1. 引言
1.1 图神经网络GNN概述
图神经网络(Graph Neural Network,GNN)是一种专门用于处理图结构数据的神经网络方法。它起源于2005年,当时Gori等人首次提出了GNN的概念,用于学习图中的节点特征以及它们之间的关系。随后,随着深度学习技术的快速发展,GNN得到了广泛的关注和研究。
1.1.1 GNN的核心算法思想
GNN的核心思想是通过迭代地聚合节点的邻居信息来更新节点的表示,从而捕获图的结构信息。这种聚合过程可以看作是一种特殊的图卷积操作,使得GNN能够有效地处理图数据,并提取出节点和边之间的关系特征。主流的GNN算法包括图卷积神经网络(GCN)、图自编码器(Graph Autoencoder)、图生成网络(Graph Generative Network)等。
1.1.2 GNN的应用场景
GNN的应用场景非常广泛,包括社交网络分析、推荐系统、生物信息学、交通流预测等。例如,在社交网络中,GNN可以用于分析用户之间的关系,预测用户的兴趣和行为;在推荐系统中,GNN可以利用用户-物品交互图来提供个性化的推荐;在生物信息学中,GNN可以用于分析蛋白质-蛋白质相互作用网络,预测蛋白质的功能和性质。
1.1.3 GNN图神经网络面临的挑战
尽管GNN在处理图数据方面取得了显著的进展,但仍面临一些挑战。首先,大规模图数据的处理是一个难题,需要设计高效的GNN架构和训练算法来应对。其次,动态图数据的处理也是一个挑战,因为图的结构和节点属性可能会随时间发生变化。此外,GNN在处理异构图(即节点和边具有不同类型和属性的图)时也需要进一步的研究。
未来,GNN的研究将继续关注提高模型的性能、扩展应用范围以及解决上述挑战。随着深度学习技术的不断进步和计算能力的提升,GNN有望在更多领域发挥重要作用,并推动图数据分析和应用的进一步发展。
1.2 节点分类
节点分类(Node Classification)是图数据分析中的一个重要任务,其目标是根据图的结构信息和节点的属性特征来预测图中节点的类别标签。在图数据中,节点通常表示实体,而边则表示实体之间的关系。节点分类在许多领域都有广泛的应用,如社交网络分析、生物信息学、推荐系统等。
1.2.1 节点分类任务的步骤
在图神经网络(Graph Neural Networks, GNNs)的框架下,节点分类通常通过以下步骤实现:
-
图数据表示:首先,需要将图数据转化为神经网络可以处理的表示形式。这通常包括节点特征矩阵(用于描述节点的属性信息)和邻接矩阵(用于描述节点之间的关系)。
-
图神经网络层:然后,使用图神经网络层来聚合节点的邻居信息。这些层通过特定的图卷积操作或图注意力机制来更新节点的表示,从而捕获图的结构信息。不同的GNN架构(如Graph Convolutional Networks, GraphSAGE, Graph Attention Networks等)具有不同的聚合函数和更新规则。
-
特征传播与聚合:在图神经网络中,特征传播是一个关键步骤。通过迭代地聚合节点的邻居信息,每个节点的表示都会逐渐融合其局部邻域的信息。这种过程可以重复多次,以便捕获更广泛的图结构信息。
-
节点分类:最后,将聚合后的节点表示输入到分类器(如全连接层、softmax层等)中进行分类。分类器会根据节点的表示预测其所属的类别标签。
节点分类任务中,GNNs的优势在于它们能够捕获图数据的复杂依赖关系,并利用这些信息来提高分类性能。与传统的机器学习方法相比,GNNs能够更好地处理图数据的非欧几里得结构,并考虑节点之间的连接关系。
1.2.2 节点分类面临的挑战
然而,节点分类也面临一些挑战。首先,当图的规模非常大时,GNNs的训练和推理过程可能会变得非常耗时。其次,对于动态图数据,GNNs需要能够处理节点和边的添加、删除以及属性变化等情况。此外,当图中的节点和边具有不同的类型和属性时,GNNs也需要具备处理异构图的能力。
展望将来,节点分类的研究将继续关注提高GNNs的性能、扩展应用范围以及解决上述挑战。随着深度学习技术的不断进步和计算能力的提升,GNNs有望在更多领域发挥重要作用,并推动图数据分析和应用的进一步发展。
1.3 GNN模型用于节点分类
图神经网络(GNN)在节点分类任务中发挥着关键作用。节点分类的目标是根据图的结构信息和节点的属性特征来预测图中每个节点的类别标签。GNN模型通过迭代地更新节点的表示来捕获节点之间的相互作用和依赖关系,进而实现高效的节点分类。
1.3.1 GNN进行节点分类的原理
GNN模型的工作原理在于通过聚合节点的邻居信息来更新节点的表示。首先,每个节点的表示向量被初始化为其初始特征向量。然后,在信息传递阶段,GNN通过图卷积操作或图注意力机制来聚合节点的邻居节点的信息,并更新节点的表示。这一过程中,邻居节点的信息被加权求和或聚合,以反映它们对目标节点的影响。通过多次迭代信息传递和聚合邻居信息的过程,GNN能够逐步更新节点的表示,使其包含更丰富的图结构信息。
1.3.2 GNN的优势及应用
GNN模型在节点分类任务中的优势在于其能够捕获图数据中的复杂依赖关系和结构信息,这对于节点分类任务至关重要。同时,GNN模型具有灵活性和可扩展性,能够处理具有不同大小和结构的图数据,并适应大规模图数据的处理需求。
GNN在节点分类任务中的应用广泛,涵盖了社交网络分析、生物信息学和推荐系统等领域。在社交网络中,GNN可以识别用户所属的潜在角色或群体,并根据兴趣对用户进行分类。在生物信息学中,GNN可以应用于分子结构的分类,预测分子的功能和性质。在推荐系统中,GNN可以处理用户-项目交互的图结构数据,预测用户对未知物品的喜好程度,并向用户推荐合适的项目。
随着深度学习技术的不断进步和计算能力的提升,GNN有望在更多领域发挥重要作用,并推动图数据分析和应用的进一步发展。
2. GNN模型实现节点分类的过程
许多在各种机器学习(ML)应用中的数据集,其实体之间存在结构关系,这些关系可以表示为图。这类应用包括社交和通信网络分析、交通预测以及欺诈检测。图表示学习旨在构建和训练用于图数据集的模型,以便用于各种机器学习任务。
本文的例子展示了一个图神经网络(GNN)模型的简单实现。该模型用于Cora数据集上的节点预测任务,以根据论文的词汇和引用网络来预测论文的主题。
本文我们从头开始实现了一个图卷积层,以便更好地理解它们是如何工作的。然而,也有许多基于TensorFlow的专用库提供了丰富的GNN API,例如Spectral、StellarGraph和GraphNets等。
2.1 设置
python
import os
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers2.2 准备下载
以下的段代码是用于下载和解压缩Cora数据集的Python脚本:
-
下载数据集 :
-
使用
keras.utils.get_file函数来下载数据集。这个函数是Keras提供的,用于下载文件并保存到本地路径。 -
fname="cora.tgz": 指定下载文件的名称为cora.tgz。 -
origin="https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz": 指定数据集的URL来源,即数据集在互联网上的位置。 -
extract=True: 表示下载完成后自动解压缩文件。
-
-
设置数据目录 :
-
data_dir = os.path.join(os.path.dirname(zip_file), "cora"): 这行代码设置了解压缩后数据的存放目录。 -
os.path.dirname(zip_file): 获取zip_file变量的目录路径,即下载文件的存放路径。 -
os.path.join(..., "cora"): 将下载文件的目录路径与"cora"字符串连接,形成完整的数据集目录路径。
-
代码的作用是确保Cora数据集被下载并解压缩到程序可以访问的目录中。Cora数据集通常用于图神经网络的节点分类任务,包含了论文的引用关系和内容信息。在机器学习或深度学习项目中,这样的数据准备步骤是常见的,以便于后续的数据加载和处理。
python
zip_file = keras.utils.get_file(
fname="cora.tgz",
origin="https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz",
extract=True,
)
data_dir = os.path.join(os.path.dirname(zip_file), "cora")2.3 数据预处理
2.3.1 加载并可视化数据集
处理并可视化数据集代码是用来加载和处理Cora数据集中的引用信息:
-
加载数据 :
- 使用
pd.read_csv函数从Pandas库来读取CSV文件。这个函数是用来读取CSV文件并将其转换成DataFrame对象的。
- 使用
-
指定文件路径 :
os.path.join(data_dir, "cora.cites"): 这行代码通过os.path.join函数来拼接数据集的基础目录data_dir和子目录"cora.cites",形成完整的文件路径。data_dir是在上一段代码中设置的Cora数据集的目录路径。
-
设置分隔符和列名 :
-
sep="\t": 指定分隔符为制表符(\t),这意味着CSV文件中的列是以制表符分隔的。 -
header=None: 指定文件中没有头部信息,即列名不在文件的第一行中。 -
names=["target", "source"]: 指定列名,即使文件没有头部信息,这里明确了两列的名称分别为"target"和"source"。
-
-
打印引用数据的形状 :
print("Citations shape:", citations.shape): 打印出DataFramecitations的形状,即行数和列数。这通常用于检查数据加载是否正确,以及理解数据集的规模。
引用数据集citations通常包含了两列,一列是被引用论文的ID(target),另一列是引用它的论文的ID(source)。在图神经网络中,这些引用可以表示为图中的边,其中每条边连接了两个节点(论文),用于捕捉论文之间的相互关系。
python
citations = pd.read_csv(
os.path.join(data_dir, "cora.cites"),
sep="\t",
header=None,
names=["target", "source"],
)
print("Citations shape:", citations.shape)2.3.2 展示数据框
下面的代码将展示引文(citations)数据框的一个样本。目标列包含了由源列中的论文ID所引用的论文ID。
在Pandas中,citations.sample(frac=1).head()这行代码执行了以下操作:
-
citations.sample(frac=1): 这是一个方法调用,作用是从citationsDataFrame中随机抽取记录。参数frac=1表示抽取全部的记录(即100%的记录)。如果不指定frac或者设置frac<1,则会按照给定的比例随机抽取记录。 -
.head(): 这个方法调用返回采样结果的前n行,其中n默认为5。也就是说,它会返回一个DataFrame的前5行。这是查看DataFrame内容的一个快速方法,特别是当你不想查看整个数据集时。
综合来看,citations.sample(frac=1).head()这行代码的作用是:从citations DataFrame中随机抽取全部记录,然后返回这些记录的前5行。这通常用于获取数据集的一个随机样本,以便进行快速检查或展示数据的多样性。
请注意,每次执行这个操作时,由于是随机采样,返回的5行可能会不同。如果你希望每次采样都得到相同的结果,可以在调用sample方法时指定随机种子,例如citations.sample(frac=1, random_state=1).head()。
python
citations.sample(frac=1).head()2.3.3 加载数据到Pandas DataFrame
现在,让我们将论文数据加载到Pandas DataFrame中。
首先创建了一个名为column_names的列表,它包含了Cora数据集中论文内容文件的所有列名。第一列是paper_id,接下来的1433列用term_0到term_1432命名,代表论文中术语的存在与否,最后一列是subject,表示论文的主题。
然后使用pd.read_csv函数读取Cora数据集的cora.content文件,这个文件包含了论文的内容信息。通过os.path.join函数构建文件的完整路径,sep参数指定了制表符作为字段的分隔符,header参数设置为None表示文件中没有提供列名的头部行,names参数用来指定前面创建的列名列表。
最后,使用print函数打印出加载后的papers DataFrame的形状,即它包含的行数和列数,这有助于了解数据集的规模。
python
column_names = ["paper_id"] + [f"term_{idx}" for idx in range(1433)] + ["subject"]
papers = pd.read_csv(
os.path.join(data_dir, "cora.content"), sep="\t", header=None, names=column_names,
)
print("Papers shape:", papers.shape)
python
Papers shape: (2708, 1435)2.3.4 展示Pandas DataFrame
展示论文DataFrame的一个样本。该DataFrame包括paper_id和subject列,以及1,433个二进制列,这些列表示相应术语是否存在于论文中。
python
print(papers.sample(5).T)显示每个主题的论文数量
python
print(papers.subject.value_counts())
python
Neural_Networks 818
Probabilistic_Methods 426
Genetic_Algorithms 418
Theory 351
Case_Based 298
Reinforcement_Learning 217
Rule_Learning 180
Name: subject, dtype: int642.3.5 创建数据索引和转换
索引和转换的目的是对Cora数据集中的论文和引用信息进行预处理,使其适合用于图神经网络模型的训练。
-
主题索引的创建 :首先,代码提取
subject列中所有独特的主题,并按字典顺序对它们进行排序,生成一个有序列表class_values。 -
主题到索引的映射 :接着,通过枚举排序后的主题列表,创建一个字典
class_idx,该字典将每个主题映射到一个唯一的索引,这个索引将用于后续模型训练中的主题表示。 -
论文索引的创建 :类似地,代码对
paper_id列中的所有独特论文ID进行排序,并创建一个字典paper_idx,将排序后的论文ID映射到它们各自的索引。 -
论文ID的转换 :在
papers数据集中,使用paper_idx字典将paper_id列中的论文ID转换为对应的数值索引。 -
引用数据的转换 :在
citations数据集中,使用paper_idx字典将source(引用源)和target(引用目标)列中的论文ID转换为数值索引。 -
主题的转换 :最后,使用
class_idx字典将papers数据集中的subject列中的主题名称转换为对应的数值索引。
通过这些步骤,原始数据集中的文本标识符被转换为模型易于处理的数值形式,为后续的图神经网络模型训练做好了准备。这种转换有助于模型更高效地学习论文之间的引用关系以及它们对应的主题分类。
python
class_values = sorted(papers["subject"].unique())
class_idx = {name: id for id, name in enumerate(class_values)}
paper_idx = {name: idx for idx, name in enumerate(sorted(papers["paper_id"].unique()))}
papers["paper_id"] = papers["paper_id"].apply(lambda name: paper_idx[name])
citations["source"] = citations["source"].apply(lambda name: paper_idx[name])
citations["target"] = citations["target"].apply(lambda name: paper_idx[name])
papers["subject"] = papers["subject"].apply(lambda value: class_idx[value])2.3.6 可视化引用图
代码用于可视化Cora数据集的引用网络,具体步骤如下:
-
设置图形大小 :使用
plt.figure函数创建一个新的图形对象,并设置图形的大小为10x10英寸,以确保有足够的空间来展示网络图。 -
准备颜色列表 :从
papersDataFrame中提取subject列的所有唯一值,将其转换为列表colors。这个列表将用于为图中的节点着色,每个主题的论文将使用不同的颜色。 -
生成图数据结构 :利用
networkx库的from_pandas_edgelist函数,从citationsDataFrame中随机抽取1500条引用记录来构建图cora_graph。这个图的节点代表论文,边代表论文之间的引用关系。 -
筛选节点主题 :从
papersDataFrame中筛选出与cora_graph图中节点对应的论文主题列表subjects。这确保了图中的每个节点都能根据其主题着上正确的颜色。 -
绘制网络图 :使用
networkx的draw_spring函数绘制图cora_graph,其中node_size参数设置为15,控制节点的大小。node_color参数设置为subjects列表,这样每个节点就会根据其主题被着上不同的颜色。
通过这种方式,代码生成了一个视觉化的网络图,其中节点代表论文,节点之间的连线代表引用关系,节点的颜色表示论文的主题。这种可视化有助于直观地理解数据集中论文之间的相互关系及其主题分布。
python
plt.figure(figsize=(10, 10))
colors = papers["subject"].tolist()
cora_graph = nx.from_pandas_edgelist(citations.sample(n=1500))
subjects = list(papers[papers["paper_id"].isin(list(cora_graph.nodes))]["subject"])
nx.draw_spring(cora_graph, node_size=15, node_color=subjects)图中的每个节点代表一篇论文,节点的颜色对应其主题。请注意,我们仅显示数据集中论文的一个样本。

2.3.7 数据分割
将数据集划分为分层的训练集和测试集
代码的目的是将Cora数据集分割为训练集和测试集,具体步骤如下:
-
初始化空列表 :首先,初始化两个空列表
train_data和test_data,用于存储训练集和测试集的数据。 -
分组并随机选择 :使用
papers.groupby("subject")对数据集中的论文按主题进行分组。对于每个主题组,使用np.random.rand生成一个与该组论文数量相同的随机数数组。通过比较这些随机数与0.5,决定每篇论文是否被选入训练集(小于或等于0.5的被选入训练集,其余的被选入测试集)。 -
分配训练集和测试集 :对于每个主题组,根据随机选择的结果,将论文分配到
train_data和test_data列表中。 -
合并数据 :使用
pd.concat函数将train_data和test_data列表中的所有分组数据合并成两个单独的DataFrame,分别代表整个训练集和测试集。 -
随机打乱数据 :使用
.sample(frac=1)确保训练集和测试集中的论文是随机分布的,frac=1表示打乱全部数据。 -
打印数据形状:最后,打印出训练集和测试集的形状,即它们各自的行数和列数,以验证数据集的规模。
通过这种方式,代码实现了数据集的分层抽样,确保了每个主题在训练集和测试集中都有代表性,同时也保证了数据的随机性,这对于训练和评估机器学习模型是非常重要的。
python
train_data, test_data = [], []
for _, group_data in papers.groupby("subject"):
# Select around 50% of the dataset for training.
random_selection = np.random.rand(len(group_data.index)) <= 0.5
train_data.append(group_data[random_selection])
test_data.append(group_data[~random_selection])
train_data = pd.concat(train_data).sample(frac=1)
test_data = pd.concat(test_data).sample(frac=1)
print("Train data shape:", train_data.shape)
print("Test data shape:", test_data.shape)2.4 训练和评估实验
2.4.1 定义超参数
设置用于训练图神经网络模型的超参数:
-
隐藏单元数 (
hidden_units): 定义了神经网络中隐藏层的单元数。在这个例子中,有两个隐藏层,每层都有32个单元。这些单元负责学习数据中的复杂特征。 -
学习率 (
learning_rate): 这是优化算法在每一步更新模型权重时使用的比例因子。这里设置为0.01,这是一个常用的起始学习率,用于控制模型训练过程中参数更新的速度。 -
dropout率 (
dropout_rate): Dropout是一种正则化技术,用于防止神经网络过拟合。这里设置为0.5,意味着在训练过程中,每层的每个神经元有50%的概率被随机丢弃(即暂时从网络中移除),这有助于网络学习更加鲁棒的特征。 -
训练周期数 (
num_epochs): 表示整个数据集将被用于训练模型的次数。这里设置为300,意味着每个样本将被用于训练模型300次。较高的周期数可以提高模型的训练质量,但也可能导致过拟合。 -
批量大小 (
batch_size): 指定了每次训练迭代中使用的样本数量。这里设置为256,意味着每次迭代将随机选择256个样本来计算损失函数并更新模型权重。批量大小会影响模型的收敛速度和训练稳定性。
这些超参数的选择对模型的性能和训练过程有重要影响。通常,这些值需要根据具体问题和数据集进行调整,以获得最佳的模型表现。
python
hidden_units = [32, 32]
learning_rate = 0.01
dropout_rate = 0.5
num_epochs = 300
batch_size = 2562.4.2 编译和训练输入模型
定义了一个名为 run_experiment 的函数,用于编译和训练给定的图神经网络模型,并返回训练过程中的历史记录。
-
编译模型 :使用
model.compile方法配置模型的训练参数。-
optimizer: 指定优化器为keras.optimizers.Adam,这是一个基于Adam算法的优化器,通常用于训练深度学习模型。 -
learning_rate: 传递前面定义的学习率,优化器将使用这个速率来调整模型的权重。 -
loss: 指定损失函数为keras.losses.SparseCategoricalCrossentropy,这是一个适用于多分类问题的损失函数,from_logits=True表示模型输出未经过softmax转换的原始分数。 -
metrics: 指定训练过程中要监控的指标,这里使用了keras.metrics.SparseCategoricalAccuracy,它计算模型预测的准确率。
-
-
创建早停法回调 :使用
keras.callbacks.EarlyStopping定义一个早停回调,以避免过拟合。-
monitor="val_acc": 指定监控的指标为验证集上的准确率val_acc。 -
patience=50: 如果验证集上的准确率在50个周期内没有改善,则停止训练。 -
restore_best_weights=True: 在训练结束时,恢复在验证集上获得最佳准确率时的模型权重。
-
-
拟合模型 :使用
model.fit方法训练模型。-
x=x_train和y=y_train: 分别指定训练数据的特征和标签。 -
epochs=num_epochs: 设置训练周期数。 -
batch_size=batch_size: 设置每个训练周期中使用的批量大小。 -
validation_split=0.15: 指定从训练数据中划分出15%作为验证集。 -
callbacks=[early_stopping]: 指定在训练过程中使用的回调函数列表,这里使用了早停法回调。
-
-
返回训练历史 :训练完成后,函数返回包含训练和验证过程中损失和准确率信息的历史记录对象
history。
这个函数封装了模型训练的整个过程,使得可以方便地对不同的模型配置进行实验,并通过早停法来优化训练过程。通过分析返回的history对象,可以了解模型在训练过程中的性能变化。
python
def run_experiment(model, x_train, y_train):
# Compile the model.
model.compile(
optimizer=keras.optimizers.Adam(learning_rate),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
# Create an early stopping callback.
early_stopping = keras.callbacks.EarlyStopping(
monitor="val_acc", patience=50, restore_best_weights=True
)
# Fit the model.
history = model.fit(
x=x_train,
y=y_train,
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.15,
callbacks=[early_stopping],
)
return history定义了一个名为 display_learning_curves 的函数,它的作用是将模型训练过程中的损失和准确率绘制成图表,以便可视化训练进度和性能。
-
创建图形和轴 :使用
plt.subplots创建一个图形 (fig) 和两个子图轴 (ax1,ax2)。这个图形有1行2列,每个子图的大小为宽15英寸、高5英寸。 -
绘制损失曲线 :
-
在
ax1上绘制训练损失 ("loss") 和验证损失 ("val_loss")。 -
使用
ax1.plot分别绘制训练和验证的损失历史。
-
-
设置图例和标签 :
-
使用
ax1.legend添加图例,标明哪些线代表训练损失,哪些代表验证损失。 -
使用
ax1.set_xlabel和ax1.set_ylabel分别设置x轴和y轴的标签。
-
-
绘制准确率曲线 :
-
同样,在
ax2上绘制训练准确率 ("acc") 和验证准确率 ("val_acc")。 -
使用
ax2.plot分别绘制训练和验证的准确率历史。
-
-
设置准确率曲线的图例和标签:与损失曲线类似,设置图例和轴标签。
-
显示图形 :最后,使用
plt.show()显示整个图形。
通过这个函数,可以直观地观察模型在各个周期(epochs)上的训练损失和准确率,以及它们在验证集上的表现。这有助于分析模型的训练动态,比如是否存在过拟合(训练损失持续下降而验证损失上升)或欠拟合(训练和验证损失都较高且没有显著下降)。同时,准确率曲线可以帮助我们了解模型在训练和验证集上的预测性能。
python
def display_learning_curves(history):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
ax1.plot(history.history["loss"])
ax1.plot(history.history["val_loss"])
ax1.legend(["train", "test"], loc="upper right")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax2.plot(history.history["acc"])
ax2.plot(history.history["val_acc"])
ax2.legend(["train", "test"], loc="upper right")
ax2.set_xlabel("Epochs")
ax2.set_ylabel("Accuracy")
plt.show()2.5 定义前馈神经网络(FFN)模块
定义了一个函数 create_ffn,用于创建一个前馈神经网络(Feed-Forward Neural Network,FFN)模块。这个模块是一个序列化的模型,可以作为图神经网络中的一部分,用于节点特征的转换和处理。
-
初始化层列表 :首先,创建一个空列表
fnn_layers,用于存储FFN中的各个层。 -
循环添加层 :使用
for循环遍历hidden_units列表,这个列表包含了FFN中每层的单元数(神经元数)。对于hidden_units中的每个单元数units:-
添加一个批量归一化层(
layers.BatchNormalization()),这有助于加速训练过程并提高模型稳定性。 -
添加一个 dropout 层(
layers.Dropout(dropout_rate)),这个层在训练时随机丢弃一些神经元的输出,以防止过拟合。 -
添加一个全连接层(
layers.Dense(units, activation=tf.nn.gelu)),其中units是该层的单元数,tf.nn.gelu是激活函数,GELU(Gaussian Error Linear Unit)是一种常用的激活函数,它可以提供非线性特性。
-
-
创建序列模型 :使用
keras.Sequential将列表fnn_layers中的所有层按顺序组合成一个序列化模型。这个模型可以接收输入数据,然后逐层传递,最终输出转换后的特征。 -
设置模型名称 :如果提供了
name参数,将其用作序列模型的名称。 -
返回模型:最后,函数返回创建的FFN模型。
这个 create_ffn 函数提供了一个灵活的方式来构建FFN模块,可以根据不同的需求调整隐藏单元的数量和dropout率,以适应不同的图神经网络架构。通过这种方式,可以轻松地在GNN模型中实现复杂的特征转换和处理逻辑。
python
def create_ffn(hidden_units, dropout_rate, name=None):
fnn_layers = []
for units in hidden_units:
fnn_layers.append(layers.BatchNormalization())
fnn_layers.append(layers.Dropout(dropout_rate))
fnn_layers.append(layers.Dense(units, activation=tf.nn.gelu))
return keras.Sequential(fnn_layers, name=name)2.6 构建基准神经网络模型
代码是数据预处理的一部分,主要负责从Cora数据集中提取特征和目标,并将它们转换为适合模型训练和测试的格式。
-
特征名称提取 :
feature_names = list(set(papers.columns) - {"paper_id", "subject"}): 这行代码首先从papersDataFrame中获取所有列名,然后使用集合操作去除"paper_id"和"subject"这两列,因为它们不是特征列。结果是一个包含所有特征列名的列表feature_names。 -
计算特征数量 :
num_features = len(feature_names): 通过获取feature_names列表的长度,计算出数据集中特征的总数。 -
计算类别数量 :
num_classes = len(class_idx): 通过获取前面创建的class_idx字典的长度,计算出数据集中类别的总数。这个字典将每个主题映射到一个唯一的索引。 -
创建训练和测试特征数组 :
-
x_train = train_data[feature_names].to_numpy(): 从train_dataDataFrame中选取feature_names列表包含的列,然后将这些特征转换为NumPy数组x_train,用于模型训练。 -
x_test = test_data[feature_names].to_numpy(): 同上,从test_dataDataFrame中选取特征列并转换为NumPy数组x_test,用于模型测试。
-
-
创建训练和测试目标数组 :
-
y_train = train_data["subject"]: 从train_dataDataFrame中选取"subject"列,这是训练数据的目标(即论文的主题),并将其用作模型训练的目标数组。 -
y_test = test_data["subject"]: 同上,从test_dataDataFrame中选取"subject"列,作为模型测试的目标数组。
-
通过这些步骤,代码准备好了用于训练和测试图神经网络模型的数据。x_train和x_test包含了输入特征,而y_train和y_test包含了对应的目标标签。这种数据格式是大多数机器学习模型训练所必需的。
python
feature_names = list(set(papers.columns) - {"paper_id", "subject"})
num_features = len(feature_names)
num_classes = len(class_idx)
# Create train and test features as a numpy array.
x_train = train_data[feature_names].to_numpy()
x_test = test_data[feature_names].to_numpy()
# Create train and test targets as a numpy array.
y_train = train_data["subject"]
y_test = test_data["subject"]2.6.1 定义基准分类器
我们添加了五个带有跳跃连接的前馈网络(FFN)块,以便生成一个基准模型,该模型大致具有与稍后要构建的图神经网络(GNN)模型相同数量的参数。
定义了一个函数 create_baseline_model 用于创建一个基线模型,这个模型是一个多层前馈神经网络(FFN),用于作为图神经网络(GNN)模型的对比基准。然后,代码实例化了这个基线模型并打印了其结构摘要。以下是详细步骤:
-
定义基线模型函数 :接收参数:隐藏层单元数
hidden_units,类别数num_classes,以及可选的dropout率dropout_rate。 -
创建输入层 :使用
layers.Input定义模型的输入层,其形状由num_features决定。 -
创建第一个FFN块 :调用之前定义的
create_ffn函数创建第一个FFN块,命名为ffn_block1。 -
循环创建额外的FFN块和跳跃连接 :
-
使用
for循环创建额外的4个FFN块,每个块后面跟一个跳跃连接(skip connection)。 -
每个FFN块通过
create_ffn函数创建,并以f"ffn_block{block_idx + 2}"命名。 -
使用
layers.Add创建跳跃连接,将前一个FFN块的输出与当前FFN块的输出相加。
-
-
计算 logits :使用
layers.Dense创建一个全连接层,其单元数等于类别数num_classes,用于计算每个类别的原始分数(logits)。 -
创建Keras模型 :将输入层和最后的logits层包装成一个
keras.Model对象,命名为 "baseline"。 -
实例化基线模型 :调用
create_baseline_model函数并传入相应的参数来创建基线模型实例。 -
打印模型摘要 :使用
baseline_model.summary()打印模型的层级结构和参数数量。
这个基线模型通过堆叠多个FFN块并使用跳跃连接来学习数据的表示,它将作为后续图神经网络模型性能的对比基准。通过比较基线模型和GNN模型的性能,可以评估GNN模型利用图结构信息的能力。
python
def create_baseline_model(hidden_units, num_classes, dropout_rate=0.2):
inputs = layers.Input(shape=(num_features,), name="input_features")
x = create_ffn(hidden_units, dropout_rate, name=f"ffn_block1")(inputs)
for block_idx in range(4):
# Create an FFN block.
x1 = create_ffn(hidden_units, dropout_rate, name=f"ffn_block{block_idx + 2}")(x)
# Add skip connection.
x = layers.Add(name=f"skip_connection{block_idx + 2}")([x, x1])
# Compute logits.
logits = layers.Dense(num_classes, name="logits")(x)
# Create the model.
return keras.Model(inputs=inputs, outputs=logits, name="baseline")
baseline_model = create_baseline_model(hidden_units, num_classes, dropout_rate)
baseline_model.summary()2.6.2 训练基准分类器
代码执行了基线模型的训练实验,并记录了训练过程中的详细统计信息。
-
调用训练函数 :使用
run_experiment函数来训练baseline_model,这是之前定义的基线模型。 -
训练数据 :将训练特征
x_train和训练目标y_train作为参数传递给run_experiment函数。这些数据是从Cora数据集的论文特征和主题标签中提取并预处理得到的。 -
编译模型 :在
run_experiment函数内部,模型首先被编译,设置好优化器(使用定义的学习率)、损失函数(稀疏分类交叉熵),以及评估指标(稀疏分类准确率)。 -
设置早停法:创建一个早停回调,用于监控验证集上的准确率。如果在50个周期内验证准确率没有提升,则停止训练过程,并恢复到最佳权重状态。
-
训练模型:模型使用指定的周期数、批量大小和验证分割比例进行训练。训练过程中会应用早停法和其他回调函数。
-
记录训练历史 :训练过程结束后,
run_experiment函数返回一个history对象,其中包含了训练和验证过程中的损失值和准确率等信息。 -
输出结果 :通过打印
history对象,可以查看模型在每个周期结束时的损失和准确率,以及早停法是否触发和在哪个周期触发的。
这个步骤是机器学习流程中模型训练的关键环节,它为后续的模型评估和调优提供了必要的信息和数据。通过分析history对象,可以对模型的训练效果有一个直观的了解。
python
history = run_experiment(baseline_model, x_train, y_train)
display_learning_curves(history)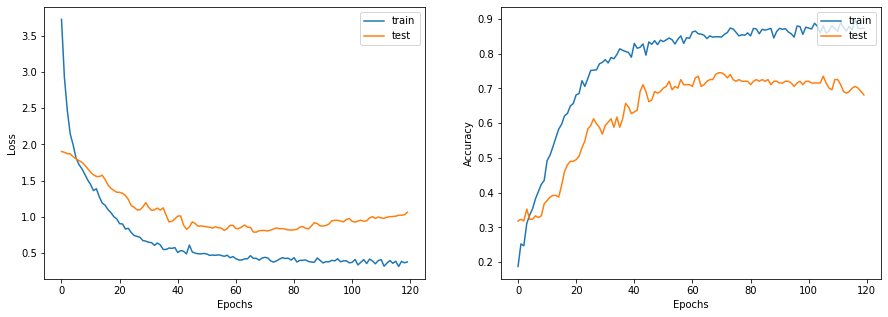
2.6.3 评估基准模型
现在我们使用测试数据拆分来评估基准模型。
-
模型评估 :使用
baseline_model.evaluate方法对模型进行评估。这个方法将返回模型在指定数据上的损失值和评估指标值。 -
测试数据 :传入测试集的特征
x_test和目标y_test作为评估的输入数据。 -
设置参数 :
verbose=0:设置为0表示在评估过程中不打印进度信息,使输出更加简洁。 -
获取测试准确率 :
baseline_model.evaluate方法返回两个值,第一个是损失值,第二个是准确率。这里使用下划线_来忽略损失值,只获取准确率。 -
计算百分比:将准确率乘以100,将其转换为百分比形式,以便于直观理解模型的性能。
-
四舍五入 :使用
round函数将准确率的百分比值四舍五入到小数点后两位,以提供更精确的展示。 -
打印结果 :最后,使用
print函数输出测试准确率的最终结果,并格式化为百分比形式。
通过这段代码,我们可以得到基线模型在未见过的数据上的表现,这是一个重要的指标,用来评估模型的泛化能力。如果准确率较高,说明模型在新数据上也能做出准确的预测;如果准确率较低,则可能需要进一步调整模型或使用更多的训练数据。
python
test_accuracy = baseline_model.evaluate(x=x_test, y=y_test, verbose=0)
print(f"Test accuracy: {round(test_accuracy * 100, 2)}%")2.7 检查基准模型的预测能力
我们通过随机生成关于单词出现概率的二进制词向量来创建新的数据实例。
2.7.1 定义函数
定义了两个函数,用于生成随机实例并展示模型对这些实例的分类概率预测。
-
generate_random_instances函数 :-
作用:生成指定数量的随机二进制实例,这些实例可以代表论文的单词出现概率。
-
参数
num_instances:需要生成的实例数量。 -
token_probability:使用训练集特征x_train的每列(即每个单词)的平均值来计算单词出现的概率。 -
循环:对于每个要生成的实例,使用
np.random.uniform生成一个与token_probability长度相同的随机数组,然后通过比较这些随机数与相应单词出现概率来创建一个二进制实例。如果随机数小于或等于单词出现概率,则该单词在实例中的值为1,否则为0。 -
返回值:将所有生成的实例作为一个NumPy数组返回。
-
-
display_class_probabilities函数 :-
作用:展示模型对每个实例的分类概率预测。
-
参数
probabilities:模型预测的每个实例的分类概率数组。 -
循环:遍历每个实例及其预测概率,
class_idx用于遍历每个类别的概率。 -
输出:打印每个实例的索引和每个类别的预测概率(转换为百分比并四舍五入到小数点后两位)。
-
这两个函数通常用于模型的解释性分析,帮助理解模型如何对输入实例进行分类预测。通过生成随机实例,可以模拟模型在面对未知或随机数据时的行为。展示分类概率可以帮助分析模型预测的置信度和多样性。
python
def generate_random_instances(num_instances):
token_probability = x_train.mean(axis=0)
instances = []
for _ in range(num_instances):
probabilities = np.random.uniform(size=len(token_probability))
instance = (probabilities <= token_probability).astype(int)
instances.append(instance)
return np.array(instances)
def display_class_probabilities(probabilities):
for instance_idx, probs in enumerate(probabilities):
print(f"Instance {instance_idx + 1}:")
for class_idx, prob in enumerate(probs):
print(f"- {class_values[class_idx]}: {round(prob * 100, 2)}%")2.7.2 实施预测
调用2.7.1 定义的函数和模型来生成随机实例,获取模型对这些实例的预测,并展示预测结果的分类概率。以下是详细步骤:
-
生成随机实例 : 调用
generate_random_instances函数,并传入num_classes作为参数,以生成与类别数量相同数量的随机实例。这些实例是根据训练数据中单词出现的平均概率随机生成的二进制向量。 -
模型预测 :使用
baseline_model.predict方法对生成的随机实例进行预测。这将返回模型对于每个实例的原始输出(logits)。 -
转换为概率 : 将模型的原始输出(logits)通过softmax函数转换为概率。这里使用
tf.convert_to_tensor将logits转换为Tensor,然后调用keras.activations.softmax来应用softmax函数。最后,使用numpy方法将概率转换为NumPy数组。 -
展示分类概率 :调用
display_class_probabilities函数,传入上一步得到的分类概率数组。这个函数将遍历每个实例,并打印出每个实例属于每个类别的概率。 -
输出结果:对于每个随机生成的实例,将按照类别索引顺序打印出每个类别的预测概率,概率值会被四舍五入到小数点后两位,并以百分比的形式展示。
通过这个过程,可以获得模型对于随机数据的响应,这有助于理解模型的泛化能力和预测行为。由于这些实例是随机生成的,它们并不代表实际的论文内容,但可以作为模型输出的一个参考。
python
new_instances = generate_random_instances(num_classes)
logits = baseline_model.predict(new_instances)
probabilities = keras.activations.softmax(tf.convert_to_tensor(logits)).numpy()
display_class_probabilities(probabilities)
python
Instance 1:
- Case_Based: 13.02%
- Genetic_Algorithms: 6.89%
- Neural_Networks: 23.32%
- Probabilistic_Methods: 47.89%
- Reinforcement_Learning: 2.66%
- Rule_Learning: 1.18%
- Theory: 5.03%
Instance 2:
- Case_Based: 1.64%
- Genetic_Algorithms: 59.74%
- Neural_Networks: 27.13%
- Probabilistic_Methods: 9.02%
- Reinforcement_Learning: 1.05%
- Rule_Learning: 0.12%
- Theory: 1.31%
Instance 3:
- Case_Based: 1.35%
- Genetic_Algorithms: 77.41%
- Neural_Networks: 9.56%
- Probabilistic_Methods: 7.89%
- Reinforcement_Learning: 0.42%
- Rule_Learning: 0.46%
- Theory: 2.92%
Instance 4:
- Case_Based: 0.43%
- Genetic_Algorithms: 3.87%
- Neural_Networks: 92.88%
- Probabilistic_Methods: 0.97%
- Reinforcement_Learning: 0.56%
- Rule_Learning: 0.09%
- Theory: 1.2%
Instance 5:
- Case_Based: 0.11%
- Genetic_Algorithms: 0.17%
- Neural_Networks: 10.26%
- Probabilistic_Methods: 0.5%
- Reinforcement_Learning: 0.35%
- Rule_Learning: 0.63%
- Theory: 87.97%
Instance 6:
- Case_Based: 0.98%
- Genetic_Algorithms: 23.37%
- Neural_Networks: 70.76%
- Probabilistic_Methods: 1.12%
- Reinforcement_Learning: 2.23%
- Rule_Learning: 0.21%
- Theory: 1.33%
Instance 7:
- Case_Based: 0.64%
- Genetic_Algorithms: 2.42%
- Neural_Networks: 27.19%
- Probabilistic_Methods: 14.07%
- Reinforcement_Learning: 1.62%
- Rule_Learning: 9.35%
- Theory: 44.7%2.8 构建图神经网络模型
2.8.1 准备数据
将图数据准备并加载到模型中进行训练是图神经网络(GNN)模型中最具挑战性的部分,这通常由专业库以不同的方式解决。在这个例子中,我们展示了一个简单的方法来准备和使用图数据,这种方法适用于你的数据集由单个完全可以在内存中加载的图组成的情况。
图数据由graph_info元组表示,它包含以下三个元素:
node_features:这是一个num_nodes,num_features的NumPy数组,包含了节点特征。在这个数据集中,节点是论文,而node_features是每个论文的单词存在二进制向量。edges:这是一个num_edges, 2的NumPy数组(注意,这里应该是num_edges,2,而不是num_edges, num_edges),表示节点之间链接的稀疏邻接矩阵。在这个例子中,链接是论文之间的引用。edge_weights(可选):这是一个num_edges的NumPy数组,包含了边的权重,这些权重量化了图中节点之间的关系。在这个例子中,论文引用之间没有权重。
以下代码实现图神经网络模型中图数据的准备工作:
-
创建边数组 :使用
citationsDataFrame中的"source"和"target"列创建一个稀疏邻接矩阵,表示图中的边。.to_numpy().T将DataFrame转换为NumPy数组,并转置它,以得到形状为[2, num_edges]的数组,其中num_edges是边的数量。 -
创建边权重数组 :使用
tf.ones创建一个形状为[num_edges]的数组,并将所有元素初始化为1。这个数组edge_weights表示每条边的权重,在本例中所有边的权重相同,没有特定的权重信息。 -
创建节点特征数组 :首先对
papersDataFrame按照"paper_id"列进行排序,然后选择特征列(feature_names),将这些特征转换为NumPy数组。使用tf.cast将这个NumPy数组转换为tf.dtypes.float32类型的Tensor,以适配TensorFlow模型的输入要求。结果是一个形状为[num_nodes, num_features]的数组node_features,其中num_nodes是节点的数量,num_features是每个节点的特征数量。 -
创建图信息元组 :将
node_features、edges和edge_weights打包成一个元组graph_info,这个元组将作为图神经网络模型的输入,提供图的结构和节点特征信息。 -
打印形状信息:打印出边数组和节点特征数组的形状,以验证它们是否符合预期的尺寸。
通过这些步骤,代码准备好了图神经网络模型所需的图数据结构,包括节点特征、边的连接信息以及边的权重,这些信息将被用于后续的图神经网络模型训练和推理。
python
# Create an edges array (sparse adjacency matrix) of shape [2, num_edges].
edges = citations[["source", "target"]].to_numpy().T
# Create an edge weights array of ones.
edge_weights = tf.ones(shape=edges.shape[1])
# Create a node features array of shape [num_nodes, num_features].
node_features = tf.cast(
papers.sort_values("paper_id")[feature_names].to_numpy(), dtype=tf.dtypes.float32
)
# Create graph info tuple with node_features, edges, and edge_weights.
graph_info = (node_features, edges, edge_weights)
print("Edges shape:", edges.shape)
print("Nodes shape:", node_features.shape)2.8.2 实现图卷积层
我们将图卷积模块实现为一个Keras层。我们的GraphConvLayer执行以下步骤:
准备:输入节点表示通过全连接网络(FFN)进行处理以生成消息。你可以通过仅对表示应用线性变换来简化处理过程。
聚合:使用与edge_weights相关的排列不变池化操作(如求和、均值和最大值)来聚合每个节点的邻居的消息,为每个节点准备一个单一的聚合消息。例如,可以使用tf.math.unsorted_segment_sum API 来聚合邻居消息。
更新:node_representations和aggregated_messages(两者都是num_nodes, representation_dim的形状)被组合并处理以生成节点表示的新状态(节点嵌入)。如果combination_type是gru,那么node_repesentations和aggregated_messages会被堆叠成一个序列,然后通过一个GRU层进行处理。否则,node_repesentations和aggregated_messages会被相加或连接,然后通过一个FFN进行处理。
所实现的技术借鉴了图卷积网络(Graph Convolutional Networks)、GraphSage、图同构网络(Graph Isomorphism Network)、简单图网络(Simple Graph Networks)和门控图序列神经网络(Gated Graph Sequence Neural Networks)的思想。另外两种未涵盖的关键技术是图注意力网络(Graph Attention Networks)和消息传递神经网络(Message Passing Neural Networks)。
图卷积层GraphConvLayer的实现包括以下几个关键部分:
-
创建GRU模型 :
create_gru函数用于创建一个具有门控循环单元(GRU)的模型,这个模型将用于后续的节点更新操作。输入参数hidden_units和dropout_rate分别定义了GRU层的大小和dropout率。 -
定义图卷积层 :
GraphConvLayer类继承自layers.Layer,是一个图卷积操作的实现。 -
初始化层参数 : 在
__init__方法中,定义了层的参数,包括隐藏单元数hidden_units,dropout率dropout_rate,聚合类型aggregation_type,组合类型combination_type,以及是否进行归一化normalize。 -
准备节点表示 :
prepare方法使用一个前馈神经网络(通过create_ffn函数创建)来准备节点的消息。 -
聚合邻居消息 :
aggregate方法根据节点的索引和邻居的消息来聚合信息,支持求和、平均和最大值聚合。 -
更新节点嵌入 :
update方法根据聚合的消息和节点当前的表示来更新节点的嵌入。如果组合类型是"gru",则使用GRU层;否则,使用前馈网络。 -
层的前向传播 :
call方法是层的前向传播实现,它接收节点表示、边和边权重作为输入,并返回更新后的节点嵌入。 -
层的调用 : 当调用
GraphConvLayer实例时,将执行call方法,处理输入数据以产生节点嵌入。
这个GraphConvLayer的设计结合了前馈网络和GRU单元来更新节点表示,使其能够捕捉图中的局部结构和节点间的关系。通过这种方式,图神经网络可以学习到节点的嵌入表示,这些表示可以用于各种下游任务,例如节点分类或图分类。
python
def create_gru(hidden_units, dropout_rate):
inputs = keras.layers.Input(shape=(2, hidden_units[0]))
x = inputs
for units in hidden_units:
x = layers.GRU(
units=units,
activation="tanh",
recurrent_activation="sigmoid",
return_sequences=True,
dropout=dropout_rate,
return_state=False,
recurrent_dropout=dropout_rate,
)(x)
return keras.Model(inputs=inputs, outputs=x)
class GraphConvLayer(layers.Layer):
def __init__(
self,
hidden_units,
dropout_rate=0.2,
aggregation_type="mean",
combination_type="concat",
normalize=False,
*args,
**kwargs,
):
super().__init__(*args, **kwargs)
self.aggregation_type = aggregation_type
self.combination_type = combination_type
self.normalize = normalize
self.ffn_prepare = create_ffn(hidden_units, dropout_rate)
if self.combination_type == "gru":
self.update_fn = create_gru(hidden_units, dropout_rate)
else:
self.update_fn = create_ffn(hidden_units, dropout_rate)
def prepare(self, node_repesentations, weights=None):
# node_repesentations shape is [num_edges, embedding_dim].
messages = self.ffn_prepare(node_repesentations)
if weights is not None:
messages = messages * tf.expand_dims(weights, -1)
return messages
def aggregate(self, node_indices, neighbour_messages, node_repesentations):
# node_indices shape is [num_edges].
# neighbour_messages shape: [num_edges, representation_dim].
# node_repesentations shape is [num_nodes, representation_dim]
num_nodes = node_repesentations.shape[0]
if self.aggregation_type == "sum":
aggregated_message = tf.math.unsorted_segment_sum(
neighbour_messages, node_indices, num_segments=num_nodes
)
elif self.aggregation_type == "mean":
aggregated_message = tf.math.unsorted_segment_mean(
neighbour_messages, node_indices, num_segments=num_nodes
)
elif self.aggregation_type == "max":
aggregated_message = tf.math.unsorted_segment_max(
neighbour_messages, node_indices, num_segments=num_nodes
)
else:
raise ValueError(f"Invalid aggregation type: {self.aggregation_type}.")
return aggregated_message
def update(self, node_repesentations, aggregated_messages):
# node_repesentations shape is [num_nodes, representation_dim].
# aggregated_messages shape is [num_nodes, representation_dim].
if self.combination_type == "gru":
# Create a sequence of two elements for the GRU layer.
h = tf.stack([node_repesentations, aggregated_messages], axis=1)
elif self.combination_type == "concat":
# Concatenate the node_repesentations and aggregated_messages.
h = tf.concat([node_repesentations, aggregated_messages], axis=1)
elif self.combination_type == "add":
# Add node_repesentations and aggregated_messages.
h = node_repesentations + aggregated_messages
else:
raise ValueError(f"Invalid combination type: {self.combination_type}.")
# Apply the processing function.
node_embeddings = self.update_fn(h)
if self.combination_type == "gru":
node_embeddings = tf.unstack(node_embeddings, axis=1)[-1]
if self.normalize:
node_embeddings = tf.nn.l2_normalize(node_embeddings, axis=-1)
return node_embeddings
def call(self, inputs):
"""Process the inputs to produce the node_embeddings.
inputs: a tuple of three elements: node_repesentations, edges, edge_weights.
Returns: node_embeddings of shape [num_nodes, representation_dim].
"""
node_repesentations, edges, edge_weights = inputs
# Get node_indices (source) and neighbour_indices (target) from edges.
node_indices, neighbour_indices = edges[0], edges[1]
# neighbour_repesentations shape is [num_edges, representation_dim].
neighbour_repesentations = tf.gather(node_repesentations, neighbour_indices)
# Prepare the messages of the neighbours.
neighbour_messages = self.prepare(neighbour_repesentations, edge_weights)
# Aggregate the neighbour messages.
aggregated_messages = self.aggregate(
node_indices, neighbour_messages, node_repesentations
)
# Update the node embedding with the neighbour messages.
return self.update(node_repesentations, aggregated_messages)2.8.3 实现图神经网络节点分类器
图神经网络(GNN)分类模型遵循图神经网络设计空间的方法,如下所述:
- 使用全连接网络(FFN)对节点特征进行预处理,以生成初始节点表示。
- 将一个或多个图卷积层(带有跳跃连接)应用于节点表示,以生成节点嵌入。
- 使用全连接网络(FFN)对节点嵌入进行后处理,以生成最终的节点嵌入。
- 将节点嵌入输入到Softmax层中以预测节点类别。
每个添加的图卷积层都会捕获来自更高级别邻居的信息。然而,添加过多的图卷积层可能会导致过平滑,即模型为所有节点生成相似的嵌入。
请注意,传递给Keras模型构造函数的graph_info,并作为Keras模型对象的属性使用,而不是训练或预测的输入数据。模型将接受一批节点索引(node_indices),这些索引用于从graph_info中查找节点特征和邻居。
首先义一个名为 GNNNodeClassifier 的类,它是一个基于图神经网络(GNN)的节点分类器,使用 TensorFlow 框架。
-
class GNNNodeClassifier(tf.keras.Model):定义了一个继承自tf.keras.Model的类,这意味着它是一个模型类,可以用于构建和训练深度学习模型。 -
__init__是类的构造函数,用于初始化模型的参数:-
graph_info: 包含图信息的元组,包括节点特征、边和边权重。 -
num_classes: 类别数,用于最终分类的输出。 -
hidden_units: 隐藏层单元数,用于定义模型中隐藏层的大小。 -
aggregation_type: 聚合类型,定义了如何聚合邻居节点的特征。 -
combination_type: 组合类型,定义了如何将节点自身特征和邻居特征组合。 -
dropout_rate: 丢弃率,用于正则化以防止过拟合。 -
normalize: 是否对边权重进行归一化处理。
-
-
super().__init__(*args, **kwargs)调用父类的构造函数。 -
node_features, edges, edge_weights = graph_info从graph_info中解包出节点特征、边和边权重。 -
如果
edge_weights未提供,则将其设置为与边数量相同的1的数组。 -
将
edge_weights归一化,使得所有边权重的和为1。 -
self.preprocess创建一个前处理层,用于对节点特征进行预处理。 -
self.conv1和self.conv2分别创建了两个图卷积层,这些层是 GNN 的核心,用于学习节点的表示。 -
self.postprocess创建一个后处理层,用于对经过图卷积层后的节点特征进行进一步处理。 -
self.compute_logits是一个密集层,用于将节点的嵌入转换为类别的对数几率(logits)。 -
def call(self, input_node_indices):定义了模型的调用函数,它接受输入节点的索引,并返回这些节点的分类结果:-
x = self.preprocess(self.node_features)对节点特征进行预处理。 -
x1 = self.conv1(...)应用第一个图卷积层,并使用残差连接。 -
x2 = self.conv2(...)应用第二个图卷积层,并使用残差连接。 -
x = self.postprocess(x)对节点嵌入进行后处理。 -
node_embeddings = tf.gather(x, input_node_indices)根据输入的节点索引提取对应的节点嵌入。 -
return self.compute_logits(node_embeddings)计算并返回分类的 logits。
-
这个模型通过图卷积层来学习节点的表示,并通过残差连接来帮助梯度流动,防止深层网络中的梯度消失问题。最终,模型通过一个密集层来输出每个节点属于各个类别的对数几率。
python
class GNNNodeClassifier(tf.keras.Model):
def __init__(
self,
graph_info,
num_classes,
hidden_units,
aggregation_type="sum",
combination_type="concat",
dropout_rate=0.2,
normalize=True,
*args,
**kwargs,
):
super().__init__(*args, **kwargs)
# Unpack graph_info to three elements: node_features, edges, and edge_weight.
node_features, edges, edge_weights = graph_info
self.node_features = node_features
self.edges = edges
self.edge_weights = edge_weights
# Set edge_weights to ones if not provided.
if self.edge_weights is None:
self.edge_weights = tf.ones(shape=edges.shape[1])
# Scale edge_weights to sum to 1.
self.edge_weights = self.edge_weights / tf.math.reduce_sum(self.edge_weights)
# Create a process layer.
self.preprocess = create_ffn(hidden_units, dropout_rate, name="preprocess")
# Create the first GraphConv layer.
self.conv1 = GraphConvLayer(
hidden_units,
dropout_rate,
aggregation_type,
combination_type,
normalize,
name="graph_conv1",
)
# Create the second GraphConv layer.
self.conv2 = GraphConvLayer(
hidden_units,
dropout_rate,
aggregation_type,
combination_type,
normalize,
name="graph_conv2",
)
# Create a postprocess layer.
self.postprocess = create_ffn(hidden_units, dropout_rate, name="postprocess")
# Create a compute logits layer.
self.compute_logits = layers.Dense(units=num_classes, name="logits")
def call(self, input_node_indices):
# Preprocess the node_features to produce node representations.
x = self.preprocess(self.node_features)
# Apply the first graph conv layer.
x1 = self.conv1((x, self.edges, self.edge_weights))
# Skip connection.
x = x1 + x
# Apply the second graph conv layer.
x2 = self.conv2((x, self.edges, self.edge_weights))
# Skip connection.
x = x2 + x
# Postprocess node embedding.
x = self.postprocess(x)
# Fetch node embeddings for the input node_indices.
node_embeddings = tf.gather(x, input_node_indices)
# Compute logits
return self.compute_logits(node_embeddings)2.8.4 测试GNN
测试一下GNN(图神经网络)模型的实例化和调用。请注意,如果你提供了N个节点索引作为输入,那么输出将是一个形状为N, num_classes的张量,这与图的大小无关。
首先创建了一个 GNNNodeClassifier 类的实例,然后打印了模型的输出形状,并显示了模型的摘要。
-
gnn_model = GNNNodeClassifier(...)创建了GNNNodeClassifier的实例,其中:-
graph_info是一个包含图信息的元组,它包括节点特征、边和边权重。 -
num_classes是分类任务中的类别数。 -
hidden_units是模型中隐藏层的大小。 -
dropout_rate是模型中使用的丢弃率。 -
name="gnn_model"给模型实例指定了一个名称。
-
-
print("GNN output shape:", gnn_model([1, 10, 100]))打印了模型对输入节点索引[1, 10, 100]的输出形状。这里的[1, 10, 100]表示我们想要模型预测这三个节点的类别。由于num_classes定义了类别的数量,输出形状将是(3, num_classes),其中3是输入节点索引的数量。 -
gnn_model.summary()打印了模型的摘要,这包括了模型的层、每层的参数数量、激活函数等信息。这有助于理解模型的结构和复杂性。
python
gnn_model = GNNNodeClassifier(
graph_info=graph_info,
num_classes=num_classes,
hidden_units=hidden_units,
dropout_rate=dropout_rate,
name="gnn_model",
)
print("GNN output shape:", gnn_model([1, 10, 100]))
gnn_model.summary()2.8.5 训练GNN模型
训练GNN模型时,我们使用了标准的监督交叉熵损失来训练模型。但是,我们可以为生成的节点嵌入添加一个自监督损失项,以确保图中相邻的节点具有相似的表示,而远离的节点具有不相似的表示。
调用定义的 GNNNodeClassifier 模型来进行训练,并记录训练过程:
-
x_train = train_data.paper_id.to_numpy():这行代码将训练数据集中的paper_id列转换为 NumPy 数组。train_data可能是一个 pandas DataFrame 或类似的数据结构,其中包含了训练数据。paper_id列可能包含了论文的唯一标识符,这些标识符将作为模型的输入。 -
history = run_experiment(gnn_model, x_train, y_train):这行代码调用了一个名为run_experiment的函数,该函数接收三个参数:-
gnn_model:之前创建的GNNNodeClassifier模型实例。 -
x_train:训练数据的特征输入,这里是转换为 NumPy 数组的paper_id。 -
y_train:训练数据的目标输出,这是模型需要预测的值,可能是论文的类别标签。
-
run_experiment 函数执行以下操作:
-
使用
x_train和y_train来训练gnn_model。 -
记录训练过程中的关键指标,如损失值和准确率,并将这些信息存储在
history对象中。 -
可能还包括验证过程,使用验证集来评估模型在未见过的数据上的表现。
history 对象通常包含了模型训练过程中的详细统计信息,可以用于后续的分析,比如绘制训练和验证损失曲线,评估模型性能等。
python
x_train = train_data.paper_id.to_numpy()
history = run_experiment(gnn_model, x_train, y_train)
display_learning_curves(history)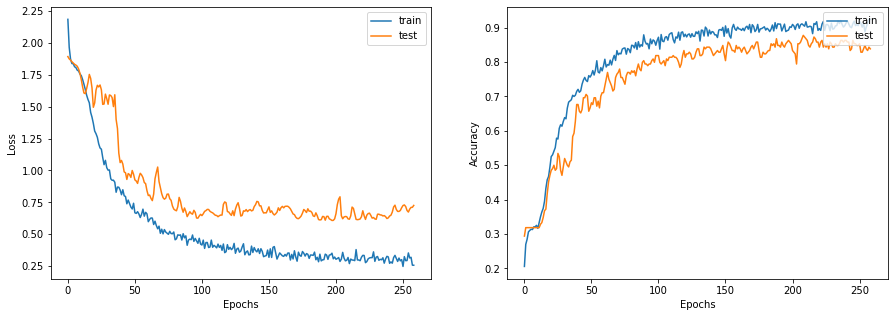
在测试数据集上评估GNN模型。结果可能会因训练样本的不同而有所变化,但GNN模型在测试准确率方面总是优于基线模型。
python
x_test = test_data.paper_id.to_numpy()
_, test_accuracy = gnn_model.evaluate(x=x_test, y=y_test, verbose=0)
print(f"Test accuracy: {round(test_accuracy * 100, 2)}%")
python
Test accuracy: 80.19%2.9 检查GNN模型的预测能力
让我们将新实例作为节点添加到node_features中,并为它们生成与现有节点之间的链接(引用)。
2.9.1 添加节点
-
添加新节点 :首先,代码通过将
new_instances特征追加到现有的node_features数组中,来将新的实例(例如新论文)作为节点添加到图中。这增加了图中的节点数量。 -
生成新节点索引 :接着,代码生成了一组新的节点索引
new_node_indices,这些索引将用于引用新添加的节点。索引的数量由num_classes决定,这里假设num_classes与新实例的数量相等。 -
创建新边:然后,代码通过遍历按主题分组的论文集合,为每个新节点创建引用边。对于每个主题:
- 选择当前主题下的5篇论文作为被引用的节点。
- 选择任意主题下的2篇论文作为被引用的节点。
- 将这两组被引用的节点索引合并。
- 对于每个新节点(即新论文),创建指向这些被引用节点的边。
-
更新边数组 :最后,将新创建的边作为数组
new_citations存储,并将其转置以匹配边的格式。然后,将这些新边追加到现有的边数组edges中,从而扩展了图的边矩阵。
这个过程模拟了新论文的引用行为,通过将新论文作为节点添加到图中,并将它们与现有论文通过边连接起来,来更新图的结构。这种更新对于图神经网络模型来说是重要的,因为它允许模型学习新论文的特征,并根据其与现有论文的关系进行分类。
python
# First we add the N new_instances as nodes to the graph
# by appending the new_instance to node_features.
num_nodes = node_features.shape[0]
new_node_features = np.concatenate([node_features, new_instances])
# Second we add the M edges (citations) from each new node to a set
# of existing nodes in a particular subject
new_node_indices = [i + num_nodes for i in range(num_classes)]
new_citations = []
for subject_idx, group in papers.groupby("subject"):
subject_papers = list(group.paper_id)
# Select random x papers specific subject.
selected_paper_indices1 = np.random.choice(subject_papers, 5)
# Select random y papers from any subject (where y < x).
selected_paper_indices2 = np.random.choice(list(papers.paper_id), 2)
# Merge the selected paper indices.
selected_paper_indices = np.concatenate(
[selected_paper_indices1, selected_paper_indices2], axis=0
)
# Create edges between a citing paper idx and the selected cited papers.
citing_paper_indx = new_node_indices[subject_idx]
for cited_paper_idx in selected_paper_indices:
new_citations.append([citing_paper_indx, cited_paper_idx])
new_citations = np.array(new_citations).T
new_edges = np.concatenate([edges, new_citations], axis=1)2.9.2 更新节点特征
现在让我们更新GNN模型中的node_features和边。
更新图神经网络模型 gnn_model 的内部状态,并使用更新后的模型来预测新节点的类别概率:
-
打印原始的
node_features和edges的形状:-
gnn_model.node_features包含了图的节点特征。 -
gnn_model.edges包含了图的边信息。
-
-
更新
gnn_model的属性:-
gnn_model.node_features = new_node_features:将之前通过添加新实例得到的新节点特征赋值给模型。 -
gnn_model.edges = new_edges:将之前通过添加新边得到的新边信息赋值给模型。 -
gnn_model.edge_weights = tf.ones(shape=new_edges.shape[1]):为新边创建权重,这里简单地为每个边分配权重1,这可能需要根据实际情况进行调整。
-
-
打印更新后的
node_features和edges的形状,以确认更新是否成功。 -
使用模型预测新节点的类别:
logits = gnn_model.predict(tf.convert_to_tensor(new_node_indices)):调用模型的predict方法来获取新节点的 logits。new_node_indices是新节点的索引数组。 -
将 logits 转换为概率:
probabilities = keras.activations.softmax(tf.convert_to_tensor(logits)).numpy():使用 softmax 函数将 logits 转换为概率分布。这里首先将 logits 转换为 TensorFlow 张量,然后应用 softmax 函数,最后将结果转换回 NumPy 数组。 -
显示新节点的类别概率:
display_class_probabilities(probabilities):这是一个假设存在的函数,用于显示或打印新节点的类别概率。这个函数的具体实现没有给出,但我们可以假设它以某种方式格式化并输出概率信息。
python
print("Original node_features shape:", gnn_model.node_features.shape)
print("Original edges shape:", gnn_model.edges.shape)
gnn_model.node_features = new_node_features
gnn_model.edges = new_edges
gnn_model.edge_weights = tf.ones(shape=new_edges.shape[1])
print("New node_features shape:", gnn_model.node_features.shape)
print("New edges shape:", gnn_model.edges.shape)
logits = gnn_model.predict(tf.convert_to_tensor(new_node_indices))
probabilities = keras.activations.softmax(tf.convert_to_tensor(logits)).numpy()
display_class_probabilities(probabilities)3. 总结
本文气密深入探索了如何使用Keras和图神经网络(GNN)库(如Spektral)来构建和训练一个模型,以处理引文网络数据。这种网络结构的数据常见于学术文献领域,其中节点代表论文,而边则代表论文之间的引用关系。
3.1 数据集与预处理
首先,我们使用了Cora数据集,这是一个广泛使用的引文网络数据集,包含了2708篇科学论文,每篇论文都被标记了所属的研究领域。为了将这些数据转化为模型可以处理的形式,我们进行了数据预处理。具体来说,我们为每个文档提取了特征向量(如使用TF-IDF或Word2Vec等方法),这些特征向量构成了图中的节点特征。同时,我们构建了邻接矩阵,其中每个元素表示两个文档之间是否存在引用关系,从而形成了图的边。
3.2 模型构建
接下来,我们构建了一个图神经网络(GNN)模型来处理这些数据。模型的核心是图神经网络层(如GraphConv层),这些层能够聚合节点的邻居信息。在每一次迭代中,图神经网络层都会将节点的特征与其邻居的特征进行聚合,从而生成新的节点表示。通过堆叠多个图神经网络层,我们可以捕获图中更广泛的上下文信息。
在聚合了足够的节点信息后,我们使用全连接层将节点表示映射到最终的输出类别。具体来说,我们为每个节点分配了一个类别标签(即论文所属的研究领域),并通过全连接层将这些节点表示转换为类别概率分布。
3.3 训练与评估
在训练过程中,我们采用了适当的优化器(如Adam)和损失函数(如交叉熵损失)。我们将数据集划分为训练集、验证集和测试集,以便在训练过程中评估模型的性能。在每个训练迭代中,我们使用训练集来更新模型的参数,并使用验证集来评估模型的性能。如果模型在验证集上的性能有所提高,则保存当前的模型参数作为最佳参数。
训练完成后,我们在测试集上评估了模型的性能。我们使用准确率、精确率、召回率和F1分数等指标来全面评估模型的性能。这些指标可以帮助我们了解模型在未见过的数据上的表现,并与其他模型进行比较。
3.4 展望
本文详细展示了如何使用Keras和图神经网络库来处理引文网络数据。这个例子不仅让我们深入了解了GNN的工作原理和应用场景,还为我们进一步研究和应用GNN提供了宝贵的经验。在未来,我们可以尝试使用更复杂的GNN结构、更先进的优化算法和更丰富的特征表示来提高模型的性能,并探索GNN在其他领域的应用潜力。