说明:集群现有broker:node1,node2,node3三个,broker.id分别为0,1,2
已有两个topic:products、cities
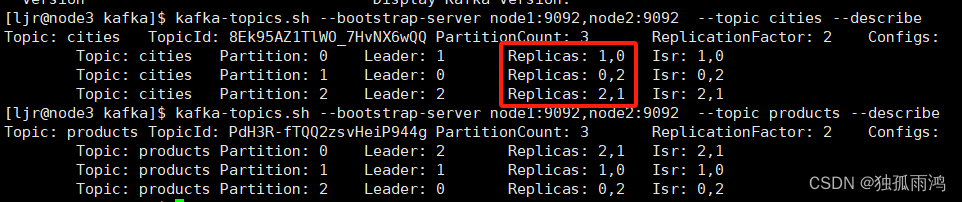
1、退役(Kafka集群中减少一个服务器broker2)
退役后要保证剩下的服务器数量大于等于备份数,否则会报错Error: Replication factor: 3 larger than available brokers: 2.;退役服务器中的数据在集群中剩下的服务器中实现负载均衡,在node3上进行操作。
操作步骤:
1.1创建json文件,写入需要均衡的主题
vim topic-move.json
{
"topics": [
{"topic": "products"},{"topic": "cities"}
],
"version": 1
}
1.2 生成储存规划
kafka-reassign-partitions.sh --bootstrap-server node1:9092,node2:9092 --topics-to-move-json-file topics-move.json --broker-list "0,1" --generate
去掉id为2的broker

执行后会给出退役broker2后数据在剩余服务器储存规划
创建json文件,把给出的规划复制粘贴进去
vim reassignment.json
{"version":1,"partitions":{"topic":"cities","partition":0,"replicas":\[1,0,"log_dirs":"any","any"},{"topic":"cities","partition":1,"replicas":0,1,"log_dirs":"any","any"},{"topic":"cities","partition":2,"replicas":1,0,"log_dirs":"any","any"},{"topic":"products","partition":0,"replicas":0,1,"log_dirs":"any","any"},{"topic":"products","partition":1,"replicas":1,0,"log_dirs":"any","any"},{"topic":"products","partition":2,"replicas":0,1,"log_dirs":"any","any"}]}
1.3 执行储存规划
kafka-reassign-partitions.sh --bootstrap-server node1:9092,node2:9092 --reassignment-json-file reassignment.json --execute

可以看到提示执行成功;
1.4 验证执行结果
kafka-reassign-partitions.sh --bootstrap-server node1:9092,node2:9092 --reassignment-json-file reassignment.json --verify

查看topic详情
kafka-topics.sh --bootstrap-server node1:9092,node2:9092 --topic cities --describe
kafka-topics.sh --bootstrap-server node1:9092,node2:9092 --topic products --describe
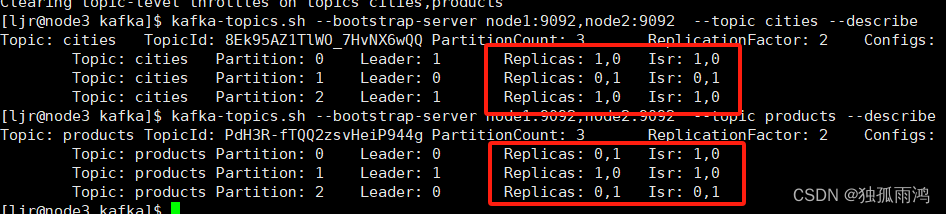
对比broker2退役前

可以看到退役后relplics和isr都剔除了2这个id
2、服役(在Kafka集群中新增一个服务器)
Kafka集群历史数据负载均衡,新增服务器承担一部分历史数据的存储任务,上文我们退役了broker2,下面我们让其重新服役
操作步骤:
2.1创建json文件,写入需要均衡的主题
vim topic-move.json
{ "topics": {"topic": "products"},{"topic": "cities"} ,"version": 1}
2.2 生成储存规划
kafka-reassign-partitions.sh --bootstrap-server node1:9092,node2:9092 --topics-to-move-json-file topics-move.json --broker-list "0,1,2" --generate 增加id为2的broker

执行后会对原集群内服务器的数据在增加了新一台服务器的基础上重新给出存储规划
创建json文件,把给出的规划复制粘贴进去
vim reassignment2.json
{"version":1,"partitions":{"topic":"cities","partition":0,"replicas":\[0,2,"log_dirs":"any","any"},{"topic":"cities","partition":1,"replicas":1,0,"log_dirs":"any","any"},{"topic":"cities","partition":2,"replicas":2,1,"log_dirs":"any","any"},{"topic":"products","partition":0,"replicas":0,1,"log_dirs":"any","any"},{"topic":"products","partition":1,"replicas":1,2,"log_dirs":"any","any"},{"topic":"products","partition":2,"replicas":2,0,"log_dirs":"any","any"}]}
2.3 执行储存规划
kafka-reassign-partitions.sh --bootstrap-server node1:9092,node2:9092 --reassignment-json-file reassignment2.json --execute

可以看到提示执行成功;
2.4 验证执行结果
kafka-reassign-partitions.sh --bootstrap-server node1:9092,node2:9092 --reassignment-json-file reassignment2.json --verify

查看topic详情
kafka-topics.sh --bootstrap-server node1:9092,node2:9092 --topic cities --describe
kafka-topics.sh --bootstrap-server node1:9092,node2:9092 --topic products --describe

对比broker2服役前

可以看到退役后relplics和isr都增加了2这个id