目录
基本原理
- 多路并行dds,传统DDS的局限性在于输出频率有限。根据奈奎斯特采样定理,单路DDS的输出频率应小于系统时钟频率的一半。但是在很多地方,要使采样率保持一致,所以,为了提高采样率,可以采样多路并行dds技术,然后并转串输出,提高采样率。
这里假设使用4个dds产生4路并行的dds,其中,4路dds的可以分别表示为:
-

-
可以从上式中看出,4路dds的pinc(频率控制字)是一样,差别是在其相位差(poff)DDS0的poff是0;DDS1的poff是f o f s *1
 ;,DDS2的poff是f o f s*2
;,DDS2的poff是f o f s*2  ;DDS3的poff是f o f s*3
;DDS3的poff是f o f s*3 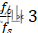 ;
;假如fs是100MHz,调用4个并行的dds,然后按照顺序将4路并行的dds拼接成一路(并转串),这样就相当于采样率是4*fs,即400MHz采样率下的数据
verilog代码
- 这里使用4路并行dds
assign dds_pinc = 32'd107374182; //fs 100m.f_out =10M 30bit ;26843545 //107374182
assign dds_poff = 32'd107374182*0; //fs 100m.f_out =10M 30bit ; 26843545
//
assign dds_pinc_1 = 32'd107374182; //fs 100m.f_out =10M 30bit ;
assign dds_poff_1 = 32'd107374182*1; //fs 100m.f_out =10M 30bit ; //26843545
//
assign dds_pinc_2 = 32'd107374182; //fs 100m.f_out =10M 30bit ;
assign dds_poff_2 = 32'd107374182*2; //fs 100m.f_out =10M 30bit ;
//
assign dds_pinc_3 = 32'd107374182; //fs 100m.f_out =10M 30bit ;
assign dds_poff_3 = 32'd107374182*3; //fs 100m.f_out =10M 30bit ;
assign dds_t_data = {dds_poff,dds_pinc};
assign dds_t_data_1 = {dds_poff_1,dds_pinc_1};
assign dds_t_data_2 = {dds_poff_2,dds_pinc_2};
assign dds_t_data_3 = {dds_poff_3,dds_pinc_3};
//
always@(posedge clk) begin
if(rst == 1'b1)begin
gen_valid <= 1'b0;
end else if(start == 1'b1)begin
gen_valid <= 1'b1;
end else begin
gen_valid <= gen_valid;
end
end
assign sin_0 = m_axis_data_tdata[31:16];
assign cos_0 = m_axis_data_tdata[15:0];
assign sin_1 = m_axis_data_tdata_1[31:16];
assign cos_1 = m_axis_data_tdata_1[15:0];
assign sin_2 = m_axis_data_tdata_2[31:16];
assign cos_2 = m_axis_data_tdata_2[15:0];
assign sin_3 = m_axis_data_tdata_3[31:16];
assign cos_3 = m_axis_data_tdata_3[15:0];
dds100m_0 dds100m_0_inst (
.aclk(clk), // input wire aclk
.s_axis_config_tvalid(gen_valid), // input wire s_axis_config_tvalid
.s_axis_config_tdata(dds_t_data), // input wire [63 : 0] s_axis_config_tdata
.m_axis_data_tvalid(dds_data_valid), // output wire m_axis_data_tvalid
.m_axis_data_tdata(m_axis_data_tdata), // output wire [31 : 0] m_axis_data_tdata
.m_axis_phase_tvalid(), // output wire m_axis_phase_tvalid
.m_axis_phase_tdata() // output wire [31 : 0] m_axis_phase_tdata
);
dds100m_0 dds100m_1_inst (
.aclk(clk), // input wire aclk
.s_axis_config_tvalid(gen_valid), // input wire s_axis_config_tvalid
.s_axis_config_tdata(dds_t_data_1), // input wire [63 : 0] s_axis_config_tdata
.m_axis_data_tvalid(dds_data_valid), // output wire m_axis_data_tvalid
.m_axis_data_tdata(m_axis_data_tdata_1), // output wire [31 : 0] m_axis_data_tdata
.m_axis_phase_tvalid(m_axis_phase_tvalid), // output wire m_axis_phase_tvalid
.m_axis_phase_tdata(m_axis_phase_tdata) // output wire [31 : 0] m_axis_phase_tdata
);
dds100m_0 dds100m_2_inst (
.aclk(clk), // input wire aclk
.s_axis_config_tvalid(gen_valid), // input wire s_axis_config_tvalid
.s_axis_config_tdata(dds_t_data_2), // input wire [63 : 0] s_axis_config_tdata
.m_axis_data_tvalid(dds_data_valid), // output wire m_axis_data_tvalid
.m_axis_data_tdata(m_axis_data_tdata_2), // output wire [31 : 0] m_axis_data_tdata
.m_axis_phase_tvalid(m_axis_phase_tvalid), // output wire m_axis_phase_tvalid
.m_axis_phase_tdata(m_axis_phase_tdata) // output wire [31 : 0] m_axis_phase_tdata
);
dds100m_0 dds100m_3_inst (
.aclk(clk), // input wire aclk
.s_axis_config_tvalid(gen_valid), // input wire s_axis_config_tvalid
.s_axis_config_tdata(dds_t_data_3), // input wire [63 : 0] s_axis_config_tdata
.m_axis_data_tvalid(dds_data_valid), // output wire m_axis_data_tvalid
.m_axis_data_tdata(m_axis_data_tdata_3), // output wire [31 : 0] m_axis_data_tdata
.m_axis_phase_tvalid(m_axis_phase_tvalid), // output wire m_axis_phase_tvalid
.m_axis_phase_tdata(m_axis_phase_tdata) // output wire [31 : 0] m_axis_phase_tdata
);仿真结果
- 可以从上图中看出,输出的余弦波有明显的相位差,最后只需要将这4路并行的dds拼接起来(并转出),即可实现4*fs 采样率。