一、基础知识
1、backbone
backbone是核心组成部分,主要负责提取图像特征。具体来说,backbone通过一系列的卷积层和池化层对输入图像进行处理,逐渐降低特征图的尺寸同时增加通道数,从而保留和提取图像中重要的特征。这些提取出的特征图会进一步传递给后续的特征金字塔网络(neck)和检测头(head)进行处理。
在YOLOv5中,常见的Backbone网络包括CSPDarknet53或ResNet等,这些网络都是相对轻量级的,能够在保证较高检测精度的同时,尽可能地减少计算量和内存占用。其结构主要包括Conv模块、C3模块和SPPF模块,其中Conv模块由卷积层、BN层和激活函数组成,C3模块负责将前面的特征图进行自适应聚合,而SPPF模块则通过全局特征与局部特征的加权融合,获取更全面的空间信息。
2、head
head是负责进行物体检测和边界框预测的关键部分。它的主要工作是对backbone和neck部分提取的特征进行进一步的处理和解析,以生成最终的检测结果。
具体来说,head部分会对特征图进行解码,生成一系列预测框,并对这些预测框进行坐标和类别的预测。它还会对这些预测框进行非极大值抑制(NMS)等后处理操作,以消除冗余的检测结果,并输出最终的物体位置和类别信息。
与backbone相比,head更侧重于对特征的解析和预测,而backbone则更侧重于对原始图像的特征提取。两者在YOLOv5算法中共同协作,以实现高效、准确的目标检测。
二、模型结构yaml文件逐行分析
关于模型结构的文件在项目的"models"目录下,如common.py、yolo.py、yolov5.yaml文件,主要是yaml文件。

之前我们使用的是yolov5s.yaml文件,打开分以下3部分:
1、Parameters
nc为类别,分类类别默认80种,对应模型自带的coco文件。
depth_multiple和width_multiple分别是深度和宽度。backbone和head里面的number和arg参数与这个有关,具体见下面。
anchors为3个特征图,每个特征图里有3组锚框(yolo算法的基础知识)。
python
# Parameters
nc: 80 # number of classes,分类类别默认80种,对应自带的coco文件
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/322、backbone
第一个重点(对应第1-10层),注释from, number, module, args:
from说明从哪里来,如-1表示从上一层来;
number说明当前模块要重复几次,一般为1,C3模块不是1,这个参数需要乘以depth_multiple参数然后与1比较取最大值;
module说明用的哪个模块,如Conv卷积模块、C3模块;
args说明实例化这个模块需要传进的参数,如输出通道数,卷积核大小,步长等参数。如Conv0的输出通道数为64,输出通道数需要乘以width_multiple参数然后与1比较取最大值,比如这里64x0.5=32>1说明经过Conv0后实际的输出通道数是32(其实与下面Tensorboard可视化方式里展示的结果对应)
python
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]各模块一定方式联结就构成了网络结构,只看代码可视化效果不好,可借助"Tensorboard"可视化,pycharm终端输入:
python
tensorboard --logdir runs回车会出现一个链接,ctrl+左键点击可跳转TensorBoard网页:
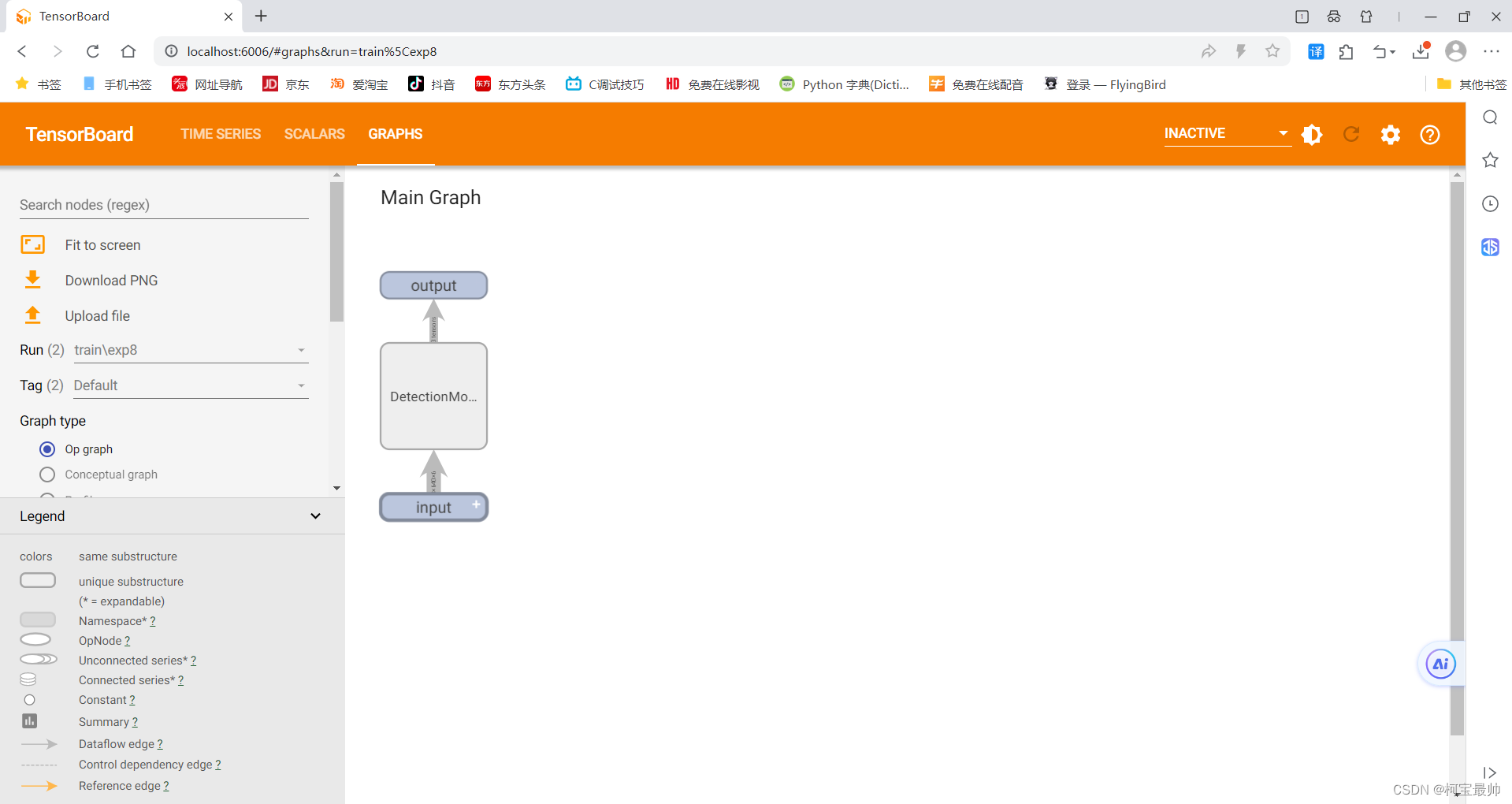
双击中间的DetectModel,可查看详细细节:
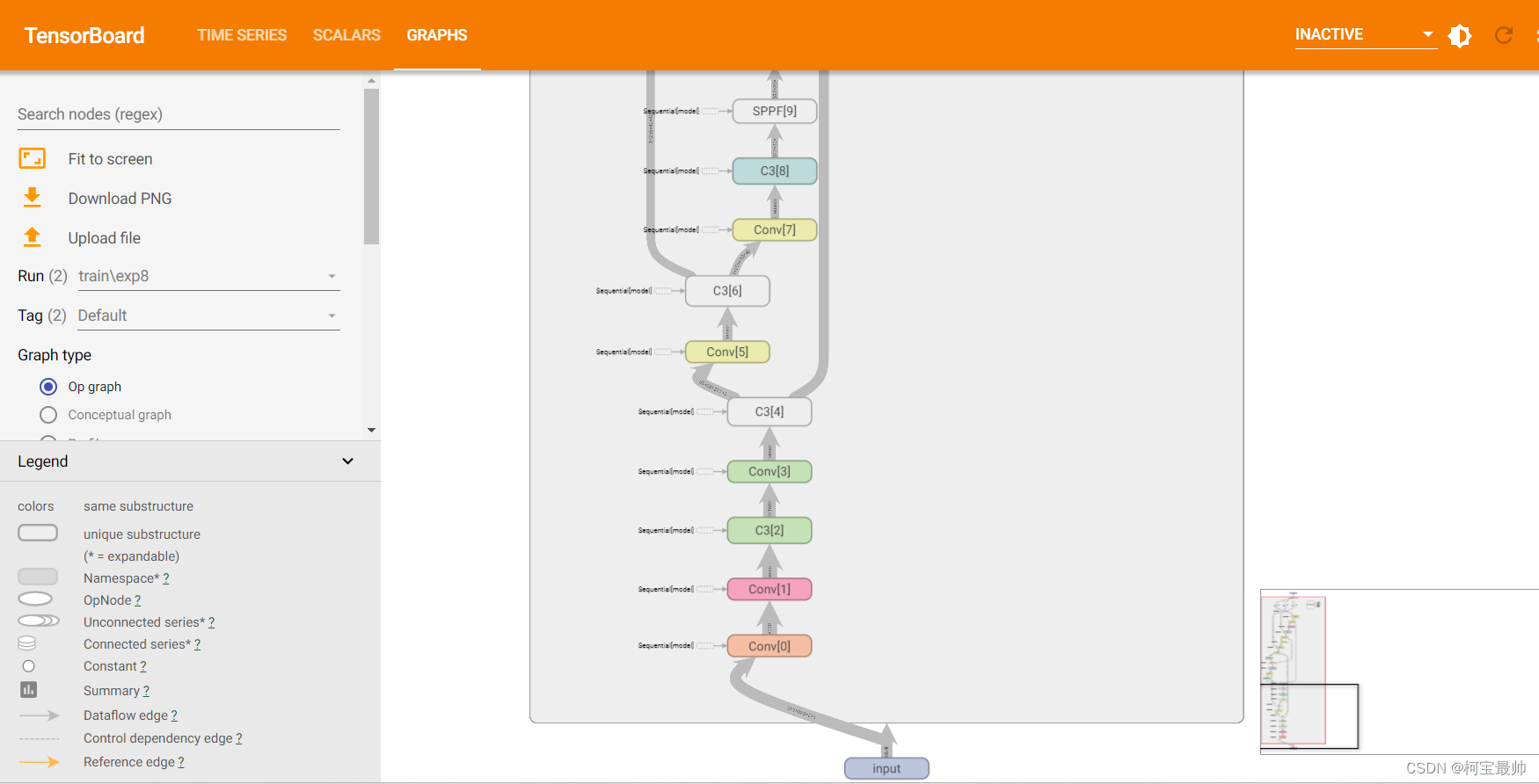
比如点击第一个卷积层Conv0,右侧会出现经过该层后数据的维度等产生了哪些变化:
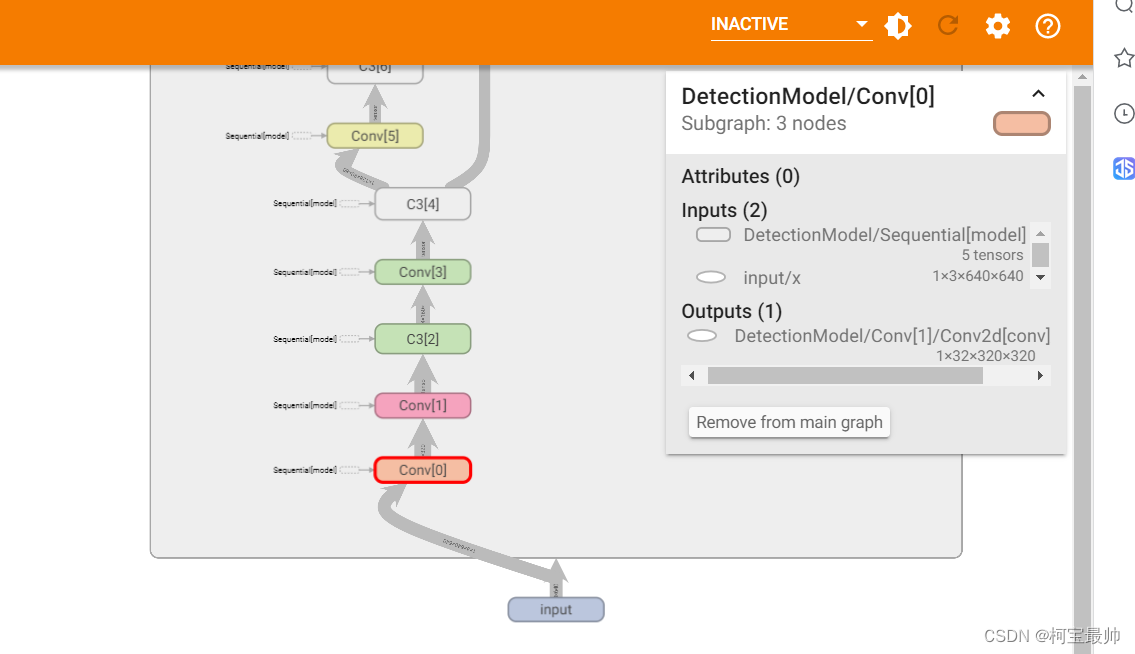
可见输入通道为3,与下面深入介绍的train.py文件的ch默认参数对应,图像尺寸是640x640,经过第一个卷积层Conv1后输出通道是32,图像尺寸从640x640变为了320x320,尺寸变化与代码的注释# 0-P1/2(除以2)是对应的,而注释中的0代表该层(模块)的编号。往后看可以发现每经过一个Conv卷积层,就相当于经过了一次下采样。
3、head
第二个重点(对应第11-25层),分析方法与上面的backbone类似也是对照上面的图,Conv卷积层;Upsample上采样;Contact意思为做拼接,所以第一个from参数为一个列表,即将上一层和第6层拼接起来(需保证两者维度相同),可对照上面的可视化图...后面以此类推。
注释中需要注意的点,第18、21、24层(对应标号17、20、23)分别做了8倍、16倍、32倍下采样,分别用来检测较小、中等、较大尺寸的目标。
python
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]后续修改模型也是在这里面修改!
三、训练时各文件之间的关系
上面简单介绍了定义模型结构的yaml文件,那么具体底层运行时怎么生成网络结构的呢?
打开train.py 文件,找到定义的train函数:
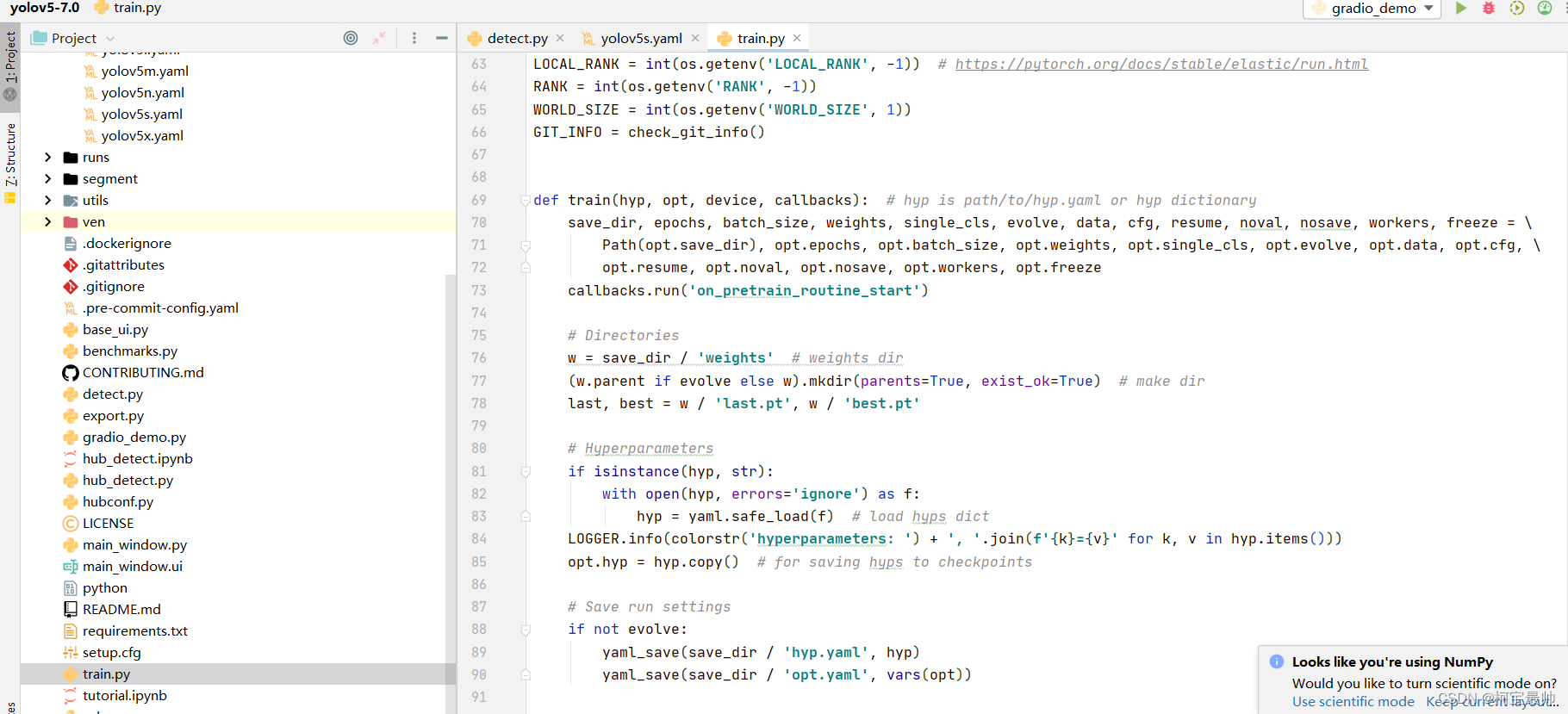
大概在第130行左右 有一行,里面的cfg参数就是传入上面定义模型结构的yaml文件,ch为输入输出通道数,nc是上面在yaml文件的类别,这里可以传参,传后就按传入的新的类别,anchors为上面介绍的锚框:
python
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create若想查看Model类的定义,按住ctrl,鼠标左击Model类 ,跳转到yolo.py 文件,该文件设定了网络结构的传参细节:
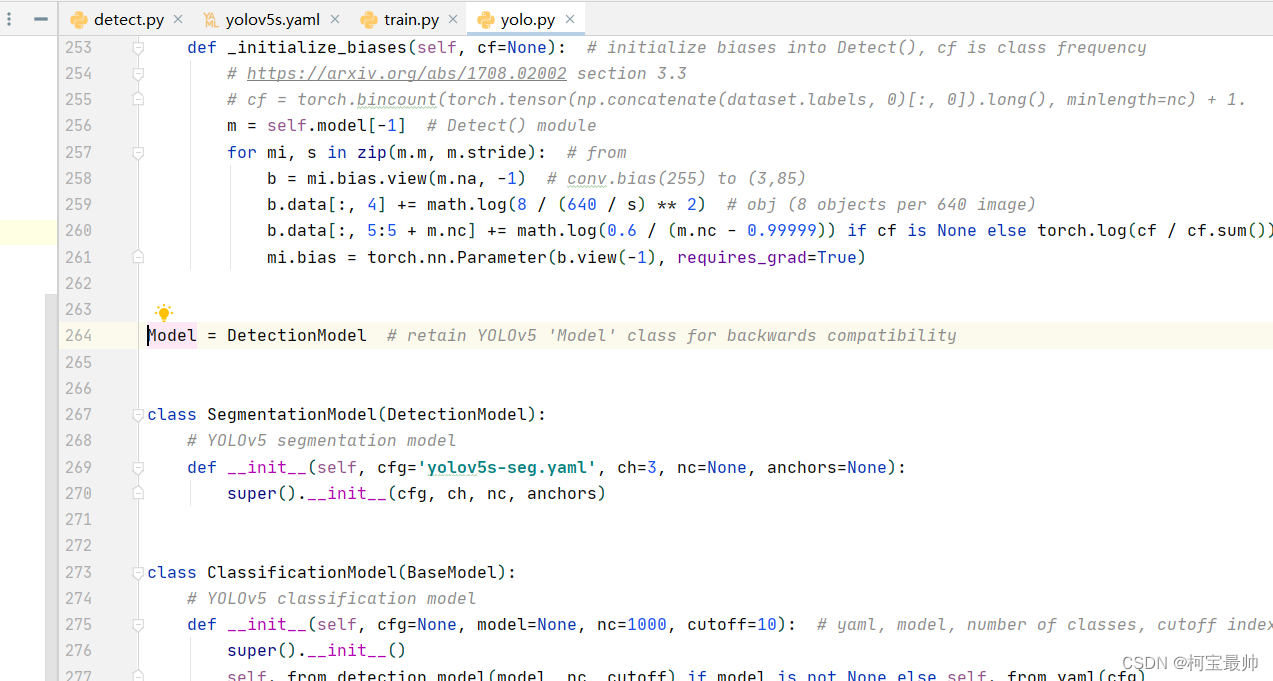
上图可以发现Model=DetectionModel ,再跳转到DetectionModel类,可发现cfg参数默认就是yolov5s.yaml,说明当train.py中不指定模型结构参数cgf时,默认使用这个.yaml文件。
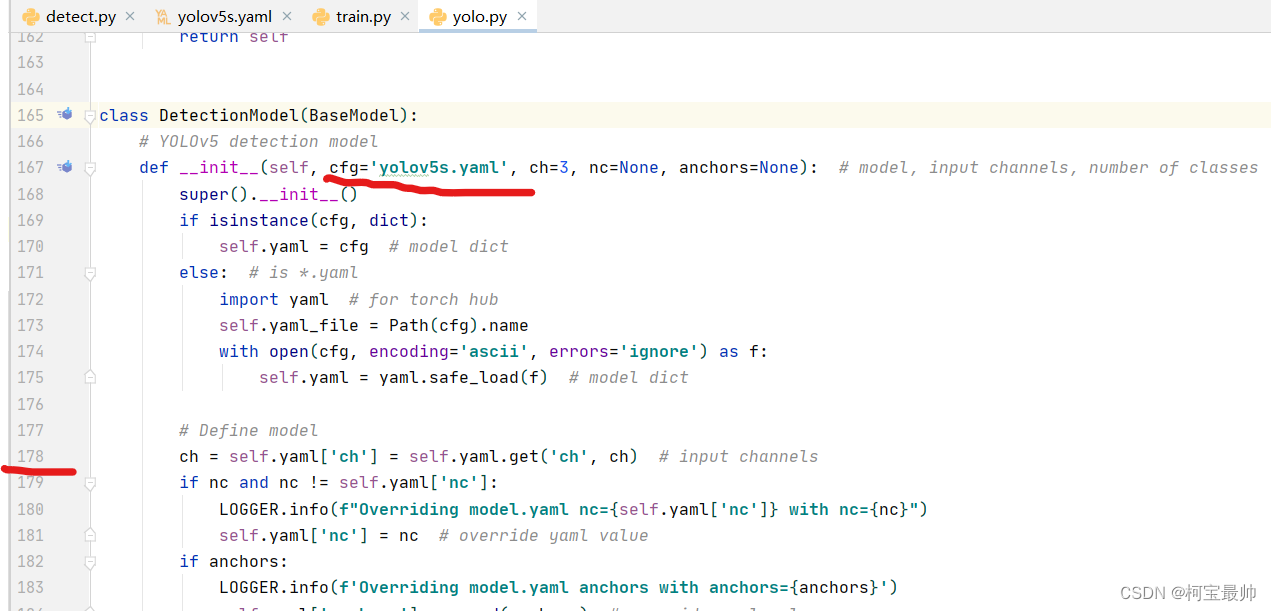
从DetectionModel类第178行-185行定义模型:
- 判断nc类别与默认是否相同,不相同传入设置的nc类别
- anchors锚框。。。
- parse_model函数传入.yaml网络结构配置文件,传入输入通道数ch

跳转到parse_model函数的定义处,d参数就是传配置文件.yaml(对照上图),函数里读取配置文件d的一些参数,然后对锚框的参数进行一些计算;从第210行开始就开始遍历yaml文件的backbone和head网络结构;第316行的n(depth gain)就是Parameters里面讲的depth_multiple深度参数,做一些缩放;
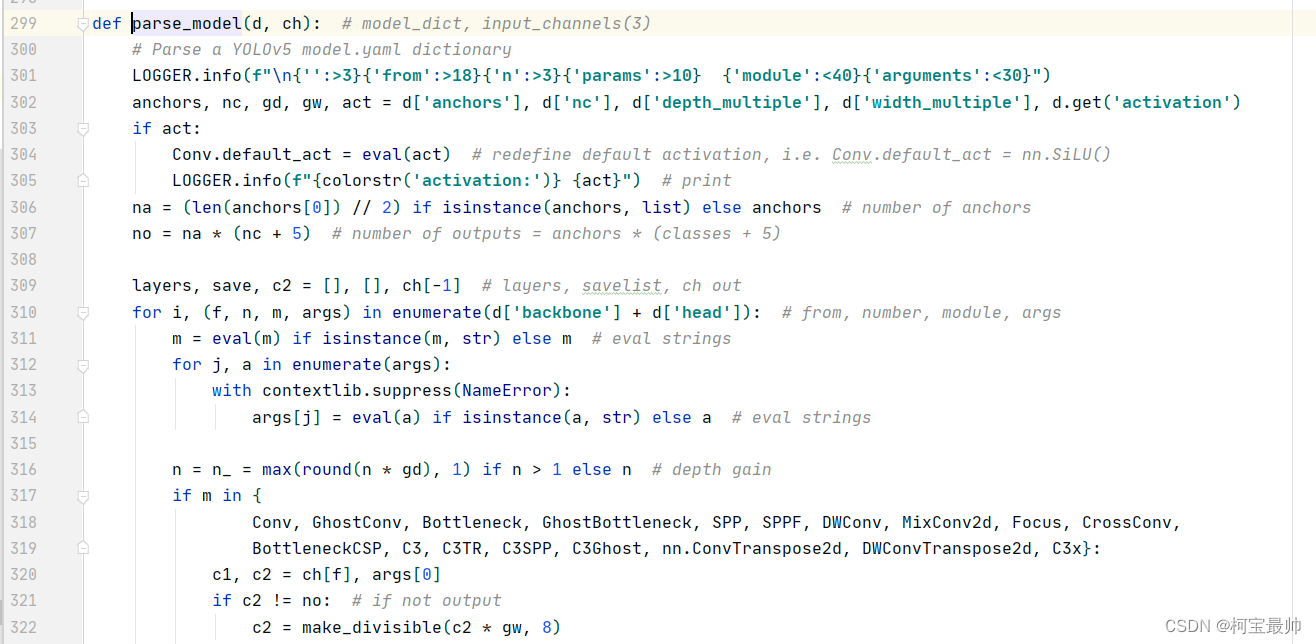
第317行开始对网络结构传入一些参数,如Conv的原始定义可跳转到common.py 文件进行分析,该文件定义了每个模块实现的详情。
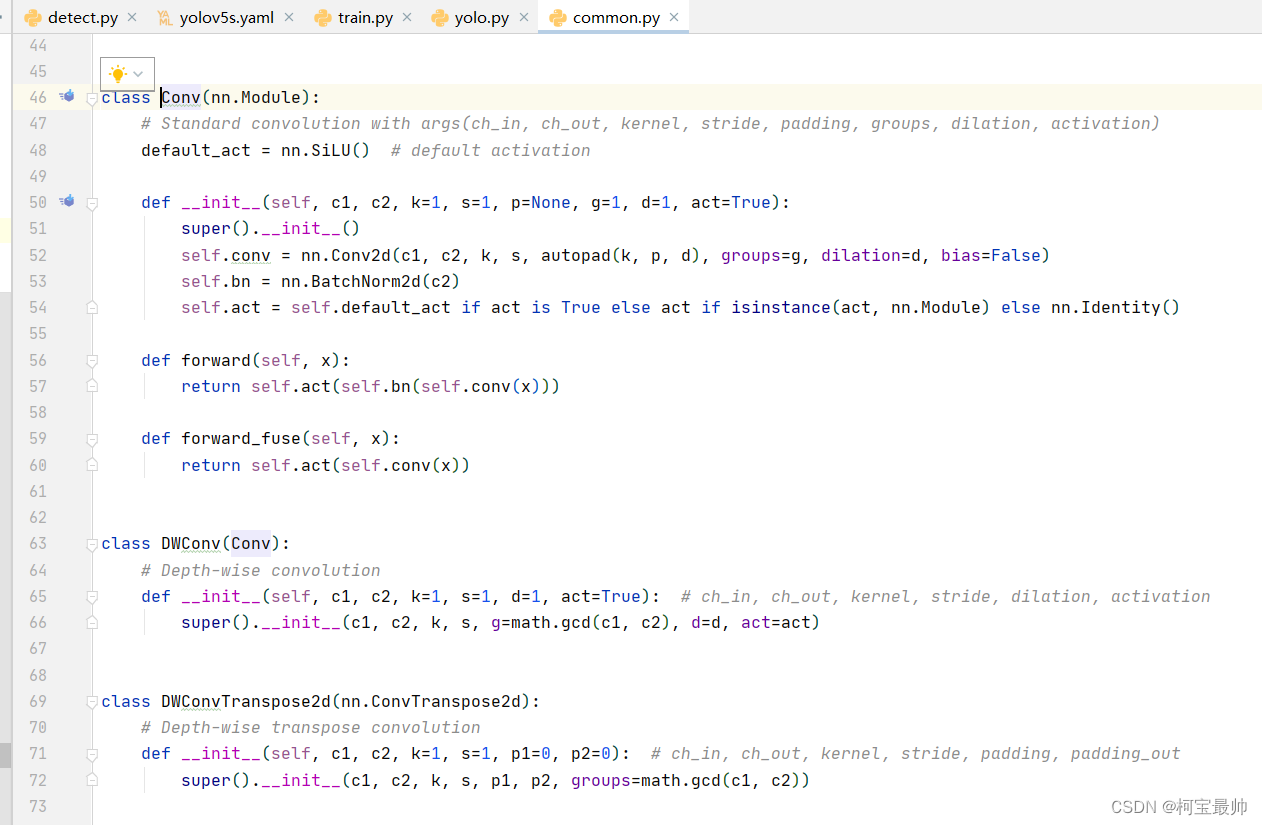
总结:网络的具体结构在common.py、yolo.py、 yolov5s.yaml这三个文件,修改网络结构是从这三个文件入手!