文章目录
- 1、SpringCloud五大组件
- 2、服务注册和发现
-
- [2.1 Eurake](#2.1 Eurake)
- [2.2 Eurake和Nacos的区别](#2.2 Eurake和Nacos的区别)
- 3、Ribbon负载均衡
-
- [3.1 策略](#3.1 策略)
- [3.2 自定义负载均衡策略](#3.2 自定义负载均衡策略)
- 4、服务雪崩与熔断降级
-
- [4.1 服务雪崩](#4.1 服务雪崩)
- [4.2 服务降级](#4.2 服务降级)
- [4.3 服务熔断](#4.3 服务熔断)
- 5、微服务监控
- 6、面试
1、SpringCloud五大组件
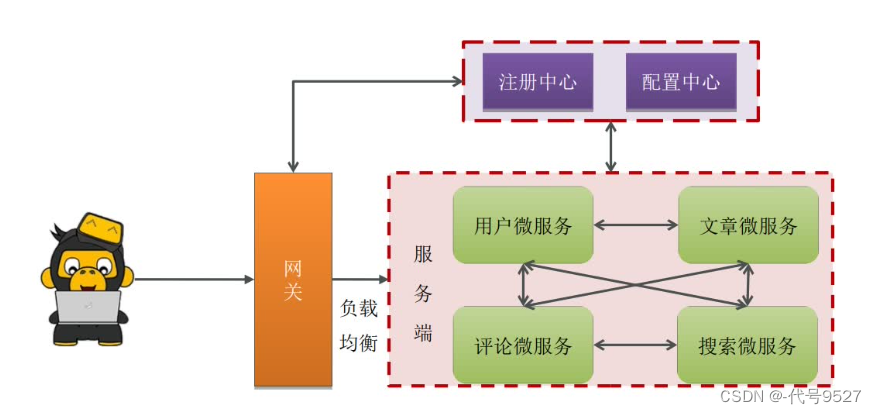
通常情况下:
- Eureka:服务注册中心(注册自己的地址上来,方便后续路由转发到对应的服务上去干活儿)
- Ribbon:负载均衡
- Feign:远程调用
- Hystrix:服务熔断
- zuul/Gateway:网关
实际项目用到了SpringCloudAlibaba相关的组件:
- Nacos:服务注册中心/配置管理
- Ribbon:负载均衡
- Feign:远程调用
- Sentinel:服务熔断
- Gateway:网关
2、服务注册和发现
微服务中,关于注册中心:
- 作用:服务注册和发现
- 常见选择:Nacos、Eureka、Zookeeper
2.1 Eurake
以Eureka为例:
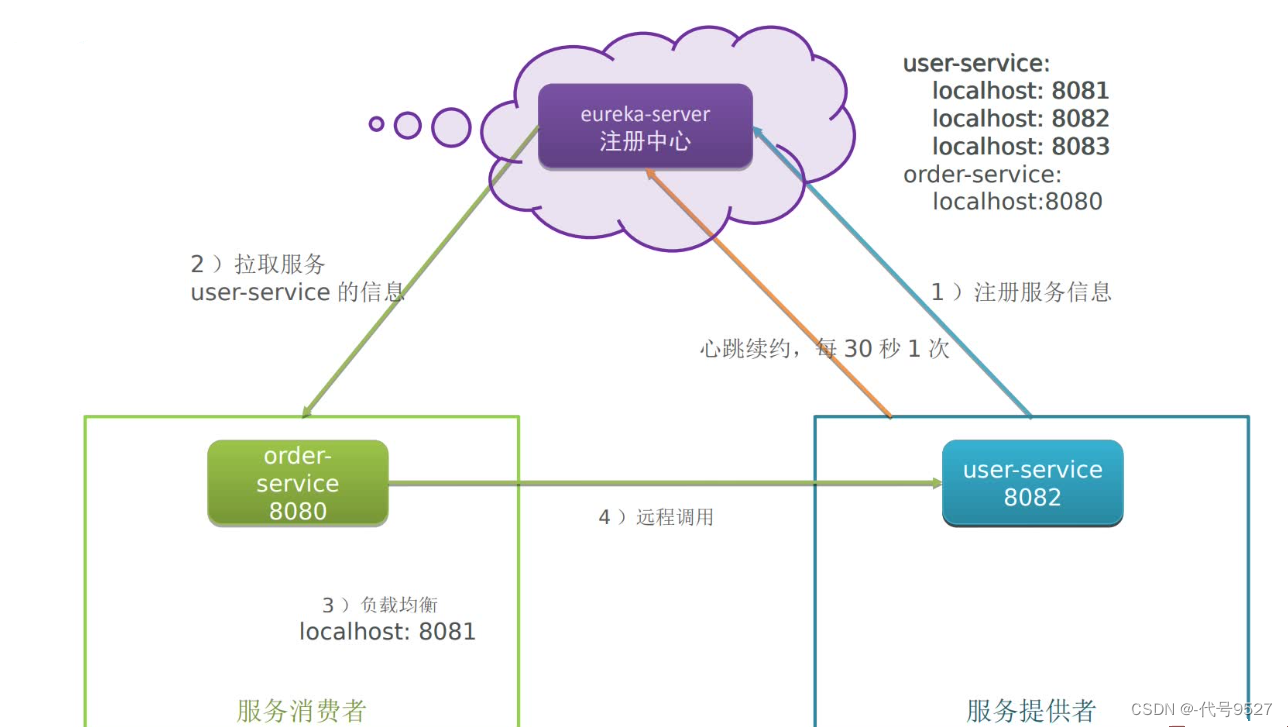
比如order服务需要远程调用user服务,则前者为服务消费者、后者为服务提供者,服务启动后详情如下,体现了Eurake的三个功能:
- 服务注册:微服务向注册中心注册自己的实例信息(服务名称、IP、端口),比如user有三个实例(Pod),地址分别为localhost:8081、8082、8083
- 服务发现:order作为服务消费者调用user服务时,从注册中心拉取注册信息,并利用负载均衡算法选择user的某一个实例,进行远程调用
- 服务监控:每个实例定期向注册中心发送心跳,比如user-service:8083实例挂掉,注册中心收不到其心跳信息,则从服务列表中删掉其注册信息
2.2 Eurake和Nacos的区别
二者的共同点:
- 都支持服务的注册和注册信息拉取
- 都支持服务提供者心跳方式做健康检查
区别:
sql
1)Nacos还支持做配置管理,Eurake只有注册中心
sql
2)Nacos临时实例采用心跳模式,非临时实例采用主动检测模式使用Nacos时,可以加这个配置,设置为非临时实例(默认临时实例):
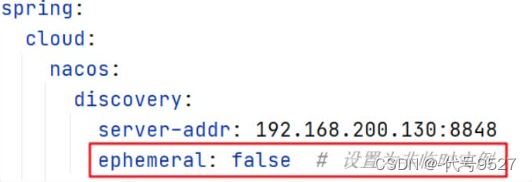
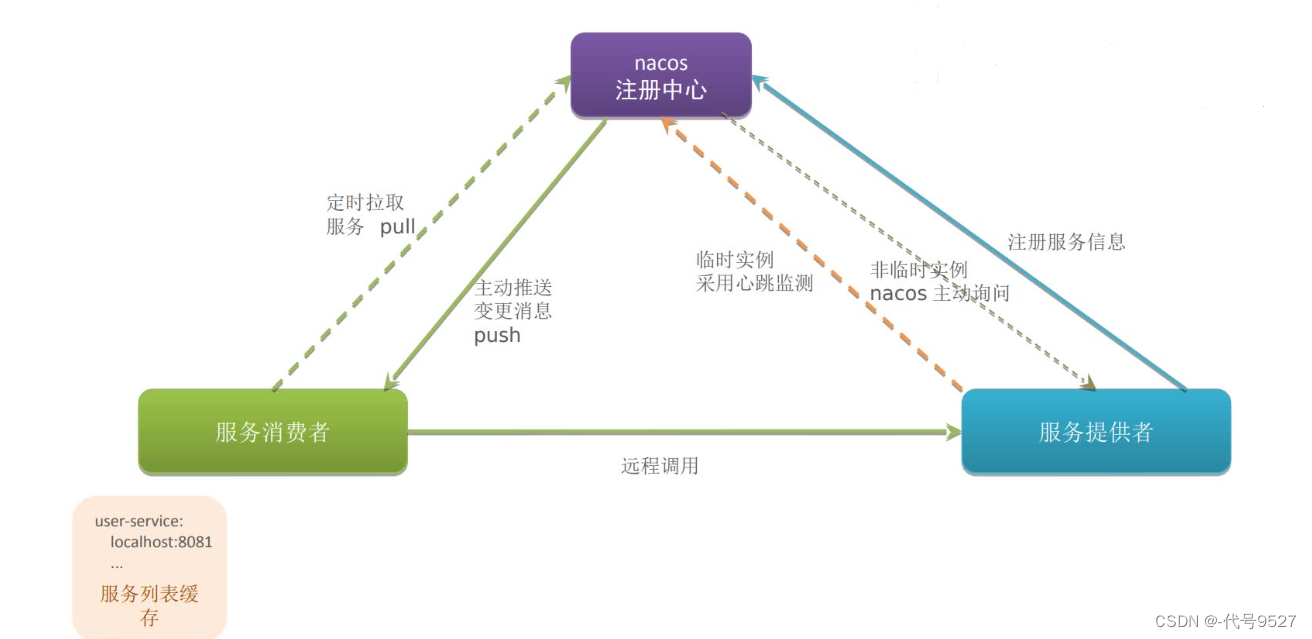
默认的临时实例,其健康检测和Eurake一样,但当设置为非临时实例时,Nacos注册中心会主动发消息询问这个实例还活着没,而不是实例向注册中心发送心跳信息。临时实例心跳不正常会被剔除,非临时实例则不会被剔除。
sql
3)服务注册信息发生变化时,Naocs会将列表变更推送到服务消费者,即服务列表实时更新如上图,即Nacos即支持服务主动定时pull拉取注册列表信息,也支持主动将变更push到服务
sql
4)Nacos集群默认是AP,即追求高可用,但当集群中存在非临时实例时,采用CP模式,即强一致性,而Eurake采用AP3、Ribbon负载均衡
3.1 策略
采用Feign远程调用时,底层是Ribbon在做负载均衡,流程如下: 从注册中心拉取的服务提供者实例列表,根据负载均衡策略,选择一个实例,比如轮询策略
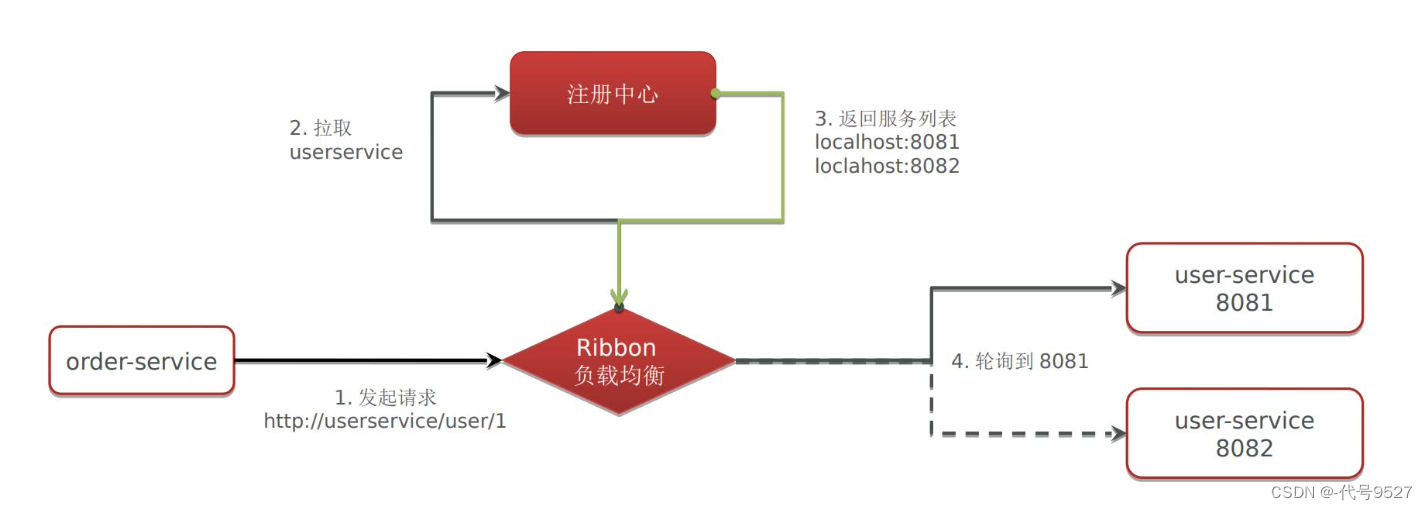
Ribbon负载均衡策略:轮流、随机、选响应快的、选比较空闲的
- 轮询:RoundRobinRule
- 按照权重来选实例,响应时间越长,权重越小:WeightedResponseTimeRule
- 随机选择一个可用的实例:RandomRule
- 忽略那些短路的实例,并选择并发数较低的实例(比较空闲的一个):BestAvailableRule
- 重试(轮询的实例宕机,重试):RetryRule
- 可用性敏感策略,先过滤非健康的,再选择连接数较小的实例:AvailabilityFilteringRule
- 区域敏感策略(默认策略,以区域可用的实例为基础进行实例的选择,使用 Zone 对实例进行分类,这个 Zone 可以理解为一个机房、一个机架等,后再对 Zone 内的多个服务做轮询。比如就近选择上海的机房服务器,而不选择放在北京的服务器,没有区域的概念则就是一个轮询):ZoneAvoidanceRule
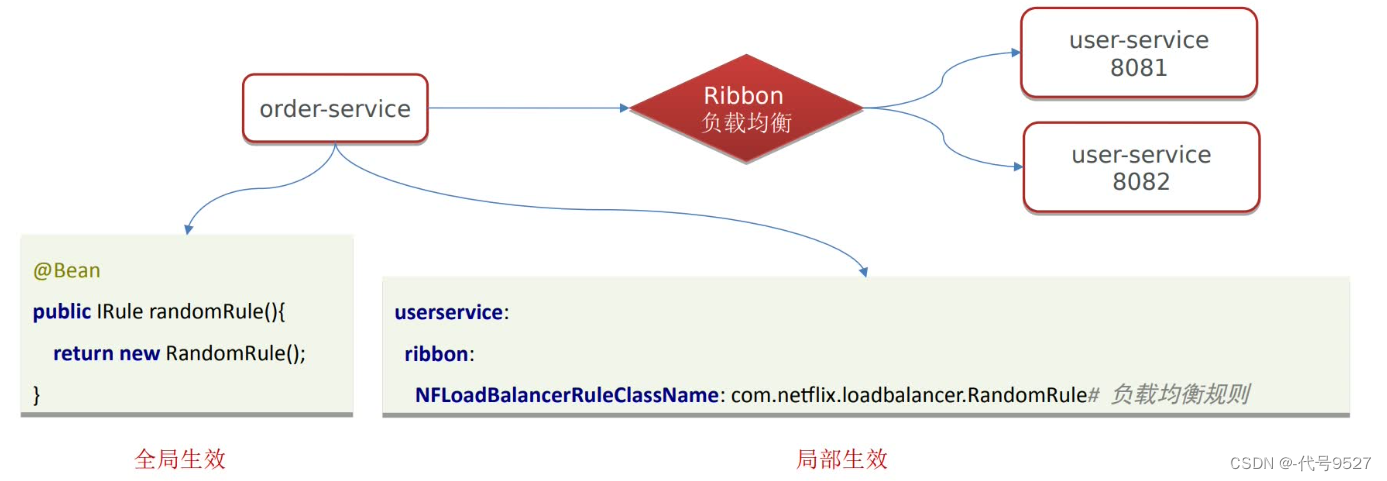
3.2 自定义负载均衡策略
方式一:
在服务消费方(发起调用的那一方),创建IRule的Bean,返回一个IRule接口的实现类,不同的实现类,对应上面的一个个策略。如此,order调用任何一个微服务,都是这种负载均衡策略。
方式二:
在配置文件中,针对调用哪一个微服务时,使用哪种策略,局部生效,只针对order调用user这一个微服务时生效。
4、服务雪崩与熔断降级
4.1 服务雪崩
服务雪崩即:一个服务宕机,导致整个调用链上的其他服务因连接数耗尽也不可用
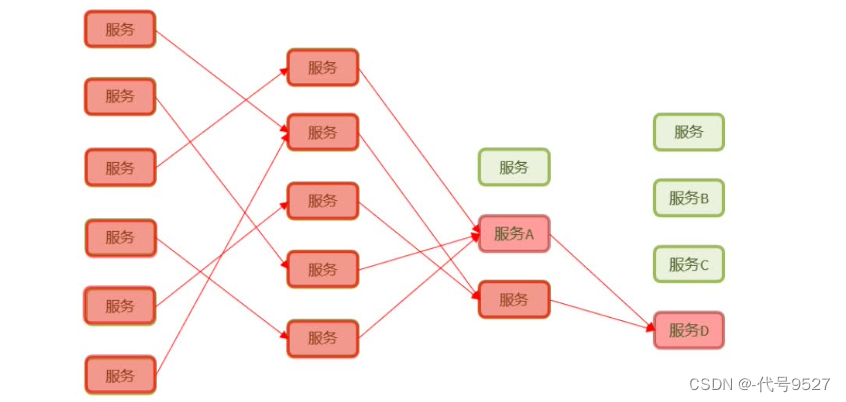
如上,D被A远程调用,后面A被B调用,此时D实例宕机,A远程请求一直得不到响应,积累久了,A的可用连接数就没了(一个服务的最大连接数是有限的,而调用失败的那些连接不会立马释放)。如此A也不可用,以此类推,整个系统都挂了。解决方案:
- 熔断降级
- 限流(只能起个预防作用)
4.2 服务降级
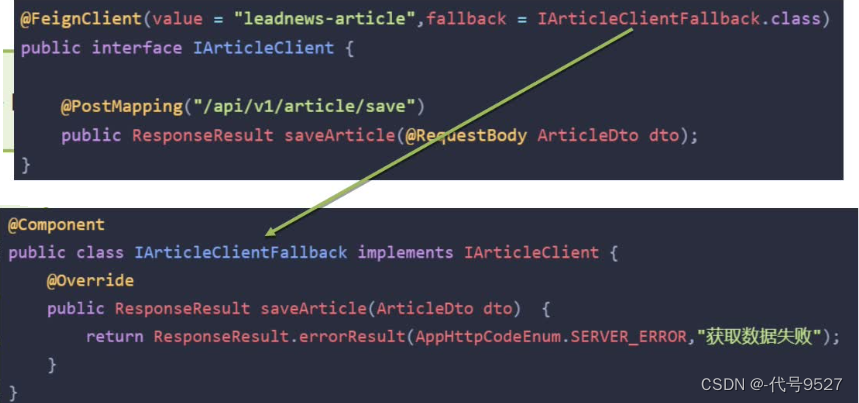
服务D远程调用不通时,走降级逻辑。
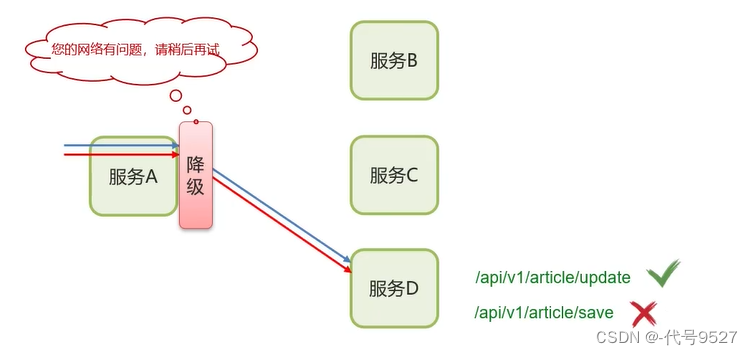
Feign时,用fallback指定降级逻辑:
4.3 服务熔断
只有降级也不行,降级只是返回了另一个提前定义好的失败调用结果,后面请求进来,还是先会去远程请求,直到超时失败才走降级代码,因此,需要加上熔断。即:远程调用失败次数到达一定阈值,请求过来,直接走降级逻辑,不再去先远程调用等到超时。
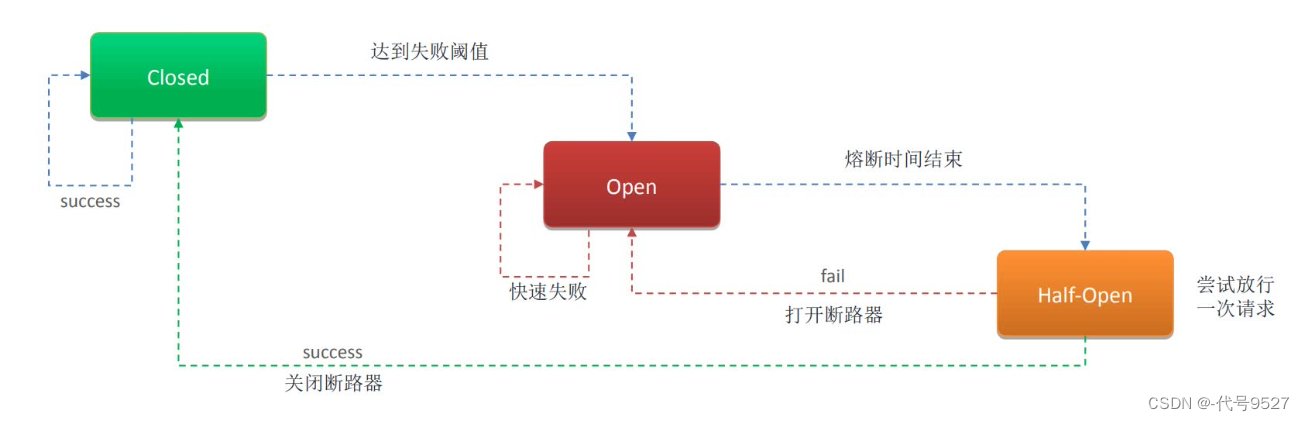
Hystrix 熔断机制,用于监控微服务调用情况 。默认关闭,开启熔断可在引导类上添加注解@EnableCircuitBreaker,如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制,断路器打开,请求过来,不管远程调用通不通,直接走降级代码。之后每隔 5 秒重新尝试请求微服务(断路器半开,放行一个请求),如果微服务还不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求流程。
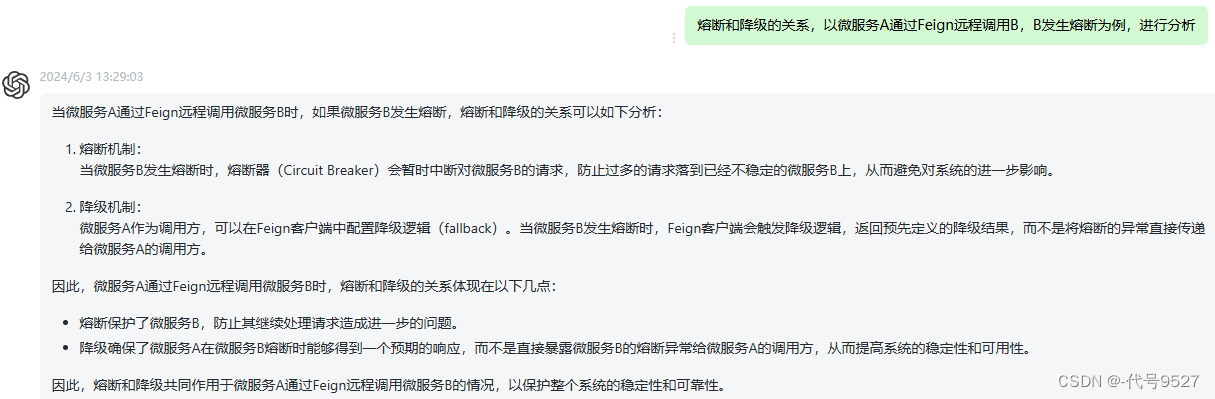
最后,注意,降级是针对远程调用某一个接口的,而熔断发生时,是全部接口。比如A远程调用B,请求B失败率到达阈值,触发熔断,则不管你直接请求B还是远程调用请求B,都是立即失败
5、微服务监控
常见技术选型:
- SpringBoot-Admin
- Prometheus + Grafana(偏监控,搭建复杂)
- Zipkin(偏链路追踪,但有代码侵入)
- Skywalking(偏链路追踪)
以SkyWalking为例:
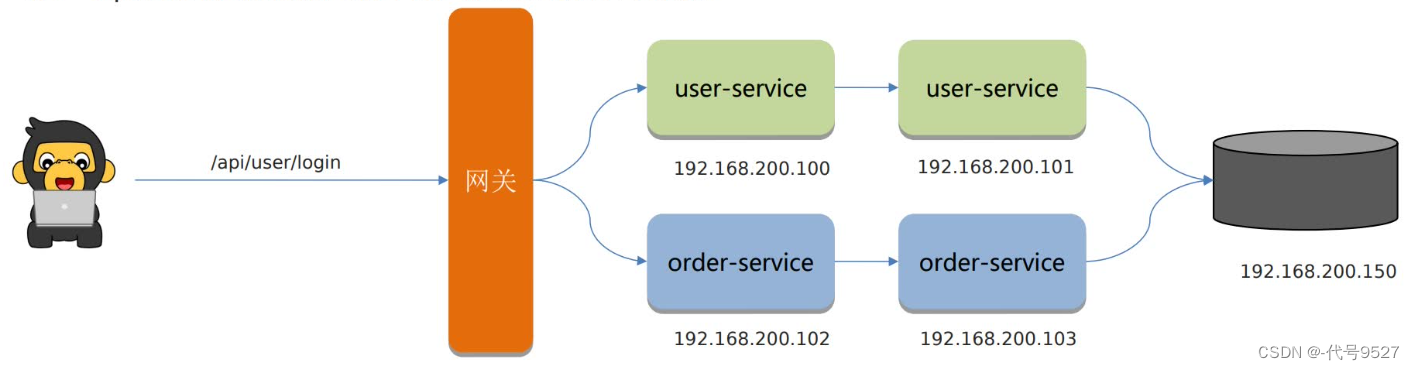
相关概念:
- 服务(Service):系统中的一个个微服务
- 端点(Endpoint):开发的一个个功能接口
- 实例(Instance):服务所在的物理机服务器
搭建完成后,根据仪表盘中的慢接口,去问题定位,拓扑图中显示了服务之间的调用关系
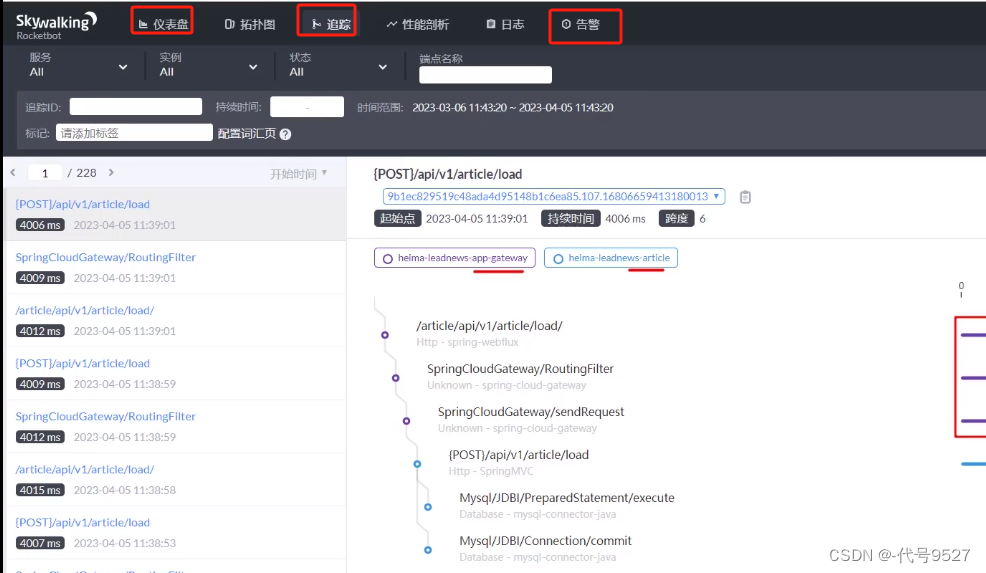
更好的是,sky walking可以设置告警规则,项目上线后,可给负责人发短信或者邮件,以便第一时间修复问题。
6、面试



