目录
[一. 更复杂的新增](#一. 更复杂的新增)
[二. 查询](#二. 查询)
[2.1 聚合查询](#2.1 聚合查询)
[2.1.2 分组查询 group by 子句](#2.1.2 分组查询 group by 子句)
[2.1.3 HAVING](#2.1.3 HAVING)
[2.2 联合查询/多表查询](#2.2 联合查询/多表查询)
[2.2.1 内连接](#2.2.1 内连接)
[2.2.2 外连接](#2.2.2 外连接)
[2.2.3 全外连接](#2.2.3 全外连接)
[2.2.4 自连接](#2.2.4 自连接)
[2.2.5 子查询](#2.2.5 子查询)
[2.2.6 合并查询](#2.2.6 合并查询)
一. 更复杂的新增
将从表名查询到的结果插入到表名2中
insert into 表名2 select .. from 表名1 ...;
创建一个学生表:

创建一个学生表2, 将学生表中的数据加到学生表2中:
 注意: 列的类型可以匹配即可插入, 列名和列的类型不一定要完全一致
注意: 列的类型可以匹配即可插入, 列名和列的类型不一定要完全一致
二. 查询
2.1 聚合查询
前面谈到的"表达式查询", 是针对列和列之间的运算, 聚合查询, 就是针对行和行之间的运算
对于行之间的运算, sql中提供了"聚合函数" 来完成这里的运算, 相当于是"库函数"
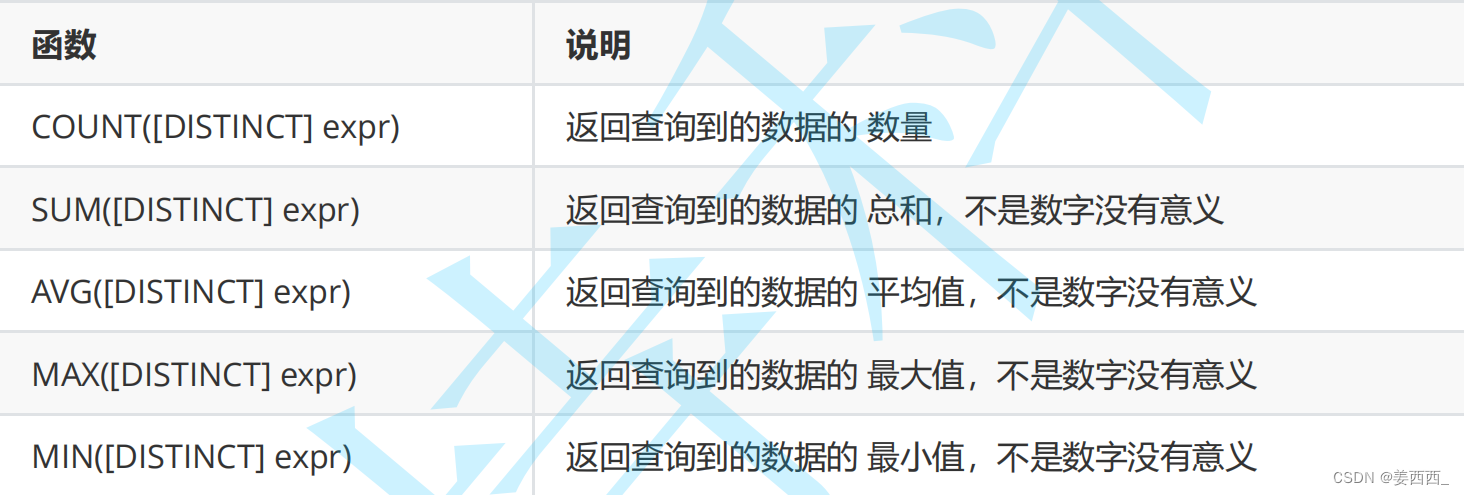
COUNT
存在这样的表:
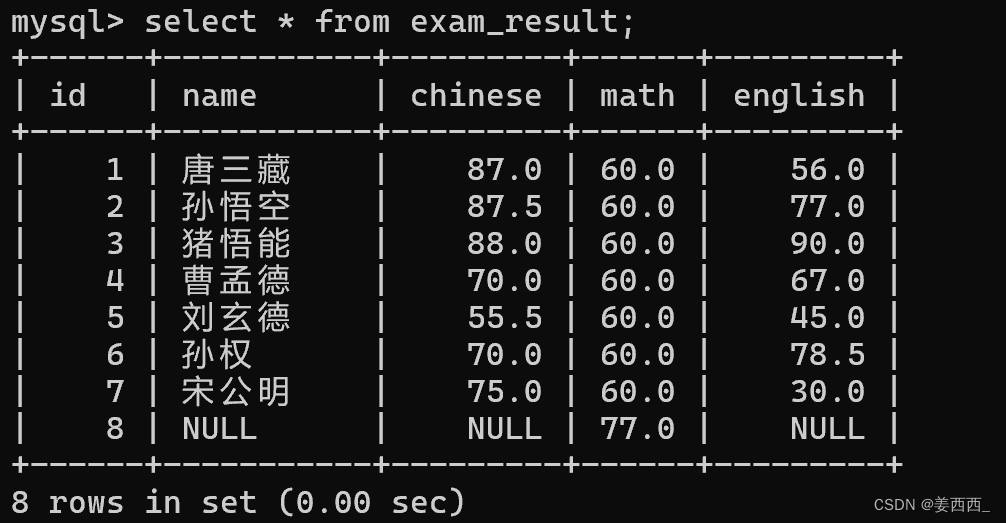

此时, 得到了表的全部行的数量
当前这个写法, 就相当于先执行了select * from exam_result, 再对结果进行count聚合
如果写具体的列, 就是针对这一列的结果进行聚合:
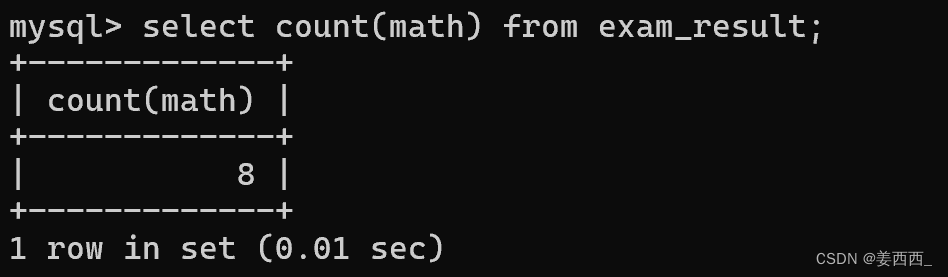
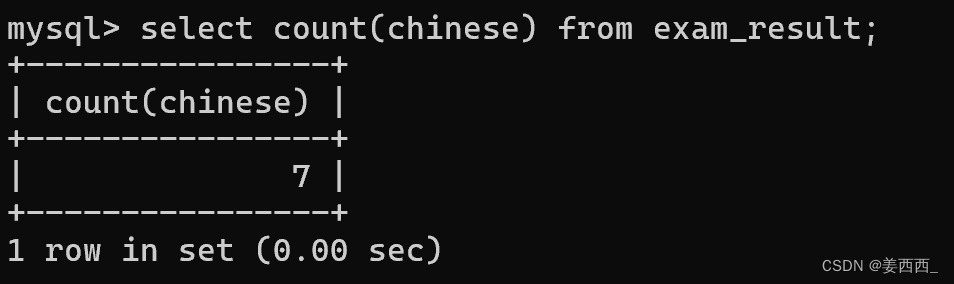 发现结果不同, 因为chinese有个空行
发现结果不同, 因为chinese有个空行
结论: 针对某一列进行聚合的时候, 只关注这一列有多少非NULL的结果 而针对*进行聚合时, 则不再是否非NULL, 全部都记录
如果在count和( )之间加个空格, 就会报错
SQL语言大部分情况下对于空格和换行都是很有好的, 但是聚合函数的函数名和括号之间, 不能有空格

SUM

相当于先执行了select chinese from exam_result, 再对结果进行sum聚合
括号中写表达式也可以:
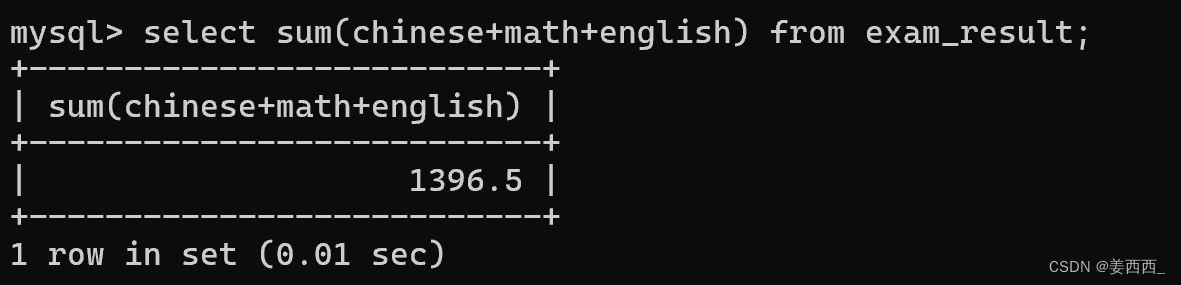
相当于先执行了select chinese+math+english from exam_result, 再对结果进行sum聚合
也可以进行带有别名:

但不能把别名写在括号中:

能用sum(*) 吗?
显然不可以
聚合函数中count(*) 其实是一种特殊情况, 只是单纯的统计行数
sum和其他的聚合函数, 涉及到相加或其他计算, 语义上没有明确定义, 不能用sum(*)
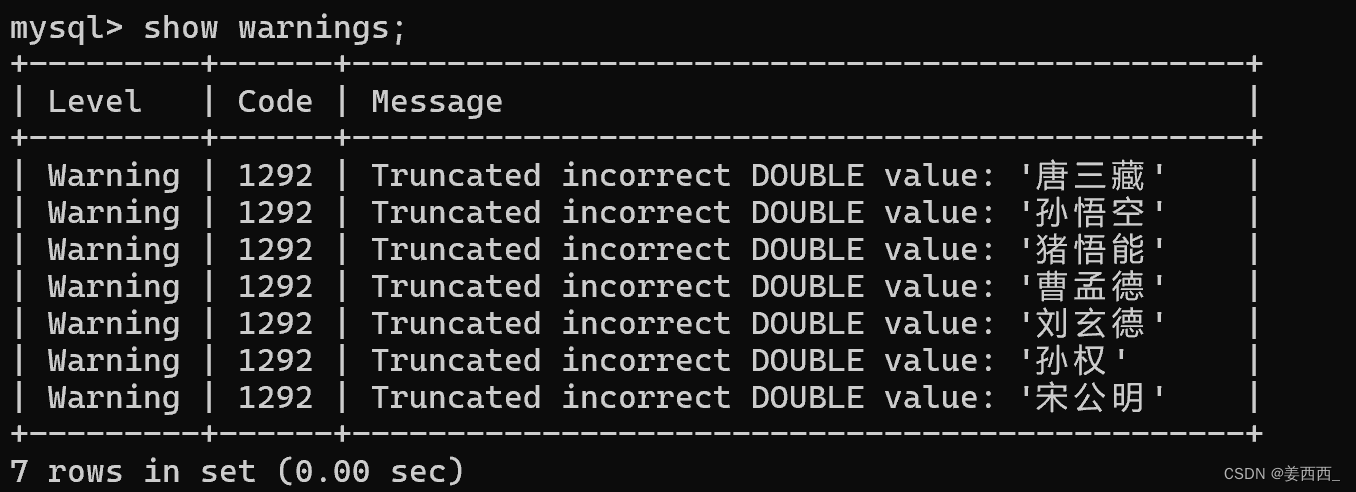
针对非数值的列, 进行加和, 虽然不会报错, 但是结果是不正确的, 会报警告:
使用show warnings; 可以查看警告
数据库试图将name转换成double类型(因为SQL是弱类型语言), 但是失败了
但是如果虽然是varchar类型, 但是你赋值为'1''2''3', 那也是可以相加的, 因为可以进行类型转换


AVG

MAX

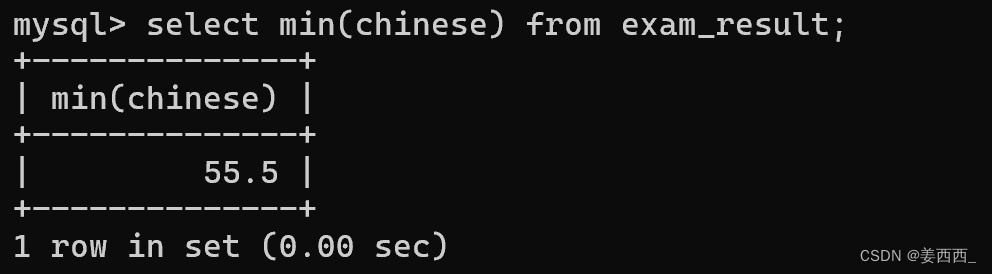
MIN
2.1.2 分组查询 group by 子句
指定某个列, 针对这个列, 把值相同的行, 分到同一个组中, 在针对每个组, 分别进行聚合查询
添加一个表:

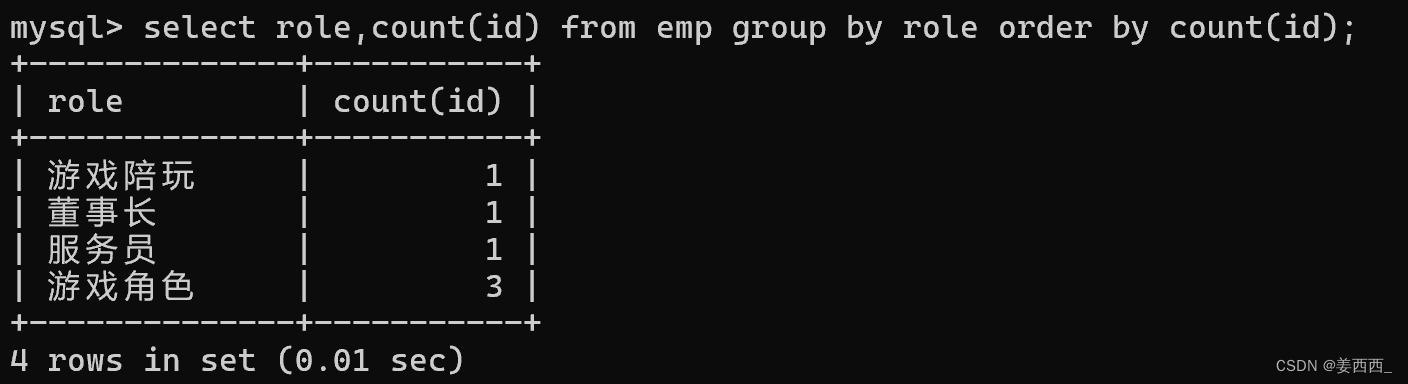
查询每个角色下有几个人:

执行顺序:
- 先执行 select role,id from emp
- 再根据group by role 设定, 按照role这一列的值, 针对上述查询结果, 进行分组
分成服务员一组, 游戏陪玩一组, 游戏角色一组, 董事长一组 - 针对上面的组, 分别执行count聚合操作
- 将上面的结果整理成临时表, 返回给客户端即可
最终结果的临时表, 这几个分组的顺序谁先谁后可不一定!!
可以针对聚合后的结果进行排序, 而不是干预每个分组中数据的先后顺序:
注意: 使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是"分组依据字段",即group by 后面的列, 其他字段若想出现在SELECT 中则必须包含在聚合函数中。
如果这么写:
每个显示的结果, 都是每个分组中的其中一条记录, 但是由于分组之后, 顺序是不确定的, 当前你这里显示的是哪行, 是不确定的, 存在一定的"随机性", 因此就没有意义

2.1.3 HAVING
给聚合查询指定条件:
- 聚合之前的条件
查询每个岗位的平均工资, 但是刨除"马云"

where写在group by 前面
- 聚合之后的条件
查询每个岗位的平均工资, 但刨除平均工资超过10000的数据
此时, 筛选聚合之后的条件, 就不能用where, 需要用having:

此时having放在group by 后面
当然, 一个sql中, 上述两种条件, 都可以存在:
计算每个岗位的平均工资, 刨除"马云", 也刨除平均工资超过10000的:

2.2 联合查询/多表查询
上面介绍的都是单表查询
想要学习多表查询, 我们先要了解一下"笛卡尔积"的概念
笛卡尔积, 就是得到了一个更大的表, 列数, 是原来两个表列数的和, 行数, 是原来两个表列数的积
在sql中, 我们很方便通过select 完成笛卡尔积:
先创建两个表student 和 class

笛卡尔积:

但是, 笛卡尔积是全排列的过程, 穷举出了所有的可能性, 自然就会产生以下不符合实际的情况的数据, 例如上述笛卡尔积中, classId只有一个, 只有相同的才是有效数据
那么我们可以加上条件:

这样写, 会产生二义性, 因为两个列名是相等的, 那么我们可以通过 表名. 列名的方式访问各自的列
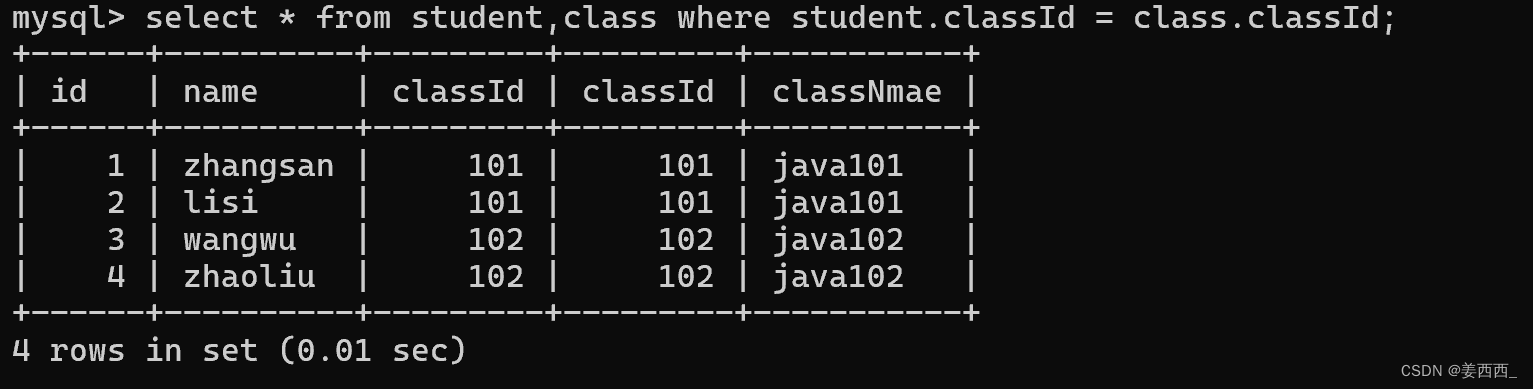
这个就是多表查询/联合查询的sql
像 where student.classId = class.classId 这种专门用来筛选出有效数据的条件, 也称为"连接条件" , 上述多表查询的操作, 也可以称为"连接操作".
创建四张表:

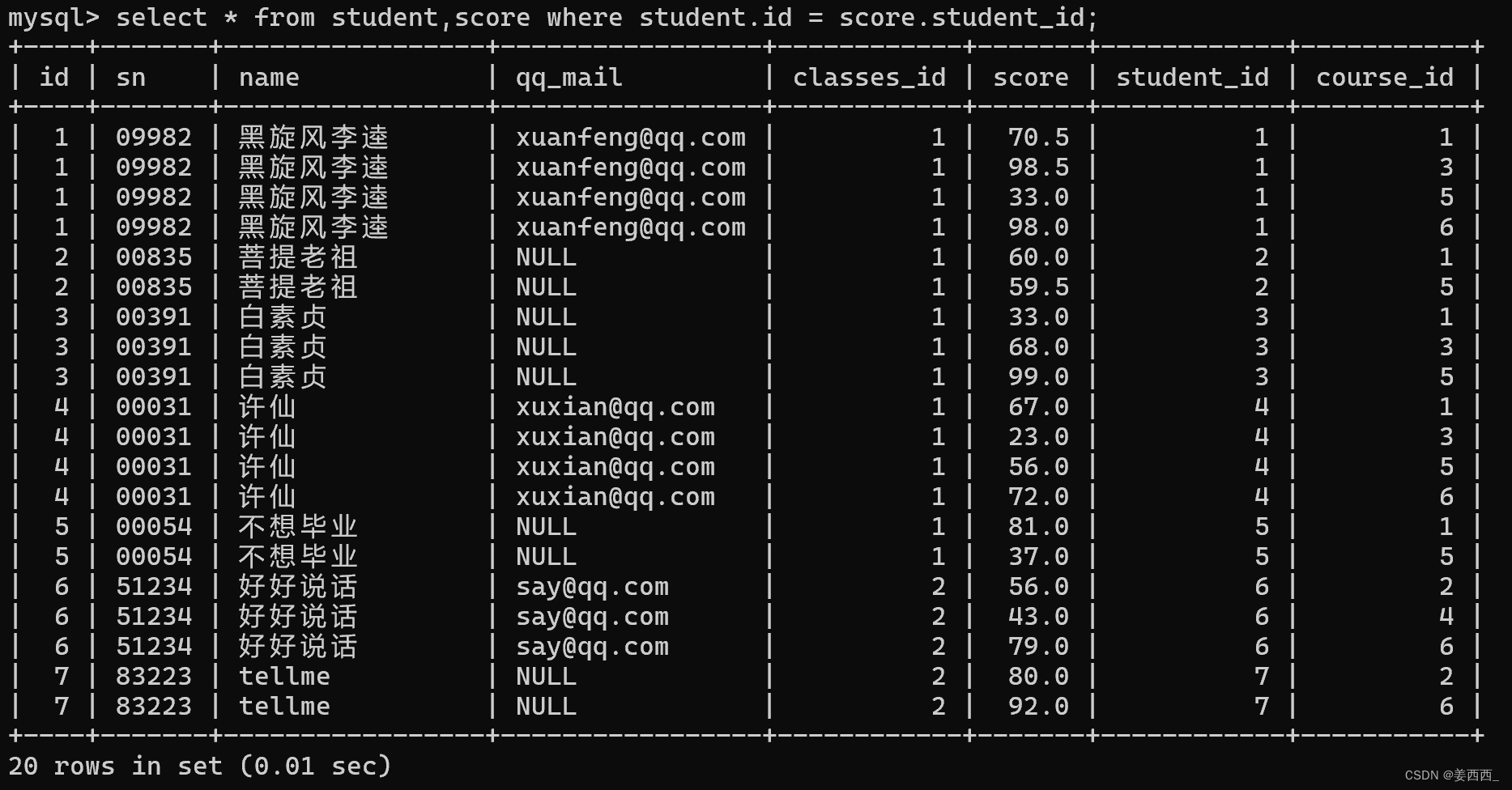
- 查询'许仙'同学的成绩
第一步: 先确定要查询的信息来自哪些表
许仙同学的名字在学生表中, 成绩在分数表中, 所以要针对学生表和分数表进行联合查询
第二步: 针对这两个表进行笛卡尔积
学生表是8条记录, 分数表是20条记录, 笛卡尔积应该有160条记录
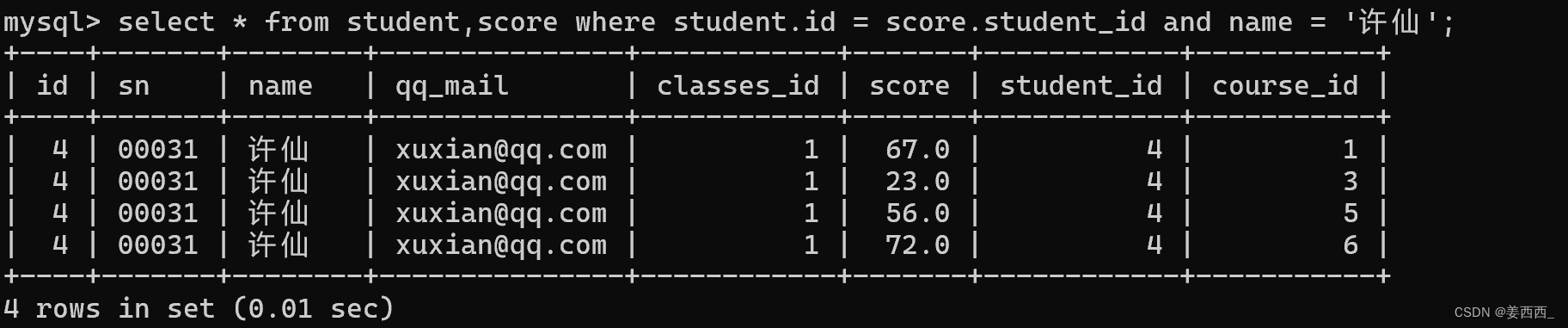
第三步: 加上连接条件, 去掉无效数据
第四步: 再根据题目, 补充其他的条件
第五步: 去掉不必要的列
因为题目要求只要许仙的成绩


- 使用join ... on 多表查询的另一种写法
第一步: 确认信息来自学生表和分数表
第二步: 笛卡尔积(用join实现笛卡尔积)
第三步: 指定连接条件(用on 代替where)
第四步: 补充其他条件
第五步: 保留必要列, 去掉其他列




- 查询所有同学的总成绩
第一步: 信息出自学生表 分数表
第二步: 学生表和分数表进行笛卡尔积
第三步: 指定连接条件
第四步: 添加其他条件, 此处需要添加聚合操作, 按照学生的姓名进行分组
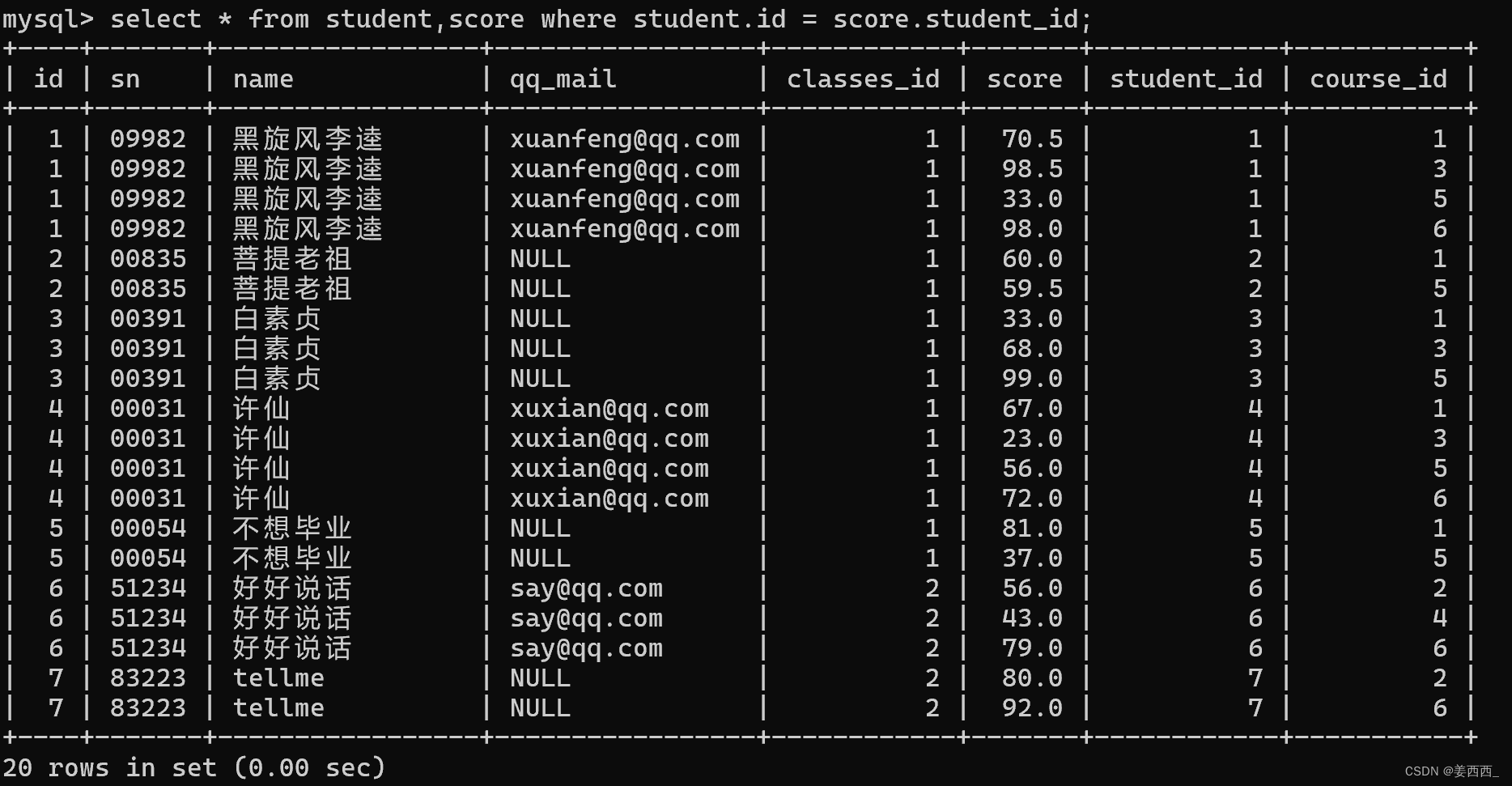

- 列出同学的成绩, 课程的名字, 课程的成绩
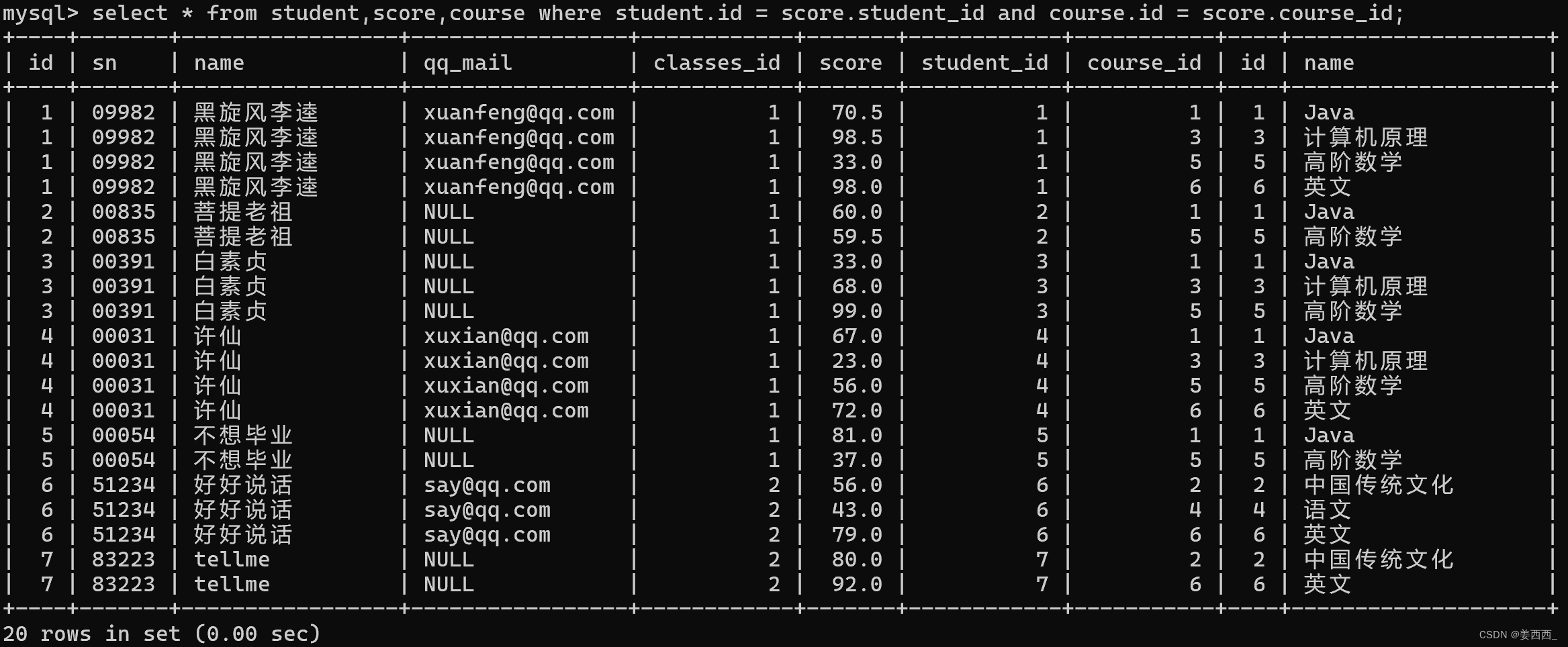
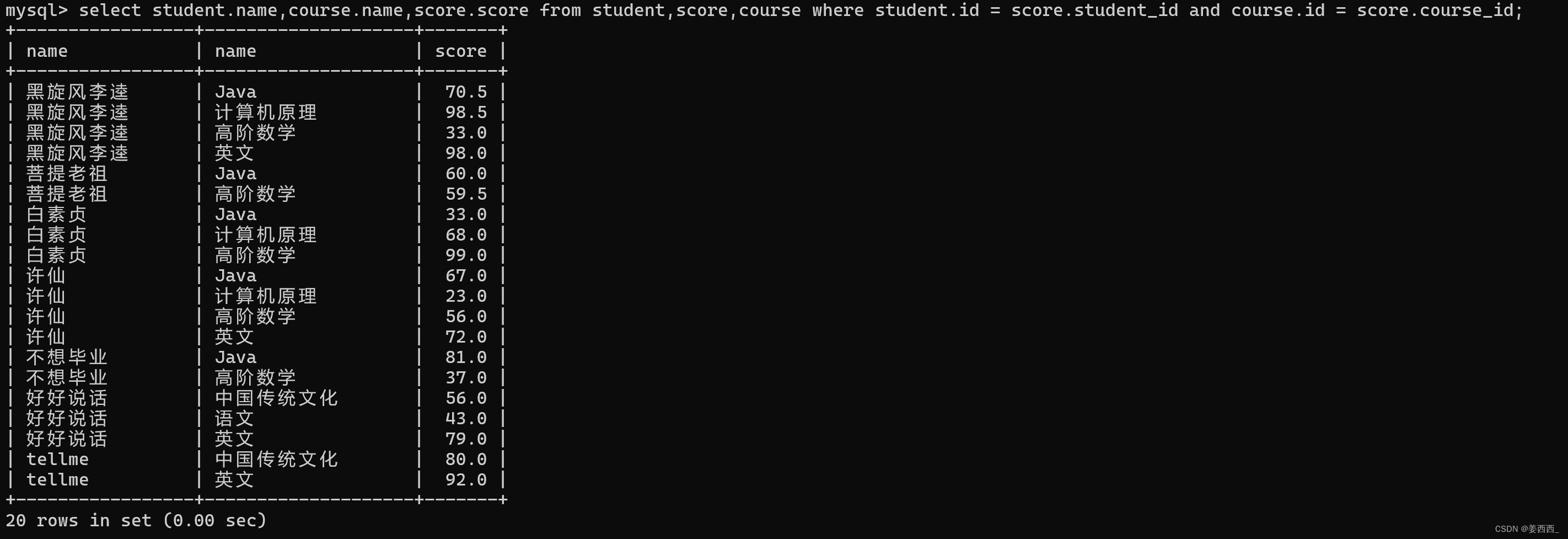
第一步: 信息来自三个表, 学生表, 课程表, 分数表
第二步: 笛卡尔积
第三步: 指定连接条件
第四步: 对列进行精简
针对多张表查询, 使用join on 可读性更好

2.2.1 内连接
上述我们所有的链接都是内连接
select * from 表1,表2 where 连接条件
select * from 表1 (inner) join 表2 on 连接条件
2.2.2 外连接
select * from 表1left/right join 表2 on 条件....;
注意: 只能使用join ..on.., 在join的前面加上left / right 关键字, 表示"左外连接" 和 "右外连接"
外连接和内连接一样, 也是基于笛卡尔积的方式来计算的, 但是对于空值/不存在的值, 处理方式是存在区别的
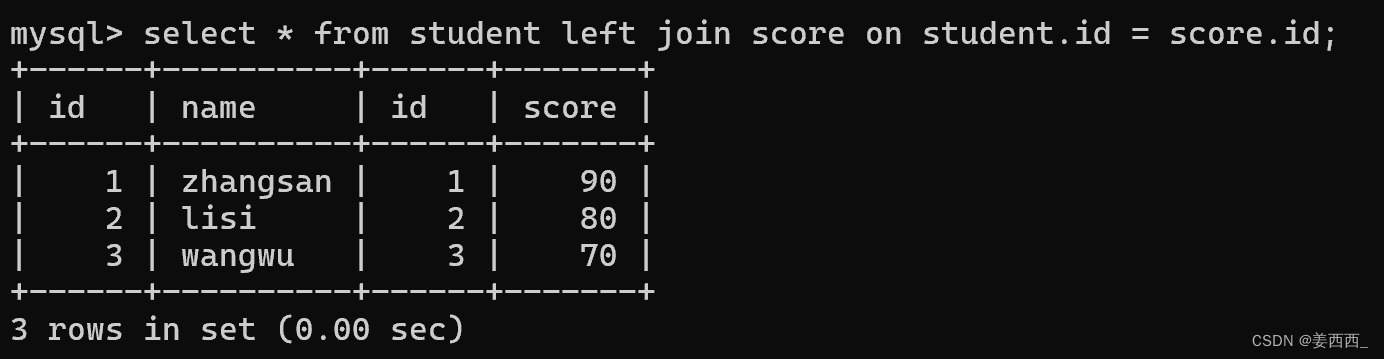
1)对于数据"一一对应"的情况
对于学生表和分数表,
任何一个学生数据, 都能在分数表中找到分数结果
任何一个分数结果, 也能在学生表中找到名字信息
此时, 进行内连接和外连接, 效果是一样的
简单创建两张表:

内连接:

外连接:
2)对于数据"非一一对应"的情况
如果我们对上述数据进行调整:

此时, wangwu的分数信息, 在分数表中不存在了
分数表中, id为4的信息, 在学生表中也不存在
内连接:

此时, 得到的结果, 是包含在两个表中都有的数据
左外连接:
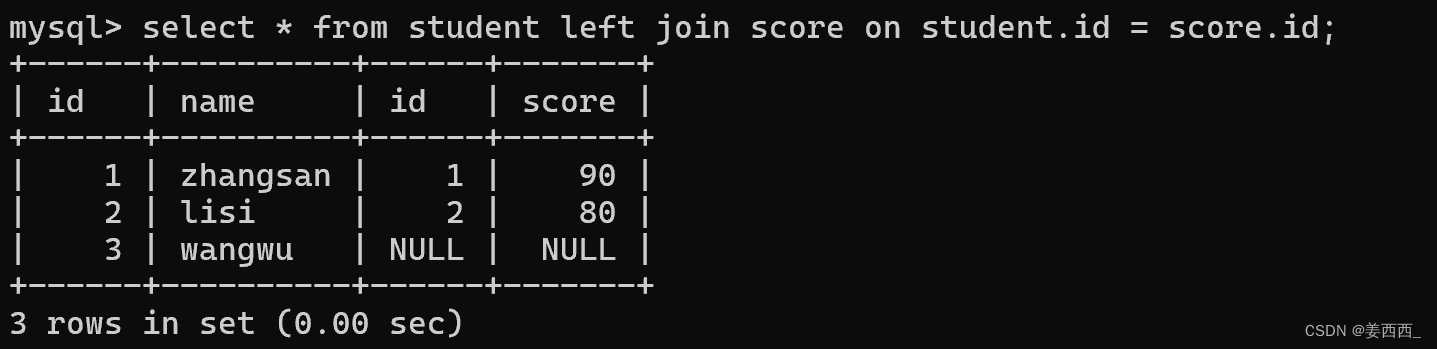
对于左外连接, 以左侧的表为基准, (写作student left join score, 此时student就是左侧表, score就是右侧表), 保证左侧表中的每一个数据, 都会存在, 左侧表数据在右侧表不存在的列, 会用null填充
右外连接:

右外连接与左外连接类似, 以右侧表为基准, 使右表中的每个数据都存在, 对应坐标中不存在的数据都用null填充
2.2.3 全外连接
结合左连接和右连接
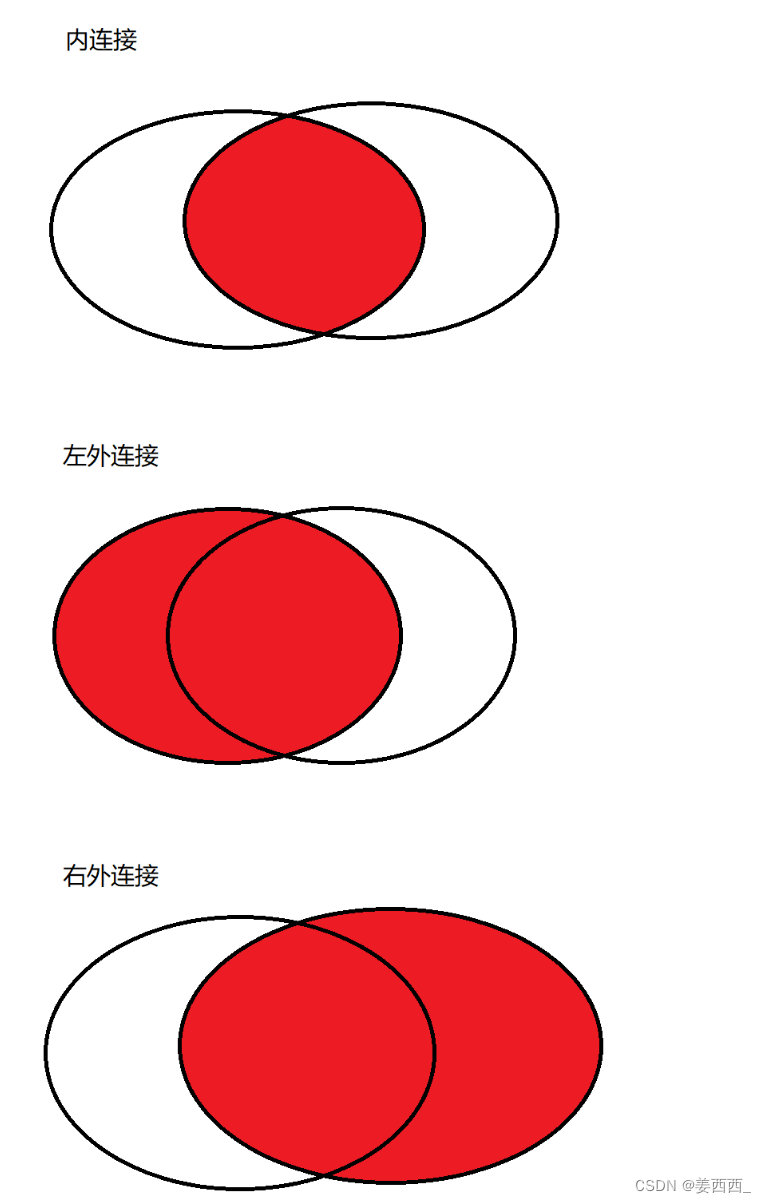
站在集合的角度看待上述几种链接:

2.2.4 自连接
同一个表, 自己和自己计算笛卡尔积
例:
还是使用上面的表

显示所有"计算机原理"成绩比"java"成绩高的成绩信息
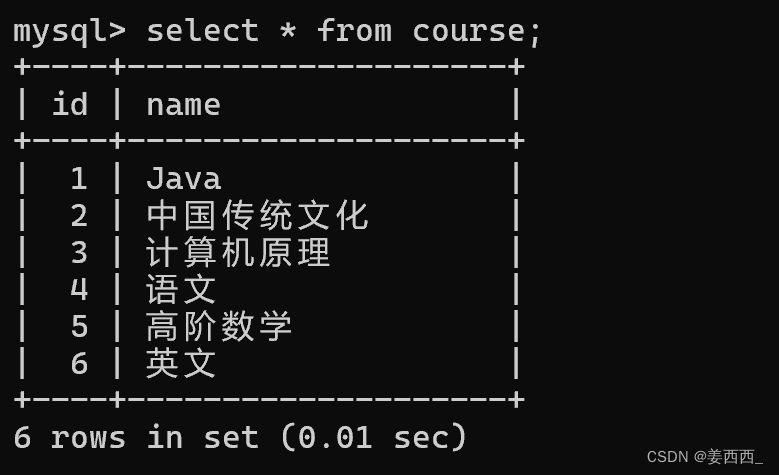
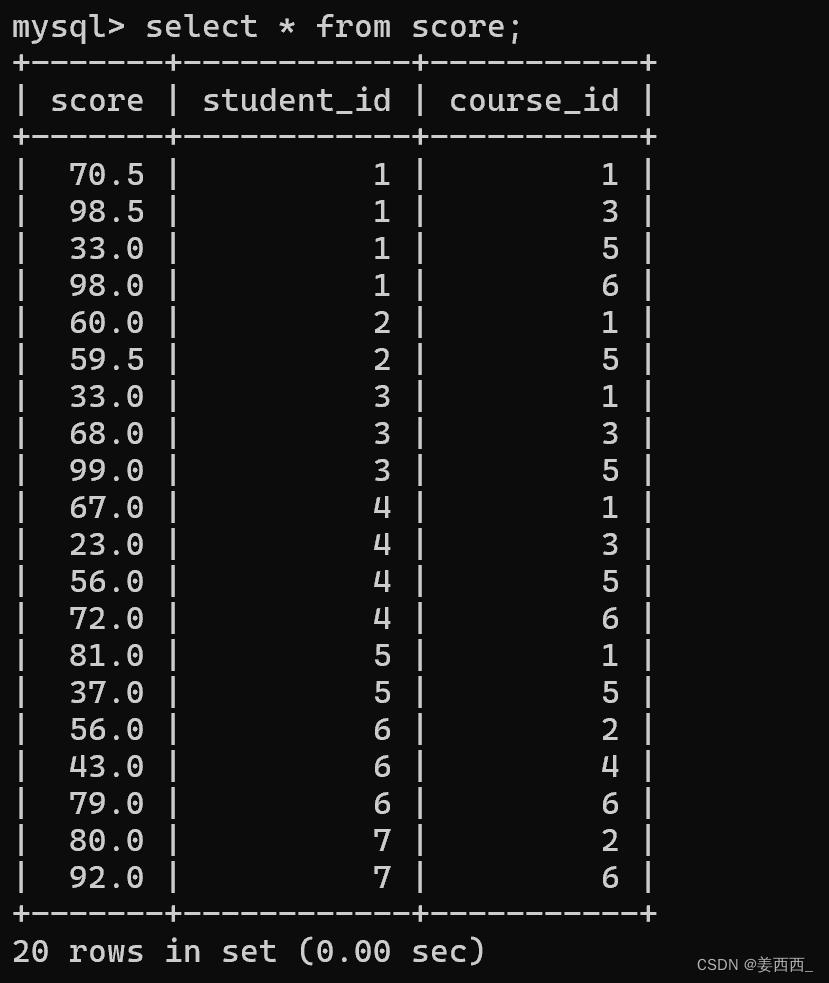
我们想要比较的是同一个学生的3号课程比1号课程成绩高的数据, 发现我们要比较的score在不同的行中, 之前我们进行的各种条件查询, 都是基于列和列之间的比较, 聚合函数时行和行之间的运算, 没法进行行和行之间的比较 , 这时我们就要想办法将行和行之间的关系, 转化成列和列之间的关系, 此时, 自连接就出现了
当我们直接进行自连接时, 发现会报错:

此时我们要给表起个别名:

继续添加条件:

2.2.5 子查询
把多个sql嵌套成了一个sql
- 单行子查询: 返回一行记录的查询
查询"不想毕业"同学的同班同学:
先知道"不想毕业"同学的班级, 再去找同班同学

子查询:

将得出的单条记录直接用sql语句代替
2)多行子查询: 返回多条记录的子查询 用in关键字
查询"语文"或"英文"课程的成绩信息:
先知道"语文"或"英文"的课程id, 再去找成绩:

子查询:

用in()来圈定范围
2.2.6 合并查询
把多个查询结果合并到一起, 使用union关键字
查询id<3,或者名字为"英文"的课程

另外, union允许从不同的表分别查询, 只要每个表查询的结果集合列的类型和列的个数匹配, 都能合并, 列的名字无所谓, 但是or只能针对一个表
union在合并是会自动去重, 如果不想要去重操作, 可以使用union all