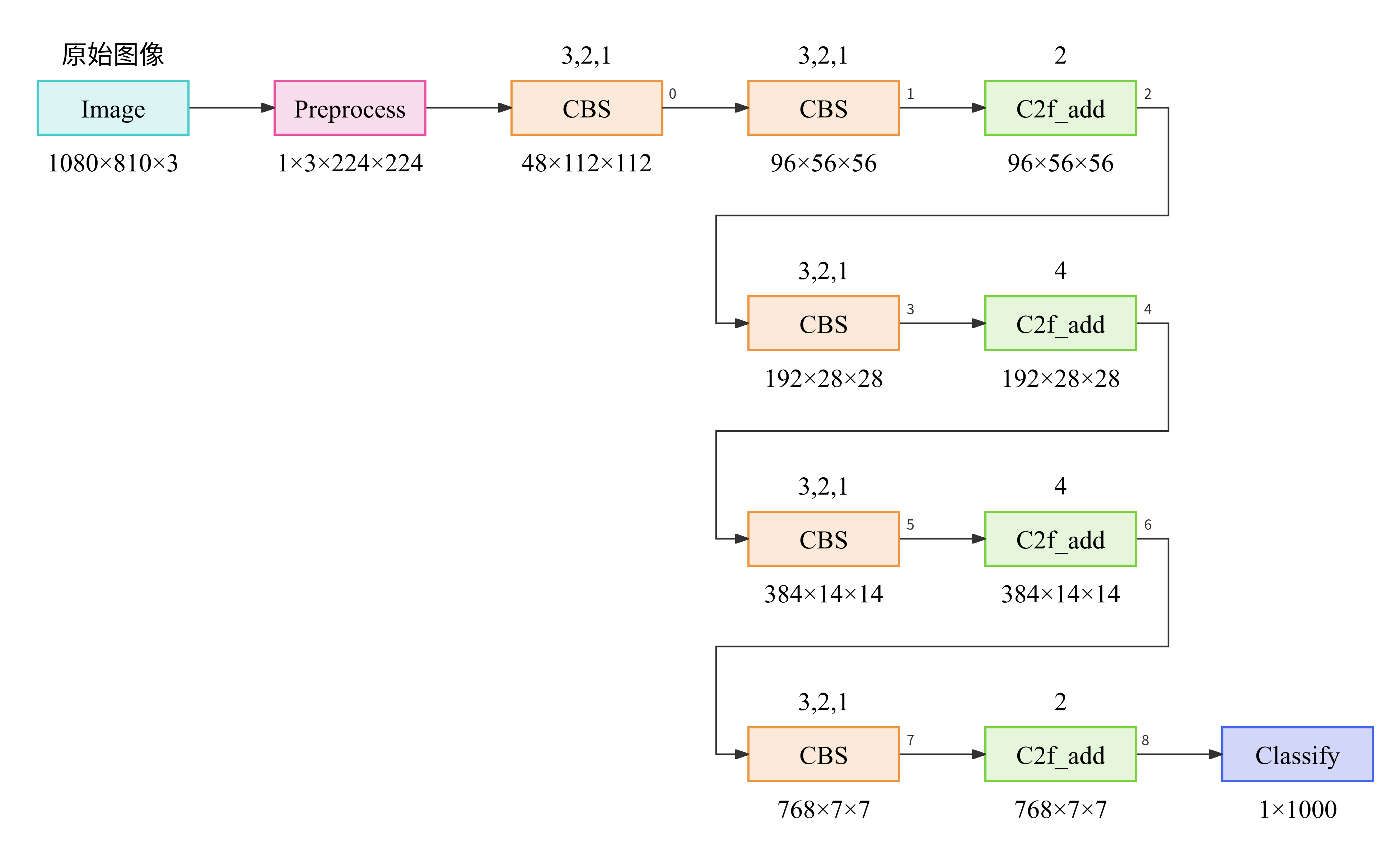
2. Head

3. Image Preprocess

Normalize 对图像数据并无影响
附录
1. 模型配置文件 yaml
https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models
python
# yolov8.yaml
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]] # 6
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]] # 8
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 10
- [[-1, 6], 1, Concat, [1]] # 11 cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #13
- [[-1, 4], 1, Concat, [1]] # 14 cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 16
- [[-1, 12], 1, Concat, [1]] # 17 cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 19
- [[-1, 9], 1, Concat, [1]] # 20 cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
python
[-1, 3, C2f, [1024, True]] # 8
"""
from: -1, 代表这一层的输入为上一层的输出
repeats: 3, 代表 C2f 中有3个 Bottleneck, 实际不同尺度的模型会根据 depth 调整数量
例如 yolov8m 该层实际的 repeats = 3*0.67 = 2
module: C2f
args: [1024, True], 代表 module 的参数
1024 代表 channel 数, 实际不同尺度的模型会根据 width 和 max_channels
例如 yolov8m 该层实际的 channel = min(1024, 768)*0.75 = 576
True 代表 Bottleneck 中是否启用 add
"""2. Block Modules
https://github.com/ultralytics/ultralytics/blob/main/ultralytics/nn/modules/block.py
SPP & SPPF

对比下方源码可知,SPP 与 SPPF 的区别主要在于 MaxPool2d 的 kernel size & padding,SPP 依次递增,SPPF 保持不变重复利用一个池化层。
python
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))C2

C2f

Bottleneck