1.hbase的介绍
hbase的基本简介:hbase依赖于hdfs,hbase是一个nosql数据库,是一个非关系型数据库,支持读写查询操作
hbase当中所有的数据都是byte\[\]
HBase中的表有这样的特点:
- 海量存储:一个表可以有上十亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
- 易扩展:Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
- 高并发:开发情况下,hbase单个io延迟下降不多。实现高并发,低延迟
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
2.hbase与hadoop的关系
1、HDFS
* 为分布式存储提供文件系统
* 针对存储大尺寸的文件进行优化,不需要对HDFS上的文件进行随机读写
* 直接使用文件
* 数据模型不灵活
* 使用文件系统和处理框架
* 优化一次写入,多次读取的方式
2 、HBase
* 提供表状的面向列的数据存储
* 针对表状数据的随机读写进行优化
* 使用key-value操作数据
* 提供灵活的数据模型
* 使用表状存储,支持MapReduce,依赖HDFS
* 优化了多次读,以及多次写
hbase是基于hdfs的,hbase的数据都是存储在hdfs上的,hbase是一个数据库,支持随机读写
3.Hbase数据存储架构
主节点:HMaster
- 用于监控regionServer的健康状态,
- 处理regionServer的故障转移
- 处理元数据变更
- 处理region的分配或者移除
- 空闲时间做数据的负载均衡
从节点:HRegionServer
- 负责存储HBase的实际数据
- 处理分配给他的region
- 刷新缓存数据到HDFS上
- 维护HLog
- 负责处理region的切片
一个HRegionServer=1个HLog+很多个region
一个region=很多个store模块
一个store模块=1个memoryStore+很多个storeFile
组件:
Write-Ahead logs:Hbase读写数据的时候数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
HFile:这是在磁盘中保存原始数据的事迹物理文件,是实际的存储文件
Store:HFile存储在Store中,一个Store对应Hbase表中的一个列族
MemStore:内存存储,位于内存中,用来保存当前数据操作,所有当数据保存在WAL中后,RegionServer会在内存中存储键值对
Region:Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一高RegionServer中可以有多个不同的region
4.Hbase的集群环境搭建
注意事项:Hbase强依赖于HDFS以及zookeeper,所以安装Hbase之前一定要保证Hadoop和zookeeper正常启动
第一步 :下载对应的 HB ase的安装包
下载Hbase的安装包,下载地址如下:
http://archive.apache.org/dist/hbase/2.0.0/hbase-2.0.0-bin.tar.gz
******第二步:******HBASE集群部署
-
目标 :实现Hbase分布式集群部署
-
实施
-
解压安装
-
上传HBASE安装包到第一台机器的/export/software目录下
cd /export/software/ rz -
解压安装
tar -zxvf hbase-2.1.0.tar.gz -C /export/server/ cd /export/server/hbase-2.1.0/修改配置
-
-
-
切换到配置文件目录下
cd /export/server/hbase-2.1.0/conf/ -
#28行 export JAVA_HOME=/export/server/jdk1.8.0_65 #125行 export HBASE_MANAGES_ZK=false -
修改hbase-site.xml
cd /export/server/hbase-2.1.0/ mkdir datas vim conf/hbase-site.xmlbash<property > <name>hbase.tmp.dir</name> <value>/export/server/hbase-2.1.0/datas</value> </property> <property > <name>hbase.rootdir</name> <value>hdfs://node1:8020/hbase</value> </property> <property > <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1,node2,node3</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> -
修改regionservers
vim conf/regionservers node1 node2 node3 -
配置环境变量
vim /etc/profile #HBASE_HOME export HBASE_HOME=/export/servers/hbase-2.1.0 export PATH=:$PATH:$HBASE_HOME/bin source /etc/profile -
复制jar包
cp lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar lib/
-
-
分发
cd /export/server/ scp -r hbase-2.1.0 node2:$PWD scp -r hbase-2.1.0 node3:$PWD -
服务端启动与关闭
-
step1:启动HDFS
-
step2:启动ZK
-
step3:启动Hbase
start-hbase.sh -
关闭:先关闭Hbase再关闭zk
stop-hbase.sh stop-zk-all.sh stop-dfs.sh
-
-
测试
-
访问Hbase Web UI
node1:16010 Apache Hbase 1.x之前是60010,1.x开始更改为16010 CDH版本:一直使用60010
-
-
Web无法访问的几个问题及原因
1.如果报错404,那么则是网页访问不了
这个问题首先检查hbase-site.xml中的端口是否和自己的hdfs端口一至,我的就是这个问题连接不上
bash<property> <name>hbase.rootdir</name> <value>hdfs://node01:9000/HBase</value> </property>
其次更换版本
我更换成了2.2.4版本
首先:删除zookeeper的注册信息;删除hbase的数据目录
报错:

2.报错500连接不上hadoop102:16010的web页面情况2:org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
可能前面启动失败一次或者安装过其他版本导致,因为hbase基于zookeeper,所以在zookeeper上已经注册了之前的hbase信息,导致第二次启动失败,所以先在zookeeper中删除hbase的注册信息:
bash# 切换到zookeeper的bin目录下 cd zookeeper/bin 2 # 然后执行 ./zkCli.sh 命令 [XXhadoop102 bin]$ ./zkCli.sh # 输入 ls / 命令行查看所有的内容 [zk: localhost:2181(CONNECTED) 0] ls / [hbase, kafka, servers, spark, zookeeper] # 使用 rmr /hbase 或者 deleteall /hbase 删除zookeeper中的所有 hbase的目录 [zk: localhost:2181(CONNECTED) 3] rmr /hbase # 此时,可以看到Zookeeper中已经没有HBase了 [zk: localhost:2181(CONNECTED) 5] ls / [kafka, servers, spark, zookeeper]-
搭建Hbase HA
-
关闭Hbase所有节点
stop-hbase.sh -
创建并编辑配置文件
vim conf/backup-mastersnode2 -
启动Hbase集群
-
-
测试HA
-
启动两个Master,强制关闭Active Master,观察StandBy的Master是否切换为Active状态
hbase-daemon.sh stop master -
【测试完成以后,删除配置,只保留单个Master模式】
-
-
-
小结
- 实现Hbase分布式集群部署
bash
node01
node02
node03创建 back-masters 配置文件 ,实现 HM aster的 高可用
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf
vim backup-masters
bash
node02第四步 :安装包分发到其他机器
将我们node01服务器的hbase的安装包拷贝到其他机器上面去
cd /export/servers/
scp -r hbase-2.0.0/ node02:$PWD
scp -r hbase-2.0.0/ node03:$PWD
第五步 :三台机器创建软连接
因为hbase需要读取hadoop的core-site.xml以及hdfs-site.xml当中的配置文件信息,所以我们三台机器都要执行以下命令创建软连接
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml /export/servers/hbase-2.0.0/conf/core-site.xml
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml /export/servers/hbase-2.0.0/conf/hdfs-site.xml
第六步 :三台机器添加 HBASE_HOME的 环境变量
三台机器执行以下命令,添加HBASE_HOME环境变量
vim /etc/profile
export HBASE_HOME=/export/servers/hbase-2.0.0
export PATH=:HBASE_HOME/bin:PATH
第七步:HB ase集群启动
第一台机器执行以下命令进行启动
cd /export/servers/hbase-2.0.0
bin/start-hbase.sh
警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告
我们可以只是掉所有机器的hbase-env.sh当中的
"HBASE_MASTER_OPTS"和"HBASE_REGIONSERVER_OPTS"配置 来解决这个问题。不过警告不影响我们正常运行,可以不用解决

另外一种启动方式:
我们也可以执行以下命令单节点进行启动
启动HMaster命令
bin/hbase-daemon.sh start master
启动HRegionServer命令
bin/hbase-daemon.sh start regionserver
第八步 :页面访问
浏览器页面访问
http://node01:16010/master-status
5.Hbase的表模型
rowkey:行键,每一条数据都是使用行键来进行唯一标识的
columnFamily:列族,列族下面可以有很多列
column:列,每一个列都必须归属于某一个列族
timestamp:时间戳,每条数据都会有时间戳的概念
versionNum:版本号,每条数据都有版本号,当数据更新时,版本号也改变
创建一张HBase表最少需要两个条件:表名+列族名
注意:rowkey是我们在插入数据的时候自己指定的,列名也是插入数据的时候动态指定的
时间戳是自动生成的,versionNum也是自己维护的
6、HBase常用shell操作
1、进入HBase客户端命令操作界面
node01服务器执行以下命令进入hbase的shell客户端
cd /export/servers/hbase-2.0.0
bin/hbase shell
2、查看帮助命令
hbase(main):001:0> help
3、查看当前数据库中有哪些表
hbase(main):002:0> list
4、创建一张表
创建user表,包含info、data两个列族
hbase(main):010:0> create 'user', 'info', 'data'
或者
hbase(main):010:0> create 'user', {NAME => 'info', VERSIONS => '3'},{NAME => 'data'}
5、添加 数据 操作
向user表中插入信息,row key为rk0001,列族info中添加name列标示符,值为zhangsan
hbase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
向user表中插入信息,row key为rk0001,列族info中添加gender列标示符,值为female
hbase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female
向user表中插入信息,row key为rk0001,列族info中添加age列标示符,值为20
hbase(main):013:0> put 'user', 'rk0001', 'info:age', 20
向user表中插入信息,row key为rk0001,列族data中添加pic列标示符,值为picture
hbase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'
6、 查询数据 操作
1 、通过 rowkey进行查询
获取user表中row key为rk0001的所有信息
hbase(main):015:0> get 'user', 'rk0001'
2 、查看 rowkey下面的某个 列族 的信息
获取user表中row key为rk0001,info列族的所有信息
hbase(main):016:0> get 'user', 'rk0001', 'info'
3 、查看 rowkey 指定 列族指定字段的值
获取user表中row key为rk0001,info列族的name、age列标示符的信息
hbase(main):017:0> get 'user', 'rk0001', 'info:name', 'info:age'
4 、查看 rowkey指定多个列族的信息
获取user表中row key为rk0001,info、data列族的信息
hbase(main):018:0> get 'user', 'rk0001', 'info', 'data'
或者你也可以这样写
hbase(main):019:0> get 'user', 'rk0001', {COLUMN => 'info', 'data'}
或者你也可以这样写,也行
hbase(main):020:0> get 'user', 'rk0001', {COLUMN => 'info:name', 'data:pic'}
4、 指定 rowkey 与列值查询
获取user表中row key为rk0001,cell的值为zhangsan的信息
hbase(main):030:0> get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}
5、指定 rowkey与 列 值模糊查询
获取user表中row key为rk0001,列标示符中含有a的信息
hbase(main):031:0> get 'user', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
继续插入一批数据
hbase(main):032:0> put 'user', 'rk0002', 'info:name', 'fanbingbing'
hbase(main):033:0> put 'user', 'rk0002', 'info:gender', 'female'
hbase(main):034:0> put 'user', 'rk0002', 'info:nationality', '中国'
hbase(main):035:0> get 'user', 'rk0002', {FILTER => "ValueFilter(=, 'binary:中国')"}
6、 查询所有数据
查询user表中的所有信息
scan 'user'
7、 列族查询
查询user表中列族为info的信息
scan 'user', {COLUMNS => 'info'}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
8、 多列 族 查询
查询user表中列族为info和data的信息
scan 'user', {COLUMNS => 'info', 'data'}
scan 'user', {COLUMNS => 'info:name', 'data:pic'}
9、 指定列族与某个列名查询
查询user表中列族为info、列标示符为name的信息
scan 'user', {COLUMNS => 'info:name'}
10、 指定列族与列名以及限定版本查询
查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
11、 指定多个列族 与按照 数据值模糊查询
查询user表中列族为info和data且列标示符中含有a字符的信息
scan 'user', {COLUMNS => 'info', 'data', FILTER => "(QualifierFilter(=,'substring:a'))"}
12、 rowkey的范围值查询
查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan 'user', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
13、 指定rowkey模糊查询
查询user表中row key以rk字符开头的
scan 'user',{FILTER=>"PrefixFilter('rk')"}
14、指定 数据范围值查询
查询user表中指定范围的数据
scan 'user', {TIMERANGE => 1392368783980, 1392380169184}
7.Hbase 总结一:
-
Hbase的功能和应用场景是什么?
功能:能够实现实时分布式随机数据存储
场景:大量的结构化数据,实时,随机,持久化存储 -
Hbase的基本存储结构是什么?
设计:分布式大量数据实时存储
分布式内存【进程】+分布式磁盘【HDFS】
实现:NameSpace:类似于数据库概念,访问表的时候必须加上NS
Table:就是表概念,表是分布式的,一张表可以有多个分区Region,每个分区可以 存储在不同的节点上
Rowkey:类似于主键的概念,唯一标识一行,作为Hbase的唯一索引,每张表都自 带一列,值由用户自定义
ColumnFamily:对列的分组,将不同的列分到不同的组中,用于加快查询效率,任 何一列都必须数据某个列族
Qualifier:列标签,按照普通的列名称进行标记,不许使用列族+对应的列的名称才 能唯一标记一列
VERSIONS:列族级别,可以指定某个列族下的列允许存储多个版本的值,默认只 查询最新版本,根据timestamp来区分
存储:KV结构:一列就是一条KV数据
K:rowkey+cf+col+ts。所有的Kiev写入底层存储都按照K进行排序V: 值。存储类型:字节
-
Hbase的架构和角色是什么?
1.Hbase:分布式主从架构
主:HMaster:管理
从:HRegionServer:存储:构建分布式内存
2.Zooleeper:辅助Master选举,存储管理元数据
3.HDFS:构建分布式磁盘 -
Hbase的常用命令是什么?
DDL:create_namespace,list_namespace.create表名+列族,drop,exist,desc,disable,enable
DML:
put 'ns:tbname','rowkey','cf:col',value
delete 'ns:tbname','rowkey','cf:col'
get 'ns:tbname','rowkey','cf:col'
scan 'ns:tbname',Filter -
Hbase的JavaAPI如何实现DDL
1.构建连接:Connection
2.构建操作:DDL:HbaseAdmin DML:Table
3.释放资源
8.JavaAPI
DML:Table
使用Hbase API实现Table的实例开发
DML的所有操作都必须构建Hbase表的对象进行操作
代码:
java
public Table getHbaseTable() throws IOException {
TableName tbname = TableName.valueOf("itcast:t1");
Table table = conn.getTable(tbname);
return table;
}DML:Put
实现Put插入或者更新数据
代码:
java
@Test
public void testPut() throws IOException {
Table table = getHbaseTable();
//构建Put对象,一个Put对象表示写入一个Rowkey的数据
Put put = new Put(Bytes.toBytes("20210101_001"));
//添加列的信息
put.addColumn(Bytes.toBytes("basic"),Bytes.toBytes("name"),Bytes.toBytes("laoda"));
put.addColumn(Bytes.toBytes("basic"),Bytes.toBytes("age"),Bytes.toBytes("18"));
put.addColumn(Bytes.toBytes("other"),Bytes.toBytes("phone"),Bytes.toBytes("110"));
//执行Put
table.put(put);
table.close();
}小结:
-
调用:Table.put(Put)
-
Put:Put操作类对象
-
new Put(rowkey)
- .addColumn(cf,col,value)
DML:Get
实现Get读取数据
先用命令行插入数据,便于测试:
Scala
put 'itcast:t1','20210201_000','basic:name','laoda'
put 'itcast:t1','20210201_000','basic:age',18
put 'itcast:t1','20210101_001','basic:name','laoer'
put 'itcast:t1','20210101_001','basic:age',20
put 'itcast:t1','20210101_001','basic:sex','male'
put 'itcast:t1','20210228_002','basic:name','laosan'
put 'itcast:t1','20210228_002','basic:age',22
put 'itcast:t1','20210228_002','other:phone','110'
put 'itcast:t1','20210301_003','basic:name','laosi'
put 'itcast:t1','20210301_003','basic:age',20
put 'itcast:t1','20210301_003','other:phone','120'
put 'itcast:t1','20210301_003','other:addr','shanghai'代码:
java
@Test
public void testGet() throws IOException {
Table table = getHbaseTable();
//构建Get:get tbname,rowkey,[cf:col]
Get get = new Get(Bytes.toBytes("20210301_003"));
//配置Get
get.addFamily(Bytes.toBytes("basic"));//指定列族读取
// get.addColumn()//指定列读取
//执行:一个Result代表一个Rowkey的数据
Result result = table.get(get);
//打印这个rowkey每一列的结果:一个Cell对象就是一列的对象:20210301_003 column=other:phone, timestamp=1624590747738, value=120
for(Cell cell : result.rawCells()){
System.out.println(
Bytes.toString(CellUtil.cloneRow(cell)) + "\t" +
Bytes.toString(CellUtil.cloneFamily(cell)) + "\t" +
Bytes.toString(CellUtil.cloneQualifier(cell)) + "\t" +
Bytes.toString(CellUtil.cloneValue(cell)) + "\t" +
cell.getTimestamp()
);
}
table.close();
}小结:
-
Get:实现Get操作对象
-
new Get(rowkey)
-
.addFamily:指定读取这个rowkey的列族
-
.addColumn:指定读取某一列
-
-
table.get(Get):实现get操作
-
Result:一个Result代表一个Rowkey的数据
- rawCells/listCells
-
Cell:一个Cell代表一列的数据
-
CellUtil:用于对Cell取值的工具类
-
cloneValue
-
cloneRow
-
cloneQualifier
-
cloneFamily
-
DML:Delete
实现Delete删除数据
代码:
java
@Test
public void testDel() throws IOException {
Table table = getHbaseTable();
//构建Delete
Delete del = new Delete(Bytes.toBytes("20210301_003"));
//删除列族
// del.addFamily()
//删除列
del.addColumn(Bytes.toBytes("other"),Bytes.toBytes("phone"));
// del.addColumns(Bytes.toBytes("other"),Bytes.toBytes("phone"));//删除所有版本
//执行删除
table.delete(del);
table.close();
}小结:
-
Delete:删除操作对象
- .addColumn:指定删除的列
-
table.delete(Delete)
DML:Scan
实现Scan读取数据
代码:
java
@Test
public void testScan () throws IOException {
Table table = getHbaseTable();
//构建Scan对象
Scan scan = new Scan();
//执行scan:ResultScanner用于存储多个Rowkey的数据,是Result的集合
ResultScanner scanner = table.getScanner(scan);
//取出每个Rowkey的数据
for (Result result : scanner) {
//先打印当前这个rowkey的内容
System.out.println(Bytes.toString(result.getRow()));
for(Cell cell : result.rawCells()){
System.out.println(
Bytes.toString(CellUtil.cloneRow(cell)) + "\t" +
Bytes.toString(CellUtil.cloneFamily(cell)) + "\t" +
Bytes.toString(CellUtil.cloneQualifier(cell)) + "\t" +
Bytes.toString(CellUtil.cloneValue(cell)) + "\t" +
cell.getTimestamp()
);
}
System.out.println("------------------------------------------------------------");
}
table.close();
}存储设计:Table,Region,RS的关系
-
问题:客户端操作的是表,数据最终存在RegionServer中,表和RegionServer的关系是什么?
-
分析
-
Table:是一个逻辑对象,物理上不存在,供用户实现逻辑操作,存储在元数据的一个概念
-
数据写入表以后的物理存储:分区
-
一张表会有多个分区Region,每个分区存储在不同的机器上
-
默认每张表只有1个Region分区
-
-
Region:Hbase中数据负载均衡的最小单元
-
类似于HDFS中Block,Kafka中Partition、用于实现Hbase中分布式
-
就是分区的概念,每张表都可以划分为多个Region,实现分布式存储
- 默认一张表只有一个分区
-
每个Region由一台RegionServer所管理,Region存储在RegionServer
-
一台RegionServer可以管理多个Region
-
-
RegionServer:是一个物理对象,Hbase中的一个进程,管理一台机器的存储
-
类似于HDFS中DataNode或者Kafka中的Broker
-
一个Regionserver可以管理多个Region
-
一个Region只能被一个RegionServer所管理
-
-
-
小结
Hbase中Table与Region,RS三者的关系是什么?
1.Table:提供用户读写的逻辑概念,并不是实际存在的
2.Region:分区的概念,一张表可以划分为多个分区,每个分区都被某一台RegionServer所管理
3.RegionServer:真正的存储数据的物理概念
存储设计:Region及数据的划分规则
- 回顾:划分规则
- HDFS:划分分区规则:按照大小划分,文件按照每128M划分为一个Block
- Redis:将0~16383划分为多个段,每个小的集群分配一个段的内容
- Kafka:自己制定一个Topic有多少个分区,数据分配规则:指定分区,按照Key的hash区域,或者粘性分区,自定义分区
-
Hbase分区划分规则:范围划分【根据Rowkey范围】
任何一个Region都会对应一个范围,-
如果只有一个Region,范围:-oo ~ +oo
-
范围划分:从整个-oo ~ +oo区间上进行范围划分
-
每个分区都会有一个范围:根据Rowkey属于哪个范围就写入哪个分区
[startKey,stopKey)- 前闭后开区间
-
-
默认:一张表创建时,只有一个Region
- 范围:-oo ~ +oo

- 范围:-oo ~ +oo
-
自定义:创建表时,指定有多少个分区,每个分区的范围
-
举个栗子:创建一张表,有2个分区Region
create 'itcast:t3',{SPLITS => [50]}
-
-
region0:-oo ~ 50
-
region1:50 ~ +oo
-
-
数据分配的规则:==根据Rowkey属于哪个范围就写入哪个分区==
-
举个栗子:创建一张表,有4个分区Region,20,40,60
create 'itcast:t3',{SPLITS => [20,40,60]} -
前闭后开
-
region0:-oo ~ 20
-
region1:20 ~ 40
-
region2:40 ~ 60
-
region3:60 ~ +oo
-
-
写入数据的rowkey:比较是按照ASC码比较的,不是数值比较
-
例如以下划分举例
-
A1234:region3
-
c6789:region3
-
00000001:region0
-
2:region1
-
99999999:region3
-
9:region3
-
-
比较规则:ASCII码前缀逐位比较
-
-
-
小结
- 分区划分规则:将整个-00到+00区间进行划分,划分多个分区段
根据Rowkey进行划分 - 数据分区规则:根据rowkey的asc码逐位匹配,rowkey属于那个范围,就写入那个分区
存储设计:Region的内部结构
- 数据在Region的内部是如何存储的?
put tbname,rowkey,cf:col,value
- tbname:决定了这张表的数据最终要读写那些分区
- rowkey:决定了具体读写哪个分区
- cf:决定了具体写入哪个Store
-
Table/RegionServer:数据指定写入哪张表,提交给对应的某台regionserver
-
Region:对整张表的数据划分,按照范围划分,实现分步式存储
-
Store:对分区的数据进行划分,按照列族划分,一个列族对应一个Store
不同列族的数据写入不同的Store中,实现了按照列族将列进行分组
根据用户查询时指定的列族,可以快速的读取对应的store
MemStore :每个Store都有一个,内存存储区域
数据写入memstore后直接返回 -
StoreFile:每个Store中可能有0个或者多个StoreFile文件
逻辑上:Store
物理上:HDFS:HFILE(二进制文件)
-
HDFS中的存储
-
问题:Hbase的数据是如何在HDFS中存储的?
-
分析 :整个Hbase在HDFS中的存储目录
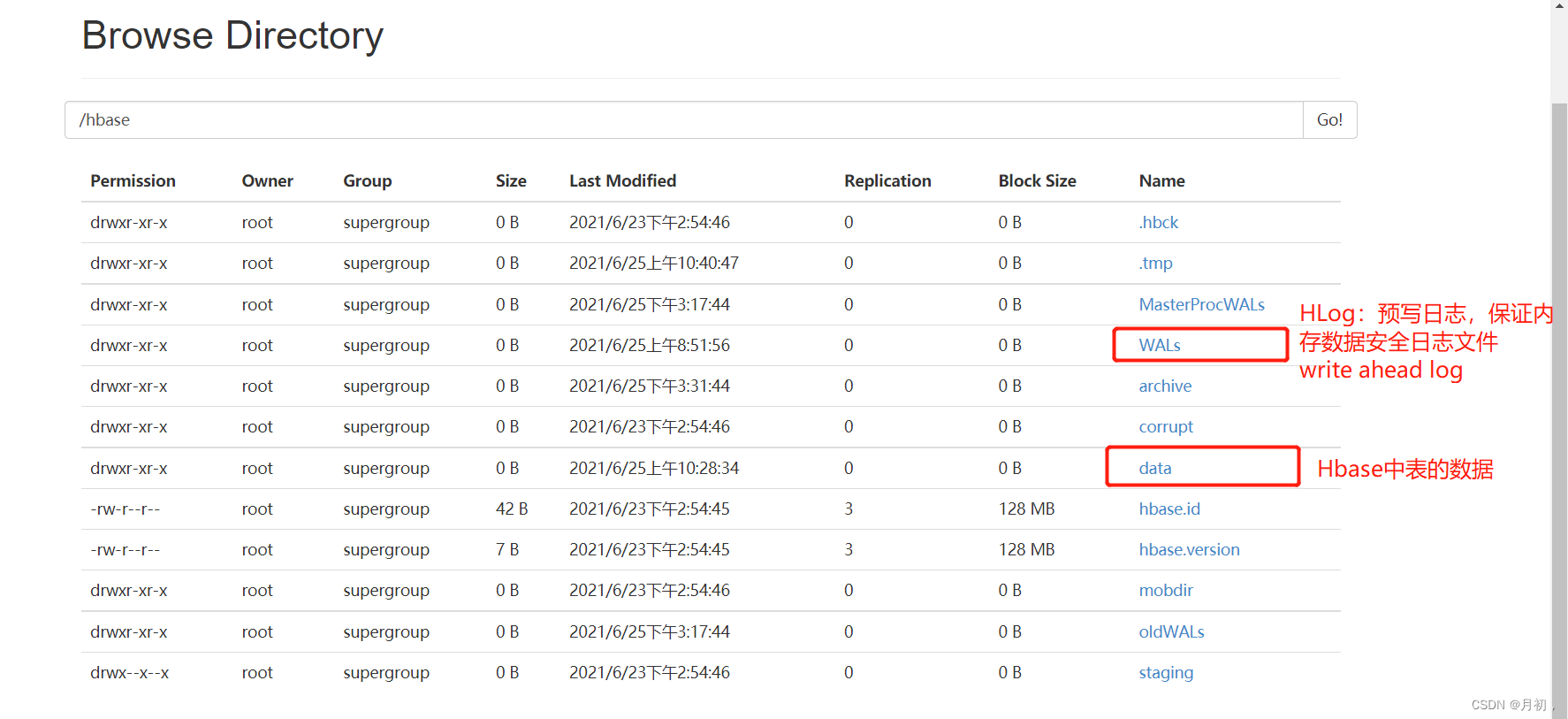 XML
XMLhbase.rootdir=hdfs://node1:8020/hbase -
NameSpace:目录结构
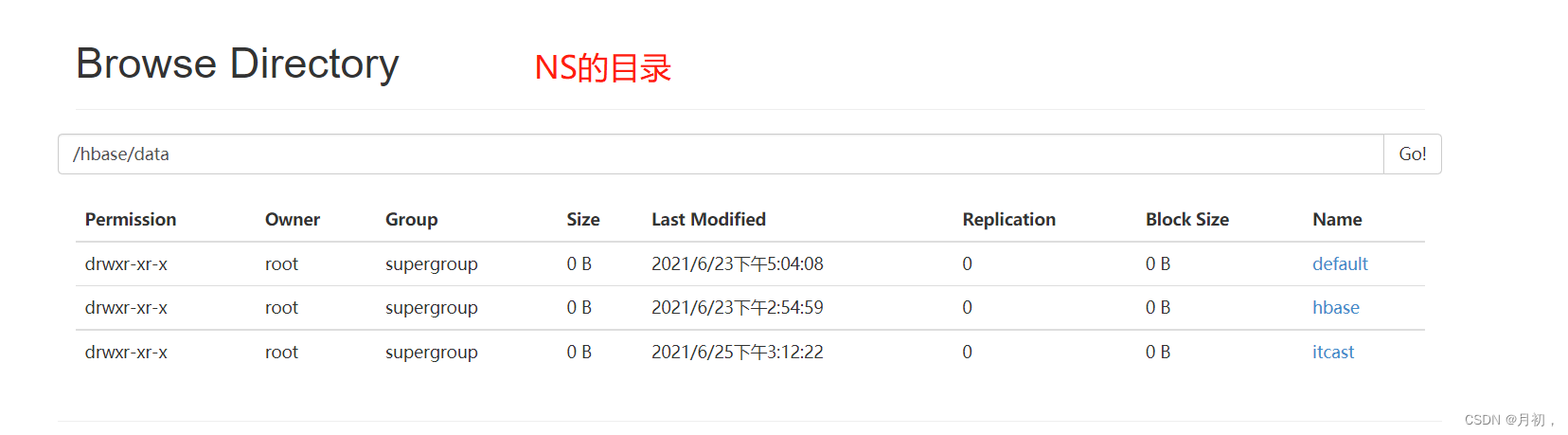
-
Table:目录结构
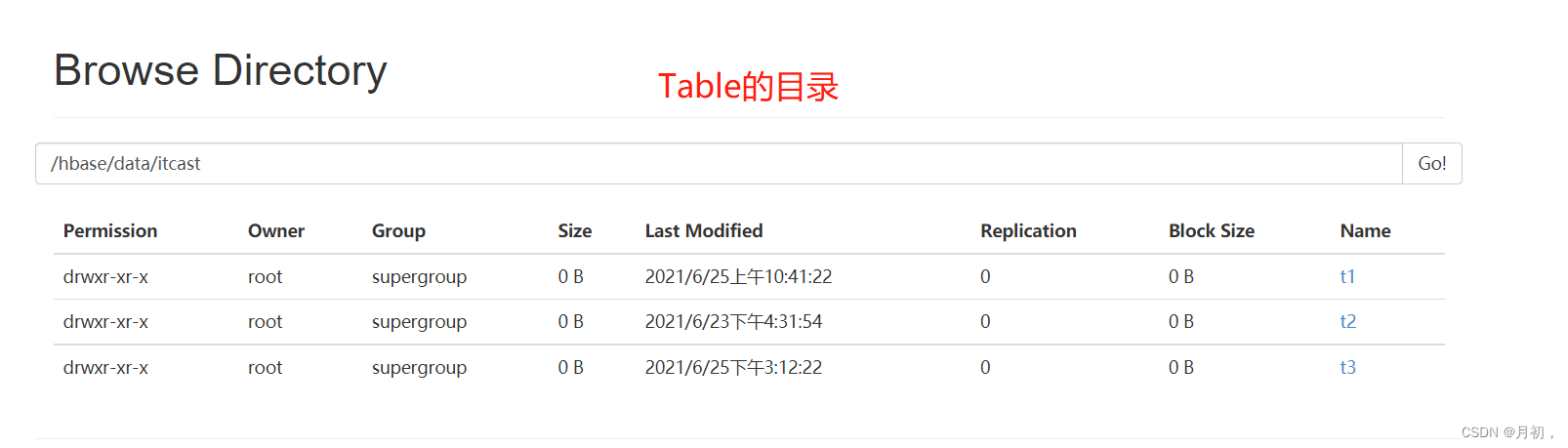
-
Region:目录结构
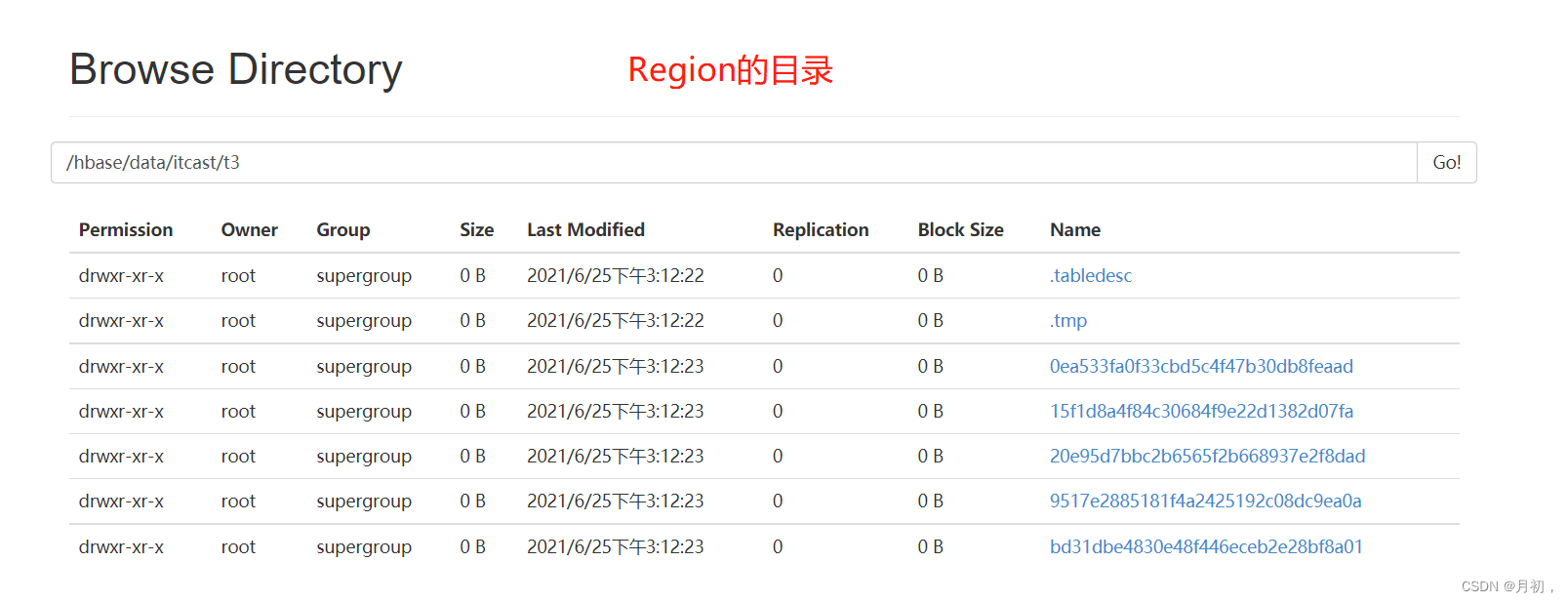
-
Store/ColumnFamily:目录结构
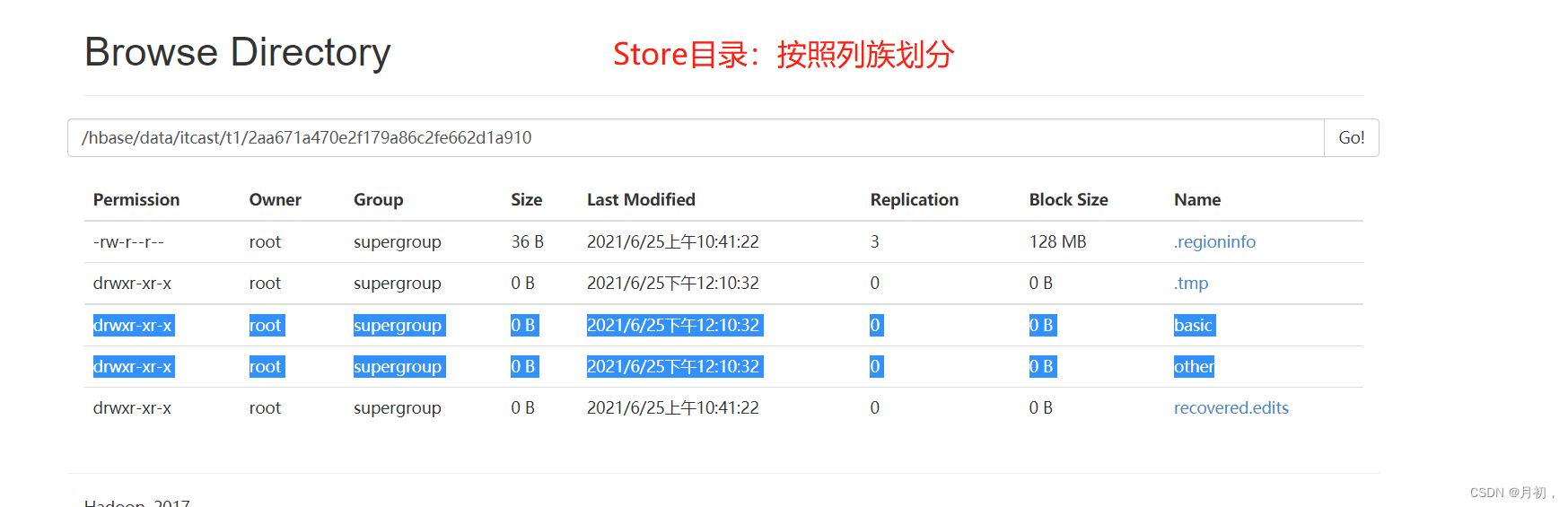
-
StoreFile
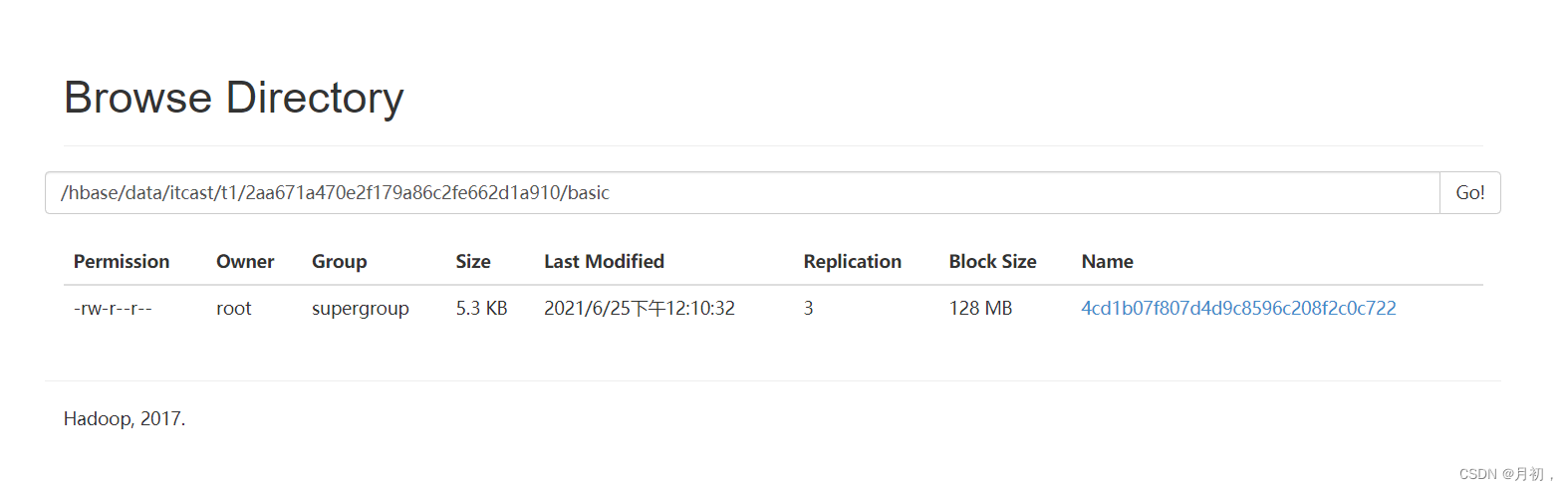
-
如果HDFS上没有storefile文件,可以通过flush,手动将表中的数据从内存刷写到HDFS中
flush 'itcast:t3'
-
-
小结
-
Region的内部存储结构是什么样的?
-
NS:Table|RegionServer:整个Hbase数据划分
-
Region:划分表的数据,按照Rowkey范围划分
-
Store:划分分区数据,按照列族划分
-
MemStore:物理内存存储
-
StoreFile:物理磁盘存储
-
逻辑:Store
-
物理:HDFSHFile
-
-
-
-
-
-
Hbase读写流程:基本流程

-
实施
-
step1:根据表名获取这张表对应的所有Region的信息
-
整个Hbase的所有Regionserver中有很多个Region:100
-
先根据表名找到这张表有哪些region:5
-
-
step2:根据Rowkey判断具体写入哪个Region
-
知道了这张表的所有region
-
根据rowkey属于哪个region范围,来确定具体写入哪个region
-
-
step3:将put操作提交给这个Region所在的RegionServer
- 获取这个Region所在的RegionServer地址
-
step4:RegionServer将数据写入Region,根据列族判断写入哪个Store
-
step5:将数据写入MemStore中
-
-
小结
-
表名:决定了这条数据要写入哪些region中
-
Rowkey:决定了这条数据具体写入哪个Region中
-
列族:决定了写入这个region哪个Store中
-
Hbase读写流程:meta表
-
实施
-
Hbase自带的两张系统表
-
hbase:namespace:存储了Hbase中所有namespace的信息
-
hbase:meta:存储了表的元数据
-
-
hbase:meta表结构
-
Rowkey:每张表每个Region的名称
itcast:t3,20,1632627488682.fba4b18252cfa72e48ffe99cc63f7604 表名,startKey,时间,唯一id
-
-
Hbase中每张表的每个region对应元数据表中的一个Rowkey
-
列
-
info:regioninfo
STARTKEY => 'eeeeeeee', ENDKEY => '' -
info:server/info:sn
column=info:sn, timestamp=1624847993004, value=node1,16020,1624847978508
-
-
-
实现
- 根据表名读取meta表,基于rowkey的前缀匹配,获取这张表的所有region信息
-
-
小结
-
meta表的功能是什么?
- 存储了表的元数据
-
每个Rowkey代表了一个Region的信息
-
Region的范围
-
Region的地址
-
-
Hbase读写流程:写入流程
-
实施
-
step1:获取表的元数据
-
==先连接zk,从zk获取meta表所在的regionserver==
-
根据查询的表名读取meta表,获取这张表的所有region的信息
-
meta表是一张表,数据存储在一个region,这个region存在某个regionserver上
-
怎么知道meta表的regionserver在哪?
-
这个地址记录在ZK中
-
-
得到这张表的所有region的范围和地址
-
-
step2:找到对应的Region
-
根据Rowkey和所有region的范围,来匹配具体写入哪个region
-
获取这个region所在的regionserver的地址
-
-
step3:写入数据
-
请求对应的regionserver
-
regionserver根据提交的region的名称和数据来操作对应的region
-
根据列族来判断具体写入哪个store
-
==先写WAL==:write ahead log
-
为了避免内存数据丢失,所有数据写入内存之前会
-
先记录这个内存操作
-
-
然后写入==这个Store的Memstore中==
-
-
-
思考:hbase的region没有选择副本机制来保证安全,如果RegionServer故障,Master发现故障,怎么保证数据可用性?
-
step1:Master会根据元数据将这台RegionServe中的Region恢复到别的机器上
-
step2:怎么实现数据恢复?
-
Memstore:WAL进行恢复
- 怎么保证WAL安全性:WAL记录在HDFS上
-
StoreFile:HDFS有副本机制
-
-
-
Hbase读写流程:读取流程
- 实施
- 获取元数据
客户端请求Zookeeper,获取meta表所在的regionserver的地址
读取meta表的数据
注意:客户端会缓存meta表的数据,只有第一次会连接ZK,读取meta表的数据,缓存会定期失效,要重新缓存,避免每次请求都要先连接zk,再读取meta表 - 找到对应的Region
根据meta表中的元数据,找到表对应的region
根据region的范围和读取的RowKey,判断需要读取具体哪一个Region
根据region的RegionServer地址,请求对应的RegionServer - 读取数据
先查询memstore,如果开启了缓存,就读BlockCache,如果缓存中没有,就读storefile,从storefile读取完成之后,放入缓存中,如果没有缓存,就读StoreFile
第一次查询一定是先度memstore,然后storefile如果开启了缓存,就将这次读取到的数据放到缓存中
LSM模型:Flush
-
功能:将内存memstore中的数据溢写到HDFS中变成磁盘文件storefile【HFILE】
-
关闭集群:自动Flush
-
参数配置:自动触发机制
css#2.x版本以后的机制 #设置了一个flush的最小阈值 #memstore的判断发生了改变:max("hbase.hregion.memstore.flush.size / column_family_number",hbase.hregion.percolumnfamilyflush.size.lower.bound.min) #如果memstore高于上面这个结果,就会被flush,如果低于这个值,就不flush,如果整个region所有的memstore都低于,全部flush #水位线 = max(128 / 列族个数,16),列族一般给3个 ~ 42M #如果memstore的空间大于42,就flush,如果小于就不flush,如果都小于,全部flush 举例:3个列族,3个memstore,90/30/30 90会被Flush 举例:3个列族,3个memstore,30/30/30 全部flush hbase.hregion.percolumnfamilyflush.size.lower.bound.min=16M #2.x中多了一种机制:In-Memory-compact,如果开启了【不为none】,会在内存中对需要flush的数据进行合并 #合并后再进行flush,将多个小文件在内存中合并后再flush hbase.hregion.compacting.memstore.type=None|basic|eager|adaptive小结
-
Hbase利用Flush实现将内存数据溢写到HDFS,保持内存中不断存储最新的数据
-
注意:工作中一般进行手动Flush
-
原因:避免大量的Memstore将大量的数据同时Flush到HDFS上,占用大量的内存和磁盘的IO带宽,会影响业务
-
解决:手动触发,定期执行
hbase> flush 'TABLENAME' hbase> flush 'REGIONNAME' hbase> flush 'ENCODED_REGIONNAME' hbase> flush 'REGION_SERVER_NAME' -
封装一个文件,通过hbase shell filepath来定期的运行这个脚本
-
LSM模型:Compaction
-
-
实现
-
功能:什么是Compaction?
-
将多个单独有序StoreFile文件进行合并,合并为整体有序的大文件,加快读取速度
-
file1:1 2 3 4 5
-
file2:6 7 9
-
file3 :1 8 10
-
|| 每个文件都读取,可能读取无效的数据
-
file:1 1 2 3 4 5 6 7 8 9 10
-
-
版本功能
-
2.0版本之前,只有StoreFile文件的合并
- 磁盘中合并:minor compaction、major compaction
-
2.0版本开始,内存中的数据也可以先合并后Flush
-
内存中合并:In-memory compaction
-
磁盘中合并:minor compaction、major compaction
-
-
-
**In-memory compaction:**2.0版本开始新增加的功能
-
原理:将当前写入的数据划分segment【数据段】
- 当数据不断写入MemStore,划分不同的segment,最终变成storefile文件
-
如果开启了内存合并,先将第一个segment放入一个队列中,与其他的segment进行合并
- 合并以后的结果再进行flush
-
内存中合并的方式
hbase.hregion.compacting.memstore.type=None|basic|eager|adaptive none:不开启,不合并 -
basic(基础型)
Basic compaction策略不清理多余的数据版本,无需对cell的内存进行考核 basic适用于所有大量写模式 -
eager(饥渴型)
eager compaction会过滤重复的数据,清理多余的版本,这会带来额外的开销 eager模式主要针对数据大量过期淘汰的场景,例如:购物车、消息队列等 -
adaptive(适应型)
adaptive compaction根据数据的重复情况来决定是否使用eager策略 该策略会找出cell个数最多的一个,然后计算一个比例,如果比例超出阈值,则使用eager策略,否则使用basic策略
-
-
minor compaction:轻量级
-
功能:将最早生成的几个小的StoreFile文件进行合并,成为一个大文件,不定期触发
-
特点
-
只实现将多个小的StoreFile合并成一个相对较大的StoreFile,占用的资源不多
-
不会将标记为更新或者删除的数据进行处理
-
-
属性
hbase.hstore.compaction.min=3
-
-
major compaction:重量级合并
-
功能:将整个Store中所有StoreFile进行合并为一个StoreFile文件,整体有序的一个大文件
-
特点
-
将所有文件进行合并,构建整体有序
-
合并过程中会进行清理过期和标记为删除的数据
-
资源消耗比较大
-
-
参数配置
hbase.hregion.majorcompaction=7天
-
-
-
小结
-
Hbase通过Compaction实现将零散的有序数据合并为整体有序大文件,提高对HDFS数据的查询性能
-
在工作中要避免自动触发majorcompaction,影响业务
hbase.hregion.majorcompaction=0 -
在不影响业务的时候,手动处理,每天在业务不繁忙的时候,调度工具实现手动进行major compact
Run major compaction on passed table or pass a region row to major compact an individual region. To compact a single column family within a region specify the region name followed by the column family name. Examples: Compact all regions in a table: hbase> major_compact 't1' hbase> major_compact 'ns1:t1' Compact an entire region: hbase> major_compact 'r1' Compact a single column family within a region: hbase> major_compact 'r1', 'c1' Compact a single column family within a table: hbase> major_compact 't1', 'c1' Compact table with type "MOB" hbase> major_compact 't1', nil, 'MOB' Compact a column family using "MOB" type within a table hbase> major_compact 't1', 'c1', 'MOB'
-
-
Region分裂Split设计及规则
-
分析
-
什么是Split分裂机制?
-
为了避免一个Region存储的数据过多,提供了Region分裂机制
-
实现将一个Region分裂为两个Region
-
由RegionServer实现Region的分裂,得到两个新的Region
-
由Master负责将两个新的Region分配到Regionserver上
-
-
-
实现
-
参数配置
XML#规则:return tableRegionsCount 1 ? this.initialSize : getDesiredMaxFileSize(); #判断region个数是否为1,如果为1,就按照256分,如果不为1,就按照10GB来分 hbase.regionserver.region.split.policy=org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy
-
-
小结
-
Hbase通过Split策略来保证一个Region存储的数据量不会过大,通过分裂实现分摊负载,避免热点,降低故障率
-
注意:工作作中避免自动触发,影响集群读写,建议关闭
hbase.regionserver.region.split.policy=org.apache.hadoop.hbase.regionserver.DisabledRegionSplitPolicy -
手动操作
split 'tableName' split 'namespace:tableName' split 'regionName' # format: 'tableName,startKey,id' split 'tableName', 'splitKey' split 'regionName', 'splitKey'
-
热点问题:现象及原因
-
现象
在某个时间段内,大量的读写请求全部集中在某个Region中,导致这台RegionServer的负载比较高,其他的Region和RegionServer比较空闲 -
原因 :本质上的原因,数据分配不均衡
-
情况一:Region范围不合理
-
Rowkey:字母开头
-
Region:3个分区
-
region0:-oo ~ 30
-
region1:30 ~ 70
-
region2:70 ~ +oo
-
-
所有数据都写入了region2
-
-
情况二 :如果这张表有多个分区,而且你的Rowkey写入时是连续的
-
一张表有5个分区
region0:-oo 20 region1:20 40 region2:40 60 region3:60 80 region4:80 +oo -
000001:region0
-
000002:region0
-
......
-
199999:region0
-
都写入了同一个region0分区
-
200000:region1
-
200001:region1
-
......
-
399999:region1
-
-
情况三:如果这张表只有一个分区
- 所有数据都存储在一个分区中,这个分区要响应所有读写请求,出现了热点
-
解决:避免热点的产生
-
构建多个分区,分区范围必须要Rowkey设计
-
构建不连续的rowkey
-
-
分布式设计:预分区
-
实施
-
需求 :在创建表的时候,指定一张表拥有多个Region分区
-
规则
-
划分的目标:划分多个分区,实现分布式并行读写,将无穷区间划分为几段,将数据存储在不同分区中,实现分区的负载均衡
-
划分的规则 :==Rowkey或者Rowkey的前缀来划分==
-
如果不按照这个规则划分,预分区就可能没有作用
-
Rowkey:00 ~ 99
-
region0: -oo ~ 30
-
......
-
regionN : 90 ~ +oo
-
-
如果分区的设计不按照rowkey来
-
region0:-oo ~ b
-
region1: b ~ g
-
......
-
regionN:z ~ +oo
-
-
-
-
实现
-
方式一:指定分隔段,实现预分区
- 前提:先设计rowkey
create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40'] #将每个分割的段写在文件中,一行一个 create 't1', 'f1', SPLITS_FILE => 'splits.txt' -
方式二:指定Region个数,自动进行Hash划分:==字母和数字的组合==
#你的rowkey的前缀是数字和字母的组合 create 'itcast:t4', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} -
方式三:Java API
javaHBASEAdmin admin = conn.getAdmin admin.create(表的描述器对象,byte[][] splitsKey)
-
-
-
小结
- 实现建表时指定多个分区
Hbase表设计:Rowkey设计
设计规则
-
业务原则:Rowkey的设计必须贴合业务的需求,一般选择最常用的查询条件作为rowkey的前缀
-
数据
oid uid pid stime …… -
Rowkey:stime
rowkey oid uid pid stime …… 20211201000000 o001 u001 p001 2021-12-01 00:00:00 -
按照时间就走索引
-
-
唯一原则:Rowkey必须具有唯一性,不能重复,一个Rowkey唯一标识一条数据
-
组合原则:将更多的经常作为的查询条件的列放入Rowkey中,可以满足更多的条件查询可以走索引查询
-
Rowkey:stime
- 缺点:不唯一、只有按照时间才走索引
-
Rowkey:stime_uid_oid
rowkey oid uid pid stime …… 20211201000000_u001_o001 o001 u001 p001 2021-12-01 00:00:00 20211201000000_u002_o002 o001 u001 p001 2021-12-01 00:00:00 …… 20211201000000_u00N_o00N o001 u001 p001 2021-12-01 00:00:00 …… 20211201000001_u001_o001 o001 u001 p001 2021-12-01 00:00:00-
订单id唯一、一个用户在同一时间只能下一个订单
-
索引查询:stime、s_time+uid、stime+uid+oid
-
想查询订单id为001:不走
- 全表扫表:对列的值进行过滤:SingleColumnValueFilter
-
-
-
散列原则:为了避免出现热点问题,需要将数据的rowkey生成规则构建散列的rowkey
-
举个栗子:一般最常用的查询条件肯定是时间
-
timestamp_userid_orderid:订单表
1624609420000_u001_o001 1624609420001_u002_o002 1624609420002_u003_o003 1624609421000_u001_o004 …… -
预分区:数值
-
region0:-oo ~ 1624
-
region1:1624 ~ 1924
-
region2:1924 ~ 2100
-
region3:2100 -2400
-
region4:2400 ~ +oo
-
-
问题:出现热点
-
-
解决:构建散列
-
方案一:更换不是连续的字段作为前缀,例如用户id
dfd342 3432sd- 缺点:可能与业务原则产生冲突
-
方案二:反转
- 一般用于时间作为前缀,查询时候必须将数据反转再查询
0000249064261_u001_o001 1000249064261_u002_o002 2000249064261_u003_o003 0010249064261_u001_o004 ……-
region0:-oo ~ 2
-
region1:2 ~ 4
-
region2:4 ~ 6
-
region3:6 ~ 8
-
region4:8 ~ +oo
-
==方案三:加盐(Salt)==,本质对数据进行编码,生成数字加字母组合的结果
1624609420000_u001_o001 1624609420001_u002_o002 1624609420002_u003_o003 1624609421000_u001_o004 | df34343jed_u001_o001 09u9jdjkfd_u002_o002- 缺点:查询时候,也必须对查询条件加盐以后再进行查询
-
-
-
长度原则:在满足业务需求情况下,rowkey越短越好,一般建议Rowkey的长度小于100字节
-
原因:rowkey越长,比较性能越差,rowkey在底层的存储是冗余的
-
问题:为了满足组合原则,rowkey超过了100字节怎么办?
-
解决:实现编码,将一个长的rowkey,编码为8位,16位,32位
-
小结:
rowkey的设计要符合以下原则:
- 业务原则:Rowkey设计贴合实际业务需求,尽量使用最常用的查询条件作为前缀
- 唯一原则:每个Rowkey唯一标识是一条数据
- 组合原则:尽量将更多的常用条件放入rowkey中
- 散列原则:构建不连续的Rowkey
- 长度原则:在满足上面原则的情况,rowkey越短越好
Hbase表设计:其他设计
- NS的设计:类似于数据库名称的设计,明确标识每个业务域,一般包含业务域名称
- 表明设计:类似于数据库中表明的设计包含业务名称即可
- 列族设计:名称没有太多意义,个数建议一般不超过3个
- 标签设计:按照实际业务字段名称标识即可,建议缩写,避免过长
BulkLoad的介绍
-
问题:有一批大数据量的数据,要写入Hbase中,如果按照传统的方案来写入Hbase,必须先写入内存,然后内存溢写到HDFS,导致Hbase的内存负载和HDFS的磁盘负载过高,影响业务
-
解决:
-
方式一:构建Put对象,先写内存
-
方式二:BulkLoad,直接将数据变成StoreFile文件,放入Hbase对应的HDFS目录中
- 数据不经过内存,读取数据时可以直接读取到
-
步骤:先将要写入的数据转换为HFILE文件,然后将HFILE加载到Hbase表中
-
特点
优点:不经过内存,降低了内存和磁盘的IO吞吐
缺点:性能上相对来说要慢,所有的数据都不会在内存中被读取
-
小结
应用场景:Hbase提供BulkLoad来实现大数据量不经过内存直接写入Hbase
BulkLoad的实现
- 作用:一种加载数据到Hbase中的方式
- 过程:先将要写入的数据转换为HFILE文件,然后将HFILE文件加载到Hbase的表中
- 实现:
数据文件bank_record.csv,每一行以逗号分割

- 创建表:create"TRANSFENR_RECORD",{NAME=>"C1"}
- 上传测试文件
hdfs dfs -mkdir -p /bulkload/input
hdfs dfs -put bank_record.csv /bulkload/input/

-
开发转换程序:将CSV文件转换为HFILE文件
-
上传jar包到Linux上

-
启动YARN
start-yarn.sh 启动过就不用了
-
转换HFILE
bashyarn jar bulkload.jar bigdata.itcast.cn.hbase.bulkload.BulkLoadDriver /bulkload/input/ /bulkload/output
运行找不到Hbase的jar包,手动申明HADOOP的环境变量即可,只在当前窗口有效
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/export/server/hbase-2.1.0/lib/shaded-clients/hbase-shaded-mapreduce-2.1.0.jar:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/audience-annotations-0.5.0.jar:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/commons-logging-1.2.jar:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/findbugs-annotations-1.3.9-1.jar:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/htrace-core4-4.2.0-incubating.jar:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/log4j-1.2.17.jar:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/slf4j-api-1.7.25.jar
重新运行
查看结果
step2:加载到Hbase表中
Swift
hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles /bulkload/output TRANSFER_RECORD查看数据
Swift
get 'TRANSFER_RECORD','ffff98c5-0ca0-490a-85f4-acd4ef873362',{FORMATTER=> 'toString'}协处理器的介绍
- 功能:协处理器指的是可以自定义开发一些功能集成到Hbase中,类似于Hive的UDF,当没有这个功能是,可以使用协处理器来自定义开发,
- observer类:观察者类,类似于监听机制,MvSQL中的触发器,Zookeeper中的监听
实现:监听A,如果A触发了,就执行B
监听对象Region,Table ,RegionServer,Master - endpioint类:终端者类,类似于Mysql中的存储过程,Java中的方法
实现:固定一个代码逻辑,可以随时根据需求调用代码逻辑 - 小结
Hbase通过协处理器来弥补一些用户自定义功能的实现,例如二级索引,一般通过第三方工具实现
协处理器的实现
路径
-
step1:开发协处理器,监听原表的put请求
-
step2:拦截原表put请求,获取put操作,获取rowkey以及值
-
step3:构建索引表的rowkey,往索引表写入数据
-
step4:释放原表请求,往原表写入数据
需求:当往第一张表写入数据时,自动往第二张表写入一条数据,并且将rowkey中的字段换位
-
put 'proc1','20191211_001','info:name','zhangsan'
-
proc1:rowkey:20191211_001
-
proc2:rowkey:001_20191211
-
创建两张表
#rowkey:time_id create 'proc1','info' #rowkey:id_time create 'proc2','info' -
将开发好的协处理器jar包上传到hdfs上
hdfs dfs -mkdir -p /coprocessor/jar mv bulkload.jar cop.jar hdfs dfs -put cop.jar /coprocessor/jar/ -
添加协处理器到proc1中,用于监听proc1的操作
disable 'proc1' alter 'proc1',METHOD => 'table_att','Coprocessor'=>'hdfs://node1:8020/coprocessor/jar/cop.jar|bigdata.itcast.cn.hbase.coprocessor.SyncCoprocessor|1001|' enable 'proc1' -
测试
put 'proc1','20191211_001','info:name','zhangsan' scan 'proc1' scan 'proc2' -
卸载协处理器
disable 'proc1' alter 'proc1',METHOD=>'table_att_unset',NAME=>'coprocessor$1' enable 'proc1'
Hbase优化:压缩机制
实施
-
本质:Hbase的压缩源自于Hadoop对于压缩的支持
-
检查Hadoop支持的压缩类型
- hadoop checknative
-
需要将Hadoop的本地库配置到Hbase中
-
关闭Hbase的服务,配置Hbase的压缩本地库:lib/native/linux-amd64-64
cd /export/servers/hbase-2.1.0/
mkdir lib/native
-
将Hadoop的压缩本地库创建一个软连接到Hbase的lib/native目录下
ln -s /export/server/hadoop/lib/native /export/server/hbase-2.1.0/lib/native/Linux-amd64-64
-
启动Hbase服务
hbase shell
Hbase优化:布隆过滤:
- 实施:什么是布隆过滤?:是列族的一个属性,用于数据查询时对数据的过滤,类似于ORC文件中的布隆索引,BLOOMFILTER => NONE | 'ROW' | ROWCOL
- NONE:不开启布隆过滤器
- ROW:开启行级布隆过滤器
- 生成StoreFile文件时,会将这个文件中有哪些RowKey的数据记录在文件的头部
- 当读取StoreFile文件时,会从文件头部获取这个StoreFile中所有的rowkey,自动判断是否包含需要的rowkey、如果包含就读取这个文件,如果不包含就过滤
小结
- Hbase通过布隆过滤器,在写入数据时,建立布隆索引,读取数据时,根据布隆索引加快数据的检索
9.Hbase 总结二:
1、Hbase如何使用JavaAPI实现DML
- step1:构建连接对象:Connection
- step2:构建操作对象:HbaseAdmin | Table
- step3:调用操作对象方法实现操作:put,Scan+Filter,Delete,Get,
2、Hbase的存储结构是什么
- NS:Table | RegionServer
Region:表的分区,对标的数据进行划分,按照Rowkey的范围,为了实现分布式
Store:分区的数据划分,按照列族划分,为了加快查询效率
Memstore:内存区域,写缓存
StoreFile:磁盘区域,HDFS文件
3、Hbase的读写流程是什么
- 元数据检索
1.所有客户端必须先读取表的元数据,元数据存储在Hbase的meta表里,但是meta表在Zookeeper中,所以Hbase要先访问Zookeeper
2.对表所在的region的regionserver进行请求 - 写
1.先写WAL:预写日志,保证内存数据安全
2.再写内存
3.Flush机制:将内存的数据溢写到磁盘
4.Compaction机制:将多个有序小文件合并为整体有序的大文件
5.Split机制:将一个分区划分为两个分区,减轻分区负载压力 - 读
1.先读MemberStore
2.可选:再读BlockCache【读缓存】,列族级别配置:默认True
3.Split机制:将一个分区划分为两个分区,减轻分区负载压力
4、Hbase怎么保证数据的安全性
- Region的安全性
- memstore:WALHDFS
- StoreFile:HDFS副本机制
5、Hbase的热点问题是什么,怎么解决
- 现象:短时间内,大量读写请求全部集中在一个Region分区中
- 原因:数据存储不均衡
1.没有做预分区,
2.做了多个分区,分区划分规则与Rowkey设计不匹配
3.做了多个分区,Rowkey是连续的 - 解决
合理设计rowkey,遵循五大原则:业务原则,组合原则,散列原则【加盐】,长度原则
6、Hbase的分区规则是什么
- 划分分区:将-00~+00区间划分为多个端,每个段是前闭后开区间,一定是按照rowkey进行划分的
- 数据分区:根据rowkey属于哪个Region的范围,就写入哪个Region
10.SQL On Hbase
11.Hive On Hbase
介绍:
-
问题:
Hbase是安列斯存储NoSQL.不支持SQL
开发接口不方便大部分用户使用,怎么办?
大数据开发:Hbase命令、Hbase Java AP
Java开发【JDBC】、数据分析师【SQL】:怎么用Hbase? -
分析:需要一个工具能让Hbase支持SQL,支持JDBC方式对Hbase进行处理
-
-
普通表数据:按行操作
id name age sex addr
001 zhangsan 18 male shanghai
002 lisi 20 female null
003 wangwu null male beijing ......
-
Hbase数据:按列操作
rowkey cf1:id cf1:name cf1:age cf2:sex cf2:addr zhangsan_001 001 zhangsan 18 null shanghai lisi_002 002 lisi 20 female null wangwu_003 003 wangwu null male beijing ……
-
-
可以基于Hbase数据构建结构化的数据形式
-
可以用SQL来实现处理
-
实现
-
将Hbase表中每一行对应的所有列构建一张完整的结构化表
-
如果这一行没有这一列,就补null
-
Hive:通过MapReduce来实现
-
Phoenix:通过Hbase API封装实现的
-
-
-
功能 :实现Hive与Hbase集成,使用Hive SQL对Hbase的数据进行处理
-
Hbase:itcast:t1
| 构建一个映射关系:数据存储在Hbase
-
Hive:itcast.t1
-
用户可以通过SQL操作Hive中表
select * from itcast.t1
-
-
原理
- 本质:在Hive中对Hbase关联的Hive表执行SQL语句,底层通过Hadoop中的Input和Output对Hbase表进行处理
-
特点
-
优点:支持完善的SQL语句,可以实现各种复杂SQL的数据处理及计算,通过分布式计算程序实现,对大数据量的数据处理比较友好
-
缺点:不支持二级索引,数据量不是特别大的情况下,性能一般
-
-
应用
- 基于大数据高性能的离线读写,并且使用SQL来开发
-
-
小结
-
Hive如何实现通过SQL读写Hbase数据?
-
通过Hadoop中的Input类和Output类来实现
-
优点:SQL支持非常全面
-
缺点:不能解决查询不走索引问题,数据量小性能一般
-
应用:离线架构中用于存储离线数据,离线开发,加快性能或者存储用户行为数据
-
-
配置:
-
修改hive-site.xml:Hive通过SQL访问Hbase,就是Hbase的客户端,就要连接zookeeper
cd /export/server/hive
vim conf/hive-site.xmlbash<property> <name>hive.zookeeper.quorum</name> <value>node01,node02,node03</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node01,node02,node03</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> -
bash
export HBASE_HOME=/export/servers/hbase-2.1.0
测试:
-
实施
如果Hbase中表已经存在,只能创建外部表bash--创建测试数据库 create database course; use course; --创建测试表 create external table course.t1( key string, name string, age string, addr string, phone string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping" = ":key,basic:name,basic:age,other:addr,other:phone") tblproperties("hbase.table.name" = "itcast:t1");查询
bashselect age,count(*) as cnt from t1 group by age order by cnt desc; -
注意
-
Hive的只是关联表,并没有数据,数据存储在Hbase表中
-
在Hive中创建Hbase的关联表,关联成功后,使用SQL通过MapReduce处理关联表
-
如果Hbase中表已经存在,只能创建外部表,使用Key来表示rowkey
-
Hive中与Hbase关联的表,不能使用load写入数据,是能通过insert通过MR读写数据
二级索引的设计及问题
二级索引设计
-
问题
-
构建二级索引表:index_Table:查询条件 + 原表的rowkey
rowkey:age_name_id col:x 18_zhangsan_001 x 18_lisi_002 x 20_zhangsan_003 x 109_wangwu_004 x …… -
需求:按照age查询,查询所有age = 20的人的信息
- 常规方案:全表扫描用列值过滤器对每一行的这一列的值进行过滤
-
构建数据表:source Table
rowkey:name_id id name age sex addr zhangsan_001 001 zhangsan 18 male shanghai lisi_002 002 lisi 18 female beijing zhangsan_003 003 zhangsan 20 male wangwu_004 004 wangwu 109 …… -
解决:二级索引
-
思想:通过走两次索引来代替全表扫描
-
step1:基于存储和常用查询需求,构建原始数据表
-
step2:基于其他查询需求,构建索引表
-
step3:先查询索引表,再查询数据表
-
-
Hbase使用Rowkey作为唯一索引,只有按照rowkey的前缀查询才是走索引查询,其他查询都是全表扫描,性能比较差
rowkey:name_id id name age sex addr zhangsan_001 001 zhangsan 18 male shanghai-
走索引:name、name + id
-
现在有40%的需求是按照id、age、setx、addr来查询,不走索引,性能差,怎么办?
-
-
二级索引问题
-
问题: Hbase使用Rowkey作为唯一索引,只有按照rowkey的前缀查询才是走索引查询,其他查询都是全表扫描,性能比较差
*rowkey:name_id id name age sex addr zhangsan_001 001 zhangsan 18 maleshanghai-
现在有40%的需求是按照id、age、setx、addr来查询,不走索引,性能差,怎么办?
-
走索引:name、name + id
-
-
解决:二级索引
-
思想:通过走两次索引来代替全表扫描
-
step1:基于存储和常用查询需求,构建原始数据表
-
step2:基于其他查询需求,构建索引表
-
step3:先查询索引表,再查询数据表
-
-
-
解决:基于不同查询条件构建不同二级索引表,先根据条件查询对应索引表,再查询原表
-
缺点
-
必须保证索引表与原表数据一致性问题
-
不同条件需要不同的索引表,每次原表发生数据变化,所有的索引表都要同步变化:管理非常麻烦
-
-
解决方案
-
方案一:手动维护
-
自己手动建索引表,自己手动维护同步,自己手动实现检索过程
create(source_t1) create(index_age_t1) put 't1','zhangsan_001' put 'index_age_t1','20_zhangsan_001' if (condition = age) rk = scan (index_age_t1) scan(source_t1,rk) -
缺点:代码开发麻烦,无法保证一致性
-
肯定不用
-
-
方案二:自己开发协处理器
-
监听原表,只要原表数据发生变化,自动对索引表进行操作
-
优点:实现索引表与原表的同步
-
缺点:索引表非常多,同步需求非常多,协处理器API非常繁琐,开发协处理器成本非常高
-
-
方案三:第三方工具
-
Phoenix:底层是大量已经开发好的封装好的协处理器来实现的API操作
-
开发者只要写SQL
create index -
自动创建索引表
-
自动维护索引表
-
自动查询索引表
-
-
-
-
-
-
小结
-
什么是Hbase的二级索引?
-
思想:通过走两次索引来代替全表扫描
-
实现
-
step1:先基于查询条件构建条件索引表
-
step2:查询时,先根据查询条件查询索引表,得到原表的rowey
- index table rowkey:查询条件 + 原表的Rowkey
-
step3:在根据获取的原表的rowkey查询原表
-
-
问题:索引表非常多,索引同步非常麻烦
-
解决:用第三方工具来实现:Phoenix
-
-
12.Phoenix
Phoenix的介绍
- 功能
-
使用Phoenix自动构建二级索引并维护二级索引
-
使用Phoenix实现基于SQL操作Hbase
-
专门基于Hbase所设计的SQL on Hbase 工具
-
原理
-
上层提供了SQL接口
- 底层全部通过Hbase Java API来实现,通过构建一系列的Scan和Put来实现数据的读写
-
功能非常丰富
- 底层封装了大量的内置的协处理器,可以实现各种复杂的处理需求,例如二级索引等
-
-
特点
-
优点
-
支持SQL接口
-
支持自动维护二级索引
-
-
缺点
-
SQL支持的语法不友好,不是通用性SQL
-
Bug比较多
-
-
Hive on Hbase对比
-
Hive:SQL更加全面,但是不支持二级索引,底层通过分布式计算工具来实现
-
Phoenix:SQL相对支持不全面,但是性能比较好,直接使用HbaseAPI,支持索引实现
-
-
-
应用
-
Phoenix适用于任何需要使用SQL或者JDBC来快速的读写Hbase的场景
-
或者需要构建及维护二级索引场景
-
-
Phoenix的安装配置
-
第一台机器上传
cd /export/softwares/ rz -
第一台机器解压
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /export/servers/ cd /export/servers/ mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix-5.0.0-HBase-2.0-bin -
修改三台Linux文件句柄数
vim /etc/security/limits.confbash#在文件的末尾添加以下内容,*号不能去掉 * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 -
将Phoenix所有jar包分发到Hbase的lib目录下
#拷贝到第一台机器 cd /export/servers/phoenix-5.0.0-HBase-2.0-bin/ cp phoenix-* /export/servers/hbase-2.1.0/lib/ #分发给第二台和第三台 cd /export/servers/hbase-2.1.0/lib/ scp phoenix-* node02:$PWD scp phoenix-* node03:$PWD -
修改hbase-site.xml,添加一下属性
cd /export/servers/hbase-2.1.0/conf/ vim hbase-site.xmlbash<!-- 关闭流检查,从2.x开始使用async --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <!-- 支持HBase命名空间映射 --> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <!-- 支持索引预写日志编码 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> -
同步给其他两台机器
scp hbase-site.xml node02:$PWD scp hbase-site.xml node03:$PWD -
同步给Phoenix
cp hbase-site.xml /export/servers/phoenix-5.0.0-HBase-2.0-bin/bin/ -
重启Hbase
stop-hbase.sh start-hbase.sh -
安装依赖
yum -y install python-argparse -
启动Phoenix
cd /export/servers/phoenix-5.0.0-HBase-2.0-bin/ bin/sqlline.py node01:2181 -
测试
!tables -
退出
!quit
Phoenix的DDL语法:NS
-
实施
-
创建NS
create schema if not exists student;, -
切换NS
use student; -
删除NS
drop schema if exists student;
-
-
小结
-
基本与SQL语法一致
-
注意:Phoenix中默认会将所有字符转换为大写,如果想要使用小写字母,必须加上双引号
-
Phoenix的DDL语法:Table
-
列举
!tables -
创建
注意规则:
建表的时候要指定字段
谁是primary key 谁就是rowkey,每张表必须有主键
定义字段时,要指定列族,列族的属性可以在建表语句中指定
split:指定建表构建多个分区,每个分区段划分语法示例:
bashCREATE TABLE my_schema.my_table ( id BIGINT not null primary key, date Date ); CREATE TABLE my_table ( id INTEGER not null primary key desc, m.date DATE not null, m.db_utilization DECIMAL, i.db_utilization ) m.VERSIONS='3'; CREATE TABLE stats.prod_metrics ( host char(50) not null, created_date date not null, txn_count bigint CONSTRAINT pk PRIMARY KEY (host, created_date) ); CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"( "id" char(10) not null primary key, "value" integer ) DATA_BLOCK_ENCODING='NONE',VERSIONS=5,MAX_FILESIZE=2000000 split on (?, ?, ?); CREATE TABLE IF NOT EXISTS my_schema.my_table ( org_id CHAR(15), entity_id CHAR(15), payload binary(1000), CONSTRAINT pk PRIMARY KEY (org_id, entity_id) ) TTL=86400如果Hbase中已存在会自动关联【常用】
Hbase中建表并导入数据
bashHbase shell ORDER_INFO.txtPhoenix中建表
bashcreate table if not exists ORDER_INFO(){ "id" varchar primary key, "C1"."USER_ID" varchar, "C1"."OPERATION_DATE" varchar, "C1"."PAYWAY" varchar, "C1"."PAY_MONEY" varchar, "C1"."STATUS" varchar, "C1"."CATEGORY" varchar } column_encoded_bytes=0;表名与列名都必须一致,大小写严格区分
-
查看
bash!desc order_info; -
删除
bashdrop table if exists order_dt1;
小结 :
-
创建表时,必须指定主键作为Rowkey,主键列不能加列族
-
Phoenix 4.8版本之前只要创建同名的Hbase表,会自动关联数据
-
Phoenix 4.8版本以后,不推荐关联表的方式
-
推荐使用视图关联的方式来实现,如果要使用关联表的方式,必须加上以下参数
bashcolumn_encoded_bytes=0;
Phoenix的DML语法:upsert
基于order_info订单数据实现DML插入数据
-
插入一条数据
bashupsert into order_info values('z8f3ca6f-2f5c-44fd-9755-1792de183845','4944191','2020-04-25 12:09:16','1','4070','未提交','电脑'); -
更新USERID为123456
bashupsert into order_info("id","USER_ID") values('z8f3ca6f-2f5c-44fd-9755-1792de183845','123456');
Phoenix的DML语法:delete
-
语法及示例
bashDELETE FROM TEST; DELETE FROM TEST WHERE ID=123; DELETE FROM TEST NAME LIKE 'foo%'; -
删除USER_ID为123456的rowkey数据
bashdelete from order_info where USER_ID='123456';
总结:与MySQL是一致的
Phoenix的DQL语法:select
基于order_info订单数据实现DQL查询数据
-
语法及示例
bashSELETE * FROM TEST LIMIT 1000; SELECT * FROM TEST LIMIT 1000 OFFSET 100; SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0 UNION ALL SELECT reviewer_name FROM CUSTOMER_REVIEW WHERE score >= 8.0 -
查询支付方式为1的数据
bashselete "id",payway,pay_money,category from order_info where payway='1'; -
查询每种支付方式对应的用户人数,并且按照用户人数降序排序
bashselete payway, count(distinct user_id) as numb from order_info group by payway order by numb desc; -
查询数据的第60行到66行
bashselect * from order_info limit 7 offset 59; -
小结:
基本查询与MySQL也是一致的,写的时候注意数据类型以及大小写的问题即可,如果遇到SQL报错,检查语法是否支持
Phoenix的使用:预分区
创建表的时候,需要根据Rowkey来设计多个分区
-
Hbase命令建表
bashcreate Ns;tbname,列族,预分区 -
Phoenix也提供了创建表时,指定分区范围的语法
bashCREATE TABLE IF NOT EXISTS "my_case_sensitive_table"( "id" char(10) not null primary key, "value" integer ) DATA_BLOCK_ENCODING='NONE',VERSIONS=5,MAX_FILESIZE=2000000 split on (?, ?, ?) -
创建数据表,四个分区
bashdrop table if exists ORDER_DTL; create table if not exists ORDER_DTL( "id" varchar primary key, C1."status" varchar, C1."money" float, C1."pay_way" integer, C1."user_id" varchar, C1."operation_time" varchar, C1."category" varchar ) CONPRESSION='GZ' SPLIT ON ('3','5','7');
Phoenix的使用:加盐salt
Rowkey设计的时候为了避免连续,构建Rowkey的散列,如果rowkey设计是连续的,怎么解决?
正常表:tb1:3个分区:
r1:-oo ~ 3
r2: 3 ~ 6
r3: 6 ~ +oo
rowkey:数值开头
盐表:
t2:3个分区
每个分区的前缀是16进制的值
rowkey:数值开头,但是Phoenix会自动为每个rowkey前面加上一个16进制的值
-
在Phoenix创建一张盐表,写入的数据会自动进行编码写入不同的分区中
bashcreate Table table ( a_key varchar primary key, a_col varchar )salt_buckets=20;//20个分区 -
创建一张盐表,指定分区个数为10
bashdrop table if exists ORDER_DTL; create table if not exists ORDER_DTL( "id" varchar primary key; C1."status" varchar, C1."money" float, C1."pay_way" integer, C1."user_id" varchar, C1."operation_time" varchar, C1."category" varchar )CONPRESSION="GZ",SALT_BUCKETS=10; -
写入数据
sqlUPSERT INTO "ORDER_DTL" VALUES('02602f66-adc7-40d4-8485-76b5632b5b53','已提交',4070,1,'4944191','2020-04-25 12:09:16','手机;'); UPSERT INTO "ORDER_DTL" VALUES('0968a418-f2bc-49b4-b9a9-2157cf214cfd','已完成',4350,1,'1625615','2020-04-25 12:09:37','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('0e01edba-5e55-425e-837a-7efb91c56630','已提交',6370,3,'3919700','2020-04-25 12:09:39','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('0f46d542-34cb-4ef4-b7fe-6dcfa5f14751','已付款',9380,1,'2993700','2020-04-25 12:09:46','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('1fb7c50f-9e26-4aa8-a140-a03d0de78729','已完成',6400,2,'5037058','2020-04-25 12:10:13','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('23275016-996b-420c-8edc-3e3b41de1aee','已付款',280,1,'3018827','2020-04-25 12:09:53','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('2375a7cf-c206-4ac0-8de4-863e7ffae27b','已完成',5600,1,'6489579','2020-04-25 12:08:55','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('269fe10c-740b-4fdb-ad25-7939094073de','已提交',8340,2,'2948003','2020-04-25 12:09:26','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('2849fa34-6513-44d6-8f66-97bccb3a31a1','已提交',7060,2,'2092774','2020-04-25 12:09:38','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('28b7e793-6d14-455b-91b3-0bd8b23b610c','已提交',640,3,'7152356','2020-04-25 12:09:49','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('2909b28a-5085-4f1d-b01e-a34fbaf6ce37','已提交',9390,3,'8237476','2020-04-25 12:10:08','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('2a01dfe5-f5dc-4140-b31b-a6ee27a6e51e','已提交',7490,2,'7813118','2020-04-25 12:09:05','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('2b86ab90-3180-4940-b624-c936a1e7568d','已付款',5360,2,'5301038','2020-04-25 12:08:50','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('2e19fbe8-7970-4d62-8e8f-d364afc2dd41','已付款',6490,0,'3141181','2020-04-25 12:09:22','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('2fc28d36-dca0-49e8-bad0-42d0602bdb40','已付款',3820,1,'9054826','2020-04-25 12:10:04','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('31477850-8b15-4f1b-9ec3-939f7dc47241','已提交',4650,2,'5837271','2020-04-25 12:08:52','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('39319322-2d80-41e7-a862-8b8858e63316','已提交',5000,1,'5686435','2020-04-25 12:08:51','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('3d2254bd-c25a-404f-8e42-2faa4929a629','已完成',5000,1,'1274270','2020-04-25 12:08:43','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('42f7fe21-55a3-416f-9535-baa222cc0098','已完成',3600,2,'2661641','2020-04-25 12:09:58','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('44231dbb-9e58-4f1a-8c83-be1aa814be83','已提交',3950,1,'3855371','2020-04-25 12:08:39','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('526e33d2-a095-4e19-b759-0017b13666ca','已完成',3280,0,'5553283','2020-04-25 12:09:01','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('5a6932f4-b4a4-4a1a-b082-2475d13f9240','已提交',50,2,'1764961','2020-04-25 12:10:07','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('5fc0093c-59a3-417b-a9ff-104b9789b530','已提交',6310,2,'1292805','2020-04-25 12:09:36','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('605c6dd8-123b-4088-a047-e9f377fcd866','已完成',8980,2,'6202324','2020-04-25 12:09:54','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('613cfd50-55c7-44d2-bb67-995f72c488ea','已完成',6830,3,'6977236','2020-04-25 12:10:06','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('62246ac1-3dcb-4f2c-8943-800c9216c29f','已提交',8610,1,'5264116','2020-04-25 12:09:14','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('625c7fef-de87-428a-b581-a63c71059b14','已提交',5970,0,'8051757','2020-04-25 12:09:07','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('6d43c490-58ab-4e23-b399-dda862e06481','已提交',4570,0,'5514248','2020-04-25 12:09:34','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('70fa0ae0-6c02-4cfa-91a9-6ad929fe6b1b','已付款',4100,1,'8598963','2020-04-25 12:09:08','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('7170ce71-1fc0-4b6e-a339-67f525536dcd','已完成',9740,1,'4816392','2020-04-25 12:09:51','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('71961b06-290b-457d-bbe0-86acb013b0e3','已完成',6550,3,'2393699','2020-04-25 12:08:49','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('72dc148e-ce64-432d-b99f-61c389cb82cd','已提交',4090,1,'2536942','2020-04-25 12:10:12','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('7c0c1668-b783-413f-afc4-678a5a6d1033','已完成',3850,3,'6803936','2020-04-25 12:09:20','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('7fa02f7a-10df-4247-9935-94c8b7d4dbc0','已提交',1060,0,'6119810','2020-04-25 12:09:21','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('820c5e83-f2e0-42d4-b5f0-83802c75addc','已付款',9270,2,'5818454','2020-04-25 12:10:09','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('83ed55ec-a439-44e0-8fe0-acb7703fb691','已完成',8380,2,'6804703','2020-04-25 12:09:52','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('85287268-f139-4d59-8087-23fa6454de9d','已取消',9750,1,'4382852','2020-04-25 12:10:00','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('8d32669e-327a-4802-89f4-2e91303aee59','已提交',9390,1,'4182962','2020-04-25 12:09:57','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('8dadc2e4-63f1-490f-9182-793be64fed76','已付款',9350,1,'5937549','2020-04-25 12:09:02','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('94ad8ee0-8898-442c-8cb1-083a4b609616','已提交',4370,0,'4666456','2020-04-25 12:09:13','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('994cbb44-f0ee-45ff-a4f4-76c87bc2b972','已付款',3190,3,'3200759','2020-04-25 12:09:25','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('9ff3032c-8679-4247-9e6f-4caf2dc93aff','已提交',850,0,'8835231','2020-04-25 12:09:40','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('9ff4032c-1223-4247-9e6f-123456dfdsds','已付款',850,0,'8835231','2020-04-25 12:09:45','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('a467ba42-f91e-48a0-865e-1703aaa45e0e','已提交',8040,0,'8206022','2020-04-25 12:09:50','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('a5302f47-96d9-41b4-a14c-c7a508f59282','已付款',8570,2,'5319315','2020-04-25 12:08:44','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('a5b57bec-6235-45f4-bd7e-6deb5cd1e008','已提交',5700,3,'6486444','2020-04-25 12:09:27','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('ae5c3363-cf8f-48a9-9676-701a7b0a7ca5','已付款',7460,1,'2379296','2020-04-25 12:09:23','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('b1fb2399-7cf2-4af5-960a-a4d77f4803b8','已提交',2690,3,'6686018','2020-04-25 12:09:55','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('b21c7dbd-dabd-4610-94b9-d7039866a8eb','已提交',6310,2,'1552851','2020-04-25 12:09:15','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('b4bfd4b7-51f5-480e-9e23-8b1579e36248','已提交',4000,1,'3260372','2020-04-25 12:09:35','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('b63983cc-2b59-4992-84c6-9810526d0282','已提交',7370,3,'3107867','2020-04-25 12:08:45','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('bf60b752-1ccc-43bf-9bc3-b2aeccacc0ed','已提交',720,2,'5034117','2020-04-25 12:09:03','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('c808addc-8b8b-4d89-99b1-db2ed52e61b4','已提交',3630,1,'6435854','2020-04-25 12:09:10','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('cc9dbd20-cf9f-4097-ae8b-4e73db1e4ba1','已付款',5000,0,'2007322','2020-04-25 12:08:38','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('ccceaf57-a5ab-44df-834a-e7b32c63efc1','已提交',2660,2,'7928516','2020-04-25 12:09:42','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('d7be5c39-e07c-40e8-bf09-4922fbc6335c','已付款',8750,2,'1250995','2020-04-25 12:09:09','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('dfe16df7-4a46-4b6f-9c6d-083ec215218e','已完成',410,0,'1923817','2020-04-25 12:09:56','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('e1241ad4-c9c1-4c17-93b9-ef2c26e7f2b2','已付款',6760,0,'2457464','2020-04-25 12:08:54','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('e180a9f2-9f80-4b6d-99c8-452d6c037fc7','已完成',8120,2,'7645270','2020-04-25 12:09:32','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('e4418843-9ac0-47a7-bfd8-d61c4d296933','已付款',8170,2,'7695668','2020-04-25 12:09:11','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('e8b3bb37-1019-4492-93c7-305177271a71','已完成',2560,2,'4405460','2020-04-25 12:10:05','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('eb1a1a22-953a-42f1-b594-f5dfc8fb6262','已完成',2370,2,'8233485','2020-04-25 12:09:24','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('ecfd18f5-45f2-4dcd-9c47-f2ad9b216bd0','已付款',8070,3,'6387107','2020-04-25 12:09:04','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('f1226752-7be3-4702-a496-3ddba56f66ec','已付款',4410,3,'1981968','2020-04-25 12:10:10','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('f642b16b-eade-4169-9eeb-4d5f294ec594','已提交',4010,1,'6463215','2020-04-25 12:09:29','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('f8f3ca6f-2f5c-44fd-9755-1792de183845','已付款',5950,3,'4060214','2020-04-25 12:09:12','机票;文娱;'); -
Phoneix中查看
objectivecselect "id" from ORDER_DTL; -
Hbase中查看
objectivecscan'ORDER_DTL'; -
小结:
由Phoenix来实现自动对Rowkey编码,解决Rowkey的热点问题,不需要自己设计散列的Rowkey,
注意:一旦使用了盐表,对于盐表数据的操作只能通过Phoenix来实现,盐表不能自己指定分区段,由Phoenix自己根据自己的规则来实现
Phoenix的使用:视图
直接关联Hbase中的表,会导致误删除,对数据的权限会有影响,容易出现问题,如何避免?
答:Phoenix中建议使用视图的方式来关联Hbase中已有的表,通过构建关联视图,可以解决大部分数据查询的数据,不影响数据,视图:可以理解为只读的表
-
删除Phoenix中的ORDER_INFO
bashdrop table if exists ORDER_INFO;会发现,Hbase中的表也会被删除
-
重新加载
bashhbase shell ORDER_INFO.txt -
创建视图,关联Hbase中已经存在的表
bashcreate view if not exists ORDER_INFO( "id" varchar primary key, "C1"."USER_ID" varchar, "C1"."OPERATION_DATE" varchar, "C1"."PAYWAY" varchar, "C1"."PAY_MONEY" varchar, "C1"."STATUS" varchar, "C1"."CATEGORY" varchar ) ; -
应用场景:
视图:Hbase中已经有这张表,写操作都是操作Hbase,Phoenix只提供读操作
建表:建表:对这张表既要读也要使用Phoenix来写
Phoenix的使用:JDBC
工作中实际使用SQL,会基于程序中使用JDBC的方式来提交SQL语句,在Phoenix中如何实现?
-
Phoenix支持使用JDBC的方式来提交SQL语句
javapublic class HbasePhoenixJDBCTest { public static void main(String[] args) throws SQLException { Connection connection = null; PreparedStatement ps = null; try { Class.forName(PhoenixDriver.class.getName()); connection = DriverManager.getConnection("jdbc:phoenix:node1.itcast.cn:2181"); ps = connection.prepareStatement( "select user_id,payway,category from order_info"); ResultSet rs = ps.executeQuery(); while(rs.next()) { System.out.println( rs.getString("USER_ID")+"\t"+ rs.getString("PAYWAY")+"\t"+ rs.getString("CATEGORY")); } }catch (Exception e){ e.printStackTrace(); }finally { if(ps != null) ps.close(); if(connection != null) connection.close(); } } }
二级索引:全局索引设计
功能:当为某一列创建全局索引时,Phoenix自动创建一张索引表,将创建索引这一列加上原表rowkey作为新的rowkey
-
-
原始数据表
rowkey:id name age -
需求:根据name进行数据查询
- 不走索引
-
创建全局索引
create index index01 on tbname(name); -
自动构建索引表
rowkey:name_id col:占位值 -
查询
-
先查询索引表:通过rowkey获取名称对应的id
-
再查询数据表:通过id查询对应的数据
-
-
**特点:**默认只能对构建索引的字段做索引查询,如果查询中包含了不是索引的字段或者条件不是索引字段,不走索引
-
**应用:**写少读多
-
当原表的数据发生更新操作提交时,会被拦截
-
先更新所有索引表,然后再更新原表
-
-
-
小结
- 了解二级索引中全局索引的设计思想
二级索引:覆盖索引设计
- 功能:在构建全局索引时,将经常作为查询条件或者结果的列放入索引表中,直接通过索引来返回数据结果
- 创建全局索引
create index index01 on tbname(name); - 自动构建索引
rowkey:name_id col:占位值 - 如果需求发生改变,查询name和age,上面的全局索引会失效
- 创建全局+覆盖索引
create index index01 on tbname (name)include(age); - 自动构建索引表
rowkey:name_id col:age - 查询
select name from table;
select name from table where age = 20
select name , age from table - 特点:基于全局索引构建,将常用的查询结果放入索引表中,直接从索引表返回结果,不用再查询原表
- 应用:适合查询条件比较固定,数据量比较小的场景(不建议将大部分列都放入覆盖索引)
小结
-
覆盖索引是基于全局索引实现的
- 全局索引:用查询条件作为索引表rowkey,先查询索引表,再查询原表
-
覆盖索引:用查询条件作为索引表rowkey,将经常查询的列直接放入索引表,查询直接从索引表返回
-
目的是将常用的查询结果放入索引表中,直接从索引表返回数据
二级索引:本地索引设计
功能:将索引数据与对应的原始数据放在同一台机器,避免跨网络传输,提高写的性能
-
与全局和覆盖的区别是什么?
- 全局和覆盖都是单独构建一张索引表
-
本地索引构建索引数据时,将索引数据直接存储在原表中,这条数据和这条数据的索引存储同一个region中
-
满足:提高读的性能,也能降低对写的影响
-
本地索引不会创建索引表
-
怎么保证数据和索引能写入同一个region呢?
-
数据:rowkey:id:001 name=zhangsan
-
索引:rowkey:zhangsan_001
-
为了保证索引和原始数据能写入同一个region,将这条数据对应的region的startkey作为索引rowkey前缀
-
-
-
本地索引的设计方式是:
原表数据所在region的start key+"\x00"+第一个二级索引字段+"\x00"+第二个二级索引字段...+"\x00"+原表rowkey
-
本地索引的创建举例:
create local index LOCAL_IDX_ORDER_DTL on ORDER_DTL("id", "status", "money", "pay_way", "user_id") ;
-
region划分
-
region0: -oo 30
-
region1:30 60
-
region2:60 +oo
-
-
写入一条Rowkey:456 lisi 到原表的region中
- region1
-
目的:将这条rowkey的索引存在同一台机器的region中
-
30_索引字段 _ 原表的Rowkey
-
30_lisi_456
-
-
特点:
即使查询数据中包含了非索引字段,也会走本地索引
本地索引会修改原始数据表
如果构建了本地索引,不能通过Hbase的API来读写数据的,必须通过Phoenix来实现读写本地
索引对盐表不生效的
-
应用:写的操作比较多,提高了构建索引对写的性能影响,