工作中的消息队列用的是Kafka,一直没有系统的了解,这边集中整理一下。
目录
7.Replica(副本机制)(和分区结合起来是Kafka实现高可用和负载均衡的原理)
[9.Consumer Group(消费者组)](#9.Consumer Group(消费者组))
[10.Consumer Offset(偏移量)(Kafka,单分区消息顺序消费的原因)](#10.Consumer Offset(偏移量)(Kafka,单分区消息顺序消费的原因))
Kafka作为消息队列(当然它不仅仅只有消息队列这一个应用场景。)
Kafka主要组件有十个部分。
1.Broker(服务器)
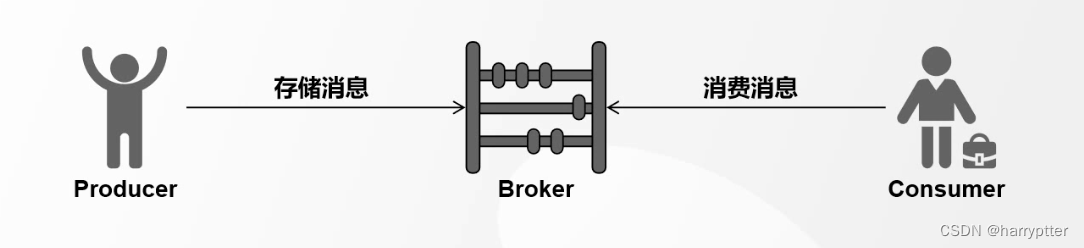 a)Broker就是Kafka的服务器,用于存储和管理消息,默认是9092端口
a)Broker就是Kafka的服务器,用于存储和管理消息,默认是9092端口
b)生产者和Broker建立连接,将消息发送到服务器上存储起来
c)消费者跟Broker建立连接,订阅和消费服务器上存储的消息。
2.Record(消息)
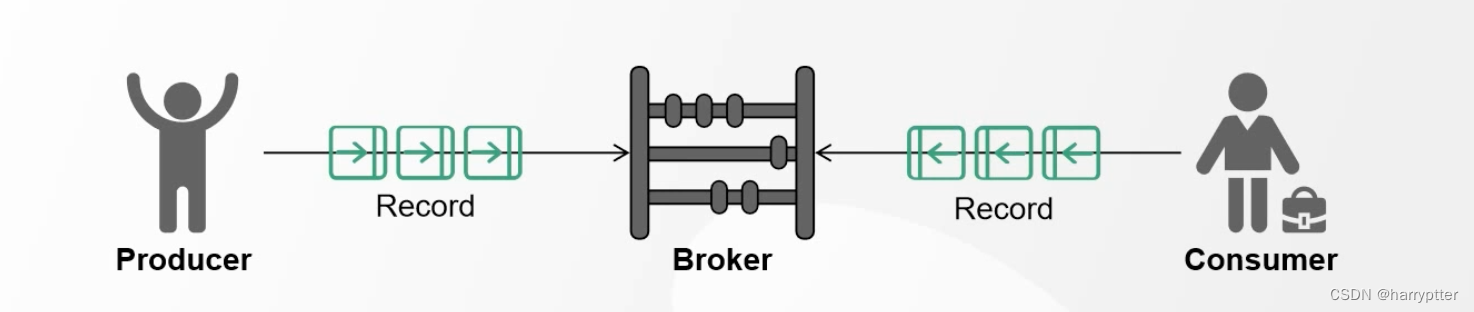 a)客户端传输的数据叫做消息,在Kafka中也叫Record.
a)客户端传输的数据叫做消息,在Kafka中也叫Record.
b)Record在客户端是一个KV键值对(ProducerRecord, ConsumerRecord)
c)Record在服务端是一个KV键值对(RecordBatch(批量发送) 或 Record).
3.Producer(生产者)
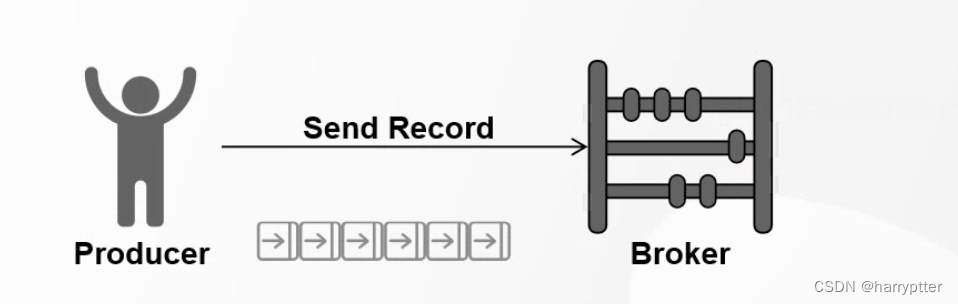 发送消息的一方称为生产者,
发送消息的一方称为生产者,
Kafka为了提升消息发送速率,生产者默认采用批量发送的方式发送消息至Broker,
一条发送多少条由参数batch.size决定(默认16K)
4.Consumer(消费者)
 a)订阅,接收消息的一方叫消费者
a)订阅,接收消息的一方叫消费者
b)消费者获取消息有两种模式:Pull模式(拉)(消费者主动从消息队列中获取消息),Push模式(推)(Broker把消息推送给消费者)
Kafka采用的是Pull模式,因为Kafka是支持大数据的,如果采用Push模式的话,海量数据可能把下游消费端给打爆,所以Kafka采用Pull模式推送消息
c)Pull模式,消费者可以控制一次到底获取多少条消息(max.pull.records 默认是500)
5.Topic(主题)
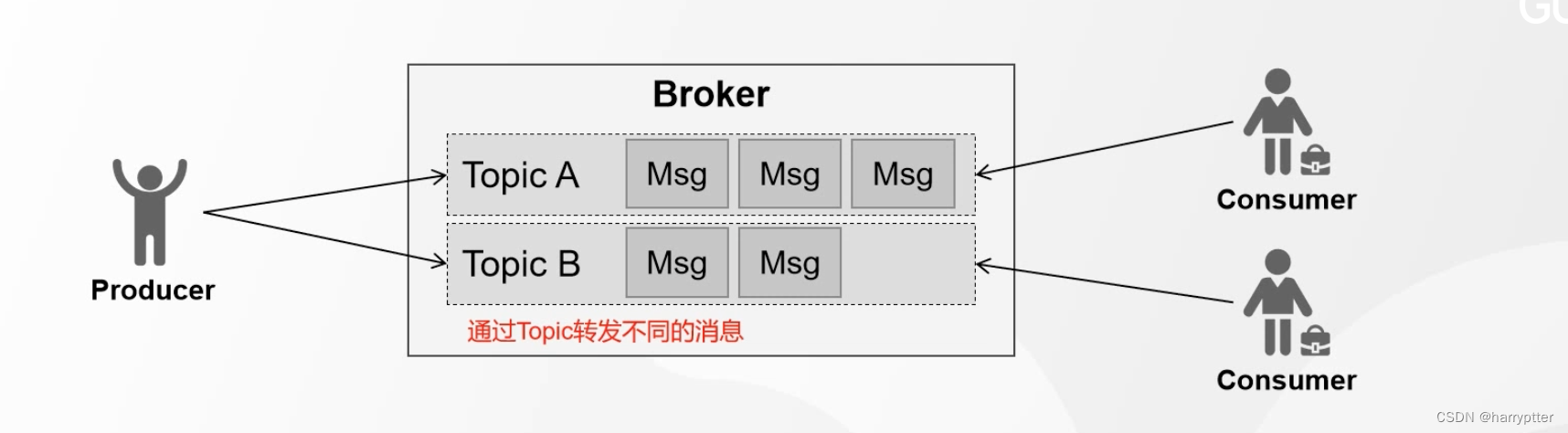
a)topic(主题)一个逻辑概念,可以理解为一组消息的集合
b)生产者和消费者通过topic进行消息的写入和读取
c)生产者发送消息时候,若topic不存在,是否自动创建:auto.create.topics.enable(建议关闭)
6.Partition(分区)

a)分区(Partition)就是把一个topic分成几个不同的部分
b)一个topic在创建时候可以划分多个分区,若没有指定,默认分区数为1,可通过参数修改(num.partitions)
c)Kafka中修改分区规则:可加,不可减
7.Replica(副本机制)(和分区结合起来是Kafka实现高可用和负载均衡的原理)
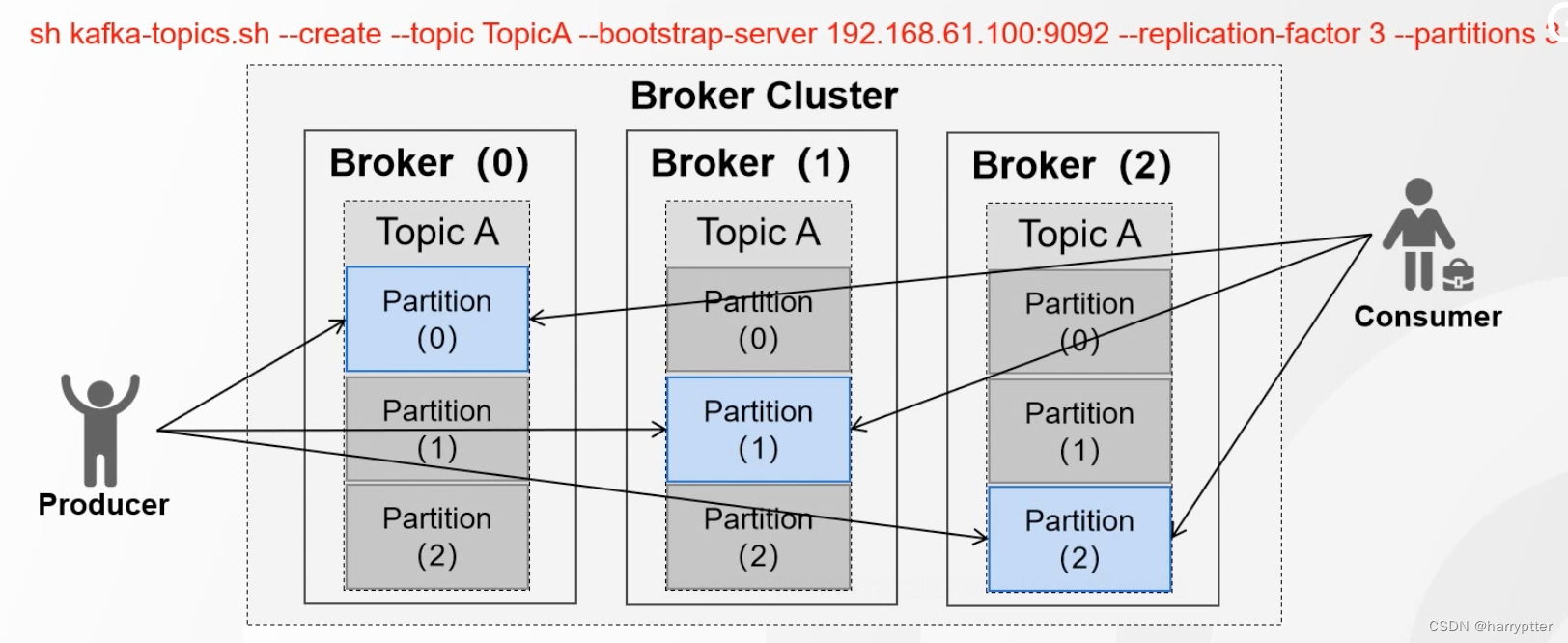
a)Replica(副本)是Partition(分区)的副本,每个分区可以有若干个副本(但是不能超过集群数量)
b)副本必须在不同的Broker上,副本包括了主从节点(Leader(图片中蓝色部分),Foller(图片中灰色部分))
c)服务端可以通过参数控制默认副本数(offsets.topic.repilication.factor)(一般不这样用,一般直接通过命令设置副本数)
生产者只会往leader节点发送消息,消费者也只会从leader节点读取消息,Kafka通过将各消息的leader节点放在不同的Broker(也就是服务器)上,实现了负载均衡,然后个分区follower节点实现了高可用
8.Segment(段)
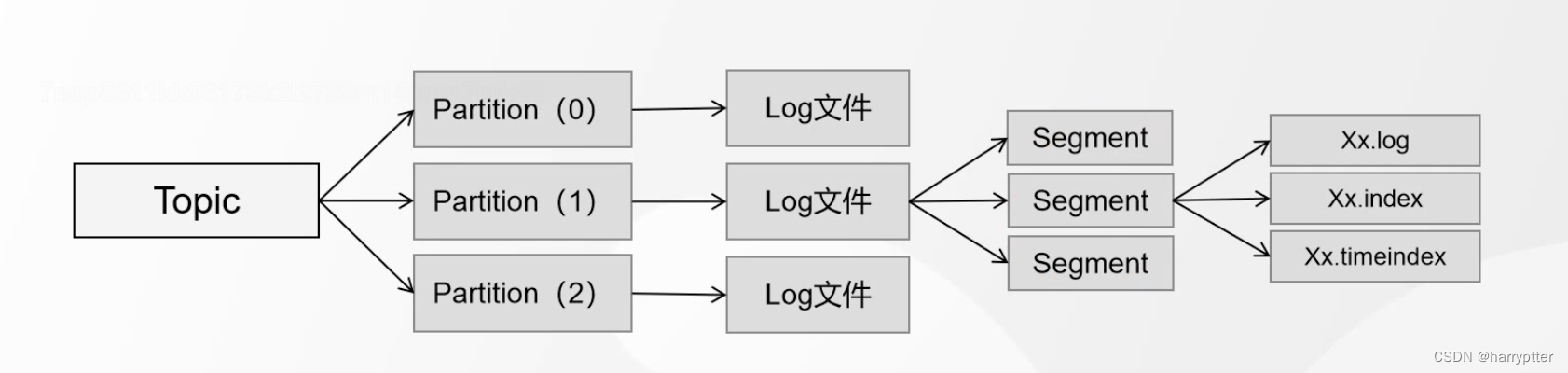
Kafka的数据文件是写在.log文件里面的,另外一起还对生成对应的索引.index文件和对应的时间.timeIndex文件。
但是很容易的可以理解,如果一直往一个log文件里面追加数据,那么长时间使用之后log文件的的查找会随着数据量变大而变慢,所以在这种情况下就引入了Segement段的概念。
a)Segement(端)的目的是:建一个分区的数据划分、存储到不同的文件中
b)每个Segment至少由一个数据文件和2个索引文件构成,3个文件是成套出现的。
c)引入段的意义:
加快查询效率
删除数据时减少逐条IO
d)Segement大小控制:
按时间周期生成 log.roll.hours(默认一周)
按文件大小生产 log.segment.bytes(默认1G)
9.Consumer Group(消费者组)

由于生产者可能短时间内生产大量消息,为了提升消息的消费速率,就增加了消费者组的概念(group id)
a)使用消费者组,提升消费效率和吞吐量
b) 同一个Group中的消费者,不能消费相同的分区(group id相同,在一个组内)
10.Consumer Offset(偏移量)(Kafka,单分区消息顺序消费的原因)
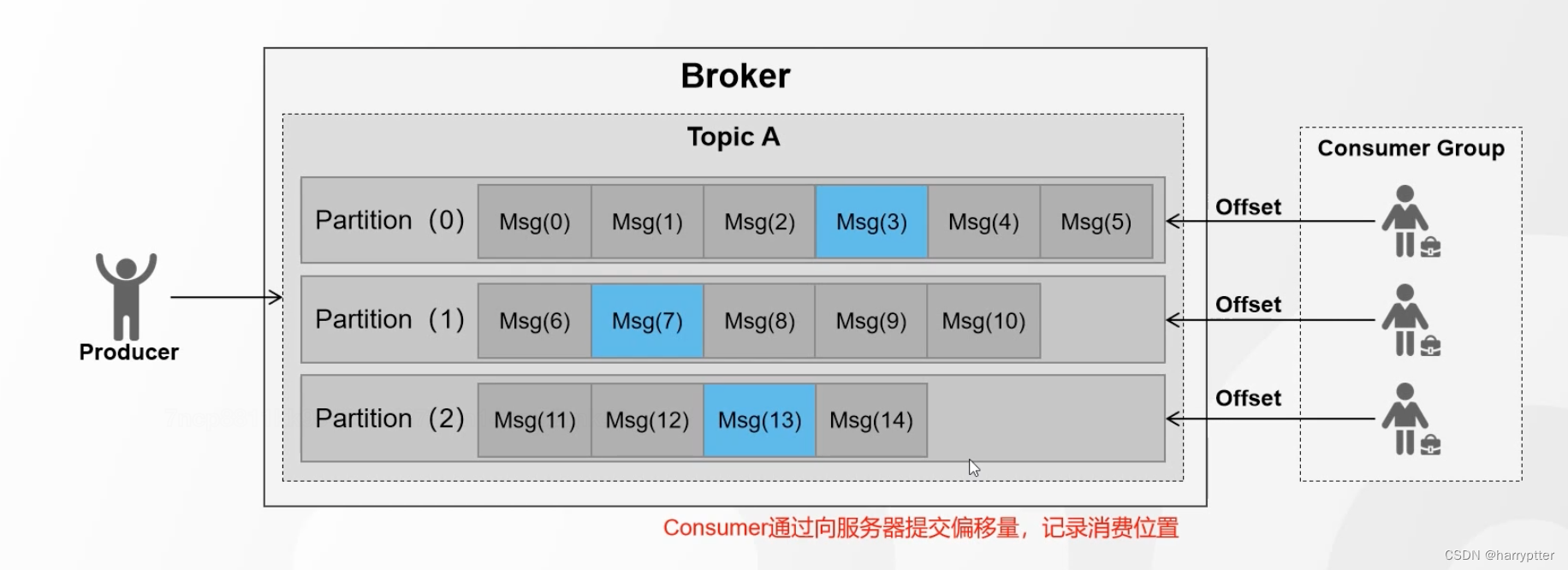
Kakfa在单分区里面的消息是顺序存储的。
a)Offset(偏移量)的目的在于:记录消费者的消费位置
b)Kafka现行版本将Offset保存在服务器(_consumer_offsets)主题中(0.9版本以前是在zooKeeper中)
Kafka的整体架构

上图所示:
集群中有三个Broker,有两个topic,都有三个副本,topic0有两个分区,分区1(图中左上角的Partition(0))的leader在Broker0中,分区2leader在Broker1中,topic1的分区leader在broker2中。
生产者往leader分区(蓝色部分)发送消息时候,leader节点会向follower节点同步备份消息(绿色线条部分)。然后每个消费者组对消息进行消费(红色箭头部分)(想通消费者组的消费者不能消费同一个分区的消息)
Kafka特性
1)磁盘顺序I/O(速度不亚于内存I/O)
Kafka采用的是磁盘顺序I/O
 磁盘顺序I/O相对于随机I/O不同点在于:
磁盘顺序I/O相对于随机I/O不同点在于:
随机I/O,数据存储在磁盘的位置是分散的,所以需要多次磁盘寻址来读取和写入数据。
但是顺序I/O只需要一次磁盘寻址。去除了重复寻址的过程。Kafka的记录是不断追加到本地磁盘的末尾的,所以是顺序I/O。
2)索引
Kafka在Broker端提供了offset索引和timeIndex(时间戳)索引,两种索引采用了稀疏索引的方案
3)批量处理和压缩传递(海量吞吐的基础)
在收发消息的时候批量处理。
压缩算法进行压缩后传递(gzip等)
4)零拷贝
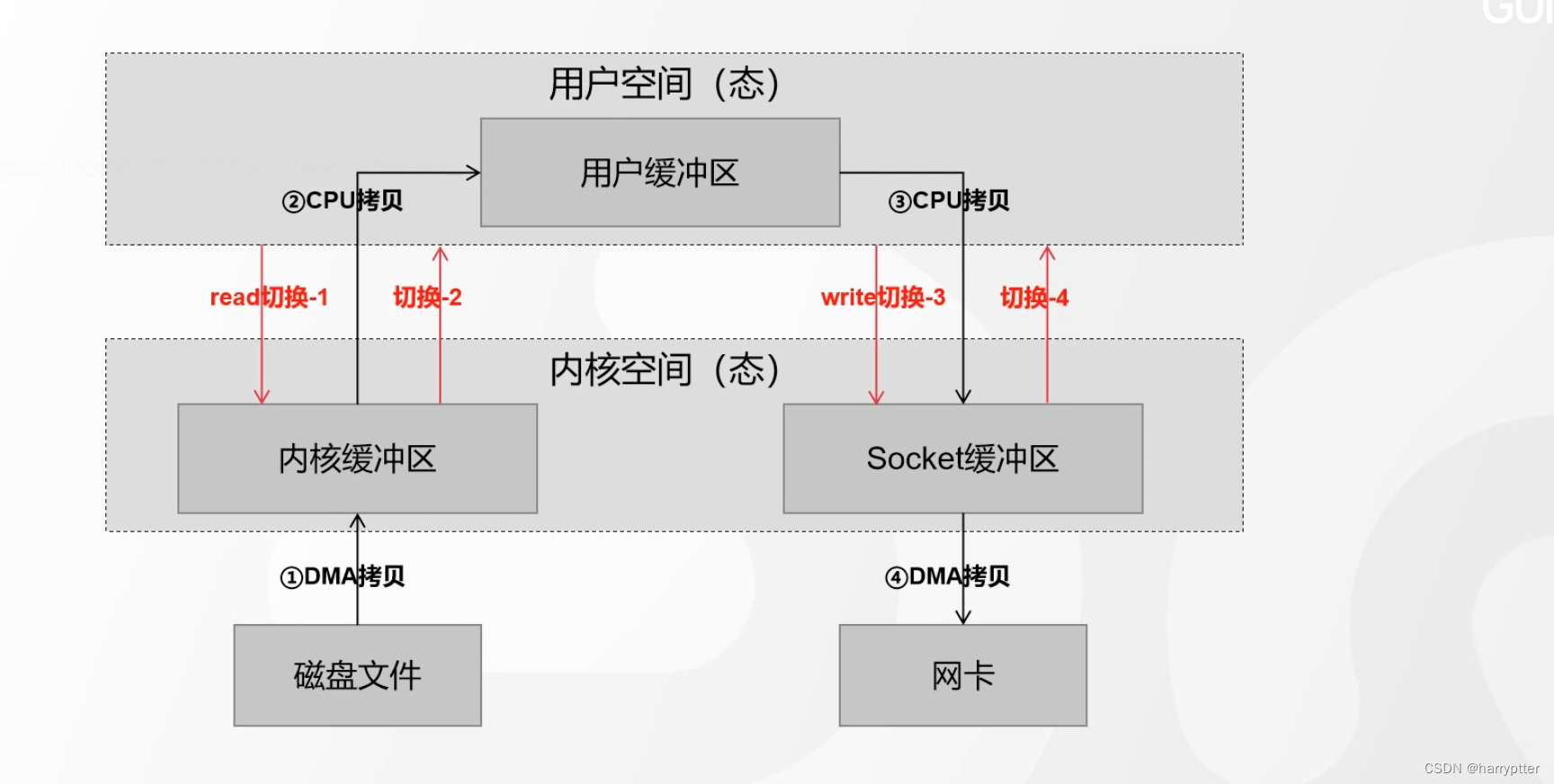
传统的I/O拷贝如上图:
数据文件从磁盘到网卡,会经过四次从用户态到内核态切换。比较耗时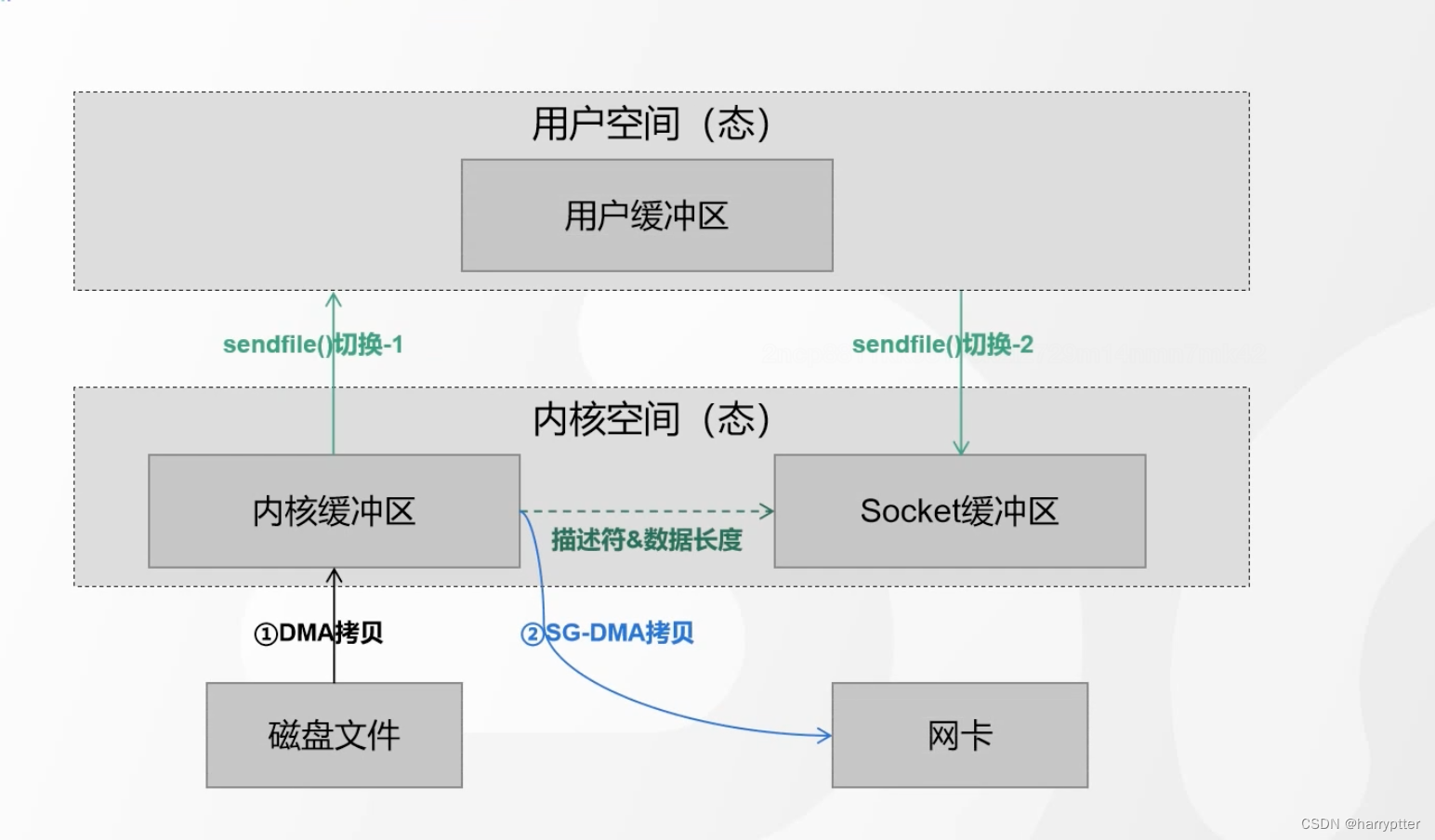
但是Kafka采用的是linux中的sendfile()函数,采用的是零拷贝的技术,使得读写有比较高的提升
对应的java源码中使用的是transferTo函数

以上就是Kafka整体架构,主要组件和对应的特性。后续还会记录几个主要组件的原理帮助理解。