文章目录
大家已经知道,OpenAI 在 GPT-4 发布一年多后终于推出了一个新模型。它仍然是 GPT-4 的一个变体,但具有前所未见的多模态功能。
有趣的是,它包括实时视频处理等强大功能,这一关键功能最终可以让我们创建强大的虚拟助手,实时支持我们的日常生活。然而,这样的功能应该很昂贵且缓慢,考虑到该模型速度极快且免费使用(有限免费),这不合情理。
那么,到底发生了什么事呢?
OpenAI 一定已经意识到了一些我们尚未意识到的事情,即我们今天讨论的智能设计决策可以以极低的价格创建出更智能的模型。
那么,这一切有何意义?它对你未来意味着什么?
多模态输入,多模态输出
那么,ChatGPT-4o 有什么特别之处呢?它是有史以来第一个真正的"多模态输入/多模态输出"前沿模型。
但我们这样说到底是什么意思呢?
在真正的多模态模型中,您可以向模型发送音频、文本、图像或视频,模型将根据需求使用文本、图像或音频(还不是视频)进行响应。
但我知道你在想什么:ChatGPT 或 Gemini 的先前版本不是已经处理和生成图像或音频了吗?是的,但有一个需要注意的点是:他们是通过独立的外生组件来实现的。
之前的模型和现在模型对比
以前,每当你向大模型发送音频时,都是这样的标准流程:
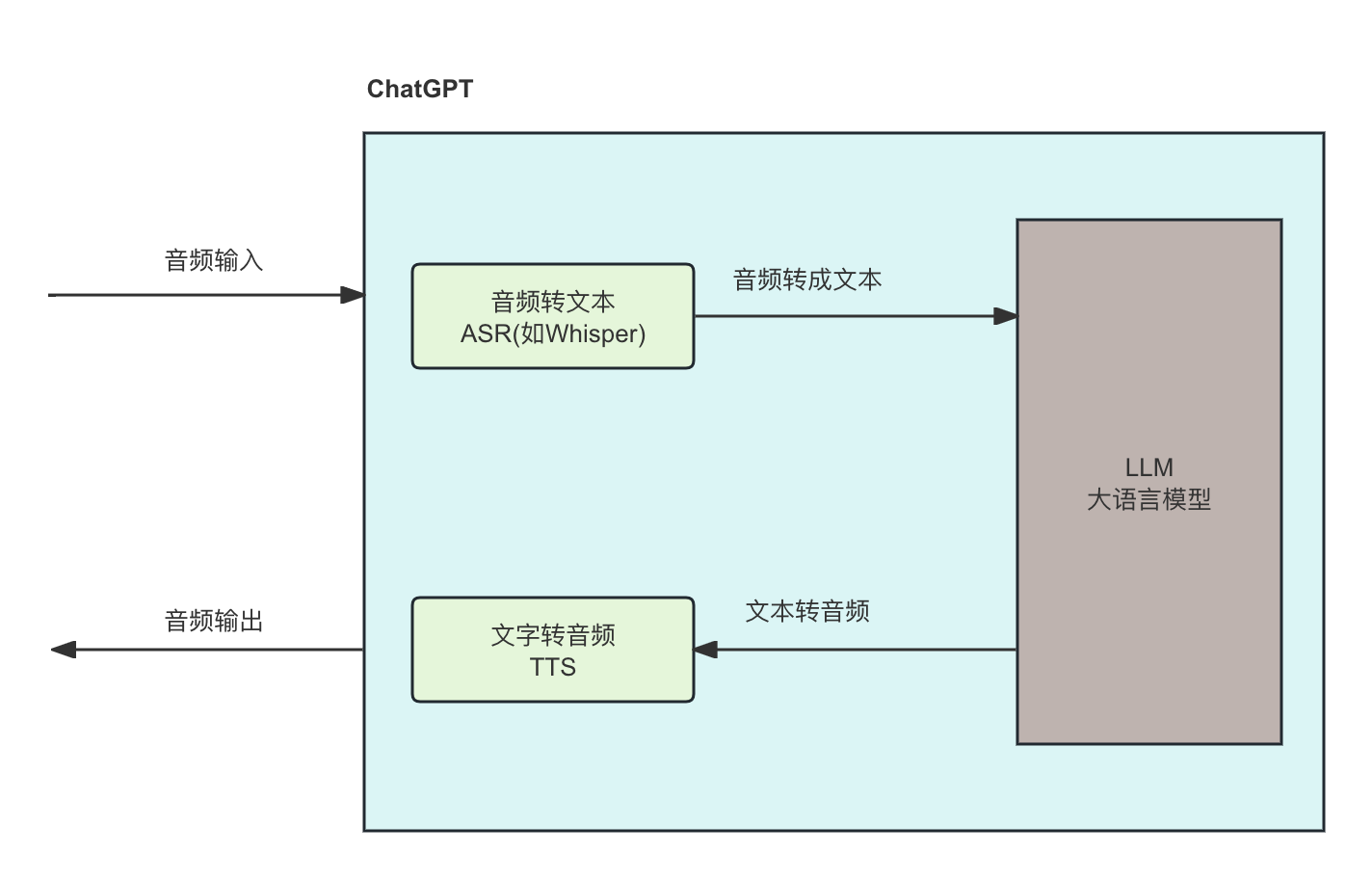
输入输出过程 :用户发出的语音请求经过自动语音识别(ASR)转为文本(这里用的Whisper),文本经过大语言模型处理生成响应文本,响应文本再经过文本转语音(TTS)模块转换为语音,最终以语音形式返回给用户。
Whisper 是由 OpenAI 开发的一种自动语音识别(ASR)系统。它利用深度学习技术和大规模语音数据进行训练,能够将语音信号转换为文本。Whisper 系统具有高准确性和多语言支持,能够处理各种音质和背景噪声的语音输入。
在此过程中,自然语音中的声调 、节奏 、韵律 、传达的情感 和关键停顿都会丢失,因为语音转文本组件Whisper会将音频转录为 LLM 可以处理的文本。
然后,LLM 将生成文本响应并将其发送到另一个组件(即文本到语音模型),该模型将生成最终传达的语音。
自然,由于人类通过语音传达的信息远不止文字,许多重要信息也因此丢失,
而且由于信息必须在不同的组件之间发送,造成的延迟并不理想。
但是在 ChatGPT-4o 中,一切都相似但又完全不同;因为一切都发生在同一个地方。
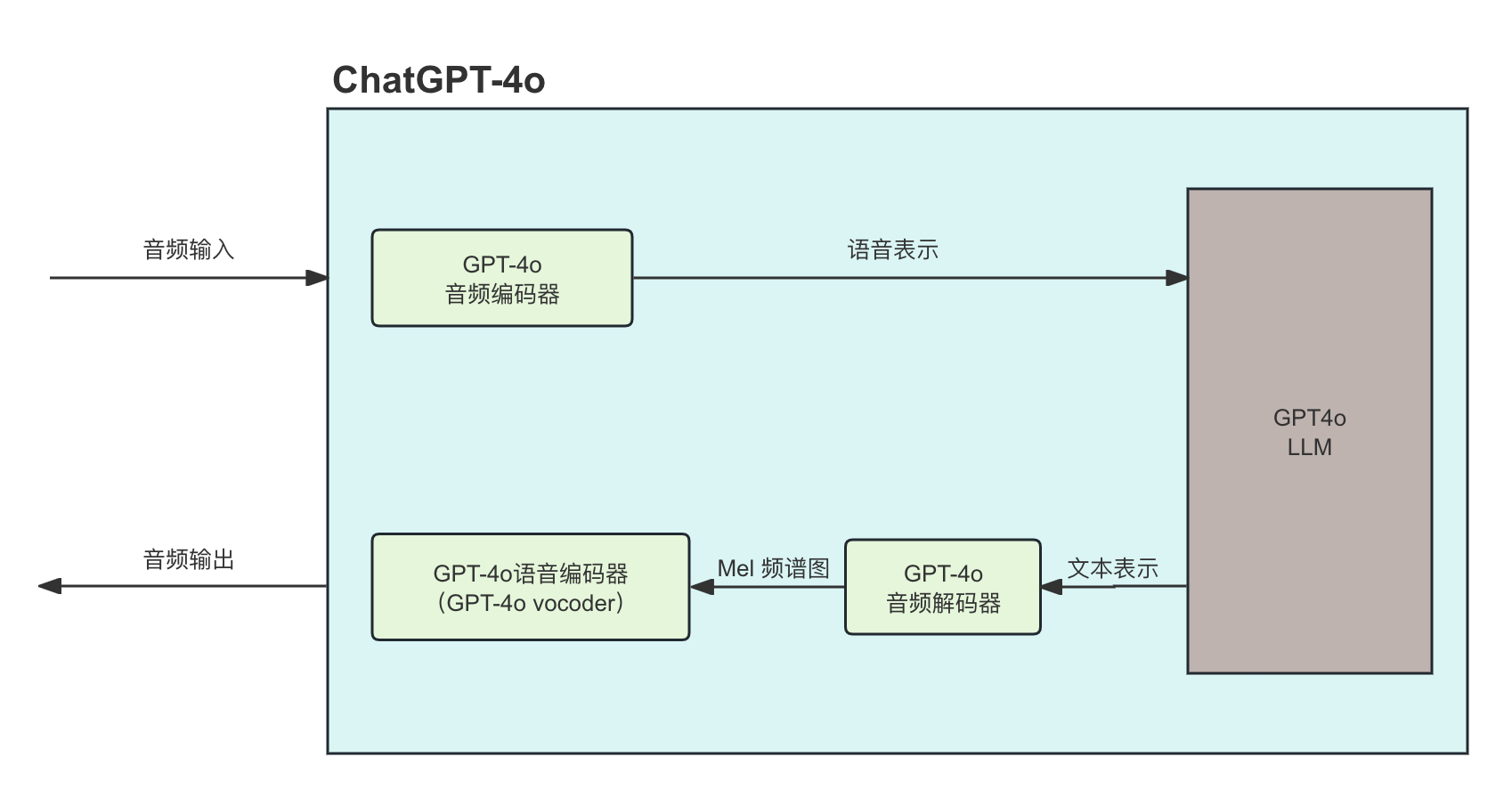
乍一看,似乎变化不大。但尽管组件几乎没有变化(vocoder和音频解码器是我们之前展示的文本转语音模型的一部分),但这些组件如何共享信息完全改变了信息丢失的程度。
具体来说,LLM 现在看到的是语音的语义表示,而不是原始文本。通俗地说,模型现在不仅能看到"我想杀了你!"这句文字,还能接收到以下信息:
json
{
转译的文字: "我想杀了你!";
情绪: "高兴";
语气: "喜悦";
}这里虽然使用了 JSON 示例来说明,但语音编码器实际上为 LLM 生成的是一组向量嵌入(Vector Embeddings) ,除了实际文本之外,它们还捕捉语音的情感、语调、节奏和其他线索。
向量嵌入 是一种将离散的数据(如单词、句子、图像等)映射到连续的低维向量空间的方法。这些向量捕捉了数据的语义关系,使得相似的数据在向量空间中更接近。
因此,LLM 生成的响应更加基于实际情况,除了文字之外,还能捕捉信息中的关键特征。
然后将该响应发送到音频解码器,音频解码器使用它来生成梅尔频谱图(很可能),最后将其发送到声码器以生成音频。
您可以将频谱图视为"查看"声音的一种方式。频谱图 是一种将音频信号的频率成分展示在二维图表上的工具。频谱图显示了音频信号在不同时间点的频率分布及其强度
那么梅尔频谱图是什么?梅尔频谱图 是一种特殊类型的频谱图,它通过 Mel 频率尺度对频率轴进行变换,更符合人耳对声音的感知
顺便说一句,所有这些也适用于图像处理和生成或视频处理,因为它们将所有组件打包成一个单一模型,而不仅仅是音频。
总而言之,ChatGPT-4o 现在可以从文本以外的其他形式捕获信息,包括关键音频、图像或视频提示,以生成更相关的响应。简而言之,它不再关心数据如何进入并适应上下文,而是需要决定必须以何种方式回复。
这个改变有多么重要?
OpenAI 实现的真正多模态向世界传递了一个鲜明的信息:
在不使模型的主干(LLM)本身更加智能的情况下,能够跨多种模态进行推理的模型必然会更加智能,因为该模型不仅具有更多功能,而且还能够在不同数据类型之间传递知识。
人类运用所有感官的能力被认为是智能的关键部分,而人工智能也旨在掌握这种能力。
作为一个很大的好处,它还使模型在推理方面变得更加高效(撇开它们本可以应用的特定效率不谈)。消除组合多个外部组件的通信开销似乎使模型的速度大大加快。
这就是 ChatGPT-4o 的特别之处。
如果你想体验ChatGPT-4o,并且想国内直接访问,可以直接访问 我要超级GPT 51supergpt, 免注册,直接使用。