缓存穿透
缓存穿透指什么
缓存穿透是指查询⼀个在缓存和数据库中都不存在的数据。由于缓存没有这个数据,所以每次查询都会"穿透"缓存直接查询数据库,如果有⼤量此类查询,会给数据库带来极⼤的压⼒。
查询流程
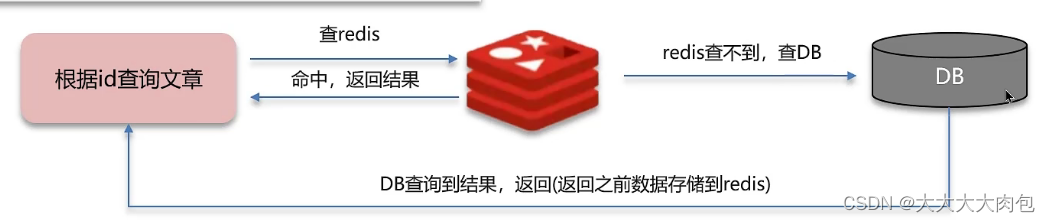 解决方案
解决方案
设置value为null
缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存

- 优点:简单
- 缺点:消耗内存,可能导致不一致性
布隆过滤器

**bitmap(位图):**相当于是一个以 (bit) 位为单位的数组,数组中每个单元只能存储二进制数0或1。
布隆过滤器作用:布隆过滤器可以用于检索一个元素是否在一个集合中。
误判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多的内存消耗。一般误判率是5%。
- **布隆过滤器优点:**内存占用较少,没有多余key。
- **布隆过滤器优点:**实现复杂,存在误判。
缓存击穿
概念
给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
查询流程

解决方案
设置热点数据永久不过期
如果某些数据特别热⻔,访问的频率远远超过其他数
据,那么可以将这部分数据设置为永不过期,这样就可以避免⼤量请求突然落
到数据库上
使用互斥锁
- 优点:强一致性
- 缺点:性能差
- 适用于与交易相关的业务
当线程1查询缓存的时候,未命中缓存,然后获取互斥锁成功。此时线程1去查询数据库,将数据写入缓存,最后释放锁。
在线程1查询缓存的时候,未命中缓存,然后线程2去获取互斥锁,获取失败,因为线程1获取到了互斥锁,此时线程2只能休眠一会再重试。当线程1写入缓存成功后并释放锁的同时,线程2重试命中缓存,命中成功直接获取缓存。
缓存雪崩
概念
缓存雪崩是指在同一时段大量的缓存key同时失效 或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
查询流程

解决方案
缓存数据的过期时间设置为随机
避免所有数据同时过期,不会出现瞬间⼤量的数据库请求。
使用多级缓存策略:
使⽤⼀级缓存和⼆级缓存,⼀级缓存的失效时间短于⼆级缓存,⼀级缓存失效后,请求会访问⼆级缓存,⽽不是直接落到数据库。
缓存预热:
在业务低峰期,对将要过期的缓存进行预热,预热的⽅式就是提前去更新数据。
使⽤高可用的缓存集群:
即使某些节点挂掉,仍然可以保证系统的可⽤性。
redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
概念:
- 当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致。
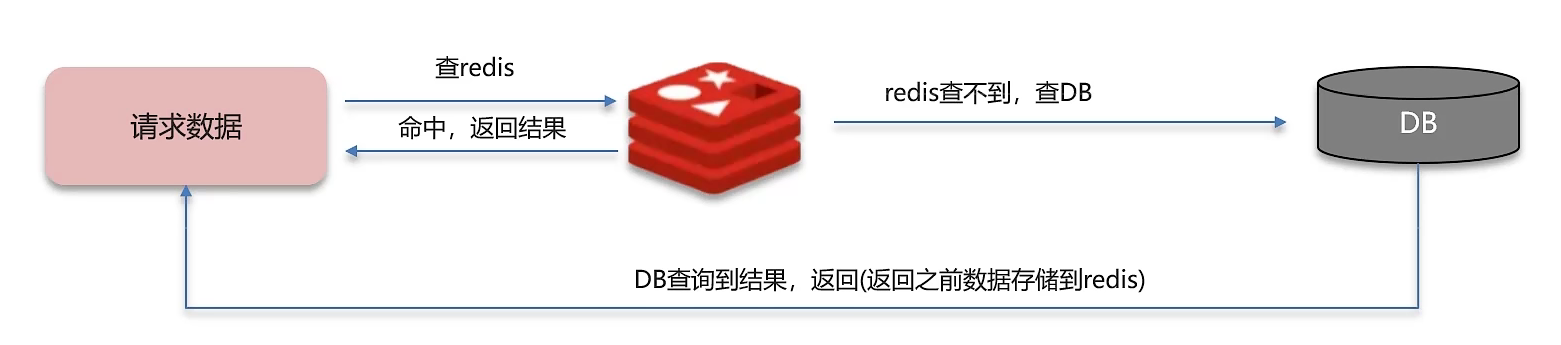
解决方案
延迟双删:
是指在更新数据库之前先删除缓存,然后再去更新数据库,更新数据库后,再去延时删除缓存。
之所以要延迟删除缓存是因为大多数的数据库并不是一个,一个数据库存在数据库损坏、宕机等问题。数据库需要做主从同步的操作,把数据库(主数据库)的数据同步到另一个数据库(从数据库)中,以实现数据的备份、负载均衡、灾难恢复等功能。数据库在做主从同步时有延迟。所以延迟双删,需要等待主从同步完成。
缺点:不能确定主从同步完成的时间,如果没有数据同步完成,查询缓存时容易出现脏数据,所以延迟双删有查询出脏数据的风险。
分布式锁(强一致性)
通过加锁的方式,保证执行时只有一个线程去操作,其他线程需要等待有锁的线程释放锁。(性能太低)
可以通过加共享锁、排它锁提高性能。
**共享锁:**其他线程可以共享读的操作,在读操作时不能进行写的操作。
**排它锁:**线程在加锁后对其他线程阻塞,不允许其他线程进行读写操作。
缺点:虽然数据保持了强一致性,但是性能低。适用于对数据要求必须一致的业务使用。
使用异步通知保证数据的最终一致性。
MQ(消息中间件)异步通知:
当请求操作完数据库后,发送一个通知给MQ(消息中间件),在缓存服务中去监听MQ(消息中间件),收到通知后去更新Redis缓存。异步通知能够保证数据的最终一致性。主要是靠MQ(消息中间件)的可靠性。
基于Canal的异步通知:
当MySQL数据库中的数据发生变化时(如插入、更新、删除操作),对应的binlog中会记录下这些数据变更事件,Canal接收到数据变更后,去通知缓存去更新数据。
好处:对于业务代码几乎是零侵入的。
数据过期策略
假如redis的key过期之后,会立即删除吗?
Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。
Redis数据删除策略-定时删除
节约内存,到时就删除,立即释放不必要的内存占用。
优点:
CPU压力较大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量。
缺点:
对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放 。
Redis数据删除策略-惰性删除
惰性删除:设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
优点:
对CPU友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查。
缺点:
对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放 。
Redis数据删除策略-定期删除
每隔一段时间,我们就对一些key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)
定期清理的两种模式:
- SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的hz 选项来调整这个次数。
- FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms。
优点:
可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:
难以确定删除操作执行的时长和频率。
数据淘汰策略
当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
八种不同的数据淘汰策略
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰。
- allkeys-random:对全体key ,随机进行淘汰。
- volatile-random:对设置了TTL的key ,随机进行淘汰。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰。
- volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰。
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰。
- volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰。
LRU算法与LFU算法
LRU(Least Recently Used) :最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
列如:key1是在3s之前访问的,key2是在9s之前访问的,删除的就是key2。
LFU (Least Frequently Used) : 最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
列如:key1最近5s访问了4次, ey2最近5s访问了9次,删除的就是key1。
淘汰策略使用建议
- 优先使用 allkeys-lru 策略。充分利用LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
主从复制
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
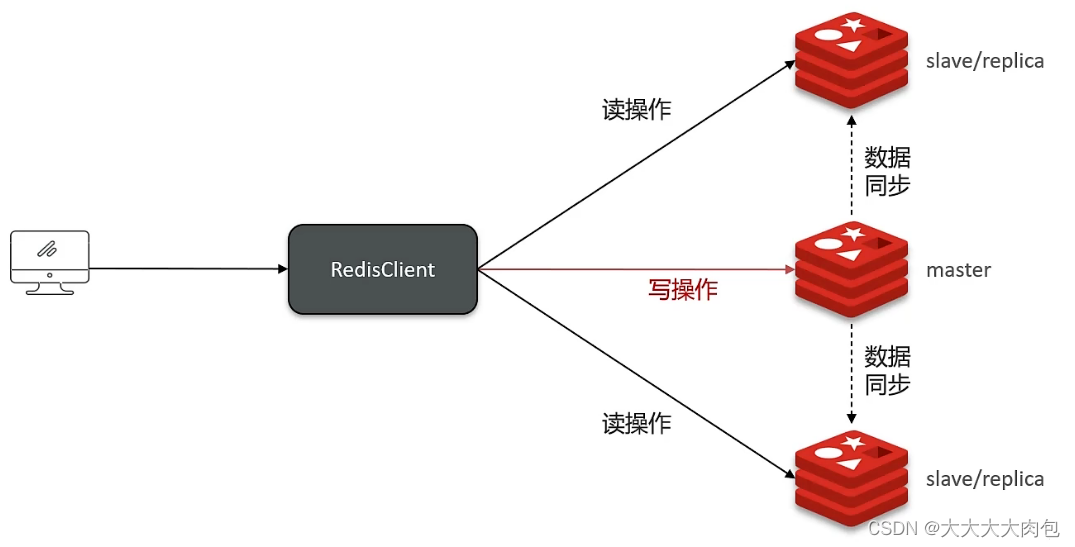
主从同步原理:

- 首先从节点执行replicaof命令用来建立连接, 然后从节点请求数据同步。主节点收到请求以后进行判断是否第一次进行同步,通过判断replid是否一致。因为刚开始每个数据库的replid都不同,只有当第一次同步后主从replid才会一致。因此主节点会根据replid判断是否是第一次同步。
- 如果是第一次同步,那么主节点会返回它的节点信息给从数据库,从节点保存版本信息以后,主节点会进行bgsave将redis的数据生成RDB文件,然后将RDB文件发送给从数据库。然后从数据库删除本地文件加载RDB文件。在生成RDB文件也需要时间,因此也会有主节点数据的写入,因此在生成RDB文件期间将写入的记录保存到repl_baklog中。再将repl_baklog中的命令发送给从节点,从节点收到后执行收到命令实现主从同步。
- 如果不是第一次同步,那么在第2步从节点会将自己的偏移量和replid发送给主节点。主节点判断replid不是第一次同步,就会将数据版本信息返回给从节点,里面也包括replid和offset。从节点然后保存这些信息。然后同步的时候不再发送RDB文件,而是将repl_baklog文件发送给从节点。至于发送多少呢?由偏移量计算觉得,比如从节点偏移量是50,主节点偏移量是80,那么主节点就会发送50-80这些偏移量的数据。当发送repl_baklog后,会将从节点的偏移量改变为最新即80。
增量同步流程:
- 从节点发送replid和offset后,主节点通过replid是不是第一次同步,如果不是第一次同步回continue给从从节点。
- 然后主节点去repl_baklog获取offset数据和从节点的offset进行对比,发送偏移量的数据给从节点。
- 从节点获取数据后进行同步。
全量同步流程:
- 从节点请求主节点同步数据 (replication id、 offset)。
- 主节点判断是否是第一次请求,是第一次就与从节点同步版本信息 (replication id和offset)
- 主节点执行bgsave,生成rdb文件后,发送给从节点去执行。
- 在rdb生成执行期间,主节点会以命令的方式记录到缓冲区(一个日志文件)。
- 把生成之后的命令日志文件发送给从节点进行同步。
哨兵模式,集群脑裂
哨兵的作用
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
- 监控: Sentinel会不断检查您的master和slave是否按预期工作。
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主。
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端。
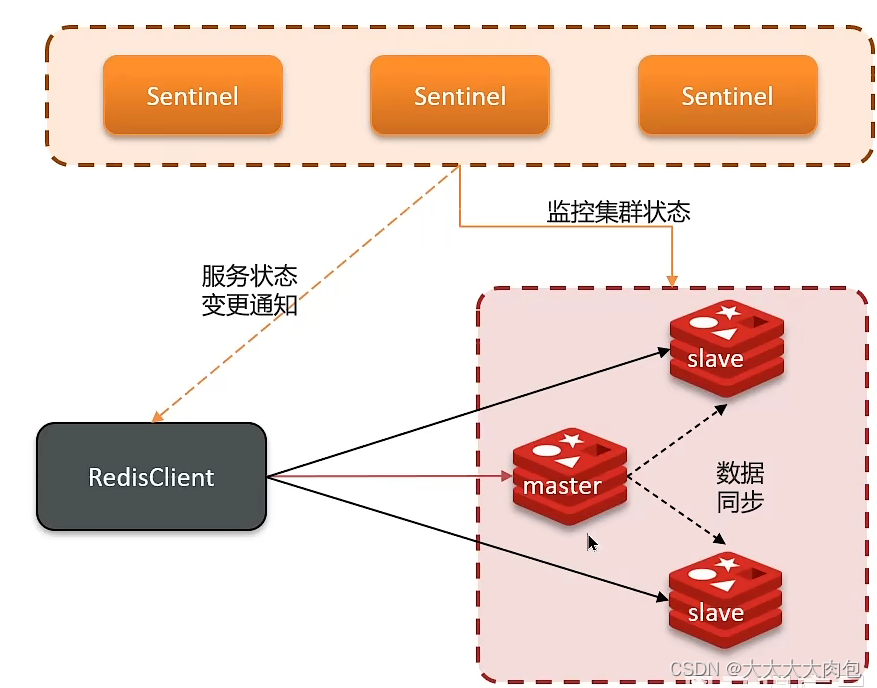
服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令
- 主观下线: 如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线: 若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
判断主节点下线流程
- 如果此时主服务器宕机,哨兵1检测到了,系统并不会⽴即进⾏failover(故障转移)过程
- 此时仅仅是哨兵1主管的认为主服务不可⽤,此现象为主观下线
- 当后续的哨兵也检测到主服务器不可⽤时,并且数量达指定数量时
- 哨兵之间就会进⾏⼀次投票,投票结果由1个哨兵发起,进⾏failover操作
- 切换成功之后,就会通过发布订阅模式,让各个哨兵把⾃⼰监控的从服务器切换主机,这个过程为客观下线
哨兵选主规则
- 首先判断主与从节点断开时间长短如超过指定值就排该从节点。因为断开时间越长,丢失的数据越多,所以选择断开时间短的,丢失数据少的节点为主节点。
- 然后判断从节点的slave-priority值,越小优先级越高。
- 如果slave-prority一样,则判断slave节点的offset值,越大优先级越高。因为offset的值越大,说明该从节点与主节点的数据差越少,所以选offset大的为主节点。
- 最后是判断slave节点的运行id大小,越小优先级越高。
故障转移过程
- Sentinel给备选的节点发送slaveof on one命令,让该节点成为Maskter
- Sentinel给其他slave发送 "slaveof ip 端⼝" 命令,开始从Master上同步数据
- 最后Sentinel将故障节点标记为slave(执⾏slaveof ip 端⼝命令),故障节点恢复以后也会成为新Master的slave
rdids的脑裂
假如此时因为网络的原因 ,将主节点和从节点分开来了。并且主节点是一个分区,其他从节点是另外一个分区。这个时候从节点分区就会从从节点选出一个主节点,然后就会出现两个master主节点,就好像脑裂了一样。
不过老的master没有挂,只是网络出现的问题,客户端还可以去对老的主节点进行写数据。这就是脑裂的现象。但是老的主节点写入的数据不能同步到新的主节点。
之后网络恢复了,哨兵会将老的master强制降为salve节点。这个savle就会送master中同步数据,就会把自己的数据清空然后同步master的数据。
然后客户端连接新的master,变成正常情况。不过丢失的数据依旧丢失了
解决方案
redis中有两个配置参数
- min-replicas-to-write 1 表示最少的salve节点为1个。必须每个主节点至少有一个从节点,才可以接受客户端的请求,否则失败。
- min-replicas-max-lag 5表示数据复制和同步的延迟不能超过5秒。
达不到要求就拒绝请求就可以避免大量的数据丢失
分片集群、数据读写规则
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
分片集群特征
- 集群中有多个master,每个master保存不同数据。
- 每个master都可以有多个slave节点。
- master之间通过ping监测彼此健康状态。
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
数据读写
Redis 分片集群引入了哈希槽 的概念,Redis 集群有 16384 个哈希槽,每个key通过CRC16 校验后对16384 取模来决定放置哪个槽,集群的每个节点负责一部分hash 槽。
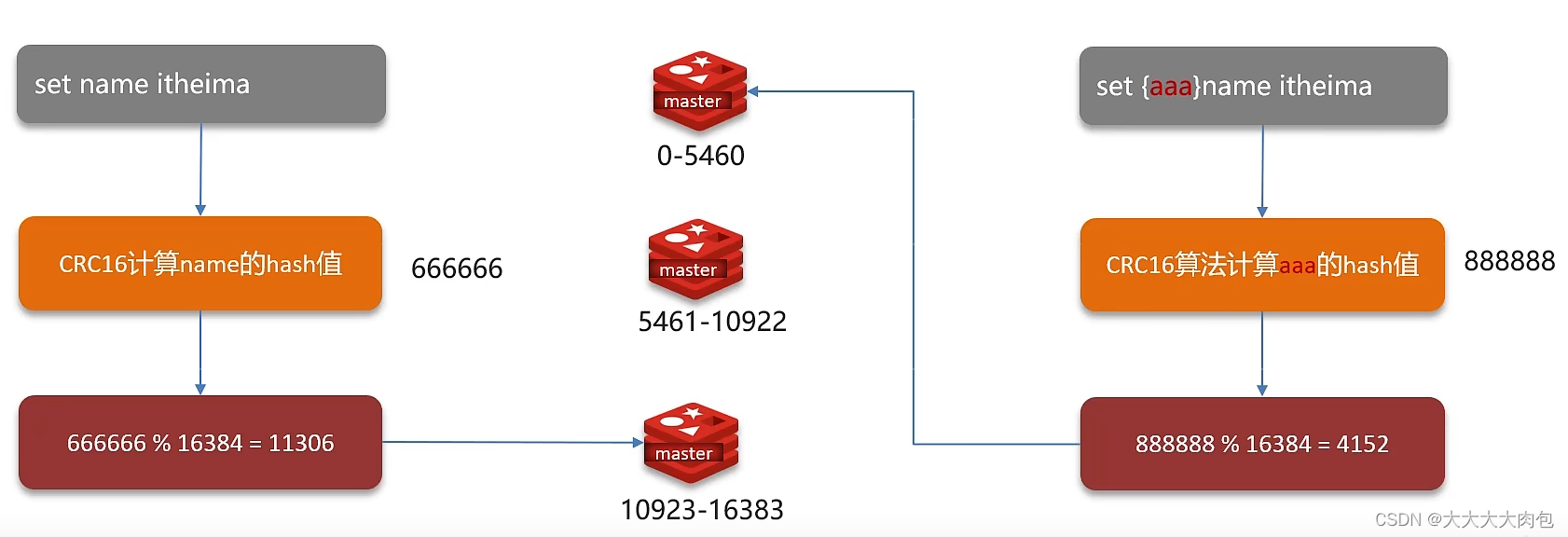
对于每个master,会根据master的数量对哈希槽进行均分。然后对于每个写或者读的key经过CRC16的计算其hash值并取模16384就可以获取所在的集群位置。