LW-DETR:实时目标检测的Transformer, Apache-2.0 开源可商用,实验超 YOLOv8
- [LW-DETR 架构](#LW-DETR 架构)
- 目的与解法拆解
论文:https://arxiv.org/pdf/2406.03459
代码:https://github.com/Atten4Vis/LW-DETR
DETR系列和YOLO系列,当今目标检测两大分支。
好的,我来简化解释这些内容。
LW-DETR 架构
LW-DETR是一个目标检测模型,主要由三部分组成:ViT编码器,投影器,和DETR解码器。
-
ViT编码器:这是处理图像的第一部分,它将图像划分成小块(称为patches),然后对这些小块进行分析,提取特征。
这个过程包括全局自注意力操作,这种操作虽然能够很好地捕捉图像特征,但计算量很大。
为了降低这部分的计算复杂度,我们引入了窗口自注意力,即只在图像的局部窗口内进行注意力操作。
-
DETR解码器:解码器的任务是根据编码器提供的特征来识别图像中的具体对象,并确定它们的位置。
我们使用了一种特殊的注意力机制(可变形交叉注意力),这可以更高效地计算,从而加快处理速度。
一般DETR模型会用6层解码器,但我们简化为3层,以进一步减少处理时间。
-
投影器:投影器是连接编码器和解码器的桥梁,它处理由编码器生成的特征图,为解码器提供必要的输入信息。
我们还为大型和超大型的模型版本设计了特别的投影器,以处理不同精度(尺寸)的特征图。
实例化
我们设计了不同大小(从微型到超大型)的检测器,以适应不同的需求和资源条件。
每种大小的检测器都有其特定的配置,比如不同层数的编码器和不同数量的对象查询(用于确定图像中的对象)。
高效训练
我们采用了多种技术来加速DETR的训练过程,包括更多的监督信号和预训练技术。
例如,我们使用了一种名为Group DETR的变体,这种方法在训练时使用多个解码器,但在实际使用时只选用其中一个。
高效推理
为了在实际应用中快速处理图像,我们对注意力机制进行了优化,引入了交错的窗口和全局注意力。
这意味着模型在处理一些层时使用窗口注意力,在其他层使用全局注意力,以此减少计算需求并加速处理。
想象你正在组织一个大型晚宴,你需要迅速而准确地识别和迎接每位宾客。
在这个情景中,你的大脑就像一个"检测器",宾客就是需要识别的"目标"。
-
轻量级的DETR方法:这就像是你用一个更简洁高效的方法来检查和确认宾客的身份,比如通过一种特别快速的签到程序。这个方法不需要复杂的设备,只需要基本的工具就能快速完成工作。
-
ViT编码器和DETR解码器:这个可以比喻为你有一个名单(编码器),上面记录了所有宾客的特征。每当有宾客到来,你就通过一个特殊的流程(解码器)来检查他们是否在名单上,并且确保每个人的身份都正确无误。
-
多级特征图聚合:想象你不仅仅是看宾客的脸,还要观察他们的穿着、行为等多个方面的特征,这样可以更准确地识别每个人。
-
变形交叉注意力:这就像你在与多个宾客交谈时,能够根据对话中的重要信息(如他们提到的名字或他们提到的其他宾客)来迅速调整你的注意力焦点。
-
窗口注意力和全局注意力:这可以理解为你在宴会中采用两种策略:一种是专注于一个小群体的宾客(窗口注意力),另一种是时不时地扫视整个房间以确保不漏掉任何人(全局注意力)。通过这样的策略,你可以更有效地管理你的注意力,避免因为同时注意太多事情而导致混乱。
精细拆解:
-
ViT编码器和DETR解码器:ViT编码器处理输入的图像以提取特征,而DETR解码器则使用这些特征来精确识别和定位图中的对象。
-
多级特征图聚合:通过结合不同层次的特征图,该技术增强了模型对图像中各种尺寸和复杂度对象的识别能力。
-
变形交叉注意力:这是一种高级注意力机制,能够根据目标对象的具体特征动态调整关注区域,从而提高检测的精度和效率。
-
窗口注意力和全局注意力:窗口注意力专注于图像的局部区域以减少计算负担,而全局注意力覆盖整个图像,确保广泛的环境因素被考虑,两者交替使用以优化性能。
目的与解法拆解
ViT编码器和DETR解码器
解法 = 图像特征提取 + 目标定位与识别
-
图像特征提取:使用ViT编码器从输入图像中提取复杂的特征图。
- 之所以用图像特征提取,是因为高质量的特征图可以更好地表示图像中的内容,从而提高后续处理的准确性。
- 例如,在一个人群照片中,精确的特征提取可以帮助模型区分不同个体的面部特征。
-
目标定位与识别:通过DETR解码器利用特征图来精确识别和定位图像中的各种对象。
- 之所以用目标定位与识别,是因为准确的对象识别和位置定位对于实时检测系统至关重要。
- 例如,自动驾驶车辆需要实时准确地识别和定位行人和其他车辆以避免碰撞。
变压器编码器:
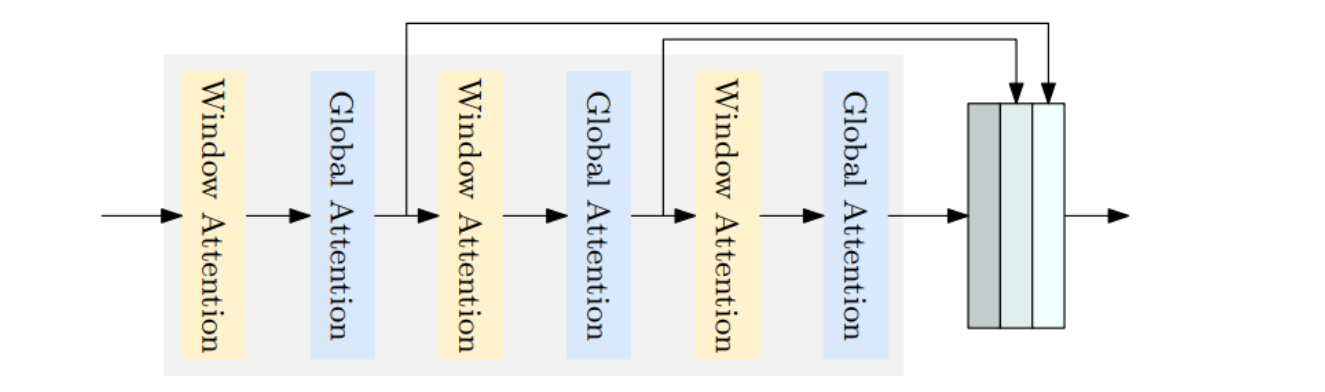
这张图展示了变压器编码器中多级特征图聚合和交错窗口及全局注意力的应用。
编码器处理输入的特征图,通过不同的注意力机制(窗口注意力和全局注意力)增强这些特征图的信息。在这里:
- 窗口注意力:仅在输入特征图的特定区域内计算注意力,有助于降低计算复杂度。
- 全局注意力:覆盖整个特征图,捕捉远程依赖关系。
这种设计的目的是在保持模型性能的同时减少计算负担。
单尺度投影器和多尺度投影器:
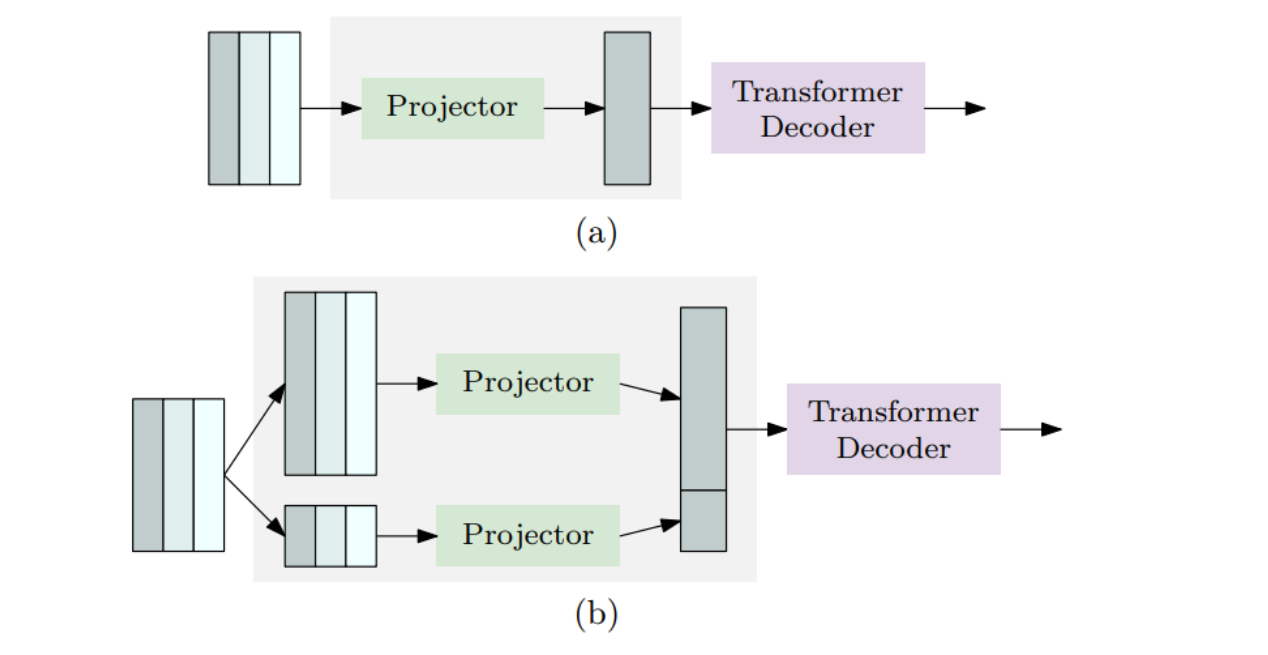
这张图说明了用于不同模型大小(微型、小型、中型和大型、超大型)的投影器配置。
- 图3a:适用于微型、小型和中型模型的单尺度投影器。在这种设置中,编码器输出的特征图通过一个投影器处理,然后输入到变压器解码器中。
- 图3b:适用于大型和超大型模型的多尺度投影器。这里,输入的特征图先经过不同尺度的处理(例如,通过上采样或下采样),然后这些不同尺度的特征图分别通过各自的投影器处理后,共同输入到变压器解码器中。
这种多尺度处理方法允许模型更有效地处理不同大小的输入特征图,从而提高了模型对于不同尺寸目标的检测能力。
这对于需要处理广泛尺寸变化的实时目标检测任务尤其重要。
多级特征图聚合
解法 = 特征图层叠 + 特征图优化
-
特征图层叠:将来自不同网络层的特征图合并,形成一个更加丰富的特征表示。
- 之所以用特征图层叠,是因为不同层次的特征图包含不同尺度和细节的信息,聚合这些信息可以增强模型对复杂场景的理解能力。
- 例如,在监控视频中,层叠特征图可以帮助模型同时识别远处的小物体和近处的大物体。
-
特征图优化:通过算法优化加工合并后的特征图,以提高特征的有效性和检测性能。
- 之所以用特征图优化,是因为简单的合并可能不足以充分利用各层特征的潜力,优化处理可以进一步提升特征的表达力。
- 例如,在复杂的交通场景中,优化的特征图可以更好地区分交通标志与其他街道元素。
变形交叉注意力
解法 = 动态焦点调整
- 动态焦点调整 :根据目标的形状和位置动态调整注意力焦点。
- 之所以用动态焦点调整,是因为不同的对象和场景要求模型在不同区域集中资源和计算力,以提高效率和准确性。
- 例如,在处理运动中的对象时,动态调整可以帮助模型跟踪目标并减少背景干扰。
窗口注意力和全局注意力
解法 = 局部关注 + 整体评估
-
局部关注:聚焦于图像的小窗口区域,进行细致的分析。
- 之所以用局部关注,是因为它可以减少不必要的全局计算,专注于可能含有关键信息的区域。
- 例如,在一个拥挤的市场场景中,局部关注可以帮助模型集中处理可能存在安全威胁的特定区域。
-
整体评估:定期扫描整个图像,确保没有错过任何重要的全局信息。
- 之所以用整体评估,是因为单纯的局部关注可能遗漏一些关键的全局事件或背景变化,整体评估确保全面覆盖。
- 例如,在自然灾害监测中,整体评估可以帮助识别突发事件的全貌,如洪水或火灾的扩散。