垂直边缘检测
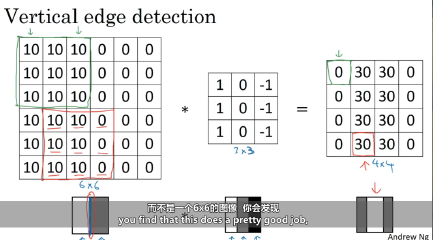
图像左边是10(亮色),右边是0(暗色),中间有一条垂直的敏感分界线(边缘),用特定的卷积核,让这条边缘"凸显"出来。
卷积操作--填充(padding)
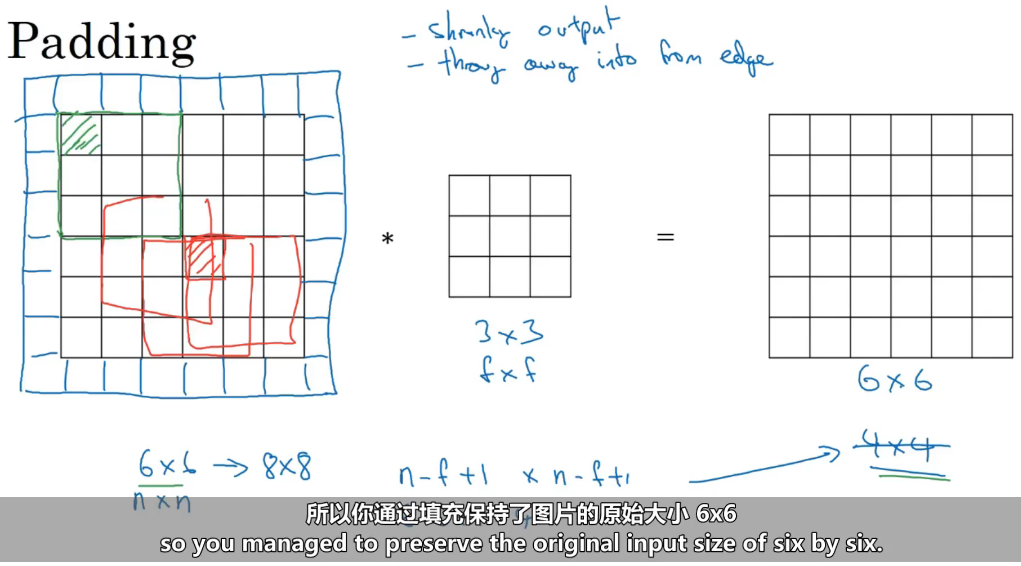
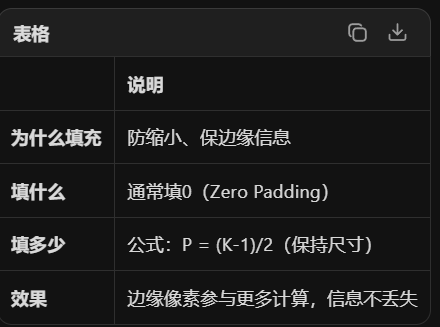
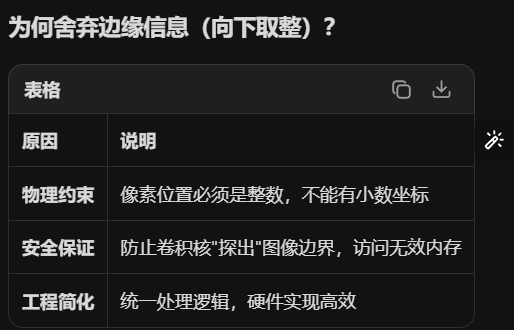
目的 在图像边缘补零(或其他值),解决卷积带来的两个问题:缺陷1:图像尺寸缩小 每卷积一次,图像就变小! 深层网络卷积多次 → 图像消失 ; 缺陷2:边缘像素被"重复计算",结果:边缘信息被"浪费",中心信息过度使用
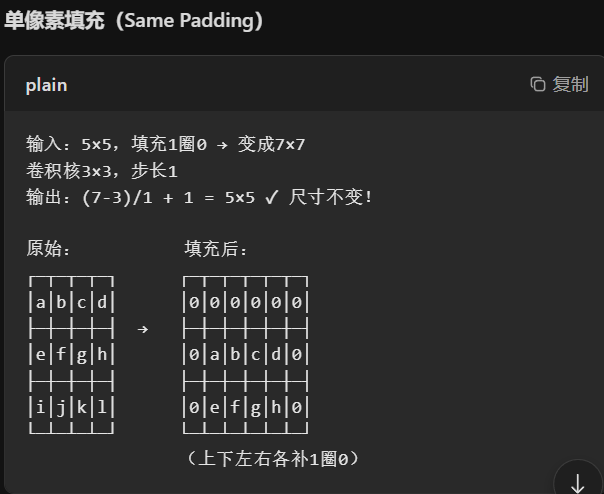
单像素填充
多像素填充

strided卷积--带步长的卷积
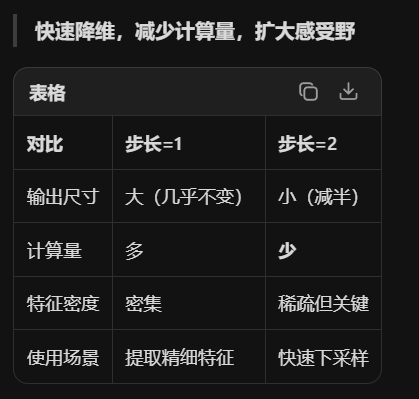
例子:输入7×7,核3×3,步长2
位置0:核覆盖[0,1,2] ✓
位置2:核覆盖[2,3,4] ✓
位置4:核覆盖[4,5,6] ✓
位置6:核覆盖[6,7,8] ✗ 越界,舍弃!
输出:⌊(7-3)/2⌋+1 = 3×3(最后一步被丢弃)工程权衡:舍弃一点边缘信息,换取实现简单和计算稳定。
数学卷积 vs 深度学习"卷积"的区别

三维卷积算法
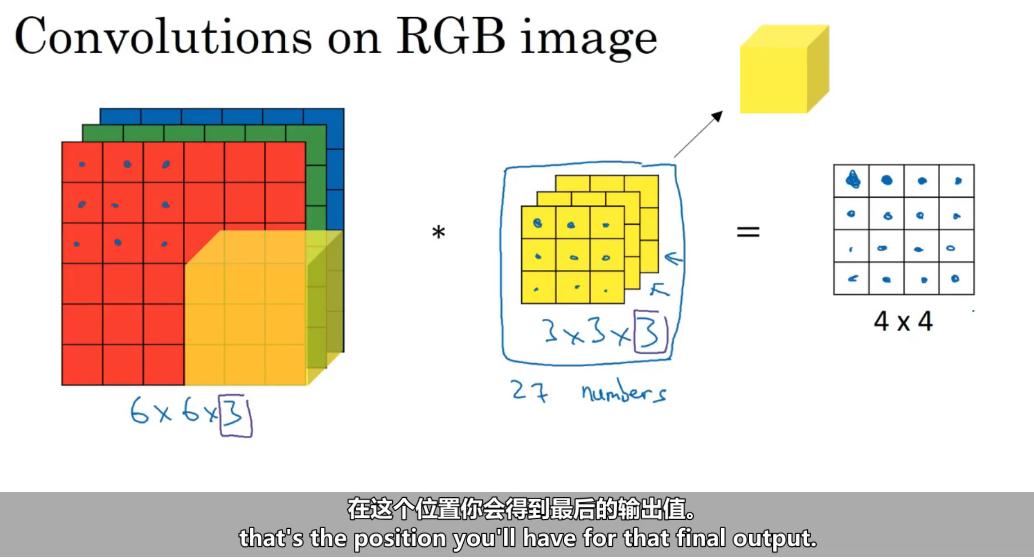
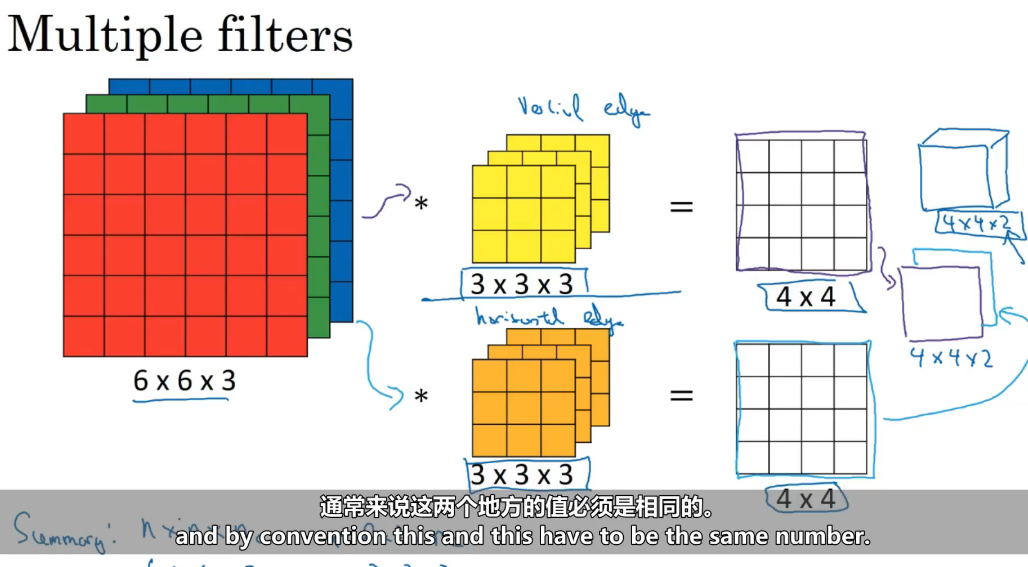
目的 同时提取多种特征,增加网络表达能力
输入:6×6×3(RGB三通道图像)
↓
┌─────────────────┐
│ 多个卷积核并行计算 │
│ │
│ 卷积核1(3×3×3)→ 检测垂直边缘 → 输出4×4 │
│ 卷积核2(3×3×3)→ 检测水平边缘 → 输出4×4 │
│ 卷积核3(3×3×3)→ 检测其他特征 → 输出4×4 │
│ ... │
└─────────────────┘
↓
输出:4×4×N(N=卷积核数量,图中N=2)
关键:每个卷积核都是3×3×3,同时看三个通道!三维卷积 = 多通道输入 + 多核并行 = 提取丰富特征 角度检测:手工设计有限角度,神经网络自动学习任意角度!
构建单层卷积网络
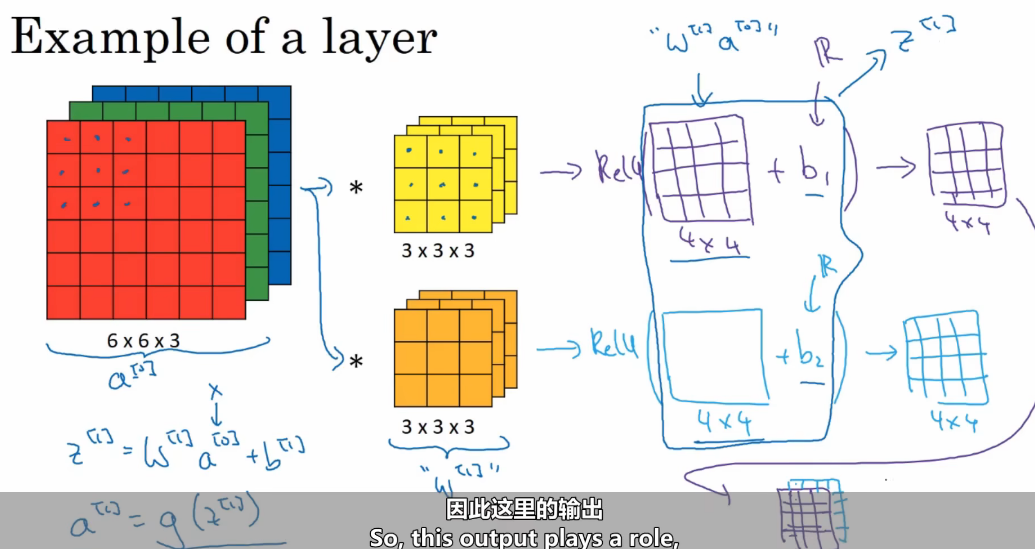
为什么要加 Bias(偏差)?--"门槛调节器"
卷积结果 + b = 可以平移激活函数
没有bias:输出必须经过原点(0,0)
有bias: 可以左右移动,拟合能力更强
例子:
z = w·x + b
↑
b=-0.5 时,原来z=0的位置现在z=-0.5,ReLU激活点改变
一句话:bias 让模型更灵活,可以调整激活的"阈值"。
输入强度:弱 ────────────── 强
2 14
无bias(b=0):
ReLU输出:0 14
↑ ↑
弱特征被杀死 强特征保留
有bias(b=5):
ReLU输出:7 19
↑ ↑
弱特征也激活 更强了
有bias(b=-10):
ReLU输出:0 4
↑ ↑
弱特征死透 强特征也被削弱
------------------------------------------------
同一卷积核,不同bias:
原图边缘: 弱边缘 强边缘
┌──┐ ┌──┐
│10│ │50│
b = -5(严): 0(被抑制) 45(保留)
b = 5(松): 15(保留) 55(更强)
→ 输出特征图亮度不同!问题2:为什么要非线性激活(ReLU)?
没有非线性(纯线性堆叠):
Conv1 → Conv2 → Conv3 = 一个大线性变换
↓
无论多少层,都等价于单层!表达能力极差
加入ReLU(非线性):
Conv1 → ReLU → Conv2 → ReLU → Conv3
↓
每层都在"折弯"数据,多层可以拟合任意复杂函数
非线性让网络能学复杂模式,否则层数再多
输入:x = -3
【无ReLU】线性网络:
Layer1: z₁ = 2×(-3) + 1 = -5
Layer2: z₂ = 3×(-5) + 2 = -13
↓
还是线性,可以合并成一层
【有ReLU】非线性网络:
Layer1: z₁ = 2×(-3) + 1 = -5
a₁ = ReLU(-5) = max(0, -5) = 0 ← 关键!负数变0了
Layer2: z₂ = 3×a₁ + 2 = 3×0 + 2 = 2
a₂ = ReLU(2) = 2
现在合并试试?
z₂ = 3·ReLU(2·x + 1) + 2
↑
ReLU在里面,没法展开成W·x + B的形式!
------------------------------------------------------------------
形象展示:
线性函数:f(x) = 2x + 1 是一条直线
↓
ReLU打断:g(x) = ReLU(2x + 1) 变成"折线"!
↑
/│
/ │
/ │ ← x > -0.5 时,斜率为2
─────/ │
│ │ ← x < -0.5 时,输出为0(水平线)
└────┘→ x
-0.5
原来是一条直线,现在被"折弯"了!
可视化:
x轴输入 ─────────────────────────────→
无ReLU(线性):  ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ (只能直线)
有ReLU(3层): ╱ ̄╲_╱ ̄╲_╱ ̄ (可以任意曲折)
↑ 多次折弯,拟合复杂模式核心目的就是让模型能学会复杂模式,而不是只能画直线
任务:检测"猫耳朵"
输入图像像素值:0~255
线性模型:
像素 ──→ 分数 只能:像素越亮 = 越像耳朵?
↓
错!耳朵有亮有暗,不是线性关系
ReLU模型:
像素 ──→ 折弯(检测边缘)──→ 折弯(检测形状)──→ 折弯(组合成耳朵)
↓
可以学:亮→暗是左边缘,暗→亮是右边缘,组合成三角形是耳朵问题3:a 为什么成为下一层输入?
a⁰ (6×6×3) ──卷积+ReLU──→ z¹ ──激活──→ a¹ (4×4×2)
输入图像 线性变换 非线性输出
↓
成为下一层输入
↓
a¹ ──卷积+ReLU──→ z² ──激活──→ a²
这就是前向传播:a⁰→a¹→a²→...→输出问题4:为什么卷积不容易过拟合?
 卷积核大小固定,扫遍全图共享权重,无论图像多大,参数就那么多!
卷积核大小固定,扫遍全图共享权重,无论图像多大,参数就那么多!
单层卷积工作原理
详细步骤:
1. 拿第1个卷积核(3×3×3),在输入上滑动,得到4×4特征图1
2. 拿第2个卷积核(3×3×3),在输入上滑动,得到4×4特征图2
3. 每个位置加bias(b₁, b₂)
4. 过ReLU激活(负数变0)
5. 两个4×4特征图堆叠 → 输出4×4×2
6. 这个输出成为下一层的输入(a¹)联合几层(神经网络)进行深度卷积

池化层
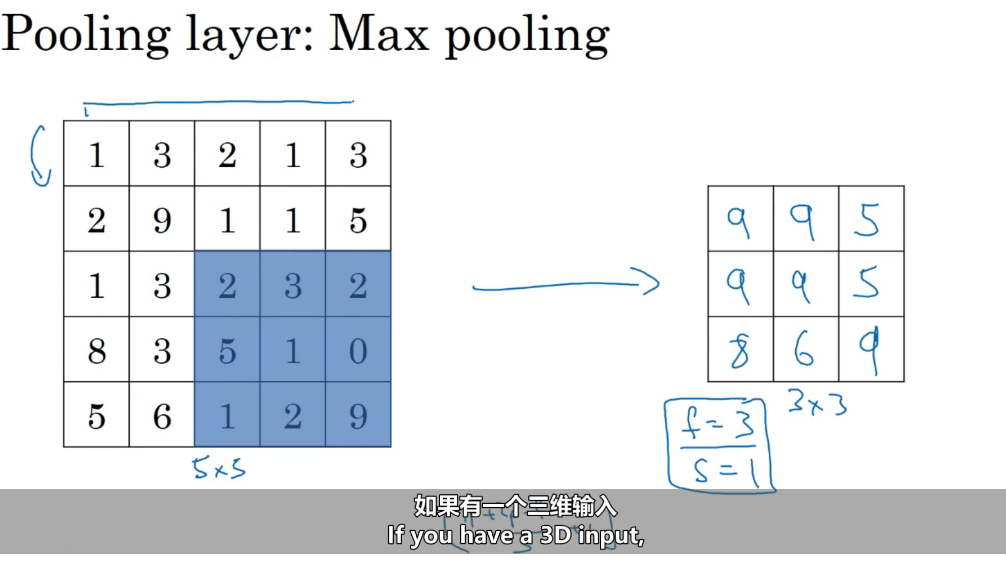
作用 降维 + 保留关键特征 + 防过拟合

卷积结合神经网络
深度卷积的参数很少?
-
1.参数共享:"同一个卷积核在图像的不同位置滑动,使用完全相同的权重参数
*传统全连接:每个输入像素 → 每个输出神经元 都有独立的权重 1000×1000图像 → 100万个神经元 = 10^12个参数 ❌ CNN参数共享:一个3×3卷积核(9个参数)扫描整张图像 无论图像多大,这个核只有9个参数 ✅就像用一个放大镜(卷积核)扫描照片,放大镜的"镜片"(权重)是不变的。无论看照片的哪个位置,判断"是否有边缘"的标准是一样的。 为什么有效? 因为图像的统计特性具有平移不变性------一张猫的照片,猫耳朵的特征在左上角和右下角应该被同样识别。
-
稀疏连接
*输入层(4个神经元) 输出层(4个神经元) [1] ───────────────→ [a] [2] ───────────────→ [b] [3] ───────────────→ [c] [4] ───────────────→ [d] 每个输出连接所有输入:4×4 = 16个连接 卷积层: 输入层(4×4=16个像素) 输出层(2×2=4个特征图位置) 假设使用2×2卷积核,步长为2: 输出[a] 只连接 输入[1,2,5,6] (左上角2×2区域) 输出[b] 只连接 输入[3,4,7,8] (右上角2×2区域) 输出[c] 只连接 输入[9,10,13,14] (左下角2×2区域) 输出[d] 只连接 输入[11,12,15,16](右下角2×2区域) 每个输出只连接局部4个输入,而非全部16个!"稀疏"指的是:每个输出神经元只与输入的局部区域相连,而非全部输入
你不需要同时看整张照片的每个像素来判断"这里有猫耳朵",只需要看这一小块区域
CNN全流程
卷积层:用卷积核扫描图像,提取局部特征 参数共享 + 稀疏连接
输入图像: 32×32×3 (RGB三通道)
↓
卷积核: 5×5×3 (滑动窗口,3个通道)
↓
输出特征图: 28×28×6 (6个不同的卷积核,提取6种特征)
激活函数:引入非线性,让网络能学习复杂模式;没有激活函数,多层卷积叠加还是线性变换,无法学习复杂特征。
ReLU: 最常用的激活函数
f(x) = max(0, x) # 负数变0,正数保持不变
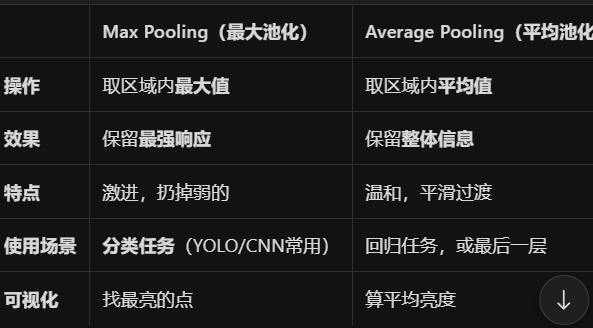
池化层:降低特征图尺寸,减少计算量,增强平移不变性;保留主要特征,丢弃精确位置信息(对分类任务影响不大)
最大池化(Max Pooling): 取2×2区域中的最大值
平均池化(Average Pooling): 取2×2区域中的平均值
28×28的特征图 → 2×2池化 → 14×14的特征图
展平层:将多维特征图转换为一维向量,方便接入全连接层
输入: 7×7×64 的特征图 (3136个数值)
↓
展平: 1×3136 的向量
全连接层:综合所有局部特征,进行最终分类决策;这里没有参数共享,每个连接都有独立权重
输入: 3136个特征
↓
全连接层1: 3136 → 1024 (每个输入连接每个输出)
↓
全连接层2: 1024 → 128
↓
输出层: 128 → 10 (比如10个类别)
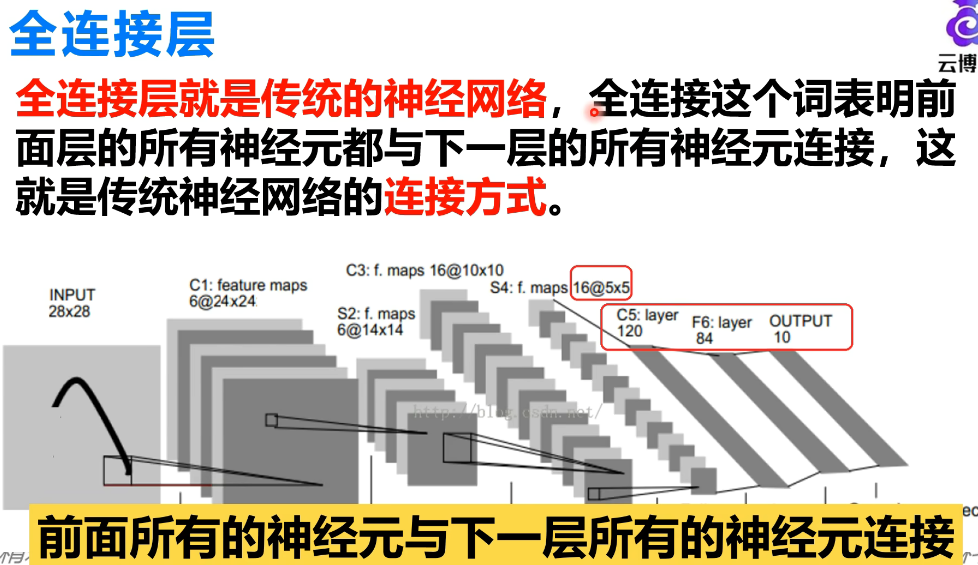

全连接层到底在连什么?
第一步:展平
在进全连接层之前,先把多层特征图"拍扁"成一维向量:
输入: 7×7×64 的特征图 (64层,每层7×7)
第1层: a1, a2, a3, a4, a5, a6, a7 ← 7个值
第2层: b1, b2, b3, b4, b5, b6, b7 ← 7个值
...
第64层:z1, z2, z3, z4, z5, z6, z7 ← 7个值
展平后: a1,a2,a3,a4,a5,a6,a7, b1,b2,b3..., z1,z2,z3...
总共 7×7×64 = 3136 个数,排成一长条!
这里不分"层"了,所有特征图的所有位置都混在一起变成一个向量。
第二步:全连接
输入向量: 3136个数字 (一维)
↓
全连接层: 每个输出神经元连接全部3136个输入
↓
输出: 比如1024个神经元
输入(3136个) 输出(1024个)1\] ──┬──────────────→ \[A
2\] ──┤ → \[B
3\] ──┤ 全连接 → \[C
... │ (每个连每个) ...
3136\]┘ → \[1024
权重矩阵: 3136 × 1024 = 3,211,264个参数!
为啥要连接这么多神经元?
卷积层提取的是基础特征 (边缘、纹理、颜色块),但真实世界需要组合判断:
基础特征(卷积层找到):
- 有毛茸茸的纹理
- 有尖耳朵形状
- 有圆形眼睛
- 有胡须线条
- 有三角形鼻子
组合判断(全连接层学习):
毛茸茸 + 尖耳朵 + 圆眼睛 + 胡须 = 猫
毛茸茸 + floppy耳朵 + 长鼻子 = 狗
光滑皮肤 + 尖嘴 + 无耳朵 = 鱼每个组合都需要一个"专家神经元"来学习!
1024个神经元 = 1024个不同的"特征组合专家"
为什么要"全连接"?不能只连部分吗?
只连"耳朵"和"尾巴"的神经元:
→ 可能把兔子也认成猫(长耳朵+短尾巴)
连所有特征的神经元:
→ 同时检查耳朵+尾巴+胡须+眼睛+鼻子+纹理
→ 准确区分猫和兔子全连接层的1024个神经元 = 1024个"特征组合专家",每个专家检查全部3136个基础特征,学习特定的模式组合(如"毛+尖耳+圆眼=猫")。连接这么多是为了捕捉复杂的特征关系,但现代网络正在寻找更高效的方式替代它。