
【摘要】高效的、针对特定任务的提示通常由专家精心设计,以整合详细的说明和领域见解,这些见解基于对大型语言模型 (LLM) 的本能和目标任务的复杂性的深刻理解。然而,自动生成这种专家级提示仍然难以实现。现有的提示优化方法往往忽视领域知识的深度,难以有效探索专家级提示的广阔空间。为了解决这个问题,我们提出了 PromptAgent,这是一种优化方法,可以自主制作质量与专家手工制作的提示相当的提示。从本质上讲,PromptAgent 将提示优化视为一个战略规划问题,并采用基于蒙特卡洛树搜索的原则性规划算法来战略性地导航专家级提示空间。受到类似人类的反复试验探索的启发,PromptAgent 通过反思模型错误并生成建设性的错误反馈来引出精确的专家级见解和深入的指导。这种新颖的框架允许代理迭代检查中间提示(状态),根据错误反馈(操作)对其进行改进,模拟未来的奖励,并搜索通向专家提示的高奖励路径。我们将 PromptAgent 应用于三个实际领域的 12 个任务:BIG-Bench Hard (BBH),以及特定领域和一般 NLP 任务,结果表明它的表现明显优于强大的 Chain-of-Thought 和最近的提示优化基线。广泛的分析强调了它能够以极高的效率和通用性制作专家级、详细且具有领域洞察力的提示。
原文:PROMPTAGENT: STRATEGIC PLANNING WITH LANGUAGE MODELS ENABLES EXPERT-LEVEL PROMPT OPTIMIZATION
地址:https://arxiv.org/abs/2310.16427
代码:https://github.com/XinyuanWangCS/PromptAgent
出版:ICLR 24
机构: UC San Diego, Mohamed bin Zayed University of Artificial Intelligence
写的这么辛苦,麻烦关注微信公众号"码农的科研笔记"!
1 研究问题
本文研究的核心问题是: 如何自动化地生成等同于专家手工设计的高质量任务提示。
假设一家医疗健康公司想训练一个大语言模型来回答医学相关的问题。为了使模型的回答足够专业和准确,工程师需要精心设计输入给模型的任务提示,融入大量医学领域知识。这通常需要领域专家投入大量的时间和精力。本文旨在探索如何用算法自动生成这种专家级别的提示,从而大大降低人工成本。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
专家级提示往往包含非常丰富和深入的领域知识,现有方法缺乏对此的考虑。
-
专家级提示空间十分广阔,现有方法难以高效探索这个空间。
-
现有方法倾向于生成与普通用户提示局部相似的变体,很难达到专家提示的深度和广度。 针对这些挑战,本文提出了一种基于蒙特卡洛树搜索的"PromptAgent"方法:
PromptAgent巧妙地将提示优化问题转化为一个策略规划问题。它将生成专家级提示的过程比喻为人类专家设计提示时的反复试错和迭代。每一轮迭代相当于PromptAgent在提示空间中走一步,通过对模型错误进行反思来选择探索方向并对当前提示进行修正。这种人性化的试错过程使PromptAgent能够像人类专家一样在失败中不断学习和进化,最终抵达最优的提示形式。同时,蒙特卡洛树搜索赋予了PromptAgent前瞻性和回溯性,它可以估计未来的回报,调整当前的探索策略,避免陷入局部最优。整个搜索过程在提示空间上形成了一棵树,PromptAgent总是选择最有希望的分支向下探索。最终,经过多轮博弈,它可以在广阔的专家提示空间中找到最优解。

2 研究方法
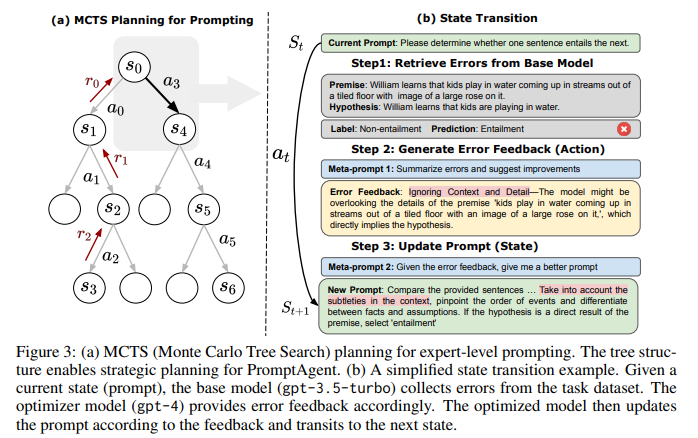
2.1 问题定义
论文将提示优化问题定义为一个马尔可夫决策过程(MDP),用元组表示。其中,表示状态空间,每个状态对应一个提示的版本;为动作空间,每个动作是基于模型错误反馈生成的修改;定义状态转移函数;是回报函数,用于评估新生成的提示在验证集上的性能。
给定当前状态,PromptAgent迭代地基于生成动作,其中是一个优化器语言模型,是用于辅助动作生成的元提示。接着,PromptAgent根据状态转移函数得到新的状态,是帮助状态转移更新提示的另一个元提示。最后,新生成状态应用动作后的质量由回报函数决定。
2.2 PromptAgent框架
如图3(a)所示,PromptAgent的核心是将MCTS规划算法引入提示优化,通过构建树状结构来策略性地探索提示空间。每个节点表示一个状态(提示),每条边表示状态间的转移动作。PromptAgent通过错误反馈生成有洞察力的动作,并利用MCTS来优先探索那些有希望获得高回报的路径。
图3(b)展示了PromptAgent的工作流程。给定一个当前状态(提示),(1)基础模型先在任务数据集上收集预测错误;(2)优化器模型根据错误总结得到错误反馈作为动作;(3)优化器模型再根据错误反馈更新提示,过渡到下一状态。通过这种基于错误反馈的试错迭代,PromptAgent可以有效地将领域知识引入到提示生成中。
2.3 基于MCTS的提示优化
MCTS通过迭代执行选择、扩展、仿真和回溯四个操作,逐步构建搜索树,更新状态-动作值函数来估计从当前状态-动作对出发的未来累积回报,指导树的扩展方向。
-
选择:从根节点出发,使用UCT算法平衡利用和探索,递归地选择最优子节点,直到到达一个可扩展的叶子节点。
-
扩展:对选择到的叶子节点,基于采样得到的多批次错误生成多个动作(错误反馈),将其应用到当前状态,得到多个新的子节点(新提示),加入到搜索树中。
-
仿真:对新扩展出的节点,通过不断迭代扩展步骤,模拟未来轨迹的累积回报,直到达到最大深度或满足早停条件。
-
回溯:当到达终止状态时,将累积回报从叶子节点传播回根节点,更新路径上每个状态-动作对的值,调整树的扩展方向。
通过预设的迭代次数,PromptAgent最终输出具有最高平均累积回报的路径作为优化的提示。MCTS的前瞻性仿真和回溯传播机制使其能高效地在庞大的提示空间中找到优质解。
2.4 算法实现细节

算法1详细展示了PromptAgent-MCTS的流程。元提示和的设计对PromptAgent至关重要,分别指导了动作生成和状态转移。论文通过held-out验证集上的任务性能来定义回报函数,并设置最大搜索深度和早停阈值来控制计算开销。此外,论文在多个不同难度的超参数设置下分析了PromptAgent的收敛性和泛化性能。总之,PromptAgent创新性地将提示优化问题建模为MDP,并应用MCTS算法进行策略规划,通过错误反馈的试错机制来纳入领域知识,以解决专家级提示工程面临的知识差距和搜索效率问题,为自动化提示优化开辟了新的思路。
2.5 举例&总结
结合论文原文,我们可以用一个简单的例子(完整方法见详细原文)来说明这个方法。
整体目的: 假设我们要为一个医疗问答系统设计输入提示,希望模型能根据提示生成专业、准确、全面的医学建议。我们希望提示能涵盖疾病定义、治疗方法、注意事项等多方面内容,并符合医学专业人士的表述习惯。传统的人工撰写提示费时费力,需要大量领域专业知识。PromptAgent旨在通过自动化方法生成高质量的"专家级"提示,大幅降低人力成本。下面我们用一个简化的例子,结合PromptAgent的核心步骤,详细说明其工作原理。
给定:
-
初始提示:"请根据病情描述,给出诊断建议。"
-
训练集:100个(病情描述,诊断建议)数据对
-
验证集:20个数据对
步骤:
步骤1:将提示优化建模为马尔可夫决策过程(MDP)
定义MDP的四个要素:
-
状态:第轮优化的提示
-
动作:根据错误反馈对的修改
-
转移:将动作应用到状态,得到新提示
-
奖励:新提示在验证集的表现提升
假设当前状态为,即初始提示。
解释:MDP建模的核心思想是将一个序贯决策过程表示为在状态空间中搜索最优路径。提示优化可以看作一个多轮对话:PromptAgent根据当前提示的错误反馈,不断生成修改建议(动作),得到新的提示(新状态),并根据新提示的效果(奖励)调整之后的优化方向。每一轮对话对应MDP中的一步决策,目标是在有限的轮数内搜索到最优提示。
步骤2:基于错误反馈生成动作
(1)用当前提示在训练集上测试,得到预测错误样本:
-
输入:小儿反复咳嗽、流涕3天,鼻塞,无发热。
-
输出:建议口服布洛芬退烧止痛,必要时请医生处方抗生素。
-
标准答案:考虑普通感冒引起上呼吸道感染,建议对症治疗,多饮水休息。必要时可使用儿童感冒冲剂缓解症状,但应避免抗生素滥用。若持续高热或症状加重,应及时就医。
(2)总结错误并生成反馈:
-
诊断不够准确,应基于具体症状给出初步判断
-
未提及一般治疗措施,如多休息多饮水
-
未提及常用药物如感冒冲剂,也未警示抗生素滥用
-
对于可能加重的情况缺乏说明
(3)基于反馈生成修改建议(动作):
-
根据症状先给出初步诊断判断
-
补充一般治疗建议,如多休息多饮水
-
提及常用对症治疗药物,警示抗生素滥用问题
-
说明可能加重的情形,建议必要时就医
解释:错误反馈是优化的关键。通过比较模型输出与参考答案,可以发现当前提示的局限性,例如缺少必要的分步指导,或遗漏了重要的注意事项。这些反馈信息可以指导PromptAgent去修正提示,添加缺失的说明,使其更加全面、合理。值得注意的是,这里的反馈总结和修改建议都是由另一个强大的语言模型(如GPT-4)自动生成的。这体现了PromptAgent的核心思路:利用LLM自身的语言理解和生成能力去优化提示。
步骤3:状态转移,生成新提示 将动作应用到状态(即)中,生成新提示(即新状态):
"针对儿童反复咳嗽、流涕、鼻塞等症状,首先请给出你的初步诊断判断。在治疗建议中,应提及一般措施如多休息、多饮水等。可以列举常用的对症药物如感冒冲剂,但要提醒避免抗生素滥用。最后还需说明若持续高热或症状加重应及时就医。"
解释:状态转移是通过语言模型实现的,给定当前提示和修改建议,由模型生成完整的新提示。可以看到,新提示较好地纳入了反馈中提到的内容,步骤更清晰,覆盖面也更全。同时新提示也保持了语言的连贯性和逻辑性。这一步的关键在于语言模型要准确理解反馈的意图,并将其自然地融入到原有提示中,生成符合人类表达习惯的内容。
步骤4:评估新提示并计算奖励 将新提示在验证集上测试,评估其性能提升:
-
提升点1:90%的样本生成了准确的诊断
-
提升点2:85%的样本提到了至少两条一般治疗建议
-
提升点3:75%的样本涉及了常用药品使用和抗生素滥用问题
-
提升点4:80%的样本对可能加重的情况提出了合理建议
假设性能提升为,则状态-动作值函数更新为:
解释:PromptAgent通过新提示在验证集上的表现来评判动作的效果。在医疗问答这个例子中,我们主要考察新提示在四个方面(诊断、治疗建议、药品使用、预后说明)的改进情况。这些维度覆盖了医疗问答的核心要素,对应问题开始时提到的"专家级"提示的特征。奖励值quantify了提示优化前后的性能差异,奖励越大,说明动作的效果越好,状态从转移到也就越有价值。PromptAgent中的函数可以看作在估计未来累积奖励的期望,它记录并更新每一个尝试过的状态-动作对的价值,指导接下来的探索方向。
PromptAgent通过上述四个步骤形成一个完整的探索迭代。在实际使用中,它会重复这个过程多轮(如12轮),通过广度优先搜索、启发式评估、回溯更新等机制不断拓展搜索树,最终输出搜索路径中性能最佳的提示作为优化结果。
3 实验
3.1 实验场景介绍
该论文提出了一个基于策略规划的prompt优化框架PromptAgent,通过蒙特卡洛树搜索(MCTS)在庞大的prompt空间进行高效探索,并利用LLM的自我反思能力引入领域知识,生成expert-level的prompts。实验旨在全面评估PromptAgent在不同任务上的优化性能,与基线方法进行比较,并分析其优化的prompts的泛化能力和质量。
3.2 实验设置
-
Datasets:12个任务,跨越BIG-Bench Hard(6个)、特定领域(3个生物医学任务)和常规NLP(文本分类、自然语言推理等3个)三大领域
-
Baseline:
-
Human Prompts:普通人工设计的指令,通常来自原始数据集
-
Chain-of-Thought (CoT) Prompts:在prompt中引入中间推理步骤,在BBH任务上效果显著
-
GPT Agent:类似Auto-GPT的自主代理,使用GPT-4的插件进行prompt优化
-
APE:最新的基于Monte Carlo搜索的迭代式prompt优化方法
-
-
Implementation details:
-
默认base LLM为GPT-3.5,优化器LLM为GPT-4
-
MCTS迭代次数设为12,exploration weight c设为2.5
-
三种超参设置:Standard(depth limit=8)、Wide(expand width=3,num samples=2)和Lite(depth limit=4)
-
-
metric:各任务的默认评估指标,如准确率、F1等
3.3 实验结果
3.3.1 实验一、PromptAgent与基线方法的性能对比
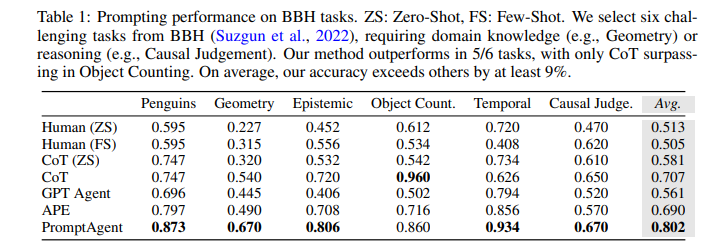
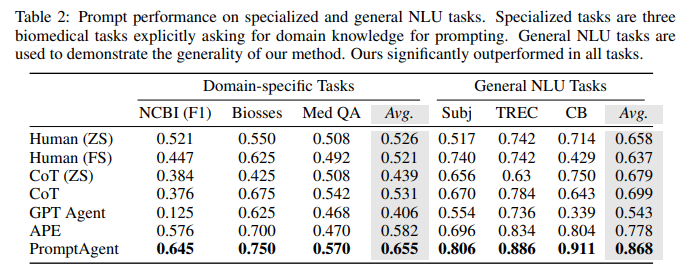
目的:评估PromptAgent生成的expert-level prompts相比human prompts、CoT prompts和现有优化方法在不同类型任务上的优势
涉及图表:表1,表2
实验细节概述: 在12个跨三大领域的任务上,将PromptAgent生成的prompts与human prompts、CoT prompts、GPT Agent和APE的结果进行对比。
结果:
-
BBH任务:PromptAgent显著优于所有基线,平均超出human prompts(ZS)、CoT和APE 28.9%、9.5%和11.2%
-
特定领域任务:PromptAgent在注入领域知识上比APE有7.3%的优势,缩小了普通工程师与领域专家之间的差距
-
常规NLP任务:PromptAgent分别超出CoT 16.9%和APE 9%,表明即使是常规任务也存在专家级别的prompt优化空间
3.3.2 实验二、PromptAgent优化prompts的泛化能力
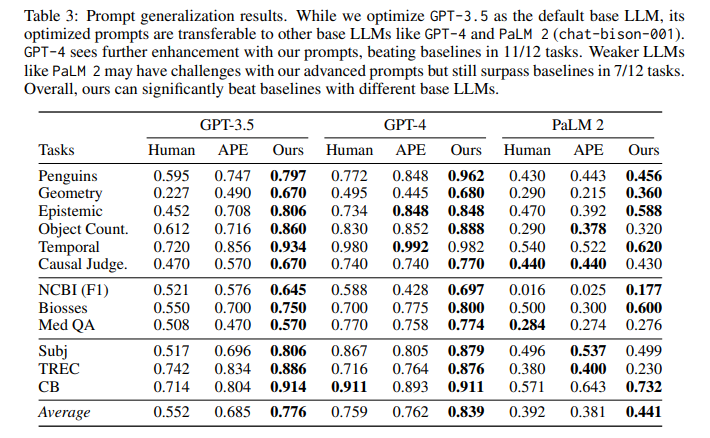
目的:探究在GPT-3.5上优化的prompts是否可直接应用于其他base LLMs(GPT-4和PaLM 2)
涉及图表:表3
实验细节概述: 将GPT-3.5上的优化prompts直接用于GPT-4和PaLM 2,并与Human prompts和APE prompts在12个任务上进行比较。
结果:
-
在更强的GPT-4上,PromptAgent的prompts在11/12个任务上达到或超过基线,进一步放大了expert prompts的潜力
-
在较弱的PaLM 2上,尽管性能有所下降,但在7/12任务上仍超过基线,特别是在特定领域任务上,表明expert prompts中的领域知识是有效的
3.3.3 实验三、搜索策略的消融实验

目的:系统研究PromptAgent中策略规划的作用,比较MCTS与其他搜索变体的性能差异
涉及图表:表4
实验细节概述: 选取三个领域的5个任务子集,将MCTS与Monte Carlo搜索、Greedy搜索和Beam搜索进行比较,除搜索算法外,其他设置与PromptAgent相同。
结果:
-
Greedy和Beam搜索显著优于无方向的Monte Carlo搜索,表明结构化迭代探索的必要性
-
在探索效率相当的情况下,Beam和Greedy性能相当,但两者都缺乏对未来结果的预见和对过去决策的回溯能力
-
PromptAgent的MCTS在所有任务上明显超过其他搜索变体,平均相对提升5.6%,凸显了策略规划在复杂prompt空间中的重要性
3.3.4 实验四、探索效率分析
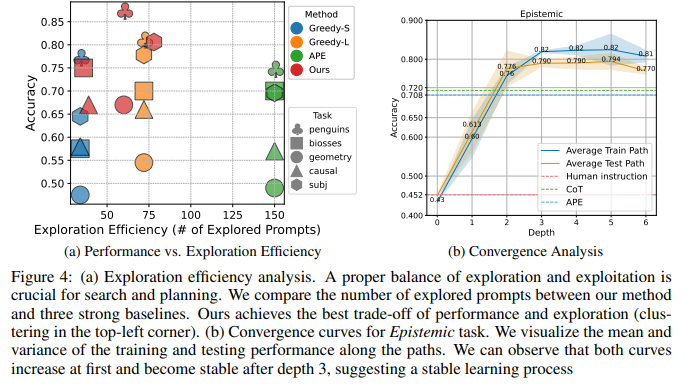
目的:比较PromptAgent与基线方法的探索效率(即搜索空间大小)与性能的关系
涉及图表:图4(a)
实验细节概述: 选取5个任务,比较PromptAgent与Greedy搜索(两个变体)和APE在探索的prompts数量和任务性能上的差异。
结果:
-
PromptAgent的点聚集在左上角,即以更少的探索实现了更高的性能,展现了探索效率的优势
-
Greedy搜索增加探索数量可提升性能,但探索成本更高,且仍不及PromptAgent
-
APE缺乏原则性指导,即使大规模探索也难以有效提升性能
3.3.5 实验五、收敛性分析
目的:研究PromptAgent在搜索树不同深度上reward的变化,分析其学习动态
涉及图表:图4(b)
实验细节概述: 以Epistemic任务为例,分析PromptAgent在不同深度上训练和测试性能的演变。
结果:
-
训练和测试曲线最初都呈上升趋势,在深度3之后趋于稳定,超过了所有基线方法
-
其他任务和超参设置下也观察到类似的上升和收敛模式,表明PromptAgent具有稳健的学习动态,可迭代优化和提升expert prompts
3.3.6 实验六、PromptAgent优化prompts的定性分析

目的:定性分析PromptAgent生成的expert-level prompts的质量
涉及图表:图5,表15
实验细节概述: 以NCBI任务为例,检查PromptAgent搜索轨迹中最优路径的前4个状态和对应的3个状态转移。不同颜色突出了相似的领域见解。
结果:
-
从人工prompt出发,PromptAgent发现多个深刻的错误反馈(action),并有效地将其合并为改进的prompt(state),提高了测试性能
-
在连续的转移中,疾病实体的定义越来越精确,无缝整合了特定于生物医学的细节
-
最后一个状态s3集合了之前路径的见解,表现为expert-level prompt,带来卓越的性能提升
-
与人工prompts和APE prompts相比,PromptAgent prompts在任务指令、术语澄清、解决方案指导、异常处理等方面提供了更全面的内容,展现了expert prompts应对复杂任务理解的优势
4 总结后记
本论文针对构建专家级提示优化系统的问题,提出了一种名为PromptAgent的策略规划方法。通过将提示优化视作一个基于MCTS的策略规划问题,结合LLM的反思能力生成错误反馈指导搜索,PromptAgent能够高效探索庞大的提示空间,自主生成富含领域知识和详尽指令的专家级提示。在BIG-Bench Hard、生物医学和通用NLP任务上的实验表明,PromptAgent生成的提示显著优于人工提示和最新的提示优化基线,展现出其在提升LLM理解和推理能力上的巨大潜力。
疑惑和想法:
-
除了MCTS,是否可以尝试其他形式的策略规划算法,如Alpha-Beta剪枝、启发式搜索等?它们在提示优化上的表现如何?
-
PromptAgent生成反馈时主要依赖于先验的元提示,能否设计一种自适应或递进式的元提示生成机制,随着搜索的进行动态更新元提示?
-
在面向新领域任务时,如何高效地为PromptAgent引入该领域的专家知识,加速strategizing过程?是否可以利用知识图谱等外部知识源?
可借鉴的方法点:
-
将提示工程建模为序贯决策问题,利用强化学习和策略规划优化提示的思路可以推广到更多LLM应用场景。
-
利用LLM的反思和自我纠错能力生成反馈信息指导优化的方法可以借鉴到其他NLP任务,如对话、问答、校对等。
-
在搜索过程中权衡exploration和exploitation的策略对于避免局部最优、发现更优解具有重要启发意义。