Kafka 介绍
Kafka 是一种分布式的,基于发布/订阅的消息系统。它最初由 LinkedIn 开发,并于 2011 年开源。Kafka 的设计目标是提供一种高效、可靠的消息传输机制,能够处理大量的实时数据。
Kafka 基本概念
-
Producer:生产者,负责将消息发布到 Kafka 主题中。
-
Consumer:消费者,负责从 Kafka 主题中订阅消息并进行处理。
-
Broker:Kafka 服务器,负责存储和管理消息。
-
Topic:主题,是消息的分类,类似于邮件的标签。
-
Partition:分区,是 Kafka 中存储消息的单元,每个主题可以被分为多个分区。
-
Offset:偏移量,是每个分区中消息的唯一标识。
Kafka 工作原理
-
生产者将消息发送到 Kafka 服务器的指定主题中。
-
Kafka 服务器将消息存储到对应的分区中,并为每个消息分配一个唯一的偏移量。
-
消费者通过订阅主题来接收消息,并根据偏移量来标识已经消费的消息。
-
消费者可以按照自己的需求来处理消息,例如将消息写入数据库,或者进行实时分析。
Kafka 优势
-
高吞吐量:Kafka 能够支持每秒百万级别的消息处理。
-
可靠性:Kafka 提供了数据的冗余存储和容错机制,保证消息不丢失。
-
分布式:Kafka 是一个分布式系统,支持水平扩展,可以轻松应对大规模的数据处理需求。
-
实时性:Kafka 支持实时的消息传输,保证消息的实时性。
-
可扩展性:Kafka 提供了丰富的 API 和插件,方便用户进行二次开发和扩展。
Kafka 应用场景
-
日志处理:Kafka 可以用于收集和处理大规模的日志数据,例如网站日志、应用日志等。
-
数据传输:Kafka 可以用于在不同的系统之间传输数据,例如将数据从数据库同步到数据仓库。
-
实时数据处理:Kafka 可以用于实时处理和分析数据,例如实时监控、实时推荐等。
-
分布式事务:Kafka 可以用于实现分布式事务,保证数据的一致性。
Kafka 总结
Kafka 是一种非常强大的分布式消息系统,它具有高吞吐量、可靠性、实时性、可扩展性等优势,被广泛应用于日志处理、数据传输、实时数据处理、分布式事务等领域。通过对 Kafka 的学习,我们了解了它的基本概念、工作原理、优势和应用场景。在以后的工作中,我们可以根据实际需求来选择是否使用 Kafka,以及如何更好地使用 Kafka 来解决问题。
Kafka 动画演示
-
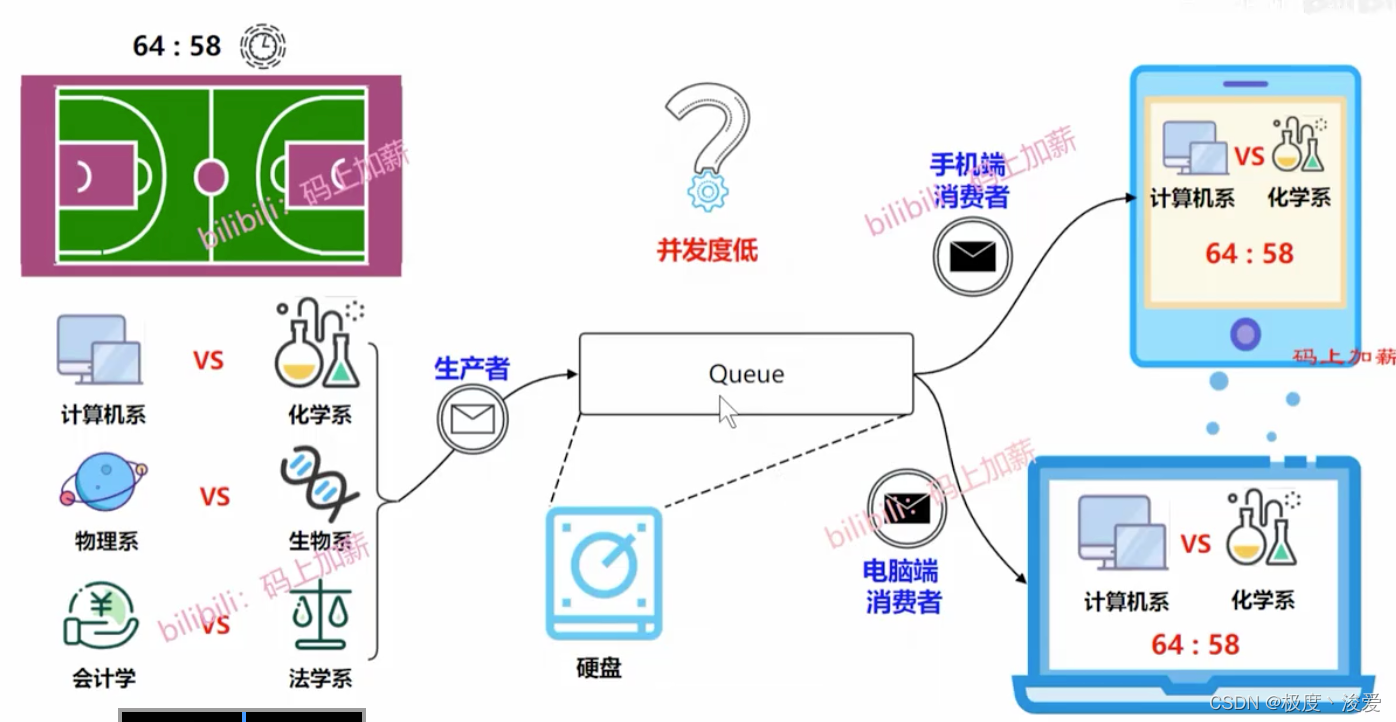
篮球比赛,实况转播相当于消费者,不同的移动端看比赛相当于是消费者。
-
数据都写入队列中,队列相当于是硬盘
-
单队列转播效率太低,可以搞多个队列
-
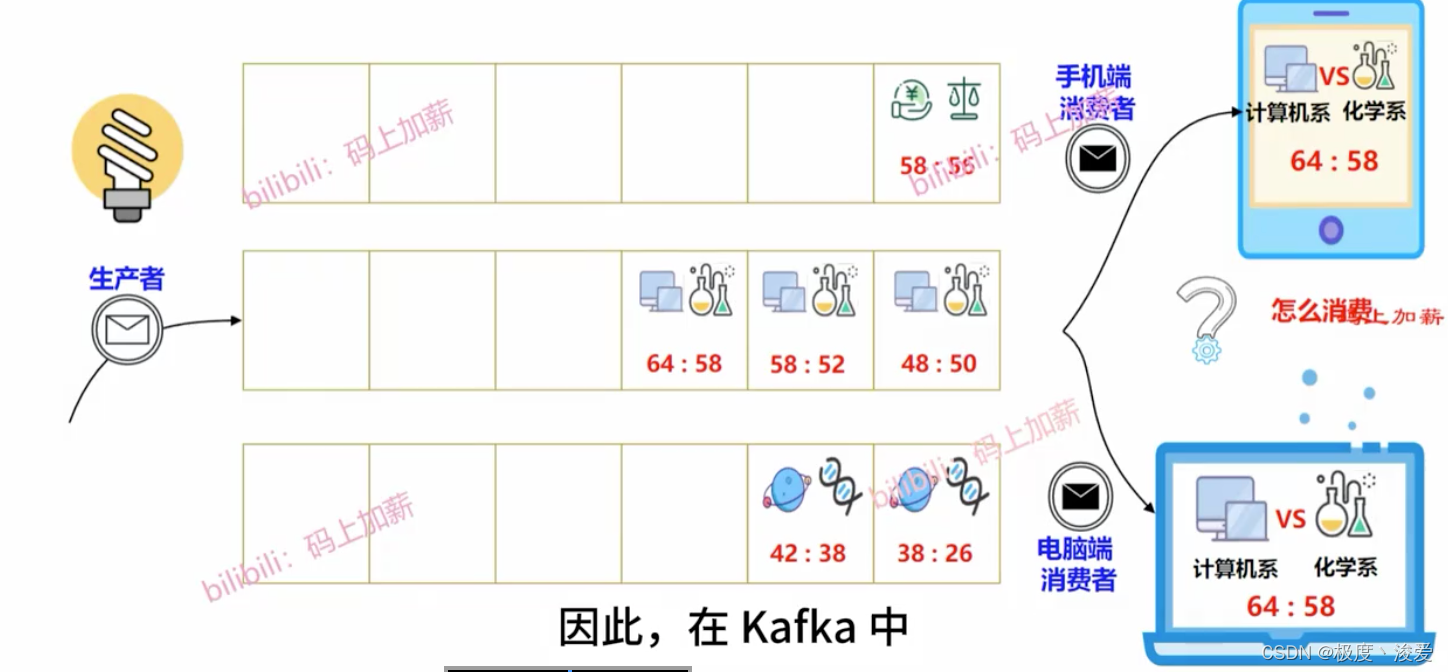
生产者将不同比赛的信息发送到不同的队列,消费者自主选择队列
-
这些不同的队列在kafka内分成不同的分区partition,队列整体叫做topic
-
分区的每条记录叫做record
-
Partition key相当于比赛的队
-
每条消息在分区中的位置被称为消息的offset,顺序从0开始单调递增

-
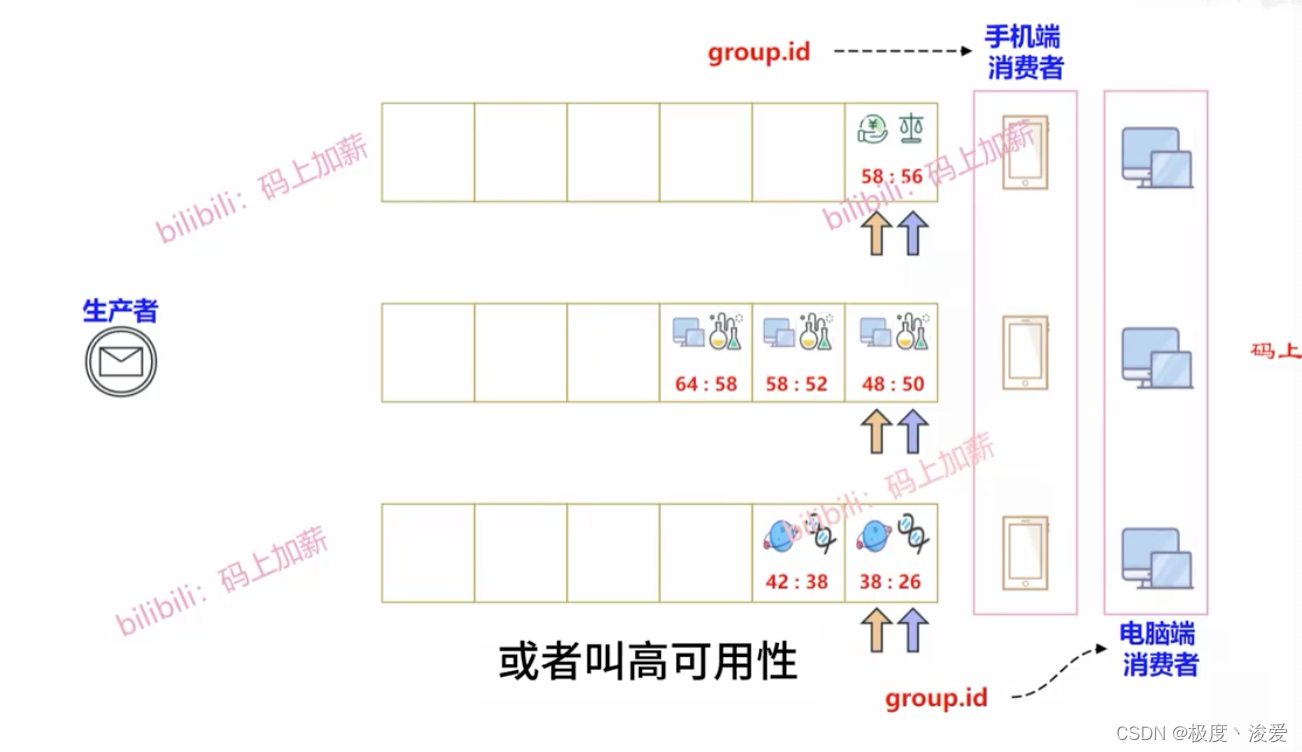
消费者如何消费数据
-
每个消费者可以topic中所有的partition
-
消费者进行划分,同一个的组的数据只能去指定的分区中消费
-
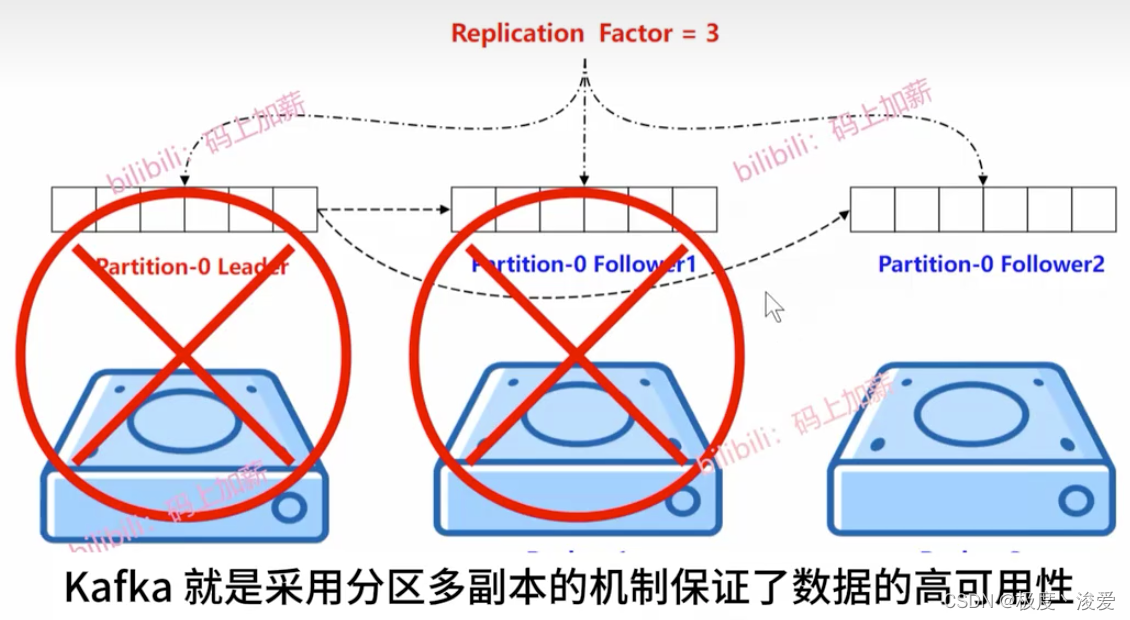
Kafka如何保障数据的高可用?
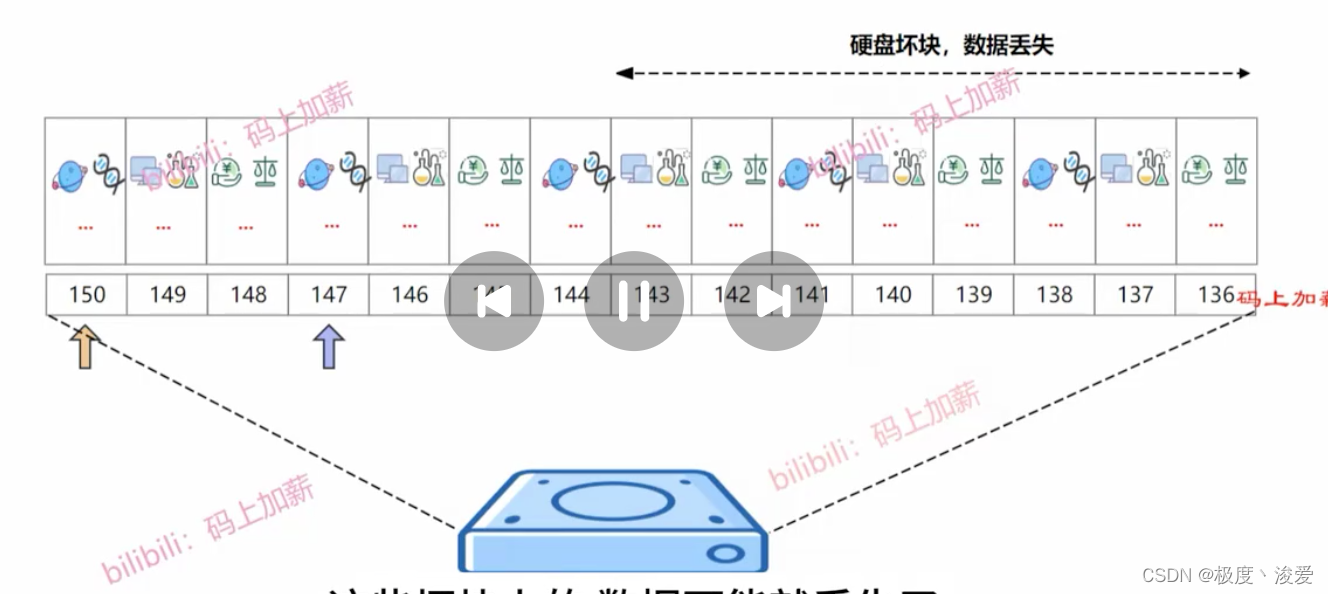
分区存在副本,每个副本的功能是备份。