Spire.PDF 完美支持将多页 PDF 拆分为单页。但是,更常见的情况是,您可能希望提取选定的页面范围并保存为新的 PDF 文档。在本文中,您将学习如何通过 Spire.PDF 在 C#、VB.NET 中根据页面范围拆分 PDF 文件。
Spire.PDF for .NET 是一款独立 PDF 控件,用于 .NET 程序中创建、编辑和操作 PDF 文档。使用 Spire.PDF 类库,开发人员可以新建一个 PDF 文档或者对现有的 PDF 文档进行处理,且无需安装 Adobe Acrobat。
E-iceblue功能类库Spire 系列文档处理组件均由中国本土团队研发,不依赖第三方软件,不受其他国家的技术或法律法规限制,同时适配国产操作系统如中科方德、中标麒麟等,兼容国产文档处理软件 WPS(如 .wps/.et/.dps 等格式
Spire.PDF for.net下载 Spire.PDF for java下载
以下是详细步骤:
步骤1 :初始化 PdfDocument类的新实例并加载测试文件。
PdfDocument pdf = new PdfDocument(); pdf.LoadFromFile("Sample.pdf");
第2步:创建一个名为pdf1的新PDF文档,初始化 PdfPageBase类的新实例。
PdfDocument pdf1 = new PdfDocument(); PdfPageBase page;
步骤 3 :根据原始页面大小和指定的边距向 pdf1 添加新页面,使用**Draw()**方法将原始页面元素绘制到新页面。使用 for 循环选择要划分的页面。
for (int i = 0; i < 5; i++) { page = pdf1.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0)); pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0)); }
步骤 4:保存文件。
pdf1.SaveToFile("DOC_1.pdf");
步骤 5:重复步骤 2 至步骤 4,将另一范围的页面提取到新的 PDF 文件中。更改参数 i 以选择页面。
PdfDocument pdf2 = new PdfDocument(); for (int i = 5; i < 8; i++) { page = pdf2.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0)); pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0)); } pdf2.SaveToFile("DOC_2.pdf");
结果:
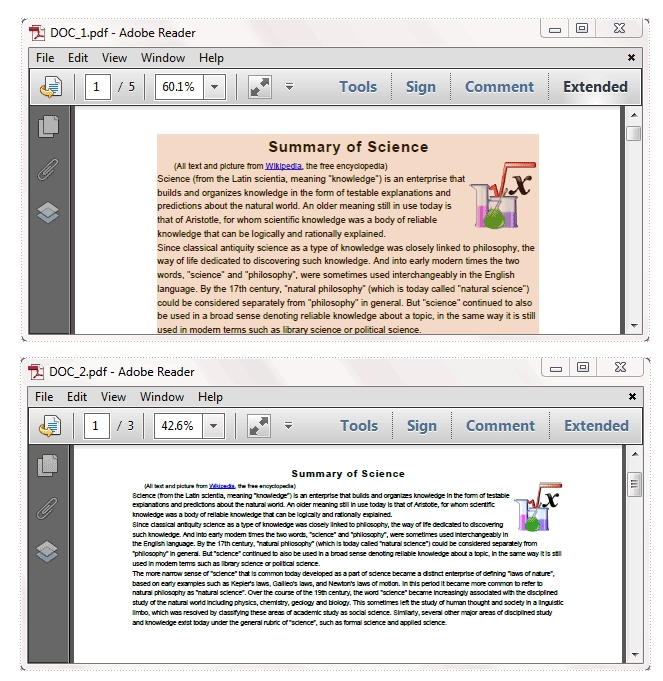
完整代码:
C#
using Spire.Pdf; namespace SplitPDFFile { class Program { static void Main(string[] args) { PdfDocument pdf = new PdfDocument(); pdf.LoadFromFile("Sample.pdf"); PdfDocument pdf1 = new PdfDocument(); PdfPageBase page; for (int i = 0; i < 5; i++) { page = pdf1.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0)); pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0)); } pdf1.SaveToFile("DOC_1.pdf"); PdfDocument pdf2 = new PdfDocument(); for (int i = 5; i < 8; i++) { page = pdf2.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0)); pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0)); } pdf2.SaveToFile("DOC_2.pdf"); } } }
VB.NET
Imports Spire.Pdf Namespace SplitPDFFile Class Program Private Shared Sub Main(args As String()) Dim pdf As New PdfDocument() pdf.LoadFromFile("Sample.pdf") Dim pdf1 As New PdfDocument() Dim page As PdfPageBase For i As Integer = 0 To 4 page = pdf1.Pages.Add(pdf.Pages(i).Size, New Spire.Pdf.Graphics.PdfMargins(0)) pdf.Pages(i).CreateTemplate().Draw(page, New System.Drawing.PointF(0, 0)) Next pdf1.SaveToFile("DOC_1.pdf") Dim pdf2 As New PdfDocument() For i As Integer = 5 To 7 page = pdf2.Pages.Add(pdf.Pages(i).Size, New Spire.Pdf.Graphics.PdfMargins(0)) pdf.Pages(i).CreateTemplate().Draw(page, New System.Drawing.PointF(0, 0)) Next pdf2.SaveToFile("DOC_2.pdf") End Sub End Class End Namespace