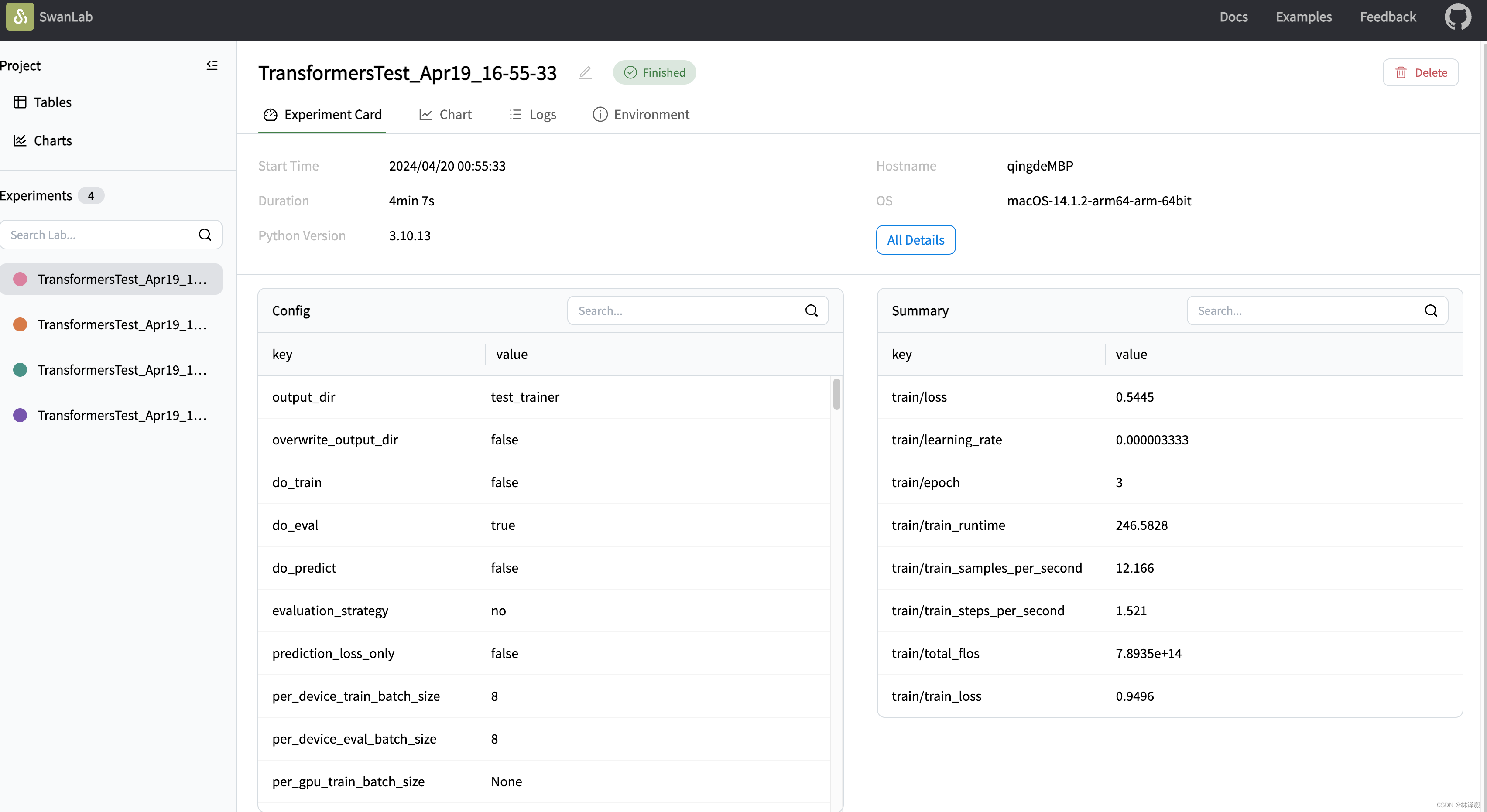
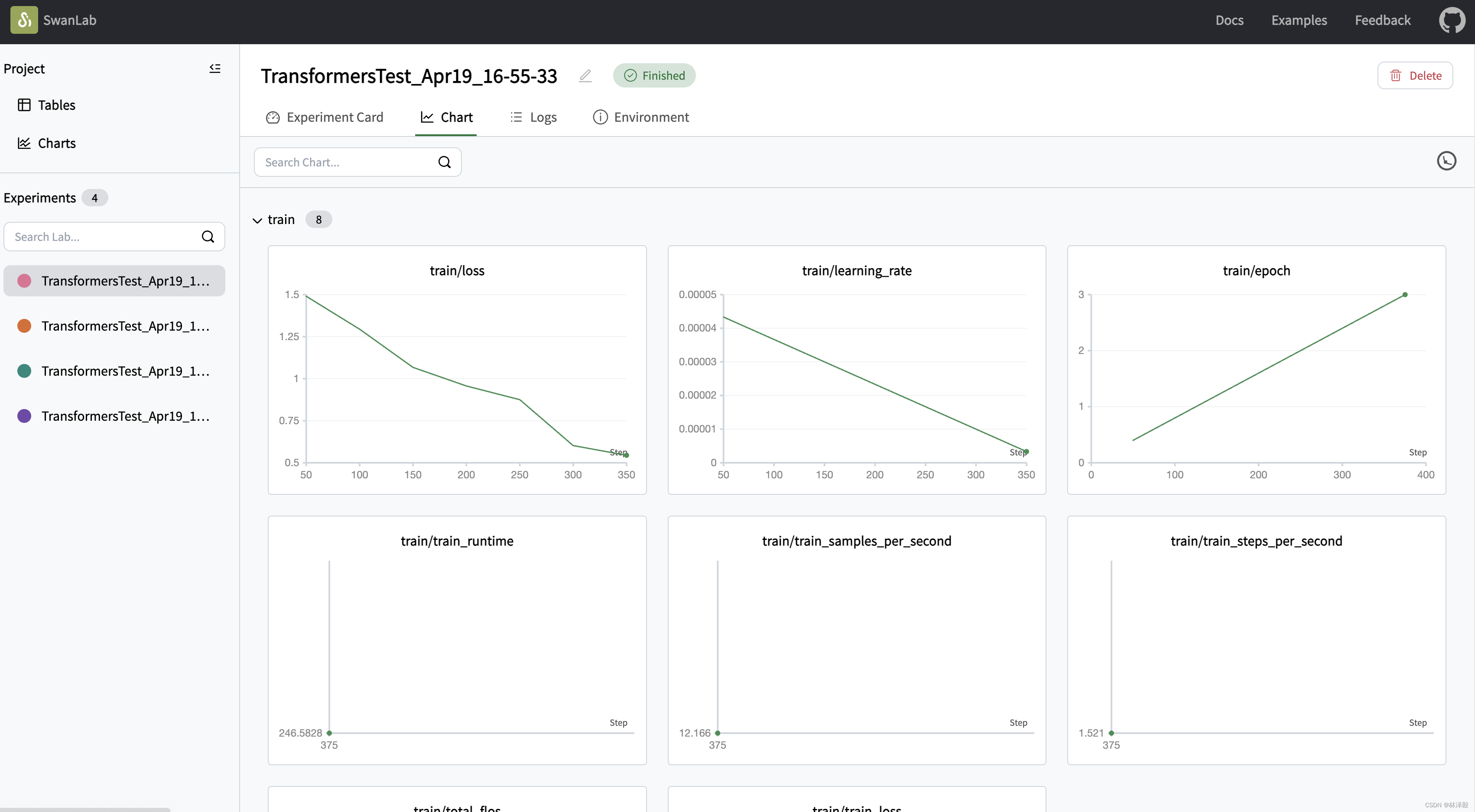
🤗HuggingFace Transformers
Hugging Face 的 Transformers 是一个非常流行的开源库,它提供了大量预训练的模型,主要用于自然语言处理(NLP)任务。这个库的目标是使最新的模型能够易于使用,并支持多种框架,如 TensorFlow 和 PyTorch。

你可以使用Transformers快速进行模型训练,同时使用SwanLab进行实验跟踪与可视化。
1. 引入SwanLabCallback
python
from swanlab.integration.huggingface import SwanLabCallbackSwanLabCallback是适配于Transformers的日志记录类。
SwanLabCallback可以定义的参数有:
- project、experiment_name、description 等与 swanlab.init 效果一致的参数, 用于SwanLab项目的初始化。
- 你也可以在外部通过
swanlab.init创建项目,集成会将实验记录到你在外部创建的项目中。
2. 传入Trainer
python
from swanlab.integration.huggingface import SwanLabCallback
from transformers import Trainer, TrainingArguments
...
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(project="hf-visualization")
trainer = Trainer(
...
# 传入callbacks参数
callbacks=[swanlab_callback],
)
trainer.train()3. 完整案例代码
python
import evaluate
import numpy as np
import swanlab
from swanlab.integration.huggingface import SwanLabCallback
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
dataset = load_dataset("yelp_review_full")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
metric = evaluate.load("accuracy")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
training_args = TrainingArguments(
output_dir="test_trainer",
# 如果只需要用SwanLab跟踪实验,则将report_to参数设置为"none"
report_to="none",
num_train_epochs=3,
logging_steps=50,
)
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(experiment_name="TransformersTest")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
# 传入callbacks参数
callbacks=[swanlab_callback],
)
trainer.train()