目录
- [1. 作者介绍](#1. 作者介绍)
- [2. VGG16介绍](#2. VGG16介绍)
-
- [2.1 背景介绍](#2.1 背景介绍)
- [2.2 VGG16 结构](#2.2 VGG16 结构)
- [3. Cat VS Dog数据集介绍](#3. Cat VS Dog数据集介绍)
- [4. 实验过程](#4. 实验过程)
-
- [4.1 数据集处理](#4.1 数据集处理)
- [4.2 训练部分设置](#4.2 训练部分设置)
- [4.3 训练结果](#4.3 训练结果)
- [4.4 问题分析](#4.4 问题分析)
- [4.5 单张图片测试](#4.5 单张图片测试)
- 5.完整训练代码与权重
- 参考文献
1. 作者介绍
孙思伟,男,西安工程大学电子信息学院,2023级研究生
研究方向:深度强化学习与人工智能
电子邮件:sunsiwei0109@163.com
2. VGG16介绍
2.1 背景介绍
VGG16 是由牛津大学的K. Simonyan 和A. Zisserman 在论文"Very Deep Convolutional Networks for Large-Scale Image Recognition"中提出的卷积神经网络模型。该模型在 ImageNet 中实现了 92.7% 的前 5 名测试准确率,ImageNet 是一个包含 1000 个类别的 1400 多万张图像的数据集。它是提交给ILSVRC-2014的著名模型之一。它通过将大型内核大小的滤波器(第一层和第二卷积层分别为 11 个和 5 个)替换为多个 3×3 个内核大小的滤波器来改进 AlexNet。
论文地址: Very Deep Convolutional Networks for Large-Scale Image Recognition
2.2 VGG16 结构
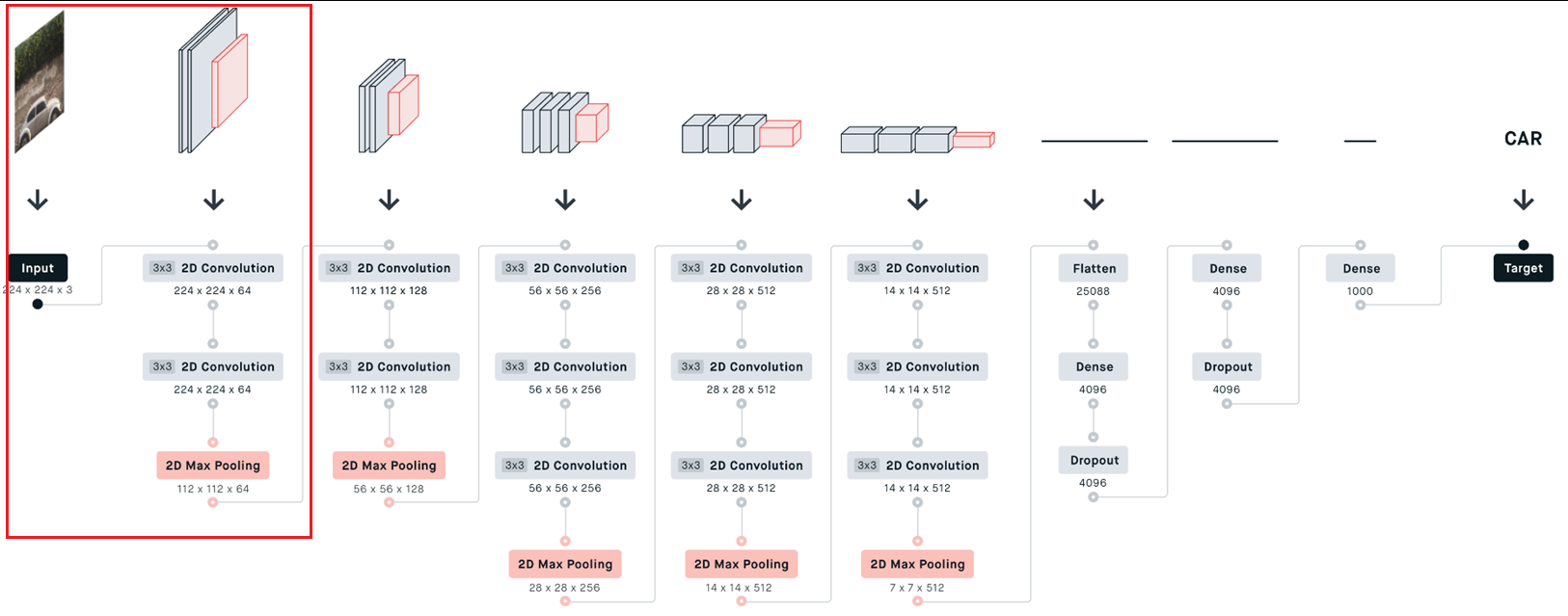
VGG16 是一个流行的卷积神经网络(CNN)架构,主要用于图像识别和处理。它由多个卷积层、激活层、池化层和全连接层组成,图1为VGG网络结构图,具体如下:

- 输入层:接受大小为 224 x 224 x 3 的图像,这意味着每个图像有 224 x 224 像素,每个像素有 3 个颜色通道(红、绿、蓝)。
- 卷积层和ReLU激活层 :
- 前两个卷积层各有 64 个过滤器,大小均为 3x3,步长为 1,通过ReLU激活函数进行非线性处理。
- 接下来是两个卷积层,每层 128 个过滤器,过滤器大小和步长不变,同样使用ReLU激活。
- 然后是三个卷积层,每层有 256 个过滤器。
- 最后是三组卷积层,每组包含三个卷积层,每层有 512 个过滤器。
- 最大池化层(Max Pooling) :
- 每几个卷积层后会跟一个最大池化层,用于降低空间尺寸(特征图的高度和宽度),池化窗口大小通常为 2x2,步长为 2。
- 全连接层 :
- 网络末端有三个全连接层。前两个全连接层各有 4096 个神经元,并使用ReLU激活函数。
- 最后一个全连接层有 1000 个输出单元,对应于 1000 个类别的分类任务。
- Softmax层 :
- 最终输出通过softmax层,该层将网络输出转换为概率分布,用于多类别分类。
VGG16 的特点是使用了很多堆叠的小卷积核(3x3),这样设计的好处是可以在保持感受野的情况下减少参数数量,提高网络的深度以学习更复杂的特征。整个网络架构简单但效果显著,适用于各种图像识别任务。
3. Cat VS Dog数据集介绍
猫狗大战(Cats vs. Dogs)数据集是一个用于二分类的图像识别任务的公开数据集,其目的是让机器学习模型能够区分图像是猫还是狗。
数据集最初由Kaggle在2013年为一个竞赛提供,现在已经成为计算机视觉和深度学习领域中一个非常流行的入门级数据集。图2是数据集内容。
数据集下载地址:Cats-vs-Dogs
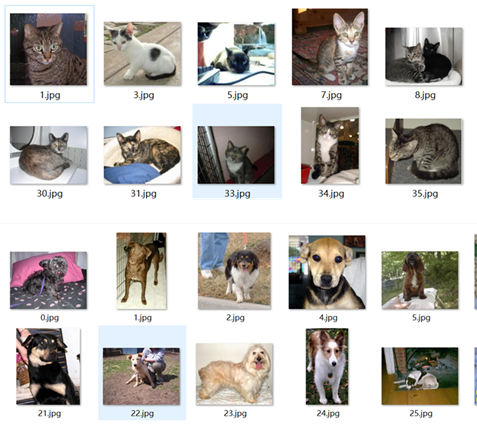
数据集特点
-
Number of data sets:
- 数据集包含25,000张彩色图像,其中猫和狗各占一半,即12,500张猫的图片和12,500张狗的图片。
-
Data set size:
- 图片的大小不一,格式为.JPG。这为处理图像时的预处理步骤(如缩放、裁剪)提供了实际的挑战。
-
Data set label:
- 每张图片都明确标记为"猫"或"狗",这简化了监督学习模型的训练过程。
应用方向
- 训练深度学习模型:这个数据集广泛用于训练各种深度学习模型,如卷积神经网络(CNN),来识别和分类图像内容。
- 模型评估和比较:数据集也常用于评估不同模型和算法的性能,以及比较各种优化技术的效果。
挑战
- 图像多样性:由于数据集中的图像在姿势、大小、背景和光照条件等方面都有很大的不同,这给模型的泛化能力带来了挑战。
- 不均匀的图像质量:部分图像可能质量较低,或者包含干扰的背景元素,这需要更复杂的数据预处理或更强大的模型来克服。
4. 实验过程
4.1 数据集处理
- 安装并导入需要的模块:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
import os
import shutil
import numpy as np
from concurrent.futures import ThreadPoolExecutor
import matplotlib.pyplot as plt- 2 数据集划分
我这里下载的数据集路径格式为:
Dog_Cat
├─Dog
└─Cat
需要划分并将数据集设置为:
Dog_Cat
├─train
│ ├─cat
│ └─dog
└─valid
├─cat
└─dog
python
#数据集划分
def create_train_valid_dirs(base_dir):
#创建训练集和验证集的目录结构
classes = ['dog', 'cat']
for cls in classes:
os.makedirs(os.path.join(base_dir, 'train', cls), exist_ok=True)
os.makedirs(os.path.join(base_dir, 'valid', cls), exist_ok=True)
def copy_files(src_files, target_dir):
#将文件列表复制到目标目录
for src in src_files:
shutil.copy(src, target_dir)
def split_data(source_dir, train_dir, valid_dir, valid_ratio=0.2):
#划分数据到训练集和验证集
classes = ['dog', 'cat']
with ThreadPoolExecutor() as executor:
for cls in classes:
class_dir = os.path.join(source_dir, cls)
files = [entry.path for entry in os.scandir(class_dir) if entry.is_file()]
np.random.shuffle(files)
split_point = int(len(files) * (1 - valid_ratio))
train_files = files[:split_point]
valid_files = files[split_point:]
# 并行复制文件到训练和验证目录
executor.submit(copy_files, train_files, os.path.join(train_dir, cls))
executor.submit(copy_files, valid_files, os.path.join(valid_dir, cls))
# 主目录
base_dir = 'D:\\Desktop\\Datasets\\Dog_Cat'
source_dir = base_dir
train_dir = os.path.join(base_dir, 'train')
valid_dir = os.path.join(base_dir, 'valid')
# 创建目录结构并划分数据
create_train_valid_dirs(base_dir)
split_data(source_dir, train_dir, valid_dir)4.2 训练部分设置
- 检查设备是否有CUDA以及导入数据集
python
# 检查CUDA是否可用,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device) # 打印出使用的设备,GPU还是CPU
# 定义训练数据的变换流程
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机大小、比例裁剪图像到224x224
transforms.RandomHorizontalFlip(), # 随机水平翻转图像
transforms.ToTensor(), # 将图片转换为Tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化处理,使用ImageNet的均值和标准差
])
# 定义验证数据的变换流程
valid_transform = transforms.Compose([
transforms.Resize(256), # 将图片大小调整为256x256
transforms.CenterCrop(224), # 中心裁剪到224x224
transforms.ToTensor(), # 将图片转换为Tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 与训练集相同的标准化处理
])
# 加载训练数据集,并应用预定义的变换
train_dataset = datasets.ImageFolder(root=r'D:\Desktop\Datasets\Dog_Cat\train', transform=train_transform)
# 加载验证数据集,并应用预定义的变换
valid_dataset = datasets.ImageFolder(root=r'D:\Desktop\Datasets\Dog_Cat\valid', transform=valid_transform)
# 定义训练数据加载器,设置批处理大小为32,并启用随机洗牌
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 定义验证数据加载器,设置批处理大小为32,不进行洗牌
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False)- 网络结构
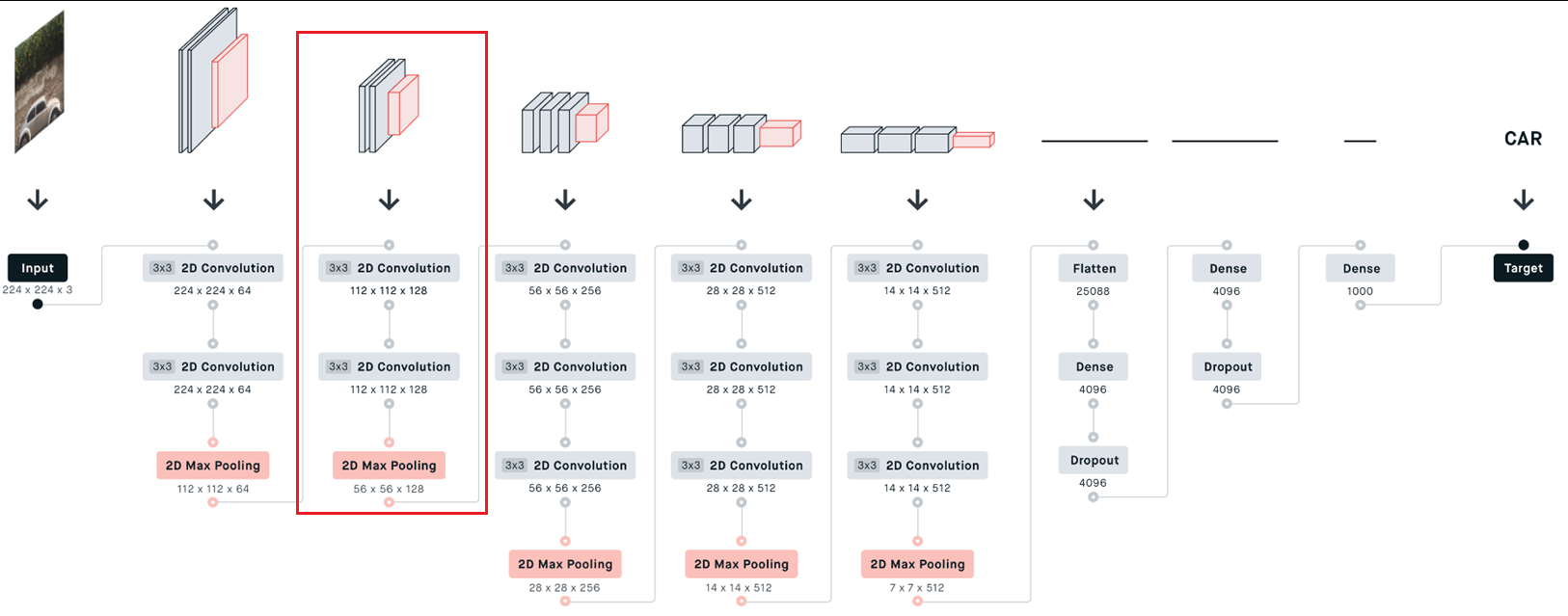
第一部分卷积:
python
# 定义VGG16模型结构
class Vgg16_net(nn.Module):
def __init__(self,num_classes= 2):
super(Vgg16_net, self).__init__()
# 第一层卷积层
self.layer1 = nn.Sequential(
# 输入3通道图像,输出64通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
# 对64通道特征图进行Batch Normalization
nn.BatchNorm2d(64),
# 对64通道特征图进行ReLU激活函数
nn.ReLU(inplace=True),
# 输入64通道特征图,输出64通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
# 对64通道特征图进行Batch Normalization
nn.BatchNorm2d(64),
# 对64通道特征图进行ReLU激活函数
nn.ReLU(inplace=True),
# 进行2x2的最大池化操作,步长为2
nn.MaxPool2d(kernel_size=2, stride=2)
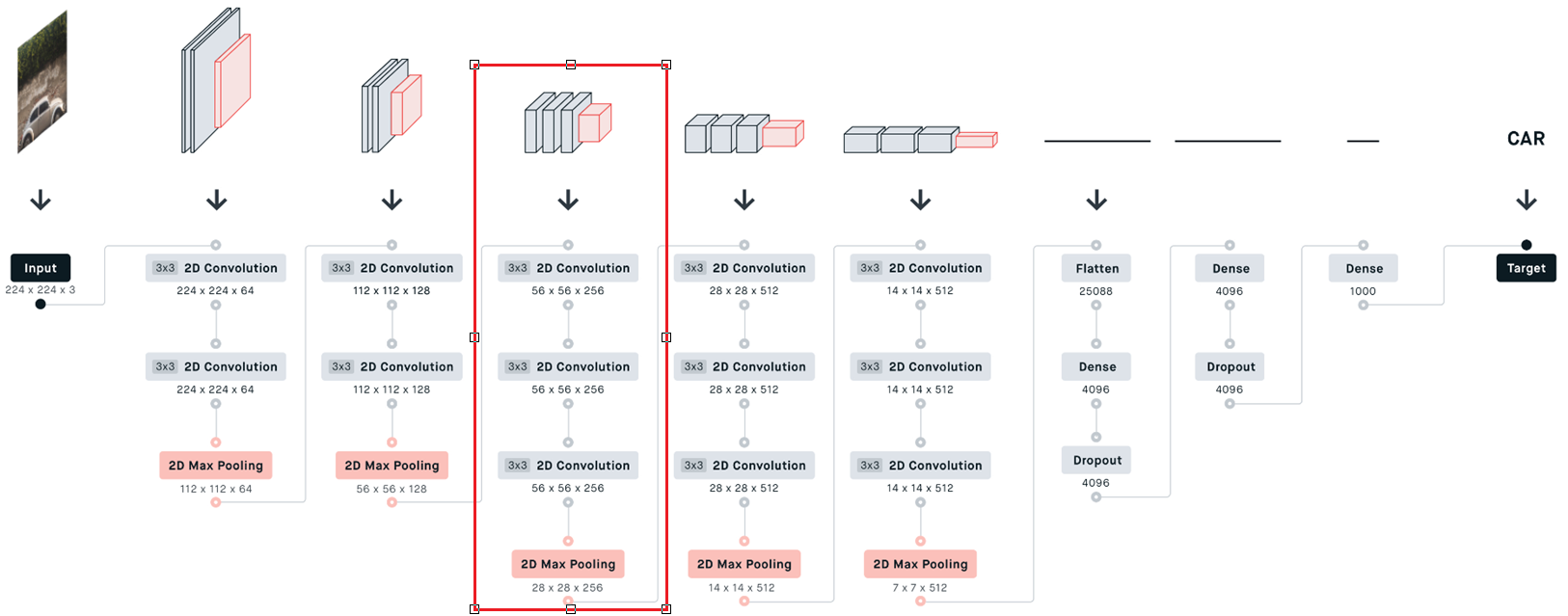
)第二部分卷积
python
# 第二层卷积层
self.layer2 = nn.Sequential(
# 输入64通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
# 对128通道特征图进行Batch Normalization
nn.BatchNorm2d(128),
# 对128通道特征图进行ReLU激活函数
nn.ReLU(inplace=True),
# 输入128通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
# 对128通道特征图进行Batch Normalization
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# 进行2x2的最大池化操作,步长为2
nn.MaxPool2d(2, 2)
)第三部分卷积
python
# 第三层卷积层
self.layer3 = nn.Sequential(
# 输入为128通道,输出为256通道,卷积核大小为33,步长为1,填充大小为1
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
# 批归一化
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)第四部分卷积
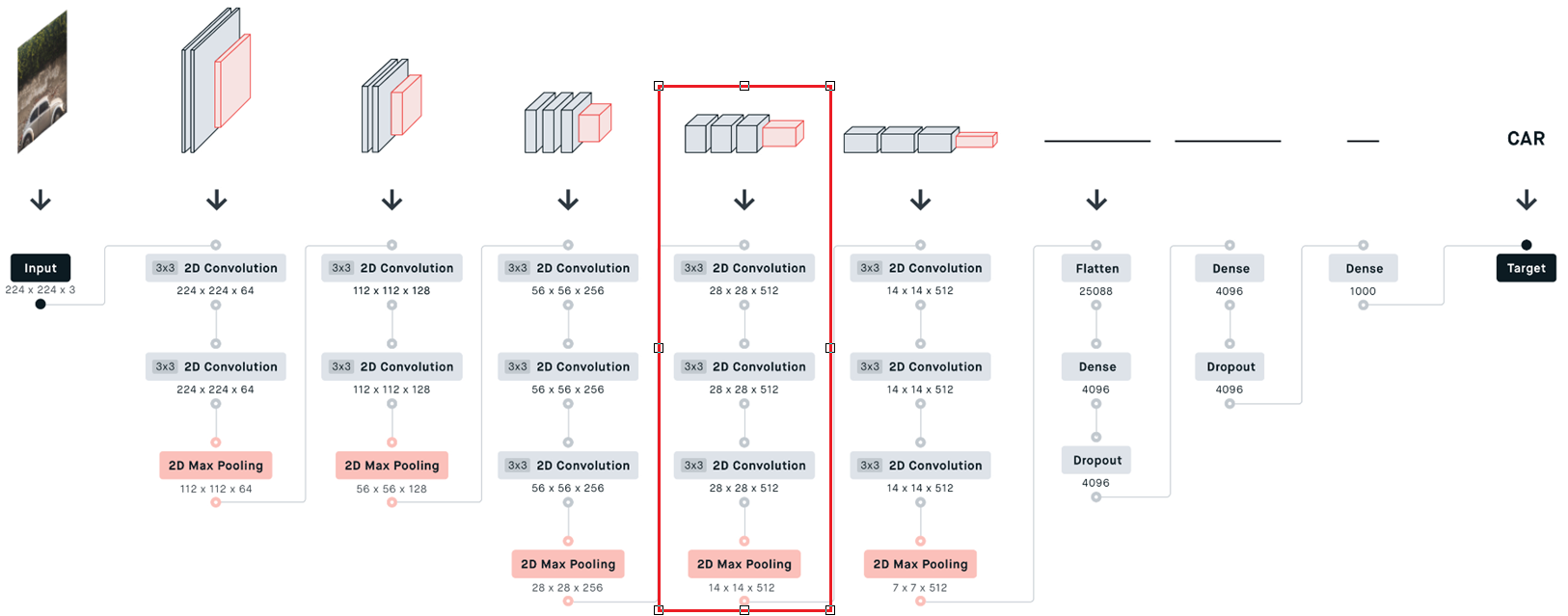
python
self.layer4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)第五部分卷积
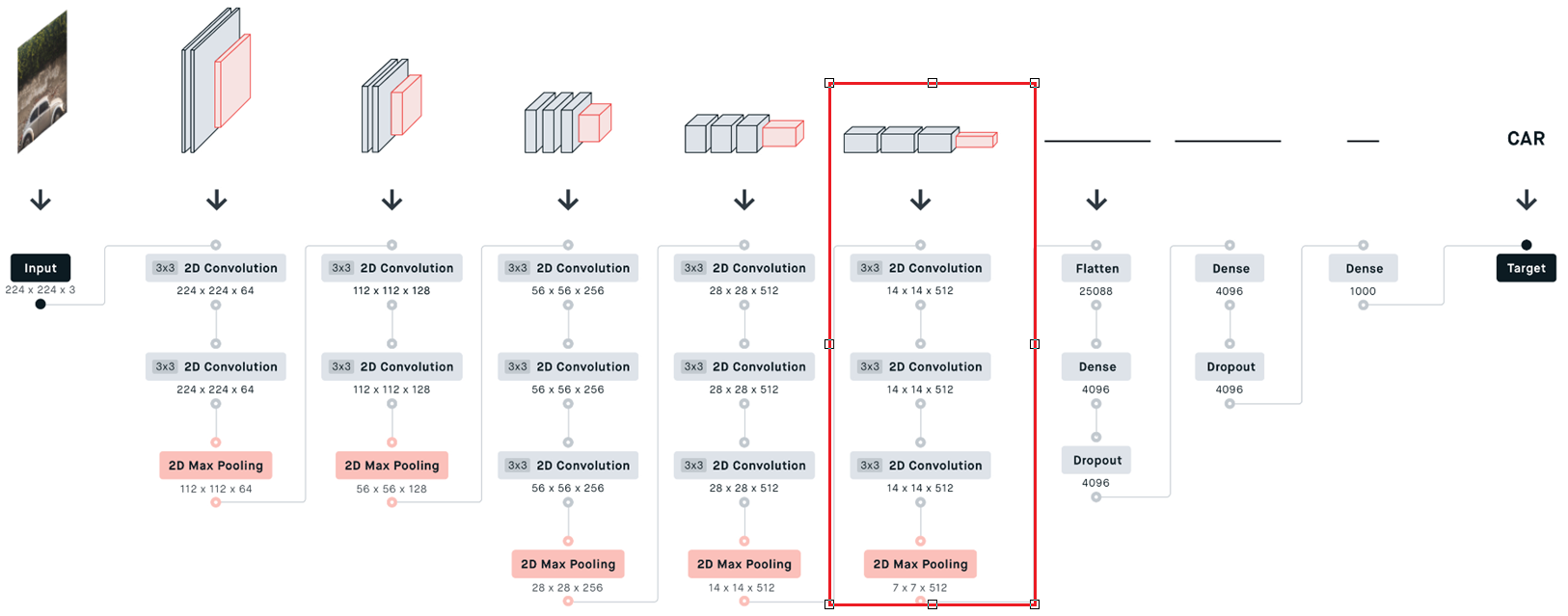
python
self.layer5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)第六部分 全连接层
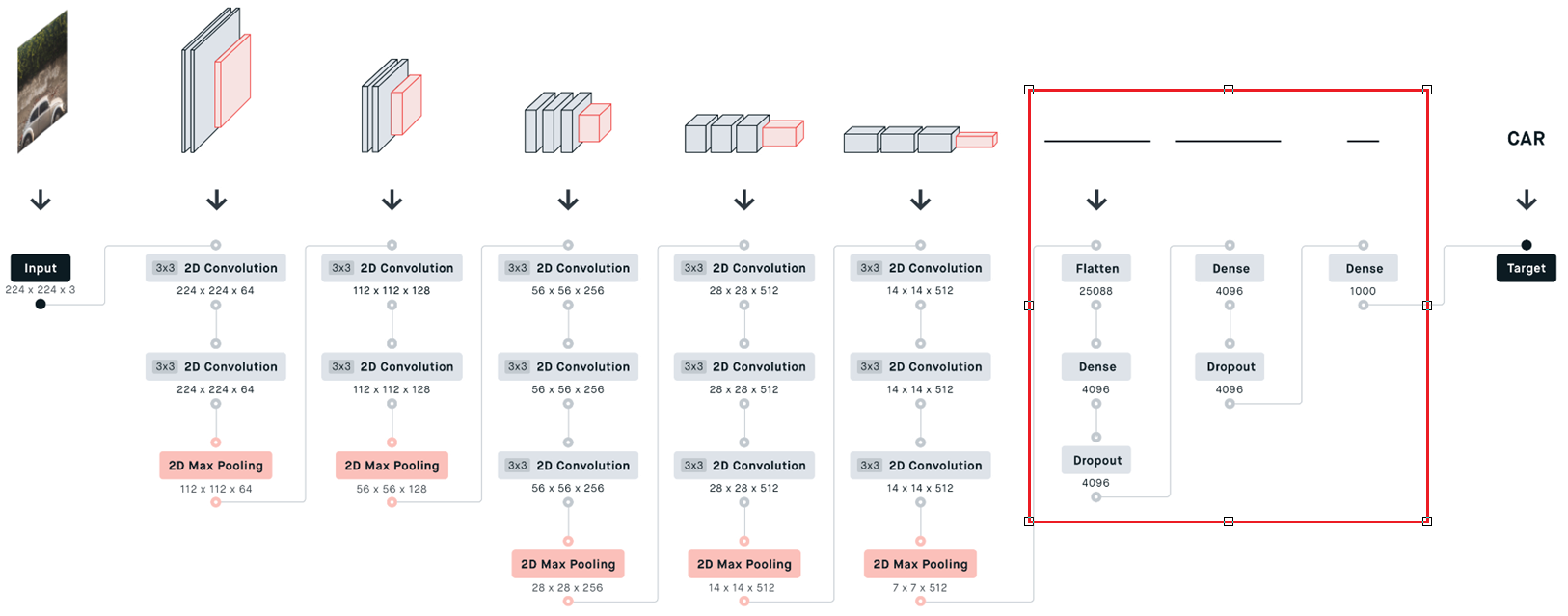
python
self.fc = nn.Sequential(
nn.Linear(512*7*7, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256, num_classes)
)forward定义
python
self.conv = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5
)
def forward(self, x):
x = self.conv(x)
# 对张量的拉平(flatten)操作,即将卷积层输出的张量转化为二维,全连接的输入尺寸为512
x = x.view(x.size(0), -1)
x = self.fc(x)
return x- 调用构建的网络,定义损失函数与优化器
python
model = Vgg16_net().to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)- 训练部分,在服务器上训练,最后将图保存,需要直接显示就取消注释最后一行代码
python
def train_model(num_epochs,initial_weights = None):
if initial_weights is not None:
model.load_state_dict(torch.load(initial_weights))
print(f"Loaded weights from {initial_weights}")
train_losses = []
validation_accuracies = []
for epoch in range(num_epochs):
model.train()
train_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
epoch_loss = train_loss / len(train_loader)
train_losses.append(epoch_loss)
print(f'Epoch {epoch+1}, Train Loss: {epoch_loss}')
torch.save(model.state_dict(), f'model_epoch_{epoch+1}.pth')
# 验证模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in valid_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
validation_accuracies.append(accuracy)
print(f'Validation Accuracy: {accuracy}%')
# 绘图
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, label='Train Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), validation_accuracies, label='Validation Accuracy', color='r')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
plt.savefig('training_validation_metrics.png')
# plt.show() # 这行被注释掉,以避免在无GUI环境中尝试显示图像
# 开始训练
train_model(100)4.3 训练结果
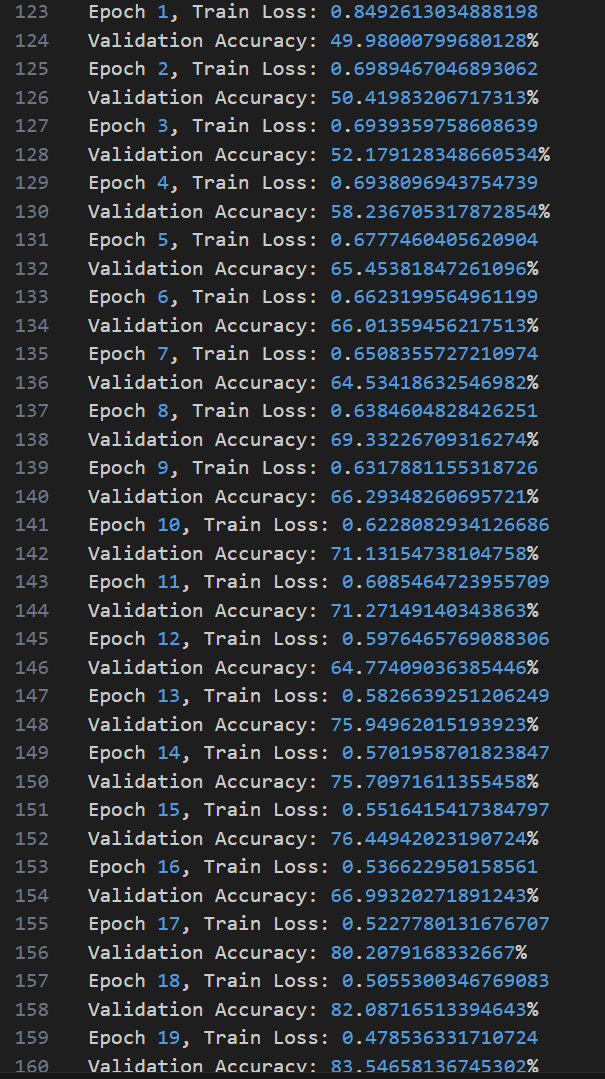
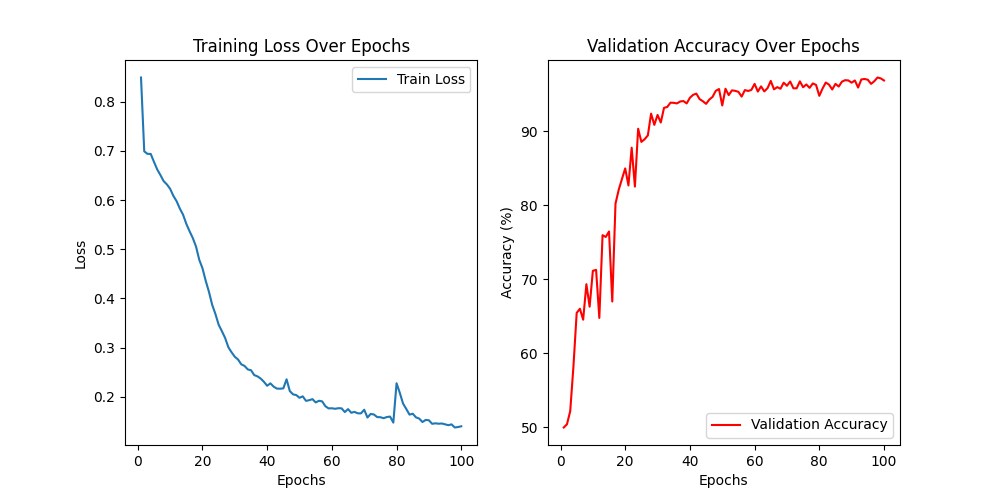 结果展示了模型在100个epochs(训练周期)中的训练损失(Training Loss)和验证准确率(Validation Accuracy)的变化情况。
结果展示了模型在100个epochs(训练周期)中的训练损失(Training Loss)和验证准确率(Validation Accuracy)的变化情况。
左图:Training Loss Over Epochs
横轴(X轴)表示训练的epochs(训练周期数),从0到100。
纵轴(Y轴)表示训练损失(Loss)。
曲线展示了训练损失随着训练周期数增加而逐渐减少的趋势。最初的训练损失大约在0.8左右,随着训练的进行,损失持续下降,到训练结束时降至接近0.2左右。
说明模型在训练过程中逐渐学习和优化,其性能在不断提高。
右图:Validation Accuracy Over Epochs横轴(X轴)表示训练的epochs(训练周期数),从0到100。
纵轴(Y轴)表示验证准确率(Accuracy),百分比表示。
曲线展示了验证准确率随着训练周期数增加而逐渐提高的趋势。最初的验证准确率大约在50%左右,随着训练的进行,准确率不断上升,到训练结束时达到接近90%左右。
验证准确率曲线在训练初期上升较快,随后逐渐趋于平稳,最终在高水平上稍微波动。这表明模型在验证集上的表现也在逐渐提高,达到一个较高的准确率水平。
总体而言,这个训练结果表明模型的训练过程是成功的。训练损失持续下降,验证准确率持续上升,最终模型在验证集上的准确率接近90%,说明模型在图像分类任务上有很好的表现
4.4 问题分析
训练过程中损失居然上升了,可能是过拟合,或者是陷入了局部最优,并且net已经加了Dorpout。
所以,这里加上一个学习率调度器试试

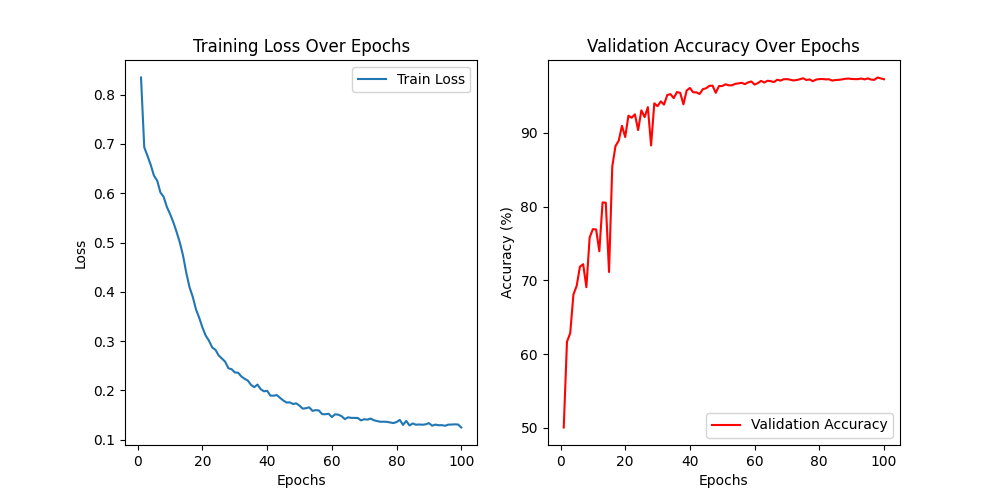
可以看到,曲线平缓了很多,且损失没有大幅上升
4.5 单张图片测试
- 调用前面的网络构建模型,再将训练好的权重load进来,用Jupyter会显示网络架构,其他不显示也没关系
python
#测试模型
model_test = Vgg16_net()
model_test.load_state_dict(torch.load('model_epoch_100.pth'))
model_test.eval() Vgg16_net(
(layer1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
...
- 图像处理
python
from PIL import Image
transform = transforms.Compose([
transforms.Resize((224, 224)), # 假设使用224x224输入
transforms.ToTensor(), # 将图片转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 归一化
])- 设置图片路径,将图片读取后增加一个batch维度,因为DataLoader在获取数据时会有batch维度,之后将数据传入GPU,用模型预测类别
python
# 加载图片
img1 = Image.open(r'C:\Users\Administrator\Pictures\cat1.png')
img2 = Image.open(r'C:\Users\Administrator\Pictures\dog1.png')
#img2 = img2.convert('RGB') # 确保图片是三通道的
#img.show()
# 应用预处理
img_tensor1 = transform(img1).unsqueeze(0) # 增加批次维度
img_tensor2 = transform(img2).unsqueeze(0) # 增加批次维度
#img_tensor.show()
# 确保使用与训练相同的设备
model_test = model_test.to(device)
img_tensor1 = img_tensor1.to(device)
img_tensor2 = img_tensor2.to(device)
# 前向传播获取输出
with torch.no_grad():
outputs1 = model_test(img_tensor1)
outputs2 = model_test(img_tensor2)
classes = ('cat', 'dog')
# 获取预测结果
_, predicted1 = torch.max(outputs1, 1)
_, predicted2 = torch.max(outputs2, 1)
print("Predicted class index:", classes[predicted1.item()])
print("Predicted class index:", classes[predicted2.item()])
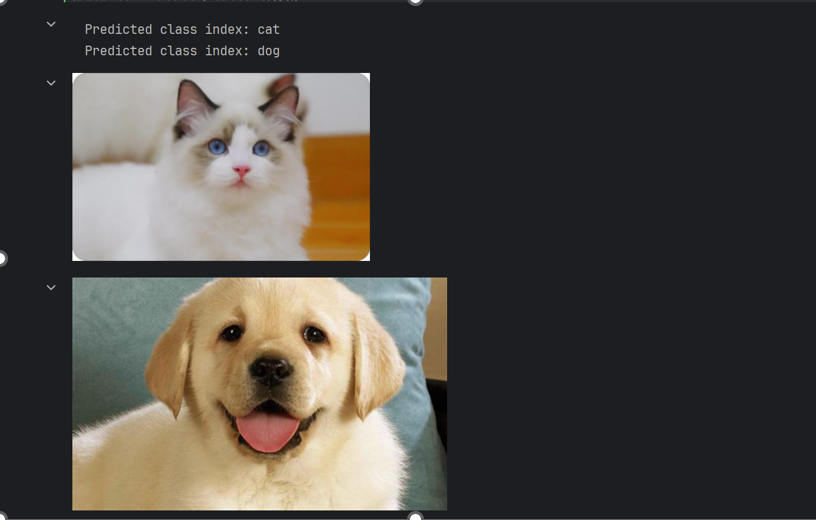
display(img2)- 测试结果
5.完整训练代码与权重
链接:https://pan.baidu.com/s/1UW2aWyF8cRrf_tbaslJihw?pwd=18uk
提取码:18uk
--来自百度网盘超级会员V7的分享
Tips 数据集过大,这里是在3090上训练得到的权重,共训练了一天,如有需要,可以直接下载训练好的权重