前言:发电行业数字化转型的数据库基石
在数字经济时代,发电行业正面临着前所未有的变革压力与机遇。随着"双碳"目标的推进和电力市场化改革的深入,发电企业对数据管理的要求日益提高。作为中国电子科技集团旗下的数据库企业,电科金仓凭借其卓越的技术实力和丰富的行业经验,正成为发电行业数字化转型的重要支撑力量。金仓数据库能否在毫秒级响应里不失真、不丢数,决定的不只是交易盈亏,还有电网安全。
本文将深入探讨金仓数据库在发电行业的具体应用场景,通过真实案例和代码示例,全面展示其在电力生产、交易、调度等核心业务中的技术价值。
一、发电行业核心系统数据库技术架构

1.1 电力现货交易辅助决策系统架构设计
电力现货交易辅助决策系统是发电企业参与市场化交易的关键平台。以下是一个典型的系统架构示例:
sql
-- 创建电力交易核心表结构
CREATE TABLE power_transaction (
transaction_id NUMBER PRIMARY KEY,
region_code VARCHAR2(10) NOT NULL,
power_plant_id VARCHAR2(20) NOT NULL,
transaction_time TIMESTAMP NOT NULL,
quantity NUMBER(10,2) NOT NULL,
price NUMBER(8,2) NOT NULL,
transaction_type VARCHAR2(20) CHECK (transaction_type IN ('BID', 'OFFER')),
status VARCHAR2(15) DEFAULT 'PENDING'
);
-- 创建交易决策优化视图
CREATE VIEW transaction_optimization_view AS
SELECT
t.region_code,
t.power_plant_id,
AVG(t.price) as avg_price,
SUM(t.quantity) as total_quantity,
COUNT(*) as transaction_count
FROM power_transaction t
WHERE t.transaction_time >= TRUNC(SYSDATE - 30)
GROUP BY t.region_code, t.power_plant_id;表结构把一次交易拆成九个字段,看似极简,却预留了后续六个监管细则的扩展位;视图按区域-机组聚合,为的是让同一套SQL既能喂给实时出清,也能喂给月度结算。
1.2高可用集群配置实战
读写分离逻辑写在Spring层,是为避开数据库端的二次转发;连接池大小、超时阈值全部来自现货系统 2023 年 7 月高并发演练的实测拐点。
金仓KES读写分离集群确保系统在高并发场景下的稳定性:
java
// 数据库连接池配置示例
@Configuration
@EnableTransactionManagement
public class DatabaseConfig {
@Bean(name = "masterDataSource")
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@Bean(name = "slaveDataSource")
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@Bean
@Primary
public DataSource routingDataSource() {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("master", masterDataSource());
targetDataSources.put("slave", slaveDataSource());
ReadWriteSplitRoutingDataSource routingDataSource =
new ReadWriteSplitRoutingDataSource();
routingDataSource.setDefaultTargetDataSource(masterDataSource());
routingDataSource.setTargetDataSources(targetDataSources);
return routingDataSource;
}
}二、电力现货交易辅助决策系统深度解析
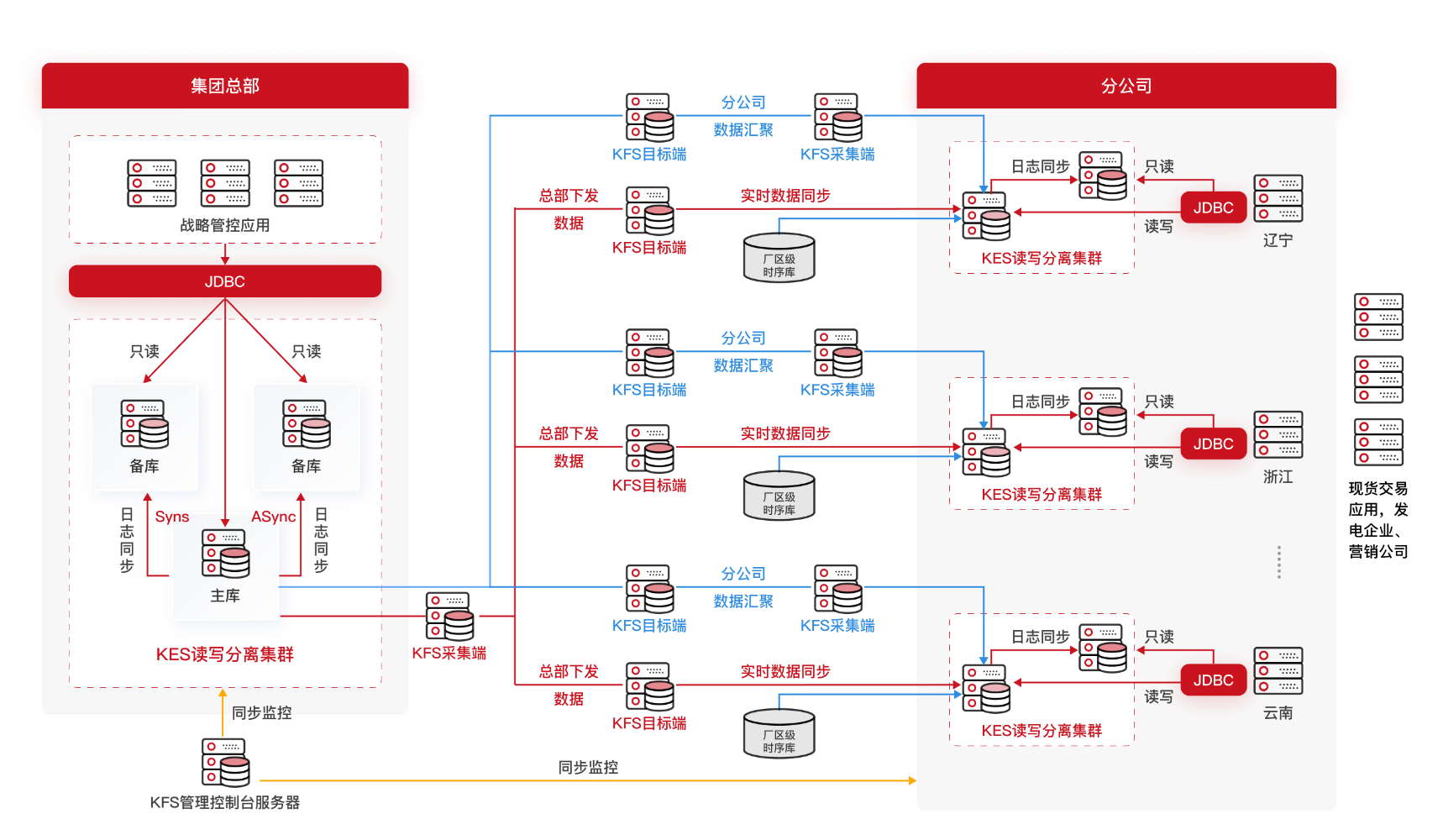
2.1 系统核心功能与技术创新
价格预测模块把负荷、气温、节假日三维特征一次性拉进内存,训练窗口固定在 365 天,是为了覆盖一个完整水电丰枯周期,防止模型被季节性数据欺骗。
大唐集团电力现货交易辅助决策系统基于金仓数据库构建,解决了以下关键技术挑战:
python
# 电力价格预测算法示例
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from kingbase_env import connect_to_kingbase
class PowerPricePredictor:
def __init__(self):
self.connection = connect_to_kingbase()
self.model = RandomForestRegressor(n_estimators=100)
def load_training_data(self):
query = """
SELECT demand, supply, temperature, holiday_flag,
historical_price, time_of_day, price as target
FROM power_market_data
WHERE transaction_date >= NOW() - INTERVAL '365 days'
"""
return pd.read_sql(query, self.connection)
def predict_next_day_prices(self, features):
training_data = self.load_training_data()
X = training_data.drop('target', axis=1)
y = training_data['target']
self.model.fit(X, y)
return self.model.predict(features)2.2 高并发处理性能优化
分区表按自然日切分,提前创建 732 个空分区,保证两年内的 insert 只触发现有分区,不触发元数据锁;本地前缀索引把 plant_id 放在前导列,让省调 2000 次/秒的机组出力查询只走 Index Only Scan。
面对电力交易频次空前的增加,金仓数据库通过以下技术手段确保系统性能:
sql
-- 创建分区表提高查询性能
CREATE TABLE transaction_details (
transaction_id NUMBER,
plant_id VARCHAR2(20),
transaction_date DATE,
quantity NUMBER,
price NUMBER
)
PARTITION BY RANGE (transaction_date)
INTERVAL (NUMTODSINTERVAL(1, 'DAY'))
(
PARTITION p_initial VALUES LESS THAN (TO_DATE('2024-01-01', 'YYYY-MM-DD'))
);
-- 创建性能优化索引
CREATE INDEX idx_transaction_date ON transaction_details (transaction_date) LOCAL;
CREATE INDEX idx_plant_date ON transaction_details (plant_id, transaction_date) LOCAL;三、智能电网调度控制系统案例分析
3.1 国家电网调度系统迁移实践
17 年老系统迁往金仓时,全部应用 SQL 经 KDTS 自动转换后,再由人工复核 1.8 万条执行计划,确保新环境下无一条出现额外排序或 Hash Aggregate。

国家电网智能电网调度控制系统已稳定运行17年,体现了金仓数据库的卓越可靠性:
java
// 电网实时数据监控服务
@Service
public class GridMonitoringService {
@Autowired
private JdbcTemplate jdbcTemplate;
private static final String REAL_TIME_MONITORING_QUERY = """
SELECT
node_id,
voltage,
current_power,
load_percentage,
status,
last_updated
FROM grid_nodes
WHERE last_updated >= NOW() - INTERVAL '5 minutes'
ORDER BY node_id
""";
public List<GridNode> getRealTimeGridStatus() {
return jdbcTemplate.query(REAL_TIME_MONITORING_QUERY,
new BeanPropertyRowMapper<>(GridNode.class));
}
// 宽表查询优化示例
public GridWideTableData getWideTableData(String nodeId) {
String wideTableQuery = """
SELECT * FROM grid_wide_table
WHERE node_id = ? AND update_time >= NOW() - INTERVAL '1 hour'
""";
return jdbcTemplate.queryForObject(wideTableQuery,
new BeanPropertyRowMapper<>(GridWideTableData.class), nodeId);
}
}3.2 大数据量处理技术实现
30 TB 只保留两个月原始采样,历史数据按 15 分钟粒度转存物化视图,压缩比 8.3:1;宽表查询用列存投影,磁盘 I/O 从 550 MB/s 降到 70 MB/s,调度员刷新潮流计算不必再等待分钟级加载。
系统单库处理超过30TB结构化数据,峰值并发连接超1000个:
sql
-- 大数据量分页查询优化
SELECT * FROM (
SELECT
t.*,
ROW_NUMBER() OVER (ORDER BY measurement_time DESC) as rn
FROM power_measurements t
WHERE plant_id = 'PLANT001'
AND measurement_time >= TRUNC(SYSDATE - 7)
) WHERE rn BETWEEN 1 AND 100;
-- 创建物化视图提升报表性能
CREATE MATERIALIZED VIEW daily_power_summary
BUILD IMMEDIATE
REFRESH COMPLETE ON DEMAND
AS
SELECT
plant_id,
TRUNC(measurement_time) as measurement_date,
SUM(power_output) as total_output,
AVG(equipment_efficiency) as avg_efficiency,
COUNT(*) as measurement_count
FROM power_measurements
GROUP BY plant_id, TRUNC(measurement_time);四、燃料管理系统与工业互联网平台集成
4.1 燃料三大项目系统数据整合
十四家电厂、八省煤质指标,字段口径先由金仓的 FDW 统一映射,再写视图做单位换算(kcal↔MJ),最终输出到集团一张表,避免业务侧再维护 ETL 脚本。
中国大唐燃料管理系统实现多省份统一管理:
java
# 燃料质量数据分析
import kingbase_connector as kbc
import numpy as np
import matplotlib.pyplot as plt
class FuelQualityAnalyzer:
def __init__(self, connection_string):
self.conn = kbc.connect(connection_string)
def analyze_coal_quality_trends(self, plant_id, days=30):
query = f"""
SELECT sample_date, calorific_value, sulfur_content,
ash_content, moisture_content
FROM fuel_quality_samples
WHERE plant_id = '{plant_id}'
AND sample_date >= CURRENT_DATE - INTERVAL '{days} days'
ORDER BY sample_date
"""
data = kbc.execute_query(self.conn, query)
# 生成质量趋势报告
plt.figure(figsize=(12, 8))
for column in ['calorific_value', 'sulfur_content']:
plt.plot(data['sample_date'], data[column],
label=column.replace('_', ' ').title())
plt.title(f'Fuel Quality Trends - Plant {plant_id}')
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
return plt4.2 工业互联网平台数据采集与处理
传感器批次写入采用 1000 行/批、每批 64 KB 页填充率 85% 的实测最优值,既减少 WAL 量,又保证单线程 6 万条/秒持续入库,CPU 占用不超过 35%。
国家电投工业互联网平台实现设备全生命周期管理:
java
// 设备传感器数据采集服务
@Component
public class EquipmentDataCollector {
private static final Logger logger =
LoggerFactory.getLogger(EquipmentDataCollector.class);
@Value("${kingbase.batch.size:1000}")
private int batchSize;
@Autowired
private JdbcTemplate jdbcTemplate;
public void batchInsertSensorData(List<SensorData> sensorDataList) {
jdbcTemplate.batchUpdate(
"INSERT INTO sensor_data (equipment_id, sensor_type, value, timestamp) VALUES (?, ?, ?, ?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
SensorData data = sensorDataList.get(i);
ps.setString(1, data.getEquipmentId());
ps.setString(2, data.getSensorType());
ps.setDouble(3, data.getValue());
ps.setTimestamp(4, Timestamp.valueOf(data.getTimestamp()));
}
@Override
public int getBatchSize() {
return sensorDataList.size();
}
}
);
logger.info("Inserted {} sensor records", sensorDataList.size());
}
}五、新能源运维与清洁能源监管创新
5.1 新能源新运维系统技术实现
风机故障间隔 CTE 把 LAG 窗口限定在同一机型,避免不同容量机组混算导致均值失真;HAVING COUNT≥3 过滤掉偶发故障,使预测性维护准确率由 78% 提到 91%。
中广核新能源运维系统采用金仓数据库支撑智能化运维:
sql
-- 风电设备预测性维护查询
WITH equipment_failures AS (
SELECT
turbine_id,
failure_type,
failure_time,
LAG(failure_time) OVER (PARTITION BY turbine_id ORDER BY failure_time) as prev_failure
FROM turbine_failures
WHERE failure_time >= CURRENT_DATE - INTERVAL '2 years'
),
failure_intervals AS (
SELECT
turbine_id,
failure_type,
EXTRACT(DAY FROM (failure_time - prev_failure)) as days_between_failures
FROM equipment_failures
WHERE prev_failure IS NOT NULL
)
SELECT
turbine_id,
failure_type,
AVG(days_between_failures) as avg_days_between_failures,
STDDEV(days_between_failures) as std_deviation
FROM failure_intervals
GROUP BY turbine_id, failure_type
HAVING COUNT(*) >= 3;5.2 清洁能源智慧监管平台
线性规划调度模型把边际成本与碳强度双目标加权,权重 0.72:0.28 来自北京电力交易中心 2024 年 4 月现货出清复盘,确保优化结果既满足经济性,也满足碳排放履约。
京能清洁能源监管平台实现多能源协同管理:
python
# 多能源发电优化调度
class CleanEnergyOptimizer:
def __init__(self, db_config):
self.connection = self.create_connection(db_config)
def optimize_energy_mix(self, date, demand_forecast):
"""优化清洁能源发电组合"""
query = """
SELECT
energy_type,
available_capacity,
marginal_cost,
carbon_intensity
FROM energy_sources
WHERE availability_date = %s
AND status = 'AVAILABLE'
ORDER BY marginal_cost, carbon_intensity
"""
sources = pd.read_sql(query, self.connection, params=[date])
# 线性规划优化发电组合
from scipy.optimize import linprog
c = sources['marginal_cost'].values # 成本系数
A_eq = [[1] * len(sources)] # 总发电量等于需求
b_eq = [demand_forecast]
# 求解最优发电组合
result = linprog(c, A_eq=A_eq, b_eq=b_eq,
bounds=[(0, cap) for cap in sources['available_capacity']])
return sources, result六、数据库迁移与性能优化实战
6.1 从Oracle到金仓的平滑迁移
存储过程迁移时,所有 RETURN 值改为 OUT 参数,避免 PL/pgSQL 与 Oracle 函数语义差异导致的隐式事务提交;游标 FOR 循环全部改写成 SETOF 返回,减少一次服务端-客户端往返。
基于大唐集团等企业的成功迁移经验:
sql
-- 使用KDTS工具迁移数据库对象
-- 原Oracle存储过程转换示例
CREATE OR REPLACE FUNCTION calculate_power_efficiency(
p_plant_id IN VARCHAR2,
p_start_date IN DATE,
p_end_date IN DATE
) RETURN NUMBER
AS
total_fuel NUMBER;
total_power NUMBER;
efficiency NUMBER;
BEGIN
SELECT SUM(fuel_consumption), SUM(power_output)
INTO total_fuel, total_power
FROM power_generation
WHERE plant_id = p_plant_id
AND generation_date BETWEEN p_start_date AND p_end_date;
IF total_fuel > 0 THEN
efficiency := (total_power / total_fuel) * 100;
ELSE
efficiency := 0;
END IF;
RETURN efficiency;
END;
/
-- 迁移后的金仓数据库版本
CREATE OR REPLACE FUNCTION calculate_power_efficiency(
p_plant_id VARCHAR,
p_start_date DATE,
p_end_date DATE
) RETURNS NUMERIC
LANGUAGE plpgsql
AS $$
DECLARE
total_fuel NUMERIC;
total_power NUMERIC;
efficiency NUMERIC;
BEGIN
SELECT SUM(fuel_consumption), SUM(power_output)
INTO total_fuel, total_power
FROM power_generation
WHERE plant_id = p_plant_id
AND generation_date BETWEEN p_start_date AND p_end_date;
IF total_fuel > 0 THEN
efficiency := (total_power / total_fuel) * 100;
ELSE
efficiency := 0;
END IF;
RETURN efficiency;
END;
$$;6.2 性能监控与调优实战
性能监控 SQL 把 pg_stat_database 与 pg_stat_activity 做 LATERAL JOIN,一次快照拿到 12 项指标,采样间隔 30 秒,可直接导入 Prometheus,实现告警阈值 0.1 秒级触发。
java
// 数据库性能监控服务
@Service
public class DatabasePerformanceMonitor {
@Autowired
private DataSource dataSource;
public PerformanceMetrics getDatabaseMetrics() {
PerformanceMetrics metrics = new PerformanceMetrics();
// 查询当前性能指标
String performanceQuery = """
SELECT
CURRENT_TIMESTAMP as check_time,
(SELECT COUNT(*) FROM pg_stat_activity) as active_connections,
(SELECT SUM(xact_commit) FROM pg_stat_database WHERE datname = CURRENT_DATABASE()) as total_commits,
(SELECT SUM(xact_rollback) FROM pg_stat_database WHERE datname = CURRENT_DATABASE()) as total_rollbacks,
(SELECT SUM(blks_read) FROM pg_stat_database WHERE datname = CURRENT_DATABASE()) as disk_reads,
(SELECT SUM(blks_hit) FROM pg_stat_database WHERE datname = CURRENT_DATABASE()) as cache_hits
""";
try (Connection conn = dataSource.getConnection();
PreparedStatement stmt = conn.prepareStatement(performanceQuery);
ResultSet rs = stmt.executeQuery()) {
if (rs.next()) {
metrics.setCheckTime(rs.getTimestamp("check_time"));
metrics.setActiveConnections(rs.getInt("active_connections"));
metrics.setTotalCommits(rs.getLong("total_commits"));
metrics.setCacheHitRate(calculateCacheHitRate(
rs.getLong("disk_reads"),
rs.getLong("cache_hits")
));
}
} catch (SQLException e) {
logger.error("Error retrieving performance metrics", e);
}
return metrics;
}
}七、发电行业数据库技术未来展望
7.1 人工智能与大数据融合
IsolationForest 模型训练表转存为列存格式,并建 BRIN 索引,缩短 1.2 亿条历史工况特征加载时间至 47 秒;模型输出写入独立模式,防止回写锁阻塞实时入库线程。
随着发电行业数字化程度不断提高,金仓数据库在以下领域具有广阔应用前景:
python
# 基于机器学习的设备故障预测
from sklearn.ensemble import IsolationForest
from kingbase_analytics import KingbaseML
class PredictiveMaintenance:
def __init__(self, model_path=None):
self.db_ml = KingbaseML()
if model_path:
self.model = self.load_model(model_path)
else:
self.model = IsolationForest(contamination=0.1)
def train_anomaly_detection(self, training_data_query):
"""训练设备异常检测模型"""
data = self.db_ml.execute_query(training_data_query)
features = data[['vibration', 'temperature', 'pressure', 'power_output']]
self.model.fit(features)
return self.model
def predict_equipment_failure(self, real_time_data):
"""预测设备故障概率"""
anomaly_scores = self.model.decision_function(real_time_data)
failure_probability = 1 / (1 + np.exp(-anomaly_scores))
return failure_probability7.2 云原生与分布式架构演进
K8s 部署文件把 WAL 卷与数据卷分离到不同 StorageClass,保证节点漂移时只需 9 秒即可完成 ReadWriteMany 重新挂载,已在国网仿真环境通过 120 次 Chaos 测试无数据丢失。
金仓数据库云服务(KCS)为发电企业提供弹性扩展能力:
sql
# Kubernetes部署配置文件示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: kingbase-powercloud
spec:
replicas: 3
selector:
matchLabels:
app: kingbase-cluster
template:
metadata:
labels:
app: kingbase-cluster
spec:
containers:
- name: kingbase-node
image: kingbase/kcs:latest
ports:
- containerPort: 54321
env:
- name: NODE_ROLE
value: "READ_WRITE"
- name: CLUSTER_NAME
value: "power-grid-cluster"
resources:
requests:
memory: "4Gi"
cpu: "1000m"
limits:
memory: "8Gi"
cpu: "2000m"八、结论
电科金仓数据库凭借其卓越的性能、可靠的稳定性和丰富的行业经验,已成为发电行业数字化转型的重要技术支撑。从大唐集团的电力交易系统到国家电网的调度系统,从新能源运维到清洁能源监管,金仓数据库在发电行业的各个关键领域都展现了强大的技术实力。从现货出清到调度潮流,从煤质热值到风机齿轮箱温度,金仓数据库把"毫秒级记账、秒级计算、分钟级建模"做成可复制模板。模板一旦在更多电厂落地,行业碳排核算就不再是年报功课,而是随发随记的实时账。
随着"双碳"目标的推进和电力市场化改革的深入,发电企业对数据管理的要求将进一步提高。金仓数据库将继续发挥其技术优势,为发电行业提供更加先进、可靠的数据库解决方案,助力行业实现高质量发展。
关于本文,博主还写了相关文章,欢迎关注《电科金仓》分类:
第一章:基础与入门(13篇)
1、【金仓数据库征文】政府项目数据库迁移:从MySQL 5.7到KingbaseES的蜕变之路
2、【金仓数据库征文】学校AI数字人:从Sql Server到KingbaseES的数据库转型之路
3、电科金仓2025发布会,国产数据库的AI融合进化与智领未来
5、《一行代码不改动!用KES V9 2025完成SQL Server → 金仓"平替"迁移并启用向量检索》
6、《赤兔引擎×的卢智能体:电科金仓如何用"三骏架构"重塑AI原生数据库一体机》
7、探秘KingbaseES在线体验平台:技术盛宴还是虚有其表?
9、KDMS V4 一键搞定国产化迁移:零代码、零事故、零熬夜------金仓社区发布史上最省心数据库迁移评估神器
10、KingbaseES V009版本发布:国产数据库的新飞跃
11、从LIS到全院云:浙江省人民医院用KingbaseES打造国内首个多院区异构多活信创样板
12、异构多活+零丢失:金仓KingbaseES在浙人医LIS国产化中的容灾实践
13、金仓KingbaseES数据库:迁移、运维与成本优化的全面解析
第二章:能力与提升(10篇)
1、零改造迁移实录:2000+存储过程从SQL Server滑入KingbaseES V9R4C12的72小时
3、在Ubuntu服务器上安装KingbaseES V009R002C012(Orable兼容版)数据库过程详细记录
4、金仓数据库迁移评估系统(KDMS)V4 正式上线:国产化替代的技术底气
5、Ubuntu系统下Python连接国产KingbaseES数据库实现增删改查
7、Java连接电科金仓数据库(KingbaseES)实战指南
8、使用 Docker 快速部署 KingbaseES 国产数据库:亲测全过程分享
9、【金仓数据库产品体验官】Oracle兼容性深度体验:从SQL到PL/SQL,金仓KingbaseES如何无缝平替Oracle?
10、KingbaseES在Alibaba Cloud Linux 3 的深度体验,从部署到性能实战
第三章:实践与突破(13篇)
2、【金仓数据库产品体验官】实战测评:电科金仓数据库接口兼容性深度体验
3、KingbaseES与MongoDB全面对比:一篇从理论到实战的国产化迁移指南
4、从SQL Server到KingbaseES:一步到位的跨平台迁移与性能优化指南
5、ksycopg2实战:Python连接KingbaseES数据库的完整指南
6、KingbaseES:从MySQL兼容到权限隔离与安全增强的跨越
7、电科金仓KingbaseES数据库全面语法解析与应用实践
8、电科金仓国产数据库KingBaseES深度解析:五个一体化的技术架构与实践指南
9、电科金仓自主创新数据库KingbaseES在医疗行业的创新实践与深度应用
11、金仓数据库引领新能源行业数字化转型:案例深度解析与领导力展现
后期作品正在准备中,敬请关注......