
大语言模型,可以生成流畅对话的会话聊天机器人、通畅起草文章的内容生成器。在炫酷技术的背后,数据、算力、算法,被视作生成式AI的三个核心要素。由此可见,高质量的训练数据对于AI算法的准确性至关重要。
**如何获得高质量的训练数据?**网络爬虫作为数据自动批量获取的强大工具,在AI时代扮演着重要角色。
ForeSpider,利用最新的人工智能技术进行自动化数据采集。本地化部署自带数据库,能够保证数据安性全;自带挖掘脚本,采集清洗一步到位,可高效采集AI模型训练所需数据。
本文以大语言模型最基础的训练数据------汉语词典为例展开演示,教程如下:
l 采集网站
**【场景描述】**采集汉语词典数据。
**【使用工具】**前嗅ForeSpider数据采集系统
【入口网址】
https://www.cidianwang.com/cd/
【采集内容】
采集汉语词典中词语、拼音、解释等。

【采集效果】
如下图所示:

l 思路分析
配置思路概览:

l 配置步骤
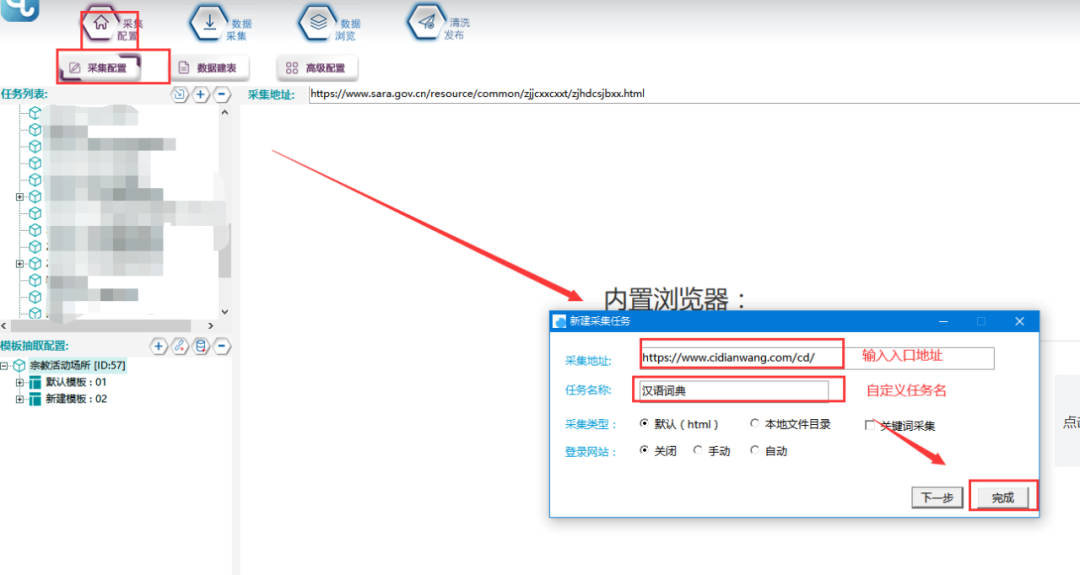
1.新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
2.获取字母链接
①在浏览器上观察页面,发现按字母分类展示。
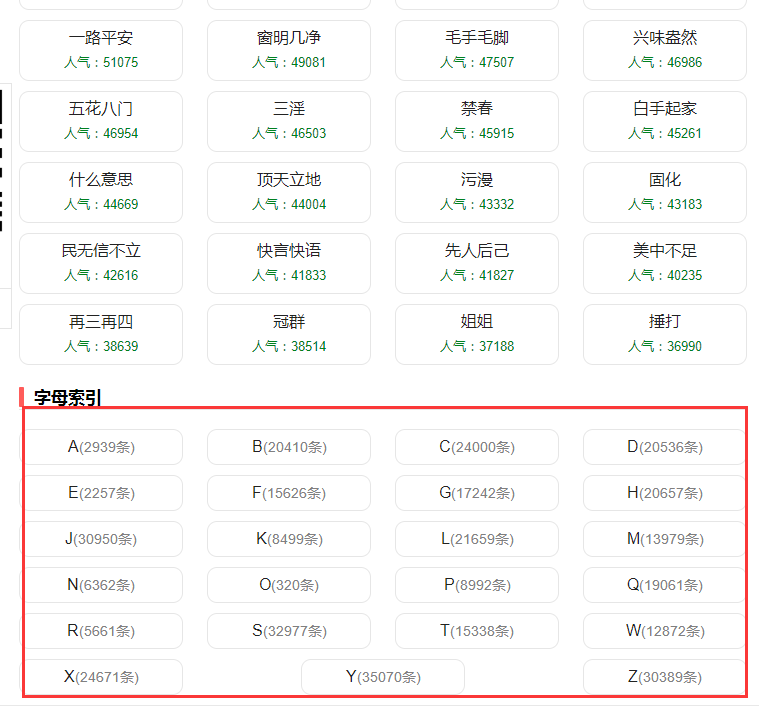
②采集预览,发现字母链接,且其规律为:
https://www.cidianwang.com/cd/**+字母+**.htm

③使用地址过滤的方法,将字母链接过滤,\c表示字母串。

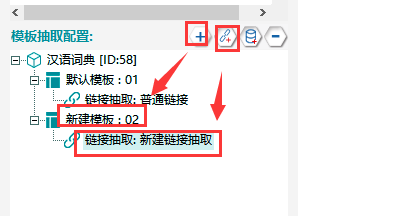
3.获取词语链接
①新建模板02,在其下新建一个链接抽取。
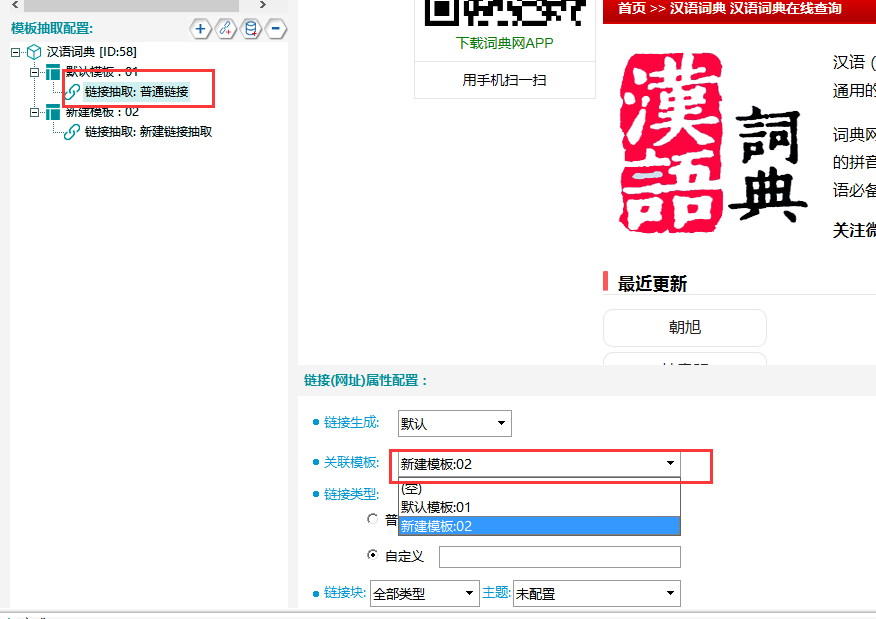
②将模版01的链接抽取,关联至模版02:
③采集预览,并观察词语链接的规律:
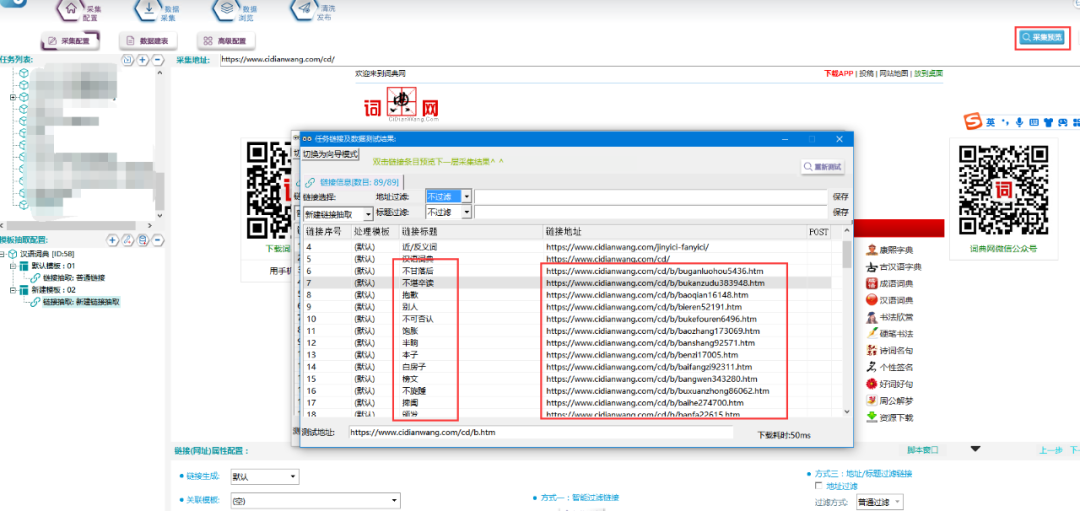
④发现其规律为:
https://www.cidianwang.com/cd/**+字母+/+词语拼音+数字串+**.htm
⑤使用地址过滤的方法,将词语链接过滤出来(\c表示字母串、\d表示数字串):

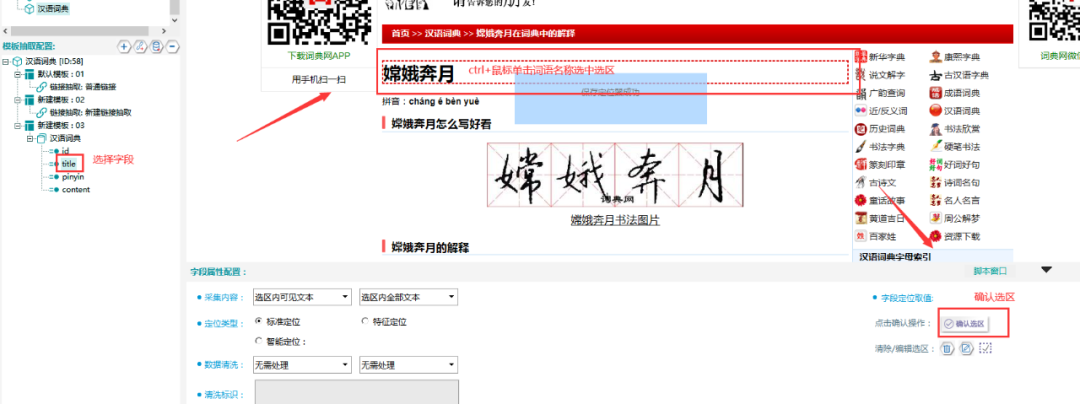
4.抽取词语数据
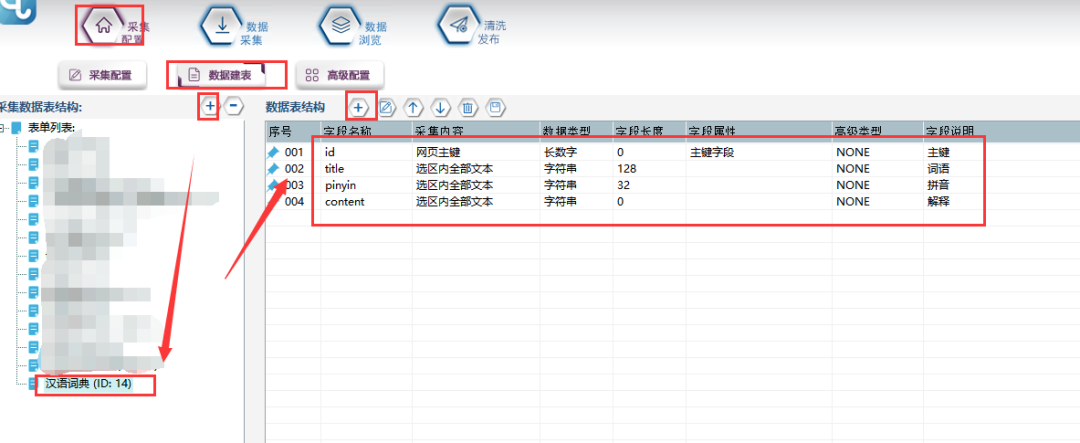
①新建一个数据表单,具体步骤和字段属性如下所示:
②新建模板03,在该模板下新建一个数据抽取。

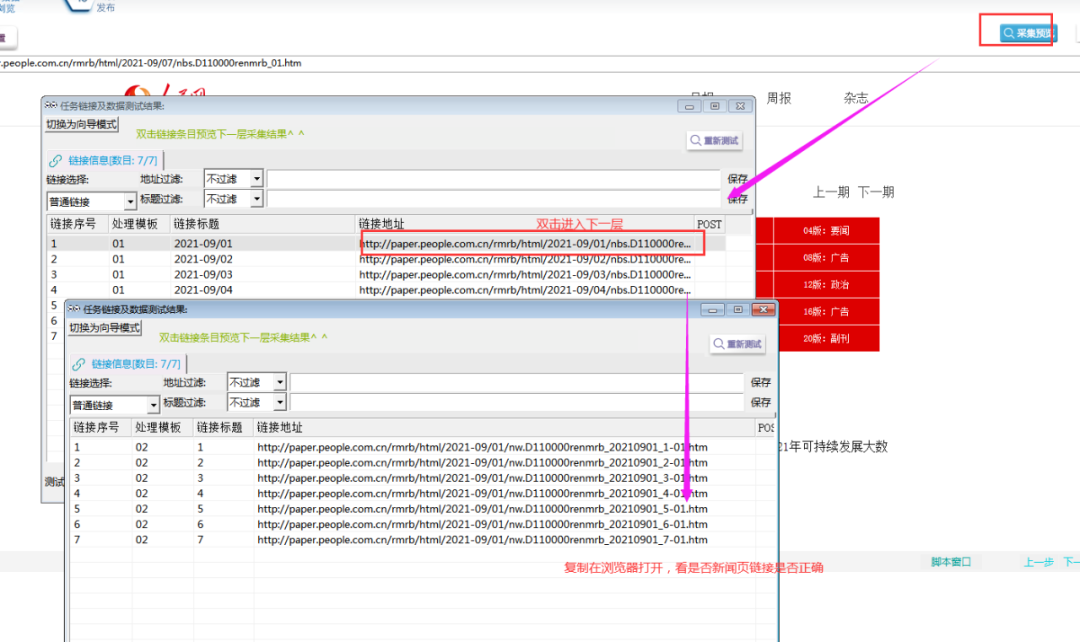
③填写示例地址,采集预览,双击进入下一层,复制任意一条词语链接,复制在示例地址位置:
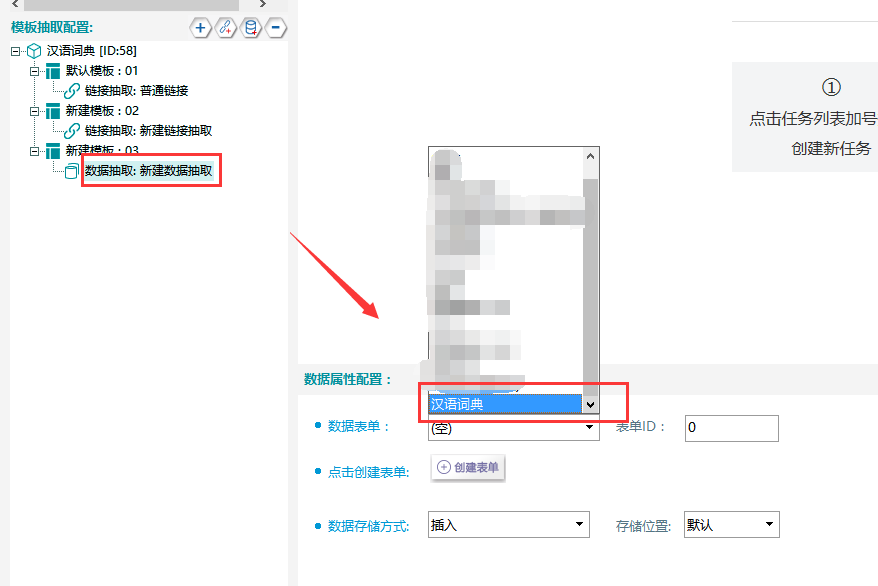
④关联数据表单,如下图所示:
⑤抽取数据采用定位取值法,具体操作如下图所示:
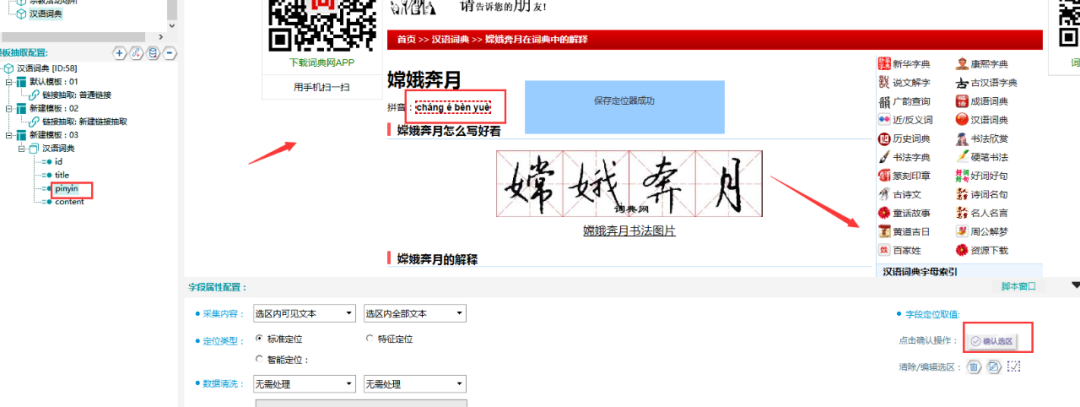
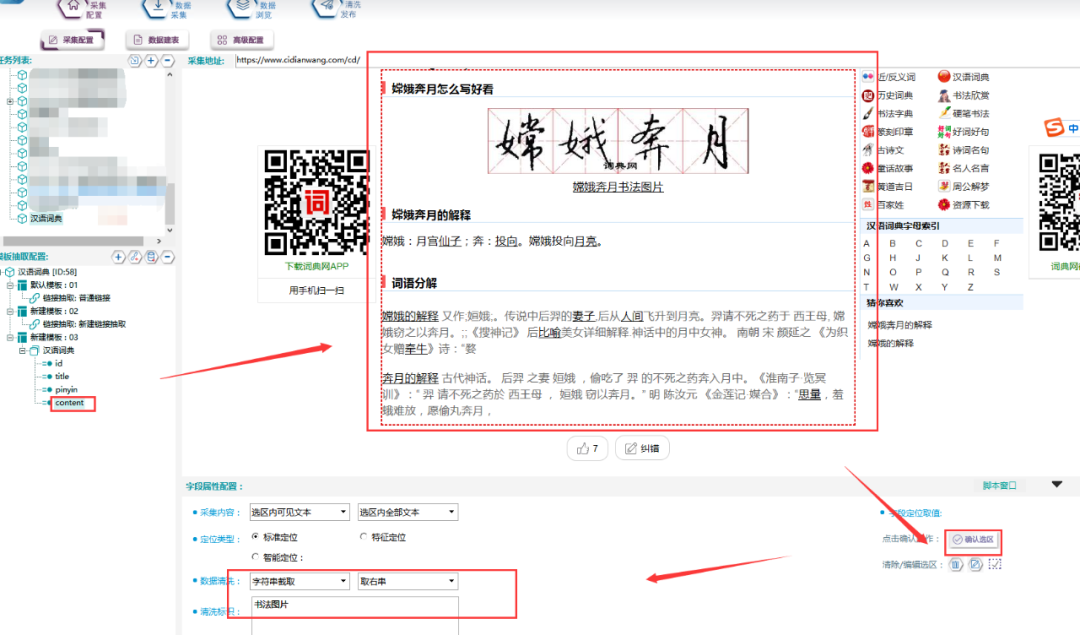
⑥将模版02关联至模版03:

⑦采集预览,如下图所示:

配置好模板以后就可以采集数据了,数据采集教程请参考:
http://www.forenose.com/view/help/course/spider/55.html?cId=31\&type=1\&dId=85
*本教程仅供学习交流,严禁用于商业用途!
未来,随着人工智能技术的发展,网络爬虫也将不断智能化,同时注重数据隐私与安全,并为多模态数据处理和知识图谱构建提供更多的支持。
我们相信ForeSpider在人工智能领域的应用前景必将更加广阔。
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于为大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品!