目录
- 标题
- 摘要
- 引言
- 背景
- 用于协同设计的深度学习系统中的编译技术
- [Buddy-Compiler: 一个针对协同设计的深度学习编译器框架](#Buddy-Compiler: 一个针对协同设计的深度学习编译器框架)
-
- [Buddy Compiler 概述](#Buddy Compiler 概述)
- 总结
标题

从标题可以看出,这篇文章是一个综述,内容上主要是关于深度学习中的编译器技术。Co-Design 可以理解为软硬件协同设计,它可以包括:
- 硬件设计:开发专用集成电路(ASIC)或张量处理单元(TPU)等硬件来加速深度学习计算。
- 软件设计:开发和优化深度学习模型、算法以及编译器技术,充分利用硬件的性能。
直白点来说,就是在深度学习模型推理领域,设计硬件时要考虑软件(设计硬件时要考虑算法是怎么做的等等),设计软件时要考虑硬件(设计编译器时要考虑指令在硬件平台上是如何计算的等等),以达到硬件和算法最佳表现。
摘要
深度学习的应用飞速在发展,但是在硬件方面因为摩尔定律的失效导致通用的处理器无法满足深度学习模型的需求,因此需要专用的硬件来加速深度学习计算。本文详细阐述了过去有关深度学习中编译器以及协同设计的工作。 最后,作者针对典型的深度学习协同设计系统提出了一种特定领域的编译框架------Buddy Compiler。
引言
通用处理器无法满足深度学习任务的性能和功耗要求。因此,工业界和学术界都致力于软硬件协同设计,在这个过程中,编译器技术是非常重要的一个环节。
在深度学习软硬件协同设计中,硬件架构的创新是根本,软件设计(算法)是关键,从软件到硬件的映射决定了效果。深度学习系统负责映射和优化,这个过程分为模型级优化、工作负载优化和工作负载映射和硬件接口。为了获得更高的性能,需要在整个过程中进行调整,这对于协同设计至关重要。在实践中,最直接的调优方法是与软硬件团队沟通确定需求。
随着当前深度学习框架和硬件平台的碎片化(意思就是上有各种各样的深度学习框架,下游有各种各样的硬件平台------LPU,TPU,GPU...),编译技术可以在协同设计中发挥关键作用,以避免组合爆炸问题(M中深度学习框架,N中硬件平台,那么组合起来就是MxN中解决方案)。编译技术的本质是抽象,软件和硬件的抽象正在走向统一的IR。
这篇文章的主要贡献如下:
- 概述了深度学习软件、硬件、协同设计和系统的发展。
- 总结了深度学习协同设计系统的关键技术。
- 从软件和硬件两个角度对协同设计中编译技术进行了分析。
- 讨论了协同设计中编译技术的当前问题和未来趋势。
- 提出了一种特定领域的编译框架------Buddy Compiler。
背景
深度学习软件和硬件的发展
这部分主要介绍了从1960年开始到深度学习软件和硬件的发展历程,可以用下面这张图概括:

在2000年后,Dennard Scaling(丹纳德缩放定律)开始失效。然后人们引入了多核设计,虽然多核的设计没有直接解决功耗问题,但是它通过引入更多的并行度进一步提高了性能,然后深度学习任务本身就有很高的并行性,所以两者刚好对应上。
**丹纳德缩放定律:**在一个集成电路上,当晶体管的尺寸缩小时,他们在芯片上的密度增加,使得在相同面积的芯片上可以容纳更多的京替换;晶体管尺寸缩小的同时,电压和电流也按比例缩小,以保持功率密度恒定,尽管功率密度保持恒定,更多的晶体管意味着更高的性能和更强的计算能力,这个定律是由Robert H. Dennard在1974年提出的。然而,Dennard Scaling并不是无限制地有效,当晶体管变得非常小时,漏电流增加,导致功耗增加;电压降低到一定程度后,进一步降低电压变得困难,这限制了功率密度的控制;尽管功率密度保持恒定,但整体功耗增加,导致散热问题变得更为严重。
不同时期的协同设计
软硬件协同设计是一种硬件和软件的联合设计方法,以实现协同并满足系统约束,例如性能和功耗。如上图所示:在神经网络的早期兴起和衰落过程中,软件和硬件是交替发展的。到了2010年代,深度学习的硬件和软件开始协同设计,为广泛的协同设计提供了机会。协同设计的范围很大,在不同时期和领域提出了各种方法,软硬件协同设计大约有30年的历史。
深度学习协同设计系统
深度学习系统可以帮助开发者减小开销,在不同层级提供优化的机会。整个系统如下图所示:

包括了端到端的深度学习软件和硬件系统,硬件发展方法和协同设计技术。
神经网络架构设计和优化
神经网络架构优化可以减少模型的计算复杂度,常用的方法有设计高效的模型结构、剪枝、量化、硬件感知神经架构搜索等。除过这些,使用编译器技术的协同设计的方法可以获得更好的结果。
协同设计技术
我们相信协同设计的本质是在软件优化和硬件优化之间取得trade-off。在实际中,软件和硬件开发者需要理解对方的设计,高效沟通,一起做决定。根据我们的经验,通用的协同设计过程包括约束的指定,接口的设计,优化策略的迭代。
用于协同设计的深度学习系统中的编译技术
一个传统的编译器可分为三个部分:前端解析语言;中端优化IR;后端生成硬件指令。
深度学习编译器
深度学习编译器的基础设施包括:前端导入,高级语言绑定,多级IR和它的括展机制,张量操作,数据结构,优化过程和管理器以及硬件平台的工具集成。在这些里面,优化技术和IR设计最为重要,因为它们分别决定了执行性能和开发效率。
深度学习编译器的优化可以更好地将神经网络工作负载映射到硬件。深度学习编译器通常将整个模型拆分为子图,然后将图级优化技术应用于子图,例如层优化,算子融合和常量折叠。随后,IR被转换为较低的抽象级别,以进行循环级和硬件相关的优化,例如循环重新排序、循环平铺和内存相关的优化。
XLA,OpenVINO,Glow等编译器定义自己的IR,和对应的前端,优化和后端支持。这些编译器的IR无法复用,必须重复开发优化。为了提升开发效率,深度学习编译器正在形成统一的生态系统。目前主要有两种生态系统,一个是TVM,一个是MLIR。
TVM 生态系统和MLIR生态系统
TVM 将不同深度学习框架的模型转换为一个统一的IR系统,避免了多个前后端带来的组合爆炸问题。TVM使用了Halide的思想,将算法和调度解耦,强大的自动调优和自动调度能力提供高性能的解决方案。在生态系统中,自动内核生成添加了多面体变化来优化张量表达式(TE)。
MLIR 提供了一个核心的抽象,名为方言(dialects),强大的扩展能力。用户可以轻易地添加新的方言和自定义的算子,类型和属性。一些编程模型和特定领域的编程语言也已经纳入MLIR生态系统,例如Triton使用MLIR来做GPU的代码生成。
总的来说,TVM是一个端到端的深度学习编译器,而MLIR是一个可复用以及可扩展的编译基础设施。虽然他们的核心理念不同,但是构建的生态系统具有可比性。TVM的可扩展性源于张量表达和优化机制,并提供强大的自动化设计来实现高的性能,然而它的领域可扩展性相对有限。MLIR的可扩展性源于IR的设计和LLVM集成,强大的IR扩展机制允许更大的生态系统。但是具体的实施需要足够的领域知识和经验才能达到预期的结果。下图展示了TVM和IREE的比较:
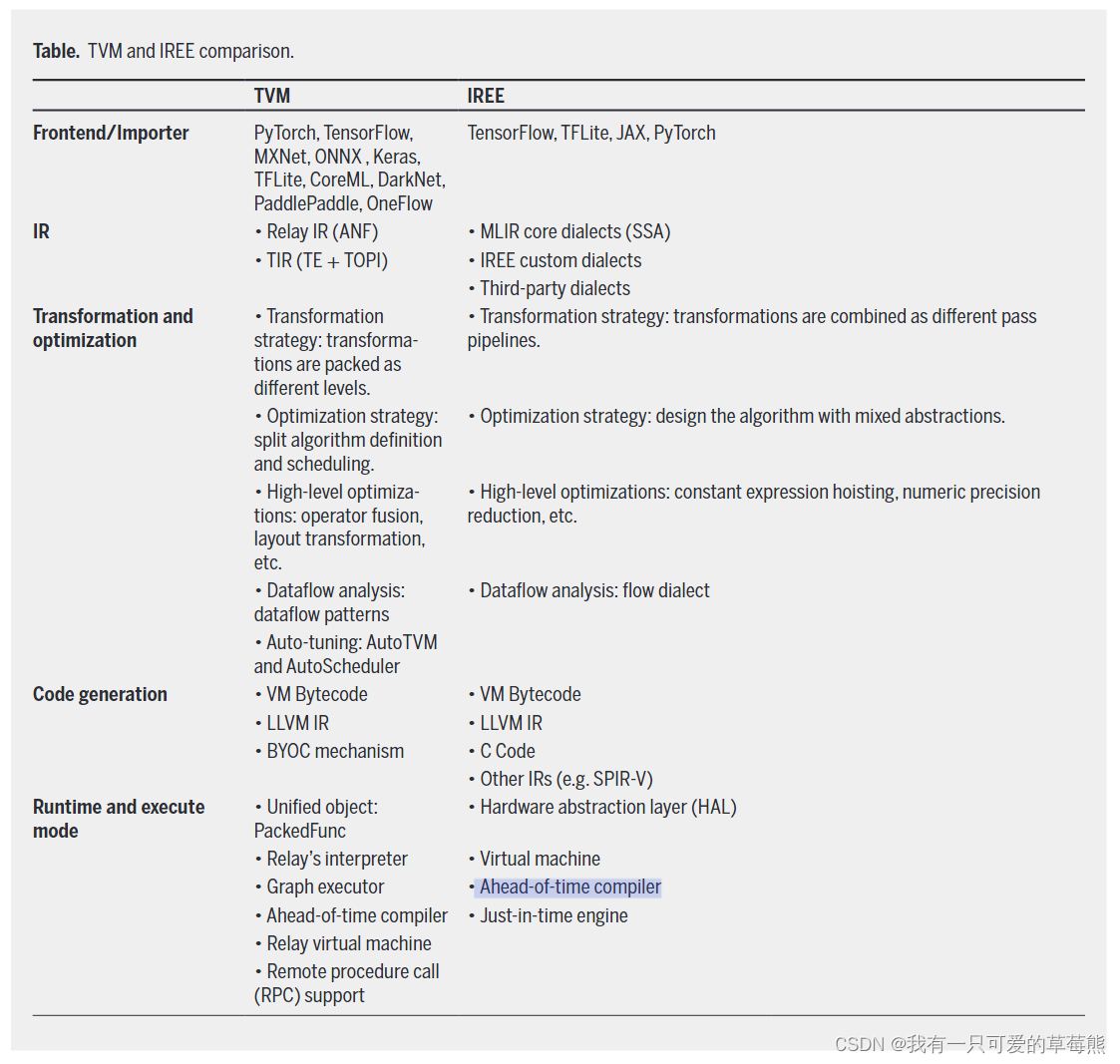
AOT 编译:编译时机,在程序运行之前,将源代码编译成机器码或中间语言;运行时,程序运行时使用已经编译好的代码,省去了运行时的编译步骤。
JIT编译:编译时机,在程序运行时即时编译,将字节码或中间语言语言转为机器码;运行时,程序在执行过程中实时编译和优化代码。
IR
IR是编译器中最重要的部分,它用来解耦深度学习框架和硬件平台。传统编译器的IR在程序语言和目标之间搭建了一个桥梁,并在IR上进行编译优化。深度学习编译器也要依赖传统编译器的IR,这是为了重用他们现有的后端生成能力。LLVM IR 是最广泛使用的传统IR。然而LLVM IR 只有单级抽象和细粒度操作,所以很难将高级抽象和粗粒度操作的深度学习模型映射到它上面去。因此,编译器会定义一个高级的IR来解决这个问题。不同级别的IR旨在扩大优化空间并缩小与低级别IR的差距,虽然多级IR并不是一个新的编译技术,但却是深度学习编译器的一个重要特性。
TVM 的IR设计可以分为两个级别。Relay IR负责映射深度学习模型和执行图级别的优化,Tensor IR(TIR)负责调度和调整。Relay IR具有带let-binding 结构的函数式风格,支持自动微分。在降级的过程中,TVM 提供TE来构建TIR,并且TE支持各种调度原语来指定优化(例如:平铺,向量化和并行化)。另外,TVM使用TOPI机制来定义常用的算子,可以减小手动编写TE的开销。经过调度和调整后,生成的TIR进一步被转为LLVM IR。
MLIR使用方言的概念来表达一个抽象级别。在IREE项目中的IR可以分为MLIR核心方言,IREE自定义方言,和第三方的方言。作为基础设施,MLIR提供了很多机制来帮助用户设计IR。它提供了一个ODS框架来定义IR。
TVM IR设计与MLIR的思路相似,但原则和系统上存在差异。本质区别在于IR的结构,虽然两者都代表深度学习模型的数据流,但TVM使用的非范式(ANF) IR结构和MLIR 使用的SSA IR结构不同。基于ANF的设计可以轻松表达功能语义和指定计算范围,从而消除语义上的歧义。基于SSA的设计可以轻松执行例如常量传播以及死代码消除这样的优化。
总结就是:TVM好上手,但是对于编译器的开发者来说难以扩展;MLIR提拱了模块化的IR设计,减少开发时间,但是对编译器的使用者要求较高
转换和优化
深度学习编译器可以执行转换和优化来提升模型执行效率。在图级别,优化方法主要包括高级抽象中的融合和数据布局转换。fusion可以减少内存访问和中间数据的通信开销,数据布局转换可以产生后端友好的数据格式。
在进一步降级后,可以执行基于滑动窗口的 peehole optimization 和 基于数据流分析的全局优化。与此同时,可以采用许多具体的优化算法来利用硬件加速架构。以CPU为导向的优化方法主要包括SIMD/vector扩展的向量化 ,针对多核架构的并行计算 以及针对内存层次结构的内存访问优化。 虽然GPU 没有CPU那么大的cache和频率,但是他们的高吞吐和并行结构帮助加速模型。因此,以GPU为导向的加速方法通常采用多线程和访存优化。对于不同的架构,auto-tuning 技术可以提高编译器优化的效率。编译器将优化策略参数化以此形成一个搜索空间,目标机器报告每个搜索步骤的结果。不断迭代搜索过程,直到满足目标约束。除了依赖编译器优化之外,程序员还可以使用硬件编程模型手动优化代码。有了许多的优化技术,下面讨论实现优化的编译器基础设施。
在IR级别,TVM 和 IREE都可以实现上述优化。然而,优化策略的实现不同。TVM 拆分算法的定义和调度,这样可以增加算法的可读性并允许有效利用调度表示进行调优。IREE使用MLIR 基础设施来添加自定义的方言并且使用混合抽象来实现优化passes。TVM和IREE中的优化策略都被实现为编译器中的pass,每一个pass都是IR级别的转换,pass基础设施具有相似的组件来管理定义,注册和执行。实现细节的差异源于不同的IR设计。MLIR引入了一种声明式的定义机制,允许pass支持灵活和可扩展的IR。多级抽象设计,加上混合方言的使用策略,在MLIRpass pipeline 中提出了挑战。一些高级优化passes 通过多种方言需要仔细安排passes才可以达到预期效果。
代码生成
传统编译器的代码生成是将IR转为目标平台的汇编代码,这个过程中的关键是指令选择和寄存器分配。指令调度可以在寄存器分配之间和之后执行,生成高质量的代码来利用ILP(指令级并行性)。
深度学习编译器执行模型,根据不同的执行方法生成相应的代码,并将生成的代码提供给处理器和执行器。 在这一部分,代码生成被分为机器代码生成和引擎指令执行。
运行时和执行模式
IR抽象出了深度学习模型的结构,代码生成将IR翻译为可以行文件。为了在目标硬件平台上运行这些可执行程序,有必要维护一个与操作系统和其他系统软件交互的运行时环境。
与程序执行类似,深度学习模型可以分为AOT编译,解释性执行和即时(JIT)编译。AOT编译 将模型转为机器码,并将其他程序链接到可以直接在目标机器上运行的可执行文件。解释执行 与将代码直接编译为机器码的方式不同,在解释执行中,程序并不会被完全编译为底层机器码,而是被转换成某种中间表示(如抽象语法树AST,图表示或者字节码),然后由解释器或虚拟机(VM)逐步解释和执行这些中间表示。JIT编译结合了AOT编译和解释执行的特性,在运行时将IR编译为机器码,可以根据运行时信息、平衡性能和灵活性进一步优化。
Buddy-Compiler: 一个针对协同设计的深度学习编译器框架
如下图所示,这个框架被分为5个模块:compier框架,benchmark框架,DSA平台,协同设计模块以及compiler作为服务平台。

- compiler框架(buddy-mlir)可以帮助开发者轻松设计和实现针对具体领域的编译器。
- benchmark框架(buddy-benchmark)可以帮助开发者评估性能。
- ...
Buddy Compiler 概述
作为一个编译器框架,buddy Compiler基于MLIR和RISC-V致力于构建一个可扩展和灵活的硬件-软件协同设计的生态系统。
Compiler模块
编译器模块(buddy-mlir)围绕MLIR构建,专门用于为DSL到DSA提供编译支持。 关于DSL支持,语言绑定具有成熟的实现方法,尤其是Python绑定。前端可以使用MLIR的Python绑定与深度学习框架(Pytorch2.0)进行对接,也具有独立的DSL支持,通过Antlr实现DSL到MLIR的映射,简化了编译器开发。中端通过自定义的MLIR方言,实现特定领域的优化。
Benchmark模块
Benchmark 模块主要是提供多级性能评估。
DSA模块
DSA模块主要是为了基于RISC-V的可编程加速器的设计和实现,并为软硬协同设计提供接口。在可编程方面,RISC-V生态系统是现在最好的选择,因为它的模块和可扩展的设计概念,并且buddy-mlir模块支持自定义RISC-V指令集的编译。从协同设计的角度来看,硬件和软件的交集是MLIR。
总结
在神经网络的历史上,软件和硬件彼此相互推动,在过去的十年中,协同设计越来越重要。在计算机架构和特定领域编译器的黄金年代,我们认为基于编译器技术的协同设计方法将会是未来深度学习系统的突破口。