在分布式系统中,多进程/多节点并发访问共享资源时,必须通过分布式锁保证资源互斥性。Redis凭借高性能、易部署的特性,成为分布式锁最主流的实现方案。本文从原理到实操,从基础实现到生产级优化,完整拆解Redis分布式锁的核心逻辑与避坑点。
一、分布式锁
特性
一个可靠的分布式锁需满足以下特性:
- 互斥性:同一时间只能有一个客户端持有锁;
- 原子性:加锁/解锁操作必须原子执行,避免并发异常;
- 防死锁:客户端宕机后锁能自动释放;
- 可重入:同一客户端可重复获取已持有的锁;
- 防误删:不能删除其他客户端持有的锁。
synchronized 为什么失效?
在分布式秒杀场景 中,synchronized 完全无法解决核心问题 ------ 因为 synchronized 是本地锁 ,只能控制「单个 JVM 进程内」的并发,而分布式系统中多个服务节点(多 JVM)的并发请求,synchronized 根本无法约束,这也是分布式锁存在的核心意义。
java
// 错误示范:用synchronized加锁
@Override
public Result seckillVoucher(Long voucherId) {
synchronized (this) { // 仅能锁住当前JVM进程内的线程
// 库存校验、扣减、下单逻辑
}
}假设你部署了 3 个秒杀服务节点(Node1、Node2、Node3),每个节点都用 synchronized 加锁:
失效场景:
- 用户 A 的请求 1 打到 Node1,
synchronized锁住 Node1 的线程,执行扣库存(库存从 100→99); - 同一时间,用户 A 的请求 2 打到 Node2,Node2 的
synchronized只能锁住 Node2 的线程,但 Node2 感知不到 Node1 的锁,直接执行库存校验(此时 Redis 库存还是 100),扣库存后库存变为 99; - 最终导致「超卖」:同一用户重复下单,库存被重复扣减。
本质原因:
synchronized的锁对象是「JVM 进程内的对象」,不同节点的 JVM 内存隔离,锁信息无法共享;- **分布式系统的并发是「跨 JVM、跨节点」**的,必须依赖「第三方共享存储(Redis/ZK)」实现锁信息的全局共享。
总结:
synchronized是本地锁,仅适用于单机应用,分布式场景下完全失效;- 秒杀场景是典型的分布式并发,必须用 Redis 分布式锁(或 Lua 脚本)实现「全局锁」,约束所有节点的请求;
- 即使单机部署,Redis Lua 脚本的性能和原子性也远优于
**synchronized**,这也是秒杀场景首选 Redis 的核心原因。
常见分布式锁
常见分布式锁实现:
**MySQL:**MySQL本身就带有锁机制,由于业务特性使用MySQL作为分布式锁并不合适,而且性能一般,一般很少使用MySQL来实现分布式锁。
**ZooKeeper:**ZooKeeper是企业级开发中较好的一个实现分布式锁的方案,相对于Redis,ZooKeeper的部署和维护复杂一些。此外,ZooKeeper的性能相对较低,适用于对性能要求不高的场景。
**Redis:**Redis分布式锁的实现通常使用了SETNX(SET if Not eXists)命令和EXPIRE命令。使用SETNX可以尝试将一个键值对设置到Redis中,只有在该键不存在的情况下才能成功。成功获取锁的客户端可以设置一个过期时间,确保即使在发生故障的情况下,锁也能自动释放。
二、Redis分布式锁基础实现
1. 核心命令:SET NX EX
Redis单线程特性保证SET命令的原子性,结合NX(不存在才设置)和EX(自动过期)参数,是分布式锁的基础:
plain
# 加锁:lock_key为锁名,unique_id为客户端唯一标识(UUID+线程ID)
SET lock_key unique_id NX EX 30
# 执行结果:
# 加锁成功 → OK
# 锁已被占用 → (nil)NX:保证互斥性,只有锁不存在时才设置成功;EX 30:设置30秒过期时间,防止客户端宕机导致死锁;unique_id:唯一标识客户端,避免解锁时误删其他客户端的锁。
这样也行,分两步,但是容易死锁(第一步执行完就宕机)
plain
127.0.0.1:6379> setnx key1 1
(integer) 1
127.0.0.1:6379> setnx key1 1
(integer) 0
127.0.0.1:6379> expire key1 60
(integer) 12. 原子解锁:Lua脚本
Lua 脚本是 Redis 分布式锁最核心、最经典的解锁逻辑 ,目的是保证解锁操作的原子性 + 防止误删其他客户端的锁,
解锁时需先校验锁归属,再删除锁,两步操作必须原子执行(避免查锁和删锁之间锁过期):
lua
-- 解锁Lua脚本
-- 1. 校验锁的归属:判断锁key的值是否等于当前客户端的唯一标识
if redis.call('get', KEYS[1]) == ARGV[1] then
-- 删除锁,返回删除结果(成功返回1,失败返回0)
return redis.call('del', KEYS[1]) -- 归属一致
else
return 0 -- 归属不一致,返回失败
end执行脚本:
plain
EVAL "脚本内容" 1 lock_key unique_idKEYS[1]:Lua 脚本的「键参数」,对应解锁时传递的锁名 (比如order_lock)
ARGV[1]:Lua 脚本的「值参数」,对应解锁时传递的客户端唯一标识 (比如uuid-123456-thread-01)
如果**不用 Lua 脚本,**解锁会拆成两步 Redis 命令:
lua
# 第一步:查锁的值
GET order_lock
# 第二步:如果值匹配,删除锁
DEL order_lock这两步操作非原子性,会导致致命问题:
场景:客户端 A 持有锁(过期时间 30 秒),业务执行了 29 秒,此时执行GET order_lock拿到了自己的标识,但还没执行DEL,锁就过期了;客户端 B 立刻加锁成功,此时客户端 A 执行DEL,就会误删客户端 B 的锁。
而 Lua 脚本会把「查值 + 删锁」封装成原子操作(Redis 单线程执行脚本,执行过程中不会被其他命令打断),从根本上避免上述误删问题。
3.Lua 脚本在秒杀场景的实战应用
秒杀场景的核心诉求是「高性能 + 原子性」:
- 高性能:Redis 内存操作响应速度达毫秒级,远优于数据库直查;
- **原子性:**将秒杀核心逻辑封装在 Lua 脚本中,Redis 单线程执行脚本,避免多请求并发导致的超卖、重复下单;
- **异步解耦:**秒杀成功后,通过 Redis Stream 队列异步处理订单入库,同步接口仅返回订单 ID,提升吞吐量。
java
<!-- Spring Data Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>1. Lua 脚本加载(Java 层)
首先在 Java 中加载 Lua 脚本文件,通过DefaultRedisScript封装脚本信息,静态代码块保证脚本仅加载一次,避免重复 IO 开销:
java
// 定义Redis Lua脚本对象
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
// 指定脚本路径(resources目录下的seckill.lua)
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
// 声明脚本返回值类型(对应Lua脚本返回的0/1/2)
SECKILL_SCRIPT.setResultType(Long.class);
}2. 秒杀接口核心逻辑(Java 层)
Java 层负责接收秒杀请求、准备参数、执行 Lua 脚本,并根据脚本返回结果处理业务响应:
java
@Override
public Result seckillVoucher(Long voucherId) {
// 1. 获取当前登录用户ID(从ThreadLocal中获取)
Long userId = UserHolder.getUser().getId();
// 2. 生成全局唯一订单ID(基于Redis自增ID生成器)
long orderId = redisIdWorker.nextId("order");
// 3. 执行Lua脚本(核心原子操作)
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(), // KEYS[]参数(示例中暂未使用,生产需优化)
voucherId.toString(), // ARGV[1]:优惠券ID
userId.toString(), // ARGV[2]:用户ID
String.valueOf(orderId) // ARGV[3]:订单ID
);
int r = result.intValue();
// 4. 根据脚本返回值处理响应
if (r != 0) {
// 1=库存不足,2=重复下单
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 5. 秒杀成功,返回订单ID(后续异步处理订单入库)
return Result.ok(orderId);
}3. 秒杀核心逻辑(Lua 脚本层)
seckill.lua
java
-- 1. 接收Java层传递的参数
local voucherId = ARGV[1] -- 优惠券ID
local userId = ARGV[2] -- 用户ID
local orderId = ARGV[3] -- 订单ID
-- 2. 定义Redis业务Key
local stockKey = 'seckill:stock:' .. voucherId -- 库存Key
local orderKey = 'seckill:order:' .. voucherId -- 已下单用户集合Key
-- 3. 原子性业务逻辑
-- 3.1 校验库存(空值处理+数值校验)
local stock = redis.call('get', stockKey)
if not stock or tonumber(stock) <= 0 then
return 1 -- 库存不足,返回1
end
-- 3.2 校验重复下单(Set集合快速判断)
if redis.call('sismember', orderKey, userId) == 1 then
return 2 -- 重复下单,返回2
end
-- 3.3 扣减库存(原子操作,避免超卖)
redis.call('incrby', stockKey, -1)
-- 3.4 记录已下单用户(防止重复下单)
redis.call('sadd', orderKey, userId)
-- 3.5 发送下单消息到Stream队列(异步处理订单入库)
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
-- 3.6 秒杀成功,返回0
return 0三、进阶优化:可重入与自动续期
1. 可重入锁实现
你想理解 "可重入" 的核心含义,简单来说:
一个执行体(线程 / 进程)在已经持有某把锁的情况 下,再次请求获取这把锁时不会被自己卡住(死锁),而是能成功拿到锁。
反之,"不可重入锁" 会因为自己持有锁又去抢锁,导致自己堵死自己。
基础锁无法支持重入(同一客户端重复加锁会失败),需基于Redis哈希结构实现:

lua
-- 加锁Lua脚本(可重入)
if redis.call('hexists', KEYS[1], ARGV[1]) == 1 then
redis.call('hincrby', KEYS[1], ARGV[1], 1) -- 重入次数+1
redis.call('expire', KEYS[1], ARGV[2])
return 1
elseif redis.call('setnx', KEYS[1], ARGV[1]) == 1 then
redis.call('expire', KEYS[1], ARGV[2]) -- 首次加锁
return 1
else
return 0 -- 锁被其他客户端持有
end
-- 解锁Lua脚本(可重入)
if redis.call('hexists', KEYS[1], ARGV[1]) == 0 then
return nil
elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 then
return redis.call('del', KEYS[1]) -- 重入次数归0,删除锁
else
return 1 -- 仅减少重入次数
end
public class DemoService {
@Resource
private RedissonClient redissonClient;
public void add1() {
// 获取分布式锁对象
RLock lock = redissonClient.getLock("heimalock");
// 尝试获取锁,最多等待3秒,锁自动释放时间为30秒
// boolean isLock = lock.tryLock(3, 30, TimeUnit.SECONDS);
// 尝试获取锁(非阻塞)
boolean isLock = lock.tryLock();
try {
// 执行业务逻辑
add2();
} finally {
// 释放锁(保证无论业务是否异常,锁都会被释放)
lock.unlock();
}
}
public void add2() {
// 获取分布式锁对象(与add1使用同一锁名,体现可重入特性)
RLock lock = redissonClient.getLock("heimalock");
// 尝试获取锁(非阻塞)
boolean isLock = lock.tryLock();
try {
// 执行业务逻辑
} finally {
// 释放锁
lock.unlock();
}
}
}代码说明与问题点:
- 可重入特性 :Redisson 的
RLock是可重入锁,同一线程在add1()中获取锁后,调用add2()时可以再次获取同一把锁,不会被阻塞。 - 锁释放优化 :原代码将
unlock()直接写在方法末尾,存在业务异常时锁无法释放的风险,因此我将其放入finally块,保证锁一定会被释放。 - 潜在问题:
-
tryLock()是非阻塞的,如果获取锁失败会直接执行业务,可能导致并发问题,生产中建议添加获取失败的处理逻辑(如重试或抛出异常)。- 未指定锁超时时间,Redisson 会启用看门狗自动续期,适合长时间业务,但需注意避免死锁。
2. 自动续期(WatchDog看门狗机制)
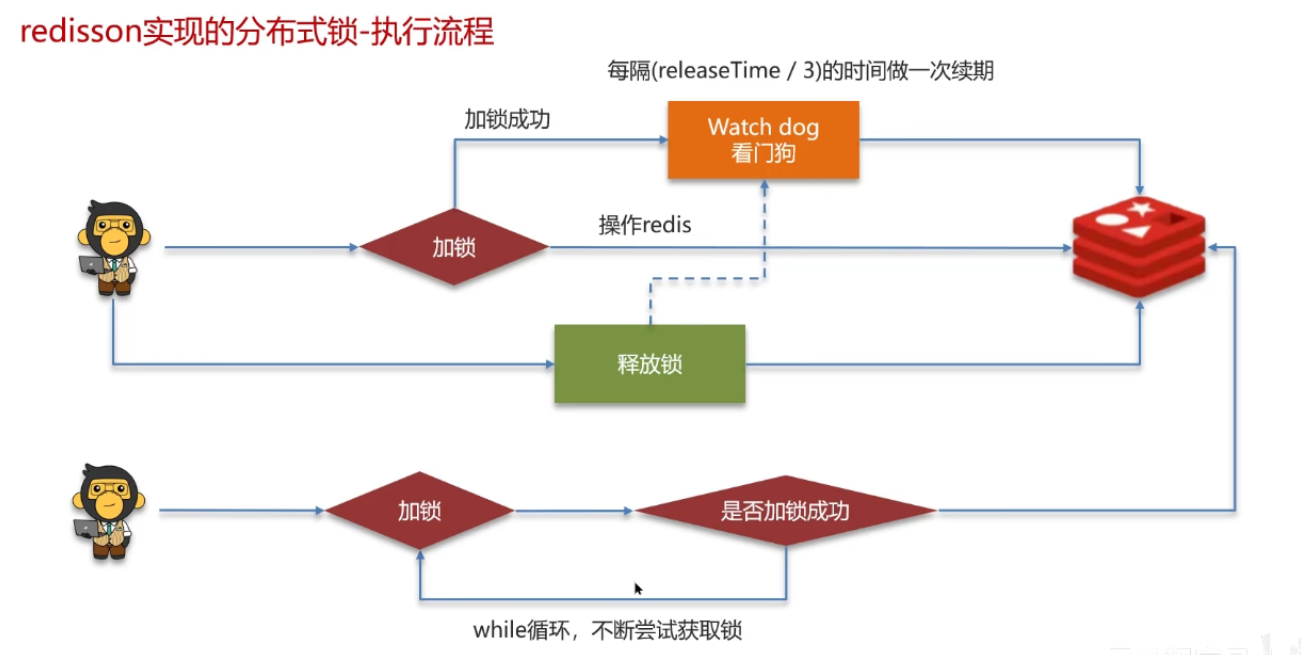
若业务执行时间超过锁过期时间,会导致锁提前释放,需通过「看门狗」自动续期:
- 原理:客户端持有锁时,启动后台线程,每隔10秒(过期时间的1/3)执行
**EXPIRE**命令重置过期时间; - 实践:直接使用Redisson框架 ,内置看门狗机制,无需手动实现。
3.Redisson 看门狗机制(实践)
lua
<!--redisson-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>代码示例:
lua
@Resource
private RedissonClient redissonClient;
//redissonClient 内置看门狗机制
private void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
Long voucherId = voucherOrder.getVoucherId();
// 创建锁对象
RLock redisLock = redissonClient.getLock("lock:order:" + userId);
// 尝试获取锁
boolean isLock = redisLock.tryLock();
// 判断
if (!isLock) {
// 获取锁失败,直接返回失败或者重试
log.error("不允许重复下单!");
return;
}
try {
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
log.error("不允许重复下单!");
return;
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
log.error("库存不足!");
return;
}
// 7.创建订单
save(voucherOrder);
} finally {
// 释放锁
redisLock.unlock();
}
}1.RLock redisLock = redissonClient.getLock("lock:order:" + userId);
- 锁名设计 :
lock:order:用户ID(比如lock:order:1001),核心是「按用户粒度加锁」------ 只限制同一个用户重复下单,不同用户之间不互斥,保证高并发下的性能(如果用全局锁,所有用户秒杀都要排队,性能极低); RLock:Redisson 封装的分布式可重入锁,兼容 JavaLock接口,使用方式和本地锁(ReentrantLock)几乎一致。
2.boolean isLock = redisLock.tryLock();
tryLock():非阻塞加锁 ,立即返回结果(获取锁成功返回true,失败返回false);对比lock():lock()是阻塞加锁,获取不到锁会一直等待,秒杀场景下会导致请求排队,甚至超时,所以优先用tryLock();- 核心目的:同一用户同时发起多个秒杀请求时,只有一个请求能拿到锁,其他请求直接返回「不允许重复下单」,避免重复创建订单。
- 加锁失败处理:快速失败
3.try里面是业务核心机制
- 锁内校验重复下单:即使加了分布式锁,仍需查询数据库校验(防止锁过期后,用户重复请求创建订单);
- 扣减库存的原子性 :
update语句中gt("stock", 0)保证「只有库存 > 0 时才扣减」,避免超卖(数据库层面的原子操作); - 所有核心业务在锁内执行,保证同一用户的请求串行化,避免重复下单、超卖。
4.释放锁:finally 块保证必释放
**unlock()**会先校验锁归属(只有当前客户端持有锁才会释放),避免误删其他客户端的锁(Redisson 内部已封装此逻辑)。
Redisson 看门狗机制(核心亮点)
1. 看门狗的作用
代码中没有手动设置锁的过期时间,但不会出现「业务执行时间过长导致锁过期」的问题 ------ 因为 Redisson 内置了看门狗(Watch Dog):
- 触发条件 :使用
tryLock()/lock()且未指定过期时间时,自动启用看门狗; - 核心逻辑:
-
- 加锁成功后,看门狗启动一个后台线程(默认每 10 秒执行一次);
- 只要客户端还持有锁,看门狗就会自动将锁的过期时间重置为「默认 30 秒」;
- 当客户端执行完业务、调用
unlock()释放锁后,看门狗线程停止;
- 解决的问题:避免业务执行时间超过锁过期时间,导致锁提前释放,进而引发重复下单。
2. 手动指定过期时间(可选)
如果想手动控制锁过期时间,可使用 tryLock 重载方法:
java
// 尝试获取锁,最多等待1秒,持有锁最多30秒(超过30秒自动释放,看门狗失效)
boolean isLock = redisLock.tryLock(1, 30, TimeUnit.SECONDS);代码优缺点分析:
优点
- 细粒度锁:按用户 ID 加锁,不同用户不互斥,并发性能高;
- 防死锁:看门狗自动续期 + finally 块释放锁,双重保障;
- 防重复下单:分布式锁 + 数据库查询双重校验,彻底避免重复;
- 防超卖 :数据库更新时加
stock > 0条件,保证库存不会为负; - 易用性:Redisson 封装了分布式锁的底层细节(Lua 脚本、原子操作、续期),开发无需关注底层。
待优化点
- 库存校验与扣减分离:锁内先查库存(代码中未显式查库存,直接扣减),高并发下可能出现「库存为 0 但仍扣减」的极端情况(建议扣减前先查库存);
- 无重试机制 :
tryLock()失败后直接返回,可增加「有限重试」(比如重试 3 次,每次间隔 100ms),提升用户体验; - 分布式事务:扣减库存 + 创建订单是两个数据库操作,无分布式事务保障(比如库存扣减成功但订单创建失败,会导致库存少了但订单没创建),可引入 Seata 或「补偿机制」。
核心总结
- 这段代码是生产级秒杀订单创建逻辑,核心是 Redisson 分布式锁按用户粒度加锁,解决重复下单问题;
- Redisson 看门狗自动续期,避免锁过期导致的并发问题,无需手动处理续期;
- 锁内必须做「重复下单校验 + 库存扣减 + 订单创建」,且释放锁必须放在 finally 块;
- 设计思路:细粒度锁保证性能 + 双重校验保证正确性 + 看门狗避免
四、生产避坑:主从一致性问题
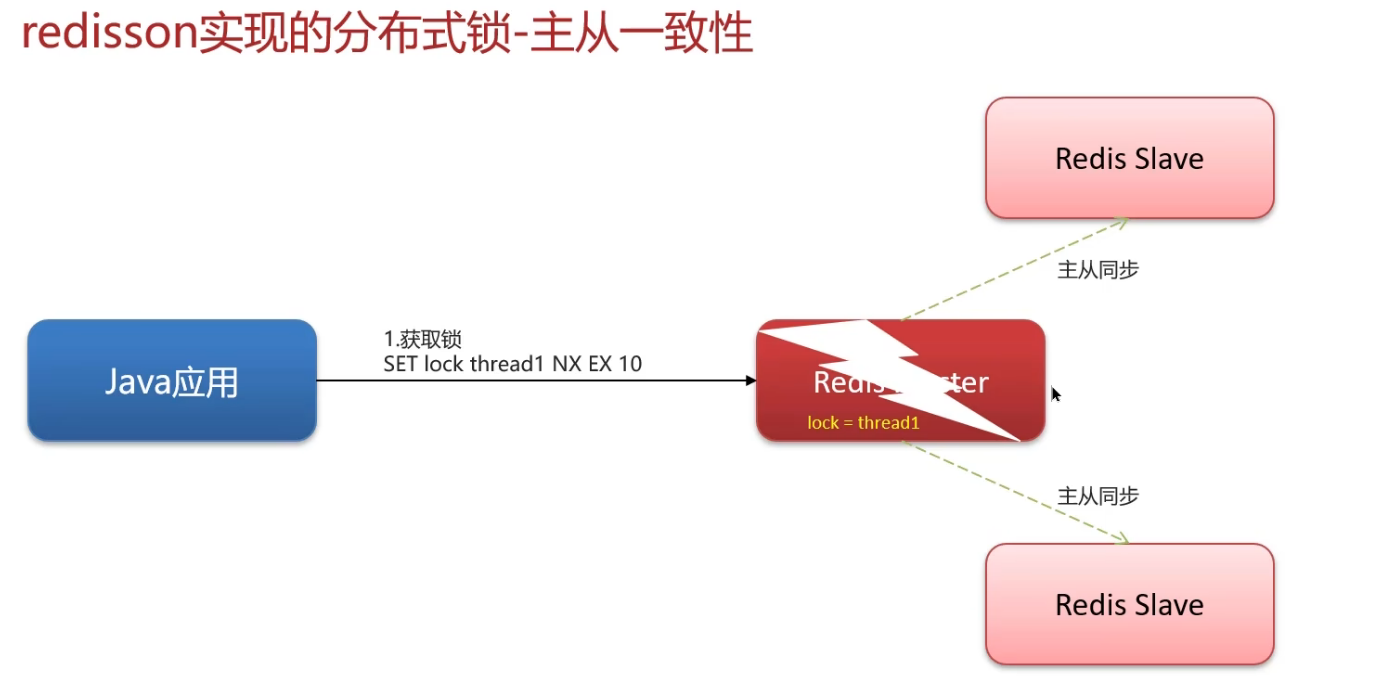
1. 问题根源
Redis主从架构下,主节点加锁成功后,若未同步锁数据到从节点就宕机 ,从节点升级为主节点 后,其他客户端可重新加锁,导致锁失效。
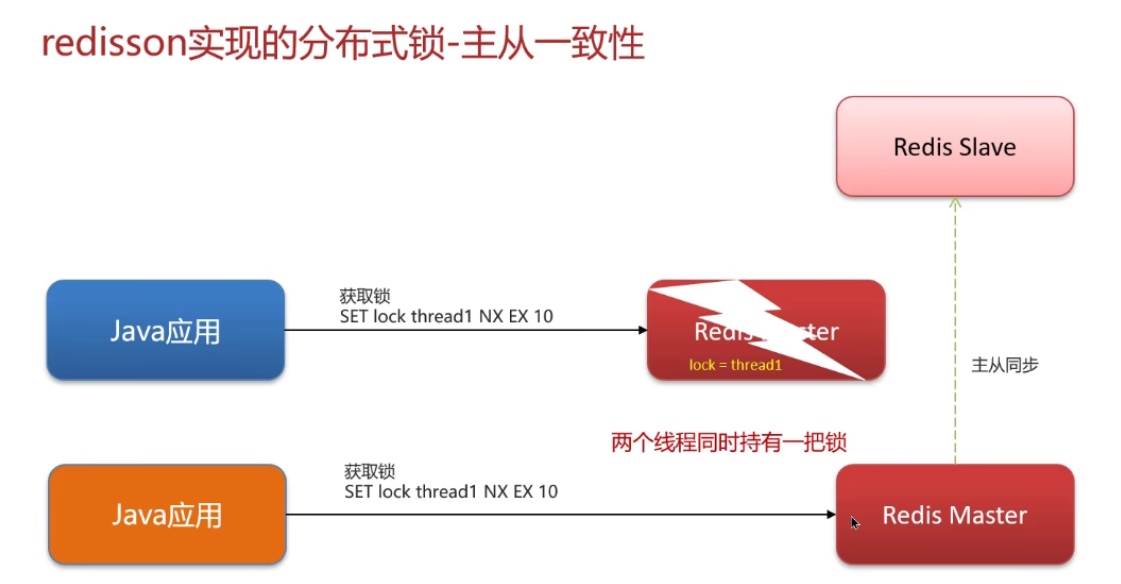
关键问题:「其他客户端可重新加锁」到底怎么了?
到这一步,核心问题就暴露了:
- 客户端 A:以为自己还持有锁(主节点宕机前加锁成功),继续执行「扣库存、创建订单」等核心业务;
- 客户端 B:在新主节点上加锁成功,也认为自己持有唯一锁,也执行相同的核心业务;
- 最终结果:同一把锁被 A 和 B 同时持有,分布式锁的「互斥性」完全失效,直接导致:
-
- 秒杀场景:超卖(A 和 B 都扣减库存,库存为负);
- 订单场景:重复下单(A 和 B 都创建同一个用户的订单);
- 转账场景:重复扣款(A 和 B 都扣同一个用户的余额)。
核心根源:异步同步 + 主从切换的数据丢失
- Redis 主从的数据同步是异步的:主节点执行写操作后,不会等从节点同步完成再返回结果,而是先返回「操作成功」,再异步把数据发给从节点;
- 主从切换时,未同步的数据会永久丢失:原主节点宕机后,未同步到从节点的
**lock_key**(锁数据)没了,新主节点完全不知道「客户端 A 已经加过锁」,所以会允许客户端 B 重新加锁。
2. 解决方案
方案1:RedLock(红锁)
部署3+个独立Redis节点**(无主从),客户端向所有节点加锁,满足以下条件则加锁成功**:
- 超过半数节点加锁成功;
- 总耗时≤锁过期时间的一半。
解锁时需向所有节点释放锁,保证锁的一致性。
方案2:替换强一致性中间件
若业务要求100%强一致性,放弃Redis,改用:
- ZooKeeper/etcd:基于CP模型,临时有序节点实现分布式锁,主节点宕机时临时节点自动删除;
- 数据库行锁 :通过唯一索引+
select ... for update实现,完全保证一致性,但性能较低。
五、分布式锁选型对比
| 方案 | 一致性 | 性能 | 部署难度 | 死锁风险 | 适用场景 |
|---|---|---|---|---|---|
| Redis基础锁 | AP | 极高 | 低 | 低 | 高并发、性能优先 |
| Redis红锁 | 强一致 | 中 | 中 | 低 | 高并发+需一致性 |
| ZooKeeper | CP | 中 | 高 | 无 | 核心业务、强一致性 |
| 数据库锁 | ACID | 极低 | 低 | 高 | 低并发、低成本 |
六、规范
- 优先使用Redisson:封装了可重入锁、公平锁、红锁等,内置看门狗,开箱即用;
- 锁名规范 :按业务维度命名(如
order:lock:1001),避免冲突; - 过期时间合理:根据业务耗时设置,留10%冗余(如业务最多执行20秒,设EX 25);
- 集群适配 :将锁key通过
KEYS[]传递给Lua脚本,保证集群槽位一致; - 异常处理:加锁失败后重试需设置间隔(如100ms),避免高频重试压垮Redis。
七、总结
Redis分布式锁是高并发场景的首选方案,核心是通过SET NX EX保证原子加锁,Lua脚本保证原子解锁;进阶场景需解决可重入、自动续期、主从一致性问题;强一致性业务可选择RedLock或替换为ZooKeeper。生产中优先使用成熟框架(如Redisson),避免重复造轮子,同时结合业务场景权衡性能与一致性。