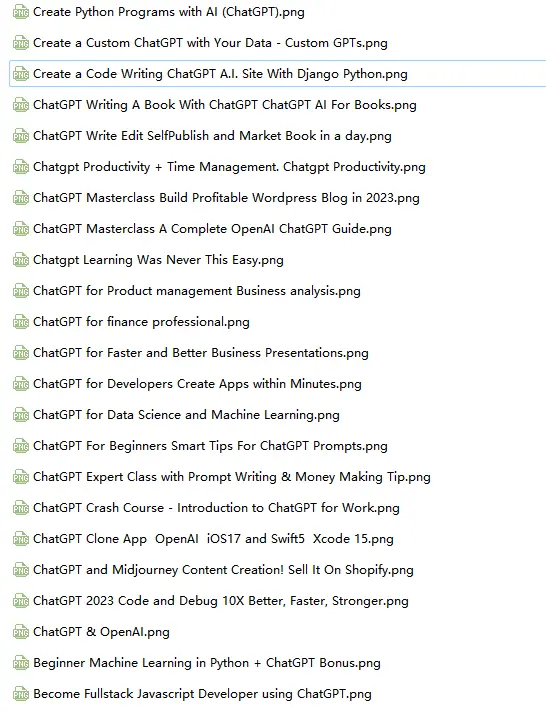
对网页指定区域批量截图,可以在deepseek的代码助手中输入提示词:
你是一个Python编程专家,一步一步的思考,完成一个对网页指定区域截图的python脚本的任务,具体步骤如下:
设置User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
找到Excel文件:"F:\AI自媒体内容\课程列表.xlsx"
读取Excel文件的第1列,作为图片标题{pictitle};
读取Excel文件的第2列,这是URL,用Undetected-chromedriver加载网页进行渲染,让窗口最大化,等待20秒;
对打开的网页进行截图,截图的区域是屏幕左上角:(X: 0,y:80),屏幕右下角:(X:1495,y:987);
截图保存为png图片格式,用{pictitle}作为图片文件名,保存到文件夹:"F:\AI自媒体内容\";
截图完成后等待30秒;
注意:
每一步都要输出相关信息到屏幕;
在用{pictitle}命名文件名之前,先检查{pictitle}中是否有不符合window系统文件命名规格的特殊符号,如果有则删除掉其中的特殊符号;
源代码:
import pandas as pd
import undetected_chromedriver as uc
from PIL import Image
import re
import os
import time
设置User-Agent
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
读取Excel文件
excel_path = "F:\AI自媒体内容\课程列表.xlsx"
df = pd.read_excel(excel_path)
设置截图保存的文件夹
save_folder = "F:\AI自媒体内容\\"
初始化undetected_chromedriver
options = uc.ChromeOptions()
options.add_argument(f'user-agent={user_agent}')
driver = uc.Chrome(options=options)
driver.maximize_window()
遍历Excel文件的每一行
for index, row in df.iterrows():
pictitle = row0
url = row1
检查pictitle是否有不符合window系统文件命名规格的特殊符号
pictitle = re.sub(r'\\\\/:\*?"\<\>\|', '', pictitle)
print(f"正在打开网页: {url}")
driver.get(url)
等待20秒
driver.implicitly_wait(20)
截图
print(f"正在截图: {pictitle}")
driver.save_screenshot('temp.png')
使用PIL库截取屏幕区域
im = Image.open('temp.png')
im = im.crop((0, 80, 1495, 987))
保存截图到指定文件夹
save_path = os.path.join(save_folder, f"{pictitle}.png")
im.save(save_path)
print(f"截图已保存到: {save_path}")
删除临时截图文件
os.remove('temp.png')
等待30秒
print("等待30秒...")
time.sleep(30)
关闭浏览器
driver.quit()