译者 | 高永祺
单位 | 东北大学自然语言处理实验室
原文链接:https://blog.research.google/2024/03/talk-like-graph-encoding-graphs-for.html
1.作者介绍

Bahare Fatemi,谷歌蒙特利尔研究部门的研究科学家,专门从事图表示学习和自然语言处理,目前在WiML董事会任职,曾在NeurIPS、ICLR、AAAI和JMLR顶级人工智能会议和期刊上发表工作。

Bryan Perozzi,谷歌研究科学家,致力于数据挖掘、机器学习、图论和网络科学的交叉领域,特别关注局部图算法。
2.译者说
图(Graph)是一种传统的数据结构,用于描述对象之间的连接。大语言模型(LLM)技术正在崛起,但LLM主要在文本上进行训练。图与文本都可以用来表示信息,如何在这两种媒介之间架起桥梁,让LLM更好地理解图?作者深入探究了如何用文本将图的信息编码,故而论文题目称为Talk like a graph。
3.译文大纲
3.1 引言
3.2 将图转换为文本
3.3 分析与结果
3.4 结论
04 译文
4.1 引言
想象一下你周围的所有事物------你的朋友、厨房里的工具,甚至是你自行车的零件。它们以不同的方式相互连接。在计算机科学中,术语"图"被用来描述对象之间的连接。图由节点(对象本身)和边(连接两个节点,表示它们之间的关系)组成。现在,图随处可见。互联网本身就是一个由网站互联构成的巨大的图。
此外,人工智能领域显著进步------例如,能够在几秒钟内编写故事的聊天机器人,甚至能够解释医疗报告的软件。这些令人兴奋的进步很大程度上归功于大语言模型(LLM)。人们针对不同用途不断开发新的LLM技术。
由于图随处可见,而LLM技术正在崛起,发表在ICLR 2024 上的论文"Talk like a Graph: Encoding Graphs for Large Language Models"提出了一种方法,可以教会强大的LLM如何更好地利用图信息进行推理。图是一种组织信息的有效方式,但LLM主要是在常规文本上进行训练的。我们的目标是测试不同的技术,看看哪种效果最好。将图转换为LLM能理解的文本是一项非常复杂的任务。困难在于图结构本身的复杂性,其中有多个节点以及将它们连接起来的复杂网络。我们的工作研究了如何将图转换为LLM能理解的格式。我们还设计了一个称为GraphQA的基准,用于研究不同的方法处理不同的图推理问题,并展示如何表达与图相关的问题,使得 LLM能够解决图问题。我们发现,LLM在图推理任务上的性能在三个层次上都有不同:1)图编码方法,2)图任务本身的性质,3)所考虑的图的结构本身。这些发现启发我们如何为LLM最好地表示图。选择正确的方法可以使LLM在图任务上提升高达60%!

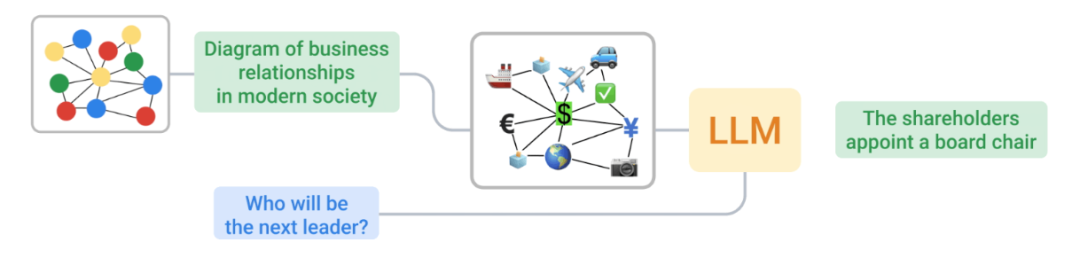
图1 将图编码为文本的过程采用了两种不同的方法,并将文本和关于图的问题输入到LLM中
4.2 将图转换为文本
为了系统地找出将图转换为文本的最佳方法,我们首先设计了一个名为GraphQA的基准。可以将GraphQA看作一个专门用于评估LLM在图问题上表现的测试。我们希望了解LLM在不同设置下理解和解决涉及图的问题的能力。为了为LLM创建一个全面而现实的测试,我们不仅仅使用一种类型的图,而是使用一系列图,确保连接数量的广度。这主要是因为,不同类型的图会使解决此类问题更容易或更难。通过这种方式,GraphQA有助于暴露出LLM思考图时的偏见,整个测试更接近LLM可能在现实世界中遇到的真实情况。

图2 我们使用LLM进行图推理的框架概览
GraphQA专注于与图相关的简单任务,例如检查边是否存在、计算节点或边的数量、查找连接到某特定节点的节点,以及检查图中是否存在循环。这些任务可能看起来很基础,但它们需要理解节点和边之间的关系。通过涵盖不同类型的挑战,从识别模式到创建新连接,GraphQA帮助模型学习如何有效地分析图。这些基本任务对于在图上进行更复杂的推理至关重要,例如在节点之间找到最短路径、检测社区或识别有影响力的节点。此外,GraphQA提供了丰富多样的数据集进行训练,包括使用各种算法生成随机图,如Erdős-Rényi1、无标度网络2、Barabasi-Albert模型3和随机块模型4,以及更简单的图结构,如路径、完全图和星形图。
在处理图时,我们还需要找到询问图相关问题的方法使得LLM能够理解。提示启发法有不同的方式来做到这一点。让我们分解一下常见的方式:
Zero-shot(零样本):简单描述任务("这个图中是否存在循环?")并告诉LLM去完成。不提供示例。
Few-shot(少样本):这类似于在真正的测试之前给LLM提供一个小练习。我们提供几个示例图问题及其正确答案。
Chain-of-Thought(思维链):我们向LLM展示如何逐步分解问题并提供示例。目标是教会它在面对新图时生成自己的"思考过程"。
Zero-CoT(零样本思维链):类似于CoT,但是我们不提供训练示例,而是给LLM一个简单的提示,比如"让我们逐步思考",以触发其自己的问题解决过程。
BAG(build a graph):这专门用于图任务。我们在描述中添加短语"让我们构建一个图...",帮助LLM集中注意力在图结构上。
我们探索了不同的方法,将图转换为LLM可以处理的文本。我们的关键问题是:
节点编码:我们如何表示单个节点?测试的选项包括简单的整数、常见名称(人名、角色)和字母。
边编码:我们如何描述节点之间的关系?方法涉及括号表示法、诸如"是朋友"之类的短语,以及箭头等符号表示法。
系统地结合了各种节点和边编码,编码函数如下图所示:

图3 用于通过文本对图进行编码的图编码函数的示例
4.3 分析与结果
我们进行了三个关键实验:一个是测试LLM处理图任务的能力,另外两个是了解LLM的大小和不同图的形状对性能的影响。所有的实验在GraphQA上进行。
4.3.1 LLM如何处理图任务
在这个实验中,我们测试了预训练的LLM处理识别连接、循环和节点度等图问题的能力。以下是我们的发现:
LLM表现不佳:在大多数基础任务中,LLM的表现并不比随机猜测好多少。
编码影响显著:如何将图表示为文本对LLM的性能有很大影响。对于大多数任务来说,"incident"编码在总体上表现优异。
我们的结果总结在以下图表中。
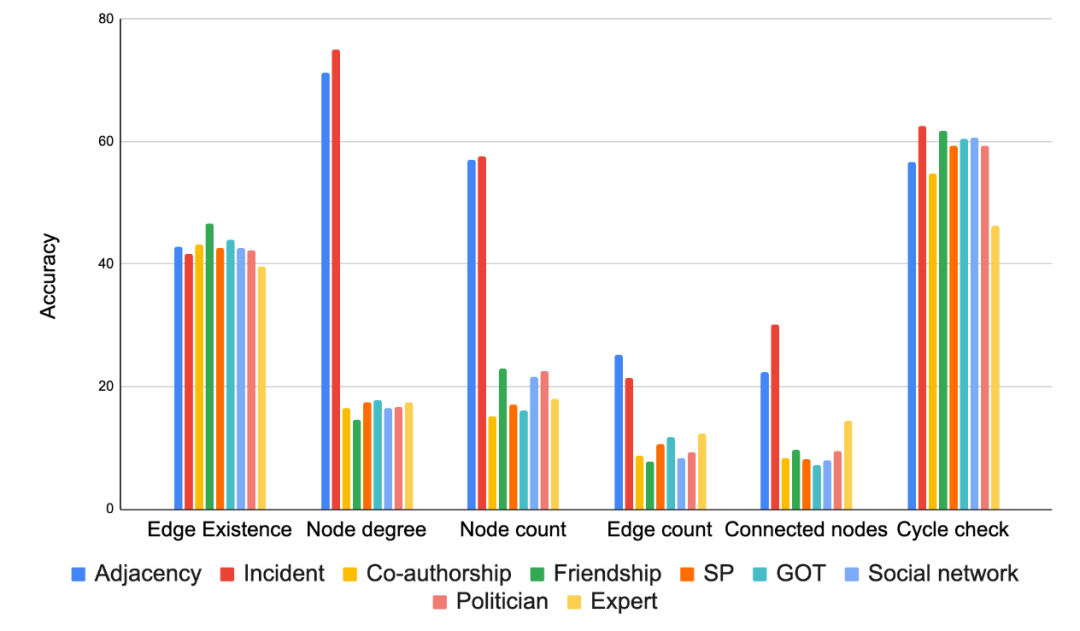
图4基于不同图任务准确率对各种图编码函数的比较。从这个图表中得出的主要结论是,图编码函数的选择对结果影响显著
4.3.2 规模越大,通常越好
在这个实验中,我们想要看到LLM的大小(以参数量为衡量)是否影响它们处理图问题的能力。为此,我们在PaLM 2的XXS、XS、S和L尺寸上测试了相同的图任务。以下是我们的研究结果总结:
总的来说,更大的模型在图推理任务上表现更好。似乎额外的参数给了它们学习更复杂模式的空间。
奇怪的是,对于"边存在"任务(找出图中两个节点是否连接)来说,模型大小并不那么重要。
即使是最大的LLM在检查循环问题(确定图是否包含循环)上也无法始终击败简单的基准解决方案。这表明LLM在某些图任务上仍有改进的空间。
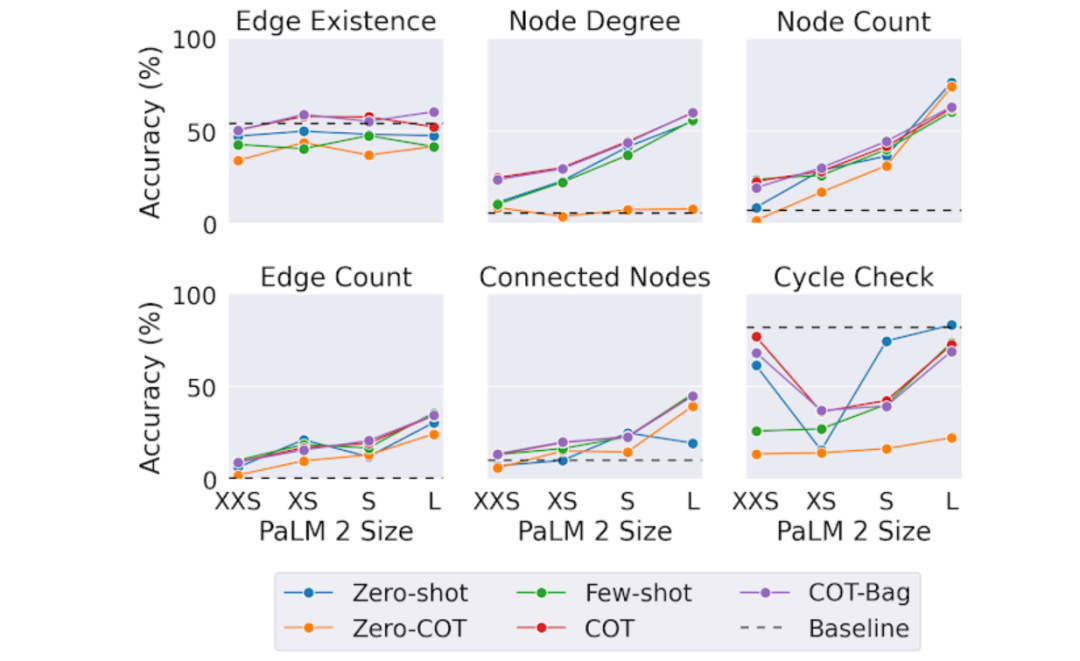
图5 模型大小对于PaLM 2-XXS、XS、S和L在图推理任务中的影响
4.3.3 不同的图的形状是否会让LLM感到困惑
我们想知道图的"形状"(节点如何连接)是否会影响LLM解决问题的能力。以下的图是图的形状的不同示例。

图6 使用GraphQA中的不同图形生成器生成的图样本。其中,ER、BA、SBM和SFN分别指Erdős--Rényi、Barabási--Albert、随机块模型和无标度网络
我们发现图的结构对LLM的性能有很大影响。例如,在询问循环是否存在的任务中,LLM在紧密相互连接的图上表现出色(循环在这里很常见),但在路径图上表现困难(从来不会出现循环)。有趣的是,提供一些混合示例可以帮助它适应。例如,在循环检查任务中,我们将一些包含循环的示例和一些不包含循环的示例作为我们提示中的少样本示例添加进去。类似的模式也出现在其他任务中。
4.4 总结
简而言之,我们深入研究了如何最好地将图表示为文本,以便LLM能够理解它们。我们发现了三个主要因素会产生影响:
将图转换为文本的方式:如何将图表示为文本显著影响了LLM的性能。在大多数任务中,"incident"编码在总体上表现出色。
任务类型:某些类型的图问题往往对LLM来说更难,即使从图到文本的转换很好。
图结构:令人惊讶的是,用于进行推理的图的"形状"(密集连接、稀疏等)会影响LLM的表现。
这项研究揭示了为LLM准备图的关键。正确的编码技术可以显著提高LLM在图问题上的准确性(从大约5%到超过60%的提升)。我们的新基准,GraphQA,将有助于推动这一领域的进一步研究。
1 https://en.wikipedia.org/wiki/Erdős–Rényi_model
2 https://en.wikipedia.org/wiki/Scale-free_network