pivot_table()透视表
python
sales.pivot_table(
values = 'Revenue',
index = 'Date',
columns = 'Name',
aggfunc = 'sum',
fill_value = 0,
margins = True,
margins_name = '总计'
)使用 Pandas 的 pivot_table 函数将一个名为 sales 的 DataFrame 转化为透视表。
1. sales.pivot_table(...)
sales: 这是你的 DataFrame 的名称,包含了你要进行透视分析的数据。
2. values='Revenue'
values: 指定你要聚合的列的名称,这里是要聚合Revenue列。
3. index='Date'
index: 指定要作为透视表行索引的列的名称,这里是要按Date列进行分组。
4. columns='Name'
columns: 指定要作为透视表列索引的列的名称,这里是要按Name列进行分组。
5. aggfunc='sum'
aggfunc: 指定对values列进行的聚合函数,这里是要对Revenue列进行求和。
6. fill_value=0
fill_value: 指定透视表中缺失值的填充值,这里将所有缺失值填充为 0。
7. margins=True
margins: 指定是否计算行和列的总计,这里是要计算总计。
8. margins_name='总计'
margins_name: 指定行和列总计的名称,这里将总计的名称设置为 "总计"。
总结:
这段代码将
salesDataFrame 中Revenue列的值按照Date列和Name列进行分组,并使用sum函数对每个分组的Revenue值进行求和,最终生成一个透视表。透视表中将Date列作为行索引,Name列作为列索引,每个单元格的值表示对应日期和名字的Revenue之和。此外,代码还计算了行和列的总计,并将总计的名称设置为 "总计"。
示例:假设
salesDataFrame 包含以下数据:
Date Name Revenue 2023-01-01 Alice 100 2023-01-01 Bob 200 2023-01-02 Alice 150 2023-01-02 Charlie 300 执行这段代码后,生成的透视表将如下所示:
Alice Bob Charlie 总计 2023-01-01 100 200 0 300 2023-01-02 150 0 300 450 总计 250 200 300 750
stack() 多变单
将一个多层索引 DataFrame(
by_name_and_date)转换为一个单层索引 DataFrame。解释:
by_name_and_date: 这是一个 DataFrame 对象,其索引是多层的。这意味着它的索引包含多个级别,例如,可能包含Name和Date两个级别。
stack(): 这是一个 Pandas DataFrame 的方法,用于将 DataFrame 的多层索引转换为单层索引。具体来说,它会将 DataFrame 的列索引(最内层索引)提升到行索引中,并将原来的行索引和列索引合并成一个新的行索引。
示例:
by_name_and_date DataFrame 如下所示:
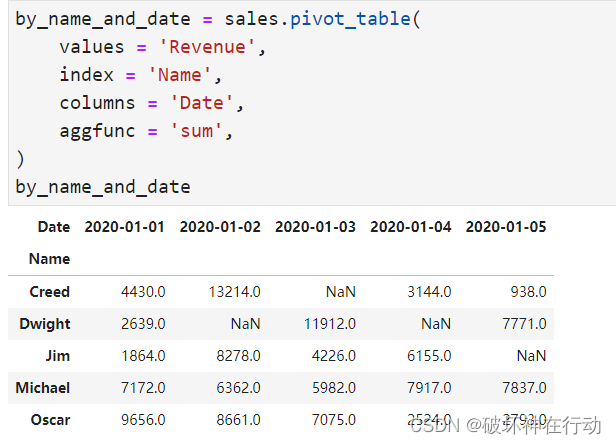
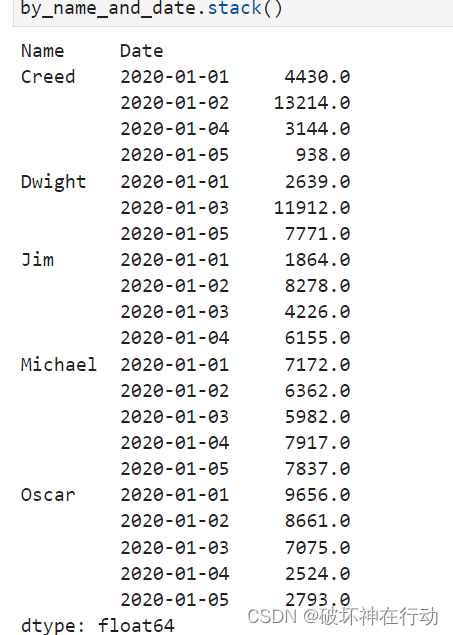
执行 by_name_and_date.stack() 后,DataFrame 将变为:
unstack() 单变多
将一个多层索引 DataFrame(
sales_by_customer)转换为一个具有层次结构的列索引 DataFrame。解释:
sales_by_customer: 这是一个 DataFrame 对象,其索引是多层的。这意味着它的索引包含多个级别,例如,可能包含Customer和Product两个级别。
unstack(): 这是一个 Pandas DataFrame 的方法,用于将 DataFrame 的行索引(最内层索引)转换为列索引。具体来说,它会将 DataFrame 的行索引中的一个级别提升到列索引中,形成一个层次结构的列索引。
示例:
sales_by_customer DataFrame 如下所示:
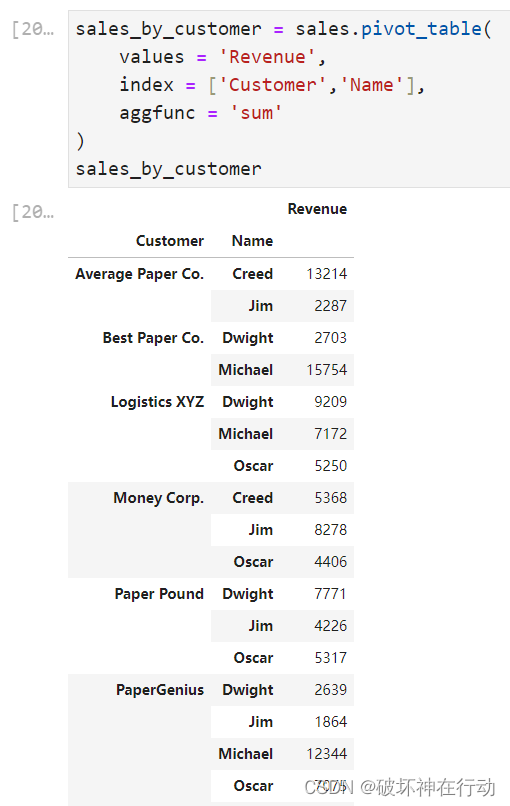
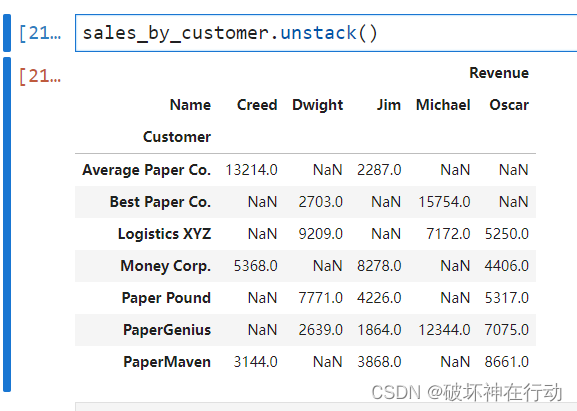
执行 sales_by_customer.unstack() 后,DataFrame 将变为:
melt()
melt()函数用于将宽格式的数据转换为长格式。
重要的参数:
id_vars: 可选参数,指定要保留为标识变量的列名列表。这些列的值将被复制到长格式数据的每一行中,以保持其唯一性。
value_vars: 可选参数,指定要转换为长格式的列名列表。如果未指定,则默认为除了"id_vars"之外的所有列。
var_name: 指定在转换后的DataFrame中,新生成的列(用来表示原宽格式列名)的名称,默认为'variable'。
value_name: 指定在转换后的DataFrame中,新生成的列(用来存放原宽格式列的值)的名称,默认为'value'。
col_level: 如果DataFrame有层次化的列名,此参数可以指定哪一层列名用于melting操作。
ignore_index: 布尔值,默认为False。如果设为True,将重置转换后DataFrame的索引。
pivot_names: 仅在Pandas 1.3及更高版本中可用,用于控制是否将原宽格式列名的层次化信息合并为一个变量名。
宽格式(Wide Format)和长格式(Long Format/Tidy Format)
是数据处理和数据分析中两种常见的数据组织形式。
宽格式的特点是每个变量占据一列,而每个观察对象(如不同的时间点、实验条件等)通常占据一行。这种格式适合于查看某个特定时间点或条件下多个变量的值,但在进行时间序列分析、分组操作或绘制涉及多个变量变化的图表时可能会比较复杂。
长格式则将数据重新组织,使得每个观察结果占据一行,且有明确的变量名和对应的值。一般而言,长格式数据包含三个关键元素:识别变量(如个体ID或时间点)、值变量(测量的数值)和一个或多个变量来标记这些值的属性(如变量名或时间点标签)。这种格式非常适合于统计建模、数据可视化,特别是在需要对不同类别或时间点进行比较和汇总时。
例如,假设我们有一个宽格式的表格记录了几个学生在不同科目上的成绩:
姓名 数学 英语 物理
张三 90 85 88
李四 80 92 90转换为长格式后,它会变成:
姓名 科目 成绩
张三 数学 90
张三 英语 85
张三 物理 88
李四 数学 80
李四 英语 92
李四 物理 90在这个转换过程中,每个学生-科目组合变成了一个单独的行,便于分析或绘图时按科目或学生分组。
python
video_game_sales.melt(id_vars='Name', value_vars='NA')解释:
-
video_game_sales: 这是一个 DataFrame 对象,它包含关于电子游戏销售的数据,可能包含多个列,例如游戏名称、地区销售额等。 -
melt(): 这是一个 Pandas DataFrame 的方法,用于将 DataFrame 从宽格式转换为长格式 。它将 DataFrame 中的多个列转换为两个新的列:variable和value。 -
id_vars='Name': 指定要保留在 DataFrame 中的标识列,这里是要保留Name列,即游戏名称。 -
value_vars='NA': 指定要转换为长格式的列,这里是要将NA列(北美地区的销售额)转换为长格式。
示例:
假设 video_game_sales DataFrame 如下所示:
Name NA EU JP
0 Super Mario 10 5 2
1 Zelda 8 3 4执行 video_game_sales.melt(id_vars='Name', value_vars='NA') 后,DataFrame 将变为:
Name variable value
0 Super Mario NA 10
1 Zelda NA 8explode()
recipes.explode('Ingredients')
使用 Pandas 的
explode()方法将 DataFramerecipes中的Ingredients列展开,将每个包含多个食材的列表拆分成独立的行。解释:
recipes: 这是一个 DataFrame 对象,包含关于食谱的信息,其中Ingredients列存储的是每个食谱的食材列表。explode('Ingredients'): 这是一个 Pandas DataFrame 的方法,用于将 DataFrame 中的指定列展开。explode()的参数是列名,这里是要展开Ingredients列。
示例:假设
recipesDataFrame 如下所示:
Name Ingredients 0 Pizza ['Tomato sauce', 'Cheese', 'Pepperoni'] 1 Salad ['Lettuce', 'Tomato', 'Cucumber']执行
recipes.explode('Ingredients')后,DataFrame 将变为:
Name Ingredients 0 Pizza Tomato sauce 1 Pizza Cheese 2 Pizza Pepperoni 3 Salad Lettuce 4 Salad Tomato 5 Salad Cucumber总结:
recipes.explode('Ingredients')将 DataFrame 中的Ingredients列展开,将每个包含多个食材的列表拆分成独立的行,使得每个食材都对应一个独立的行。
练习
1 在 cars 数据集中,聚合汽车价格的总和。在行轴上按燃料类型分组结果。
2 在 cars 数据集中,聚合汽车的数量。在索引轴上按制造商分组,在列轴上按变速箱类型分组。显示行和列的子总数。
3 在 cars 数据集中,聚合汽车价格的平均值。在索引轴上按年份和燃料类型分组,在列轴上按变速箱类型分组。
4 给定上一个挑战中的 DataFrame,将变速箱级别从列轴移动到行轴。
5 将 min_wage 从宽格式转换为窄格式。换句话说,将数据从八个年份列(2010-17)移动到单个列中。
python
car = pd.read_csv('used_cars.csv')
car
min_wage = pd.read_csv('minimum_wage.csv')
min_wage.head()
#1.
car.pivot_table(
values = 'Price',
index = 'Fuel',
aggfunc = 'sum'
)
#2.
car.pivot_table(
values = 'Price',
index = 'Manufacturer',
columns = 'Transmission',
aggfunc = 'count',
margins = True,
margins_name = 'Total'
)
#3.
car.pivot_table(
values = 'Price',
index = ['Year','Fuel'],
columns = 'Transmission',
aggfunc = 'mean'
)
#4.
c1 = car.pivot_table(
values = 'Price',
index = ['Year','Fuel'],
columns = 'Transmission',
aggfunc = 'mean'
)
c1.stack()
#5.
year = ['2010','2011','2012','2013','2014','2015','2016','2017']
min_wage.melt(id_vars = 'State',var_name = 'Year',value_name = 'wage')