
往期精彩内容:
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-CSDN博客
基于麻雀优化算法SSA的预测模型------代码全家桶-CSDN博客
风速预测(八)VMD-CNN-Transformer预测模型-CSDN博客
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型-CSDN博客
独家原创 | 基于TCN-SENet +BiGRU-GlobalAttention并行预测模型-CSDN博客
独家原创 | BiTCN-BiGRU-CrossAttention融合时空特征的高创新预测模型-CSDN博客
CEEMDAN +组合预测模型(CNN-Transfromer + XGBoost)-CSDN博客
时空特征融合的BiTCN-Transformer并行预测模型-CSDN博客
独家首发 | 基于多级注意力机制的并行预测模型-CSDN博客
独家原创 | CEEMDAN-CNN-GRU-GlobalAttention + XGBoost组合预测-CSDN博客
多步预测系列 | LSTM、CNN、Transformer、TCN、串行、并行模型集合-CSDN博客
独家原创 | CEEMDAN-Transformer-BiLSTM并行 + XGBoost组合预测-CSDN博客
涨点创新 | 基于 Informer-LSTM的并行预测模型-CSDN博客
独家原创 | 基于 Informer + TCN-SENet的并行预测模型-CSDN博客
粉丝福利 | 再添 Seq2Seq 多步预测模型-CSDN博客
暴力涨点! | 基于 Informer+BiGRU-GlobalAttention的并行预测模型-CSDN博客
热点创新 | 基于 KANConv-GRU并行的多步预测模型-CSDN博客
重大更新!锂电池剩余寿命预测新增 CALCE 数据集_calce数据集-CSDN博客
基于 VMD滚动分解+Transformer-GRU并行的锂电池剩余寿命预测模型
快速傅里叶变换暴力涨点!基于时频特征融合的高创新时间序列分类模型-CSDN博客
基于CNN-BiLSTM-Attention的回归预测模型!-CSDN博客
连续小波变换(CWT)+时间序列预测!融合时频分析与深度学习的预测新思路
前言
本期我们推出创新性预测模型:CEEMDAN分解+Informer-LSTM+XGBoost组合预测模型。通过CEEMDAN自适应信号分解将原始序列解耦为多频分量,构建高频-低频两级预测通道:
-
高频分量由于其复杂性,采用参数丰富的 Informer-LSTM 并行模型,这种结合了注意力机制和长短期记忆网络的模型能更好地捕获长程依赖和复杂动态变化;
-
低频分量则使用 XGBoost,这是一种高效的梯度提升决策树模型,能够快速处理简单且低频的特征,避免过拟合。
各模型分别对其对应的分量进行预测,生成每个 IMFs 的预测值;然后将所有预测的 IMFs 重新组合,构建出完整的预测信号。通过合理分配复杂模型和简单模型的任务,我们能够在不同频率特征的信号上实现最佳的预测性能。
模型适用单变量数据集预测!(风速、负荷、锂电池寿命预测等任务)
1 创新模型简介
1.1 模型评估:

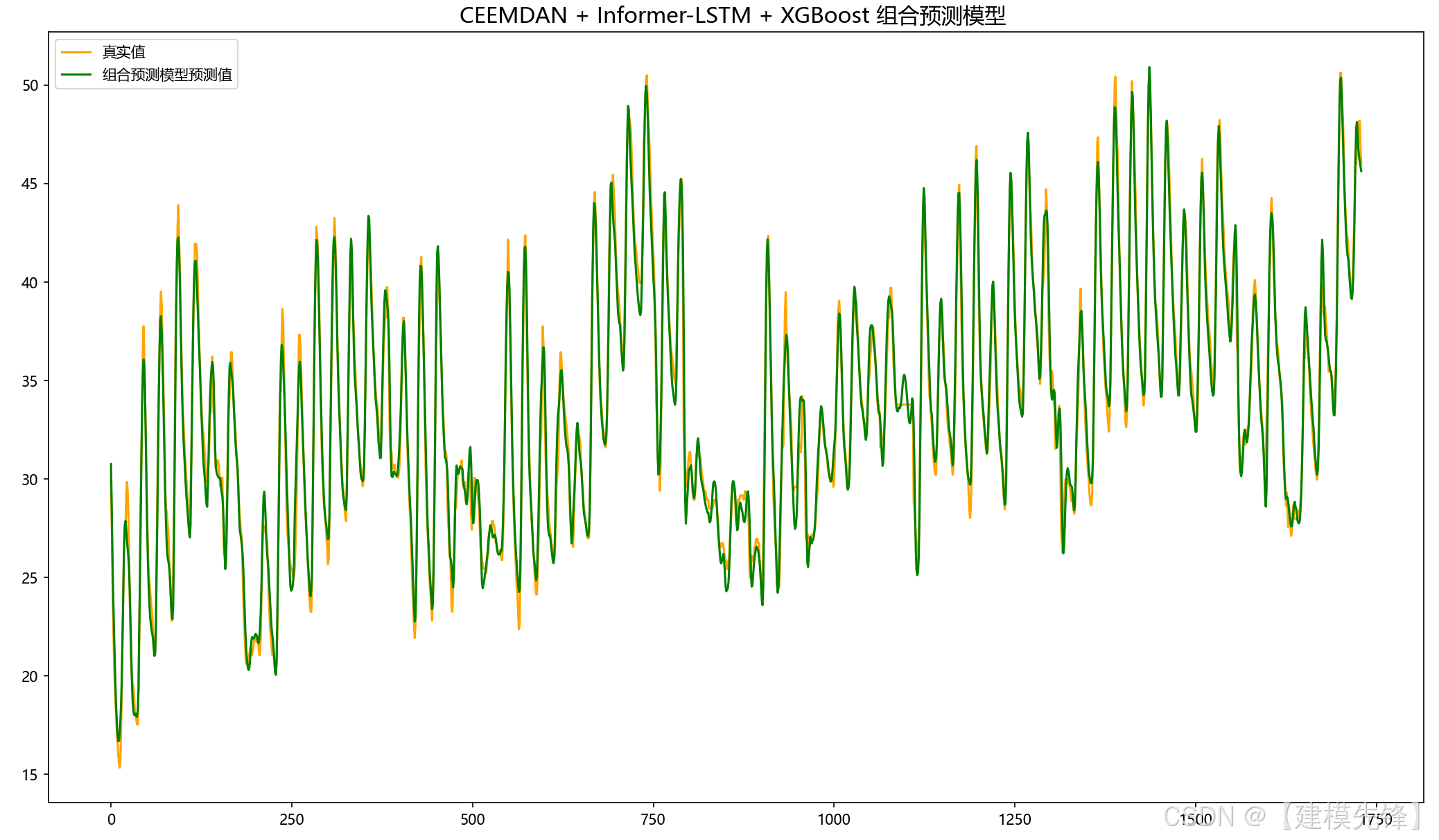
1.2 预测可视化:
我们同时提供详细的资料、解说文档和视频讲解,包括如何替换自己的数据集、参数调整教程,预测任务的替换等,代码逐行注释,参数介绍详细:
● 数据集:单特征(变量)数据集
● 环境框架:python 3.9 pytorch 2.1 及其以上版本均可运行
● 单步预测模型分数:测试集 0.98
● 使用对象:论文需求、毕业设计需求者
● 代码保证:代码注释详细、即拿即可跑通。
2 模型创新点介绍
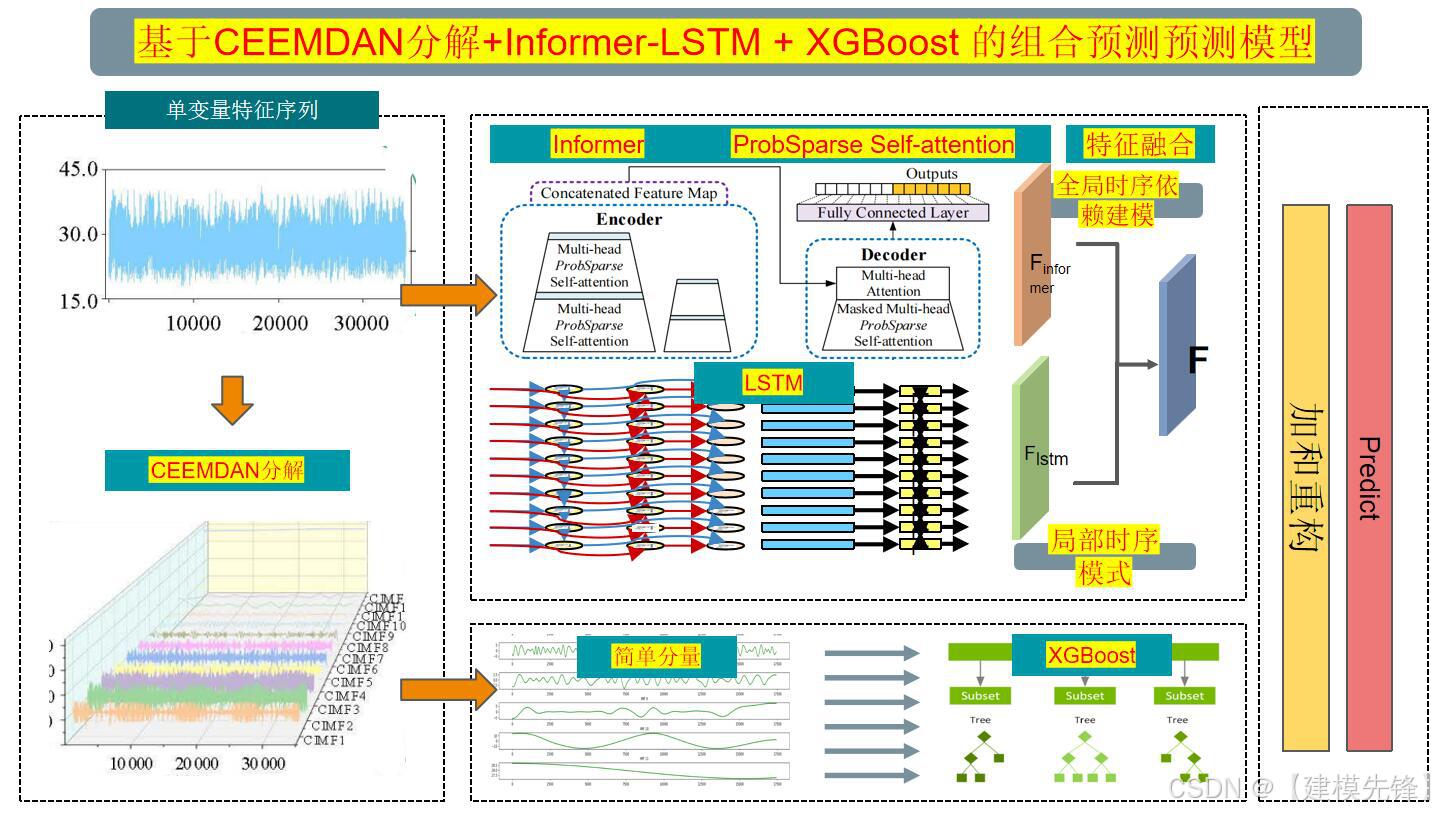
2.1 分解-组合预测策略
使用复杂模型去预测数据的分量特征,因为复杂模型参数量大,适合预测高频复杂分量特征,但是低频分量特征比较简单,要是还用复杂模型的话,就容易过拟合,反而效果不好,所以对于低频分量特征 我们采用简单模型(或者机器学习模型)去预测,然后进行预测分量的重构以实现高精度预测。
2.2 数据预处理与分解
原始时间序列数据被输入到 CEEMDAN 算法中进行分解。CEEMDAN 是一种改进的集合经验模态分解方法,能够有效地将信号分解为若干固有模态函数(IMFs),这些 IMFs 各自代表不同频率的信号成分。
样本熵是一种用于衡量序列复杂度的方法,可以通过计算序列中的不确定性来评估其复杂性。样本熵越高,表示序列的复杂度越大。依据每个分量的频率特性和复杂程度,将其分类为高频复杂分量和低频简单分量
2.3 高频复杂分量预测
-
Informer:擅长处理长时间序列,能够并行计算,提高了计算效率和预测性能。Informer在Transformer的基础上进行了改进,使其更适合时序数据,特别是具有长时间依赖的序列数据。
-
LSTM:在捕捉序列数据的短期和长期依赖性方面表现出色,能够很好地处理序列数据中的时序关系。
通过将这两种模型并行使用,可以更好地捕捉不同时间尺度上的模式,提高预测的准确性和鲁棒性。
2.4 低频复杂分量预测
利用 XGBoost 进行建模。XGBoost 以其快速的训练速度和强大的泛化能力,能够在低频特征上提供稳定的预测性能。
2.5 预测结果重构与评估:
将所有预测的 IMFs 重新组合,构建出完整的预测信号。这个过程确保了各个分量的预测结果被整合为一个整体,保持了原始信号的结构和特征。对组合后的预测结果进行验证,通过与真实数据的比较,评估模型的预测精度,并根据反馈进行优化调整。
3 数据CEEMDAN分解与可视化
3.1 导入数据
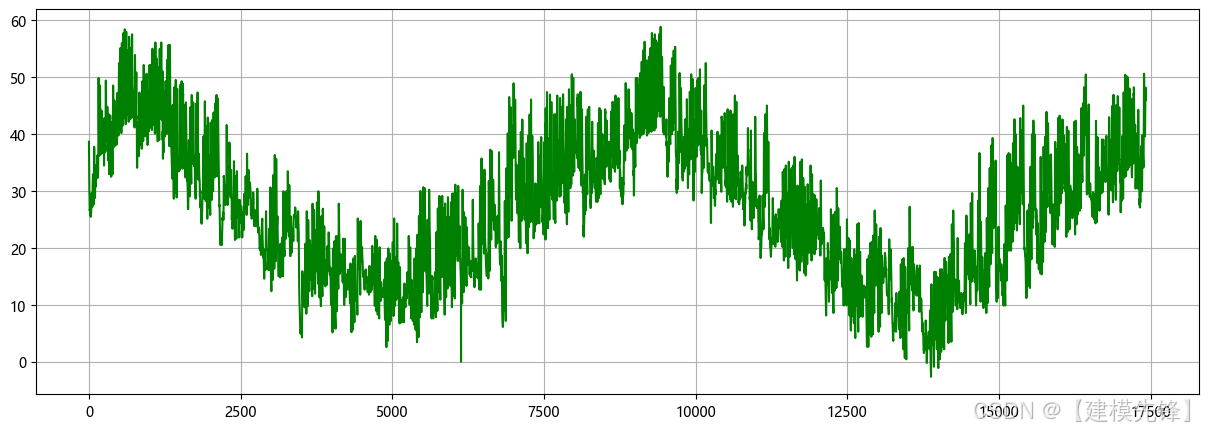
3.2 CEEMDAN分解
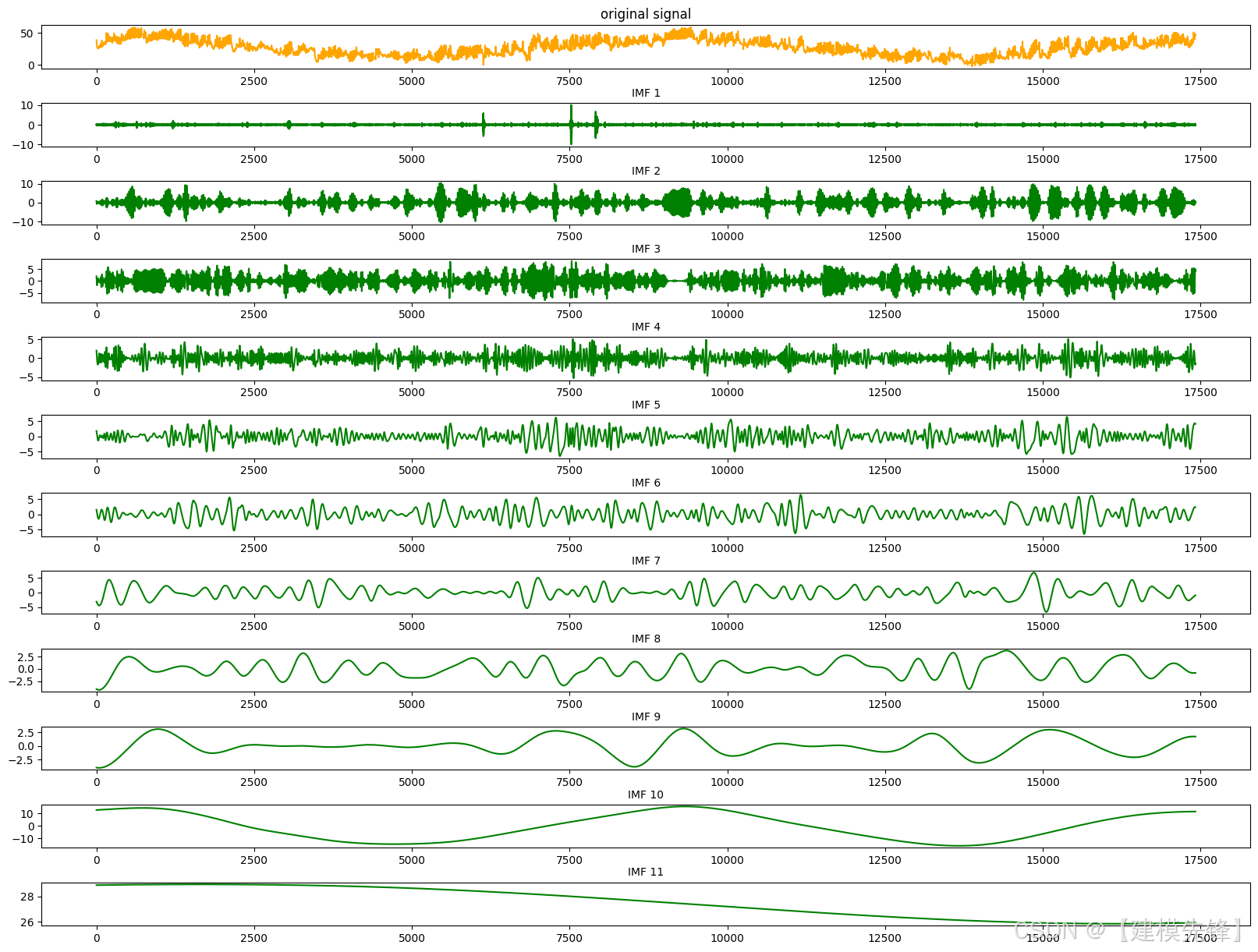
根据分解结果看,CEEMDAN一共分解出11个分量,然后通过计算每个分量的样本熵值进行分析。样本熵是一种用于衡量序列复杂度的方法,可以通过计算序列中的不确定性来评估其复杂性。样本熵越高,表示序列的复杂度越大。
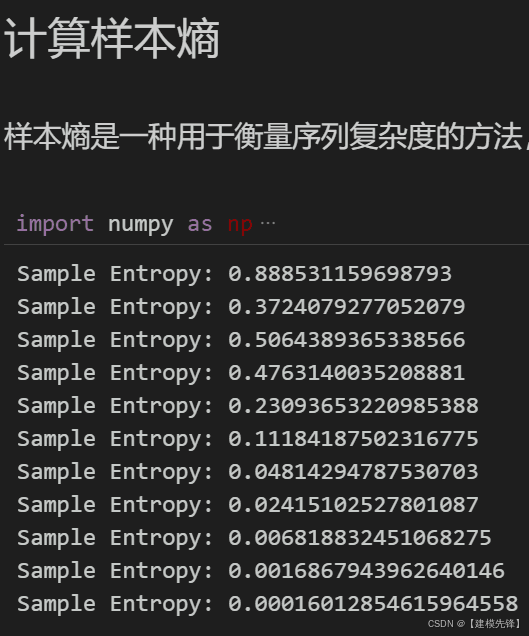
我们把前6个高样本熵值复杂分量作为Informer-LSTM并行模型的输入进行预测,后5个低样本熵值简单分量作为XGBoost模型的输入进行预测.
3.3 数据集制作与预处理
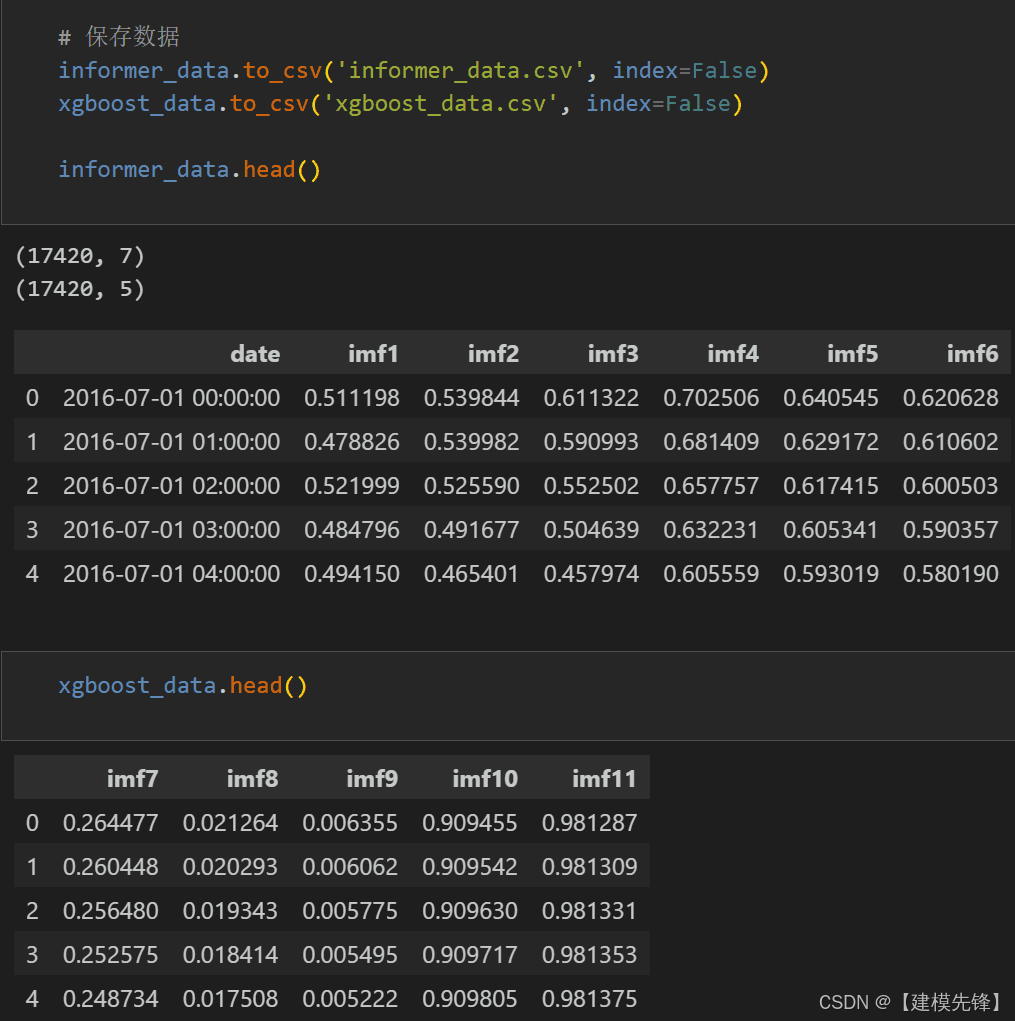
详细介绍见提供的文档!
4 基于CEEMDAN分解 + Informer-LSTM + XGBoost的组合预测模型
4.1 定义Informer-LSTM并行预测网络模型
4.2 设置参数,训练模型
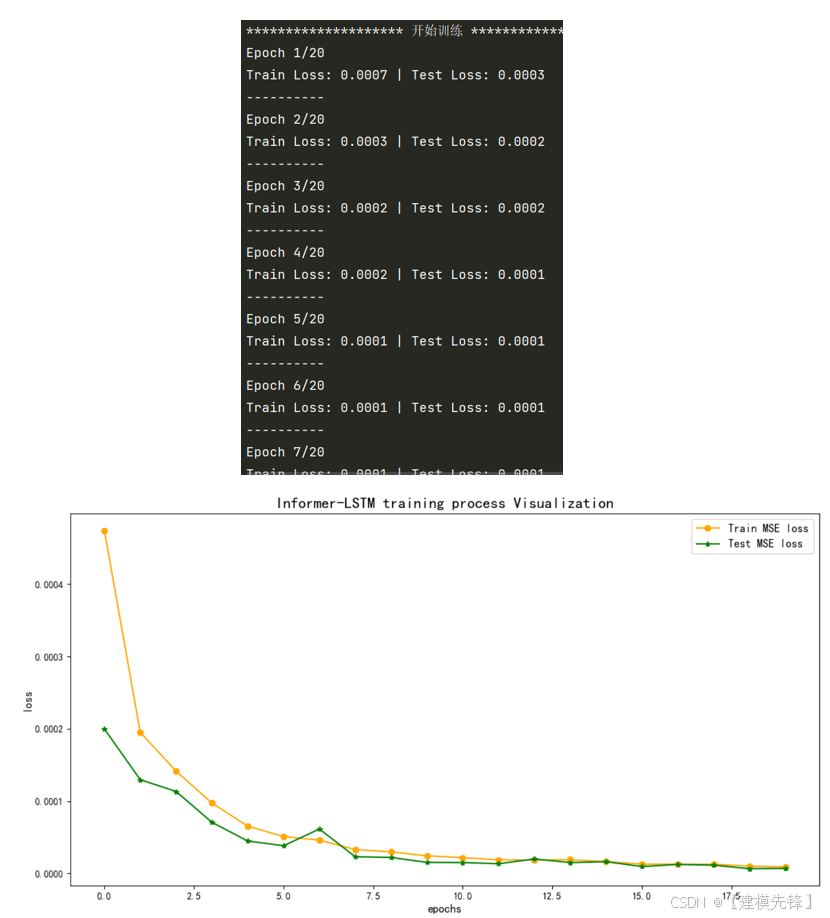
50个epoch,MSE 为0.000879, Informer-LSTM并行预测效果显著,模型能够充分利用Informer的长时间依赖建模能力和LSTM的短期依赖捕捉能力征,收敛速度快,性能优越,预测精度高,适当调整模型参数,还可以进一步提高模型预测表现。
4.3 基于XGBoost的模型预测
数据加载,训练数据、测试数据分组,5个分量,划分5个数据集
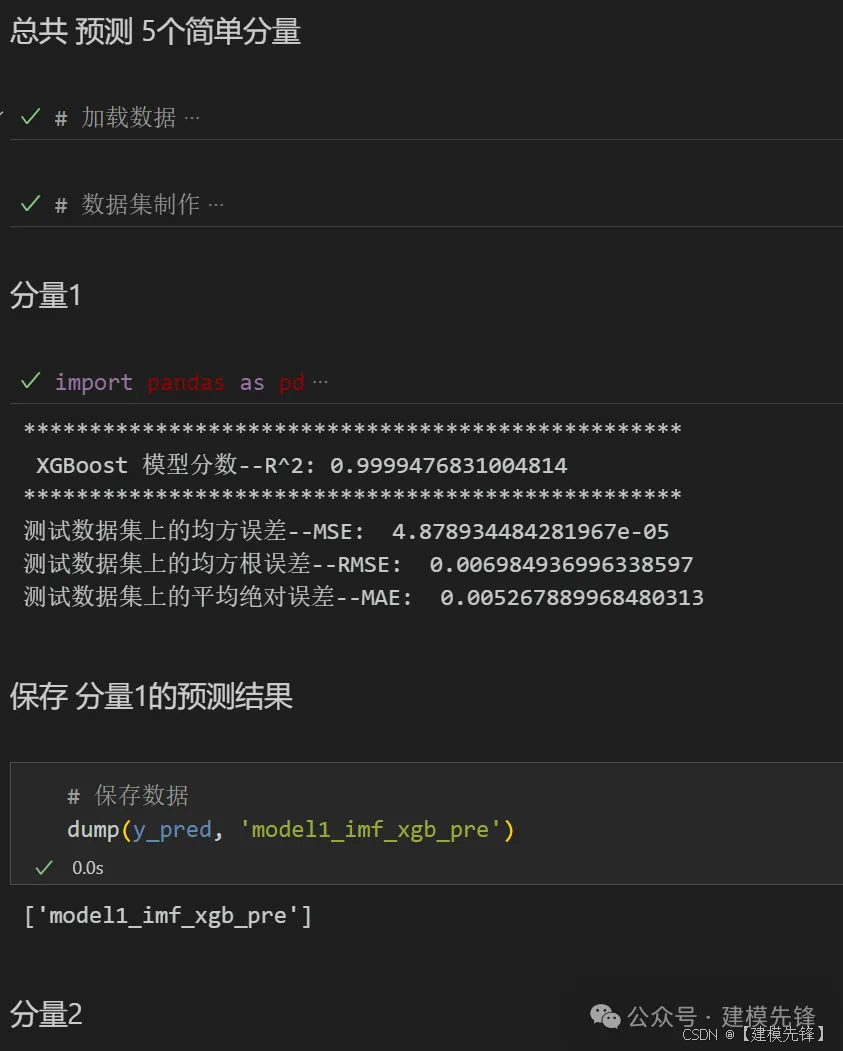
保存预测的数据,其他分量预测与上述过程一致,保留最后模型结果即可。
5 结果可视化和模型评估
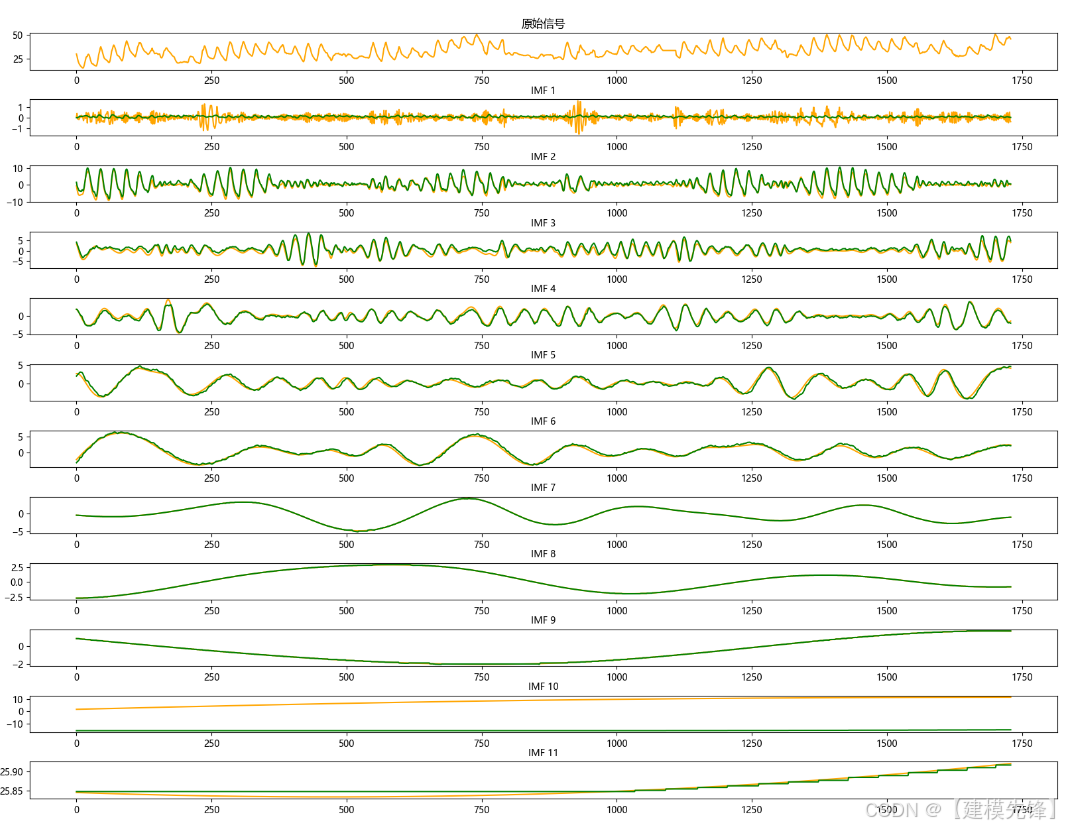
5.1 分量预测结果可视化
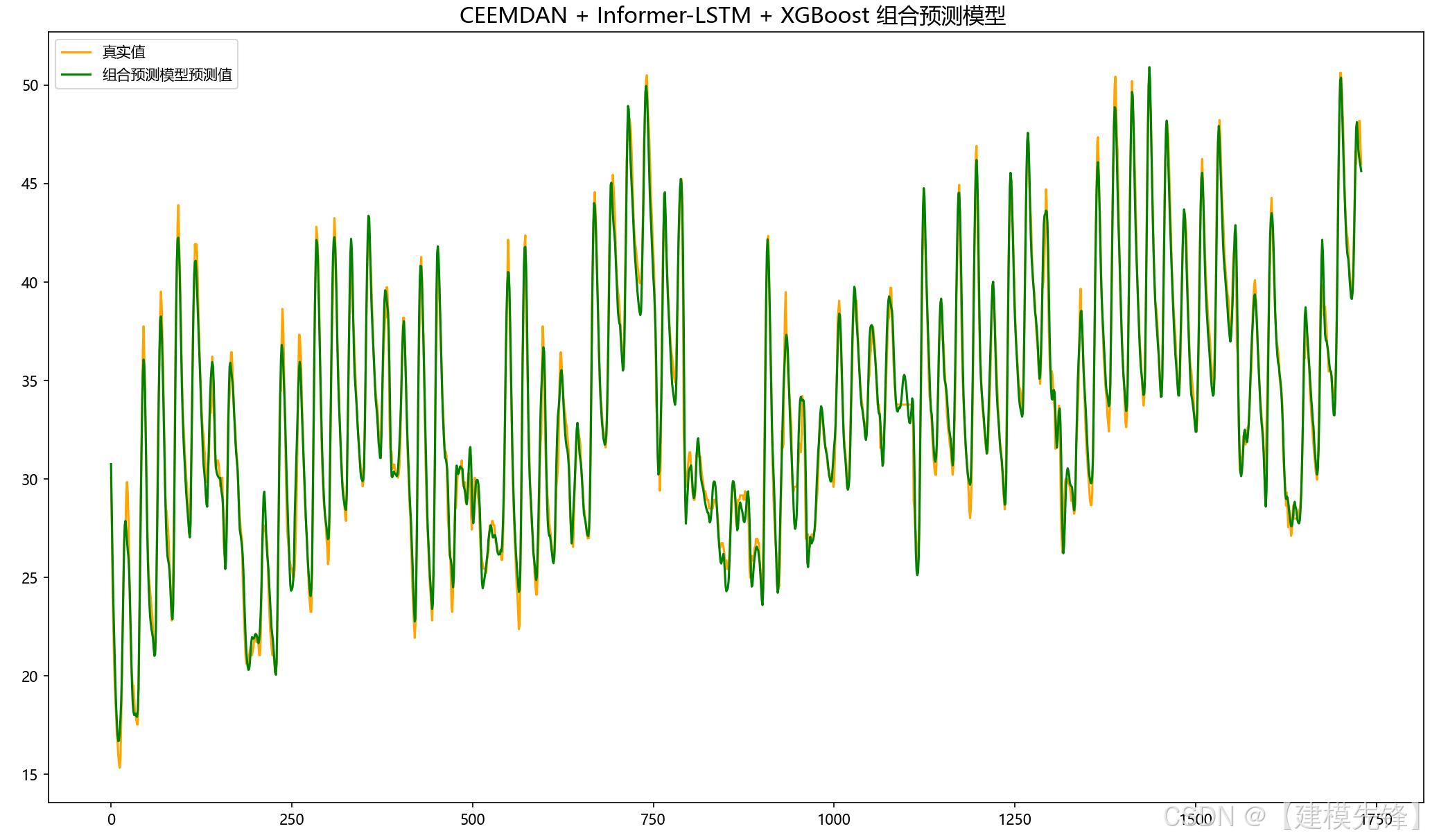
5.2 组合预测结果可视化
5.3 模型评估
由分量预测结果可见,前6个复杂分量在Informer-LSTM并行预测模型下拟合效果良好,后5个简单分量在XGBoost模型的预测下,拟合程度特别好,组合预测效果显著!

6 代码、数据整理如下:
点击下方卡片获取代码!