Ceph是一种可靠的、可扩展的、统一的、分布式的存储系统。Ceph高度可靠、易于管理且免费。Ceph提供了非凡的可扩展性------数以千计的客户端访问PB到EB的数据。Ceph存储集群相互通信以动态复制和重新分配数据。目前众多云厂商都在使用Ceph,应用广泛。如:华为、阿里、腾讯等等。目前火热的云技术OpenStack、Kubernetes都支持后端整合Ceph,从而提高数据的可用性、扩展性、容错等能力。
本案例主要介绍使用3台云主机搭建Ceph分布式集群存储系统和使用Ceph分布式集群存储系统。
1. 规划节点
表1 规划节点
| IP地址 | 主机名 | 节点 |
|---|---|---|
| 192.168.169.3 | ceph-node1 | Monitor/OSD |
| 192.168.169.4 | ceph-node2 | OSD |
| 192.168.169.5 | ceph-node3 | OSD |
2. 基础准备
在OpenStack平台中,使用提供的CentOS7.9镜像创建3个云主机,flavor使用2vCPU/4G/40G硬盘+临时磁盘20G类型。创建完成后,修改三个节点的主机名为ceph-node1、ceph-node2和ceph-node3,命令如下:
shell
[root@ceph-node1 ~]# hostnamectl set-hostname ceph-node1
[root@ceph-node1 ~]# hostnamectl
Static hostname: ceph-node1
Icon name: computer-vm
Chassis: vm
Machine ID: cc2c86fe566741e6a2ff6d399c5d5daa
Boot ID: 677af9a2cd3046b7958bbb268342ad69
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.el7.x86_64
Architecture: x86-64这3台虚拟机各需要有20 GB的空闲硬盘。可以使用lsblk命令进行验证。
shell
[root@ceph-node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 40G 0 disk
└─vda1 253:1 0 40G 0 part /
vdb 253:16 0 20G 0 disk修改3台虚拟机的/etc/hosts文件,修改主机名地址映射关系。
shell
192.168.169.3 ceph-node1
192.168.169.4 ceph-node2
192.168.169.5 ceph-node3在所有Ceph节点上修改Yum源,均使用本地源。(软件包使用提供的ceph-14.2.22.tar.gz)
三个节点下载ceph-14.2.22.tar.gz软件包至/root目录下,并解压缩到/opt目录下,命令如下:(三个节点都要执行)
shell
[root@ceph-node1 ~]# curl -O http://mirrors.douxuedu.com/competition/ceph-14.2.22.tar.gz
[root@ceph-node1 ~]# tar -zxvf ceph-14.2.22.tar.gz -C /opt解压完成,然后配置repo文件,首先将/etc/yum.repos.d下面的所有repo文件移走,并创建local.repo文件,命令如下:(三个节点都要执行)
shell
[root@ceph-node1 ~]# mv /etc/yum.repos.d/* /media/
[root@ceph-node1 ~]# vi /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=file:///opt/ceph
gpgcheck=0
enabled=1
[centos]
name=centps
baseurl=file:///opt/centos
gpgcheck=0
enabled=1
[iaas]
name=iaas
baseurl=file:///opt/iaas/iaas-repo
gpgcheck=0
enabled=1要部署Ceph集群,需要使用ceph-deploy工具在3台虚拟机上安装和配置Ceph。ceph-deploy是Ceph软件定义存储系统的一部分,用来方便地配置和管理Ceph存储集群。
1. 创建Ceph集群
首先,在ceph-node1上安装Ceph,并配置它为Ceph monitor和OSD节点。
(1)在ceph-node1上安装ceph-deploy。
shell
[root@ceph-node1 ~]# yum install ceph-deploy -y python-setuptools(2)通过在cep-node1上执行以下命令,用ceph-deploy创建一个Ceph集群。
shell
[root@ceph-node1 ~]# mkdir /etc/ceph
[root@ceph-node1 ~]# cd /etc/ceph
[root@ceph-node1 ceph]# ceph-deploy new ceph-node1(3)ceph-deploy的new子命令能够部署一个默认名称为Ceph的新集群,并且它能生成集群配置文件和密钥文件。列出当前的工作目录,可以查看到ceph.conf和ceph.mon.keying文件。
shell
[root@ceph-node1 ceph]# ll
total 12
-rw-r--r-- 1 root root 229 Sep 20 16:20 ceph.conf
-rw-r--r-- 1 root root 2960 Sep 20 16:20 ceph-deploy-ceph.log
-rw------- 1 root root 73 Sep 20 16:20 ceph.mon.keyring(4)在ceph-node1上执行以下命令,使用ceph-deploy工具在所有节点上安装Ceph二进制软件包。命令如下:(注意需要加上--no-adjust-repos参数,不然系统会默认去安装epel-release源,此处全使用本地安装)
shell
[root@ceph-node1 ceph]# ceph-deploy install ceph-node1 ceph-node2 ceph-node3 --no-adjust-repos
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
...
...
[ceph-node3][INFO ] Running command: ceph --version
[ceph-node3][DEBUG ] ceph version 14.2.22 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)(5)ceph-deploy工具包首先会安装Ceph组件所有的依赖包。命令成功完成后,检查所有节点上Ceph的版本信息。
shell
[root@ceph-node1 ceph]# ceph -v
ceph version 14.2.22 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)
[root@ceph-node2 ~]# ceph -v
ceph version 14.2.22 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)
[root@ceph-node3 ~]# ceph -v
ceph version 14.2.22 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)(6)在ceph-node1上创建第一个Ceph monitor。
ceph-deploy mon create-initial 命令用于在初始阶段创建 Ceph Monitor(监视器)节点。这个命令会在一个或多个指定的主机上创建并初始化 Ceph Monitor
shell
[root@ceph-node1 ceph]# ceph-deploy mon create-initial
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
...
...
[ceph_deploy.gatherkeys][DEBUG ] Got ceph.bootstrap-rgw.keyring key from ceph-node1.(7)Monitor创建成功后,检查集群的状态,这个时候Ceph集群并不处于健康状态。
shell
[root@ceph-node1 ceph]# ceph -s
cluster:
id: e901edda-49e8-4910-a5de-b860da4811c2
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum ceph-node1 (age 47s)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 复制密钥
shell
[root@ceph-node1 ceph]# ceph-deploy admin ceph-node{1,2,3}2. 创建OSD
(1)列出ceph-node1上所有的可用磁盘。
shell
[root@ceph-node1 ceph]# ceph-deploy disk list ceph-node1
... ...
[ceph-node1][INFO ] Disk /dev/vda: 53.7 GB, 53687091200 bytes, 104857600 sectors
[ceph-node1][INFO ] Disk /dev/vdb: 21.5 GB, 21474836480 bytes, 41943040 sectors(2) 创建共享磁盘,3个节点都要执行。对系统上的空闲硬盘进行分区操作。
先umount磁盘,在使用fdisk工具分区。
(3)分区完毕后,使用命令将这些分区添加至osd,命令如下:
ceph-node{1,2,3}都需要进行分区
ceph-node1节点:
OSD (Object Storage Daemon)对象存储
shell
[root@ceph-node1 ceph]# ceph-deploy osd create --data /dev/vdb1 ceph-node1
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create --data /dev/vdb1 ceph-node1
... ...
[ceph-node1][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host ceph-node1 is now ready for osd use.ceph-node2节点:
shell
[root@ceph-node1 ceph]# ceph-deploy osd create --data /dev/vdb1 ceph-node2
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create --data /dev/vdb1 ceph-node2
... ...
[ceph-node2][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host ceph-node2 is now ready for osd use.ceph-node3节点:
shell
[root@ceph-node1 ceph]# ceph-deploy osd create --data /dev/vdb1 ceph-node3
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create --data /dev/vdb1 ceph-node3
... ...
[ceph-node3][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host ceph-node3 is now ready for osd use.(4)添加完osd节点后,查看集群的状态,命令如下:
shell
[root@ceph-node1 ceph]# ceph -s
cluster:
id: 09226a46-f96d-4bfa-b20b-9021898ddf53
health: HEALTH_WARN
no active mgr
services:
mon: 1 daemons, quorum ceph-node1
mgr: no daemons active
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs: 可以看到此时的状态为警告,因为还没有设置mgr节点,安装mgr,命令如下:
ceph-deploy 命令是用于部署和管理 Ceph 集群的工具。在您的命令中,您使用 ceph-deploy mgr create 命令来创建 Ceph 管理器(Manager)ceph-deploy 将在指定的主机上创建一个 Manager 节点,并将其添加到 Ceph 集群中。Manager 节点将负责集群管理任务,例如监控、维护和提供 RESTful API 服务
shell
[root@ceph-node1 ceph]# ceph-deploy mgr create ceph-node1 ceph-node2 ceph-node3
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy mgr create ceph-node1 ceph-node2 ceph-node3
... ...
[ceph-node3][INFO ] Running command: systemctl start ceph-mgr@ceph-node3
[ceph-node3][INFO ] Running command: systemctl enable ceph.target(5)检查Ceph集群的状态。此时仍然是warn的状态,需要禁用不安全模式命令如下:
shell
[root@ceph-node1 ceph]# ceph -s
cluster:
id: e901edda-49e8-4910-a5de-b860da4811c2
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum ceph-node1 (age 6m)
mgr: ceph-node1(active, since 27s), standbys: ceph-node2, ceph-node3
osd: 3 osds: 3 up (since 47s), 3 in (since 47s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 使用如下命令禁用不安全模式:
shell
[root@ceph-node1 ceph]# ceph config set mon auth_allow_insecure_global_id_reclaim false再次查看集群状态,集群是HEALTH_OK状态。
shell
[root@ceph-node1 ceph]# ceph -s
cluster:
id: e901edda-49e8-4910-a5de-b860da4811c2
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-node1 (age 9m)
mgr: ceph-node1(active, since 3m), standbys: ceph-node2, ceph-node3
osd: 3 osds: 3 up (since 3m), 3 in (since 3m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: (6)开放权限给其他节点,进行灾备处理。
shell
# ceph-deploy admin ceph-node{1,2,3}
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.31): /usr/bin/ceph-deploy admin ceph-node1 ceph-node2 ceph-node3
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to ceph-node1
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to ceph-node2
[ceph-node2][DEBUG ] connected to host: ceph-node2
[ceph-node2][DEBUG ] detect platform information from remote host
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to ceph-node3
[ceph-node3][DEBUG ] connected to host: ceph-node3
[ceph-node3][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
# chmod +r /etc/ceph/ceph.client.admin.keyring
shell
[root@ceph-node1 ~]# ceph health
HEALTH_OK3. Ceph集群运维命令
有了可运行的Ceph集群后,现在可以用一些简单的命令来体验Ceph。
(1)检查Ceph的安装状态。
shell
# ceph status(2)观察集群的健康状况。
shell
# ceph w(3)检查Ceph monitor仲裁状态。
shell
# ceph quorum_status --format json-pretty(4)导出Ceph monitor信息。
shell
# ceph mon dump(5) 检查集群使用状态。
shell
# ceph df(6) 检查Ceph Monitor、OSD和PG(配置组)状态。
shell
# ceph mon stat
# ceph osd stat
# ceph pg stat(7)列表PG。
shell
# ceph pg dump(8)列表Ceph存储池。
shell
# ceph osd lspools(9)检查OSD的CRUSH。
shell
# ceph osd treeceph 删除osd
1、删除osd
查看osd
shell
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01959 root default
-3 0.00980 host ceph-node1
0 hdd 0.00490 osd.0 up 1.00000 1.00000
1 hdd 0.00490 osd.1 up 1.00000 1.00000
-5 0.00490 host ceph-node2
2 hdd 0.00490 osd.2 up 1.00000 1.00000
-7 0.00490 host ceph-node3
3 hdd 0.00490 osd.3 up 1.00000 1.000002、停止此osd进程,执行,我的因为坏盘原因已经停止
shell
[root@ceph-node1 ceph]# systemctl stop ceph-osd@1
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01959 root default
-3 0.00980 host ceph-node1
0 hdd 0.00490 osd.0 up 1.00000 1.00000
1 hdd 0.00490 osd.1 down 1.00000 1.00000
-5 0.00490 host ceph-node2
2 hdd 0.00490 osd.2 up 1.00000 1.00000
-7 0.00490 host ceph-node3
3 hdd 0.00490 osd.3 up 1.00000 1.000003、下线 osd 执行
shell
[root@ceph-node1 ceph]# ceph osd out 1
marked out osd.1.
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01959 root default
-3 0.00980 host ceph-node1
0 hdd 0.00490 osd.0 up 1.00000 1.00000
1 hdd 0.00490 osd.1 down 0 1.00000
-5 0.00490 host ceph-node2
2 hdd 0.00490 osd.2 up 1.00000 1.00000
-7 0.00490 host ceph-node3
3 hdd 0.00490 osd.3 up 1.00000 1.000004、将osd.0踢出集群,执行:ceph osd crush remove osd.1 ,此时osd.1已经不再osd tree中了
格式化
shell
[root@ceph-node1 ceph]# ceph osd crush remove osd.1
removed item id 1 name 'osd.1' from crush map
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01469 root default
-3 0.00490 host ceph-node1
0 hdd 0.00490 osd.0 up 1.00000 1.00000
-5 0.00490 host ceph-node2
2 hdd 0.00490 osd.2 up 1.00000 1.00000
-7 0.00490 host ceph-node3
3 hdd 0.00490 osd.3 up 1.00000 1.00000
1 0 osd.1 down 0 1.000005、执行ceph auth del osd.0 和 ceph osd rm 0,此时删除成功但是原来的数据和日志目录还在,也就是数据还在
shell
[root@ceph-node1 ceph]# ceph auth del osd.1
updated
[root@ceph-node1 ceph]# ceph osd rm 1
removed osd.1
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01469 root default
-3 0.00490 host ceph-node1
0 hdd 0.00490 osd.0 up 1.00000 1.00000
-5 0.00490 host ceph-node2
2 hdd 0.00490 osd.2 up 1.00000 1.00000
-7 0.00490 host ceph-node3
3 hdd 0.00490 osd.3 up 1.00000 1.000006、此时我们将/dev/sdc磁盘umount,然后将磁盘进行擦除那么数据就会被完全删除了,然后执行
shell
[root@ceph-node1 ceph]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 12M 2.0G 1% /run
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 2.3G 15G 14% /
/dev/sda1 1014M 138M 877M 14% /boot
tmpfs 394M 0 394M 0% /run/user/0
tmpfs 2.0G 52K 2.0G 1% /var/lib/ceph/osd/ceph-0
tmpfs 2.0G 52K 2.0G 1% /var/lib/ceph/osd/ceph-1
[root@ceph-node1 ceph]# umount /var/lib/ceph/osd/ceph-1
[root@ceph-node1 ceph]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 12M 2.0G 1% /run
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 2.3G 15G 14% /
/dev/sda1 1014M 138M 877M 14% /boot
tmpfs 394M 0 394M 0% /run/user/0
tmpfs 2.0G 52K 2.0G 1% /var/lib/ceph/osd/ceph-0
shell
[root@ceph-node1 ceph]# dmsetup remove_all
dmsetup remove_all:该命令用于移除所有的设备映射(Device Mapper mappings)。Device Mapper 是 Linux 内核中的一个子系统,用于进行逻辑卷管理和设备映射。执行 dmsetup remove_all 将移除所有当前活动的设备映射,包括与 Ceph 相关的映射。7、格式化
shell
[root@ceph-node1 ceph]# sudo mkfs -t ext4 /dev/sdb3(10)列表集群的认证密钥。
shell
# ceph auth listceph-dashboard界面安装:
三个节点都需要安装:
ceph-rpm-nautilus-el7-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
shell
[ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
priority=1
type=rpm-md
gpgkey=http://mirrors.163.com/ceph/keys/release.asc
[centos]
name=centos
baseurl=http://192.168.162.15/centos
gpgcheck=0
enabled=1
[iaas]
name=iaaas
baseurl=http://192.168.162.15/iaas/iaas-repo
gpgcheck=0
shell
### 安装依赖Dashboard
[root@ceph-node1 ceph]# yum install -y ceph-mgr-dashboard
### 启动Dashboard --force 强制开启
[root@ceph-node1 ceph]# ceph mgr module enable dashboard --force
### 创建证书并安装自签名的证书 https
[root@ceph-node1 ceph]# ceph dashboard create-self-signed-cert
Self-signed certificate created
### 创建登录密码
[root@ceph-node1 ceph]# echo 'gxl@ceph' > cephadmin-password
[root@ceph-node1 ceph]# cat cephadmin-password
gxl@ceph
### 创建用户
[root@ceph-node1 ceph]# ceph dashboard ac-user-create cephadmin -i cephadmin-password administrator
{"username": "cephadmin", "lastUpdate": 1699617115, "name": null, "roles": ["administrator"], "password": "$2b$12$sRwYqfNmS.FQ0SvyN/J6FOZn5j6GBrq3BJR6a.zxm7nJP72KUjgI.", "email": null}
- cephadmin `用户`
- -i `指定密码文件`
- cephadmin-password `密码文件`
- administrator `用户身份`
### 验证服务
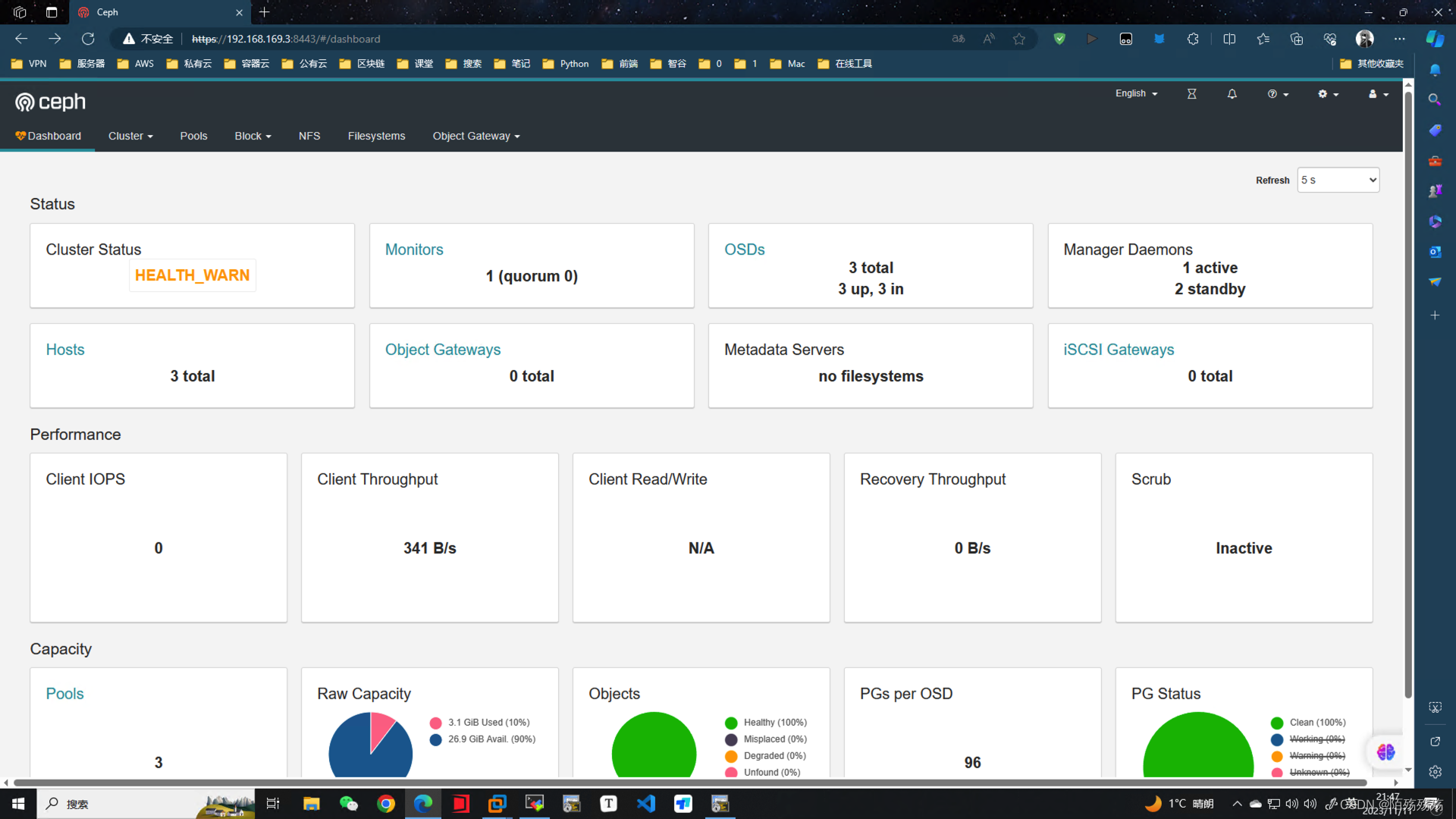
[root@ceph-node1 ceph]# ceph mgr services
{
"dashboard": "https://ceph-node1:8443/"
}
报错解决
shell
[root@ceph-node1 ceph]# ceph -s
cluster:
id: 3bc797b7-582f-48aa-8c9b-972cb4da1603
health: HEALTH_WARN
1 osds down
1 host (1 osds) down
services:
mon: 1 daemons, quorum ceph-node1 (age 5m)
mgr: ceph-node3(active, since 73s), standbys: ceph-node1, ceph-node2
osd: 3 osds: 2 up (since 2m), 3 in (since 10m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.02939 root default
-3 0.00980 host ceph-node1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
-5 0.00980 host ceph-node2
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host ceph-node3
2 hdd 0.00980 osd.2 down 1.00000 1.00000
[root@ceph-node1 ceph]# ceph osd out 2
marked out osd.2.
[root@ceph-node1 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.02939 root default
-3 0.00980 host ceph-node1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
-5 0.00980 host ceph-node2
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host ceph-node3
2 hdd 0.00980 osd.2 down 0 1.00000
[root@ceph-node1 ceph]# ceph osd in 2
marked in osd.2.
[root@ceph-node3 ~]# systemctl enable ceph-osd@2 --now
[root@ceph-node3 ~]# systemctl status ceph-osd@2
● ceph-osd@2.service - Ceph object storage daemon osd.2
Loaded: loaded (/usr/lib/systemd/system/ceph-osd@.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2023-11-11 18:54:58 CST; 1s ago
Process: 1983 ExecStartPre=/usr/lib/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id %i (code=exited, status=0/SUCCESS)
Main PID: 1988 (ceph-osd)
CGroup: /system.slice/system-ceph\x2dosd.slice/ceph-osd@2.service
└─1988 /usr/bin/ceph-osd -f --cluster ceph --id 2 --setuser ceph --setgroup ceph